
Статья больше ориентирована на сетевых инженеров с небольшим опытом в python. В помощь при автоматизации мониторинга и улучшения качества жизни и работы, в отсутствии необходимости руками актуализировать весь парк объектов.

Long story short, we have built a monitoring
Привет! Меня зовут Александр Прохоров, и вместе с командой сетевых инженеров нашего отдела мы занимаемся сетью в #ITX5. Наш отдел развивает сетевую инфраструктуру, мониторинг и автоматизацию сети. Да и все, что связано с передачей данных.
Я бы разбил систему мониторинга на 5 подзадач:
- Загрузка мастер-данных
- Получение информации о состоянии объектов
- Триггеры и оповещения
- Составление отчетности
- Визуализация
В этой статье хотели бы поделиться, как делали интеграцию мониторинга с мастер-данными в нашей компании.
У нас 14 000 торговых объектов, и первая задача, которую мы решали — это определение недоступных объектов, их количество и географическое распределение.
Мониторинг делали на Zabbix. В двух словах почему — повезло и legacy. Остальное:
Когда я пришел работать в компанию в 2013 году, у нас не было мониторинга сети, хотя сеть даже на тот момент была большой, порядка 4000 объектов. О массовых (и не очень) падениях мы узнавали чаще всего от лавинообразного поступления заявок, пользователей или от других отделов.

Первым был установлен Zabbix 1.8, как набирающий обороты (модный, современный, молодежный) продукт, легкий и доступный к установке open source с большим сообществом. Нам просто повезло с выбором.
Ресурсов для установки не было, никто и не запрашивал. Было непонятно, будет ли это вообще работать, опыта внедрения ни у кого не было. Но нам было нужно, и мы установили его на компьютер «под стол». Уровень резервирования — ИБП.
Основной вопрос после установки — как влить все объекты (4к!) в мониторинг, и при этом успевать делать заявки, которые уже висят в Remedy. Zabbix уже поддерживал импорт/экспорт xml с данными по узлам сети. Количество объектов большое, создавать отдельную группу под объект смысла не было(да и не появилось), и было решено вгружать в качестве узла сети роутер объекта. Больше из сетевого оборудования ничего не управлялось (уже управляется).
Был сделан парсинг нашего файла с хостами сети (IPAM в excel), он и переформатирован в xml, который «Заббикс» согласен переварить. Не с первого раза, но все хосты были вгружены, актуализацию проводили раз в три месяца, удаляя закрывшиеся объекты и добавляя новые. Со временем получилось так, что Zabbix стал главным и единственным источником информации для нас и горячей линии по доступности объектов и, главное, по массовым падениям. Это позволило горячей линии узнавать о массовых авариях даже ночью, и будить инженеров звонками (к слову, когда никто об этом не знал, жить было проще). Не всегда ночные отключения питания в офисе позволяли ИБП достойно поддерживать мониторинг нашей сети. В какой-то момент мы стали уже делать бекапы. Т.к. мониторинг работал нестабильно и с перебоями, в компании приняли решение организовать группу, занимающуюся только этой задачей. Очень скоро она занялась внедрением централизованного Zabbix, который проверяет не только сеть.
Наш старенький Zabbix продолжал жить под столом. После добавления определенного количества item’ов стала немного тормозить база, web, очередь и задержка опроса вырастала, так что вскоре пришлось обзавестись еще двумя компьютерами в качестве proxy и поставить их все в кроссовую, чтобы уж настоящее резервирование (да и место под столом закончилось). Жизнь в нем поддерживалась, чтобы быстро добавлять какой-то кастомный параметр в мониторинг и наблюдать за ним. В остальном мы переехали на централизованный.
Централизованный мониторинг занимался всем IT-оборудованием – роутерами, серверами, кассами, терминалами. Спустя время он оброс огромным количеством item'ов. Для доступа к бесценной информации о доступности необходимо было слегка подождать, возможно, даже выпить кофе. К тому же у нас появлялось все больше требований к более специфичному и кастомному мониторингу сети. Имея на тот момент некоторый опыт по работе с системой, мы решили сделать старое внедрение с нуля, но уже правильно, — под названием zabbix.noc.x5.ru Он разместился в ЦОДе с реализацией необходимых нам функций by ourselves. Об этом то внедрении и основное тело статьи.
Версия Zabbix – 3.0 LTS. Обновляемся только в рамках LTS версий.
Конфигурация – 4 виртуальных машины: Server+Database, Proxy, Proxy, Web
По ресурсам старались следовать рекомендациям на zabbix.com для большого и очень большого внедрения.
Первая проблема, которая перед нами встала – это автоматическое добавление узлов сети в мониторинг. Штатный дискаверинг отпал сразу. Наш диапазон сетей находится на всех просторах супернета 10/8. Очень много адресов приходилось бы опрашивать и автоматическое обнаружение занимало бы много ресурсов системы, но не решало бы задачи добавления нетехнической информации об объекте.

Как добавляли объекты
Решением стало использование внешних скриптов для добавления объектов. Мастер-данные по торговым объектам нашли в используемом в компании SAP'е. Синхронный доступ к web-service для выгрузки данных напрямую из SAP не вышел, запрос по всем объектам выполнялся довольно долго. Сделали асинхронный вызов. Ровно в полночь полная выгрузка из SAP складывается на ftp в виде XML, а в течение дня на него попадают XML’ки с diff'ами от последних версий.
Для загрузки данных в Zabbix использовался Zabbix API, а взаимодействовали с ним из Python.
