

DeepMind, дочерняя компания Alphabet, которая занимается исследованиями в области искусственного интеллекта, объявила о новой вехе в этом грандиозном квесте: впервые ИИ обыграл человека в стратегии Starcraft II. В декабре 2018 года свёрточная нейросеть под названием AlphaStar размазала профессиональных игроков TLO (Дарио Вюнш, Германия) и MaNa (Гжегож Коминц, Польша), одержав десять побед. Об этом событии компания объявила вчера в прямой трансляции на YouTube и Twitch.
В обоих случаях и люди, и программа играли за протоссов. Хотя TLO не специализируется на этой расе, но зато MaNa оказал серьёзное сопротивления, а потом даже выиграл одну игру.
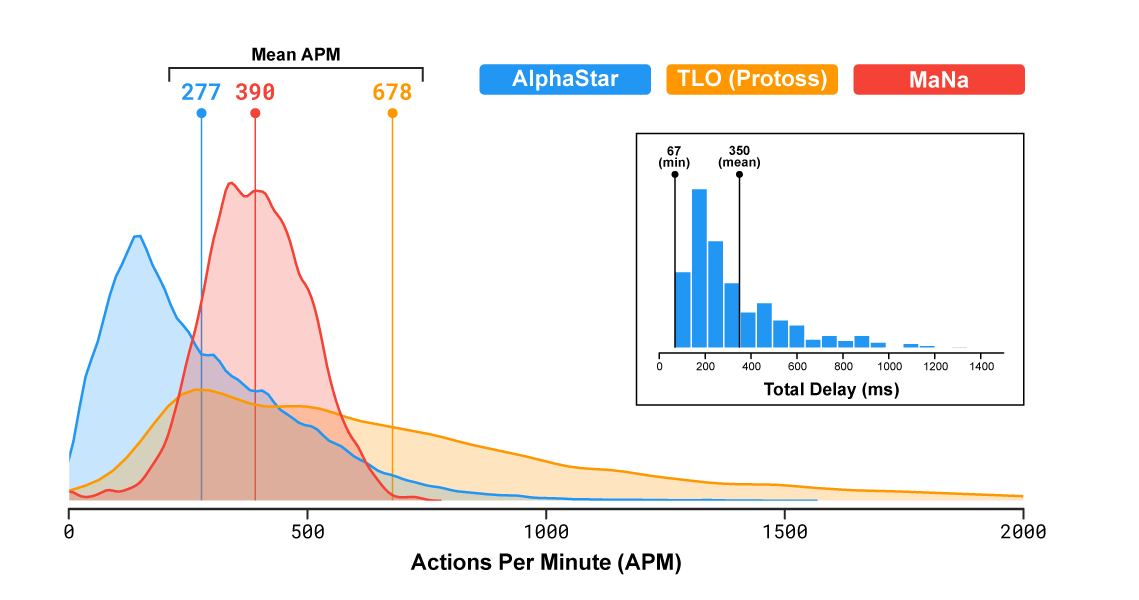
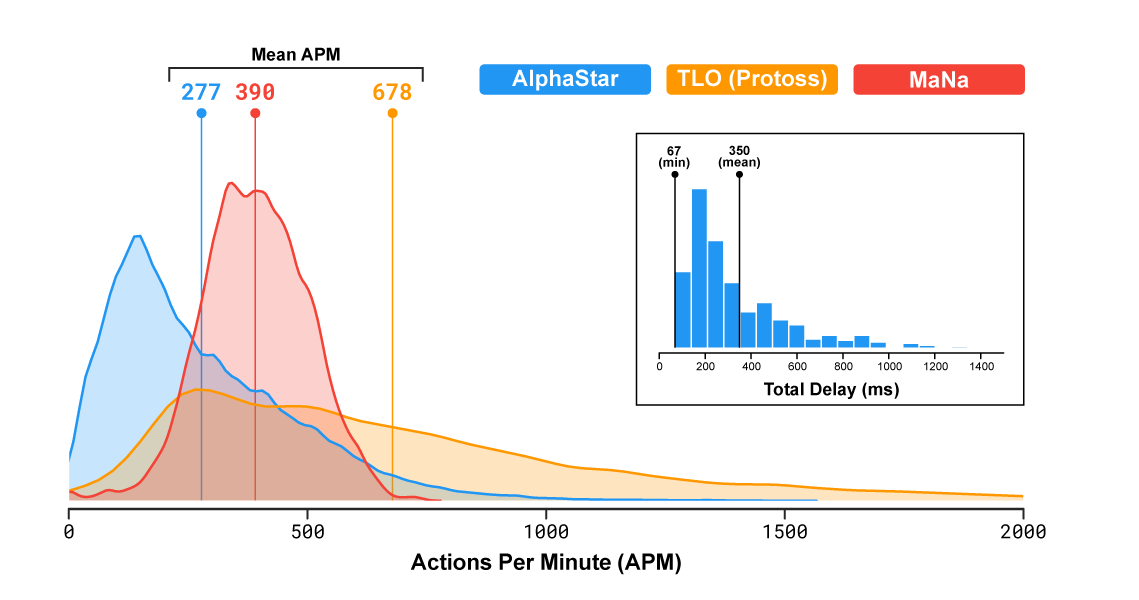
В популярной стратегии реального времени игроки представляют одну из трёх рас, которые конкурируют за ресурсы, строят структуры и сражаются на большой карте. Важно отметить, что скорость действия программы и её область видимости на поле боя были ограничены, чтобы AlphaStar не получила несправедливого преимущества над людьми (поправка: судя по всему, область видимости ограничили только в последнем матче). Собственно, по статистике программа даже совершала меньше действий в минуту, чем люди: в среднем 277 у AlphaStar, 390 у MaNa, 678 у TLO.
На видео показан вид игры с точки зрения агента ИИ во втором матче против MaNa. Вид со стороны человека тоже показан, но он был недоступен для программы.
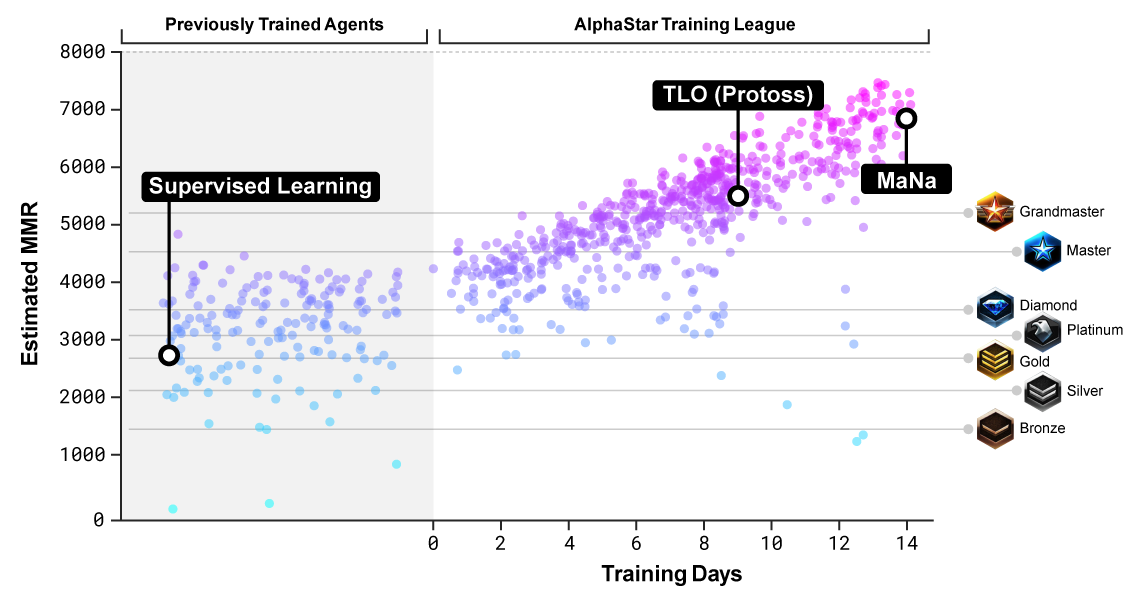
AlphaStar обучалась играть за протоссов в среде под названием AlphaStar League. Сначала нейросеть трое суток просматривала записи игр, затем играла сама с собой, используя технику, известную как обучение с подкреплением, оттачивая навыки.
В декабре сначала организовали игровую сессию против TLO, в которой было проверено пять разных версий AlphaStar. По этому поводу TLO пожаловался, что никак не мог приспособиться к игре противника. Программа выиграла со счётом 5?0.
После оптимизации настроек нейросети через неделю был организован матч против MaNa. Программа опять выиграла пять игр, но MaNa взял реванш в последней игре против самой новой версии алгоритма в прямом эфире, так что ему есть чем гордиться.
Оценка уровня противников, на которых обучалась нейросеть
Чтобы понять принципы стратегического планирования, AlphaStar должна была освоить особое мышление. Методы, разработанные для этой игры, потенциально могут оказаться полезными во многих практических ситуациях, когда требуется сложная стратегия: например, торговля или военное планирование.
Starcraft II — не только чрезвычайно сложная игра. Это также игра с неполной информацией, где игроки не всегда могут видеть действия своего противника. В ней также нет оптимальной стратегии. И требуется время, чтобы стали понятны результаты действий игрока: это тоже затрудняет обучение. Команда DeepMind использовала очень специализированную архитектуру нейронных сетей для решения этих проблем.
Ограниченность обучения на играх
DeepMind известна как разработчик программного обеспечения, которые обыграли лучших в мире профессионалов по го и шахматам. До этого компания разработала несколько алгоритмов, которые научились играть в простые игры Atari. Видеоигры — это отличный способ измерить прогресс в области искусственного интеллекта и сравнить компьютеры с людьми. Впрочем, это очень узкая область тестирования. Как и предыдущие программы, AlphaStar выполняет только одну задачу, хотя и невероятно хорошо.
Можно сказать, что слабый ИИ узкого назначения освоил навыки стратегического планирования и тактики боевых действий. Теоретически, эти навыки могут пригодиться в реальном мире. Но на практике это не обязательно так.
Некоторые эксперты считают, что подобные узкоспециализированные применения ИИ не имеют ничего общего с сильным ИИ: «Программы, которые научились мастерски играть в конкретную видеоигру или настольную игру на «сверхчеловеческом» уровне, полностью теряются при малейшем изменении условий (изменение фона на экране или изменение положения виртуальной «площадки» для отбивания «шарика»), — пишет профессор компьютерных наук в Портлендском государственном университете Мелани Митчелл в статье «Искусственный интеллект упёрся в барьер понимания». — Это лишь несколько примеров, демонстрирующих ненадёжность лучших программ ИИ, если ситуация немного отличаются от тех, на которых они обучались. Ошибки этих систем варьируются от смешных и безвредных до потенциально катастрофических».
Профессор считает, что гонка по коммерциализации ИИ оказала огромное давление на исследователей по созданию систем, которые работают «достаточно хорошо» в узких задачах. Но в конечном счёте развитие надёжного ИИ требует более глубокого изучения наших собственных способностей и нового понимания когнитивных механизмов, которые мы сами используем:
Наше собственное понимание ситуаций, с которыми мы сталкиваемся, основано на широких интуитивных «понятиях здравого смысла» о том, как работает мир, и о целях, мотивах и вероятном поведении других живых существ, особенно других людей. Кроме того, наше понимание мира опирается на наши основные способности обобщать то, что мы знаем, формировать абстрактные концепции и проводить аналогии — короче говоря, гибко адаптировать наши концепции к новым ситуациям. На протяжении десятилетий исследователи экспериментировали с обучением ИИ интуитивному здравому смыслу и устойчивым человеческим способностям к обобщению, но в этом очень трудном деле мало прогресса.
Нейросеть AlphaStar пока умеет играть только за протоссов. Разработчики заявили о планах обучить её в будущем играть и за другие расы.
Комментарии (123)

