

Всем хорошего дня. Перед вами первая статья из серии PHP для начинающих разработчиков. Это будет необычная серия статей, тут не будет
echo "Hello World", тут будет hardcore из жизни PHP программистов с небольшой примесью «домашней работы» для закрепления материала.Начну с сессий — это один из самых важных компонентов, с которыми вам придется работать. Не понимая принципов его работы — наворотите делов. Так что во избежание проблем я постараюсь рассказать о всех возможных нюансах.
Но для начала, чтобы понять зачем нам сессия, обратимся к истокам — к HTTP протоколу.
HTTP Protocol
HTTP протокол — это HyperText Transfer Protocol — «протокол передачи гипертекста» — т.е. по сути — текстовый протокол, и его понять не составит труда.
Изначально подразумевали, что по этому протоколу будет только HTML передаваться, отсель и название, а сейчас чего только не отправляют и =^.^= и(•_?_•)
Чтобы не ходить вокруг да около, давайте я вам приведу пример общения по HTTP протоколу.
Вот пример запроса, каким его отправляет ваш браузер, когда вы запрашиваете страницу
http://example.com:GET / HTTP/1.1
Host: example.com
Accept: text/html
<пустая строка>А вот пример ответа:
HTTP/1.1 200 OK
Content-Length: 1983
Content-Type: text/html; charset=utf-8
<html>
<head>...</head>
<body>...</body>
</html>
Это очень упрощенные примеры, но и тут можно увидеть из чего состоят HTTP запрос и ответ:
- стартовая строка — для запроса содержит метод и путь запрашиваемой страницы, для ответа — версию протокола и код ответа
- заголовки — имеют формат ключ-значение разделенные двоеточием, каждый новый заголовок пишется с новой строки
- тело сообщения — непосредственно HTML либо данные отделяют от заголовков двумя переносами строки, могут отсутствовать, как в приведенном запросе
Так, вроде с протоколом разобрались — он простой, ведёт свою историю аж с 1992-го года, так что идеальным его не назовешь, но какой есть — отправили запрос — получите ответ, и всё, сервер и клиент никоим образом более не связаны. Но подобный сценарий отнюдь не единственный возможный, у нас же может быть авторизация, сервер должен каким-то образом понимать, что вот этот запрос пришёл от определенного пользователя, т.е. клиент и сервер должны общаться в рамках некой сессии. И да, для этого придумали следующий механизм:
- При авторизации пользователя, сервер генерирует и запоминает уникальный ключ — идентификатор сессии, и сообщает его браузеру
- Браузер сохраняет этот ключ, и при каждом последующем запросе, его отправляет
Для реализации этого механизма и были созданы cookie (куки, печеньки) — простые текстовые файлы на вашем компьютере, по файлу для каждого домена (хотя некоторые браузеры более продвинутые, и используют для хранения SQLite базу данных), при этом браузер накладывает ограничение на количество записей и размер хранимых данных (для большинства браузеров это 4096 байт, см. RFC 2109 от 1997-го года)
Т.е. если украсть cookie из вашего браузера, то можно будет зайти на вашу страничку в facebook от вашего имени? Не пугайтесь, так сделать нельзя, по крайней мере с facebook, и дальше я вам покажу один из возможных способов защиты от данного вида атаки на ваших пользователей.
Давайте теперь посмотрим как изменятся наши запрос-ответ, будь там авторизация:
Request
POST /login/ HTTP/1.1
Host: example.com
Accept: text/html
login=Username&password=UserpassМетод у нас изменился на POST, и в теле запроса у нас передаются логин и пароль. Если использовать метод GET, то строка запроса будет содержать логин и пароль, что не очень правильно с идеологической точки зрения, и имеет ряд побочных явлений в виде логирования (например, в том же
access.log) и кеширования паролей в открытом виде.Response
HTTP/1.1 200 OK
Content-Type: text/html; charset=utf-8
Set-Cookie: KEY=VerySecretUniqueKey
<html>
<head>...</head>
<body>...</body>
</html>Ответ сервер будет содержать заголовок
Set-Cookie: KEY=VerySecretUniqueKey, что заставит браузер сохранить эти данные в файлы cookie, и при следующем обращении к серверу — они будут отправлены и опознаны сервером:Request
GET / HTTP/1.1
Host: example.com
Accept: text/html
Cookie: KEY=VerySecretUniqueKey
<пустая строка>Как можно заметить, заголовки отправляемые браузером (Request Headers) и сервером (Response Headers) отличаются, хотя есть и общие и для запросов и для ответов (General Headers)
Сервер узнал нашего пользователя по присланным cookie, и дальше предоставит ему доступ к личной информации. Так, ну вроде с сессиями и HTTP разобрались, теперь можно вернутся к PHP и его особенностям.
PHP и сессия
Я надеюсь, у вас уже установлен PHP на компьютере, т.к. дальше я буду приводить примеры, и их надо будет запускать
Язык PHP создавался под стать протоколу HTTP — т.е. основная его задача — это дать ответ на HTTP запрос и «умереть» освободив память и ресурсы. Следовательно, и механизм сессий работает в PHP не в автоматическом режиме, а в ручном, и нужно знать что вызвать, да в каком порядке.
Вот вам статейка на тему PHP is meant to die, или вот она же на русском языке, но лучше отложите её в закладки «на потом».
