

Когда пришли оркестраторы контейнеров, вроде Kubernetes, подход к разработке и деплою приложений изменился кардинально. Появились микрослужбы, а для разработчика логика приложения больше не связана с инфраструктурой: создавай себе приложения и предлагай новые функции.
Kubernetes абстрагируется от физических компьютеров, которыми управляет. Только скажите ему, сколько надо памяти и вычислительной мощности, — и все получите. Ифраструктура? Не, не слыхали.
Управляя образами Docker, Kubernetes и приложения делает переносимыми. Разработав контейнерные приложения с Kubernetes, их можно деплоить хоть куда: в открытое облако, локально или в гибридную среду, — и при этом не менять код.
Мы любим Kubernetes за масштабируемость, переносимость и управляемость, но вот состояния он не хранит. А ведь у нас почти все приложения stateful, то есть им нужно внешнее хранилище.
В Kubernetes очень динамичная архитектура. Контейнеры создаются и уничтожаются в зависимости от нагрузки и указаний разработчиков. Поды и контейнеры самовосстанавливаются и реплицируются. Они, по сути, эфемерны.
Внешнему хранилищу такая изменчивость не по зубам. Оно не подчиняется правилам динамического создания и уничтожения.
Чуть только надо развернуть stateful-приложение в другую инфраструктуру: в другое облако там, локально или в гибридную модель, — как у него возникают проблемы с переносимостью. Внешнее хранилище можно привязать к конкретному облаку.
Вот только в этих хранилищах для облачных приложений сам черт ногу сломит. И поди пойми хитровыдуманные значения и смыслы терминологии хранилищ в Kubernetes. А еще есть собственные хранилища Kubernetes, опенсорс-платформы, управляемые или платные сервисы…
Вот примеры облачных хранилищ от CNCF:

Казалось бы, разверни базу данных в Kubernetes — надо только выбрать подходящее решение, упаковать его в контейнер для работы на локальном диске и развернуть в кластер как очередную рабочую нагрузку. Но у базы данных свои особенности, так что мысля — не айс.
Контейнеры — они же так слеплены, что своё состояние не сохраняют. Потому-то их так легко запускать и останавливать. А раз нечего сохранять и переносить, кластер не возится с операциями чтения и копирования.
С базой данных состояние хранить придется. Если база данных, развернутая на кластер в контейнере, никуда не переносится и не запускается слишком часто, в игру вступает физика хранения данных. В идеале контейнеры, которые используют данные, должны находиться в одном поде с базой данных.
В некоторых случаях базу данных, конечно, можно развернуть в контейнер. В тестовой среде или в задачах, где данных немного, базы данных комфортно живут в кластерах.
Для продакшена обычно нужно внешнее хранилище.
Kubernetes общается с хранилищем через интерфейсы плоскости управления. Они связывают Kubernetes с внешним хранилищем. Привязанные к Kubernetes внешние хранилища называются плагинами томов. С ними можно абстрагировать хранение и переносить хранилища.
Раньше плагины томов создавались, привязывались, компилировались и поставлялись с помощью кодовой базы Kubernetes. Это очень ограничивало разработчиков и требовало дополнительного обслуживания: хочешь добавить новые хранилища — изволь менять кодовую базу Kubernetes.
Теперь деплой плагины томов в кластер — не хочу. И в кодовой базе копаться не надо. Спасибо CSI и Flexvolume.