inferrna
26.01.2019 18:55Действительно, интересно, есть ли какой-то уровень абстракции, на котором нейросеть выделяет объекты из изображения? Или так и работает, как чёрный ящик — нарисуй юнитов иначе и обучай всё с 0 по-новому?

BingoBongo
26.01.2019 20:47Не думаю, что нейросеть работает с изображением, т.к. это тупая нудная задача, которая имеет практически тривиальное решение, но вносит дополнительную вероятность ошибки. Скорее всего сеть на вход получает координаты и данные юнитах и зданиях, которые не скрыты за туманом войны.

Slavik_Kenny
26.01.2019 18:57Важно отметить, что скорость действия программы и её область видимости на поле боя были ограничены, чтобы AlphaStar не получила несправедливого преимущества над людьми.
На другом ресурсе видел информацию о том, что хотя туман войны и был для ИИ, но по имеющемуся API программа получала информацию о видимых вражеских юнитах на всём видимом участке без необходимости двигать камеру. Когда эту возможность отключили человек выиграл. Но была оговорка что в таком режима ИИ учился играть намного меньше времени.Afterk
26.01.2019 19:26Только в последней игре (в которой выиграл MaNa), была имплементирована имитация камеры. Перед этим один агент ИИ (их выбрали 5ш, разных) выиграл за счёт лучшего микроменеджмента (то есть не обязательно «мозгом»). Пока потенциал текущей версии AlphaStar не раскрыт полностью, так как не особо тренировался с профессионалами (imho это не очень то и дошло до TLO и MaNa).
Slavik_Kenny
26.01.2019 18:58+3Нашел — nplus1.ru/news/2019/01/25/en-taro-alphago
Стоит отметить что все же небольшое преимущество у AlphaStar было — несмотря на то, что туман войны закрывал карту для нейросети так же, как и для человека, программа получала для обработки не частичное изображение известной области (условный экран), а видела сразу все, что позволяет увидеть игра. Благодаря этому нейросети не приходилось постоянно переключаться между разными зонами карты для контроля за происходящим. Когда же для еще одного демонстрационного матча с MaNa разработчики заставили AlphaStar играть с обычным ограничением масштаба видимой области, то нейросеть проиграла человеку. Правда, в DeepMind отмечают, что самостоятельно двигающая камеру версия программы обучалась в «лиге AlphaStar» всего семь дней.
shaukote
26.01.2019 19:20678 APM — это же ~11 кликов/нажатий в секунду. И это среднее значение.
Это определённо выходит за рамки моего понимания человеческих возможностей. о_оDracoL1ch
26.01.2019 19:35Хоткеи входят сюда же, и (вроде) приказ группе из 10 юнитов = 10 действий, поправьте если тут не прав. С хоткеями уже смотрится вполне реалистично, с групповыми приказами — более чем.

Virviil
25.01.2019 23:11+1Хоткей — да, групповой приказ — нет. Впрочем 678 — это реально занадто. Чемпионы играют 250-350, хотя смотря за какую рассу.

wataru
27.01.2019 01:22При этом большинство этих кликов — это бездумные клики в одно и то же место. Дай бог, десяток процентов осмысленных команд отдается. У бота же все его ~600 APM осмысленные.