Перво-наперво необходимо «стартовать» сессию — для этого воспользуемся функцией session_start(), создайте файл session.start.php со следующим содержимым:
<?php
session_start();Запустите встроенный в PHP web-server в папке с вашим скриптом:
php -S 127.0.0.1:8080Запустите браузер, и откройте в нём Developer Tools (или что там у вас), далее перейдите на страницу http://127.0.0.1:8080/session.start.php — вы должны увидеть лишь пустую страницу, но не спешите закрывать — посмотрите на заголовки которые нам прислал сервер:
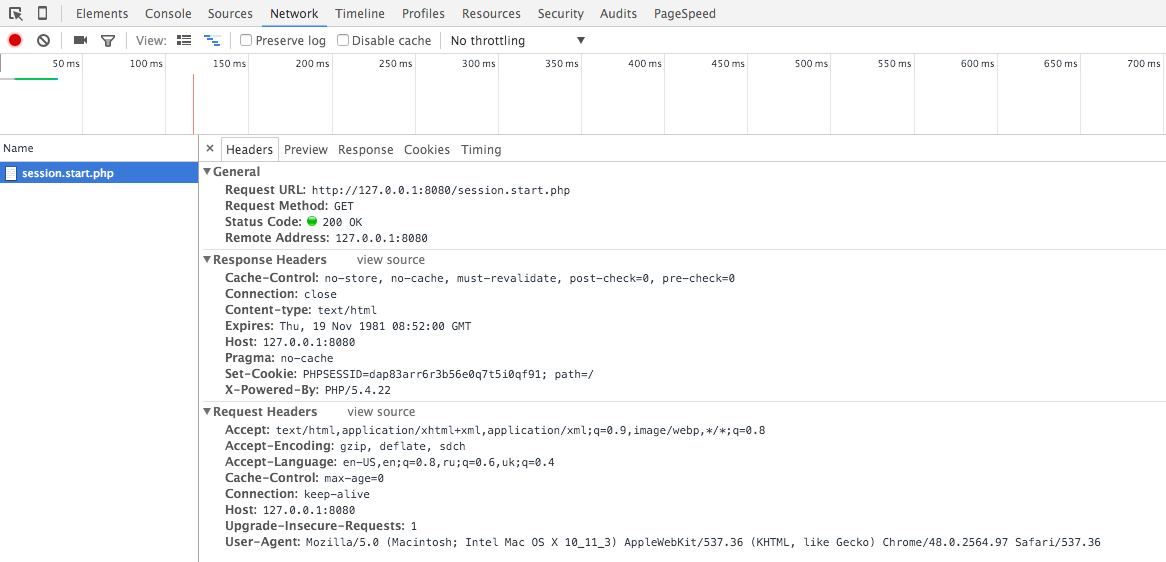
Там будет много чего, интересует нас только вот эта строчка в ответе сервера (почистите куки, если нет такой строчки, и обновите страницу):
Set-Cookie: PHPSESSID=dap83arr6r3b56e0q7t5i0qf91; path=/Увидев сие, браузер сохранит у себя куку с именем `PHPSESSID`:
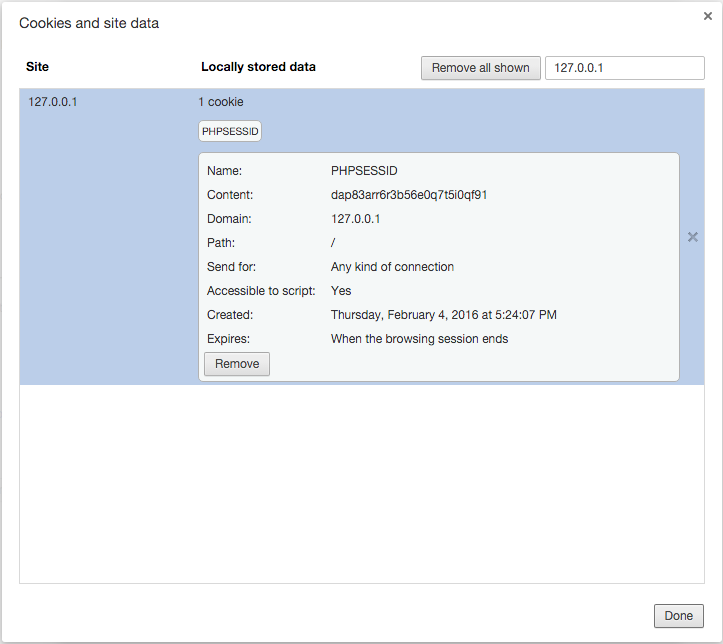
PHPSESSID — имя сессии по умолчанию, регулируется из конфига php.ini директивой session.name, при необходимости имя можно изменить в самом конфигурационном файле или с помощью функции session_name()И теперь — обновляем страничку, и видим, что браузер отправляет эту куку на сервер, можете попробовать пару раз обновить страницу, результат будет идентичным:

Итого, что мы имеем — теория совпала с практикой, и это просто отлично.
Следующий шаг — сохраним в сессию произвольное значение, для этого в PHP используется супер-глобальная переменная
$_SESSION, сохранять будем текущее время — для этого вызовем функцию date():session_start();
$_SESSION['time'] = date("H:i:s");
echo $_SESSION['time'];Обновляем страничку и видим время сервера, обновляем ещё раз — и время обновилось. Давайте теперь сделаем так, чтобы установленное время не изменялось при каждом обновлении страницы:
session_start();
if (!isset($_SESSION['time'])) {
$_SESSION['time'] = date("H:i:s");
}
echo $_SESSION['time'];Обновляем — время не меняется, то что нужно. Но при этом мы помним, PHP умирает, значит данную сессию он где-то хранит, и мы найдём это место…
Всё тайное становится явным
По умолчанию, PHP хранит сессию в файлах — за это отвечает директива session.save_handler, путь по которому сохраняются файлы ищите в директиве session.save_path, либо воспользуйтесь функцией session_save_path() для получения необходимого пути.
