
Всем привет! Представляю вам перевод статьи Analytics Vidhya с обзором событий в области AI / ML в 2018 году и трендов 2019 года. Материал довольно большой, поэтому разделен на 2 части. Надеюсь, что статья заинтересует не только профильных специалистов, но и интересующихся темой AI. Приятного чтения!
Навигация по статьеЧасть 1
— Natural Language Processing (NLP)
— Тренды в NLP на 2019 год
— Компьютерное зрение
— Тренды в машинном зрении на 2019 год
Часть 2
— Инструменты и библиотеки
— Тренды в AutoML на 2019 год
— Reinforcement Learning
— Тренды в Reinforcement Learning на 2019 год
— AI для хороших мальчиков – движение к “этичному” AI
— Этические тренды в AI на 2019 год
Введение
Последние несколько лет для AI энтузиастов и профессионалов в области машинного обучения прошли в погоне за мечтой. Эти технологии перестали быть нишевыми, стали мейнстримом и уже влияют на жизни миллионов людей прямо сейчас. В разных странах были созданы AI министерства [подробнее тут — прим. пер.] и выделены бюджеты чтобы не отставать в этой гонке.
То же самое справедливо и для профессионалов в области data science. Еще пару лет назад вы могли комфортно себя чувствовать, зная пару инструментов и приёмов, но это время прошло. Количество событий, произошедших за последнее время в data science и объем знаний, который требуется, чтобы идти в ногу со временем в этой области, поражают воображение.
Я решил сделать шаг назад и взглянуть на разработки в некоторых ключевых областях в сфере искусственного интеллекта с точки зрения специалистов по data science. Какие прорывы произошли? Что случилось в 2018 и чего ждать в 2019 году? Прочитайте эту статью, чтобы получить ответы!
P.S. Как в любом прогнозе, ниже представлены мои личные выводы, основанные на попытках соединить отдельные фрагменты в целую картину. Если ваша точка зрения отличается от моей, я буду рад узнать ваше мнение о том что ещё может измениться в data science в 2019 году.
Области, которые мы затронем в этой статье:
— Natural Language Proces (NLP)
— Компьютерное зрение
— Инструменты и библиотеки
— Reinforcement Learning
— Проблемы этики в AI
Natural Language Processing (NLP)
Заставлять машины разбирать слова и предложения всегда казалось несбыточной мечтой. В языках очень много нюансов и особенностей, которые иногда сложно понять даже людям, но 2018 год стал по настоящему переломным моментом для NLP.
Мы наблюдали один потрясающий прорыв за другим: ULMFiT, ELMO, OpenAl Transformer, Google BERT, и это не полный список. Успешное применение transfer learning (искусство применять предварительно обученные модели к данным) распахнуло двери применению NLP во множестве задач.
Transfer learning (трансферное обучение) — позволяет адаптировать заранее обученную модель/систему к вашей конкретной задаче с использованием относительно небольшого объема данных.Давайте посмотрим на некоторые из этих ключевых разработок более детально.
ULMFiT
Разработанный Себастьяном Рудером и Джереми Ховардом (fast.ai), ULMFiT был первым фреймворком, который получил transfer learning в этом году. Для непосвященных, аббревиатура ULMFiT означает “Universal Language Model Fine-Tuning”. Джереми и Себастьян по праву добавили слово “универсальный” в ULMFiT — этот фреймворк может применяться практически к любой задаче NLP!
Самое лучше в ULMFiT то, что вам не нужно обучать модели с нуля! Исследователи уже сделали самое сложное за вас — берите и применяйте в своих проектах. ULMFiT превзошел другие методы в шести задачах по классификации текста.
Можете почитать туториал от Пратика Джоши [Pateek Joshi — прим. пер.] о том как начать применять ULMFiT для любой задачи по классификации текста.
ELMo
Угадайте, что означает аббревиатура ELMo? Сокращение от Embeddings from Language Models [вложения из языковых моделей — прим. пер.]. И ELMo привлек внимание ML сообщества сразу после релиза.
ELMo использует языковые модели, чтобы получать вложения для каждого слова, а также учитывает контекст, в котором слово укладывается в предложение или параграф. Контекст — важнейший аспект NLP, в реализации которого большинство разработчиков раньше проваливались. ELMo использует двунаправленные LSTM для создания вложений.
Долгая краткосрочная память (англ. Long short-term memory; LSTM) — разновидность архитектуры рекуррентных нейронных сетей, предложенная в 1997 году Сеппом Хохрайтером и Юргеном Шмидхубером. Как и большинство рекуррентных нейронных сетей, LSTM-сеть является универсальной в том смысле, что при достаточном числе элементов сети она может выполнить любое вычисление, на которое способен обычный компьютер, для чего необходима соответствующая матрица весов, которая может рассматриваться как программа. В отличие от традиционных рекуррентных нейронных сетей, LSTM-сеть хорошо приспособлена к обучению на задачах классификации, обработки и прогнозирования временных рядов в случаях, когда важные события разделены временными лагами с неопределенной продолжительностью и границами.Как и ULMFiT, ELMo качественно повышает производительность в решении большого количества NLP задач, таких, как анализ настроения текста или ответы на вопросы.
