
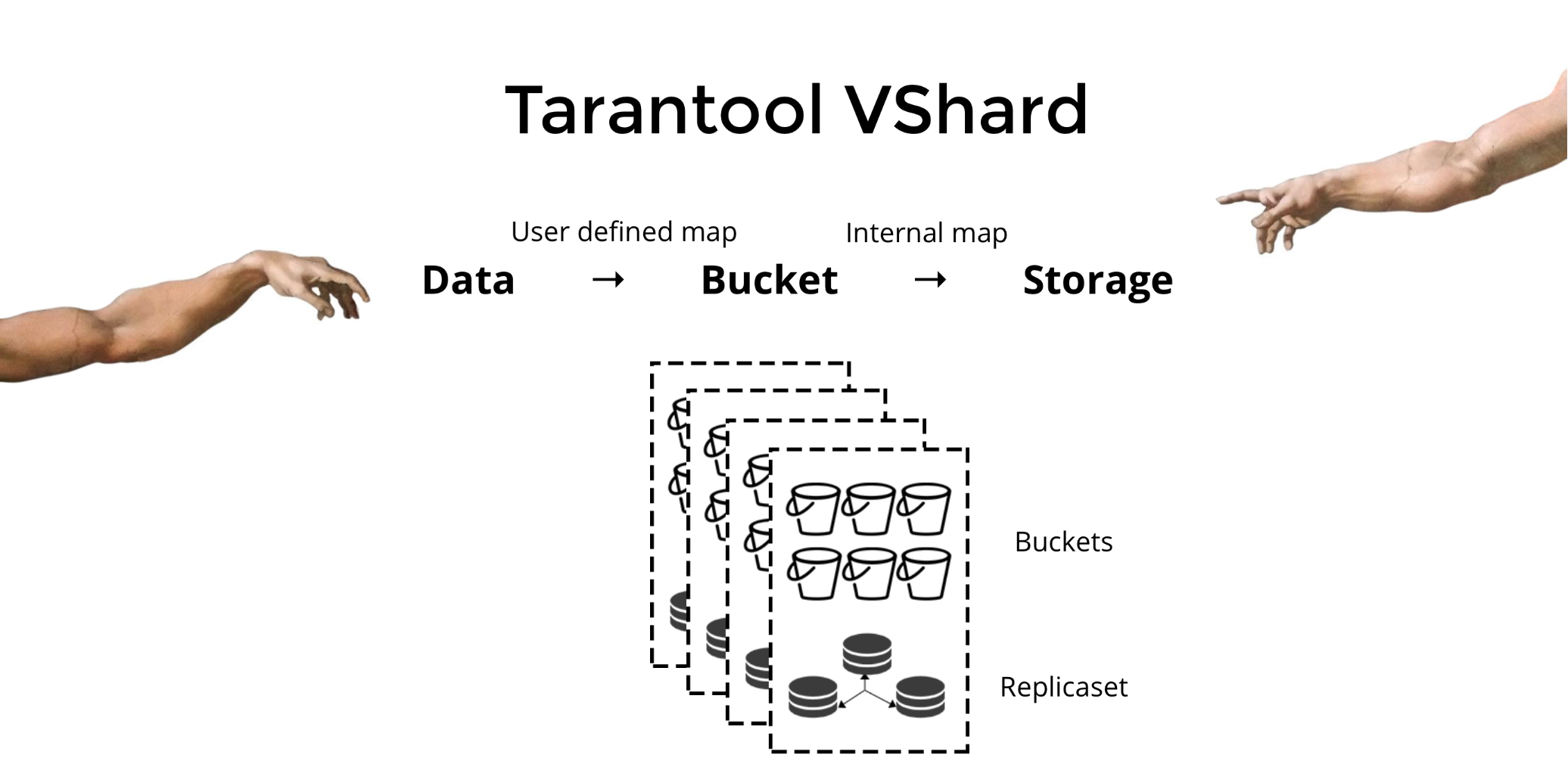
Меня зовут Владислав, я участвую в разработке Tarantool — СУБД и сервера приложений в одном флаконе. И сегодня расскажу вам, как мы реализовали горизонтальное масштабирование в Tarantool при помощи модуля VShard.
Сначала немного теории.
Масштабирование бывает двух типов: горизонтальное и вертикальное. Горизонтальное делится на два типа: репликацию и шардинг. Репликация служит для масштабирования вычислений, шардинг — для масштабирования данных.
Шардинг делится еще на два типа: шардинг диапазонами и шардинг хешами.
При шардинге диапазонами мы от каждой записи в кластере вычисляем некоторый шард-ключ. Эти шард-ключи проецируются на прямую линию, которая делится на диапазоны, которые мы складываем на разные физические узлы.