В вашей конфигурации путь к файлам может быть не указан, тогда файлы сессии будут хранится во временных файлах вашей системы — вызовите функцию sys_get_temp_dir() и узнайте где это потаённое место.
Так, идём по данному пути и находим ваш файл сессии (у меня это файл
sess_dap83arr6r3b56e0q7t5i0qf91), откроем его в текстовом редакторе:time|s:8:"16:19:51";Как видим — вот оно наше время, вот в каком хитром формате хранится наша сессия, но мы можем внести правки, поменять время, или можем просто вписать любую строку, почему бы и нет:
time|s:13:"\m/ (@.@) \m/";Для преобразования этой строки в массив нужно воспользоваться функцией session_decode(), для обратного преобразования — session_encode() — это зовется сериализацией, вот только в PHP для сессий — она своя — особенная, хотя можно использовать и стандартную PHP сериализацию — пропишите в конфигурационной директиве session.serialize_handler значение
php_serialize и будет вам счастье, и $_SESSION можно будет использовать без ограничений — в качестве индекса теперь вы сможете использовать цифры и специальные символы | и ! в имени (за все 10+ лет работы, ни разу не надо было :)session_decode(), вот вам тестовый набор данных для сессии (для решения знаний регулярных выражений не требуется), текст для преобразования возьмите из файла вашей текущей сессии:$_SESSION['integer var'] = 123;
$_SESSION['float var'] = 1.23;
$_SESSION['octal var'] = 0x123;
$_SESSION['string var'] = "Hello world";
$_SESSION['array var'] = array('one', 'two', [1,2,3]);
$object = new stdClass();
$object->foo = 'bar';
$object->arr = array('hello', 'world');
$_SESSION['object var'] = $object;
$_SESSION['integer again'] = 42;Так, что мы ещё не пробовали? Правильно — украсть «печеньки», давайте запустим другой браузер и добавим в него теже самые cookie. Я вам для этого простенький javascript написал, скопируйте его в консоль браузера и запустите, только не забудьте идентификатор сессии поменять на свой:
javascript:(function(){document.cookie='PHPSESSID=dap83arr6r3b56e0q7t5i0qf91;path=/;';window.location.reload();})()Вот теперь у вас оба браузера смотрят на одну и туже сессию. Я выше упоминал, что расскажу о способах защиты, рассмотрим самый простой способ — привяжем сессию к браузеру, точнее к тому, как браузер представляется серверу — будем запоминать User-Agent и проверять его каждый раз:
session_start();
if (!isset($_SESSION['time'])) {
$_SESSION['ua'] = $_SERVER['HTTP_USER_AGENT'];
$_SESSION['time'] = date("H:i:s");
}
if ($_SESSION['ua'] != $_SERVER['HTTP_USER_AGENT']) {
die('Wrong browser');
}
echo $_SESSION['time'];Это подделать сложнее, но всё ещё возможно, добавьте сюда ещё сохранение и проверку
$_SERVER['REMOTE_ADDR'] и $_SERVER['HTTP_X_FORWARDED_FOR'], и это уже более-менее будет похоже на защиту от злоумышленников посягающих на наши «печеньки».Ключевое слово в предыдущем абзаце похоже, в реальных проектах cookies уже давно «бегают» по HTTPS протоколу, таким образом никто их не сможет украсть без физического доступа к вашему компьютеру или смартфону
Стоит упомянуть директиву session.cookie-httponly, благодаря ей сессионная кука будет недоступна из JavaScript'a. Кроме этого — если заглянуть в мануал функции setcookie(), то можно заметить, что последний параметр так же отвечает за HttpOnly. Помните об этом — эта настройка позволяет достаточно эффективно бороться с XSS атаками в практически всех браузерах.
По шагам
А теперь поясню по шагам алгоритм, как работает сессия в PHP, на примере следующего кода (настройки по умолчанию):
session_start();
$_SESSION['id'] = 42;- после вызова
session_start()PHP ищет в cookie идентификатор сессии по имени прописанном вsession.name— этоPHPSESSID - если нет идентификатора — то он создаётся (см. session_id()), и создаёт пустой файл сессии по пути
session.save_pathс именемsess_{session_id()}, в ответ сервера будет добавлены заголовки, для установки cookie{session_name()}={session_id()} - если идентификатор присутствует, то ищем файл сессии в папке
session.save_path:
- не находим — создаём пустой файл с именем
sess_{$_COOKIE[session_name()]}(идентификатор может содержать лишь символы из диапазоновa-z,A-Z,0-9, запятую и знак минус) - находим, читаем файл и распаковываем данные (см. session_decode()) в супер-глобальную переменную
$_SESSION(файл блокируется для чтения/записи)
- не находим — создаём пустой файл с именем
- когда скрипт закончил свою работу, то все данные из
$_SESSIONзапаковывают с использованиемsession_encode()в файл по путиsession.save_pathс именемsess_{session_id()}(блокировка снимается)
PHPSESSID, пусть это будет 1234567890, обновите страницу, проверьте, что у вас создался новый файл sess_1234567890А есть ли жизнь без «печенек»?
