
Многим организациям, в особенности финансовым, приходится иметь дело с различным стандартами безопасности — например, с PCI DSS. Такие сертификации требуют шифрования данных. Прозрачное шифрование данных на диске Transparent Data Encryption реализовано во многих промышленных СУБД.
Apache Ignite используется в банках, поэтому, в нём было решено реализовать TDE.
Я расскажу, как мы разработали TDE силами сообщества, публично, через апачевские процессы.
Ниже, текстовая версия доклада:
Я постараюсь рассказать про архитектуру, про сложность разработки, как это реально выглядит в open source.
На данный момент реализована Apache Ignite TDE. Phase 1.
Она включает в себя базовые возможности работы с шифрованными кэшами:
В Phase 2 планируется включить возможность ротации (смены) мастер-ключа.
В Phase 3 возможность ротации кэш-ключей.
Реализовано все по следующей схеме:
В банках и других организациях применяют свои алгоритмы шифрования: ГОСТ и другие. Понятно, что мы предусмотрели возможность подсунуть свой Encryption SPI — ту реализацию шифрования, которая нужна конкретному пользователю.
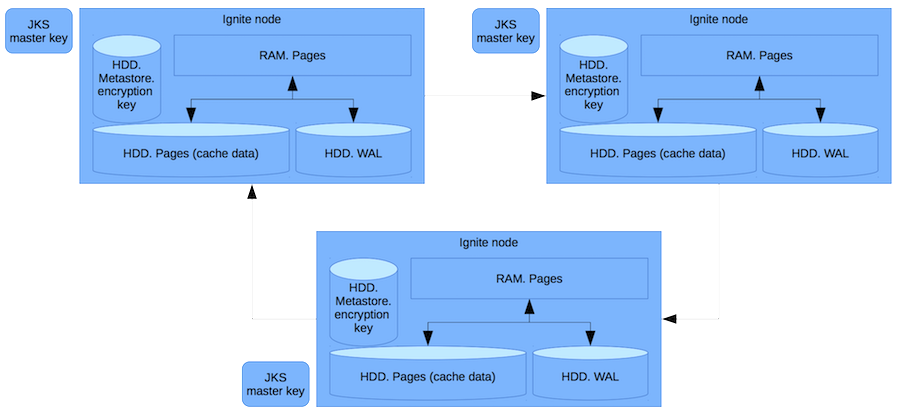
Итак, у нас есть RAM — оперативная память со страницами, содержащими чистые данными. Использование RAM подразумевает, что мы не защищаемся от хакера, который получил root доступ и сдампил всю память. Мы защищаемся от администратора, который берет жесткий диск и продает его на Тушинском рынке (или где сейчас подобные данные продают).
Помимо страниц с кэшем, данные также хранятся в write ahead log, который записывает на диск дельту измененных в транзакции записей. В metastore хранятся ключи шифрования кэшей. И в отдельном файлике — мастер-ключ.
Каждый раз, когда создается ключ для кэша, перед записью или передачей в сеть, мы шифруем этот ключ при помощи мастер-ключа. Чтобы никто не мог получить ключ кэша, получив данные Ignite. Только украв и мастер-ключ и данные, можно получить к ним доступ. Это маловероятно, поскольку для доступа к этим файлам нужны различные права.
Алгоритм действий таков:
Теперь подробнее:
При старте ноды у нас есть callback, который запускает наш EncryptionSPI. Мы, в соотетствии, с параметрами вычитываем мастер-ключ из jks-файла.
Далее, по готовности metastore, достаём сохранённые ключи шифрования. Мастер-ключ при этом у нас уже есть, так что мы можем расшифровать ключи, получить доступ к данным кэша.
Отдельно, есть очень интересный процесс – как нам заджойнить новую ноду в кластер. У нас уже есть распределенная система, состоящая из нескольких нод. Как убедиться, что новая нода сконфигурирована правильно, что это не злоумышленник?
Мы выполняем вот такие действия:
Вторая часть — надстройка над I/O-операциями. В файл партиции пишутся странички. Наша надстройка смотрит, от какого кэша странички, соответствующим образом шифрует их и сохраняет.