Шардинг хешами проще: от каждой записи в кластере считаем хеш-функцию, записи с одинаковым значением хеш-функции складываем на один физический узел.
Я расскажу про горизонтальное масштабирование при помощи шардирования по хешам.
Предыдущая реализация
Первым модулем горизонтального масштабирования у нас был Tarantool Shard. Это очень простой шардинг хешами, который считает шард-ключ от первичного ключа всех записей в кластере.
function shard_function(primary_key)
return guava(crc32(primary_key), shard_count)
endНо потом возникла задача, с которой Tarantool Shard оказался неспособен справиться по трем фундаментальным причинам.
Во-первых, требовалась локальность логически связанных данных. Когда у нас есть данные, которые связаны логически, мы хотим всегда хранить их на одном физическом узле, как бы ни менялась топология кластера и ни проводилась балансировка. А Tarantool Shard этого не гарантирует. Он считает хеш только по первичным ключам, и при перебалансировке даже записи с одинаковым хешем могут на какое-то время разделиться — перенос не атомарен.
Проблема отсутствия локальности данных мешала нам больше всего. Приведу пример. Есть банк, в котором клиент открыл счёт. Данные о счёте и клиенте нужно всегда физически хранить вместе, чтобы их можно было прочитать за один запрос, поменять за одну транзакцию, например, при переводе денег со счёта. Если использовать классический шардинг с Tarantool Shard, то у счетов и клиентов значения шард-функции будут разные. Данные могут оказаться на разных физических узлах. Это сильно усложняет и чтение, и транзакционность работы с таким клиентом.
format = {{'id', 'unsigned'},
{'email', 'string'}}
box.schema.create_space('customer', {format = format})
format = {{'id', 'unsigned'},
{'customer_id', 'unsigned'},
{'balance', 'number'}}
box.schema.create_space('account', {format = format})
В примере выше поля
id запросто могут не совпадать у счетов и клиентов. Связаны они через поле аккаунта customer_id и id клиента. Одинаковое поле id сломало бы уникальность первичного ключа аккаунтов. И по-другому Shard шардировать не умеет.Следующая проблема — медленный решардинг. Это классическая проблема всех шардов на хешах. Суть в том, что когда мы меняем состав кластера, у нас обычно меняется шард-функция, потому что она, как правило, зависит от количества узлов. И когда функция меняется, нужно проходить по всем записям кластера и пересчитывать шард-функцию заново. Возможно, перенести какие-то записи. И пока мы их переносим, мы не знаем, перенеслись ли уже данные, которые нужны очередному приходящему запросу, может быть, они сейчас в процессе переноса. Поэтому во время решардинга приходится на каждое чтение делать запрос по двум шард-функциям: старой и новой. Запросы становятся в два раза медленнее, и для нас это было неприемлемо.
Ещё одной особенностью Tarantool Shard было то, что при отказе некоторых узлов в replica set’ах он показывает плохую доступность на чтение.
Новое решение
Для решения трёх описанных проблем мы создали Tarantool VShard. Его ключевое отличие в том, что уровень хранения данных виртуализирован: появились виртуальные хранилища поверх физических, и по ним распределяются записи. Эти хранилища называются bucket’ами. Пользователю не нужно думать о том, что и на каком физическом узле лежит. Bucket — это атомарная неделимая единица данных, как в классическом шардинге один кортеж. VShard всегда хранит bucket’ы целиком на одном физическом узле и во время решардинга переносит все данные одного bucket’а атомарно. За счет этого обеспечивается локальность. Нам надо просто положить данные в один bucket, и мы можем всегда быть уверены, что эти данные будут вместе при любых изменениях кластера.

Каким образом можно положить данные в один bucket? В схеме, которую мы раньше ввели для клиента банка, добавим в таблицы по новому полю
bucket id. Если оно у связанных данных одинаковое, записи будут в одном bucket’е. Преимущество в том, что мы можем эти записи с одинаковым bucket id хранить в разных пространствах (space), и даже в разных движках. Локальность по bucket id обеспечивается вне зависимости от того, как эти записи хранятся.format = {{'id', 'unsigned'},
{'email', 'string'},
{'bucket_id', 'unsigned'}}
box.schema.create_space('customer', {format = format})
format = {{'id', 'unsigned'},
{'customer_id', 'unsigned'},
{'balance', 'number'},
{'bucket_id', 'unsigned'}}
box.schema.create_space('account', {format = format})
Почему мы так к этому стремимся? Если у нас классический шардинг, то данные могут расползтись по всем физическим хранилищам, какие у нас только есть. В примере с банком придется при запросе всех счетов какого-то клиента обратиться ко всем узлам. Получится сложность чтения O(N), где N — это количество физических хранилищ. Ужасно медленно.