PHP может работать с сессией даже если cookie в браузере отключены, но тогда все URL на сайте будут содержать параметр с идентификатором вашей сессии, и да — это ещё настроить надо, но оно вам надо? Мне не приходилось это использовать, но если очень хочется — я просто скажу где копать:
А если надо сессию в базе данных хранить?
Для хранения сессии в БД потребуется изменить хранилище сессии и указать PHP как им пользоваться, для этой цели создан интерфейс SessionHandlerInterface и функция session_set_save_handler.
Отдельно замечу, что не надо писать собственные обработчики сессий для redis и memcache — когда вы устанавливаете данные расширения, то вместе с ними идут и соответствующие обработчики, так что RTFM наше всё. Ну и да, обработчик нужно указывать до вызова session_start() ;)SessionHandlerInterface для хранения сессии в MySQL, проверьте, работает ли он.Это задание со звёздочкой, для тех кто уже познакомился с базами данных.
Когда умирает сессия?
За время жизни сессии отвечает директива session.gc_maxlifetime. По умолчанию, данная директива равна 1440 секундам (24 минуты), понимать её следует так, что если к сессии не было обращении в течении заданного времени, то сессия будет считаться «протухшей» и будет ждать своей очереди на удаление.
Интересен другой вопрос, можете задать его матёрым разработчикам — когда PHP удаляет файлы просроченных сессий? Ответ есть в официальном руководстве, но не в явном виде — так что запоминайте:
Сборщик мусора (garbage collection) может запускаться при вызове функции
session_start(), вероятность запуска зависит от двух директив session.gc_probability и session.gc_divisor, первая выступает в качестве делимого, вторая — делителя, и по умолчанию эти значения 1 и 100, т.е. вероятность того, что сборщик будет запущен и файлы сессий будут удалены — примерно 1%.session.gc_divisor так, чтобы сборщик мусора запускался каждый раз, проверьте что это так и происходит.Самая тривиальная ошибка
Ошибка у которой более полумиллиона результатов в выдаче Google:
Cannot send session cookie — headers already sent by
Cannot send session cache limiter — headers already sent
Для получения таковой, создайте файл session.error.php со следующим содержимым:
echo str_pad(' ', ini_get('output_buffering'));
session_start();Во второй строке странная «магия» — это фокус с буфером вывода, я ещё расскажу о нём в одной из следующих статей, пока считайте это лишь строкой длинной в 4096 символов, в данном случае — это всё пробелы
Запустите, предварительно удалив cookie, и получите приведенные ошибки, хоть текст ошибок и разный, но суть одна — поезд ушёл — сервер уже отправил браузеру содержимое страницы, и отправлять заголовки уже поздно, это не сработает, и в куках не появилось заветного идентификатора сессии. Если вы стокнулись с данной ошибкой — ищите место, где выводится текст раньше времени, это может быть пробел до символов
<?php, или после ?> в одном из подключаемых файлов, и ладно если это пробел, может быть и какой-нить непечатный символ вроде BOM, так что будьте внимательны, и вас сия зараза не коснется (как-же,… гомерический смех).require_once 'include/sess.php';
sess_start();
if (isset($_SESS["id"])) {
echo $_SESS["id"];
} else {
$_SESS["id"] = 42;
}Для осуществления задуманного вам потребуется функция register_shutdown_function()
Блокировка
Ещё одна распространённая ошибка у новичков — это попытка прочитать файл сессии пока он заблокирован другим скриптом. Собственно, это не совсем ошибка, это недопонимание принципа блокировки :)
Но давайте ещё раз по шагам:
session_start()не только создаёт/читает файл, но и блокирует его, чтобы никто не мог внести правки в момент выполнения скрипта, или прочитать не консистентные данные из файла сессии- блокировка снимается по окончанию выполнения скрипта
«Воткнутся» в данную ошибку очень легко, создайте два файла:
// start.php
session_start();
echo "OK";
// lock.php
session_start();
sleep(10);
echo "OK";
Теперь, если вы откроете в браузере страничку
lock.php, а затем в новой вкладке откроете start.php то увидите, что вторая страничка откроется только после того, как отработает первый скрипт, который блокирует файл сессии на 10 секунд.Есть пару вариантов, как избежать подобного явления — «топорный» и «продуманный».
«Топорный»
Использовать самописный обработчик сессий, в котором «забыть» реализовать блокировку :)
Чуть лучше вариант, это взять готовый и отключить блокировку (например у memcached есть такая опция — memcached.sess_locking) O_o
Потратить часы на дебаг кода в поисках редко всплывающей ошибки…
«Продуманный»
Куда как лучше — самому следить за блокировкой сессии, и снимать её, когда она не требуется:
— Если вы уверенны, что вам не потребуется вносить изменения в сессионные данные используйте опцию
read_and_close при старте сессии:
session_start([
'read_and_close' => true
]);
Таким образом, блокировка будет снята сразу по прочтению данных сессии.
— Если вам таки нужно вносить изменения в сессию, то после внесения оных закрывайте сессию от записи:
session_start();
// some changes
session_write_close();
start.php и lock.php, создайте ещё файлы read-close.php и write-close.php, в которых вы будете контролировать блокировку перечисленными способами. Проверьте как работает (или не работает) блокировка.В заключение
В этой статье вам дано семь заданий, при этом они касаются не только работы с сессиями, но так же познакомят вас с MySQL и с функциями работы со строками. Для усвоения этого материала — отдельной статьи не нужно, хватит и мануала по приведенным ссылкам — никто за вас его читать не будет. Дерзайте!