Halt
26.01.2019 20:29Последний матч в трансляции показывали от лица игрока. В правом нижнем углу камера периодически показывает его руки. Ну и в ролике про TLO тоже было.
omikron24
26.01.2019 19:26Я хотя и не отношусь к свидетелям шапочки из фольги, но если предоставить такой системе достаточно масштабирования и данные в применимом формате — её можно будет применить в военных целях. Только управлять она будет реальными пехотинцами, танками, авианосцами и т.д. пусть даже как военный советник.
Slavik_Kenny
26.01.2019 19:29+2Вот только населения планеты не хватит чтоб обучить такую систему :)
Это просто к тому, что в играх нет и десятой доли всех возможных вариантов развития событий из реальной жизни (в том-же старкрафте нет дезертиров, морали, погоды и т.д.)
Или вон как на недавних учениях — столкнулись два корабля НАТО :)
Все учесть невозможно, так что только на реальной жизни и можно обучать систему для реальной жизни…omikron24
26.01.2019 19:36GO тоже считалась непостижимой для машин, ввиду количества комбинаций, буквально пару лет назад.
shaukote
26.01.2019 19:46+1Тут тонкость в том, что с го можно было виртуально прогонять бесчисленное количество партий, чтобы обучить нейронку всем возможным вариантам развития событий.
А вот с реальными боевыми конфликтами так не получится. :)omikron24
25.01.2019 23:30+2Ничто не мешает то же самое прогонять в симуляторе типа ARMA III, приближенному к реальности, запустить такой интеллект на сервера для игры с людьми и научить его воевать. В реальном конфликте число комбинаций хоть и будет астрономически велико, но будет конечным, интеллект на то и интеллект чтобы подстраиваться по мере изменения условий, используя не только накопленный опыт, но и например психологию людей, будь то шахматы или война в условиях городского боя. Все ии проигрывают поначалу, пока учатся, только со временем вырабатывают иммунитет к каждому приёму. Если военным такая идея понравится, они её шустро профинансируют, как было со многими технологиями до этого.
Slavik_Kenny
26.01.2019 19:48Ну количество комбинаций не то-же самое. Правила там четко формализуемы, а не так, что с какой-то вероятностью параметры юнитов могут измениться (и на сколько) из-за погоды. Хотя пусть система еще и обучается сразу в плане предсказания погоды, чтоб это учитывать :)
Чтоб система этому научилась надо все это заложить в «правила». Даже варианты того, что прапорщик разбавил топливо, солдаты напились, а генерал продал план наступления противнику. И разных сценариев (а тем-более их сочетаний) можно придумать столько, что невозмножно будет в обозримое время заложить все это в программу обучения.
Ну и количество вариантов срабатываний разных событий мне кажется легко переплючент количество вариантов в ГО :)

redpax
26.01.2019 12:46Дезертиры, мораль, погода, это всего лишь дополнительны параметры которые можно оцифровать и работать с ними как с вероятностями. Проблема только в обучении, в реальной жизни обучить сложновато, не хватит людей и русурсов, а вот создать симуляцию боевых действий пусть даже не со всеми возможными параметрами уже даст многократное преимущество перед противником.
Slavik_Kenny
26.01.2019 15:32+1пусть даже не со всеми возможными параметрами
И если при проверке в реальности возникнет такой неучтенный параметр, то все что планирует делать ИИ идет в топку, т.к. он просто не поймет что произошло.
И это если говорить про какие-то параметры, которые можно предположить, а вот как быть с управлением техникой? Мастерство экипажа в симуляциях одинаковое для всей однотипной техники, а в реале это очень сильно разнится, и один и тот-же самолет будет показывать разные результаты в зависимости от пилота — будем учитывать в симуляции каждого человека? Так у нас нет их параметров, есть только ТТХ техники…
Мне бы очень хотелось посмотреть на ИИ в настолках с кубиками (например тот-же Вархаммер). Вот где куча вариантов состава армии, и куча рандома в виде кубиков, и пусть попробует собрать армию против любого противника, да еще и научится играть не зная, как войска себя поведут, это только в старкрафте войска беспрекословно выполняют приказы и всегда попадают в цель.
Нет, научится не играть, а выигрывать.
Druu
27.01.2019 08:37+1Дезертиры, мораль, погода, это всего лишь дополнительны параметры которые можно оцифровать и работать с ними как с вероятностями.
Если вы это сделаете, то сможете легко выиграть любую войну и без ИИ.

dipsy
26.01.2019 19:46Только воевать в таком стиле сейчас не с кем. Могут покрасоваться, пригнать пару авианосцев, побомбить муджахидов на ослах. Могут точечными ракетными ударами уничтожать склады с оружием. Танки сейчас тоже скорее для красоты, уничтожаются на счет раз с ПТРК (ПЗРК для вертолетов) стоимостью на 3 порядка меньше чем тот танк.
ИИ может пригодиться в автономном вооружении, умных ракетах, дронах.
Pro-invader
26.01.2019 20:49Танки сейчас тоже скорее для красоты, уничтожаются на счет раз с ПТРК
А люди уничтожаются из автомата, сейчас тоже скорее для красоты, корабли уничтожаются торпедой, сейчас тоже скорее для красоты, самолеты уничтожаются ракетой…
Может не стоит так категорично утверждать?
VDG
26.01.2019 00:41+2Танки в городе продвигаются со скоростью 50м/час. Из любого угла им бок в упор прожигают. На ютубе есть реальные бои. Танки эффективны только для подавления на открытой местности издалека пехоты, вооружённой только калашами, аля ВОВ. В бою с современной регулярной армией без подавления вертолётов хоть всю колонну выжигай. Как говорится, «генералы готовятся к предыдущей войне».
mamont801
26.01.2019 11:35Ага. А генералы то не знают. VDG своими глазами на ютубе видел, что в город на танке нельзя.
В пехотинца тоже снайпер из любого угла. Это не говорит о том что пехоте в город нельзя. А танк — это лучшая броня из придуманной, да не идеальная, но ничего лучше нет. Плюс пушка на гусеницах. Может сложить целое здание. Естественно танк без пехоты не идёт. И пехоте без танка неуютно. И тыл должен быть прикрыт, а не на середину площади с разбегу. И все последние конфликты в Сирии и Донбассе только подтверждают необходимость танков в том числе в городских боях.VDG
27.01.2019 22:22Реальный бой. Пара десятков солдат пряталась за жопы пяти абрамсов, пока те два часа(!) долбили хибару в ста метрах, где прятались несколько «повстанцев» с ПТРК. Один абрамс имел дурость подползти на 40 метров и тут же получил в бочину из-за угла.
Ваши «все последние конфликты» — это не война, а локальные подавления бегающих с калашами. Будь это настоящий соперник, он за 100км мимоходом выпустил бы пару ракет, и сгорели бы все эти железные тушки. И не важно, прикрыт у них был «тыл» или нет. Вылезайте из WOT.
dipsy
27.01.2019 06:31Да, вы правы, сейчас нужны только ракеты по сути, и противоракеты как защита от них. Разбомбите ракетами мосты и электростанции
и склады амазони всё, противник не страшнее стайки обезьян в джунглях.
Танки, пехота и прочее, могут пригодиться в локальных конфликтах для подавления незаконных бандформирований. А исходно я полез в дискуссию о том, что ИИ якобы мог бы пригодиться для просчета какой-то тактики на поле боя, что неактуально уже лет как минимум 50.Silverado
27.01.2019 11:00Вы случайно Доктрину Дуэ. Только она того, не работает как-то. Единственный пример — Югославия, но там совсем уж неравные силы. Уже в Ираке через 4 года пришлось по старинке, пехотой и танками воевать.
dipsy
27.01.2019 11:03А давно это было, в Ираке? Дроны тогда были уже, через которые точно определяли где базы/склады боевиков, чтобы потом туда ракеточкой-другой жахнуть?
Silverado
27.01.2019 11:17Вовсю использовались еще с Югославии. Плюс спутниковая разведка. Разница с сегодняшними возможностями, конечно, есть, но не драматическая.
BingoBongo
26.01.2019 21:00Боевые действия — это не стратегия, где выделил юнитов мышкой и отправил в бой. Главные преимущества получаются путем разведки, шпионажа, двойного шпионажа, лжи, введения в заблуждение, неожиданных атак, переговоров, политики и т.д. Кучу проблем доставляют всякие бытовые проблемы вида как прокормить мобилизованную сотню тысяч человек или доставить боеприпасы. Если почитать искусство войны Сунь Цзы, то окажется, что уже как не одну тысячу лет победа в войнах закладывается задолго до начала боевых действий, лобовые столкновения — это уже завершающий этап. Провести начавшееся сражение — это тривиальная задача для которой ИИ не нужен.