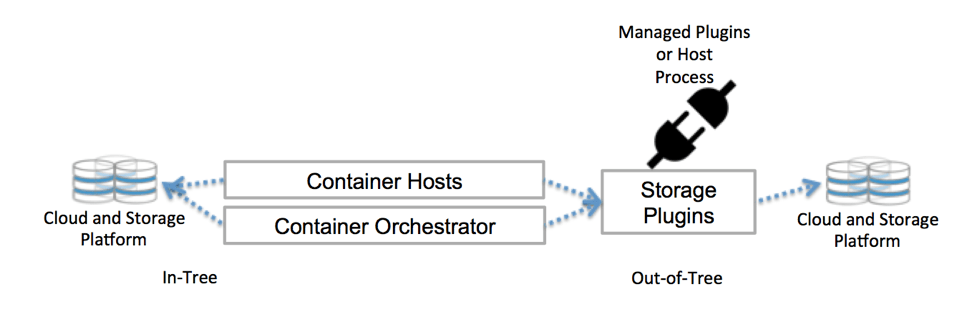
Собственное хранилище Kubernetes
Как Kubernetes решает вопросы хранения? Решений несколько: эфемерные варианты, постоянное хранение в постоянных томах, запросы Persistent Volume Claim, классы хранилищ или StatefulSets. Поди разберись, в общем.
Постоянные тома (Persistent Volumes, PV) — это единицы хранения, подготовленные админом. Они не зависят от подов и их скоротечной жизни.
Persistent Volume Claim (PVC) — это запросы на хранилище, то есть PV. С PVC можно привязать хранилище к ноде, и эта нода будет его использовать.
С хранилищем можно работать статически или динамически.
При статическом подходе админ заранее, до запросов, готовит PV, которые предположительно понадобятся подам, и эти PV вручную привязаны к конкретным подам с помощью явных PVC.
На практике специально определенные PV несовместимы с переносимой структурой Kubernetes — хранилище зависит от среды, вроде AWS EBS или постоянного диска GCE. Для привязки вручную нужно указать на конкретное хранилище в файле YAML.
Статический подход вообще противоречит философии Kubernetes: ЦП и память не выделяются заранее и не привязываются к подам или контейнерам. Они выдаются динамически.
Для динамической подготовки мы используем классы хранилища. Администратору кластера не нужно заранее создавать PV. Он создает несколько профилей хранилища, наподобие шаблонов. Когда разработчик делает запрос PVC, в момент запроса один из этих шаблонов создается и привязывается к поду.

Вот так, в самых общих чертах, Kubernetes работает с внешним хранилищем. Есть много других вариантов.
CSI — Container Storage Interface
Есть такая штука — Container Storage Interface. CSI создан рабочей группой CNCF по хранилищам, которая решила определить стандартный интерфейс хранения контейнеров, чтобы драйверы хранилища работали с любым оркестратором.
Спецификации CSI уже адаптированы для Kubernetes, и есть куча плагинов драйвера для деплоя в кластере Kubernetes. Надо получить доступ к хранилищу через драйвер тома, совместимый с CSI, — используйте тип тома csi в Kubernetes.
С CSI хранилище можно считать еще одной рабочей нагрузкой для контейнеризации и деплоя в кластер Kubernetes.
Если хотите подробностей, послушайте, как Цзе Юй рассказывает о CSI в нашем подкасте.
Опенсорс-проекты
Инструменты и проекты для облачных технологий шустро плодятся, и изрядная доля опенсорс-проектов — что логично — решают одну из главных проблем продакшена: работа с хранилищами в облачной архитектуре.
Самые популярные из них — Ceph и Rook.
Ceph — это динамически управляемый, распределенный кластер хранилища с горизонтальным масштабированием. Ceph дает логическую абстракцию для ресурсов хранилища. У него нет единой точки отказа, он сам собой управляет и работает на базе ПО. Ceph предоставляет интерфейсы для хранения блоков, объектов и файлов одновременно для одного кластера хранилища.
У Ceph очень сложная архитектура с RADOS, librados, RADOSGW, RDB, алгоритмом CRUSH и разными компонентами (мониторы, OSD, MDS). Не будем углубляться в архитектуру, достаточно понимать, что Ceph — это распределенный кластер хранилища, который упрощает масштабируемость, устраняет единую точку отказа без ущерба для производительности и предоставляет единое хранилище с доступом к объектам, блокам и файлам.
Естественно, Ceph адаптирован для облака. Деплоить кластер Ceph можно по-разному, например с помощью Ansible или в кластер Kubernetes через CSI и PVC.