Благодаря bucket’ам и локальности по
bucket id мы всегда можем прочитать данные с одного узла за один запрос, независимо от размера кластера.
Вычислять
bucket id и присваивать одинаковые значения нужно самостоятельно. Для кого-то это преимущество, для кого-то недостаток. Я считаю преимуществом, что вы можете сами выбирать функцию для вычисления bucket id.В чём ключевое отличие классического шардинга от виртуального с bucket’ами?
В первом случае, когда мы меняем состав кластера у нас появляется два состояния: текущее (старое) и новое, в которое надо перейти. В процессе перехода нужно не только перенести данные, но и пересчитать хеш-функции для всех записей. Это очень неудобно, потому что в любой момент времени мы не знаем, какие данные уже перенеслись, а какие нет. Кроме того, это не надежно и не атомарно, так как для атомарного переноса набора записей с одинаковым значением хеш-функции нужно персистентно хранить состояние переноса на случай необходимости восстановления. Возникают конфликты, ошибки, приходится многократно перезапускать процедуру.
Виртуальный шардинг гораздо проще. У нас нет двух выделенных состояний кластера, есть лишь состояние bucket’а. Кластер становится более маневренным, он постепенно переходит из одного состояния в другое. И состояний теперь больше двух. Благодаря плавному переходу можно на лету менять балансировку, удалять только что добавленные хранилища. То есть сильно повышается управляемость балансировки, она становится гранулярной.
Использование
Допустим, мы выбрали функцию для
bucket id и залили в кластер столько данных, что места перестало хватать. Теперь мы хотим добавить узлы, и чтобы данные на них сами переехали. В VShard это делается следующим образом. Сначала запускаем новые узлы и Tarantool-ы на них, а затем обновляем конфигурацию VShard. В ней описаны все участники кластера, все реплики, replica set’ы, мастеры, присвоенные URI и многое другое. Добавляем новые узлы в конфигурацию, и с помощью функции VShard.storage.cfg применяем её на всех узлах кластера.function create_user(email)
local customer_id = next_id()
local bucket_id = crc32(customer_id)
box.space.customer:insert(customer_id, email, bucket_id)
end
function add_account(customer_id)
local id = next_id()
local bucket_id = crc32(customer_id)
box.space.account:insert(id, customer_id, 0, bucket_id)
