
 Гугл любит пасхалки. Любит настолько, что найти их можно практически в каждом продукте компании. Традиция пасхалок в Android тянется с самых первых версий операционной системы (я думаю, все в курсе, что будет, если в настройках несколько раз нажать на строчку с версией Android).
Гугл любит пасхалки. Любит настолько, что найти их можно практически в каждом продукте компании. Традиция пасхалок в Android тянется с самых первых версий операционной системы (я думаю, все в курсе, что будет, если в настройках несколько раз нажать на строчку с версией Android).Но бывает и так, что пасхалки обнаруживаются в самых неожиданных местах. Есть даже такая легенда: однажды один программист загуглил «mutex lock», а вместо результатов поиска попал на страницу foo.bar, решил все задачи и устроился на работу в Google.
Вот такая же удивительная история (только без хэппи-энда) произошла со мной. Скрытые послания там, где их точно не может быть, реверс Java кода и нативных библиотек, секретная виртуальная машина, прохождение собеседования в Google — все это под катом.
DroidGuard
Одним скучным вечером я сделал factory reset и начал заново настраивать смартфон. Первым делом свежий Android попросил меня ввести мой гугловый аккаунт. «Интересно, а как вообще происходит регистрация и логин в Android?»- подумал я. Вечер переставал быть томным.
Для перехвата и анализа трафика я использую Burp Suite от PortSwigger. Бесплатной Community версии будет достаточно. Чтобы мы смогли увидеть https запросы, для начала нужно установить на девайс сертификат от PortSwigger. Для тестов у меня в закромах нашелся восьмилетний Samsung Galaxy S с Android 4.4 на борту. Если у вас что-то посвежее, то могут возникнуть проблемы с https: certificate pinning и все такое.
На самом деле, ничего особо интересного в обращениях к Google API нет. Девайс отправляет данные о себе, в ответ получает токены… Единственный непонятный момент — POST запрос к anti-abuse сервису.
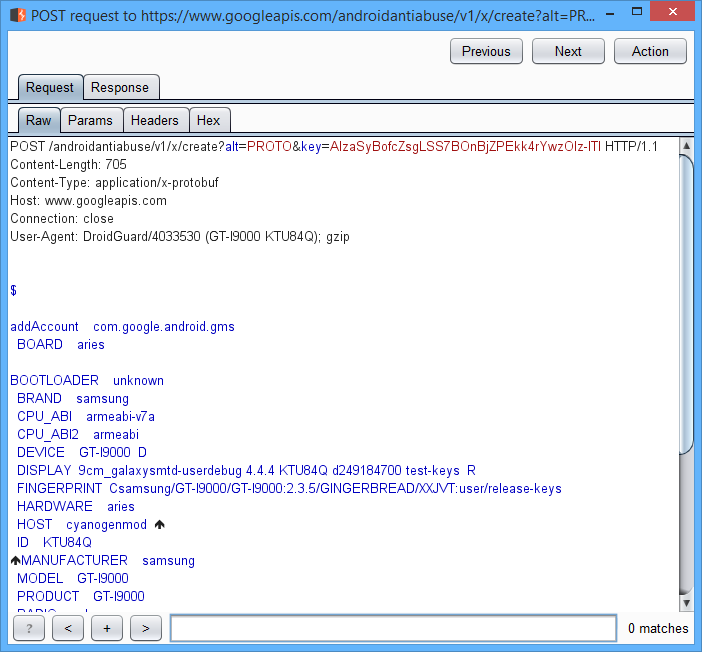
После этого запроса среди непримечательных параметров появляется один загадочный, с названием droidguard_result. Представляет он собой очень длинную Base64 строку:

DroidGuard — это механизм Google для отделения ботов и эмуляторов от настоящих устройств. SafetyNet в своей работе тоже использует данные от DroidGuard. Похожая штука у Google есть и для браузеров — Botguard.
Но все-таки, что это за данные, что в них передается? Сейчас будем разбираться.
Protocol Buffers
Откуда вообще берется ссылка www.googleapis.com/androidantiabuse/v1/x/create?alt=PROTO&key=AIzaSyBofcZsgLSS7BOnBjZPEkk4rYwzOIz-lTI, кто именно в системе Android делает этот запрос? Нетрудно найти, что эта ссылка прямо в таком виде хранится в одном из обфусцированных классов Google Play Services:
public bdd(Context var1, bdh var2) {
this(var1, "https://www.googleapis.com/androidantiabuse/v1/x/create?alt=PROTO&key=AIzaSyBofcZsgLSS7BOnBjZPEkk4rYwzOIz-lTI", var2);
}
Как мы уже видели в Burp, Content-Type у POST запросов по этой ссылке — application/x-protobuf (Google Protocol Buffers, протокол для бинарной сериализации от Google). Не json, конечно — так сразу и не поймешь, что там пересылается.
Работает protocol buffers таким образом:
- сначала описываем структуру сообщения в специальном формате и сохраняем в .proto файл
- компилируем .proto файлы, на выходе компилятор protoc генерирует исходный код на выбранном языке программирования (в случае с Android это Java)
- используем сгенерированные классы в проекте
Чтобы декодировать сообщения в формате protobuf у нас есть два пути. Первый — использовать какой-либо инструмент для анализа protobuf и пытаться воссоздать оригинальное описание .proto файлов. Второй — выдернуть готовые сгенерированные protoc-компилятором классы из Google Play Services. По второму пути я и пошел.
Берем apk файл Google Play Services той же версии, что установлен на девайсе (а если девайс рутованый, то apk можно скопировать прямо с него же). С помощью dex2jar перегоняем .dex файл обратно в .jar и открываем любимым декомпилятором. Мне в последнее время очень нравится Fernflower от JetBrains. Работает он как плагин к IntelliJ IDEA (или Android Studio), поэтому просто открываем в Android Studio класс с той самой заветной ссылкой. Если proguard старался не сильно, то декомпилированный Java код для создания сообщений protobuf можно просто целиком копировать себе в проект.
По декомпилированному коду видно, что в protobuf сообщении на сервер уходят константы Build.* (ладно, это сразу было очевидно):
...
var3.a("4.0.33 (910055-30)");
a(var3, "BOARD", Build.BOARD);
a(var3, "BOOTLOADER", Build.BOOTLOADER);
a(var3, "BRAND", Build.BRAND);
a(var3, "CPU_ABI", Build.CPU_ABI);
a(var3, "CPU_ABI2", Build.CPU_ABI2);
a(var3, "DEVICE", Build.DEVICE);
...
А вот в ответе сервера, к сожалению, все поля protobuf сообщения после обфускации превратились в бессмысленные буквы латинского алфавита. Но что в этих полях хранится, можно узнать по обработке ошибок. Вот так проверяются данные, которые приходят с сервера:
if (!var7.d()) {
throw new bdf("byteCode");
}
if (!var7.f()) {
throw new bdf("vmUrl");
}
if (!var7.h()) {
throw new bdf("vmChecksum");
}
if (!var7.j()) {
throw new bdf("expiryTimeSecs");
}
Судя по всему, именно так и назывались поля до обфускации: byteCode, vmUrl, vmChecksum и expiryTimeSecs. Такой нейминг уже наталкивает на определенные догадки.
Собираем все декомпилированные классы из Google Play Services в тестовый проект, переименовываем, набиваем тестовые константы Build.* и запускаем (при желании можно имитировать параметры любого девайса). Если кто-то хочет повторить, то вот ссылка на мой гитхаб.
При корректном запросе с сервера возвращается такой результат:
00:06:26.761 [main] INFO d.a.response.AntiabuseResponse — byteCode size: 34446
00:06:26.761 [main] INFO d.a.response.AntiabuseResponse — vmChecksum: C15E93CCFD9EF178293A2334A1C9F9B08F115993
00:06:26.761 [main] INFO d.a.response.AntiabuseResponse — vmUrl: www.gstatic.com/droidguard/C15E93CCFD9EF178293A2334A1C9F9B08F115993
00:06:26.761 [main] INFO d.a.response.AntiabuseResponse — expiryTimeSecs: 10
Первый этап позади. Сейчас посмотрим, что интересного прячется за ссылкой vmUrl.