r4nd0m
26.01.2019 12:20В Старкрафте в играх между людьми есть почти всё перечисленное. По-моему нет только двойного шпионажа, политики и логистики. Но зато есть многое, что недоступно в реальных боевых действиях, поэтому стратегии могут быть очень разнообразными.

voidptr0
26.01.2019 19:54Ну, я ждал, я смотрел. Но после того как первый раз раскатали TLO просто вчистую уже дальше смотреть не стал — все было понятно. У ИИ было ограничение в 180 АРМ, но оно реально успевало больше, чем TLO, хотя бы в анализе. Например, в то время как TLO кинулся в первые атаки в надежде на быструю победу, он упустил, как мне показалось, сбор ресурсов и построение новых юнитов, в то время как ИИ после контратаки просто заваливало его свежими юнитами до окончательной победы.
P.S. Я даже представить боюсь как оно будет играть за зергов.
striver
26.01.2019 19:57+1В другой теме писал, но оставлю и здесь. Неплохой комментарий каждого матча от
Алекса007voidptr0
26.01.2019 20:47Что и требовалось доказать, когда ИИ был поставлен в равные с человеком условия, он уже выглядел не так блистательно. Прямо говоря -«сдулся».
striver
26.01.2019 20:54+1Сдулся, потому что не тренировался в таких условиях. Для этого он поиграет еще недельку и будет на том же уровне, что и с картой.
voidptr0
26.01.2019 21:00Для этого он поиграет еще недельку и будет на том же уровне, что и с картой.
Дудки, он «сдулся» потому что заставили играть с ограниченным объемом информации. Т.е видит не всю карту, а как человек — кусочками.striver
26.01.2019 21:05Его проблема в том, что он Ф2-чил… войском водил хороводы. А мозгов не хватило построить Феникс. С учетом уровня игры, которого достиг ИИ за 2 неделю, думаю, что на тысячную игру он был «допер» как этому противостоять, возможно даже раньше. Но это не точно.

iDm1
26.01.2019 01:00Всю карту Alpha Star не видел ни в одной игре, его информация была так же ограничена «туманом войны», как и для человека. Суть тут в том, что во всех играх, кроме последней, Alpha Star не был ограничен своим экраном, а как бы выдел одновременно всю не скрытую «туманом войны» ему как игроку территорию.
BingoBongo
26.01.2019 21:09Опустили пользование камерой — это преимущество ни о чем. Давайте теперь отменим превосходство над человеком шахматных ИИ потому что они не могут перемещать фигуры на настоящей деревянной доске.