endКак вы помните, при классическом шардинге с изменением количества узлов меняется и шард-функция. В VShard этого не происходит, у нас фиксированное количество виртуальных хранилищ — bucket’ов. Это константа, которую вы выбираете при запуске кластера. Может показаться, что из-за этого масштабируемость ограничена, но на самом деле нет. Вы можете выбрать колоссальное количество bucket’ов, десятки и сотни тысяч. Главное, чтобы их было хотя на два порядка больше, чем максимальное количество replica set-ов, которое у вас когда-либо будет в кластере.
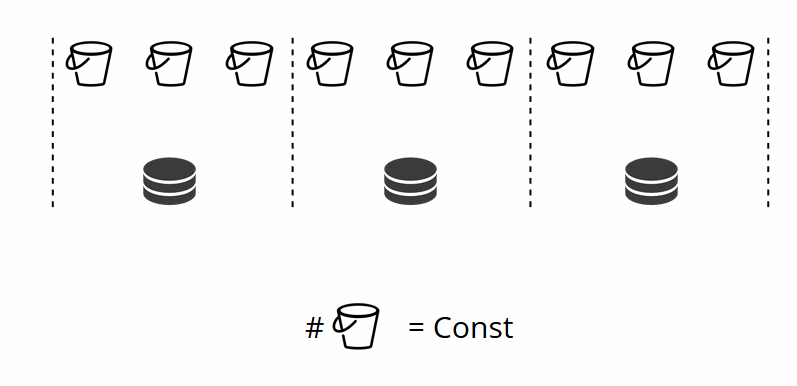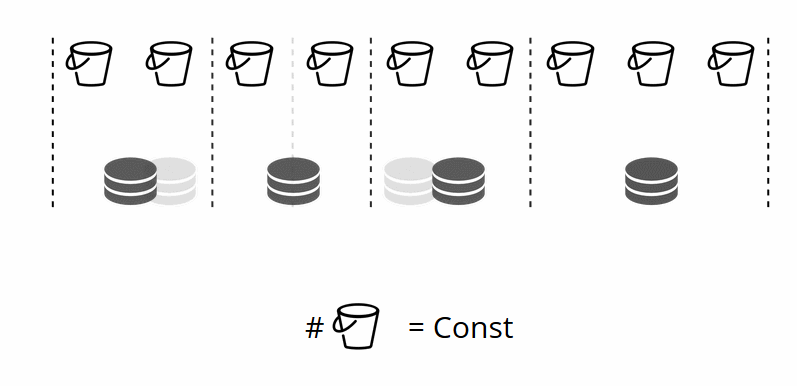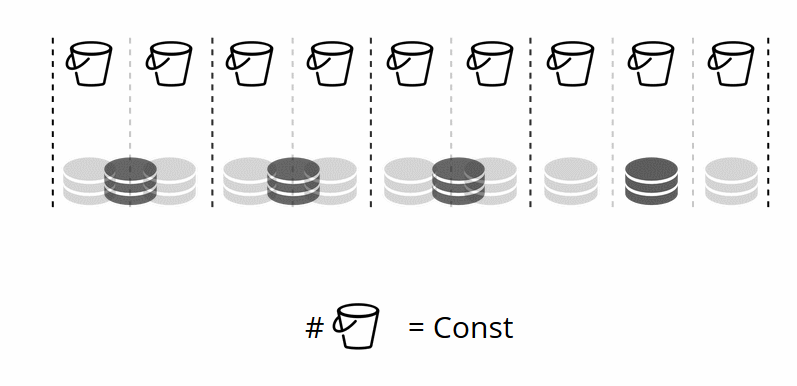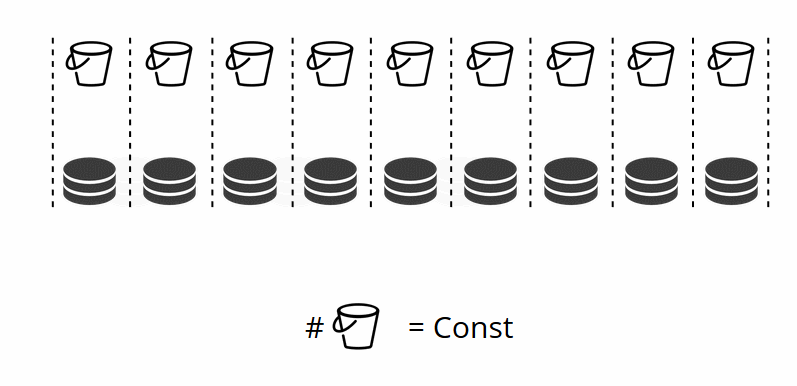
Поскольку количество виртуальных хранилищ не меняется, — а шард-функция зависит только от этого значения, — то физических хранилищ мы можем добавлять сколько угодно без пересчёта шард-функции.
Каким образом bucket’ы самостоятельно распределяются по физическим хранилищам? При вызове VShard.storage.cfg на одном из узлов просыпается процесс ребалансировщик. Это аналитический процесс, который вычисляет идеальный баланс в кластере. Он ходит на все физические узлы, спрашивает, у кого сколько bucket’ов, и строит маршруты их перемещения, чтобы усреднить распределение. Ребалансировщик отправляет маршруты переполненным хранилищам, и те начинают отправлять bucket’ы. Через какое-то время кластер становится сбалансирован.
Но в реальных проектах понятие идеального баланса может быть иным. К примеру, я хочу на одном replica set хранить меньше данных, чем на другом, потому что там меньше объём жёстких дисков. VShard думает, что всё хорошо сбалансировал, а у меня на самом деле хранилище вот-вот переполнится. Мы предусмотрели механизм корректировки правил балансировки с помощью весов. Каждому replica set и хранилищу можно задать вес. Когда балансировщик принимает решение о том, кому сколько bucket’ов отправить, он учитывает отношения всех пар весов.
К примеру, у одного хранилища вес 100, а у другого 200. Тогда первое будет хранить в два раза меньше bucket’ов, чем второе. Обратите внимание, что я говорю именно об отношении весов. Абсолютные значения не имеют никакого влияния. Вы можете выбрать веса исходя из 100 % распределения по кластеру: у одного хранилища 30 %, у другого 70 %. Можете взять за основу ёмкость хранилищ в гигабайтах, а можете измерять веса в количестве bucket’ов. Главное, соблюсти нужное вам отношение.