P.S. Если узнали что-то новое из статьи — отблагодарите автора — зашарьте статью в социалках ;)
P.P.S. Да, это кросс-пост статьи с моего блога, но она актуальна и поныне :)
Комментарии (41)

kenbo
29.01.2019 14:17+2Стоит упомянуть о принудительной очистки сессии. Удалять не валидные сессии в потоке обработки запроса не лучшая идея.

andreymal
29.01.2019 14:23+2он [HTTP] простой
Нет, он лишь внешне смотрится просто. Один только RFC 2616 занимает 176 страниц, а более новые RFC 7230-7235 — все 305 страниц в сумме
(если использовать метод GET, то строка запроса будет содержать логин и пароль, и может оказаться сохраненной на каких нибудь промежуточных прокси серверах, что очень плохо)
Прокси-серверы по определению видят ВЕСЬ запрос, в том числе тело и куки. Сохранить, соответственно, тоже могут что угодно куда угодно. Если же запрос зашифрованный (https, vpn и т.п.), то они не смогут увидеть ни тела, ни кук, ни строку запроса тоже. Если имеется в виду кеширование GET-запросов, то это отключается средствами HTTP, а POST-запрос нужен совсем не поэтому
Set-Cookie: KEY=VerySecretUniqueKey
Не такой уж и Secret, если флагов HttpOnly и Secure нет (впрочем, ниже по тексту HttpOnly упоминается)
Язык PHP создавался под стать протоколу HTTP — т.е. основная его задача — это дать ответ на HTTP запрос и «умереть» освободив память и ресурсы. Следовательно, и механизм сессий работает в PHP не в автоматическом режиме, а в ручном, и нужно знать что вызвать, да в каком порядке.
Из первого предложения никак не следует второе
расскажу о способах защиты [...] будем запоминать User-Agent
Вообще не защита. User-Agent не является секретом и подбирается на ура, особенно для популярных браузеров
die('Wrong browser');
То есть после выхода новой версии браузера пользователь больше не сможет пользоваться сайтом?
добавьте сюда ещё сохранение и проверку $_SERVER['REMOTE_ADDR']
То есть пользователи мобильных сетей больше не смогут пользоваться сайтом?
$_SERVER['HTTP_X_FORWARDED_FOR']
Этот заголовок вообще может установить пользователь как хочет, и опираться на него без предварительной настройки сервера нельзя
это уже более-менее будет походить на защиту от злоумышленников
Это будет походить на защиту от обычных пользователей, которые всего лишь обновили свой хром из гугл-плея и/или перебежали в другой макдональдс и потеряли доступ к сайту
эта настройка [HttpOnly] позволяет достаточно эффективно бороться с XSS атаками в практически всех браузерах
HttpOnly не имеет вообще никакого отношения к XSS. Если есть XSS, то ничто не мешает напакостить и, например, отправлять ajax-запросы без и чтения кук (куки к запросам на тот же origin автоматически добавит сам браузер)
AntonShevchuk Автор
29.01.2019 14:41Ух, как-то совсем серьёзно отнеслись к статье «для начинающих».
Имхо, не стоит начинающих пугать RFC, хорошо если усвоят азы HTTP, и да я не собирался пересказывать весь мануал, лишь провести поверхностное знакомство для понимания механизма сессий, чутка затронув различия GET и POST запросов.
По «защите» я хотел донести главное, что её нужно внедрять, что AS IS оставлять не следует.
По работе сессии и РНР — согласен, не верно сформулировал мысль, надо будет исправить.andreymal
29.01.2019 14:45+1«Для начинающих» не означает, что можно писать что-то не соответствующее действительности. Ну или в крайнем случае можно для упрощения объяснений, но с обязательной припиской о неточности и ссылкой для интересующихся, где почитать подробнее
я хотел донести главное, что её нужно внедрять
Судя по качеству продемонстрированноый защиты — на этой мысли и стоило остановиться, а сейчас реализация из статьи лишь несёт вред
mayorovp
30.01.2019 10:22+1Тем не менее, обычно в access-логах сохраняется именно url, а не содержимое тела запроса.
Передавать логин с паролем нужно через POST не для защиты от перехвата трафика, а для защиты от подобного сохранения в логах. Чтобы не получилось, что в БД все пароли хранятся строго в виде хешей и все как бы безопасно — а рядом лежит файлик с теми же самыми паролями в открытом виде.

rjhdby
30.01.2019 11:31+1Прокси-серверы по определению видят ВЕСЬ запрос, в том числе тело и куки. Сохранить, соответственно, тоже могут что угодно куда угодно
Статья рассказывает про механизм сессиий, для совсем начинающих. Придираться и залезать в такие дебри — сильно за рамками. Но это ладно.
Касательно вашего замечания. Ключевое слово тут «могут». Access log апача (и аналоги) практически никогда не отключаются и сохраняют историю запросов именно в виде URL. Т.е. со всеми GET полями. С другой стороны, я ни разу не встречал ситуации, когда сохранялись заголовки и тело. Напомню, что речь про поведение по умолчанию.andreymal
30.01.2019 11:33+1Вот именно про access.log и нужно было рассказать в статье, а прокси вообще не упоминать
AntonShevchuk Автор
30.01.2019 11:35Ребята, статью я подправил так, чтобы всё было правильно и понятно для начинающих, и не смущало никого.