На первом этапе был определен набор данных, который необходим нам для создания объекта. Все полученные признаки используем для правильной классификации объекта в системе или для дальнейшего удобства. К таким признакам относятся:
- IP Address – самое главное поле, для создания интерфейса мониторинга
- SAP ID – у нас уникальный идентификатор объекта
- Status – открыт/закрыт
- Name – название или номер объекта, часто используется пользователями при обращении
- Location – физический адрес
- Phone – контактный телефон
- Groups – этот набор групп формируем исходя из типа и расположения объекта

Модуль sap-sync.py
<?xml version="1.0" encoding="ISO-8859-1"?>
<werks>
<WERKS>1234</WERKS>
<NAME1>4321-Пятерочка</NAME1>
<PLANT_IP>192.168.1.50</PLANT_IP>
<REGION>31</REGION>
<PSTLZ>308580</PSTLZ>
<CITY1>с.Мониторинговое</CITY1>
<CITY2>Москвоская обл.</CITY2>
<STREET>Ленина ул.</STREET>
<HOUSE_NUM1>1</HOUSE_NUM1>
<TEL_NUMBER>(999)777-77-77</TEL_NUMBER>
<BRANCH>CH</BRANCH>
<REGION>CH_MSK</REGION>
<REGION_NAME>Регион Центральный</REGION_NAME>
<FORMAT>CH_MSK_D</FORMAT>
<STATUS>Объект открыт</STATUS>
</werks>
#!/usr/bin/python3
import sys, os, getopt, ipaddress
from datetime import datetime as dt
from zabbix.api import ZabbixAPI
import xml.etree.cElementTree as et
from report import report
import existhost
def ping(ip):
if os.system('ping -c 2 -W 1 %s > /dev/null'%ip) == 0:
return True
else:
return False
def main(argv):
global opath
try:
opts, args = getopt.getopt(argv,"hp:",["path="])
except getopt.GetoptError:
print('sync-sap-chg.py -p <path>')
sys.exit(2)
for opt, arg in opts:
if opt == '-h':
print('sync-sap-chg.py -p <path>')
sys.exit()
elif opt in ("-p", "--path"):
opath = arg
def asynchronization(file, reportdata):
zapi = ZabbixAPI(url='http://z.noc.x5.ru', user='user', password='pwd')
#Константы, которые потом пригодятся
left_kidney = '17855'
right_kidney = '17856'
f_type={'S':'Super','D':'DK','H':'Giper','A':'DK'}
format={'D':'13','S':'14','H':'12','A':'13'}
region={'CT':'21','UR':'19','SZ':'17',~omit~}
try:
#Начинаем разбор XML
tree = et.ElementTree(file=file)
root = tree.getroot()
for werks in root.iter('werks'):
#Создаем структуру словаря для объекта Zabbix
interfaces=[{
'main':'1',
'type':'2',
'useip':'1',
'port':'161'
}]
shop={
'inventory':{},
'interfaces':interfaces,
'groups':[],
'templates':[{'templateid':'10194'}],
'inventory_mode':'1'
}
#Данные, которые будем искать в XML
di = {
'WERKS':'',
~omit~,
'STATUS':'Object Opened'
}
#Переводим все в словарь
for item in werks:
di[item.tag] = item.text
#Достаем из SAPID только цифры
if item.tag == 'WERKS':
n_proxy = ''.join(filter(lambda x: x.isdigit(), item.text))
#Находим IP роутера по адресу сервера. Подсеть везде /26
try:
ipaddress.ip_interface('%s/%s'%(di['PLANT_IP'].strip(),26))
ip_chk = True
except:
ip_chk = False
#Дальнейшая обработка, только если IP адрес верный
if (di['PLANT_IP'] != '1.1.1.1') and ip_chk:
#Записываем данные в словарь
if di['FORMAT'][-1] in ['D','A','S','H']:
shop['inventory']['alias']=di['WERKS']
shop['inventory']['name']=di['NAME1']
shop['inventory']['poc_1_phone_a']=di['TEL_NUMBER']
shop['inventory']['location']=di['STREET']
#Особенности для каждого формата
if (di['FORMAT'][-1] in ['H']):
shop['host']=f_type[di['FORMAT'][-1]]+di['WERKS']
shop['interfaces'][0]['ip']=str(ipaddress.ip_interface('%s/%s'%(di['PLANT_IP'].strip(),24)).network[1])
#Добавляем ID шаблона мониторинга для объекта
shop['templates'][0]['templateid']='29529'
elif (di['FORMAT'][-1] in ['S']):
~omit~
#For D balance in proxies
if int(n_proxy[-1]) % 2 == 0:
shop['proxy_hostid'] = right_kidney
else:
shop['proxy_hostid'] = left_kidney
#В inventory тоже добавим IP
shop['inventory']['oob_ip']=shop['interfaces'][0]['ip']
#Назначение групп по словарям format и region
shop['groups']=[{'groupid':'9'}]
shop['groups'].append({'groupid':format[di['FORMAT'][-1]]})
shop['groups'].append({'groupid':region[di['FORMAT'][:2]]})
#Проверка статуса магазина
if di['STATUS'] == 'Объект открыт':
shop['status']='0'
else:
shop['status']='1'
#Записать текущую дату
T = dt.date(dt.now()).strftime("%d %B %Y")
shop['inventory']['date_hw_decomm'] = T
#Проверить есть ли такой хост в Zabbix
hostid = existhost.exist(shop['host'])
ip = shop['interfaces'][0]['ip']
#Если новый - создаем!
if hostid == 0 and shop['status'] == '0' and ping(ip):
zapi.host.create(shop)
reportdata['new'].append(di['WERKS'])
#Если уже есть - обновляем!