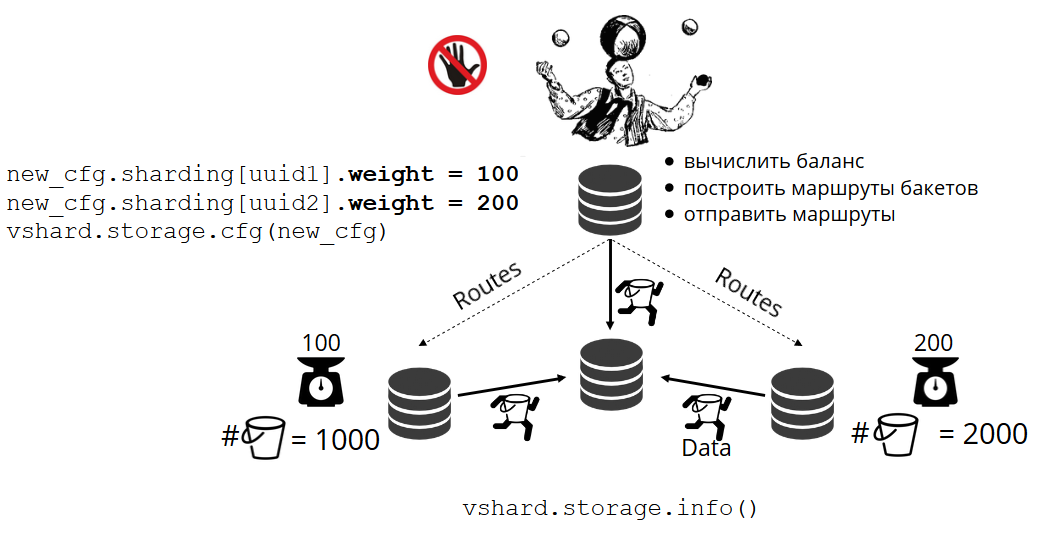
У такой системы есть интересный побочный эффект: если какому-нибудь хранилищу присвоить нулевой вес, то балансировщик прикажет хранилищу раздать все свои bucket’ы. После этого можно удалить из конфигурации весь replica set.
Атомарный перенос bucket’а
У нас есть bucket, он принимает какие-то запросы на чтение и запись, и тут балансировщик просит перенести его в другое хранилище. Bucket перестает принимать запросы на запись, иначе его успеют обновить в ходе переноса, потом успеют обновить переносимый апдейт, затем переносимый апдейт апдейта, и так до бесконечности. Поэтому запись блокируется, а читать из bucket’а еще можно. Начинается перенос чанков на новое место. После завершения переноса bucket снова начнет принимать запросы. На старом месте он тоже еще лежит, но уже помечен как мусорный и впоследствии сборщик мусора его удалит чанк за чанком.
С каждым bucket’ом ассоциированы метаданные, которые физически хранятся на диске. Все вышеописанные шаги сохраняются на диске, и что бы ни произошло с хранилищем, состояние bucket’а будет автоматически восстановлено.
У вас могли возникнуть вопросы:
- Что будет с теми запросами, которые работали с bucket’ом, когда его начали переносить?
В метаданных каждого bucket’а есть два типа ссылок: на чтение и на запись. Когда пользователь делает запрос к bucket’у, то указывает, как будет с ним работать, read only или read write. Для каждого запроса увеличивается соответствующий счетчик ссылок.
Для чего нужен счетчик ссылок на читающие запросы? Допустим, bucket спокойно переносится, и тут приходит сборщик мусора и хочет этот bucket удалить. Он видит, что счетчик ссылок больше нуля, поэтому удалять нельзя. А когда запросы будут обработаны, сборщик мусора сможет завершить свою работу.
Счетчик ссылок на пишущие запросы гарантирует, что bucket даже не начнет переноситься, пока с ним работает хотя бы один пишущий запрос. Но ведь пишущие запросы могут приходить постоянно, и тогда bucket не перенесется никогда. Дело в том, что если балансировщик изъявил желание перенести его, то новые запросы на запись начнут блокироваться, а завершения текущих система будет ожидать в течение какого-то таймаута. Если в отведённое время запросы не завершатся, система снова начнёт принимать новые запросы на запись, отложив перенос bucket’а на какое-то время. Таким образом балансировщик будет совершать попытки переноса, пока одна не увенчается успехом.
У VShard есть низкоуровневый API bucket_ref на тот случай, если вам мало возможностей высокоуровневого. Если очень хочется что-то сделать самостоятельно, достаточно обратиться к этому API из кода. - Можно ли совсем не блокировать записи?
Нельзя. Если bucket содержит критические данные, к которым нужен постоянный доступ на запись, то придётся вообще заблокировать его перенос. Для этого есть функцияbucket_pin, она жёстко прикрепляет bucket к текущему replica set’у, не допуская его переноса. При этом соседние bucket’ы смогут перемещаться без ограничений.

Есть средство ещё более сильное, чемbucket_pin— блокировка replica set’а. Она делается уже не в коде, а через конфигурацию. Блокировка запрещает перемещение любых bucket’ов из этого replica set’а и прием новых. Соответственно, все данные будут постоянно доступны для записи.