Секретный apk
Ссылка ведет нас прямиком к .apk файлу, название которого соответствует его SHA-1 хэшу. Размер и содержимое apk файла скромные — файл весит 150 килобайт. Экономия тут не лишняя: если его загружает каждое из двух миллиардов Android устройств, то набегает уже 270 терабайт трафика.
DroidGuardService, который является частью Google Play Services, заботливо загружает этот файл на девайс, распаковывает, извлекает .dex и .so файлы и бесцеремонно, через reflection, использует класс com.google.ccc.abuse.droidguard.DroidGuard. Если происходит какая-то ошибка, то DroidGuardService переключается с DroidGuard на Droidguasso. Но как работает Droidguasso — это отдельная история.По сути, класс
DroidGuard — это просто JNI обертка вокруг нативной .so библиотеки. ABI нативной библиотеки соответствует тому, что мы отправляли в protobuf запросе в поле CPU_ABI: можем запросить armeabi, можем x86, а можем даже mips.Сам сервис
DroidGuardService не содержит какой-либо интересной логики для работы с загруженным классом DroidGuard. Он просто создает новый экземпляр класса DroidGuard, передав ему в конструктор byteCode из protobuf сообщения, вызывает публичный метод, который возвращает массив байт. Этот массив байт и отправляется на сервер в параметре droidguard_result.Чтобы получить примерное представление о том, что происходит внутри
DroidGuard мы можем повторить логику DroidGuardService (только без загрузки apk, раз нативная библиотека у нас и так уже есть). Мы можем взять .dex файл из секретного APK, перегнать в .jar и после этого использовать в проекте. Единственная проблема заключается в том, как класс DroidGuard загружает нативную библиотеку. В статическом блоке инициализации вызывается метод loadDroidGuardLibrary():static
{
try
{
loadDroidGuardLibrary();
}
catch (Exception ex)
{
throw new RuntimeException(ex);
}
}
В свою очередь, метод
loadDroidGuardLibrary() читает файл library.txt (который лежит в корне .apk файла) и загружает библиотеку с таким именем через вызов System.load(String filename). Не самый удобный для нас способ, придется что-то выдумывать при сборке apk, чтобы положить в корень library.txt и .so файл. Было бы удобнее стандартно хранить .so файл в папке lib и загружать через System.loadLibrary(String libname). Исправить это несложно. Для этого будем использовать smali/baksmali — ассемблер/дизассемблер для dex формата. С его помощью classes.dex превращается в набор .smali файлов. Класс
com.google.ccc.abuse.droidguard.DroidGuard нужно поправить таким образом, чтобы в статическом блоке инициализации вызывался метод System.loadLibrary("droidguard") вместо loadDroidGuardLibrary(). Синтаксис smali довольно простой, выглядеть новый блок инициализации будет вот так:.method static constructor <clinit>()V
.locals 1
const-string v0, "droidguard"
invoke-static {v0}, Ljava/lang/System;->loadLibrary(Ljava/lang/String;)V
return-void
.end method
С помощью утилиты baksmali все это собирается обратно в .dex, который в свою очередь конвертируется в .jar. После этих манипуляций на выходе получаем jar файл, который можем использовать в тестовом проекте. Кстати, вот и он.
Вся работа с
DroidGuard занимает пару строчек. Самое важное — загрузить массив байт, который мы получили на прошлом шаге после запроса к anti-abuse сервису и передать его в конструктор DroidGuard.private fun runDroidguard() {
var byteCode: ByteArray? = loadBytecode("bytecode.base64");
byteCode?.let {
val droidguard = DroidGuard(applicationContext, "addAccount", it)
val params = mapOf("dg_email" to "test@gmail.com", "dg_gmsCoreVersion" to "910055-30",
"dg_package" to "com.google.android.gms", "dg_androidId" to UUID.randomUUID().toString())
droidguard.init()
val result = droidguard.ss(params)
droidguard.close()
}
}
Теперь с помощью профайлера Android Studio мы можем посмотреть, что происходит во время работы DroidGuard.
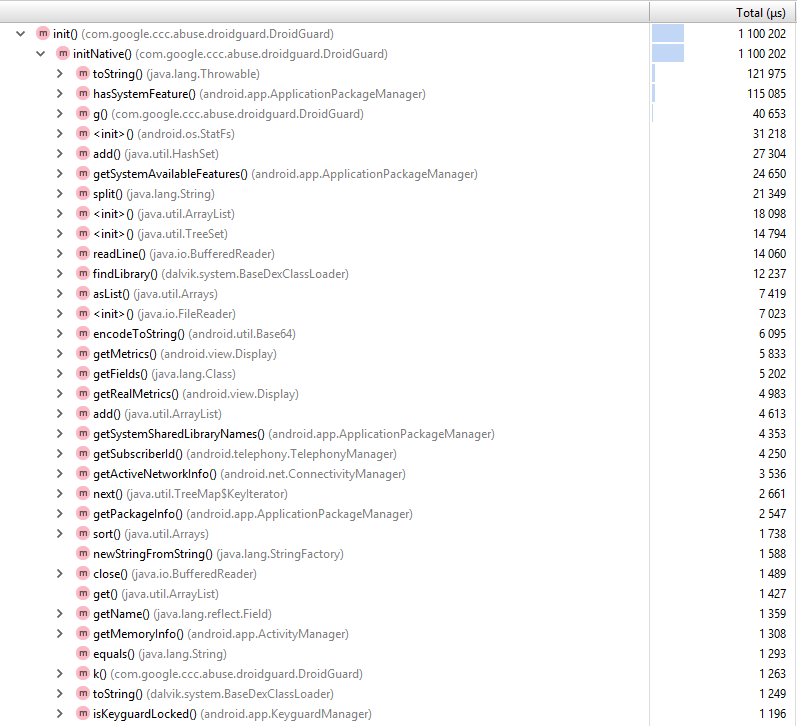
Нативный метод
initNative() собирает информацию о девайсе и вызывает java-методы: hasSystemFeature(), getMemoryInfo(), getPackageInfo()… Уже что-то, но конкретной логики по прежнему не видно. Ладно, ничего не остается, кроме как дизассемблировать .so файл.libdroidguard.so
На самом деле, анализ нативной библиотеки не намного сложнее, чем анализ .dex и .jar файлов. Понадобится программа, похожая на Hex-Rays IDA и изредка небольшое знание ассемблера под arm или x86, на выбор. Я выбрал arm, потому что у меня есть подходящий для дебага рутованный девайс. Если под рукой такого нет, то можно взять библиотеку под x86 и дебажить в эмуляторе.
Программа, похожая на Hex-Rays IDA, декомпилирует бинарник в что-то похожее на c-код. Если откроем код метода
Java_com_google_ccc_abuse_droidguard_DroidGuard_ssNative, то увидим приблизительно такую картину:__int64 __fastcall Java_com_google_ccc_abuse_droidguard_DroidGuard_initNative(int a1, int a2, int a3, int a4, int a5, int a6, int a7, int a8, int a9)
...
v14 = (*(_DWORD *)v9 + 684))(v9, a5);
v15 = (*(_DWORD *)v9 + 736))(v9, a5, 0);
...
Выглядит так себе. Для начала надо сделать пару предварительных шагов, чтобы привести это в приличный вид. Декомпилятор ничего не знает о JNI, поэтому устанавливаем Android NDK и импортируем файл jni.h. Как мы прекрасно знаем, первые два параметра JNI метода — это
JNIEnv* и jobject (this). Типы остальных параметров и их назначение мы можем узнать из Java кода DroidGuard. После присвоения нужных типов, бессмысленные смещения превращаются в вызовы JNI методов:__int64 __fastcall Java_com_google_ccc_abuse_droidguard_DroidGuard_initNative(_JNIEnv *env, jobject thiz, jobject context, jstring flow, jbyteArray byteCode, jobject runtimeApi, jobject extras, jint loggingFd, int runningInAppSide)
{
...
programLength = _env->functions->GetArrayLength)(_env, byteCode);
programBytes = (jbyte *)_env->functions->GetByteArrayElements)(_env, byteCode, 0);
...
