

Что вас бесит сильнее всего, когда вы пытаетесь организовать читаемые логи в вашем NodeJS приложении? Лично меня чрезвычайно напрягает отсутствие каких-либо вменяемых зрелых стандартов по созданию trace ID. В этой статье мы поговорим о том, какие есть варианты создания trace ID, разберемся на пальцах как работает continuation-local storage или CLS и призовем на помощь силу Proxy, чтобы завести все это с абсолютно любым логером.
Почему в NodeJS вообще есть проблема с созданием trace ID для каждого запроса?
В давние-давние-давние времена, когда по земле еще ходили мамонты, все-все-все серверы были многопоточными и создавали по новому потоку на запрос. В рамках этой парадигмы создание trace ID — дело тривиальное, т.к. есть такая штука как thread-local storage или TLS, которое позволяет положить в память некие данные, которые доступны любой функции в этом потоке. Можно в начале обработки запроса нагенерить рандомный trace ID, положить его в TLS и потом в любом сервисе его прочитать и что-то с ним сделать. Беда в том, что в NodeJS так не получится.
NodeJS — однопоточный (не совсем, учитывая появление воркеров, но в рамках проблемы с trace ID воркеры роли никакой не играют), так что о TLS можно забыть. Здесь парадигма другая — жонглировать кучей разных коллбеков в рамках одного потока, и как только функция захочет сделать что-то асинхронное, отправить этот асинхронный запрос, а процессорное время отдать другой функции в очереди (если вам интересно как эта штука, гордо именуемая Event Loop работает под капотом, рекомендую эту серию статей к прочтению). Если задуматься о том, как NodeJS понимает какой коллбек когда вызывать, можно предположить, что каждому из них должен соответствовать какой-то ID. Более того в NodeJS даже есть API, который предоставляет доступ к этим ID. Им-то мы и воспользуемся.
В давние-давние времена, когда мамонты уже вымерли, но люди все еще не ведали блага центральной канализации, (NodeJS v0.11.11) у нас был addAsyncListener. На основе него Forrest Norvell создал первую имплементацию continuation-local storage или CLS. Но о том как оно работало тогда, мы сейчас говорить не будем, так как этот API (я про addAsyncLustener) приказал долго жить. Его не стало уже в NodeJS v0.12.
До NodeJS 8 не было никакого официального способа отслеживать очередь асинхронных событий. И, наконец-то, в 8 версии разработчики NodeJS восстановили справедливость и подарили нам async_hooks API. Если вам хочется подробнее разобраться с async_hooks, то рекомендую ознакомиться с этой статьей. На основе async_hooks был сделан рефакторинг предыдущей имплементации CLS. Библиотека получила название cls-hooked.