VShard.router
VShard состоит из двух подмодулей: VShard.storage и VShard.router. Их можно независимо создавать и масштабировать даже на одном инстансе. При обращении к кластеру мы не знаем, где какой bucket лежит, и за нас его по
bucket id будет искать VShard.router.Посмотрим на примере, как это выглядит. Возвращаемся к банковскому кластеру и клиентским счетам. Я хочу иметь возможность вытащить из кластера все счета конкретного клиента. Для этого пишу обычную функцию для локального поиска:
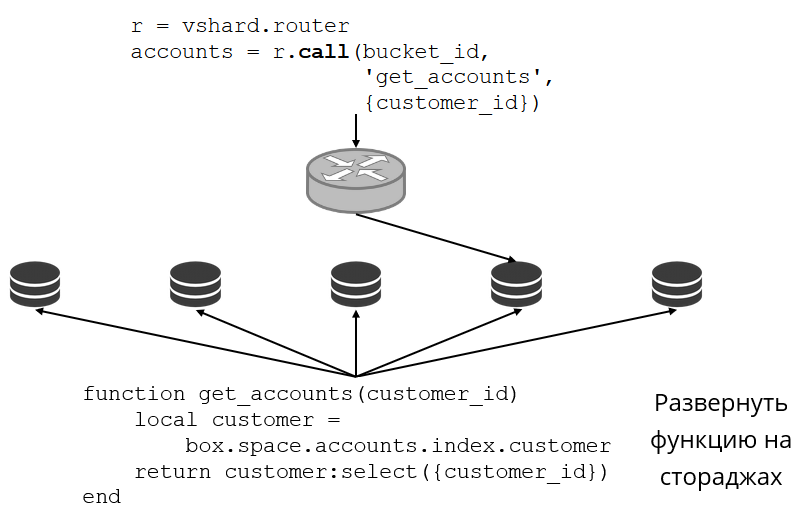
Она ищет все счета клиента по его id. Теперь мне нужно решить, на каком из хранилищ вызвать эту функцию. Для этого от идентификатора клиента в моем запросе вычисляю
bucket id и прошу VShard.router вызвать мне такую-то функцию в том хранилище, где живет bucket с получившимся bucket id. В подмодуле есть таблица маршрутизации, в которой прописано расположение bucket’ов в replica set’ах. И VShard.router проксирует мой запрос.Конечно, может случиться так, что в это время начался решардинг и bucket’ы стали переезжать. Роутер в фоновом режиме постепенно обновляет таблицу большими кусками: запрашивает у хранилищ их актуальные таблицы bucket’ов.
Может случиться даже так, что мы обращаемся к bucket’у, который только что переехал, и роутер еще не успел обновить свою таблицу маршрутизации. Тогда он обратится к старому хранилищу, а оно либо подскажет роутеру, где искать bucket, либо просто ответит, что нужных данных у него нет. Тогда роутер обойдет все хранилища в поиске нужного bucket’а. И всё это прозрачно для нас, мы даже не заметим промаха в таблице маршрутизации.
Нестабильность чтения
Вспомним, какие изначально у нас были проблемы:
- Не было локальности данных. Решили с помощью добавления bucket’ов.
- Решардинг всё замедлял и сам тормозил. Реализовали атомарный перенос данных bucket’ами, избавились от пересчитывания шард-функции.
- Нестабильное чтение.
Последняя проблема решается VShard.router’ом при помощи подсистемы автоматического read failover.
Роутер периодически пингует хранилища, указанные в конфигурации. И вот какое-то из них перестало пинговаться. У роутера есть горячее резервное подключение к каждой реплике, и если текущая перестала отвечать, он пойдет к другой. Запрос на чтение будет обработан штатно, потому что на репликах мы читать можем (но не писать). Можем задавать приоритет реплик, по которому роутер должен выбирать failover для чтений. Делаем мы это при помощи зонирования.