То же самое и для WAL. Есть сериализатор, который сериализует обьекты WAL-записей. И если запись для шифрованных кэшей, то мы ее обязаны зашифровать и только после этого сохранять на диск.
Сложности общие для всех более-менее сложных open source проектов:
Сейчас реализована Phase 1. Вы, как разработчик, можете помочь с Phase 2. Задачи предстоят интересные. PCI DSS, как и другие стандарты, требует дополнительных свойств системы шифрования. Наша система должна уметь сменить мастер-ключ. Например, если он был скомпрометирован или просто пришло время в соответствии с политикой безопасности. Сейчас Ignite этого не умеет. Но в следующих релизах мы научим TDE менять мастер-ключ.
То же самое и с возможностью смены cache key без остановки кластера и работы с данными. Если кэш долгоживущий и при этом хранит какие-то данные — финансовые, медицинские — Ignite должен уметь менять ключ шифрования кэша и все перешифровать на лету. Эту задачу мы будем решать в третьей фазе.
Подведем итоги. Они будут актуальны для любого open source. Я участвовал и в Kafka, и в других проектах – везде история одинаковая.
Дальше более очевидные советы, которым бывает не так-то просто следовать:
Спасибо, что прочитали!
Apache Ignite используется в банках, поэтому, в нём было решено реализовать TDE.
Я расскажу, как мы разработали TDE силами сообщества, публично, через апачевские процессы.
Ниже, текстовая версия доклада:
Я постараюсь рассказать про архитектуру, про сложность разработки, как это реально выглядит в open source.
Что сделано и что предстоит?
На данный момент реализована Apache Ignite TDE. Phase 1.
Она включает в себя базовые возможности работы с шифрованными кэшами:
- Управление ключами
- Создание шифрованных кэшей
- Сохранение всех данных кэша на диск в зашифрованном виде
В Phase 2 планируется включить возможность ротации (смены) мастер-ключа.
В Phase 3 возможность ротации кэш-ключей.
Терминология
- Transparent Data Encryption — прозрачное (для пользователя) шифрование данных при сохранении на диск. В случае Ignite — шифрование кэша, потому что Ignite это про кэши.
- Ignite cache — key-value кэш в Apache Ignite. Данные кэша умеют сохраняться на диск
- Pages — страницы данных. В Ignite все данные разбиты по страницам. Страницы записываются на диск, и их нужно шифровать.
- WAL — write ahead log. Там сохраняются все изменения данных в Ignite, все действия, которые мы выполнили для всех кэшей.
- Keystore — стандартный java keystore, который keytool’ом джавовским генерируется. Он работает и сертифицирован везде, мы использовали его.
- Master key — мастер-ключ. С помощью него шифруются ключи для таблиц, ключи шифрования кэша. Хранится в java keystore.
- Cache keys — ключи, с помощью которых реально шифруются данные. Вместе с мастер-ключом получается двухуровневая структура. Мастер-ключ хранится отдельно от кэш ключей и основных данных — в целях безопасности, разделения прав доступа и т.п.
Архитектура
Реализовано все по следующей схеме:
- Все данные кэша шифруются при помощи нового Encryption SPI
- По умолчанию используется AES — промышленный алгоритм шифрования.
- Мастер-ключ хранится в JKS-файле — стандартном java'овском файле для ключей.
В банках и других организациях применяют свои алгоритмы шифрования: ГОСТ и другие. Понятно, что мы предусмотрели возможность подсунуть свой Encryption SPI — ту реализацию шифрования, которая нужна конкретному пользователю.
Схема работы
Итак, у нас есть RAM — оперативная память со страницами, содержащими чистые данными. Использование RAM подразумевает, что мы не защищаемся от хакера, который получил root доступ и сдампил всю память. Мы защищаемся от администратора, который берет жесткий диск и продает его на Тушинском рынке (или где сейчас подобные данные продают).
Помимо страниц с кэшем, данные также хранятся в write ahead log, который записывает на диск дельту измененных в транзакции записей. В metastore хранятся ключи шифрования кэшей. И в отдельном файлике — мастер-ключ.