Если запастись терпением и проследить за путем массива байт, который мы получили от anti-abuse сервера, то можно расстроиться. К сожалению, простого ответа на вопрос «что здесь вообще происходит?» не будет. Это действительно самый настоящий байт-код, а нативная библиотека — виртуальная машина. Немного AES шифрования, а дальше виртуальная машина байт за байтом читает байт-код и выполняет команды. Каждый байт — это команда, за которой следуют операнды. Команд не так много, всего штук 70: прочитать int, прочитать byte, прочитать строку, вызывать java метод, умножить два числа, if-goto и так далее.
Wake up, Neo
Я решил пойти еще чуть дальше и разобраться с форматом байт-кода для этой виртуальной машины. С командами есть одна проблема: периодически (раз в несколько недель) появляется новая версия нативной библиотеки, в которой каждой команде соответствует другой байт. Меня это не остановило, и я решил воссоздать эту виртуальную машину на Java.
Байт-код как раз и выполняет всю рутинную работу по сбору информации о девайсе. Например, загружает строку с именем метода, получает его адрес через dlsym и выполняет. В своей java версии виртуальной машины я реализовал от силы 5 методов и научился интерпретировать буквально первые 25 команд байт-кода anti-abuse сервиса. На 26-ой по счету команде виртуальная машина прочитала очередную зашифрованную строку из байт-кода. Внезапно оказалось, что это далеко не имя очередного метода.
Virtual Machine command #26
Method invocation vm->vm_method_table[2 * 0x77]
Method vmMethod_readString
index is 0x9d
string length is 0x0066
(new key is generated)
encoded string bytes are EB 4E E6 DC 34 13 35 4A DD 55 B3 91 33 05 61 04 C0 54 FD 95 2F 18 72 04 C1 55 E1 92 28 11 66 04 DD 4F B3 94 33 04 35 0A C1 4E B2 DB 12 17 79 4F 92 55 FC DB 33 05 35 45 C6 01 F7 89 29 1F 71 43 C7 40 E1 9F 6B 1E 70 48 DE 4E B8 CD 75 44 23 14 85 14 A7 C2 7F 40 26 42 84 17 A2 BB 21 19 7A 43 DE 44 BD 98 29 1B
decoded string bytes are 59 6F 75 27 72 65 20 6E 6F 74 20 6A 75 73 74 20 72 75 6E 6E 69 6E 67 20 73 74 72 69 6E 67 73 20 6F 6E 20 6F 75 72 20 2E 73 6F 21 20 54 61 6C 6B 20 74 6F 20 75 73 20 61 74 20 64 72 6F 69 64 67 75 61 72 64 2D 68 65 6C 6C 6F 2B 36 33 32 36 30 37 35 34 39 39 36 33 66 36 36 31 40 67 6F 6F 67 6C 65 2E 63 6F 6D
decoded string value is (You're not just running strings on our .so! Talk to us at droidguard@google.com)
Очень странно, до этого момента виртуальные машины никогда не разговаривали со мной. Мне показалось, это тревожный звоночек, если ты видишь адресованные тебе секретные послания. Чтобы убедиться, что крыша у меня все еще на месте, я решил прогнать через свою виртуальную машину пару сотен разных ответов от anti-abuse сервиса с байт-кодом. Каждый раз буквально через 25-30 команд в байт-коде пряталось сообщение. Часто они повторялись, но я отобрал уникальные. Адрес почты, правда, я поменял. Плюс в каждом таком сообщении адрес почты имел формат «droidguard+tag@google.com»: для каждого запроса к anti-abuse сервису этот tag уникальный.
droidguard@google.com: Don't be a stranger!
You got in! Talk to us at droidguard@google.com
Greetings from droidguard@google.com intrepid traveller! Say hi!
Was it easy to find this? droidguard@google.com would like to know
The folks at droidguard@google.com would appreciate hearing from you!
What's all this gobbledygook? Ask droidguard@google.com… they'd know!
Hey! Fancy seeing you here. Have you spoken to droidguard@google.com yet?
You're not just running strings on our .so! Talk to us at droidguard@google.com
Наверное, я тот самый избранный? Я решил, что пора прекратить копаться в DroidGuard и связаться с Google, раз они меня об этом просят.
Ваш звонок очень важен для нас
О результатах своих исследований я решил сообщить по указанному адресу. Чтобы результаты выглядели внушительнее, я немного автоматизировал процесс анализа виртуальной машины. Дело в том, что строки и массивы байт в байте-кода хранятся зашифрованными. Виртуальная машина декодирует используя константы, которые заинлайнил компилятор. С помощью программы, похожей на Hex-Rays IDA, достать их оттуда не трудно. Но с каждой новой версией нативной библиотеки эти константы меняются и доставать их вручную неудобно.
На Java парсинг нативной библиотеки получился на удивление нетрудным. При помощи jelf (библиотека для парсинга ELF файлов) находится смещение метода
Java_com_google_ccc_abuse_droidguard_DroidGuard_initNative в бинарнике, а дальше с помощью Capstone (фреймворк для дизассемблинга, есть биндинги для разных языков программирования, в том числе Java) можно получить код на ассемблере и поискать в нем загрузку констант в регистры.По итогу получилась программка, которая повторяет всю работу DroidGuard: делает запрос к anti-abuse сервису, загружает apk, распаковывает, парсит нативную библиотеку, достает оттуда нужные константы, подбирает мапинг команд виртуальной машины и интерпретирует байт-код. Собрав все это в кучу, я отправил письмо в Google. Параллельно я стал готовиться к переезду и полез изучать glassdoor на тему средней зарплаты в компании. Меньше чем на шестизначную сумму я решил не соглашаться.
Ответ не заставил себя долго ждать. Письмо от члена команды DroidGuard было довольно лаконичным: «Зачем ты этим вообще занимаешься?».

«Прост» — ответил я. Сотрудник Google объяснил мне, для чего нужен DroidGuard: для защиты Android от злоумышленников (не может быть!). И было бы разумным нигде не размещать мои исходники виртуальной машины DroidGuard. На этом наше общение закончилось.
Собеседование
Месяц спустя неожиданно пришло еще одно письмо. В команду DroidGuard в Цюрихе нужен новый сотрудник. Может я хотел бы присоединиться к ним? Еще бы!
Никаких окольных путей для устройства в Google нет. Максимум, что мог сделать для меня мой визави — переслать мое резюме в hr отдел. После этого запускается стандартная бюрократическая процедура из серии собеседований.
Информации о собеседовании в Google в интернете с избытком. Алгоритмы, олимпиадные задачки и программирование в Google Doc не было моим коньком, поэтому я стал усердно готовиться. Я затер до дыр курс «Алгоритмы» на coursera, прорешал сотню задачек на hackerrank, мог с закрытыми глазами написать обход графа в ширину и в глубину…
В подготовке прошло два месяца. Сказать, что я был готов — ничего не сказать. Google Doc стала моей любимой IDE. Мне казалось, что я знал об алгоритмах практически все. Конечно, я адекватно оценивал свои силы и понимал, что 5 очных собеседований в Цюрихе я навряд ли пройду. Но бесплатно съездить в Диснейленд для программистов в Швейцарию — это тоже неплохо. Первый этап — это собеседование по телефону, чтобы отсеять совсем слабых кандидатов и не тратить время разработчиков на очные собеседования. Был назначен день, я стал ждать звонка…
… и я сразу же провалил самое первое собеседование по телефону. Мне повезло, мне попался вопрос, который я заранее видел в интернете и который я уже решал перед собеседованием. Задача заключалась в сериализации массива строк. Я предложил кодировать строки в Base64 и сохранять их через разделитель. В ответ интервьюер предложил мне реализовать алгоритм Base64. После этого собеседование превратилось скорее в монолог, в котором интервьюер объяснял мне как работает Base64, а я вспоминал битовые операции в Java.