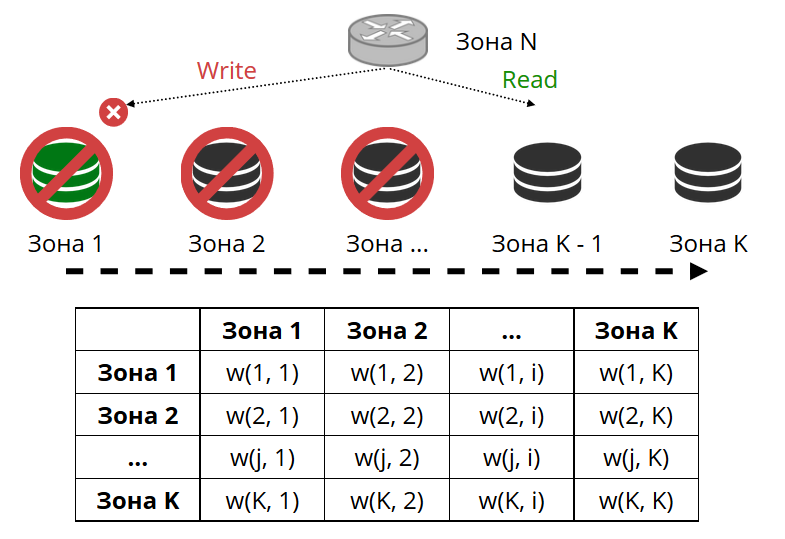
Каждой реплике и каждому роутеру присваиваем номер зоны и задаем таблицу, в которой указываем расстояние между каждой парой зон. Когда роутер принимает решение, куда отправить запрос на чтение, он выберет реплику в той зоне, которая ближе всего к его собственной.
Как это выглядит в конфигурации:
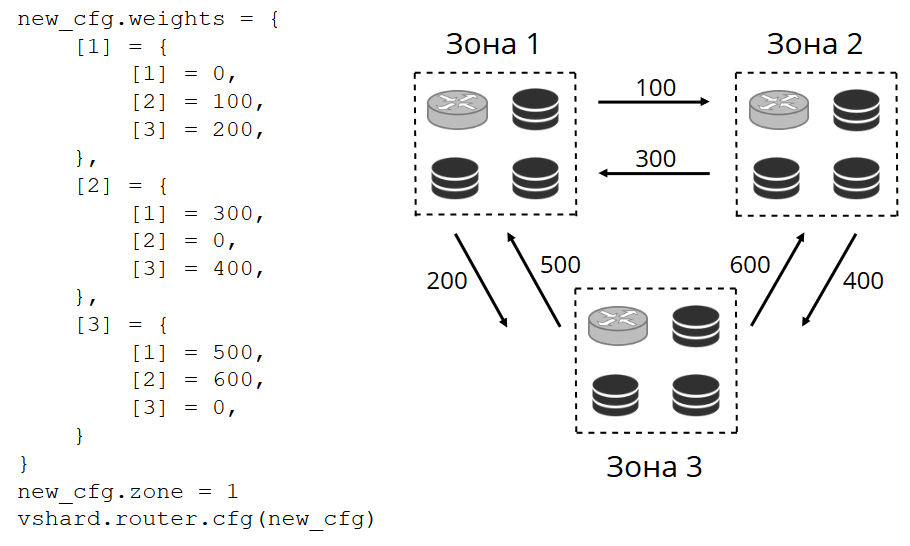
В общем случае можно обращаться и к произвольной реплике, но если кластер большой и сложный, очень сильно распределенный, тогда зонирование сильно пригодится. Зонами могут быть разные серверные стойки, чтобы не загружать сеть трафиком. Или это могут быть географически удаленные друг от друга точки.
Также зонирование помогает при разной производительности реплик. К примеру, у нас в каждом replica set’е есть одна бэкап-реплика, которая должна не принимать запросы, а только хранить копию данных. Тогда мы делаем её в зоне, которая будет очень далеко от всех роутеров в таблице, и они станут обращаться к ней в самом крайнем случае.
Нестабильность записи
Раз уж мы заговорили про read failover, то что насчёт write failover при смене мастера? Здесь у VShard не всё так радужно: выборы нового мастера в нём не реализованы, придется делать это самостоятельно. Когда мы его каким-то образом выбрали, нужно, чтобы этот инстанс теперь взял на себя полномочия мастера. Обновляем конфигурацию, указав для старого мастера
master = false, а для нового — master = true, применим через VShard.storage.cfg и раскатаем на хранилища. Дальше всё происходит автоматически. Старый мастер перестает принимать запросы на запись и начинает синхронизацию с новым, потому что могут быть данные, которые уже применились на старом мастере, а на новый ещё не доехали. После этого новый мастер вступает в роль и начинает принимать запросы, а старый мастер становится репликой. Так работает write failover в VShard.replicas = new_cfg.sharding[uud].replicas
replicas[old_master_uuid].master = false
replicas[new_master_uuid].master = true
vshard.storage.cfg(new_cfg)Как теперь следить за всем эти многообразием событий?
В общем случае хватит двух ручек —
VShard.storage.info и VShard.router.info.VShard.storage.info показывает информацию в нескольких секциях.
vshard.storage.info()
---
- replicasets:
<replicaset_2>:
uuid: <replicaset_2>
master:
uri: storage@127.0.0.1:3303
<replicaset_1>:
uuid: <replicaset_1>
master: missing
bucket:
receiving: 0
active: 0
total: 0
garbage: 0
pinned: 0
sending: 0
status: 2
replication:
status: slave
Alerts:
- ['MISSING_MASTER', 'Master is not configured for ''replicaset <replicaset_1>']Первая — это секция репликации. Здесь отображается состояние replica set’а, к которому вы применили эту функцию: какой у него репликационный лаг, с кем у него есть соединения и с кем нет, кто доступен и не доступен, на кого какой мастер сконфигурирован, и т.д.
