

Я хочу рассказать история, как запускали приложение в Openshift. Так же по ходу пьесы рассмотрим утилиты для управления приложением внутри Openshift. Это расшифровка выступления на kubernetes SPB meetup #3..
Цель
Обычно клиенты разворачивают на отдельных серверах, но тут пришла задача, прощупать возможность запуска в openshift и пособирать граблей.
Для начала надо поговорить про наше приложение. Проект с богатой историей. Используется в больших организациях и вероятно каждый из вас косвенно пересекался. Приложение поддерживает множество баз данных, интеграций итд итп.
Пререквизиты

Приложение должно работать в совершенно разных окружениях. Как результат наша документация по установке, весьма, обширная. Но если посмотреть свысока, то ничего сложного:
- Применить схему БД.
- Настроить сервер приложений.
- Установить лицензию.
- Настроить приложение и интеграции с внешними системами.

Но мир жесток, у нас был ряд ограничений:
- Приложение можно собирать только на специально Jenkins, который занимается подписанием. И только там.
- Нет доступа из клиентского Openshift в окружение для разработки.
- По ряду идеологических причин Не было возможности переиспользовать существующие Docker образы для разработки.
- У нас есть ansible playbooks для установки и настройки приложения на серверах.
Ansible-container demo
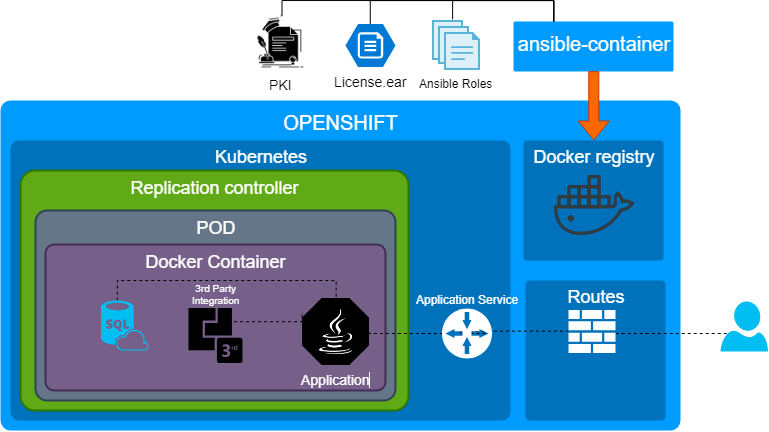
Ansible container это открытое программное обеспечение, которое преследует цель автоматизации сборки контейнеров, деплоя и управления процессом. Как можно догадаться из названия. для сборки контейнеров используется Ansible. У нас уже были написано Ansible роли для инсталляции и развертывания приложения поверх серверов, так что мы решили не изобретать велосипед и переиспользовать их. Не то что бы это идеальный инструмент, но быстрое переиспользование существующих ролей оказалось решающим фактором для демо.
По большому счету, что бы сделать сделать демо мы взяли существующие роли, настраивающие всё и вся, и сделали "монолитный контейнер". Что собрать контейнер не было особых проблем, т.к. у Openshift есть замечательные рекомендации, но отдельно отмечу:
- Роли было необходимо было доработать, т.к. мы используем systemd.
- По умолчанию, в целях безопасности в openshift запрещено использовать некоторые syscall. Как следствие будут нюансы с chroot, sudo. Привет CVE-2019-5736.
- Аналогично из соображений безопасности контейнер запускается из под пользователя со случайным ID, это так же настраиваемое поведение.
Основная идея в этом пункте, что мы сделали демо ооочень быстро.