CLS под капотом
В общих чертах схему работы CLS можно представить следующим образом:
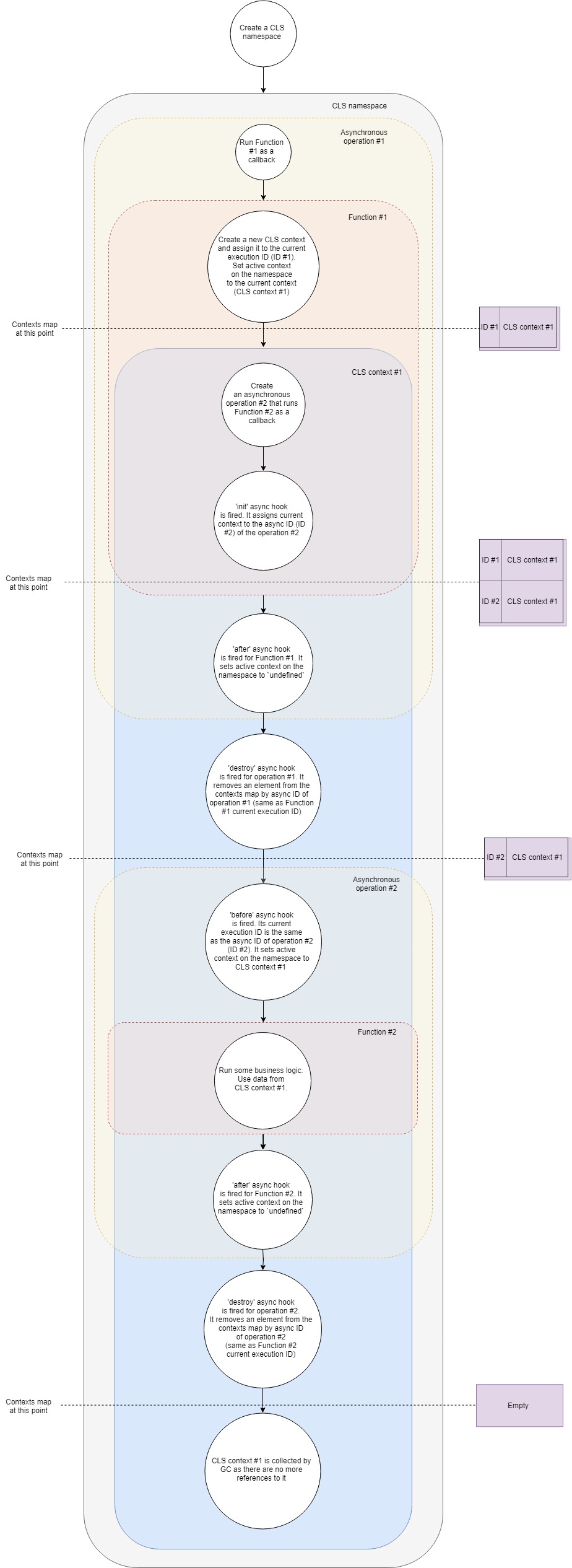
Давайте разберем ее чуть подробнее:
- Предположим, у нас есть типичный Express веб-сервер. Первым делом создадим новый CLS namespace. Один раз и на все время жизни приложения.
- Во-вторых, сделаем middleware, которая будем для каждого запроса создавать свой CLS контекст.
- Когда приходит новый запрос, вызывается эта middleware (Function #1).
- В этой функции создаем новый CLS контекст (как один вариантов, можно использовать Namespace.run). В Namespace.run мы передаем функцию, которая исполнится в скоупе нашего конекста.
- CLS добавляет свежесозданный контекст в Map с контекстами по ключу current execution ID.
- У каждого CLS namespace есть свойство
active. CLS присваивает этому свойству сслыку на наш контекст. - В скоупе контекста мы делаем какой-то асинхронный запрос, скажем, к БД. Драйверу БД передаем коллбек, который будет вызван, когда запрос завершится.
- Срабатывает асинхронный хук init. Он добавляет текущий контекст в Map с контекстами по async ID (ID новой асихронной операции).
- Т.к. наша функция больше не имеет никаких дополнительный инструкций, она завершает выполнение.
- Срабатывает асинхронный хук after для нее. Он присваивает свойству
activeу namespaceundefined(на самом деле не всегда, т.к. у нас может быть несколько вложенный контекстов, но для наиболее простого случая это так). - Срабатывает асинхронный хук destroy для нашей первой асинхронной операции. Он удаляет контекст из Map с контекстами по async ID этой операции (он такой же как current execution ID первого коллбека).
- Завершается запрос в БД и вызывается второй коллбек.
- Срабатывает асинхронный хук before. Его current execution ID такой же как и async ID второй операции (запрос к БД). Свойству
activeу namespace присваивается контекст найденный в Map с контекстами по current execution ID. Это тот самый контекст, который мы создали до этого. - Теперь выполняется сам второй коллбек. Отрабатывает какая-то бизнес логика, пляшут черти, льется водка. Внутри этой мы можем получить любое значение из контекста по ключу. CLS попробует найти данный ключ в текущем контексте или вернет
undefined. - Срабатывает асинхронный хук after для этого коллбека по его завершении. Он присваивает свойству
activeу namespaceundefined. - Срабатывает асинхронный хук destroy для этой операции. Он удаляет контекст из Map с контекстами по async ID этой операции (он такой же как current execution ID второго коллбека).