Логи/кеширование/хистори браузера и т.д. и т.п. — всё это побочные явления при использовании GET (это не считая идеолигически неверного GET для подобных операций).andreymal
30.01.2019 11:41+2Текущая формулировка лучше изначальной. Но access.log всё равно лучше упомянуть, потому что, в отличие от туманного какого-то там «логирования и кеширования», файлы access.log начинающий сможет найти без труда на почти любом хостинге
Loki3000
29.01.2019 14:32AntonShevchuk Автор
29.01.2019 14:45Эта директива относится к файлам кук, но не касается файлов сессии
Loki3000
30.01.2019 09:10Да вы правы. Не на тот якорь ссылку скопировал. Нужно было на session.gc_maxlifetime.
AntonShevchuk Автор
30.01.2019 11:04Опять же, это время когда сессия будет считаться протухшей, в статье я рассказываю в какой момент времени перестанет существовать файл
Loki3000
30.01.2019 11:12Он именно и перестанет существовать после этого времени. Если отключить сборщик мусора, то сессии будут жить долго и счастливо вне зависимости от состояния этой настройки.
AntonShevchuk Автор
30.01.2019 11:17Не перестанет, после этого времени она будет протухшей и будет ждать сборщик мусора, а он запускается не каждый же раз
Loki3000
30.01.2019 11:53Вы в этом точно уверены? Не хотите проверить?
<?php //время жизни сессии 10 секунд ini_set('session.gc_maxlifetime', 10); session_start(); var_dump(empty($_SESSION['number'])?0:$_SESSION['number']); if (empty($_SESSION['number'])) { $_SESSION['number']=42; }
Если ваше утверждение верно, то через 10 секунд сессия прервется. Я же утверждаю что она будет вполне себе живой до следующего прохода сборщика мусора.AntonShevchuk Автор
30.01.2019 11:57+1Где вы это у меня прочитали? О_о
Вы сейчас утверждаете тоже самое, что я написал в статье…

Pochemuk
29.01.2019 15:25Совсем не затронут вопрос создания «долгоиграющих» сессий. Т.е. таких, которые не прекращаются при закрытии браузера, а восстанавливаются даже через несколько дней.
Я, конечно, давно не делал ничего с сессиями на PHP (да и вообще на PHP), но меня терзает смутное сомнение, что при выполнении session_start() браузеру отправляется директива не приводящая к созданию файловой куки. Сессионный идентификатор хранится только в памяти браузера и уничтожается при закрытии браузера.
А чтобы создать файловую куку, нужно выполнить команду setcookie, причем с установленным достаточно большим временем ее жизни. И в эту куку уже записывать ID сессии или/и «билет» входа (сессионный пароль).
Хотя… извиняюсь, если что попутал.AntonShevchuk Автор
29.01.2019 16:59Вызов
session_start()приводит к отправке заголовкаSet-CookiecPHPSESSID, хранит браузер это значение в памяти, в БД или сохраняет в файл — это уже он сам для себя решает.Pochemuk
29.01.2019 21:08Да… в последнее время у некоторых браузеров даже сессионные куки хранятся в БД. Но речь не столько о способе хранения, сколько о продолжительности. Раньше различие было четко — сессионные куки не хранились на диске в виде файлов или в БД, а информация длительного хранения записывалась в файловые куки. С тех пор многое изменилось. Но суть в том, что по session_start() в браузер передается директива Set-Cookie без указания срока хранения этой информации (с нулевым сроком), т.е. краткосрочная. А для создания куки длительного хранения используется setcookie с указанием срока годности этой информации.
Т.е. — это механизмы для создания сессий разного срока действия.
Но… действительно все зависит от браузера. Говорят, Хром не удаляет id сессий с нулевым сроком жизни при закрытии. И они могут быть использованы повторно.
nokimaro
30.01.2019 17:24Ещё со времен РНР4 есть возможность задать $lifetime для сессионой куки
session_set_cookie_params ( int $lifetime [, string $path [, string $domain [, bool $secure = FALSE [, bool $httponly = FALSE ]]]] ) : bool
php.net/manual/ru/function.session-set-cookie-params.php
shahrudinov
29.01.2019 16:05+1Я в свое время когда изучал php очень рад был найти такие статьи. Так как помню этот ад когда начинаешь проходить какую то тему и начинается что то с чем то. Когда куча ссылок и куча непонятной информации помимо основной темы и ты просто начинаешь прыгать по темам и теряться. Детальность это конечно хорошо но вспомните себя. Для новичка который хочет понять что такое сессия — хорошая статья.

Mixalych
29.01.2019 17:57+1При изучении сессий в свое время очень долго тупил по некоторым моментам (описание ситуация из 2004 года, а не сегодняшние):
1. Не работают сессии. О ней вы немного рассказали — нельзя выводить текст в браузер до старта сессии. Вообще никакой ни из какого файла — если старт сессии происходит в подключенном файле (include), то по пути до самой этой функции старта сессии ничего не должно выводиться в браузер. Я долго спотыкался о display_errors — когда о всех notice и warning инфа выдается в браузер (пример):
index.php
<?php if ($_GET["logout"]) { // code } session_start();
Пример больше надуманный, но сессия стартовать не будет, так как прилетит notice о том, что в массиве $_GET нет индекса logout — это неявная на первый взгляд ситуация. Но сам будучи новичком — нервов попила эта ситуация — я же нигде echo не вызываю!?