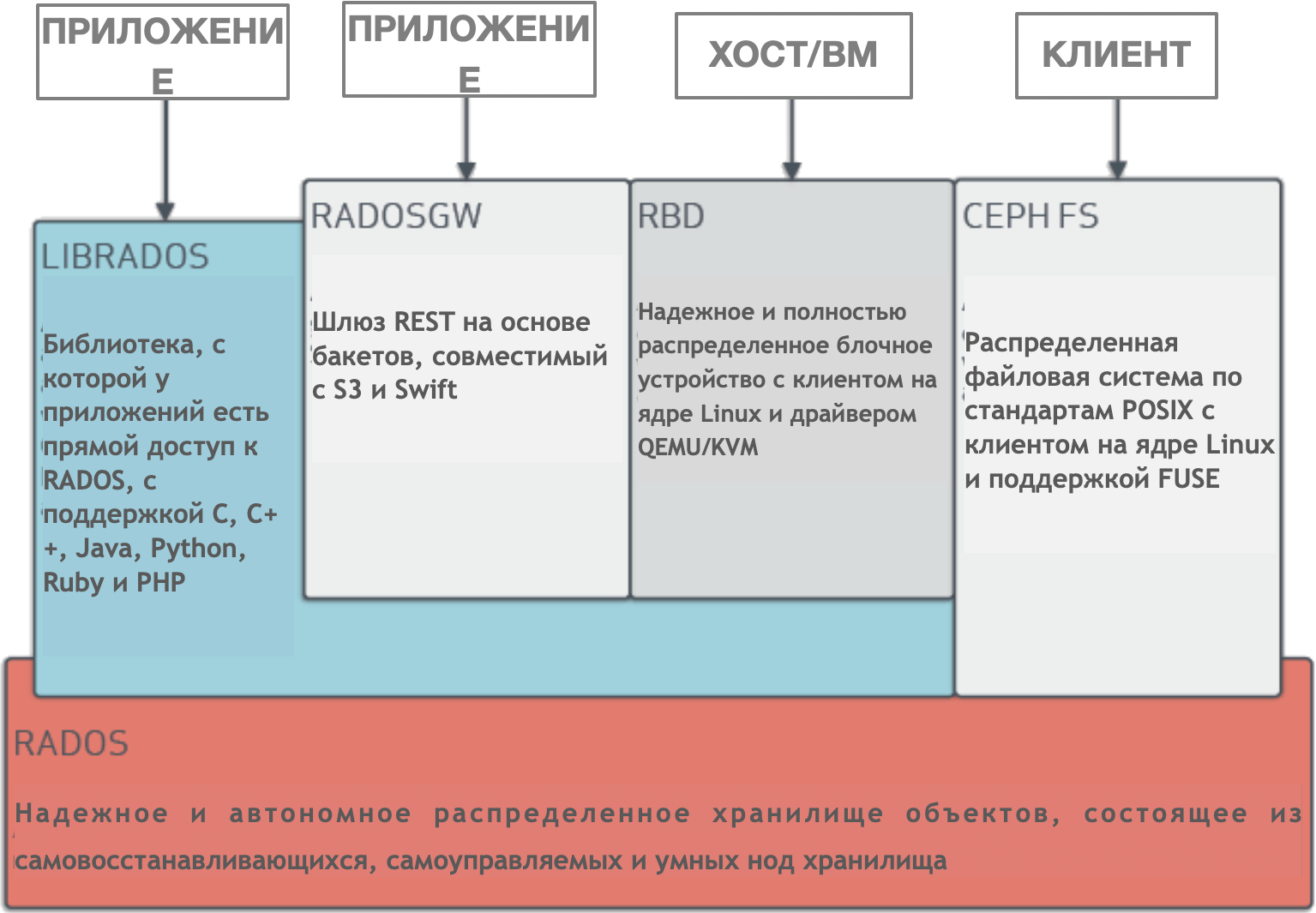
Архитектура Ceph
Rook — это еще один интересный и популярный проект. Он объединяет Kubernetes с его вычислениями и Ceph с его хранилищами в один кластер.