- Сборщик мусора (GC) освобождает память связанную с объектом контекста, т.к. у нас в приложении больше нет на него ссылок.
Это упрощенное представление того, что происходит под капотом, но оно покрывает основные фазы и шаги. Если у вас есть желание копнуть еще чуть глубже, рекомендую ознакомиться с сорцами. Там всего 500 строк кода.
Создание trace ID
Итак, разобравшись с CLS, попробуем эту штуку заюзать на благо человечества. Создадим middleware, которое для каждого запроса создает свой CLS контекст, создает случайный trace ID и добавляет его в контекст по ключу traceID. Затем внутри офигиллиарда наших контроллеров и сервисов этот trace ID получим.
Для express подобная middleware может выглядеть так:
const cls = require('cls-hooked')
const uuidv4 = require('uuid/v4')
const clsNamespace = cls.createNamespace('app')
const clsMiddleware = (req, res, next) => {
// req и res - это event emitters. Мы хотим иметь доступ к CLS контексту внутри их коллбеков
clsNamespace.bind(req)
clsNamespace.bind(res)
const traceID = uuidv4()
clsNamespace.run(() => {
clsNamespace.set('traceID', traceID)
next()
})
}А в нашем контроллере или сервисе мы можем получить этот traceID буквально одной строчкой кода:
const controller = (req, res, next) => {
const traceID = clsNamespace.get('traceID')
}Правда, без добавления этого trace ID в логи пользы от него, как от снегоуборщика летом.
Давайте запилим простой форматтер для winston, который будет добавлять trace ID автоматом.
const { createLogger, format, transports } = require('winston')
const addTraceId = printf((info) => {
let message = info.message
const traceID = clsNamespace.get('taceID')
if (traceID) {
message = `[TraceID: ${traceID}]: ${message}`
}
return message
})
const logger = createLogger({
format: addTraceId,
transports: [new transports.Console()],
})И если бы все логгеры поддерживали кастомные форматтеры в виде функций (у многих из них есть причины этого не делать), то этой статьи, наверное, и не было бы. Так как бы могли добавить trace ID в логи обожаемого мной pino?
Взываем к Proxy, дабы подружить ЛЮБОЙ логер и CLS
Пару слов о самом Proxy: это такая штука, которая оборачивает наш исходный объект и позволяет переопределять его поведение в определенных ситуациях. В строго определенном ограниченно списке ситуаций (по науке они называются traps). С полным списком можете ознакомиться здесь, нас же интересует только trap get. Он дает нам возможность переопределять возвращаемое значение при обращении к свойству объекта, т.е. если взять объект const a = { prop: 1 } и завернуть его в Proxy, то с помощью trap get мы можем вернуть все, что нам вздумается, при обращении к a.prop.
В случае с pino мысль следующая: мы создаем случайный trace ID для каждого запроса, создаем дочерний инстанс pino, в который передаем этот trace ID и кладем этот дочерний инстанс в CLS. Затем оборачиваем наш исходный логер в Proxy, который будет использовать для логирования этот самый дочерний инстанс, если есть активный контекст и в нем есть дочерний логер, или же использовать исходный логер.
Для такого случая Proxy будет выглядеть следующим образом:
const pino = require('pino')
const logger = pino()
const loggerCls = new Proxy(logger, {
get(target, property, receiver) {
// Если логер в CLS не найдем, использум оригинал
target = clsNamespace.get('loggerCls') || target
return Reflect.get(target, property, receiver)
},
})Наша middleware станет выглядеть следующим образом:
const cls = require('cls-hooked')
const uuidv4 = require('uuid/v4')
const clsMiddleware = (req, res, next) => {
// req и res - это event emitters. Мы хотим иметь доступ к CLS контексту внутри их коллбеков
clsNamespace.bind(req)
clsNamespace.bind(res)
const traceID = uuidv4()
const loggerWithTraceId = logger.child({ traceID })
clsNamespace.run(() => {
clsNamespace.set('loggerCls', loggerWithTraceId)
next()
})
}А использовать логер мы сможем так:
const controller = (req, res, next) => {
loggerCls.info('Long live rocknroll!')