nidalee
26.01.2019 12:32Во многих стратегиях (если не во всех) изменение предела максимальной «высоты» камеры является читерством.
GiperBober
26.01.2019 21:38Сам факт того, что ИИ УЖЕ СЕЙЧАС приходится «ставить в равные с человеком условия» намекает на превосходство ИИ. Рост быстродействия машин будет только расти, как и рост сложности алгоритмов ИИ.
С другой стороны, если уж была бы задача «поставить ИИ в равные условия с человеком», то надо было создавать аппаратную человекоподобную платформу, а не эмулировать ограничения. Т.е. играть должен был человекоподобный робот (причём без подключения к сети), таращащийся в монитор и тыкающий механическими пальцами в клавиатуру и мышь. Вот если бы такая связка обыграла бы профессиональных игроков, то это бы реально пугало…voidptr0
26.01.2019 21:50Весь вопрос в микроменеджменте": Сдвинуть юнит на 2 пикселя", «огонь», «через 212 мс на 4 пикселя назад»таймаут 0,5". Вы точно так представляете себе битву с ИИ? Даю прекурсор — Вы никогда его не победите в микроменеджменте, вы чисто человечески не сможете — анализ всей карты всегда превалирует над анализом областей.
michael_vostrikov
27.01.2019 08:40У калькулятора тоже превосходство в вычислениях, это ничего не означает.
pavel_smolnikov
25.01.2019 22:31+2Сделал полный перевод их официальной статьи:
habr.com/ru/post/437486
NeoPhix
26.01.2019 00:11Пока ИИ не выиграет какой-нибудь даже простенький турнир в интернете — это все ни более, чем хайп. Сама новость полна абсурда:
Заголовок: «ИИ обыграл профессионалов в SC2 10-0!»
Где-то далеко внизу: «ИИ играл за одну расу, один матчап, на одной карте, с полным контролем всей карты, не закрытой туманом войны, по одной игре с разными агентами (т.е. без возможности людей адаптироваться)».
Не многовато ли ограничений? Пока звучит как: «ИИ смог обыграть человека в шахматы! Правда, человек играл без ферзя, слонов, коня и ладьи. А еще ему нельзя было ходить на клетки по е6, е2 и б4 и можно есть фигуры соперника только первыми тремя пешками».
Я даже не удивлюсь, если матчи были подтасованными и сыгранными по сценарию. TLO вообще детские ошибки допускал с варпом сталкеров на поле боя.
Не хочется умалять заслуги разработчиков, которые сделали то, чего раньше не делал никто, но стоит объективно оценивать результат. Правда на такую объективность денег не выделят :(aftertherainbow
26.01.2019 00:37Вы видимо не в курсе что такое про сцена СтарКрафта. Нет игроков которые на профессиональном уровне могут одинаково сильно играть всеми расами, даже человек выбирает какую-то одну. Так что мачап против Маны вполе себе может сойти за финал какого-нибудь чемпионата между двумя протосами которые прошли через сетку.
А про невозможность людей адаптироваться это просто смешно. Мана входит в 10ку лучших игроков-протосов планеты, поверьте, на своё обучение он потратил гораздо больше времени чем этот ИИ. И на таком уровне просто не сущестует понятия «адаптироваться». Те игроки к которым можно адаптироваться ничего не достигают.
Но смысл же не в этом. Я удивляюсь комментаторам которые пытаются доказать, что ИИ в чём-то вёл себя «нечестно». Да ребят, ему не нужно нажимать на клавиши, смиритесь. Чтобы соответствовать вашим представлениям о «честности» я так понимаю дип майнд должны посторить андроида да?
Вы можете сравнить с предыдущими достижениями в этой области habr.com/ru/post/370431 вот статья например и осознать что это просто невероятный скачок вперёд.
alex_blank
26.01.2019 04:20Вот что сам MaNa пишет на реддите, когда его спросили, чем бот был лучше/хуже человека:
I would say that clearly the best aspect of its game is the unit control. In all of the games when we had a similar unit count, AlphaStar came victorious. The worst aspect from the few games that we were able to play was its stubbornness to tech up. It was so convinced to win with basic units that it barely made anything else and eventually in the exhibition match that did not work out. There weren’t many crucial decision making moments so I would say its mechanics were the reason for victory.
То есть, бот тупо рашил базовыми юнитами не особо заботясь о стратегии, и это работало. В этом нет никакой особой интеллектуальности, тупо победа за счет лучшей механики микроконтроля.
Это как называть бота в Counter-Strike прорывом в ИИ и скачком вперёд, потому что он хедшоты делает со 100% точностью. "The goal is to create artificial intelligence, not artificial aiming"
redpax
26.01.2019 12:58+1Есть лишь один вопрос. Почему до вчерашеного дня никому и никогда не удавалось создать бота для Старкрафт который бы победил человека даже имея неорганиченыц АПМ и скрипты для микроконтроля?
alex_blank
26.01.2019 20:08Потому что со всем остальным (кроме бешеного APM) у тех ботов было совсем плохо, они были слишком «запрограммированные» и негибкие, что позволяло легко найти брешь в их алгоритме и нагнуть их.
Но при наличии минимального интеллекта у игрока (что DeepMind вполне себе демонстрирует), сверхчеловеческое микро уже не «контрится» — тонкий игровой баланс Старкрафта на такое просто не рассчитан.
aftertherainbow
26.01.2019 14:36+2Вы же понимаете что никто специально не задавался целью обыграть про игрока в старкрафт/шахматы/го — просто сложность задач с каждым разом становится всё выше. Я ещё раз говорю вам, суть не в этом. Сравнивается не человек/ии, а предыдущие достижения ИИ с текущими. Человек однозначно проиграет в этой борьбе, тут даже никаких вопросов нет. Люди долго не признавали поражение в шахматах, но в конце концов смирились.
Это как в средневековье пригнать трактор и говорить, что нечестно на нём побеждать на рыцарском турнире, вы же в него соляру заливаете, а не овёс. Но трактор-то не для турниров, на тракторе поле можно вспахать, ребят.Slavik_Kenny
26.01.2019 15:35+1Человек однозначно проиграет в этой борьбе, тут даже никаких вопросов нет.
В доте все еще не проиграл :)
И есть еще один немаловажный момент — изменения правил у игр. Баланс часто меняют, патчи выходят регулярно, и человек к ним подстраивается намного быстрее, а ИИ придется тренировать по-новой в некоторых случаях.
NeoPhix
26.01.2019 11:01Я понимаю это, но это же ведь скорее подтверждает откровенную фейковость заголовка «ИИ победил про в SC2» и подтверждает мои слова про то, что игра была с ограничениями для людей/форой для бота.
По поводу честности: к таким заявлениям приводят желтые заголовки. Никто не спорит, что это очередной огромный прорыв в области обучения ИНС человеческим играм. Претензия именно к прямому обману обывателя, который, не разбираясь в деталях, будет думать, что «скоро будем жить в постапокалипсисе из терминатора».
P.S. По поводу времени на обучение: а давайте посмотрим не по критерию «время на обучение», а по критерию «количество игр, на которых был обучен ИИ». Все зависит метрики, по которой сравнивать.
Druu
27.01.2019 08:44+1Я удивляюсь комментаторам которые пытаются доказать, что ИИ в чём-то вёл себя «нечестно». Да ребят, ему не нужно нажимать на клавиши, смиритесь.
Смотрите. Если вы на бнете будете микрить сталкерами как АльфаСтар, то вас забанят ;)
michael_vostrikov
27.01.2019 08:44+1Мана входит в 10ку лучших игроков-протосов планеты, поверьте, на своё обучение он потратил гораздо больше времени чем этот ИИ.
А если в количестве игр посчитать?
Abiron
26.01.2019 04:39Уточнение: ИИ не видел скрытые туманом войны области. Он просто видел карту разом. Как играть на растянутой миникарте.
EviGL
26.01.2019 16:15Во многом согласен, но разные агенты это, объективно, плюс в копилку AlphaStar.
Пока мир не может сделать одного бота чтобы побороть прогеймеров, ребята одновременно сделали 5 разных, со стабильно хорошими результатами.
Адаптироваться на лету к разным противникам это как люди выигрывают на ладдере, турнирах и становятся прогеймерами.
alex_blank
26.01.2019 00:34bigfatbrowncat
26.01.2019 18:00+1Самое забавное, что эти трюки можно использовать в качестве датасета для изначального обучения сети. И она попытается их повторить. Возможно, успешно.
А вообще, если Близы не профукают такую возможность, они смогут доточить баланс до идеального. Например, добавят маленький откат навыку «сесть в бункер». Сделают блинк не мгновенным, а занимающим, скажем, 10 миллисекунд (чтобы снаряд успел попасть). И т. п…
На даннвй момент игра сбалансирована только на уровне человеческой реакции. Но никто не мешает сделать ее такой, чтобы уравнять шансы как для людей, так и для «сверхлюдей».
andreyverbin
26.01.2019 01:53+1Почему никто не отмечает важные отличия игры AlphaStar от игры человека?
— Он лучше строит, почти всегда у AlphaStar больше ресурсов и юнитов.
— Он лучше микрит, stalker с blink у ИИ практически бессмертный. Такая эффективность управления недоступна человеку и ломает баланс. Immortal должен побеждать stalker, но нет, под управлением ИИ stalker побеждает.
— Он может разбивать армию на много кусочков, окружать и «дергать» армию противника со всех сторон. Человек такого не может, просто не внимания.
— Он не учится в процессе игры, прилетел дроп, и AI продолжал гоняться за ним пока не проиграл.
AlphaStar в основном побеждал за счет нечеловечески точного и быстрого управления юнитами. Он не показывал чудеса стратегии или какие-то крутые игровые идеи. Просто он умеет быстро елозить мышкой и делает это в 1000 раз быстрее и точнее человека. Надежда людей в этом противостоянии только на то, что всю дурь из AlphaStar не получится выбить и всегда будут новые стратегии, к которым он не готов, как тот дроп из 2х immortal.
И надо быть справедливым к людям, если бы они играли с AlphaStar несколько дней подряд, то счет был бы 0-10 в пользу людей. Уже в 6 игре Mana нашел фатальный недостаток у ИИ.alex_blank
26.01.2019 02:18+2Просто если бы они выставили адекватное ограничение APM (думаю они пытались), то игроки-люди разделали бы бота под орех, и никакой красивой презентации для инвесторов не вышло бы. А у них дедлайны, надо что-то показать.
Вот тут AMA на reddit с разработчиками, и там выясняется что лимитер APM был настроен так, что даже (теоретически) допускались кратковременные burst'ы под 2500 APM (на практике мы видели 1500 в боях), что конечно полный бред, ни один человек никогда так не сможет кликать — чисто физически эффективный APM не может быть выше 200-300, все что выше это бессмысленные «раскликивания», возможно даже с помощью макросов клавиатурных. Причем бот кликает с суперточностью, ему не надо рамкой выделять юнитов и елозить курсором, он может суперточно выбрать любой набор юнитов в любых местах карты одновременно — ему даже и камерой не нужно было елозить, он играл с «зумхаком» все игры кроме последней (где он позорно слился). Это профанация полная, рассчитанная то чтобы впечатлить и убедить тех, кто в SC никогда не играл. Манипулирование числами и статистикой (это я про их «средний APM даже ниже чем у игроков-людей» и красивые графики распределений, где сравниваются яблоки и апельсины).
Barry_Y
26.01.2019 09:50Ну я бы не был так категоричен. Вы конечно правы что у ИИ преимущества в виде точности и более высокого АПМа. Но:
Если верить этому графику, то средний АПМ был выше не у ИИ, а у MaNa (390 vs 277), при этом максимальный — у TLO (2000 vs 1600).
Конечно надо учитывать что у TLO такой высокий апм из-за хоткеев (багнутая фича — частое использование хоткеев сильно завышает АПМ). И конечно у ИИ нет спама, в отличие от людей. Поэтому возможно в 2-3 раза выше эффективный апм, но не на порядки же.
«Зумхак» тоже преимущество, но бот по-прежнему оперирует неполной информацией (ту же информацию имеет любой про-игрок который смотрит на миникарту — тот же Серрал потому и выигрывает всегда; у него отличный map presence, вне зависимости от того где его камера в какой-либо момент).
Ну и 200-300 эффективный АПМ физически всё же возможен, если использовать множество способностей, хоткеев (уместных) и быстро-часто направлять юнитов по какой-нибудь оптимальной кривой.
В конце концов печатать-то люди вполне успешно умеют с эффективной средней скоростью в 700-1400 букв минуту (не все, конечно, но всё же — достаточно взглянуть на klavogonki.ru).
А так — я, как мл-тосс, впечатлён. Убрать все преимущества и подучить нейросеть играть «с камерой» — и всё равно будет игрок уровня грандмастера. Да даже сейчас думаю он как минимум любого мастера обыграет в большинстве случаев, даже если сильнее АПМ поуменьшат и «с камерой».
А самое главное — со стороны не то чтобы легко отличить, компьютер или человек играет.Randl
26.01.2019 13:12У ИИ есть спам
alex_blank
27.01.2019 06:36Только в тех ситуациях, когда APM больше «не на что» было потратить эффективно, т.е. не в моментах интенсивных стычек. Этому AI научился у людей, так как первую версию обучали на реплеях, перед тем как она начала играть сама с собой. Но поскольку это не влияло на винрейт, ИИ «не смог забыть» эту привычку. А вот в критические моменты он тратил свой APM очень эффективно, так как это влияло на винрейт при обучении.
alex_blank
27.01.2019 05:27Этот график — профанация и притягивание за уши… Какой нафиг APM в 2000 у человека, и какая разница какой APM «средний» если важно то, какой он пиковый в критические моменты игры, и какой процент полезных действий в этом APM, ведь большая часть человеческого APM это спам-клики и перемещение камеры, при том что боту же даже камеру перемещать не надо было.
Вот очень хороший пост в /r/MachineLearning где все четко расставляют по полочкам:
> Поэтому возможно в 2-3 раза выше эффективный апм,
Но в Старкрафте это гигантское преимущество и полностью меняет игру, при в 2-3 раза большем APM чем у топовых прогеймеров, оптимальным стилем игры становится массить блинк сталкеров и давить ими c трех сторон одновременно. В Старкрафте в балансе многое рассчитано на то, что идеальный контроль у человека невозможен, и баланс старкрафта во многом про искусство эффективного менеджмента ограниченного количества действий в секунду. Если его не ограничивать, то игра просто теряет смысл.