elif hostid != 0 and di['PLANT_IP'] != '1.1.1.1':
#Указываем какой HOSTID обновляем
shop['hostid']=hostid
#При обновлении нужно отрезать интерфейсы
shop.pop('interfaces')
zapi.host.update(shop)
reportdata['update'].append(di['WERKS'])
#Переместить обработанный файл в архив
os.system('mv %s /mnt/ftp/old_data/'%(file))
except:
reportdata['error'].append(di['WERKS'])
report('Ошибка с файлом %s. Объект с ошибкой:%s'%(file, str(reportdata['error'])), 'SAP Sync Failed!')
sys.exit()
def checking(path):
files = os.listdir(path)
files.sort()
reportdata ={'new':[], 'update':[], 'error':[]}
for file in files:
asynchronization(path+file, reportdata)
if files != []:
report('Файлы %s успешно синхронизированы! \n Добавлено %s объектов. \n Их sap:\n %s. \n Обновлено %s объектов. \n Их sap:\n %s'%(str(files), len(reportdata['new']), str(reportdata['new']), len(reportdata['update']), str(reportdata['update'])), 'SAP Sync Succeed!')
if __name__ == "__main__":
main(sys.argv[1:])
checking(opath)
Основное назначение этого модуля — парсинг XML и перевод в JSON для API Zabbix. Очень удобно в этом случае использовать словари Python, т.к. не нужно их дополнительно форматировать, — с использованием модуля zabbix.api можно просто скормить ему словарь с правильной структурой. JSON со структурой выглядит так:
{
'host': 'Hostname'
'groups': [...]
'interfaces': [{},{},{}]
'inventory': {}
'templates': [{},{},{}]
'inventory_mode': '1'
'proxy_hostid': 'INT'
'status': '0'
}
[] - массив
{} - словарь
У нас в поле с IP- адресом в SAP хранится адрес сервера, а не маршрутизатора, но с помощью модуля ipaddress считаем первый адрес подсети, который в нашем случае всегда роутер.
str(ipaddress.ip_interface('%s/%s'%(di['PLANT_IP'].strip(),24)).network[1])
Дату последнего успешного обновления записываем в Inventory, в спорных ситуациях помогает понять, насколько актуальна информация в системе.
#Записать текущую дату
T = dt.date(dt.now()).strftime("%d %B %Y")
shop['inventory']['date_hw_decomm'] = T
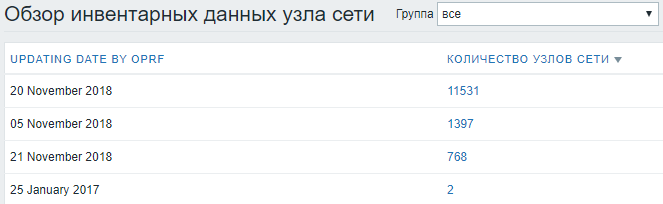
Потом в инвентарных данных очень удобно смотреть статистику по дате обновления:
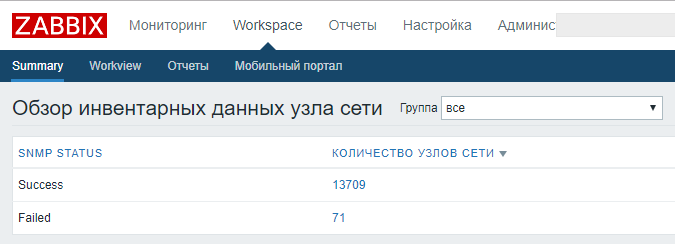
Самое главное поле – STATUS, «открыт» – добавляется и начинает мониториться, любой другой статус — деактивирует узел сети. Объекты не удаляем, чтобы сохранить исторические данные и статистику.
После тестов пришлось дописать функцию пинга, чтобы перед первичным добавлением проверять доступен ли хост, т.к. на практике стали попадаться статусы «Открыт», которые не совсем еще открыты, но уже почти.
def ping(ip):
if os.system('ping -c 2 -W 1 %s > /dev/null'%ip) == 0:
return True
else:
return False
Ранее в Zabbix API была функция host.exist, но в новых версиях ее совместили с host.get. Если узел существует, то запрос возвращает hostid в базе zabbix’а. Если не найден — возвращает 0. Для проверки теперь пришлось дописать existhost, но по факту это host.get.
#!/usr/bin/python3
import sys, getopt
from zabbix.api import ZabbixAPI
def main(argv):
global aname
try:
opts, args = getopt.getopt(argv,"hn:",["name="])
except getopt.GetoptError:
print('existhost.py -n <name>')
sys.exit(2)
for opt, arg in opts:
if opt == '-h':
print('existhost.py -n <name>')
sys.exit()
elif opt in ("-n", "--name"):
aname = arg
def exist(name):
zapi = ZabbixAPI(url='http://z.noc.x5.ru/', user='user', password='pwd')
hostget = zapi.host.get(search={'name':'%s'%name}, output='hostid')
if hostget == []:
return 0
else:
return int(hostget[0]['hostid'])
if __name__ == "__main__":
main(sys.argv[1:])
print(exist(aname))
Напоследок собираем информацию о проведенной работе, добавляем в логи, репорты и перемещаем обработанный файл в хранилище в OLD.
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import smtplib, sys
from email.mime.text import MIMEText
def report(message, subject):
me = 'zbx-scripts@x5.ru'
you = 'mail@x5.ru'
smtp_server = 'smtp.ru'
msg = MIMEText(message)
msg['Subject'] = subject
msg['From'] = me
msg['To'] = you
s = smtplib.SMTP(smtp_server)
s.sendmail(me, [you], msg.as_string())
s.quit()
if __name__ == '__main__':
report(sys.argv[2], sys.argv[1])
В целом база для мониторинга готова, пускаем скрипт в cron для автозапуска и забываем.