Через 3 дня после звонка я получил письмо, в котором мне сообщали, что собеседовать дальше меня не хотят. На этом мое общение с Google полностью закончилось.
Зачем в DroidGuard спрятаны сообщения, призывающие пообщаться, я так и не понял. Возможно, просто для статистики. Как мне сказали, пишут им с разной частотой: иногда каждую неделю по три человека, а иногда раз в год.
Я думаю, чтобы попасть на собеседование в Google есть способы намного проще. В конце концов, с таким же успехом можно попросить любого из ста тысяч сотрудников компании (хотя разработчиков там поменьше, конечно). Но опыт получился интересным.
Комментарии (211)

citius
19.03.2019 13:18+2То самое чувство, когда провалил важное собеседование из-за того, что переволновался, перетрудился при подготовке, и сфейлил первый же простейший вопрос.
Знакомо. :(
andrei_mankevich Автор
19.03.2019 13:30+1Для меня вообще собеседования — это жуткий стресс. Поэтому я по ним не хожу и опыта прохождения не имею :) Я могу по пальцам одной руки перечислить все свои собеседования в жизни.
Но я бы и в спокойной обстановке не выдал Base64, просто потому что понятия не имел как он работает и всю жизнь воспринимал его как данность. А ведь это так, только цветочки перед 5 ягодками настоящего очного собеседования.
Мне процесс собеседования показался очень сложным, и я бесконечно далек от этого уровня. Не знаю, зачем Гуглу нужны все эти гении-олимпиадники, но им виднее.
DMGarikk
19.03.2019 13:49+1Не знаю, зачем Гуглу нужны все эти гении-олимпиадники, но им виднее.
Потому что они могут себе позволить выбирать, в отличии от других контор, у них реально «очередь за забором»
===
другое дело что такой высокий уровень вхождения, и отнюдь не блестящее качество программных продуктов… вот что для меня не понятно
Archon
19.03.2019 13:56+4другое дело что такой высокий уровень вхождения, и отнюдь не блестящее качество программных продуктов… вот что для меня не понятно
Потому что умение щёлкать олимпиадные задачки имеет мало пересечений с умением делать качественный продукт.
Такой выбор тут скорее действительно «потому что могут». Когда очередь рассосётся, они выкинут задачки про круглый люк в этот самый люк и будут набирать нормально.
Revertis
19.03.2019 19:40+6Потому что умение щёлкать олимпиадные задачки имеет мало пересечений с умением делать качественный продукт.
Не совсем так. Тут на Хабре тоже была статья о том, какие там порядки. Для повышения там надо предоставлять громкие цифры или ремейки, перезапуски и выпуски нового. А за фикс багов и оптимизации вы там так и будете сидеть на низшей ступени.
roman_kashitsyn
20.03.2019 00:14+3Оптимизации — вещь полезная, но их надо уметь преподносить.
Ключевая сложность с промо — нужно скрупулёзно собирать метрики и доказывать свою полезность, чтобы твоему менеджеру было что показать комитету, который ни про тебя, ни про твои проекты вообще ничего не знает. Чтобы сделать что-то для промо, нужно в 3 раза больше времени, чем просто это сделать.
При этом процесс всё равно не особо честен. Часто люди получают промо за запуски оперденей, выхлопа от которых нуль без палки, а мега-продуктивные люди, которые пилят ключевую инфраструктуру и получают важные результаты, годами не номинируются.
andrei_mankevich Автор
19.03.2019 14:01+3При этом гении-олимпиадники внутри Google не могут родить ничего дельного (я на Google в обиде, имею право так считать).
Насколько я понимаю, тот же DroidGuard — проект компании Impermium. Google поглотил Impermium, команда перешла в Google, а в Android появилась толковая защита от фрода.
tyomitch
19.03.2019 18:07Можете в общих словах описать, в чём именно она состоит (хотя бы — от чего конкретно они пытаются защититься), и зачем им та виртуальная машина?
andrei_mankevich Автор
19.03.2019 18:11+1Защититься от ботов, которые делают вид, что они настоящие Android устройства.
Для этого DroidGuard собирает определенную информацию о девайсе. Какую именно информацию — это решает логика, заложенная в байт-код. Байт-код каждый раз новый возвращается с сервера. По итогу чтобы написать бота, надо реализовать виртуальную машину, которая сможет интерпретировать байт-код DroidGuard.tyomitch
19.03.2019 18:30От каких именно «ботов»? Что этим «ботам» мешает запустить Android в эмуляторе в 100500 экземплярах?
andrei_mankevich Автор
19.03.2019 18:32+3Вот именно этим DroidGuard и занимается: отличает настоящие живые устройства от эмуляторов, рутованные девайсы или нет и так далее.
tyomitch
19.03.2019 18:54Всё равно недопонимаю: какие возможности Android недоступны пользователям эмуляторов, рутованных девайсов, и «ботам»?

smilyfox
19.03.2019 19:15+7Манипуляции с имейлами, соцсетями и прочим. Это хорошие деньги. Не зря китайцы не заморачиваютя, а просто собирают фермы из сотен настоящих смартфонов. Это дешевле, чем регулярно обход проверок переписывать
tyomitch
19.03.2019 21:37Спасибо, цель защиты проясняется.
Теперь хочется понять механизм. В Android есть какой-то API, посредством которого приложения «соцсетей и прочего» узнают результат проверки — бот ими пользуется или не бот?
Если так, то что мешает «боту» подменить на своём устройстве эту API?khim
20.03.2019 06:21Если так, то что мешает «боту» подменить на своём устройстве эту API?
Тем, что это API не находится на устройстве?
То есть да, вы можете подменить этот API и убедить программу, что она общается с настощим Facebook'ом и настоящим GMail'ом и эти фейковые Facebook и GMail верят ей… дальше что? Греть воздух?
Для этого более простые способы есть…tyomitch
20.03.2019 10:32Неа, не понимаю.
Устройство грузит (обфусцированный с использованием одноразовой ВМ) код для валидации. Выполняет его.
Что делается с результатом выполнения этого кода?
Сохраняется локально для использования приложениями «соцсетей и прочего»? (Тогда что мешает его подменить локально?)
Отправляется на сервер гугла? (Тогда что мешает вместо него отправить гуглу эталонный результат, полученный на настоящем устройстве?)
DCNick3
20.03.2019 12:37+1Вам нужно убедить в том, что вы не бот, не локальное приложение, а сервер. Именно поэтому результат выполнения DroidGuard отправляется гуглу.
tyomitch
20.03.2019 12:45Тогда что мешает отправить гуглу эталонный результат, полученный обфусцированным кодом на настоящем устройстве? Для этого в обфускации разбираться не требуется.

wataru
20.03.2019 13:07+1Этот результат, очевидно, уникальный и зависит от загружаемой ВМ и байткода. Байткод уникальный для каждой проверки, ВМ меняется раз в несколько недель.
Для обхода защиты надо раз в несколько недель перереализовывать ВМ, понять, какие АПИ и как оно может дергать и эмулировать их все, как на реальном устройстве.
bay73
20.03.2019 13:12Читайте внимательно:
«Байт-код каждый раз новый возвращается с сервера.»
Поэтому и ответы ожидаются каждый раз новые.

Nexus7
19.03.2019 20:40+1Виртуальная машина DroidGuard пользуется системными функциями для получения информации из системы? Если они заранее известны и их количество ограничено, то что мешает эмулировать эти функции, если они вызываются в контексте обычного процесса?
andrei_mankevich Автор
19.03.2019 20:45Не совсем так. Например, в виртуальной машине есть команды: загрузить строку, загрузить через reflection класс с определенным именем, выполнить через reflection метод с определенным именем. Вот откуда это имя берется — это логика байт-кода. Чтобы узнать имя класса и имя метода, надо интерпретировать команды байт-кода, которые работают со строками.