// Выводит
// {"level":30,"time":1551385666046,"msg":"Long live rocknroll!","pid":25,"hostname":"eb6a6c70f5c4","traceID":"9ba393f0-ec8c-4396-8092-b7e4b6f375b5","v":1}
}cls-proxify
На основе вышеизложенной идеи была создана небольшая библиотека cls-proxify. Она из коробки работает с express, koa и fastify. Помимо создания trap для get, она создает и другие traps, чтобы предоставить разработчику больше свободы. Благодаря этому мы можем использовать Proxy для оборачивания функций, классов и многого другого. Здесь есть live demo того, как интегрировать pino и fastify, pino и express.
Надеюсь, вы не потратили время зря, и статья была вам хоть чуточку полезна. Просьба пинать и критиковать. Будем учиться кодить лучше вместе.
Комментарии (12)

bocharovf
04.03.2019 23:01Лично меня чрезвычайно напрягает отсутствие каких-либо вменяемых зрелых стандартов по созданию trace ID
А OpenTracing чем не подошел?
Вот есть OpenTracing для Node.js
А вот Jaeger под ноду.keenondrums Автор
04.03.2019 23:30Я обеими руками за opentracing, но не очень вижу как оно решает проблему создания trace ID автоматом.
serf
05.03.2019 09:04Возможно тупой вопрос. Для веба ведь есть Zone.js позволяющая «работать» с контекстом вызова, это нельзя прикрутить к ноде малой кровью?
mayorovp
05.03.2019 09:11Zone.js подменяет базовые асинхронные функции, такие как setTimeout. На ноде же их попросту слишком много.
А ещё Zone.js не умеет работать с функциями, объявленными как async, без транспиляции.
RidgeA
05.03.2019 10:06Все хорошо, конечно, но:
- как у этого решения с производительностью?
- Как-то не хочется в прод тащить экспериментальные модули (async_hooks), нет информации когда обещают перевести в статус стабильного?!
keenondrums Автор
05.03.2019 14:361. На бенчмарки можно тут посмотреть github.com/nodejs/benchmarking/issues/181 и решить для себя насколько оно критично. Как по мне иметь возможность адекватной трассировки важнее.
2. Зависит от того, что у вас за прод. Меня, как любителя смузи и всего модного-стильного-молодежного, это не смутило и поюзать уже успел, но и компания была вполне себе хипстерская, а не кровавый энтерпрайз.RidgeA
05.03.2019 16:30спасибо за ссылку, гляну.
но там только async_hooks, я помню касательно Proxy то же не все гладко (было по крайней мере, может сейчас это пофиксили)
Просто я бы это добавил в статью — как минимум то, что это эксперементальный модуль…

wentout
05.03.2019 14:11+1Все, кто сюда дочитал, обратите внимание ещё на такую вещь.
И cls-hooked и вообще всё, что основано на async_hooks имеет одну существенную проблему.
Проблема НЕ в асинхронной части. Она большей степени покрыта. Проблема в том, что синхронный контекст можно разделить. Например:
issues/59
issues/249
Пример для Front-End
Исходя из этого наивное применение подобных пакетов чревато потерей контекста.
Посему все нормальные пакеты рекомендуют делать обёртки в тех местах, которые не могут быть покрыты асинхронным контекстом автоматически. Поэтому «биндить» только req и res — мало. Надо биндить ещё и кучу всего остального, например общение с БД. Посмотреть можно, например, тут, самый конец файла: Cloud Tracing Mongoose Sync Split Wrapper:

maxp
Все эти сложности сделаны только для того, чтобы не пробрасывать явно конктекст обработки?
PrinceKorwin
Не всегда возможно явно пробрасывать контекст обработки (например используется сторонняя функция/библиотека).
keenondrums Автор
Если многоуровневые сервисы, то больно его руками передавать.
Все это для того, чтобы заменить Thread-local storage.