Multiple containers demo
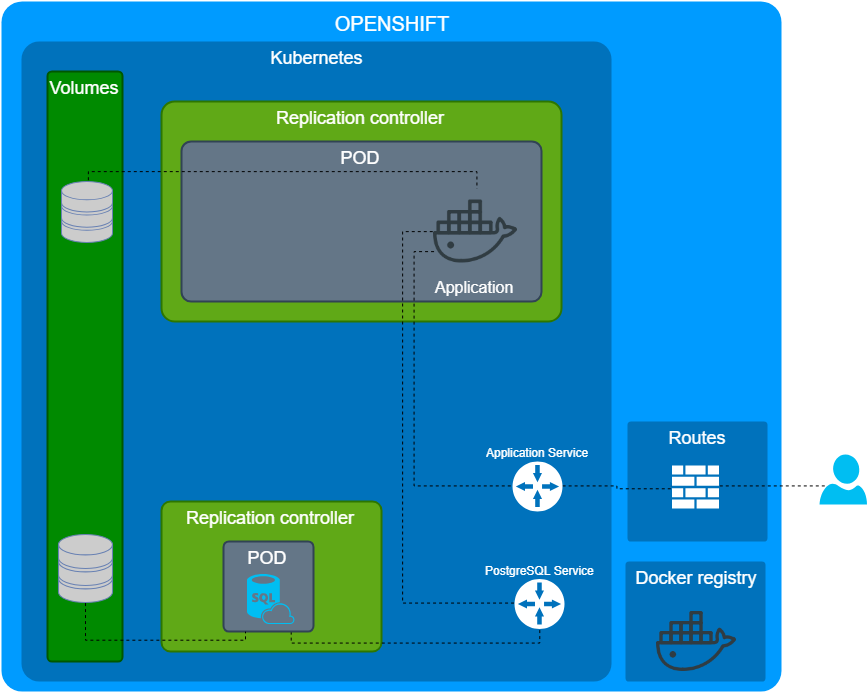
Демо контейнер выполнил свою роль и мы распилили его на отдельные составляющие:
- Наше приложение.
- База данных.
- Внешние сервисы итд...
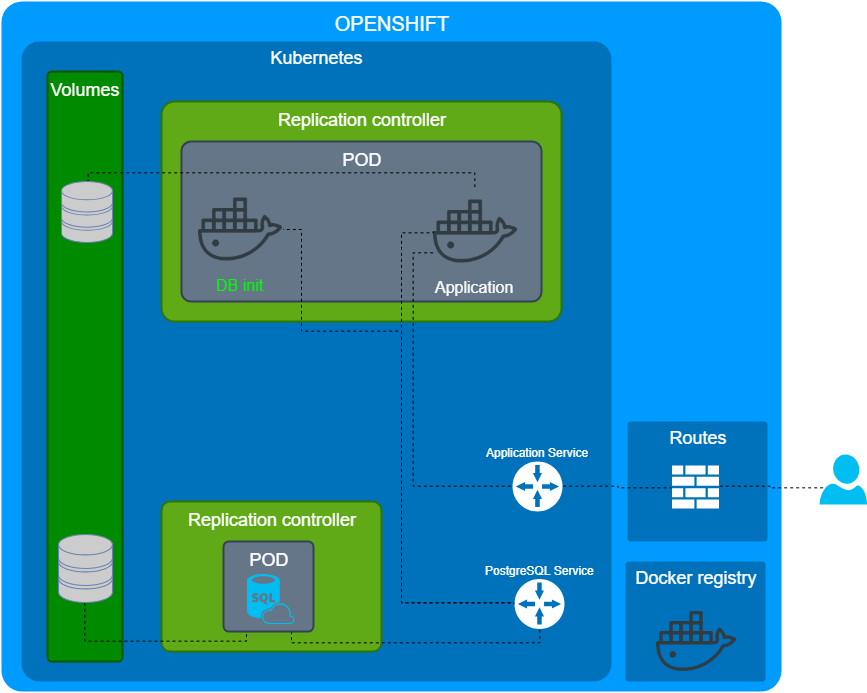
Первое с чем столкнулись, как инициализировать базу данных? Понятно что используем миграции, но когда и как их применять? Тут стоит дать ссылку на замечательную статью описывающие устройство POD: PODs life. По большому счету есть несколько подходом:
- Использовать init-container
- Использовать системы оркестрации, которые определят порядок развертывания сервисов и накатят миграции когда надо.
Мы решили пойти по пути Init-container. Т.е. в POD нашего приложение, до старта нашего приложения, стартует контейнер, который катит миграции. Но как сконфигурировать само приложение и внешние интеграции?