Nexus7
19.03.2019 20:55+1Вопрос несколько в другом: если DroidGuard работает в контексте стандартного Linux-процесса, то к железу за данными он пойдёт через системные вызовы, которые наверняка можно локализовать и идентифицировать? Я к тому, что может быть не надо разбирать, что делает внутри себя конкретная инкарнация виртуальной машины, может достаточно поместить её в окружение, которое предоставит ей все нужные для прохождения проверки данные?
andrei_mankevich Автор
19.03.2019 21:05+3Во-первых, у меня не было цели обмануть DroidGuard, я просто решил хорошо провести время :)
Во-вторых, защиту SafetyNet вполне успешно обходят, и это совсем не новость. Есть даже опенсорс реализация всех проприетарных гугловых сервисов microG Project.Nexus7
19.03.2019 22:19Спасибо за информацию. Со времён книжек Криса Касперски я знал, что виртуалки используются для защиты приложений, но даже не догадывался, как их может использовать Google в Android.
tyomitch
19.03.2019 21:55Судя по ответу andrei_mankevich чуть выше — список возможных системных вызовов теоретически не ограничен, т.е. эмулировать придётся все поддерживаемые системой. Плюс нужно разгадать, какой результат для каждого вызова проверка ожидает получить.
Nexus7
19.03.2019 22:16Если там нет криптопротоколов, то конкретная железка всегда будет отвечать то же самое, если BRAND, ABI, DEVICE не меняются. Если парни из Google знают, что Samsung A10 всегда выдаёт «bar» на вызов foo(), то на этом могут строить свою проверку. Соответственно, достаточно один раз прогнать на живом A10 виртуалку DroidGuard, записать всё, что система ей отдавала, и в дальнейшем всегда успешно проходить проверку.
Системных вызовов меньше 400 ;) И не удивлюсь, если Google под каждую железку, которая проходила у них сертификацию, уже сгенерила набор виртуалок, которыми пользуется.
Но это всё чисто теоретические измышлизмы, без конкретной цели монетизации этого взлома можно даже не начинать разбираться, слишком много работы :)
AlexSmall
19.03.2019 22:41-1А представляете какие возможности открываются у «корпорации добра» когда постоянно все устройства загружают и безусловно выполняют некий никем не контролируемый код… каждые 10 секунд…
А если кто-то дискредитирует канал связи с «корпорацией добра»?
Опасненько… ;)Nexus7
19.03.2019 22:53+1Каждый раз, когда мне приходит push-уведомление, я вспоминаю Google Play Services, которые постоянно в онлайне ;)
Весь мир строится на доверии, и надежды на то, что «нас-то всяко пронесёт». Иначе как ездить на машине, ходить по улице и писать на Хабр? :)
vsb
19.03.2019 23:10+1Помимо системных вызовов, вероятно, нужно также идеально сэмулировать процессор, включая всякие экзотические команды, периферийные устройства, возможно, даже, тайминги, ведь любую информацию можно использовать для поиска отличий. Если вы сэмулируете всё это идеально и не отличимо от железного, то вы сделаете идеальный эмулятор, который, конечно же, распознать нельзя. Это уже принцип фильма «Матрица» получается или солипсизма. Вероятно на практике это невозможно и вы быстро упрётесь в проблему, когда код прогоняете, но он отличается от железного и гугл ответ не принимает. Тут вам нужно будет разобраться, почему он отличается. Чтобы это понять, вам в общем случае нужно дизассемблировать переданную виртуальную машину, разобраться в переданном байткоде. Пока вы это будете делать, они уже выпустят новую виртуальную машину. Если же у вас получилось эмулировать устройство и вы смогли зарегистрировать ботов, ну, очевидно этих ботов распознают в дальнейшем и будут разбираться, как вы их зарегистрировали. Изучат ваши ответы и постараются модифицировать байткод и/или виртуальную машину так, чтобы использовать другие методы и исключить уже уязвимые. Понятно, что процесс итеративный, но, вероятно, гуглу тут выигрывать проще, чем вам.
Nexus7
19.03.2019 23:20+1Поэтому я и не буду этим заниматься ;)
Мне было интересно, копал ли топикастер эту тему дальше. С практической точки зрения меня больше интересует применение вирутальных машин внутри приложения для защиты его данных.
Здесь показана интересная фишка — генерация не только нового исполняемого кода, но целиком виртуальной машины для единственной проверки. На такой идее можно построить систему защиты контента в приложении, каждой инсталляции отдавать с сервера свою версию виртуальной машины, которая будет работать только на данном конкретном устройстве и уметь расшифровывать только данный конкретный файл.tyomitch
19.03.2019 23:26Эта идея не нова: vmpsoft.com/support/user-manual/introduction/what-is-vmprotect
И уязвима она совсем с другой стороны: не «дизассемблировать переданную виртуальную машину, разобраться в переданном байткоде», а запустить его на выполнение на реальном телефоне (одном на 100500 эмуляторов) и передать результат от имени эмулятора.Nexus7
19.03.2019 23:39Я несколько о другом. Предположим, приложение имеет платный контент. Проверка оплаты происходит на сервере. Если сервер банально отвечает да/нет, то вся система оплаты ломается парой байт.
Если же сервер передаёт после покупки зашифрованный контент и виртуальную машину, специально заточенную для расшифровывания этого контента, причём только на этом конкретном устройстве, плюс приложение хранит в железном KeyStore какие-то данные для работы этой виртуалки, то ломать эту конструкцию будет гораздо сложнее.
Или я изобретаю ещё один велосипед? ;)andrei_mankevich Автор
20.03.2019 00:06Вот насчет заточки под прям конкретное устройство — я это не очень представляю. Но в целом вы сейчас еще раз описали принцип работы DroidGuard :)
Данные (строки, например) внутри байт-кода можно считать тем самым контентом. Байт-код несет в себе логику по работе с этими данными, а виртуальная машина исполняет команды.Nexus7
20.03.2019 00:24Отсюда и возникает изначальный вопрос, какие системные вызовы делает DroidGuard, чтобы идентифицировать устройство?
Что есть на поверхности:
- Android ID
- Application ID
- Order ID — уникальный идентификатор покупки
- марка/модель/ABI
- случайное число, ключ для расшифровывания которого храним в KeyStore
Раньше ещё можно было потрогать MAC, IMEI, но и этого должно хватить, чтобы сделать уникальную виртуалку со своим уникальным набором команд и регистров, на которой достаточно реализовать какой-нибудь кастомный вариант ChaCha20.
vsb
20.03.2019 00:19А в чём интерес этой фишки? Вы всегда можете реализовать внутри виртуальной машины ещё одну виртуальную машину, например и так сколько угодно раз. А передавать машинный код, в который будет вшит нужный байткод. Честно говоря я не понимаю, почему гугл так не делает.
Nexus7
20.03.2019 00:34Интерес в том, чтобы максимально затруднить копирование платного контента, предоставляя каждый раз уникальный блок данных и уникальную виртуалку для его расшифровывания.
Много слоёв будут слишком медленно работать на конечном устройстве. Плюс лишние слои не добавят безопасности, если она вся основана на нескольких переменных, которые лежат почти на поверхности. Мы с вами просто не знаем, где их читать.andrei_mankevich Автор
20.03.2019 00:54Проблема в том, что байт-код для проверки у гугла каждый раз новый и разный, а платный контент — уникальный и один на всех. После того, как виртуальная машина его расшифрует и он окажется в незашифрованном в виде в памяти, можно будет снять дамп и дальше его распространять.