— источник. Wikipedia
BERT от Google
Довольно много экспертов отмечают, что выход BERT обозначил начало новой эры в NLP. Следом за ULMFiT и ELMo BERT вырвался вперед, продемонстрировав высокую производительность. Как гласит оригинальный анонс: “BERT — концептуально простой и эмпирически мощный”.
BERT показал выдающиеся результаты в 11 NLP задачах! Посмотрите результаты в тестах SQuAD:
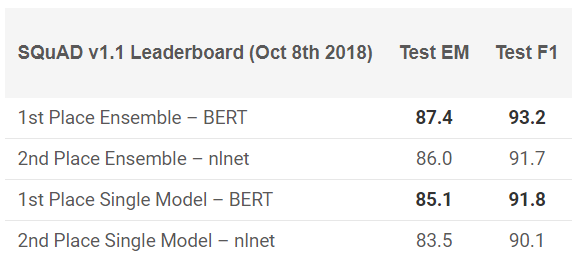
Хотите попробовать? Можете использовать реимплементацию на PyTorch, либо TensorFlow код от Google и попробовать повторить результат на своей машине.
PyText от Facebook
Как же Facebook мог остаться в стороне от этой гонки? Компания предлагает собственный open-source NLP фреймворк, который называется PyText. Как следует из исследования опубликованного Facebook, PyText увеличил точность диалоговых моделей на 10% и сократил время обучения.
PyText фактически стоит за несколькими собственными продуктами Facebook, такими как Messenger. Так что работа с ним добавит неплохой пункт в ваше портфолио и бесценные знания, которые вы, несомненно, получите.
Можете попробовать сами, скачайте код с GitHub.
Google Duplex
Сложно поверить в то что вы ещё не слышали о Google Duplex. Вот демо, которое долгое время мелькало в заголовках:
Поскольку это продукт Google, есть небольшой шанс, что рано или поздно код будет опубликован для всех желающих. Конечно, эта демонстрация поднимает много вопросов: от этических, до вопросов конфиденциальности, но об этом мы поговорим позже. Пока просто наслаждайтесь тем, как далеко мы продвинулись с ML в последние годы.
Тренды в NLP на 2019 год
Кто лучше, чем сам Себастьян Рудер, может дать представление о том, куда NLP движется в 2019 году? Вот его выводы:
- Применение предварительно обученных языковых моделей вложений станет повсеместным; передовые модели без поддержки будут очень редко встречаться.
- Появятся предварительно обученные представления, которые могут кодировать специализированную информацию, которая дополнит вложения языковой модели. Мы сможем групировать различные типы предварительно обученных представлений в зависимости от требований задачи.
- Появится больше работ в области многоязычных приложений и многоязычных моделей. В частности, опираясь на межъязыковые вложения слов, мы увидим появление глубоких предварительно обученных межъязыковых представлений.
Компьютерное зрение

Сегодня компьютерное зрение — самое популярное направление в области deep learning. Похоже, что первые плоды технологии уже получены и мы находимся на стадии активного развития. Независимо от того, изображения это или видео, мы наблюдаем появление множества фреймворков и библиотек, которые с легкостью решают задачи компьютерного зрения.
Вот мой список лучших решений, которые можно было увидеть в этом году.
Выход BigGANs
Йен Гудфеллоу спроектировал GANs в 2014 году, и концепт породил множество разнообразных приложений. Год за годом мы наблюдали как оригинальный концепт дорабатывался для применения на реальных кейсах. Но одна вещь оставалась неизменной до этого года — изображения, сгенерированные компьютером, были слишком легко отличимы. В кадре всегда появлялась некоторая несогласованность, которая делала различие очень очевидным.
В последние месяцы в этом направлении появились сдвиги, а, с созданием BigGAN, такие проблемы могут быть решены раз и навсегда. Посмотрите на изображения сгенерированные этим методом:

Не вооружившись микроскопом, сложно сказать, что не так с этими изображениями. Конечно каждый решит сам для себя, но нет сомнений в том, что GAN изменяет способ восприятия цифровых изображений (и видео).
Для справки: эти модели сначала прошли обучение на наборе данных ImageNet, а затем на JFT-300M, чтобы продемонстрировать, что эти модели хорошо переносятся c одного датасета на другой. Вот ссылка на страницу из рассылки GAN, объясняющая способ визуализации и понимания GAN.
Модель Fast.ai обучилась на ImageNet за 18 минут
Это действительно крутая реализация. Существует распространенное мнение о том, что, для выполнения задач глубокого обучения, вам потребуются терабайты данных и большие вычислительные ресурсы. Это же справедливо для обучения модели с нуля на данных ImageNet. Большинство из нас думали так же, прежде чем несколько человек на fast.ai не смогли доказать всем обратное.
Их модель давала точность в 93% при впечатляющих 18 минутах. Железо, которое они использовали, в деталях описанное в их блоге, состояло из 16 публичных AWS облачных инстансов, каждый с 8 GPU NVIDIA V100. Они построили алгоритм использующий fast.ai и PyTorch библиотеки.