В секции Bucket можно в реальном времени посмотреть, сколько bucket’ов сейчас перемещается на текущий replica set, сколько с него уезжает, сколько на нем сейчас работает в штатном режиме, сколько помечено как мусор, сколько прикреплено.
Секция Alert — это такая сборная солянка всех проблем, которые VShard смог самостоятельно определить: не сконфигурирован мастер, недостаточный уровень redundancy, мастер есть, а все реплики отказали, и т.д.
И последняя секция — это лампочка, которая загорается красным, когда всё становится очень плохо. Представляет собой число от нуля до трех, чем больше, тем хуже.
В VShard.router.info такие же секции, но означают они немного другое.
vshard.router.info()
---
- replicasets:
<replicaset_2>:
replica: &0
status: available
uri: storage@127.0.0.1:3303
uuid: 1e02ae8a-afc0-4e91-ba34-843a356b8ed7
bucket:
available_rw: 500
uuid: <replicaset_2>
master: *0
<replicaset_1>:
replica: &1
status: available
uri: storage@127.0.0.1:3301
uuid: 8a274925-a26d-47fc-9e1b-af88ce939412
bucket:
available_rw: 400
uuid: <replicaset_1>
master: *1
bucket:
unreachable: 0
available_ro: 800
unknown: 200
available_rw: 700
status: 1
alerts:
- ['UNKNOWN_BUCKETS', '200 buckets are not discovered']Первая секция — это репликация. Но только здесь не репликационные лаги, а информация о доступности: какие подключения у роутера, каким replica set’ом они держатся, какое подключение горячее и какое резервное на случай отказа мастера, кто выбран мастером, на каком replica set’е сколько bucket’ов доступно на чтение и запись, сколько доступно только на чтение.
В секции Bucket отображается общее количество bucket’ов, которые на этом роутере доступны сейчас на чтение и запись или только на чтение; про расположение скольких bucket’ов роутер не знает; или знает, но не имеет подключения к нужному replica set’у.
В секции Alert, в основном, рассказывается про подключения, про срабатывания failover, про неопознанные bucket’ы.
Наконец, здесь тоже есть простейший индикатор от нуля до трех.
Что нужно для использования VShard?
Первое — выбрать константное количество bucket’ов. Почему нельзя просто задать с помощью
int32_max? Потому что с каждым bucket’ом хранятся метаданные — по 30 байтов в хранилище и по 16 байтов на роутере. Чем больше у вас bucket’ов, тем больше места занимают метаданные. Но в то же время у вас будет меньше размер bucket’а, а значит выше гранулярность кластера и скорость переноса одного bucket’а. Так что придётся выбрать, что вам важнее и какой запас масштабируемости вы хотите заложить.Второе — нужно выбрать шард-функцию для вычисления
bucket id. Здесь правила такие же, как при выборе шард-функции для классических шардингов, потому что bucket — это как если бы мы в классическом шардинге фиксировали количество хранилищ. Функция должна равномерно распределять выходные значения, иначе размеры bucket’ов будут расти неравномерно, а VShard оперирует только количеством bucket’ов. И если вы не сбалансируете свою шард-функцию, то данные придётся перекладывать из bucket’а в bucket, менять шард-функцию. Поэтому выбирать надо аккуратно.Резюме
Vshard обеспечивает:
- локальность данных;
- атомарный решардинг;
- более высокую маневренность кластера;
- автоматический read failover;
- множество ручек управления bucket’ами.
VShard сейчас активно развивается. Реализация каких-то запланированных задач уже началась. Первое — это балансировка нагрузки на роутер. Бывают тяжёлые запросы на чтение, и грузить ими мастер не всегда целесообразно. Пусть бы роутер мог самостоятельно балансировать запросы на разные читающие реплики.
Второе — lock-free перенос bucket’ов. Уже реализован алгоритм, при помощи которого можно не блокировать bucket’ы на запись даже на время переноса. Это придется сделать только в конце, чтобы зафиксировать сам факт переноса.
Третье — атомарное применение конфигурации. Самостоятельно применять конфигурацию ко всем хранилищам неудобно и не атомарно: какое-то хранилище может быть недоступно, конфигурация не применилась, и что тогда делать? Поэтому мы работаем над механизмом автоматического распространения конфигурации.
Оригинал моего доклада