Конечно, смотря о каком контенте идет речь и как этот контент используется. В том же DroidGuard даже значения переменных в памяти хранятся в зашифрованном виде. Но это не мешает с помощью дебагера перехватить их значения в тех местах где они используются.Nexus7
20.03.2019 12:12Понятно, что абсолютной защиты не существует и при наличии достаточно большого бюджета и/или мотивации ломается всё. Но подобные методы защиты отпугнут недостаточно мотивированных копателей. Плюс встроенный head hunting ;)
Пример подобного приложения с платным контентом пробегал здесь позавчера, lamptest.ru. В его платной версии показываются дополнительные параметры лампочек. Если не защищать весь контент, который приходит с сервера, то нехорошим людям достаточно просто сделать бесплатный клон этого приложения типа lamptest.pro, который будет круче, и зарабатывать на рекламе и/или подписках.

petrovichtim
20.03.2019 07:27Google поглотил Impermium, команда перешла в Google
Вот Вы и описали трудоустройство в Google не через собеседования
Yoooriii
20.03.2019 22:37+2Тут как повезет. Некоторое время назад Гугл выкупил небольшую компанию в Украине. Люди около года радовались, хотя и не вполне понимали что происходит: зарплату платили а задач не ставили. Через год всех уволили. В чем смысл? А смысл в том, что у компании была небольшая наработка, и Гугл выкупил права на эту наработку, а люди им и #*#*# не нужны были.
andreyvo
19.03.2019 17:14+10smart and gets things done — вот насчет gets things done это хороший вопрос.
Умение проходить гугловские интервью говорит лишь об умении проходить гугловские интервью. Самые комфортные свои работы я находил вообще без дурацких интервью с олимпиадными задачками. Самое короткое интервью заняло три минуты с VP

jawaharlalnehru
19.03.2019 14:01Первое моё собеседование было для меня таким стрессом, что я подумал «Так не пойдёт!». Я решил прокачать этот скилл. Как разработчику Андроид приложений, мне постоянно пишут всякие рекрутеры, грех было этим не воспользоваться. Я решил отвечать на ВСЕ предложения. Итого, за три месяца, что я этим занимаюсь, у меня было около 20 телефонных интервью и пять очных. И я прям чувствую, что стал намного уверенней, расслабленней. Мне стало легче сосредоточиться на решении задачи. Бонусом прокачал английский и получил некое представление о хотелках разных работодателей.

ferzisdis
19.03.2019 16:34Интересно, сколько из 25 собеседований Вы не прошли? Или все были успешными?
jawaharlalnehru
19.03.2019 16:49В основном, это были разговоры с рекрутерами. Я неплохо так завысил ожидаемую зарплату, поскольку всё устраивало и на нынешней работе. Поэтому основная масса отказов была из-за высокой зарплаты. А вот при общении уже с реальными работодателями я завалил два интервью (оба про алгоритмы сортировки) и успешно прошёл три. Одна фирма была стартапом и уже собиралась меня нанять, но тут январь, годовой отчёт инвестору и потеря финансирования. Другая фирма прислала мне готовый контракт с зарплатой на 10% меньше моих запросов и я отказался. Вот в пятницу опять телефон с потенциальным работодателем.

Nitrofen
19.03.2019 17:27+1да суть не в том сколько ты пройдешь, а как быстро адаптируешься к стрессу. вот читаю здесь коменты и офигеваю… програмисты програмисты, а никак самой просто сути не поймут — чем больше таких интервью тем больше подкованней и уверенней становишься… это же не ракетная наука
DMGarikk
19.03.2019 18:06+3не все вокруг экстраверты, для меня например огромный стресс ходить на собеседования, в полной мере я это испытал когда ушёл из сисадминства и 1С в обычный программинг… и если с 1С и сисадминством работа сама меня находила, в программинге пришлось искать самому… с ужасом представляю что через какоето количество лет придется ещё раз проходить через этот процесс…
Nitrofen
19.03.2019 18:09+3так вот именно по этому и нужно практиковать то что боишся, ведь только так побороть страх можно и попроще к этому стрессу относится. Я тоже раньше боялся этого пздц как сильно, но после енного количества встреч и переговоров както ушел страшок и прочие мелочи, стал более сфокусированным на вопросах и ответах. Практика превыше всего и нечего боятся там. За то что пойдете поговорить никто не осудит вас кроме вас самих. По проще нада жить и относится к этому
DMGarikk
19.03.2019 19:06+4За то что пойдете поговорить никто не осудит вас кроме вас самих
вот в этом и проблема кстати если углубляться, сложно для самого себя оказаться лузером
потому что например работаешь на разных работах, получаешь 100500 денег и весь такой уважаемый профи, а потом идешь на собеседование на +20% от твоей ЗП, а тебя начинают валить голой академической теорией как джуна… и в итоге выходишь оттуда… как будто у тебя и нет опыта за плечами и кучи успешных проектов… ты незнаешь основ… и собеседующие смотрят на тебя снисходительно… ну чё ты такой лох то… а потом обсуждают что «ходят черти кто на собеседования, найти нельзя нормальных людей»
Я отлично знаю что все конторы разные, и что бывают неадекватные собеседования как я описал выше… но себя сложно обмануть, ведь реально я не знаю наизусть определения из учебника… и это угнетает морально
==
у меня синдром самозванца, да
не особо спасает даже понимание что я был на двух собеседованиях всего чтобы найти работу не имея коммерческого опыта в (обычном) программинге и вообще не просев даже по зарплате по сравнению с прошлой работой (одинесником, где у меня около 8 лет опыта)… т.е. не-безуспешно тыкался и разочаровалсяNitrofen
19.03.2019 19:40-4ну сударь если так относится к этому то мне вас жаль — ведь получается что вам всего страшно и хрен его знает как вы тогда в жизни вообще… если вы боитесь что какойто чел который видит вас впервые будет чтото думать о вас и вам это важно то… ноу коментс тут. то есть получается вам даже важно что прохожие люди о вас думают… сидите дома а когда идете на работу смотрите тупо в пол и не подымайте глаз
DMGarikk
19.03.2019 20:00+4если бы мне всё было реально так страшно что я тупо в пол на работе смотрю, то я бы никогда бы не добился своего положения нынешнего
Одно дело боятся, другое боятся и делать. я просто описал этот страх и что он реален и более серьёзен чем кажется. Это не помешало мне и иметь оффлайновый бизнес (7 лет и побегать потом с ним по прокуратуре отбиваясь от уголовки когда он развалился) и поработать в куче самых разных отраслей, от ремонта электрооборудования в вагонах до банковского процессинга (в разных отделах)… сейчас вот программинг, от написания успешного сервиса в одно лицо до просто бекенд-программист (вынужденный дауншифтинг в профессии но с повышением зп, для повышения квалификации)
Вы скорее всего экстраверт если не понимаете что это нельзя перебороть усилием мысли… да можно натренироваться, я когда работал с 1С получил навык общения с начальством что меня ни раз выручало… но всёравно подсознательно меня это очень всё угнетаетNitrofen
19.03.2019 20:03оно и будет угнетать. я просто говорю что не нада заострять внимание на этой части а переступать ее. я был в ваших ботинках, и меня тоже угнетало и угнетает любая такая процедурка… но таковы реалии и мы должны просто справлятся с ними. Учитывая ваш опыт вы уже просто ассом должны стать в этом моменте.
fpir
20.03.2019 10:40Вот поэтому человек проходит собеседования, когда не собирается менять работу. Рекрутеры смотрят на соискателя снисходительно, как на джуна и думают, что он им не подходит. А соискатель уже прошёл собеседование и получил работу и смотрит на рекрутёров, как на официантов, пытающихся ему услужить. Психологически, позиции уравновешиваются и стороны на равных. После нескольких итераций такая позиция становится привычной социальной ролью. А теперь вспомните или представьте, как Вы будете проходить собеседование имея 8 лет реального опыта- спокойно, легко, расслабленно. Даже если не знаете чего-то, ответите что-то типа- за 8 лет мне это не понадобилось и в гугле меня пока не забранили. И вполне возможно, что такой ответ устроит работодателя. Так вот, пройдя 10-50-100 собеседований, вы сможете так ответить имея 2 недели опыта и возможно, работодателя это снова устроит.