Initialize the application
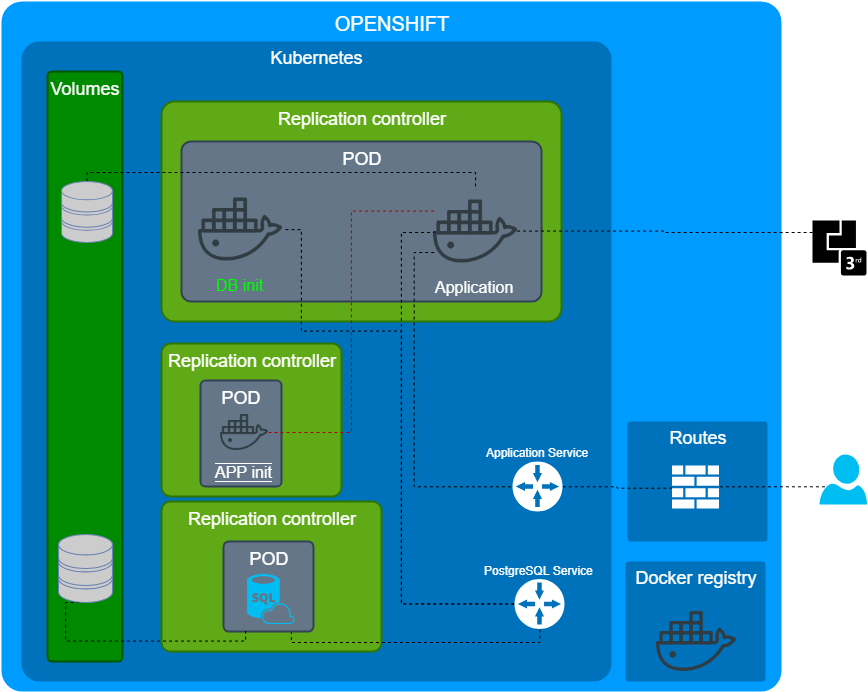
Как я уже упоминал, наше приложение может и должно работать совершенно в разных окружениях, с разными БД и интеграциями. Опять же вопрос, как это все настраивать?
- Использовать системы оркестрации, которые определят порядок развертывания сервисов и применять конфигурацию после старта приложения.
- Передавать через переменные окружения контейнеру как настроиться.
- Использовать start hook.
- Сделать отдельный контейнер, который содержит конфигурацию и применит ее к приложению. Грубо аналог миграция для БД.
Мы выбрали последний подход, т.к. он позволяет делать конфигурацию воспроизводимой и самодостаточной. Только зачем-то изначально сделали этот контейнер в отдельном replication controller с фактором 1.
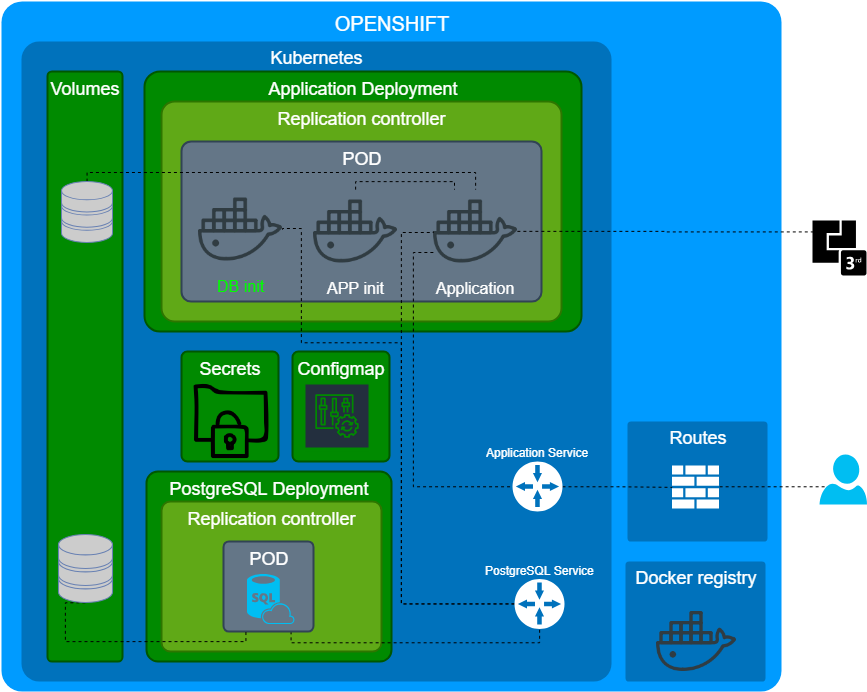
Ок, почитаем документацию снова.
A pod (as in a pod of whales or pea pod) is a group of one or more containers (such as Docker containers), with shared storage/network, and a specification for how to run the containers.
POD это группа контейнеров. В итоге наш под состоял из 3 контейнеров
- Init container для инициализации a PostgreSQL.
- Контейнер с приложение.
- Контейнер с конфигурацией приложения.