Как заполняли inventory
Мы уже не мы, мы — сетевики.
Второй этап – наполнение объектов данными, которые необходимы инженерам для работы. Необходимо видеть все данные для решения инцидента в одной системе, чтобы не бегать по разным системам, собирая информацию по кусочкам из разных источников. И так как основные технические данные в мониторинге, то остальные мы также втягиваем в мониторинг.
Для сбора и передачи необходимой информации в Zabbix был написан inventory.py, который в большой степени занимается сбором данных по SNMP с оборудования, и в меньшей парсингом Excel-файла.
Напрашивается вопрос — почему бы не использовать встроенные item’ы и заносить их результат в inventory средствами самого Zabbix? Ответа три:
- Недостаточная вложенность действий, т.к. часто необходимо вытянуть значение по SNMP и использовать результат в следующем запросе.
- Запускать один раз в день сбор данных по всем узлам внешним скриптом не нагружает основную деятельность мониторинга и не образуется очередь по item’ам
- Есть данные, которые не собрать по SNMP
Данные по провайдерам, без которых не обойтись инженерам 1-й и 2-й линии, хранятся в excel-файле на общем сетевом диске и актуализируются менеджерами, ведущими договоры по связи. Интеграция с файлом вызывала большие сомнения — парсинг excel, заполняемого вручную, который может поменять структуру, название, расположение и т.д., скорее всего будет постоянно вываливать ошибки. Но из-за отсутствия другого актуального источника таких данных пришлось использовать его. Чтобы как-то обезопасить себя от постоянных правок скрипта, договорились с менеджерами о структуре и корректном заполнении, объяснили, как будет выполняться автоматическая выгрузка и что важно соблюдать текущую структуру. На практике, конечно, возникали ошибки, но мы довольно быстро их отслеживали, ругались, но исправляли.
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import sys, json, pysnmp, ipaddress, xlrd
from datetime import datetime as dt
from pysnmp.entity.rfc3413.oneliner import cmdgen
def snmp(host, operation, *oid):
generator = cmdgen.CommandGenerator()
auth_data = cmdgen.UsmUserData('user', 'pwd', 'hash')
transport = cmdgen.UdpTransportTarget((host, 161))
getAtt = getattr(generator, '%sCmd'%operation)
rst = (errorIndication, errorStatus, errorIndex, varBinds) = getAtt(auth_data, transport, *oid)
if not errorIndication is None or errorStatus is True:
return "Error: %s %s %s %s" % rst
else:
if operation=='get':
return varBinds
elif operation=='next':
result=[]
for var in varBinds:
result.append(var)
return result
def xlsdata(file, sap):
rb = xlrd.open_workbook(file)
sheet = rb.sheet_by_index(0)
base = {}
for i in range(0, sheet.nrows-1):
sapnum = str(round(sheet.cell(i,4).value)) if isinstance(sheet.cell(i,4).value,float) else sheet.cell(i,4).value
name = str(round(sheet.cell(i,8).value)) if isinstance(sheet.cell(i,8).value,float) else sheet.cell(i,8).value
if sap.upper() == sapnum.upper():
base = {
'type' : (sheet.cell(i,2).value),
'serialno_a' : (sheet.cell(i,13).value),
'serialno_b' : (sheet.cell(i,20).value),
'tag' : ('2') if sheet.cell(i, 20).value != '' else ('1'),
'macaddress_a' : (sheet.cell(i, 15).value),
'macaddress_b' : (sheet.cell(i, 22).value)
}
base['date_hw_purchase'] = dt.date(dt.now()).strftime("%d %B %Y")
return (base)
def inventory(host, sap):
BGPASBASE={}
for line in open('/path/a.prokhorov/integration/BGP-AS-BASE.cfg'):
if ':' in line:
line = line.split(':')
BGPASBASE[line[0]]='%s(%s)'%(line[1].rstrip(), line[0])
### Get Data from Operator
shop = xlsdata('/mnt/oprf/providers_base.xlsx', sap)
shop['date_hw_expiry'] = 'Failed'
### Get SNMP data
shop['host_router'] = 'None'
shop['host_netmask'] = 'None'
shop['host_networks'] = 'None'
try:
### Get Networks from router
networks = ''
for ip,mask in snmp(host, 'next', 'iso.3.6.1.2.1.4.20.1.1', 'iso.3.6.1.2.1.4.20.1.3'):
networks = networks+str(ipaddress.ip_interface(u'%s/%s'%(ip[1].prettyPrint(), mask[1].prettyPrint())))+'\n'
shop['host_networks']=networks
### Get BGP information
bgppeers, ispnames = '',''
for peer,asbgp in snmp(host, 'next', 'iso.3.6.1.2.1.15.3.1.7', 'iso.3.6.1.2.1.15.3.1.9'):
asbgp = asbgp[1].prettyPrint()
bgppeers = bgppeers+peer[1].prettyPrint()+'\n'
ispnames = ispnames+(BGPASBASE.get(asbgp) if BGPASBASE.get(asbgp)!=None else asbgp)+'\n'
shop['host_router'] = bgppeers.strip()[:38]
shop['host_netmask'] = ispnames.strip()[:38]
### Get Vendor name and Model type
hardware = snmp(host, 'get', 'iso.3.6.1.2.1.47.1.1.1.1.13.1', 'iso.3.6.1.2.1.47.1.1.1.1.10.1', 'iso.3.6.1.2.1.47.1.1.1.1.12.1', 'iso.3.6.1.2.1.1.1.0', 'iso.3.6.1.2.1.47.1.1.1.1.7.1')
if str(hardware[0][1]) == '0235A325':
shop['model'] = hardware[4][1].prettyPrint()
else:
shop['model'] = hardware[0][1].prettyPrint()
shop['os_short'] = hardware[1][1].prettyPrint()
shop['vendor'] = hardware[2][1].prettyPrint()
version = hardware[3][1].prettyPrint()
os = version.split('\n')[0]
shop['os_full'] = version[:250]
shop['os'] = ''.join(os.split(',')[:2])[:60]
### Make indicators
shop['date_hw_expiry'] = 'Success'
shop['date_hw_install'] = dt.date(dt.now()).strftime("%d %B %Y")
except:
shop.pop('host_router')
shop.pop('host_netmask')
shop.pop('host_networks')
return shop
#return json.dumps(dict([('inventory',shop)]), sort_keys=True, indent=4)
if __name__ == "__main__":
print(inventory(sys.argv[1], sys.argv[2]))
3216:Beeline
9002:Retn
2854:Orange
~omit~
8359:MTS
Файл BGP-AS-BASE.cfg представляет собой соответствие номера AS и названия провайдера. Нужен, чтобы определять провайдера, с которым установлено BGP (вдруг в файлике с договорами ошибка). Не использовалась внешняя база, т.к. есть много приватных номеров AS.