WraithOW
19.03.2019 20:45+4- Пожалуйста, не надо путать интроверсию и социальную тревогу. Одно не подразумевает другого (хотя часто встречаются вместе).
- Практика как раз хорошо помогает от тревожности. Завалите вы одно собеседование, второе — и в какой-то момент придет осознание того, что ничего катастрофичного в этом нет. Зато каждое хорошее техническое собеседование — это отличный срез своих знаний: чем хорошо владеешь, а где плаваешь.
- Каждое успешно пройденное собеседование даёт мощный плюс к самооценке. Прекрасное чувство.
- Не забывайте — на другом конце стола зачастую сидит такой же человека, как и вы. И, возможно, он волнуется больше вашего.
Удачи!
Yoooriii
20.03.2019 22:51+2Я когда-то неуютно чувствовал себя на собеседованиях, я тогда разослал резюме и з-пл указал на уровне 60-70% от рынка. За месяц — около 40 собеседований. Под конец я уже мог отвечать на вопросы автоматом, не дожидаясь пока интервьюер сформулирует свой вопрос целиком, в том числе и типовые задачки на сообразительность. В принципе ничего нового никто не спрашивал, на 99% все стандартно. А поскольку мне на тот момент уже работа была не нужна, то я и не волновался особо.
Сейчас, если мне нужна работа, то я в первую неделю собеседуюсь в неинтересные мне конторы. Для поднятия тонуса. После этого уже на автомате проскакиваешь.
Я конечно в курсе, что отнимать чужое время не совсем красиво (сколько стоит час программиста итд), но тут дело такое. Либо я в хорошем тонусе попадаю на хорошее место, либо это место занимает кто-то другой.
Ghost_nsk
19.03.2019 14:49Врят ли они просили реализовать именно base64, по сути они просили реализвать перевод из одной системы счисления (256) в другую (64 — автор сам выбрал) на выходе и получится base64 в поправкой на алфавит и некоторые тонкости. Эта задача изучается в одном семесте/четверти с «Привет, мир!».
Tsvetik
19.03.2019 15:51Кажется, перевод в base64 намного проще, чем в систему с произвольным основанием.
tbl
19.03.2019 16:14Я бы сначала написал перевод в произвольную систему счисления, а дальше оптимизировал под base64: выкинуть деления и вычисления остатка, заменив соответственно битовыми сдвигами и наложением битовой маски, ну и работать сразу с триплетами, что делает ненужными умножения и сложения.
Ghost_nsk
19.03.2019 16:25+2Суть задачи именно такая, а вот на способ релизации, будете ли вы использовать длинную арифметику или догадаетесь что при таких основаниях можно оптимизировать до битовых операций и будет смотреть интервьюер.
khim
20.03.2019 06:31Да — но нет. Вы можете примерно с тем же успехом заметить, что дерево — это граф, использовать представление с матрицей смежности и потом поверх вот этого реализовывать какой-нибудь обход в ширину.
Математически — это то же самое, а практически — отличный способ развлечься на интервью и получить отказ.
Всё-таки base64 — это перевод 3 байтов в 4 c помощью битовых манипуляций, а дальше обработка массива в цикле, а не превращение данных в длинное целое и попытка потом реализовать эффективно операции деления.Ghost_nsk
20.03.2019 09:33Програмирование и есть математика.
И кстати, ваша формулировка «c помощью битовых манипуляций» (и картинка с битами в голове) мешает вам же искать другие решения, почему не использовать таблицу? Надо всего то 64Mb памяти, это может внезапно оказаться быстрее плохой реализации с битами.
Потому что: для преобразования одного блока из 3 байт нужна будет только одна операция хоть и дорогая по тактам (примерно mov eax, [tbl + esi]), а для «битовых манипуляций» операций будет на порядок больше, пусть и дешевых.WraithOW
20.03.2019 11:50А как у такого подхода с доступом к памяти? 64 метра в кэш, как мне кажется, не войдут, и miss'ы постоянные будут.
Ghost_nsk
21.03.2019 12:53Для общего случая да, будет в несколько раз хуже, но напрмиер если на входе в основном будут строчные латинские буквы/цифры/пробел/скобки (читай обычный текст) то нужные куски таблицы попадают в кеш и этот способ уже работает быстрее битовых операций.
khim
21.03.2019 17:11Даже скучный «обычный текст» вряд ли уместится в L1. Вот если вы регулярно кодируете пустые файлы — там уже можеть быть выигрыш. Но даже и в этом случае он нифига не гарантирован: L1 выдаёт данные через 3-4 такта, за это время десяток простых операций можно исполнить…
Ghost_nsk
22.03.2019 08:49PoC pastebin.com/MwHy4cF1
на чем было под рукой, размер исходных данных только кратный трем, в примере 30Mb
Random source data: []byte{0x52, 0xfd, 0xfc, 0x7, 0x21, 0x82, 0x65, 0x4f, 0x16, 0x3f}...
Run bitwise 0.053900 s
Base64: Uv38ByGCZU8WP18PmmIdcpVmx00QA3xNe7sEB9Hi...
Run tabular 0.128237 s
Base64: Uv38ByGCZU8WP18PmmIdcpVmx00QA3xNe7sEB9Hi...
Text source data: :d9d fxqpe 0bq9}{mbx3kdadbqf8 ...
Run bitwise 0.042929 s
Base64: OmQ5ZCBmeHFwZSAwYnE5fXttYngza2RhZGJxZjgg...
Run tabular 0.024196 s
Base64: OmQ5ZCBmeHFwZSAwYnE5fXttYngza2RhZGJxZjgg...
Результат не стабильный, но для текста табличный метод всегда быстрее.
datacompboy
22.03.2019 11:55У меня всегда хуже на рандоме ваш пример, и иногда лучше, но чаще хуже на алфавите:
$ ./a
Prepare table
Random source data: []byte{0x52, 0xfd, 0xfc, 0x7, 0x21, 0x82, 0x65, 0x4f, 0x16, 0x3f}...
Run bitwise 0.040010 s
Base64: Uv38ByGCZU8WP18PmmIdcpVmx00QA3xNe7sEB9Hi...
Run tabular 0.118122 s
Base64: Uv38ByGCZU8WP18PmmIdcpVmx00QA3xNe7sEB9Hi...
Text source data: :d9d fxqpe 0bq9}{mbx3kdadbqf8 ...
Run bitwise 0.033740 s
Base64: OmQ5ZCBmeHFwZSAwYnE5fXttYngza2RhZGJxZjgg...
Run tabular 0.037435 s
Base64: OmQ5ZCBmeHFwZSAwYnE5fXttYngza2RhZGJxZjgg...
А если добавить в алфавит еще и большие буквы, то сразу становится стабильно не пыщпыщ:
Text source data: Ds1OwN"G}nUKsDeVtsZjbd"mqv:YlA...
Run bitwise 0.034508 s
Base64: RHMxT3dOIkd9blVLc0RlVnRzWmpiZCJtcXY6WWxB...
Run tabular 0.052095 s
Base64: RHMxT3dOIkd9blVLc0RlVnRzWmpiZCJtcXY6WWxB...
tbl
20.03.2019 19:28Так вам над этим 64-метровым числом надо повторять операцию деления на 64 до тех пор, пока в частном не получится 0, т.е. 87 миллионов раз. Операция деления таких длинных чисел занимает большое время, вам нужно вручную пройтись по всем разрядам (пусть даже вы будете обрабатывать по 64 бита за раз), аккуратно делая переносы остатка с разряда на следующий разряд. Навскидку, сложность предложенного вами решения получается O(n^3). Битовый же энкодер base64 даёт O(n), причем без тяжеловесной для CPU операции деления.
khim
21.03.2019 01:18+1Вы вообще, похоже, не поняли предложения. Три байта — это число от 0 до 16777215. Так как нам нужно эти три байта преобразовать в четыре, то мы можем просто массив сделать и туда смотреть.