Rook — это оркестратор облачных хранилищ, дополняющий Kubernetes. С ним пакуют Ceph в контейнеры и используют логику управления кластерами для надежной работы Ceph в Kubernetes. Rook автоматизирует деплой, начальную загрузку, настройку, масштабирование, перебалансировку, — в общем все, чем занимается админ кластера.
С Rook кластер Ceph можно деплоить из yaml, как Kubernetes. В этом файле админ в общих чертах описывает, что ему нужно в кластере. Rook запускает кластер и начинает активно мониторить. Это что-то вроде оператора или контролера — он следит, чтобы все требования из yaml выполнялись. Rook работает циклами синхронизации — видит состояние и принимает меры, если есть отклонения.
У него нет своего постоянного состояния и им не надо управлять. Вполне в духе Kubernetes.
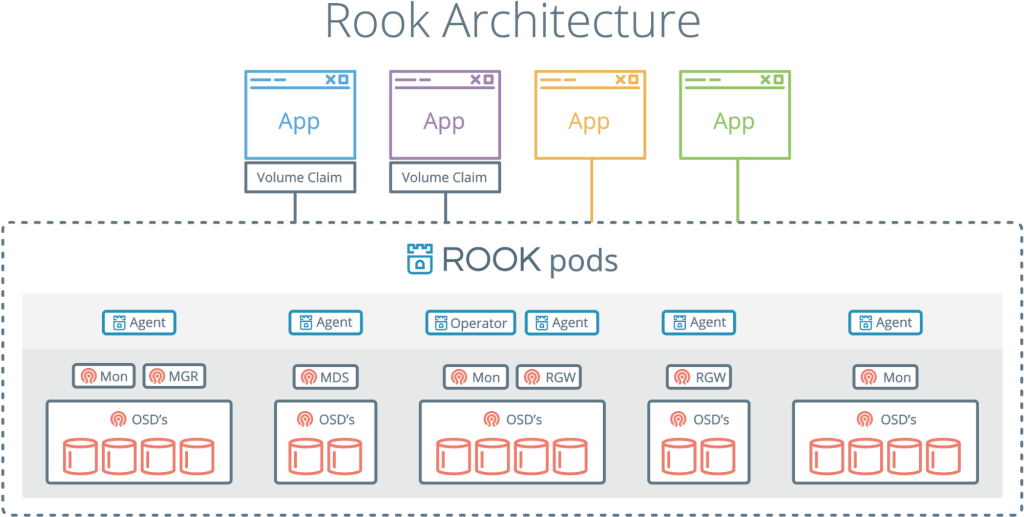
Rook, объединяющий Ceph и Kubernetes, — это одно из самых популярных облачных решений для хранения: 4000 звезд на Github, 16,3 млн загрузок и больше сотни контрибьюторов.
Проект Rook уже приняли в CNCF, а недавно он попал в инкубатор.
Больше о Rook вам расскажет Бассам Табара в нашем эпизоде о хранилищах в Kubernetes.
Если в приложении есть проблема, нужно узнать требования и создать систему или взять нужные инструменты. Это относится и к хранилищу в облачной среде. И хотя проблема не из простых, инструментов и подходов у нас завались. Облачные технологии продолжают развиваться, и нас обязательно ждут новые решения.
Комментарии (5)

yetanotherman
22.02.2019 01:01Ceph OSD как рабочая нагрузка в Kubernates? Идея интересная, но документация по Ceph напрямую не рекомендует так делать — а именно, иметь любые слои абстракции между OSD и диском, включая даже аппаратный рейд. Это как-то учитывается в этом проекте?

past
22.02.2019 09:45Rook не создаёт лишних слоев между ceph и железом. Он шедулит демонсет с OSD сервисами и подает в них блочное устройство с хоста.
navion
Можете описать проблемы «работы с облачными хранилищами», которые решаются поднятием ceph поверх EBS?
past
Не лучший кейс. Ceph не нужен, если есть EBS