Инструментарий
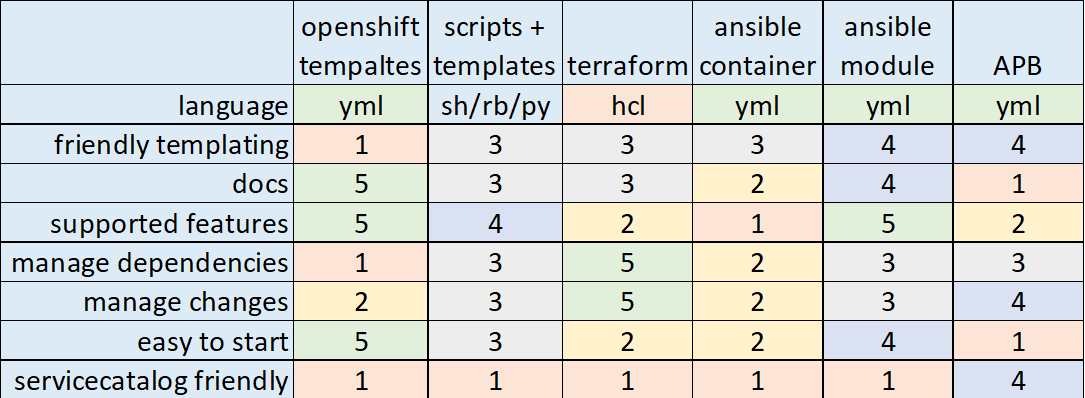
У нас получилась схема как выглядит приложение развернутое. Теперь настало время обсудить инструментарий в природе существует много уже готового, я рассмотрю некоторые из списка ниже и сделаю субъективные выводы.
- Openshift templates
- bash/python/ruby + yml templates
- Terraform k8s provider
- Ansible-container
- Ansible + k8s module
- Ansible Playbook Bundle
- Ansible bender
- operator
- source2image
- kustomize
- helm
- Automation broker
Openshift templates
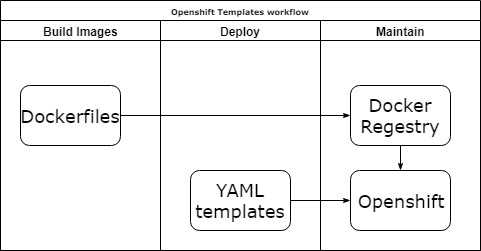
Плюсы:
- Нативно и у них отличная документация.
Минусы:
- Еще один шаблонизатор.
- Длинные и ужасные YAML файлы.
- Если у вас есть зависимости между сервисами и их очередностью старта, то будет сложно.
Scripts and template
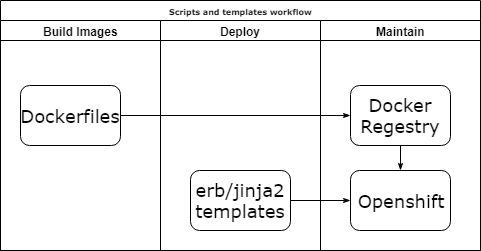
Плюсы:
- Можете использовать отличные инструменты и всю мощь ООП.
Минусы:
- Костыли, которые поддерживать. И не только вам.
Terraform k8s provider
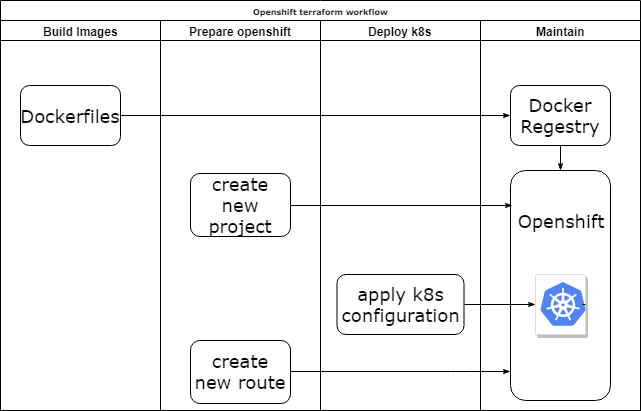
Плюсы:
- Вы не беспокоитесь об очередности создания элементов инфраструктуры.
- Можно переиспользовать код инфраструктуры как модули.
- Можно добавить логику инициализации приложения.
Минусы:
- Нет поддержки Openshift, только k8s.
- Иногда устаревшая дока и модули.
- Еще одна тула в вашей команде.
Ansible-container
Плюсы:
- Make CM, no bash
- Можно переиспользовать код в виде ролей.
- В нашем случае один инструмент для всего.
Минусы:
- Огромные образы, т.к. идут одним слоем.