Alexey_mosc
26.01.2019 09:22"Он не учится в процессе игры, прилетел дроп, и AI продолжал гоняться за ним пока не проиграл."
Чисто технически это можно сделать, нет проблем. Проблема в необходимости огромного количества материала для обучения.

jaguard
26.01.2019 20:09+2Не обязательно, что это можно сделать в принципе. То есть, конкретно этой нейросети «бесконечным» обучением залепить все «дырки» в ИИ при решении такой сложной задачи, как игра в Старкрафт. Как никогда сверточные НС не смогут 100% определять что изображено на картинке (просто потому, что сопоставляют картинку обобщенному образу из обучения, а не анализируют что именно изображено — а значит кот, который вклеен внутри собаки, которая замаскирована под слона гарантированно взорвет «ИИ» «мозг»), так и человек, получив свободный доступ к такому ИИ, довольно быстро найдет способ ему противостоять — как «атака пикселем» в случае картинок. Именно на макроуровне — определенным видом билдордера или раша.
Но надо отдать «Дипмайнду» должное, в плане «микро» он весьма неплох.
А вообще, если устраивать соревнование «человек против машины», мне кажется, человеку тоже надо выдать пачку костылей, для компенсации. Самым простым будет уменьшение скорости до Normal, чтобы примерно сравнять возможности по микро-контролю.
Старкрафт-2 все-таки не только и не столько стратегия, сколько соревнование «кликеров», он нарочно неудобный для определенных вещей. Хотя и гораздо более простой нежели первая часть серии, где нужно было совсем всё-всё делать руками — например, вейпоинты на минералы не работали, у выделенных «магических» юнитов не работали способности, если к выделению примешивались юниты другого типа, а сами способности «кастовались» у всей группы на одну и ту же точку. Наверное, у «alphaGo» в этом случае было бы еще больше преимуществ.
Oliksolik
26.01.2019 08:31После просмотра последней карты возник вопрос, если ему не ограничили поле видимости он бы так же отбивался от дропа?
В целом мне не понравилось, они просто вывели идеальные билды и тайминги и тупо перемасили и переконролили человека.
Я бы лучше посмотрел против кингкобры, который я думаю его бы в легкую зафатонил.
И ещё, нужно было дать время подготовиться игрокам, если б они нашли слабые стороны значит это херовый ИИ, если б ИИ в процессе адаптировался значит хороший.bigfatbrowncat
26.01.2019 15:57Как забавно читать, когда обычный человек, начинает критиковать игру уровня профессионалов. Всегда слышится «а мой брат бы твоего легко победил — он у меня сильный, дом поднимет одной левой!»
Я думаю, что пока оно училось играть на уровне алмазной лиги, оно весьма успешно научилось отбиваться от фотонок. И не только.
На последнем матче была выпущена явно сырая, недоученная сетка. Он не отбился не из-за ограниченного поля видимости, а из-за того, что он не научился в новой механике правильно ориентироваться. Возможно, надо было доработать топологию. Ошибка со сталкерами, пытавшимися достать дроп с берега — вообще похожа на программерский баг. Хотя, я деталей не знаю — утверждать наверняка не могу.

shasoft
26.01.2019 16:55по статистике программа даже совершала меньше действий в минуту, чем люди: в среднем 277 у AlphaStar, 390 у MaNa, 678 у TLO.
Компьютер может с первого раза ткнуть в нужный пиксель и послать войска куда нужно даже с учетом скорости противника. А человеку придется корректировать свои войска.bigfatbrowncat
26.01.2019 17:52Истину глаголите.
Вот только нюанс: для того, чтобы отдать приказ боевой единице не чаще, скажем, чем раз в секунду, надо на эту секунду вперед прогнозировать. Именно способностью к долгосрочным прогнозам на основе неточных данных до сего момента человек обыгрывал ботов. И именно по причине куцей способности к предсказанию, бот вынужден «перекликивать» человека в разы, чтобы играть на том же уровне. Он тупо меняет мнение с частотой 100 герц.
А бот, основанный на нейросетях, «мыслит» так же, как и мы с вами. Он оценивает свои шансы, прогнозирует и отдает приказы на несколько секунд вперед. Именно поэтому у него, как у человека, APM так сильно плавает, в зависимости от того, насколько «горяча» ситуация. И, да, он не промахивается по юнитам и не делает лишние тычки. Но, полагаю, прогеймеры тоже промахиваются довольно редко, а «тычками» только руки прогревают. Так что оценка APM довольно объективна.