2. Я изначально думал, что сессии — это замена кукам, а потом сделал для себя «открытие», что для поднятие сессии можно идентификатор хранить в тех же куках, а не дергать его из параметров запроса в браузере на каждом файле. И что это дополняющие друг-друга функциональности.
3. Долго не мог понять, зачем вообще эти сессии помимо авторизации (разграничения доступа к определенному функционалу) — они ведь позволяют хранить вообще любые данные для конкретного пользователя на самом сервере, а не на клиенте. Но фишка как раз в том, что в сессии можно хранить данные, которые можно «передавать» между различными запросами, то есть что-то делал на одном шаге, сохранил состояние. Помню, что когда клепал каталог товаров с возможностью покупки, то хранил эти самые покупки в отдельном файлике — самописный функционал, файл назывался session_id.txt, то есть авторизацию проводил через сессию, а вот параметры хранил через свои костыли. До этого я просто не мог понять, читая статьи, что можно в сессиях хранить что-то больше, чем идентификатор. То есть для новичков пишут — хранить там можно все. А дальше нарисуй сову сам. А если бы объясняли на пальцах, что состояние корзины покупок мы можем хранить в массиве, который в свою очередь можем хранить в сессии и потом доставать из него штатными средствами php, чтобы решить задачу, а не изобретать костыли для ее решения.
4. Так же пояснять о том, что сессию «поднять» можно закрыв вкладку, но для этого нужно настроить куку, точнее ее время хранение и для какого домена (страниц) она должна отдаваться браузеру.
Я б не стал набирать комментарий, но вот кратко описал то, с чем столкнулся при изучении. Из статьи я тоже понял только то, что сессия позволяет распознавать пользователя на сайте. И все. Что там что-то можно хранить, но для чего это может понадобиться — не сказано. А если учитель привел бы конкретные примеры/ситуации или решение пусть того же to-do list через сессии — то есть завтра можно открыть вкладку и что-то дописать/отредактировать (потом как эту же задачу решить с помощью голого mysqli, затем как с помощью классов — PDO — тут же про иньекции и пр). Тут как раз можно было бы осветить большую часть возможностей, но уже вместе с практикой.
Отступление: еще в школьные годы, к бабушке-соседке приезжал внук: толковый парень, мог с механикой решить и аргументировать решение своей задачи — под каким углом срезать уголки, чтобы сварочный шов был крепче. По звуку мог определить с каким цилиндром что-то не то. И т. д. Но вот забить гвоздь не умел. Наточить нож тоже. Зато знал все в теории, потому что практика у него отсутствовала. Может не было мотивации, может еще что-то. Может он просто инженер-теоретик. Но суть мысли в другом — теория, закрепленная практикой — бесценна. Знания остаются в памяти более надолго.
Нужно знать для чего инструмент (сессия) — для решения каких задач — корзина покупателя, авторизация, передача параметров между запросами в пять дней между самими запросами и т.д. — а не просто вот вам есть такой инструмент. Бывают конечно и исключения из правил — синяя изолента и молоток с ломом, но это уже другая история.
Какое-то большое имхо получилось…
Статья неплохая получилась, но хотелось бы чуточку «для чего это нужно», а не просто сухой текст.

Compolomus
29.01.2019 19:05Автору респект. Когда то помогла статья про принеси, там более менее я смог понять что это и зачем. Так же ковырял фрэймворк товарища, чисто в научных целях.
Можно узнать оглавление будущих тем?AntonShevchuk Автор
29.01.2019 19:14У меня в серии статей «PHP для начинающих» пока лишь 4-ре статьи:
— Сессия
— Подключение файлов
— Буфер вывода
— Обработка ошибокCompolomus
29.01.2019 19:24Не думали подойти к обучению не стандартным способом, каких тысячи, что книги, что статьи? Например начинать с композера и с readme пакетов, строить свое используя чужие наработки. Думаю js чистый ни кто не пишет сейчас. Сразу берут все с пакетов
AntonShevchuk Автор
29.01.2019 19:49Ну книгу уже писал, ещё про jQuery :)
Мне нравится формат статей с акцентом на то, что обычно опускают в книгах. Например рассказ про сессии без привязки к HTTP считаю как раз таким моментом, и про то где же хранятся данные сессий и как с ними можно работать. Интересно получать фидбек и доводить статьи «до блеска», так что я очень положительно смотрю на фидбеки в комментариях (как например andreymal писал выше).
Мне интересно воспитывать разработчиков, а не пользователей фреймворков. Писать про пакеты и наработки — этим должны авторы фреймворков и пакетов заниматься, мне же за изменениями не успеть.
Mixalych
29.01.2019 21:20Предложения:
1. Про подключение файлов — неплохо бы было затронуть тот факт, что подключаемый файл может возвращать результат, а то глаза были квадратными, когда я впервые увидел конструкцию $data = require 'config.php';
2. Если будете рассказывать про операции с файлами, то неплохо уделить внимание, что работать можно с контекстом — то есть контекст — интерфейс ввода вывода, или если на пальцах — писать/читать можно в сокет, буфер, файл, что это одно и тоже по-сути, только трансфер данных идет на разном уровне (протоколе).
3. Для буфера — разницу между ob_flush, что он не везде сразу выводит данные в браузер, что буферизацию можно использовать для пост обработки данных (по сути создавать фильтры и модули в проекте без изменения ядра), создания виджетов на сайте, что ее не нужно использовать везде и всякий раз.
4. Обработка ошибок — FILE_APPEND для file_put_content, перехват throw new Exception('error text') в блоке try catch, var_export, своя раскраска debug_backtrace. Что фатальные ошибки (ошибки парсинга) не перехватываются и пр.