Каждый раз, когда создается ключ для кэша, перед записью или передачей в сеть, мы шифруем этот ключ при помощи мастер-ключа. Чтобы никто не мог получить ключ кэша, получив данные Ignite. Только украв и мастер-ключ и данные, можно получить к ним доступ. Это маловероятно, поскольку для доступа к этим файлам нужны различные права.
Алгоритм действий таков:
- При старте ноды вычитываем master key из jks.
- При старте ноды вычитываем meta store и расшифровываем cache keys.
- При join ноды в кластер:
– сверяем хэши мастер ключа.
– сверяем ключи для общих кэшей.
– сохраняем ключи для новых кэшей.
- При динамическом создании кэша — генерируем ключ и сохраняем его в meta store.
- При чтении/записи страницы расшифровываем/шифруем её.
- Каждую запись WAL для шифрованного кэша также шифруем.
Теперь подробнее:
При старте ноды у нас есть callback, который запускает наш EncryptionSPI. Мы, в соотетствии, с параметрами вычитываем мастер-ключ из jks-файла.
Далее, по готовности metastore, достаём сохранённые ключи шифрования. Мастер-ключ при этом у нас уже есть, так что мы можем расшифровать ключи, получить доступ к данным кэша.
Отдельно, есть очень интересный процесс – как нам заджойнить новую ноду в кластер. У нас уже есть распределенная система, состоящая из нескольких нод. Как убедиться, что новая нода сконфигурирована правильно, что это не злоумышленник?
Мы выполняем вот такие действия:
- Когда новая нода приходит, она присылает в хэш от мастер-ключа. Мы смотрим, что он совпадает с имеющимся
- Затем сверяем ключи для общих кэшей. От ноды приходит айдишник кэша и зашифрованный кэш-ключ. Мы сверяем их, чтобы убедиться, что все данные на всех нодах у нас зашифрованы одним и тем же ключом. Если это не так, то мы просто не имеем права пускать ноду в кластер — иначе произойдет разъезжание по ключам и по данным.
- Если на новой ноде есть какие-то новые ключи и кэши, сохраняем их, чтобы дальше использовать.
- При динамическом создании кэша предусмотрена функция генерации ключа. Генерируем его, сохраняем в meta store и можем дальше проводить описанные операции.
Вторая часть — надстройка над I/O-операциями. В файл партиции пишутся странички. Наша надстройка смотрит, от какого кэша странички, соответствующим образом шифрует их и сохраняет.
То же самое и для WAL. Есть сериализатор, который сериализует обьекты WAL-записей. И если запись для шифрованных кэшей, то мы ее обязаны зашифровать и только после этого сохранять на диск.
Сложности в разработке
Сложности общие для всех более-менее сложных open source проектов:
- Для начала нужно вообще разобраться в устройстве Ignite. Для чего, что и как там было сделано, как и в какие места прицепить свои обработчики.
- Нужно обеспечить обратную совместимость. Это бывает достаточно сложно, неочевидно. Когда разрабатываешь продукт, который используется другими, нужно учесть, что пользователи хотят обновляться без проблем. Обратная совместимость — это правильно и хорошо. Когда делаешь такую большую доработку, как TDE, то изменяешь правила сохранения на диск, что-то шифруешь. И над обеспечением обратной совместимости приходится поработать.
- Еще один неочевидный момент связан с распределенностью нашей системы. Когда разные клиенты пытаются создать один и тот же кэш, нужно согласовать ключ шифрования, ведь по умолчанию будут сгенерированы два разных. Мы решили эту задачу. Подробней останавливаться не буду — решение заслуживает отдельного поста. Сейчас у нас гарантированно используется один ключ.
- Следующая важная вещь привела к большим доработкам, когда казалось, что всё уже готово (знакомая история?) :). Шифрование имеет overhead. У нас есть init vector — нулевые случайные данные, которые используются в алгоритме AES. Они хранятся в открытом виде, и с их помощью мы увеличиваем энтропию: одни и те же данные при разных сессиях шифрования будут по-разному зашифрованы. Грубо говоря, даже если у нас будет два Ивана Петрова, с одинаковой фамилией, то каждый раз при шифровании мы будем получать разные шифрованные данные. Это уменьшает вероятность взлома.