paradd
26.01.2019 20:09Более показательно было бы выступление бота в пошаговой стратегии с неполной информацией а-ля герои 3, цивилизация. В старике микроконтроль многое решает. Можно не быть супермозгом, но тупо перекликать.
And_Ray
26.01.2019 20:53Коллеги, можете пояснить, по каким критериям считался проигрыш? Игрок пишет GG хотя вроде и база цела и добыча не остановлена и остатки армии пристутсвуют? (Я играл в TA, механика старкрафта мне не очень очевидна)
striver
26.01.2019 20:58Ну, это очень субъективно. Игрок принимает решение сам, что на каком-то этапе его дальнейшее сопротивление в любом случае станет поражением.
wmgeek
26.01.2019 21:49-1Интересно, насколько далеко уйдут подобные алгоритмы где-нибудь на валютной бирже?
rPman
26.01.2019 23:34Биржи — это саморегуляция, при этом держится все на утверждении — одни обогащаются за счет других. Т.е. главное, каждому новому трейдеру приходится сражаться против всей совокупной силы и разума тех кто уже имеет там опыт.
Лет десять назад нейронные сети уже давали профит, трейдерские форумы об этом говорили…
p.s. на истории не научиться как следует, учиться надо на реальных действиях ибо каждое действие меняет реакцию рынка, но для нейронных сетей нужны данные и желательно значительно больше чем кажется необходимо. Конкретно этот обсуждаемый ИИ использует следующий подход — играть сам с собой, т.е. чтобы создать торговый алгоритм, ему необходимо создать эмитатор рынка, который ведет себя похожим образом… это конечно решит задачу получения дохода но выглядит слишком избыточной по сложности, что то мне кажется эта задача пока не по зубам.
{kind=link}
bigfatbrowncat
Интересно, когда же, наконец, разработчики игр возьмут на вооружение разработки в области Deep Learning для создания «человечных» NPC и интересных диалогов… Это будет новая эра в игростроении.
А пока хоть бы Близы добавили нормальный ИИ в игру. Так ведь не станут — это ж снизит посещаемость Battle.Net…
rPman
Если вы думаете что целью у этих ИИ будет сделать игру интереснее, то скорее всего ошибаетесь. Главной целью, которую поставят ИИ будет — нужно больше золота. И вместо интересной игры геймерам будут давить на центры удовольствия и теребить животные инстинкты.
Т.е. идеальной игрой, которую сделает ИИ, станет этакий экран с абстрактной анимационной картинкой, гипнотизирующей человека и заставляющего его вываливать все деньги из своих карманов.
MaxxONE
Хех, вот вы поболтаете с НПЦ, а ваша беседа уйдет корпорации. Это же бесценные данные, особенно в совокупности по многим людям.
bigfatbrowncat
Уже давно всё, что вы обсуждаете с вашими друзьями и родственниками в соцсетях, уходит корпорациям. И?
Мирового коллапса это пока не вызвало.
Мне кажется, утечка информации в играх — последнее, чего следует опасаться в связи с развитием искусственного интеллекта.
MaxxONE
А я не о коллапсе. Я о деньгах.
HaJIuBauKa
Позвольте уточнить. Как я понимаю, Макс имеет в виду обучение алгоритма поведения НПС на основе переданных данных от всех игроков в диалогах. Это обратная связь очень интересна, но пока довольно непредсказуема и сложна.
bigfatbrowncat
Возможно. Я, лично, вообще не думаю об ММО. Я их не люблю :) Предпочитаю сингл плеер. Поэтому и не сообразил сразу.
MaxxONE
Нет, я представлял себе что-то вроде данных об интересах пользователей. На основе которых можно, скажем, таргетировать рекламу, прогнозировать спрос и т.п.
Персональный шпион-НПЦ в любимой игре, которому ты наивно доверишь свои самые интимные секреты — вот о чем я подумал. Сейчас такое возможно лишь на самом примитивном уровне, а с ИИ-НПЦ можно попытаться вытянуть из юзера нужную информацию путем индивидуального подхода.
Oplkill
Есть такой фанфик по этой теме, когда создали ИИ который полностью управлял онлайн игрой(весь контент ИИ генерировал сам), но что-то пошло не так…
P.S. не стоит смущаться, что фанфик по mlp сообществу, на конкретно понях там не зацикливаются, вся тема про ИИ
Blaine_Mono
Это смотря с какой точки зрения посмотреть. С некоторых все наоборот пошло очень даже так.
Max_JK
Прочитал на одном дыхании, хоть я и не являюсь фанатом пони, отличный рассказ.
Zet_Roy
А вот это суровая правда, сейчас ИИ используется для того что бы получше впаривать людям не нужное им говно вместо того что бы кинуть все силы на разработку против серьезных болезней.
striver
BigFlask
esc
Ненужное говно ИИ сейчас не особо умеет впаривать. ИИ только помогает лучше совместить набор товаров с группами людей, которые эти товары хотели бы купить. За создание спроса пока отвечает не ИИ.
Alexufo
с другой стороны врага увидим в лицо
Max-812
Тогда 99% игроков просто не смогут справится с NPC. Большинство людей в играх таки отдыхают, а не работают, imho. И если от них там будет требоваться работа — большинство просто перестанет играть. «Долбанутые» геймеры останутся, конечно, но кассу они не делают.
bigfatbrowncat
А кто сказал, что оно должно быть умнее человека?
Вы можете обучить его быть глупым, средним… Лишь бы при этом оно выглядело человечно. Неписи в современных игрушках раздражают не глупостью, а механичностью, неестественностью. Они выглядят тупой неживой декорацией. И геймдизайнерам приходится идти на сотню ограничений и уловок, чтобы это было как можно менее заметно. И всё равно не помогает.
Лично меня в этой демонстрации СтарКрафта больше всего впечатлило не то, что нейросеть размазала противников почти всухую (этого следовало ожидать рано или поздно), а то, что она легко и изящно проходит тест Тьюринга.
Самое революционное в этой сетке то, что она побеждает сильных игроков, при этом имея более низкий средний APM. А еще то, что она попутно решает задачи в духе «как двигать камерой, чтобы видеть самое интересное».
DesertFlow
Ага, для реалистичных NPC надо не просто создать сильный ИИ, но еще и заставить его отыгрывать роль! Чтобы он тактично уходил от каверзных вопросов игрока, придерживаясь механики игровой вселенной. А это уже не просто сильный ИИ, а очень сильный! Не каждый профессиональный GM так может.
bigfatbrowncat
Ну зачем же такой максимализм-то? Или механическая игрушка: или сразу GM…
Давайте, для начала, представим себе, что NPC разговаривает в разных «интонациях» и чуть разными словами, в зависимости от его настроения и вашей силы/поведения. Просто, смоделировать нормальную особенность человека — по-разному реагировать на разных собеседников.
Уже будет какая-никакая жизнь.
А выбор ваших реплик в диалоге еще очень долго придется делать из списка — тут да, непросто.
BigFlask
redpax
Ну стоит уточнить, что продул агент с камерой который учился 5 дней всего, другие же агенты без камеры учились по 200 лет каждый, а таких агентов было более 1000 и вот с ними уже было 0 шансов у человека. Я как любитель в старкрафт могу сказать, что тест Тюринга ИИ проходит он действует как человек но при этом почти не совершает ошибок. Самые значительные отклонения от человека заключаются в начальной разведке, да и в разведке в целом и видно, что разведка дроном это некий рудимент обучения на людях, бот пытается повторить эти действия но не до конца и не понимает зачем ему это.
bigfatbrowncat
А вы чуть-чуть понизьте планку.
Если не требовать от бота, чтобы он побеждал чемпионов, а просто понизить ему пиковый APM до человеческого, скажем, 300. Я вам ручаюсь как многолетний житель серебряно-золотой лиги СК2 — если этого бота пустить туда и научить его в конце партии вежливо говорить «gg», даже опытный игрок не отличит его от человека.
algotrader2013
Скорее всего, будут оптимизировать под целевые поведенческие паттерны игрока. Условно, не «победил» -> плюс в карму, а
«игрок играл еще более часа после конкретной битвы» -> плюс,
«игрок выключил комп после битвы» -> «минус»,
«игрок задонатил после битвы» -> «100 плюсов»,
«игрок удалил акк после битвы» -> «100 минусов».
Но, разумеется, куда более аккуратнее, и с более микроструктурными метриками
Max-812
То, что она «легко и изящно проходит тест Тьюринга» — это как раз не вызывает никакого удивления. Просто потому, что для создателей ИИ проход теста Тьюринга является первичным мотивом, что бы там они не декларировали. Потому как на нем их творения будут проверять всегда в первую очередь, безотносительно основной задачи. :)
bigfatbrowncat
А вы сами пробовали создать ИИ, который бы проходил тест Тьюринга? Хотя бы в простых игровых правилах
Max-812
Я не говорю, что это просто. Я говорю о том, что для создателей пройти этот тест — священная корова.
bigfatbrowncat
Ну так и круто! Для меня — тоже. Вот я ими и восторгаюсь ;)
wataru
APM — APM-ом, а точность кликов и скорость реакции совершенно нечеловеческие. И в 10 первых ихрах бот видел всю карту сразу (хоть и с туманом войны) и камеру никуда не двигал. Разработчкики, конечно, говорили, что, мол, он внимание фокусировал вроде как в одном месте, но там был момент, где бот контролировал одновременно 3 группы юнитов с разных сторон, когда окружал армию противника.