В части SNMP:
- запрашиваем у роутера подсети по OID 1.3.6.1.2.1.4.20.1.1 и маски подсетей по OID 1.3.6.1.2.1.4.20.1.3 в одном запросе. Обрабатываем, переводим в вид x.x.x.x/xx и записываем в ячейку host_networks.
- запрашиваем данные о ip адресах BGP пиров, а также их ASN, находим в созданной нами базе имя провайдера по номеру. Записываем их в поля host_router и host_netmask. Важно сразу сделать ограничение на 38 символов, т.к. эти поля не поддерживают большее количество. У нас названия полей в БД не всегда совпадают с данными, которые они хранят, т.к. использовали уже существующие поля в БД Zabbix, чтобы не возится с созданием новых полей в таблице. Правильные названия полей правили в WEB'е, путаницы не было.
- выгружаем данные по вендору, модели и софту оборудования. Парсим, пишем в переменные. Конструкция, связанная с записью модели железки связана с тем, что у Cisco в некоторых моделях название пишется в другой OID(чаще всего для шасси), поэтому пришлось сделать дополнительную проверку данных.
Весь блок связанный с SNMP заключен в try-except, чтобы в случае отсутствия на оборудовании SNMP скрипт не вываливался, и мы хотя бы получили данные из Excel по провайдерам. Для понимания какая часть скрипта выполнилась, а какая нет — успешность SNMP блока записываем в поле date_hw_expiry, плюс записываем дату, когда последний раз смогли снять все данные по SNMP, и дату когда последний раз смогли найти данные в Excel файле.
Все это возвращается в виде готового для Zabbix’а JSON.
Обновление всех инвентарных данных запускается раз в день, выполняя выгрузку всех хостов и запуская inventory.py для каждого объекта.
#!/usr/bin/python3
# -*- coding: utf-8 -*-
from multiprocessing import Pool
import time
from zabbix.api import ZabbixAPI
from inventory import inventory
from report import report
def updating(shop):
try:
shop['inventory'] = inventory(shop['interfaces'][0]['ip'], shop['host'][-4:])
shop.pop('interfaces')
shop['inventory_mode'] = '1'
shop.pop('host')
print (shop['hostid'])
return zapi.host.update(shop)
except:
print(">>>",shop['hostid'])
with open ('/home/local/integration/error.txt', 'a') as err:
err.write(shop['hostid'])
err.write("\n")
if __name__ =='__main__':
t = time.time()
zapi = ZabbixAPI(url='http://z.noc.x5.ru/', user='user', password='pwd')
shopbase = zapi.host.get(output=['host', 'hostid'], groupids= ['12', '13', '14'], monitored="1", selectInterfaces=['ip'])
pool = Pool(processes=10)
p=[0 for x in range(0,len(shopbase))]
for i in range(0, len(shopbase), 10):
print ("Index:", i,"\n",shopbase[i],"\n")
pool.map(updating,shopbase[i:i+10])
pool.close()
pool.join()
print(time.time()-t)
report('Инвентарные данные обновлены в Zabbix.', 'Inventory updating succeed')
Используется multiprocessing (пример взят с бескрайних просторов интернета). Для поиска используем SAP ID, который у нас присутствует в названии хоста. Полученный вывод записываем update’ом в Zabbix.
Summary
Для осуществления всех интеграций, автообновления и актуализации встроенных механизмов API Zabbix более чем достаточно. Основные используемые функции — это host.get, host.create и host.update, которые вместе позволяют полностью управлять созданием и обновлением базы объектов мониторинга. Данные на вход этих функций можно подавать из любых систем и источников, которые есть в наличии.
Основные модули python, которые помогли нам справится с этой задачей: pysnmp, xlrd, zabbix.api, xml, ipaddress, json.
xlrd – парсинг excel.
xml — парсинг XML.
pysnmp – вытаскивание данных по SNMP с оборудования.
Взаимодействие по SNMP легче чем по SSH, как минимум потому что на практике железка более быстро отзывается на SNMP, чем на соединение по SSH, парсинг ответов SNMP практически не нужен, хотя CLI различных вендоров часто сильно разнится друг от друга, а выводы одной и той же команды могут отличаться даже в разных моделях одного вендора.