Шифрование происходит блоками по 16 байт, и если данные не выровнены на 16 байт, то мы добавляем padding info — сколько у нас реально данных зашифровано. На диск нужно писать страницу, кратную 2 Кб. Таковы требования по перфомансу: мы должны использовать буфер диска. Если мы пишем не 2 Кб (не 4 или не 8, в зависимости от буфера диска), то тут же получаем большой перфоманс дроп.
Как мы решили проблему? Пришлось залезть в PageIO, в оперативной памяти и отрезать 16 байт от каждой страницы, которая при записи на диск будет зашифрована. В эти 16 байт мы и записываем init vector.
- Еще одна сложность — ничего не поломать. Это обычное дело, когда ты приходишь и вносишь какие-то изменения. В действительности это не так просто, как кажется.
- В MVP получилось 6 тысяч строк. Сложно ревьювить, да и мало кто хочет этим заниматься — особенно из экспертов, у которых и так времени нет. У нас есть различные части — public API, core-часть, SPI managers, persistent store для страниц, WAL-менеджеры. Изменения в различных подсистемах требуют, чтобы их ревьюили различные люди. И это тоже дополнительные сложности накладывает. Особенно когда ты работаешь в сообществе, где все люди заняты своими задачами. Тем не менее, у нас все получилось.
Что будет в TDE.Phase 2 и 3
Сейчас реализована Phase 1. Вы, как разработчик, можете помочь с Phase 2. Задачи предстоят интересные. PCI DSS, как и другие стандарты, требует дополнительных свойств системы шифрования. Наша система должна уметь сменить мастер-ключ. Например, если он был скомпрометирован или просто пришло время в соответствии с политикой безопасности. Сейчас Ignite этого не умеет. Но в следующих релизах мы научим TDE менять мастер-ключ.
То же самое и с возможностью смены cache key без остановки кластера и работы с данными. Если кэш долгоживущий и при этом хранит какие-то данные — финансовые, медицинские — Ignite должен уметь менять ключ шифрования кэша и все перешифровать на лету. Эту задачу мы будем решать в третьей фазе.
Итого: Как реализовать большую фичу в open source проекте?
Подведем итоги. Они будут актуальны для любого open source. Я участвовал и в Kafka, и в других проектах – везде история одинаковая.
- Начните с маленьких задач. Никогда не беритесь решать супербольшую задачу сразу. Нужно разобраться, что происходит, как происходит, как реализуется. Кто тебе будет помогать. И вообще – с какой стороны к этому проекту подходить.
- Разберитесь в проекте. Обычно все разработчики — по крайней мере, я — приходят и говорят: надо все переписать. До меня были все плохо, а сейчас я перепишу – и все будет хорошо. Желательно с такими заявлениями повременить, разобраться, что конкретно плохо и нужно ли это менять.
- Обсудите, нужны ли доработки. У меня были случаи, когда я приходил с наработками в различные комьюнити — например в Spark. Рассказывал, а комьюнити оказывалось не заинтересовано по каким-то причинам. По-всякому бывает. Тебе эта доработка нужна, а комьюнити говорит: нет, мы не заинтересованы, не будем merge'ить и помогать.
- Сделайте дизайн. Есть open source проекты, в которых это обязательно. Вы не можете начинать кодировать без дизайна, который согласовали комитеры и опытные люди. В Ignite это формально не так, но вообще это важная часть разработки. Нужно сделать описание на грамотном английском или русском языке — в зависимости от проекта. Чтобы текст читался и по нему было понятно, что конкретно вы собираетесь сделать.
- Обсудите public API. Основной аргумент: если будет красивый и понятный public API, который легко использовать – значит, и дизайн правильный. Эти вещи обычно соседствуют друг с другом.
Дальше более очевидные советы, которым бывает не так-то просто следовать:
- Реализуйте фичу ничего не сломав. Сделайте тесты.
- Попросите и дождитесь (это бывает сложнее всего) ревью от нужных ребят, от нужных членов комьюнити.
- Сделайте бенчмарки, узнайте нет ли у вас performance drop. Это особенно важно при доработке каких-то критических подсистем.
- Дождитесь merge, сделайте примеры и документацию.
Спасибо, что прочитали!