В последней игре, вроде как, ввели понятие камеры для бота и он ее проиграл.
hudson
Ну мне кажется можно не делать харкор, а добавить вариативности — в поведении, характере NPC, возможности или настроении дать какое-то задание.
UPD: bigfatbrowncat опередил и дал более развернутый ответ ))
struvv
интересные диалоги такой ИИ не сделает. Слова, это всего лишь способ передачи информации между воображениями двух людей. ИИ не имеет воображение и поэтому имеет фундаментальный дефект в задах, связанных с человеческой речью.
Банальная пример-
ИИ решить не сможет, так как ему нечем представить произошедшее.
А человек настолько легко это делает, что ему кажется, что этот процесс настолько прост, что его можно вообще не реализовывать в ИИ, что абсолютно неверно
striver
struvv
Это не так много исследовали, но как мне кажется, воображение появляется до появления речи и оно фундаментальная часть нервной системы человека.
При этом у животных оно не появляется.
Закликать человека это не проблема. Проблема касается всех тех областей, где нужно что-то представлять
DesertFlow
Как раз такого рода задачи ИИ уже относительно хорошо решает. См. например датасет bAbI. Там как раз такого рода примеры:
1 Mary moved to the bathroom.
2 John went to the hallway.
3 Where is Mary? bathroom
И более сложные запутанные ситуации. Но в целом верно, существующие системы обучения ИИ оторваны от реального мира и нет никаких гарантий, что из предоставляемых им датасетов можно извлечь эту информацию. О том что на самом деле происходит в описываемом тексте. Не говоря о практически отсутствующей у текущих слабых ИИ возможности делать последовательные рассуждения.
struvv
Такие это какие? Я специально привёл пример, в котором не работает простые трюки в ассоциации. Я не просто так писал не набор команд, а предложение, которое надо воображать, чтобы понять, что происходит
То есть утверждение должно быть в духе
1) Кто не успел съесть торт? Почему?
2) Кто получит подарок Кати?
3) Почему Оля отмечает день рождения у однокурсника в квартире? Что они там делают?
А не
Вот эта «небольшая» разница подачи и есть та пропасть между ИИ и человеком
DesertFlow
Это потому что в bAbI вопросы специально разбиты на категории по отдельным задачам. Вот смотрите, задача по выявлению временных зависимостей (Taks 14):
Предложения специально перепутаны местами. Про сегодняшний день первое и третье предложение, а второе про вчерашний. Причем в первом предложении ничего не говорится о том, в какой день после обеда это произошло. Нужно из общего контекста понять, что речь идет о сегодняшнем дне.
Это довольно близко к вашему примеру, не так ли? Из него тоже нужно выделить временную последовательность событий, что и в каком порядке происходило. Хотя предложения в тексте вашего примера тоже идут не в хронологическом порядке, как и в Task 14. Вот в какой последовательности у Кати прошел день:
Приведенные вами вопросы — это вопросы по контексту. Просто чуть более сложный вариант, но принципиально такой же, как восстанавливать из контекста, что первое и третье предложение в примере из Task 14 касаются сегодняшнего дня.
Ну и не надо забывать, что bAbI это игрушечный сборник задач. Один из первых такого рода.
struvv
нет, это очень далеко, это человеческое восприятие искажает ощущение, что это очень близко, в этом и состоит та пропасть, про которую я говорю.
На второй вопрос #3 ИИ не сможет ответить, а человек очень легко.
И «контекст» тут проблему не решает дальше этой самой пропасти — будет нужно специально затачивать предложение, так как «чуть чуть» не хватает, чтобы ИИ мог дать ответ на предложение в любой форме. А всё потому, что человек просто представит ситуацию #3 — Олю, отмечающую день рожденье в квартире её однокурсника, куда ещё не пришла Юля, и может представить много чего. Воображение это симуляция реальности, в этом его сила и огромное отличие от того, как работают ИИ. Причём человек может представлять что либо существенное время(мечтать), либо эмулировать уже состоявшуюся ситуацию с разными вариантами, как она могла пройти. Этот сильнейший скилл так лёгок в применении, что это упускают в оценках с ИИ.
А ИИ этого не делает, ИИ лишь выдаёт результат, который по сути функция от вводных данных.
caffeinum
Строго говоря, «вообразить» что-то – это тоже функция от входных данных. Это просто промежуточное представление. А именно благодаря «промежуточным» слоям нейросети последнее время так хорошо работают. То, что называется Deep Learning, это и есть «вообразить», как вы называется.
Более конкретный пример: автоэнкодер. У него в середине слой очень маленького «разрешения», поэтому нейросети «приходится» при тренировке придумать очень скомпрессированное представление того, что ей подали на вход.
Схема:
Отсюда же картинки про «сумму» очков и лица:
Есть некое промежуточное представление того, что такое «очки», и как их «надевать» на лицо.
Почему это не «воображение»?
michael_vostrikov
Нет. Если вы слышите, как кошка лазит за шкафом, у вас в воображении появляется и кошка и шкаф и примерное расположение кошки. А входные данные это шум. А в другой ситуации, например в гостях у друга, у которого собака, или если у вас нет кошки, такой же шум даст другую картинку в воображении.
То есть это функция не только от входных данных, а еще и от предыдущих запомненных. Их тоже можно считать входными, но вопрос в том, как они появляются в воображении из входных данных на тот момент.
struvv
Потому что это симуляция реального мира это не просто математическая функция от текущих входных данных. Разница огромна между симуляцией и преобразованием картинки через нейросеть
Когда подросток читает «Таинственный возраст» он создаёт мир, в котором есть всё, что описано в книге по тексту книги.
Когда нейросеть «читает» этот же текст, то она ничего подобного не делает.
Когда один из собеседников говорит слово «Москва», это слово несёт за собой сложнейший концепт, из жизни собеседников в городе, где каждый может представить запахи, погоду, метро, работу, учёбу, ночную жизнь и прочий бесконечный набор очень сложных и объёмных знаний, очень многие из которых исключительно сенсорные и все эти знания и образы первичны, а слово «Москва» всего лишь триггер для того, чтобы собеседник представил тоже самое.
У человека, в отличии от ИИ, за каждым словом стоит целый сложный мир, а для ИИ слова «Москва» всего лишь набор символов, влияющих на веса.
Вот когда ИИ сможет парсить вот такие вопросы:
Тогда есть смысл говорить о том, что ИИ как-то приблизился к человеку. Иначе это всё специфичные выборки, которые маскируют тот фундаментальный дефект ИИ, о котором я говорю
DesertFlow
Неверное утверждение. Нейросеть как раз делает то, что и подросток — создает, воображает модель мира. Другое дело, что ни одну нейросеть пока не обучали на таком же объеме данных, как получает за жизнь подросток.
Пруф. По одной картинке (слева) нейросеть воображает целый лабиринт, который мог бы соответствовать этой картинке. Это и есть воображение (или внутренняя модель мира в сознании), о котором вы говорите.
Druu
Нейросеть решает конкретную задачу, на которую вы ее обучите. Это совсем другое.
bigfatbrowncat
Человеческий мозг, в конечном счете, тоже решает одну единственную задачу. Победить в эволюционной гонке. Выжить, обойти других представителей своего вида по общественно-значимым критериям, оставить жизнеспособное потомство. Всё, что мы делаем в процессе, либо служит этим целям, либо нам кажется, что служит. Большинство игр в широком смысле этого слова (в том числе и художественная литература) имеют или обучающую задачу, то есть повышают общие знания и интеллект, помогая выжить, или создают иллюзию такого обучения, которая захватывает человека, паразитируя на инстинктах.
Человеческий разум не может быть смоделирован целиком не из-за какой-то особенной сущности, а всего лишь из-за чрезвычайной сложности.
Но возможность смоделировать его поведение в рамках решения отдельной задачи (а задачи эти всё продвинутее и все более творческие по своей сути) уже убедительно доказана.
michael_vostrikov
Смысл воображения не в том, чтобы получить видео, а чтобы там были отдельные наблюдаемые объекты. Если там один объект "двигающееся изображение", такое воображение ничего не дает.
Например, здесь правильно будет если нейросеть будет распознавать понятия "столбик", "стена", "пространство", характеристики цвет, высота, их различие, сможет представить столбик отдельно от всего остального с разных сторон.
Чтобы у нейросети были информационные элементы, с которыми можно связать все эти слова, поданные на вход текстом. Или в отладчике их выделить каким-нибудь анализатором. Видео здесь скорее дальше чем ближе к тому что требуется.
bigfatbrowncat
Эта задача называется object detection и решается с помощью сети еще проще, чем продемонстрированная выше.