Обязательным считаю рассказать новичкам про форматирование кода при наборе — сразу же, 0-м пунктом. Чтобы приучать к порядку. Еще бы и IDE бы настраивать сразу. Потому как связка FileZilla --> Notepad++ (Sublime) --> FileZilla отнимает очень много времени от решения задач. Еще в IDE есть сразу подсказки, есть ссылки на онлайн документацию — причем она же на русском языке. Раньше таких средств не было, книги и чужие исходники. Это очень не хватало раньше. А то открываем блокнот… Расскажите, что нет необходимости уже закрывать файл ?>. Что функция — это ключ на 10, который откручивает только гайку на 10, что набор ключей — это несколько функций, которые решают определенный тип задач и их можно выгрузить в отдельный модуль — пространство имен. Что такой же ключ в другом чемодане — это уже другое пространство имен. То есть одна функция от разных авторов, выполняющая другую задачу. Что железный конструктор, о котором в 90-х мечтали — гайки, болты, штанги, колеса — это просто переменные, разные. Даже можно сказать — что гайка — это константа, то есть переменная, значение которой никогда не меняется. Что ключ, отвертка — это функции для работы с данными (гайками), по сути это уже объект (класс) — содержит данные и инструменты (функции) для работы с ними. Конструктор — и есть класс. Объект класса — это конкретный конструктор. Вот из конструктора можно сделать разные детали — это потомки объекта. Сам конструктор как идея — это интерфейс, если дальше проводить аналогию. То есть он предполагает наличие деталей и инструментов для работы с ними. Два обязательных условия, о которых мы просто заявили. А вот в каждом конструкторе есть свой набор деталей — у железного один набор, у лего — другой, у паззла — третий. Все они идут в коробках (интерфейсах). Проданный конструктор одному клиенту — это как создание объекта — new ClassName. И вот клиент ушел с покупкой делать свои дела и магазину неважно, так и менеджер памяти сам следит за кол-вом ссылок на объект. Вот как-то на примитиве хочется все.edogs
29.01.2019 22:19фатальные ошибки (ошибки парсинга) не перехватываются и пр.
Это не совсем верно.
register_shutdown_function вызовется по завершении скрипта даже если была ошибка парсинга.
При этом если Вы ловите буфер через ob_start то внутри register_shutdown_function можете посмотреть и обработать соответственно контент перед выдачей юзеру, там же заодно и ошибку увидеть при display_errors=1.
Кроме того, debug_backtrace поможет Вам определить где она произошла и что к этому привело.
Т.е. продолжить работу скрипта Вы не сможете, но обработать ошибку парсинга на достаточно высоком идейно-художественном уровне можно.AntonShevchuk Автор
30.01.2019 11:31Если использовать PHP7, то всё становится куда как проще:
try { require_once 'file-with-parse-error.php'; } catch (\Throwable $e) { // display error page }
edogs
29.01.2019 21:39+1Статьи про сессии от новичков в написании обучающих статей всегда можно определить по отсутствию в них хоть пары букв про закрытие сессий. По нашему опыту в эти грабли (с закрытие сессии) вляпывается каждый первый, при чем именно благодаря игнорированию в обучающих статьях закрытия сессий.
Допустим Вы открыли сессию, скрипт у Вас работает 10 секунд (не важно почему, так получилось). А пользователь в то время пытается открыть другую страницу Вашего сайта. Что будет? Если Вы не закрыли сессию, то другая страница откроется только после того, как полностью отработает первая. Почему? Потому что Вы не закрыли сессию!
Кажется мелочью? Но не тогда, когда у Вас сайт грузится 0.5 секунды, а юзер открыл 10 вкладок и они у него висят по 1-5 секунд.
Или когда повисла одна вкладка надолго, а юзер пытается посмотреть другие страницы сайта и ждет, ждет, ждет открытия.
А еще на некоторых сайтах всякие цсс стили и некоторые картинки отдаются скриптом, при чем разумеется, со стартом сессии. Как долго будет грузиться это? А если открыто несколько страниц?
А ведь в мануале написано же session_write_close
данные сессии заблокированы для предотвращения одновременной конкурирующей записи, только один скрипт может работать с сессией в любой момент времени
И даже в мануале по session_start об этом упоминается, хотя и не так явно
// Если мы знаем, что в сессии не надо ничего изменять,
// мы можем просто прочитать ее переменные и сразу закрыть,
// чтобы не блокировать файл сессии, который может понадобиться другим сессиямAntonShevchuk Автор
29.01.2019 22:18Спасибо за ценное дополнение, видать я эти грабли так давно прошёл, что уже забыл про них =)
Akdmeh
Статья может быть и хороша для новичков, но ей не место на Хабре, где для большинства это банальные истины.
Каждый PHPшник должен написать фреймворк, создать блог и написать свой учебник по PHP.
peresada
Накинулись на автора. Есть тег — «Для начинающих», есть пометка «Tutorial». По какому принципу вы определяете «место или не место на Хабре»?
Akdmeh
По информативности и качеству слога.
Я видел много намного более качественных tutorial и учебников, в которой эта информация изложена более информативно и более качественным языком.
AntonShevchuk Автор
Вы уж опеределитесь по каким критериям статье не место на хабре ;)
YuraLia
Мне лично статья очень интересна. Хороших свободных материалов по пхп не так уж много.
Поэтому голосую обеими руками «ЗА»!