Основные применяемые OID'ы:
iso.3.6.1.2.1.4.20.1.1 — адреса всех интерфейсов роутера
iso.3.6.1.2.1.4.20.1.3 — маски подсетей всех интерфейсов роутера
iso.3.6.1.2.1.15.3.1.7 — все BGP пиры роутера
iso.3.6.1.2.1.15.3.1.9 — AS всех BGP пиров роутера
iso.3.6.1.2.1.47.1.1.1.1.13.1 — модель
iso.3.6.1.2.1.47.1.1.1.1.10.1 — краткая версия софта
iso.3.6.1.2.1.47.1.1.1.1.12.1 — вендор
iso.3.6.1.2.1.1.1.0 — подробная версия софта
iso.3.6.1.2.1.47.1.1.1.1.7.1 — модель, тип шасси
Dashboard пришлось немного дописать, чтобы разделить проблемы по торговым сетям и не мешать их в кучу. Также добавить несколько полей, например ip, имя провайдера и адрес, чтобы в случае массовой аварии достаточно было copy-paste из браузера в письмо все объекты с проблемой, сразу со всеми необходимыми для провайдера данными.
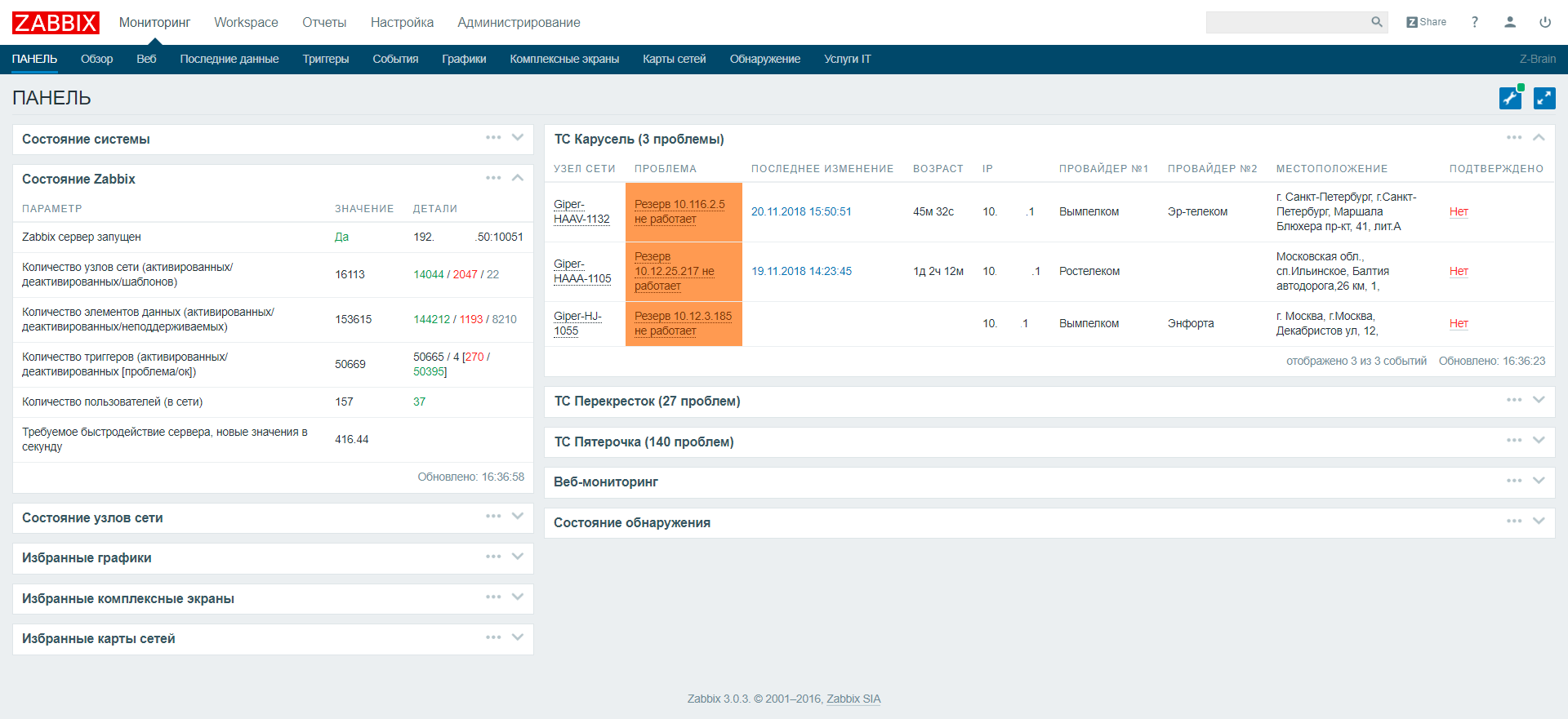
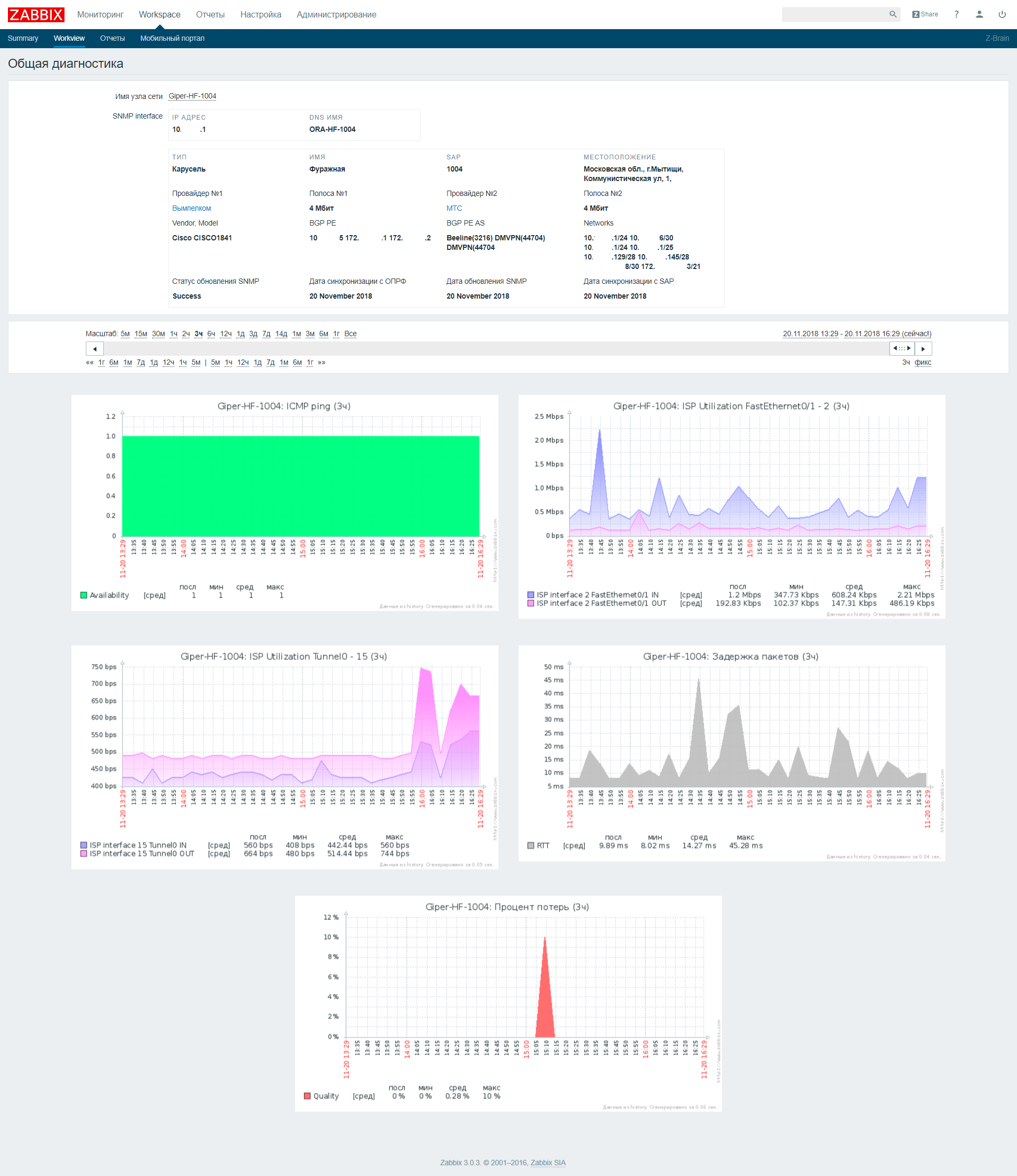
Отдельно был написан «Workview», в котором мы можем найти всю собранную информацию, плюс графики, которые собираются для данного объекта.
Комментарии (17)

iddqda
04.02.2019 12:43Спасибо, прочитал с интересом. Тема мне очень близкая. Тащу примерно такие же задачи, правда в меньшем объеме, но стараюсь по возможности автоматизировать. Для чего использую те же инструменты: zabbix, python, ansible еще.
Отдельное спасибо за рассказ про компьютер под столом, общие папки и IPAM в xls — это прям откровение.
А где же ci/cd и скрам с эджайлом?
Я думал у вас почти Амазон :)
Пара вопросов:
1. Как себя ощущает сервер на виртуалке с 14К хостов и 144K Items?
У меня железный Xeon трудится с 24 ядрами и 32Г памяти, обслуживает около 1К хостов и 60К Items и дышит с трудом