Общая стоимость сборки составила всего 40 долларов! Более подробно Джереми описал их подходы и методы здесь. Это общая победа!
vid2vid от NVIDIA
За последние 5 лет обработка изображений достигла больших успехов, но как насчет видео? Методы перевода из статического фрейма в динамический оказались немного сложнее, чем предполагалось. Можете ли вы взять последовательность кадров из видео и предсказать, что произойдет в следующем кадре? Такие исследования были и раньше, но публикации были в лучшем случае расплывчатым.

NVIDIA решила сделать общедоступным свое решение в начале этого года [2018 год — прим. пер.], что было положительно оценено обществом. Цель vid2vid состоит в том, чтобы вывести функцию отображения из заданного входного видео, чтобы создать выходное видео, которое передаёт содержание входного видео с невероятной точностью.
Вы можете попробовать их имплементацию на PyTorch, забирайте на GitHub тут.
Тренды в машинном зрении на 2019 год
Как я упоминал ранее, в 2019 году мы скорее увидим развитие тенденций 2018 года, а не новые прорывы: самоуправляемые автомобили, алгоритмы распознавания лиц, виртуальная реальность и другое. Можете не согласиться со мной, если у вас другая точка зрения или дополнения, поделитесь ей, что еще нам ожидать в 2019 году?
Вопрос с дронами, ожидающий одобрения политиков и правительства, может наконец получить зеленый свет в Соединенных Штатах (Индия в этом вопросе далеко позади ). Лично мне хотелось бы, чтобы больше исследований проводились в реальных сценариях. Такие конференции, как CVPR и ICML, хорошо освещают последние достижения в этой области, но насколько проекты близки к реальности — не очень понятно.
“Visual question answering” и “visual dialog systems”, могут, наконец, выйти с долгожданным дебютом. Эти системы лишены возможности обобщения, но ожидается, что мы скоро увидим интегрированный мультимодальный подход.
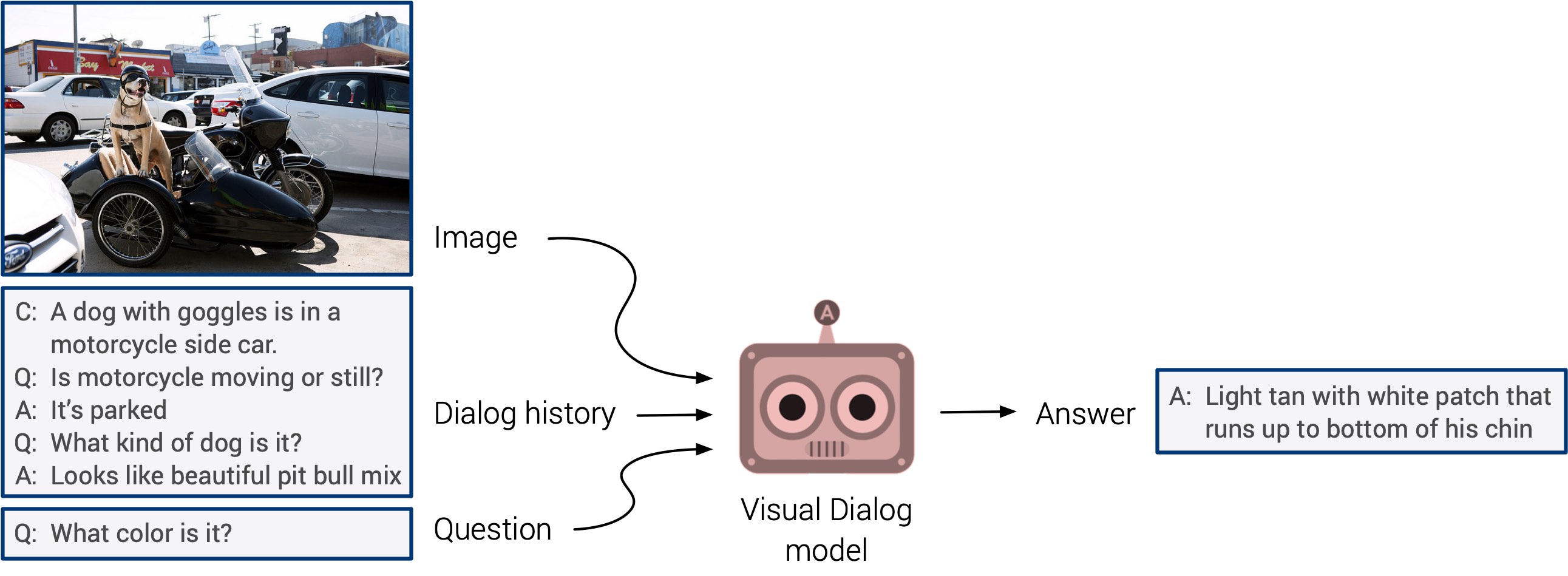
Самообучение вышло на первый план в этом году. Могу поспорить, что в следующем году оно найдет применение в гораздо большем количестве исследований. Это действительно крутое направление: признаки определяются напрямую из вводимых данных, вместо траты времени на маркировку изображений вручную. Будем держать пальцы скрещенными!