- Выглядит покинутым и не поддерживаемым. Был заменен Ansible bender.
Ansible k8s module
Плюсы:
- Один плэйбук для описания все инфраструктуры проекта внутри Openshift.
- Переиспользование кода в виде ролей.
- Можно добавить логику инициализации приложения.
Минусы:
- Нет поддержки прокси.
- Вы заботитесь об удаление. Если объект больше не нужен надо описать его удаление.
- Вы сами описываете очередность создания элементов инфраструктуры.
Ansible Playbook Bundle
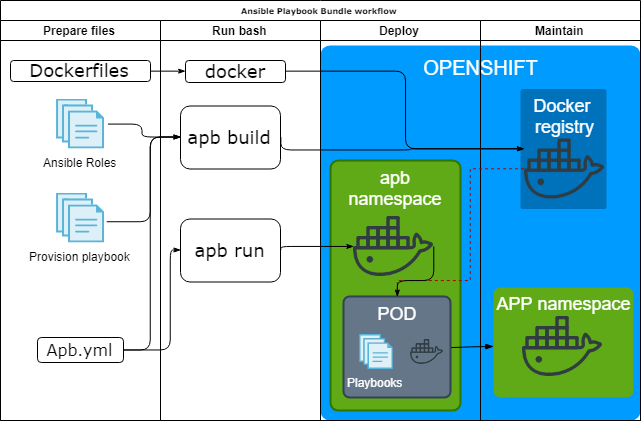
Утилита Ansible Playbook Bundle (APB) предлагает подход: а давайте запакуем ansible роли для развертывания приложения внутри k8s/openshift в контейнер и будем запускать внутри k8s/openshift.
Плюсы:
- Всё свое ношу с собой.
- Тестируемо и воспроизводимо.
- Интеграция с Service catalogue(дружелюбный веб интерфейс для запуска приложений).
Минусы:
- Вам нужны привилегии уровня администратора.
- Документация иногда оставляет желать лучшего.
Result
Не хочется быть последний инстанцией, но поделюсь своими умозаключениями:
- Если не планируете предоставлять приложение как сервис то Ansible k8s module ваш выбор.
- Но если оно вам надо, то надо копать про automation broker и Ansible Playbook Bundle.
P.S.
Комментарии (23)

gecube
27.02.2019 18:20Очень интересный доклад и статья тоже.
Жаль, что не рассмотрены альтернативные решения.
Используем gitlab-ci и хотим использовать openshift. И желательно не как кубернетес на дрожжах. А именно опеншифт. Вот и интересно послушать мнение бывалых.
ultral Автор
28.02.2019 08:47Жаль, что не рассмотрены альтернативные решения.
это какие? что упустил?про сборку:
- Ansible bender — замена ansible container, форсится как замена ansible container
- source2image — грубо ci/cd из коробки из опешифта
про управление
- operator — мб доберусь
- Automation broker -мб доберусь
- kustomize — вмерджен в kubectl, не актуально
- helm — у нас опеншифт, извините

mommys_little_hacker
28.02.2019 08:32На тему шаблонизаторов для манифестов.
Давно и крепко подсел на envsubst из пакета gettext. Все что он делает — заменяет в входном файле переменные окружения на их значения. Очень удобно использовать в связках с современными CICD фреймворками, т. к. они экспортируют все необходимые переменные в окружение. Получается просто один пайп, например:
cat manifest-template.yml | envsubst | kubectl apply -f -
Единственное неудобство — этот пакет надо ставить дополнительно, т. к. в минимальных образах он отсутствует по умолчанию, хотя есть во всех репах дистров (apt, apk, yum).gecube
28.02.2019 08:34Может лучше jinja2 или gomplate? Минус в том, что их тоже нужно устанавливать дополнительно, а плюс в том, что они мощнее, чем envsubst.
ultral Автор
28.02.2019 08:54в моем обзоре это "Scripts and template". с этим жить можно но попахивает велосипедами. без понятно на то необходимости, не стал бы тащить.