2. «Недостаточная вложенность действий, т.к. часто необходимо вытянуть значение по SNMP и использовать результат в следующем запросе»
LLD неплохо подходит для этого. Там как раз два прохода получается: Discovery rules + Items Prototypes
3. На скринах засветились циски и проприетарный цискин DMVPN. У вас только сеть Заббиксом мониторится? Не пробовали что-нибудь специальное сетевое? LibreNMS например?
4. В чем храните конфиги тех же цисок?pod
04.02.2019 14:15Отвечу по своему опыту с забиксом — 1к хостов, 77к итемов — один железный сервер, бд mysql и сервер забикса на нем, по железу i5 3570, 16gb ram. Все крутится относительно шустро, но после апгрейда ssd на nvme 970pro la вырос до 8-9, причем нагрузка от mysql, хотя очереди не больше 30 сек и данные в веб интерфейс прогружаются шустро. Вообще основной «тормоз» забикса — подсистема хранения. Когда перешли с обычных винтов на ссд — разница просто огромная, дальше просто апгрейдились по мере исчерпания места, производительности хватало.
AboutX Автор
04.02.2019 14:39+1Рад что полезно :)
По поводу стола могу сказать, что это было давно и мы искали подходы. Не все сразу получается сделать идеально, часто находим решение, пробуем и понимаем что нам нужно что-то еще, или что-то другое.
По вопросам:
1. Ощущает неплохо, основное на что мы стараемся делаеть упор — не мониторить все сразу, а создавать item'ы только по необходимым метрикам. Как пример — бывают неполадки связанные с кольцами, но мы не стали мониторить STP на всем оборудовании, т.к. их очень мало и они редко возникают, и проще осуществлять починку уже в real-time зайдя на оборудование и проведя диагностику. Если добавлять такой item на все объекты получится +14к айтемов и +14к триггеров. В общем, немного lean, делаем проверки по топ-проблемам.
У нас сейчас item/trigger 146k/52k. Распеределение item по сервер/прокси_1/прокси_2 — 6k/70k/70k. Машины все виртуальные — 8 CPU, 16 RAM. Но сейчас, чтобы улучшить производительность, растем линейно — добавляем еще 2 прокси, плюс выводим базу на отдельный сервер. Веб всегда жил отдельно. В основном рост связан с увеличением числа объектов, плюс появление новых item, чтобы следить за новыми сервисами.
2. Да, изначально было так, но исходя из бережливого подхода мониторим только необходимые параметры. Тут тоже пример — нам нужно следить только за внешними интерфейсами на маршрутизаторе, которые связаны с провайдером, аплинки в общем. LLD без фильтра выведет все интерфейсы роутера, коих может быть очень много и начет мониторить все. Если использовать LLD с фильтром, то у всех внешних интерфейсов должен быть один признак, например, description, чтобы по результату LLD мы могли отфильтровать. Но у нас description были разные, да и человеческий фактор может привести к ошибке (инженер зашел и поменял, логика сломалась). Чтобы этого избежать мы этим признаком выбрали наличие BGP сессии на интерфейсе. Т.е. находим через snmpwalk всех соседей (на самом деле смотрим ip source для bgp сессий), а потом находим интерфейсы с этими ip и используем их id. По сути тот же LLD, только запускает он внешний скрипт, а не стандартный SNMP.
3. Для магазинов используем для сети только заббикс, выходит дешевле, т.к. опенсорс, и очень гибкий, все что угодно можем доделать. Недавно внедрили Splunk. Для корневой сети используем решение посложнее — CA Spectrum. Очень помогает Grafana. Есть желание попробовать описать эти решения в последующих статьях.
4. Конфиги пока собираем через python-ssh, но сейчас развиваем тему автосбора средствами железок в git. По мере развития постараюсь описать и этот подход, если он будет интересен.
isakov
04.02.2019 16:20+1Почему, почему не PRTG?
AboutX Автор
04.02.2019 17:06+1Похоже на риторический вопрос. Как IOS vs Android. В целом, изначально выбрали заббикс, а развивать дальше лучше существующее, чем постоянно менять коней на переправе. Тем более, возможностей текущего решения хватает и путей развития и масштабирования тоже масса. PRTG к тому же платный.

KanuTaH
04.02.2019 19:12+1Лет этак 14 назад, когда я работал инженером в телекоме областного уровня, я написал свой мониторинг на Tcl :) Типа everything is serious, с многопоточным микроядром, модулями, шаблонами для одинакового оборудования, autodiscovery сущностей и связей между объектами, alarm'ами, сетевым API на основе текстовых команд с поддержкой мгновенных асинхронных уведомлений, и так далее. Где-то тысячи полторы железок это все мониторило (а если считать по item'ам — то десятки тысяч) на железе тех времен (на Solaris/SPARC) без особых проблем. Ностальгия :)

Konstantin_Aksenov
04.02.2019 21:10Спасибо за пост, проделана просто огромная работа…
Но как, так…
«Данные по провайдерам, без которых не обойтись инженерам 1-й и 2-й линии, хранятся в excel-файле на общем сетевом диске и актуализируются менеджерами, ведущими договоры по связи.»
Ребята вы берете инфу о магазинах из SAP, при этом храня данные по провам в excel файле? Что мешает использовать только SAP?
«У нас в поле с IP- адресом в SAP хранится адрес сервера, а не маршрутизатора, но с помощью модуля ipaddress считаем первый адрес подсети, который в нашем случае всегда роутер»
А, как вы поступаете с другими устройствами? Коммутаторами, точками например? Есть ли что-то на dhcp?
Есть ли интеграции с сервисдеск системами? Много ли ложных срабатываний?
Прошу прощения за такое количество вопросов:)
AboutX Автор
04.02.2019 21:21Ну что тут сказать. Legacy, legacy, legacy. Но честности ради, у нас идет сейчас большая работа по созданию единой CMDB которая учитывает и сетевое оборудование, и провайдеров и создает связи между ними, но это отдельная совсем тема. Тут больше о том, что любую боль можно преодолеть и даже автоматизировать ее. Улучшать можно бесконечно.
Другие устройства нас интересуют в меньше степени, поэтому Zabbix для маршрутизаторов. Его задача оперативно отслеживать доступность каналов связи и каналообразующего оборудования. Коммутаторы, как и роутеры, отсылают свои данные в Splunk, это тоже больше отдельная тема. Никто не скажет про коммутатор больше, чем он сам. Но не исключаю, что мы добавим их в zabbix также при наличии необходимости.
На DHCP держим только менеджмент точек доступа. Остальной менеджмент весь статикой.
Интеграция — созданием заявок в Remedy по выбранным событиям или цепочке событий.
Ложные срабатывания это сложный вопрос. Что считать ложным? Ложных не было, бывали случаи когда пропала связь одного Zabbix-Proxy с внешним миром, и он, абсолютно обоснованно, посчитал что все объекты выпали из сети и он забил тревогу. Но это правильное поведение.kbool
05.02.2019 13:17Но честности ради, у нас идет сейчас большая работа по созданию единой CMDB которая учитывает и сетевое оборудование, и провайдеров и создает связи между ними, но это отдельная совсем тема.
Если не секрет, какое решение для CMDB используете?
BigD
Круто! Очень интересен такой опыт больших российских компаний!
AboutX Автор
Спасибо :)