Зачем может такое понадобиться? ну предположим
- мы хотим использовать мощь ООП, описать нашу инфраструктуру и потом перенести в реальный мир… ну ок… как потом поддерживать это не понятно… могут же и узнать домашний адрес после увольнения вашего. ^_^
- более реальный случай, у нас есть некая СМДБ, с которой мы выгружаем нашу инфру(описание стэндов каких-нибудь?), генерим шаблон и катим…
можно. но зачем?
mommys_little_hacker
28.02.2019 12:08Они безусловно мощнее, но у них и порог вхождения выше. Также, у них больше зависимостей. К тому же, мне сложно представить, зачем в манифесте нужна настолько сложная логика. Плюс envsubst в том, что он очевиден и понятен всем. Для 99% процентов случаев (подставить тег докер-образа, или какие-то данные разнящиеся на продовых и тестовых контурах) его возможностей достаточно.
gecube
28.02.2019 16:13Мне удобно, что
- указанные шаблонизаторы позволяют выделять повторяющиеся блоки кода (так себе аргумент, но YAML anchor не очень удобны, все-таки jinja понятнее)
- позволяют грузить переменные не только из env, но с stdin, другого файла (json, например) и пр. интересные штуки Это бывает полезно для отладки.
mommys_little_hacker
28.02.2019 17:26Буду честен, у меня такого юз-кейса не было. А еще я знаю только bash :)
Но, возможно, вам имеет смысл подумать о написании полноценных helm чартов. ЕМНИП, они изначально задумывались для подобного.
amarao
С потрясающим интересом прочитал обзор, поскольку прямо сегодня с совещания мы думали о том, как нам «объединять» несколько плейбук из разных репозиториев. К сожалению, каждое из описанных решений слишком openshift/docker-centric (насколько я увидел), и вместо того, чтобы быть инструментом, каждый из них тащит в качестве полиси использование больших монстров…
Увы.
ultral Автор
Но создание своего решения, далеко не факт что приведет вас к счастью. Если не секрет к чему склоняетесь?
amarao
Пока что я после нескольких часов обсуждений придумал терминологию и описал проблему яснее. У ансибла нет абстракции выше playbook'и, а хочется. Мы их назвали facilities и будем вендорить. Каждая facility в своём каталоге. Инструментария не нашёл, увы. Вот неотвеченный вопрос на SO по этому поводу: stackoverflow.com/questions/54906261/integration-level-for-anisble-between-roles-and-playbooks
gecube
По-русски, плиз, тезка. Че-то слишком сложно объясняете. Ну, и можно всегда в телеграмме обсудить поднятый вопрос.
p.s. кстати, плюсанул на SO — не знаю, кто там минусанул, но среда там менее токсичная, чем здесь.
ultral Автор
мы для этого используем «мета роли». Это специальный вид ролей, который инклюдает другие роли с параметрами. Мы в них собираем конфигурацию из кирпичиков.
Приведу пример. Пусть есть базовые роли
— install java
— install oracle
— install postgresql
— install wildfly
— install glassfish
Есть мета роль «install app 3.2.1.» установить наше приложение версии 3.2.1. поверх pg и установить такие-то пароли, она, условно инклюдает часть ролей передавая туда параметры при инклюде.
далее мета роль применяем на сервера и радуемся жизни. проблемы начинаются когда это надо множить на несколько серверов… это решается не очень удобно тем, что есть playbook установи приложение версии 1.2.3 и там размазана логика по плэям.
gecube
Есть готовый пример на гитхабе/гитлабе?
ultral Автор
в паблике нет ничего что можно выложить. Сделал псевдо пример https://github.com/ultral/ansible-meta-roles-demo там есть роль ansible-dev можно на неё ориентироваться
amarao
Мета-роли, или роли-врапперы, это хорошо известная вещь. К сожалению, роль может работать только на тех хостах, куда её назначили, то есть роль не может определять список хостов, на которые надо выполнять задачи. И это проблема, если задача «меты» скоординировать несколько ролей на разных серверах.
ultral Автор
да, именно про эту проблему и говорил в комментарии про плэйбуки, что логику по плэям размазываем.
amarao
А дальше проблема: а как переиспользовать чужие плейбуки в проекте? Нет механизма, нет терминологии (нам же надо не только плейбука, но и её роли, а может быть, и её files/templates).
Сейчас я думаю о том, как это вендорить. Терминологию уже придумали (facility) — но как именно её культурно вендорить надо думать.
ultral Автор
добавить новый слой вложености и генерировать плэйбуки на лету?
amarao
Самомодифицирующиеся playbook'и — отличный метод увеличить сложность и снизить вероятность отладки.
ultral Автор
снизить вероятность удачной отладки? или снизить вероятность самого процесса отладки?
amarao
Я пострадал день, пострадал два. Моё текущее решение — git-vendor (гуглябельно). Не очень удобная структура получается, но всё-таки хоть что-то.