Проблема в том, что вы этим решением убъёте нафиг кеш, как WraithOW
написал — и при этом ещё и получите ужасную скорость (64MB ни на одном современном процессоре ни в один кеш не влезут, а за время обращения в память процессор может выполнить порядка тысячи инструкций).
Однако если его чуть-чуть модифицировать и использовать три таблички по паре килобайт — то есть уже шанс вписаться в L1 кеш, однако, во-первых, не факт, что пользователям вашей процедуры так уж понравится, что вы существуенную долю кеша заняли, а во вторых — тут уже всё равно будут нужны дополнительные манипуляции и не факт, что будет выигрыш.Ghost_nsk
22.03.2019 11:24Даже без модификаций, на огрниченном алфавите (например текст на одном языке) может давать выигрыш. Выше выложил proof of concept.

slava_k
19.03.2019 15:39+9Google не единственная компания на планете, хотя для разработчиков под Android быть частью такой компании это идеальный пункт в резюме. С другой стороны, это даже хорошо, что у этой компании столь замороченный и сложный процесс собеседования, мало связанный с реальной повседневной работой. Это означает, что у конкурентов Google как минимум есть хорошие шансы найти себе в команду качественных разработчиков вроде Вас, кто умеет видеть задачу и способны в ней детально разбираться. Ну и в компаниях поменьше Google можно быстрее вырасти и добиться своих целей (меньше ступеней в иерархии должностей с мЕньшими ограничениями по переходу выше).
Тут еще не факт, что в итоге больше потеряли (в плане возможностей) от такого итога собеседования именно Вы, а не Google. В истории довольно много примеров, когда провалы на собеседованиях в одной компании становились причиной роста числа или силы конкурентов такой компании.andrei_mankevich Автор
19.03.2019 16:05+4Спасибо, очень приятный комментарий! :)
Хотя точно могу сказать, что мне подготовка пошла все-таки в плюс. Теперь каждый раз когда пишу код, автоматом думаю о сложности O(n). Раньше такие вопросы приходили в голову только если что-то медленно работало и это дело надо оптимизировать.slava_k
19.03.2019 17:08+2Тренировки мозга и навыков по алгоритмам это всегда полезно. Ну и важно помнить о балансе в вопросах оптимизации. Идеальный код это хорошо, но в нынешнем мире капитализма он не самоцель, иначе это необязательная потеря времени, ресурсов и конкурентоспособности.

dollar
19.03.2019 19:12По-моему, как раз уже пора делать ставку на близкий к идеалу код. И я сейчас говорю не столько про оптимизацию, сколько про размер готового продукта и баги в нём. Хотя эти 3 вещи сильно коррелируют, так что все 3 важны.
slava_k
19.03.2019 21:12+3В моем опыте за десяток лет пока только один случай, когда ставка именно на серьезный рефакторинг кода и его качественное улучшение существенно сыграла по деньгам.
Своеобразный случай, потому как продукт готовили на продажу уже как небольшой по доходу и работающий бизнес. Сначала проект пытались продать AS IS, с проблемами не только в коде, но и в документации API, серьезными проблемами в момент пиковых нагрузок от клиентов и прочими прелестями. Продажа не состоялась, цену продукта примерно ожидали в $180..200k (копейки).
После окончательной потери надежды продать или привлечь доп средства на развитие, владелец этого бизнеса чуть позже случайно познакомился с командой, которая занималась консультированием и private TPA (частный техаудит проектов), ребята предложили помочь оценить самые дорогие проблемы в проекте и потратить полгода на его доведение до стабильно работающего состояния за 20% от конечной стоимости повторной продажи. Команда у них также была своя (4-5 человек примерно) + несколько временно привлекаемых консультантов по AWS и лоеры для аудита схем монетизации. За несколько месяцев было все донастроено по инфраструктуре, далее переписаны криво реализованные сервисы, протестировали уже дополненные тесты, дописали доки.
Была возможность слегка поучаствовать в этом и наблюдать со стороны. Сравнивая визуально репу старого проекта и репы нового, кода стало раз в 10 меньше, сервисов (API endpoints) тоже поубавилось, тестов различных появилось много (нагрузочные), внедрена автодокументация на javaDoc, поправлена старая. Короче технически проект был причесан и вылизан очень грамотно.
После всего, через год в сумме (из-за ожидания каких-то конкретных эвентов, типа бизнесс-выставок и встреч) у проекта появилось несколько покупателей, им был передан отчет по аудиту и проделанной работе, также переделанные основные доки по проекту и в конечном итоге после аукциона его продали за $1.8m (сильно больше ожидаемого). Проект по тематике довольно нишевый, связанный с оптимизацией логистики, страхования, хранения и перевозки грузов. Далее через год этот проект уже выкупила одна из продуктовых сетей (кажется Kroger) за $4m. Да, за прошедший год у проекта появилась другая команда.
По сути на старте проекту сильно повезло как в плане того, что конкурентов особо не появилось за все это время изменений, так и в плане случайных совпадений и знакомств, которые вытащили бизнес из глубокой дыры (финансовой и развития).
Во всех остальных, довольно многих случаях, попытки просто улучшить код, рефакторить все с самого начала, затягивая развитие самих бизнес-процессов — всегда приводили к одному и тому же: начинающие проекты со временем становились просто никому не нужны, так как быстро появлялись конкуренты и просто забирали целевые ниши. Что с такси, что с хостелами, что с сервисами самокатов или чего-то более серьезного. Попробуй в таком окружении встань на feature freeze на месяцок, ага.
Так что первые версии продуктов, вернее где-то первый год существования бизнеса в рынке — сервисы/продукты, увы, всегда будут жрущими ресурсы и тормозящими, но выполняющими те бизнес-процессы, которые приносят доход и действительно нужны. И только они сначала улучшаются, после идут уже всякие улучшения в UI use-cases, разбор и оценка качества пользования сервисом, размеры бинарников, network traffic shaping и прочее. Поэтому либо так, либо на рынке будет существенно меньше выбора. Если он будет вообще.
Nagg
19.03.2019 23:33Знание Base64 сразу выделяет людей, которые интересуются simd :) ибо это по сути одна из тренажерных задачек.
datacompboy
20.03.2019 01:45+2Но… Но если подумать? Base64 — это упихивание бинарных данных в печатные символы.
64 намекает что мы используем 64 символа, 6 бит. НОК(6, 8) = 24. То есть каждые 3 байта можно нарубить на ровные 4 символа.
Это как перевести в 64-ричную систему исчисления указанное число.
itoa же можете реализовать? ну вот ровно так же, только не по основанию 10, а по основанию 64…
Homo97Sapiens
20.03.2019 23:19+1Сотрудник одной компании рассказывал про собеседование вчерашней студентки. Не вдаваясь в подробности, компания в основном использует C#, из натива — максимум C++, при этом у девушки по нисходящей начали спрашивать про C, Asm и «завалили» её только на вопросах о физической реализации ЭВМ.
Компания выглядит адекватной, и я сомневаюсь, что девушка из-за незнания принципа работы транзисторов не попала на работу, однако, думаю, она испытала немалый стресс. (Я бы испугался, если бы почувствовал, что человек специально ищет тему, на которой можно меня завалить)

xPomaHx
19.03.2019 19:05+1А кто зафейлил тока непонятно. Собеседование это функция которая принимает людей и дает тру фолс, если она на тех может решать рабочие продуктовые задачи дает фолс значит фейлит она, в данном случае гугл.
wataru
20.03.2019 13:18+1Ну, гугл может позволить себе false positive. У них всегда очередь из кандидатов. Все интервью — просто костыли, попытка предсказать то, что можно измерить только постфактум, посмотрев на результаты работы человека на новом месте после нескольких месяцев. Ошибки там всегда будут.
OnYourLips
19.03.2019 20:49+3А мне показалось, что вопрос сильно отличается от типовых задач в сфере. В результате работу получают люди, которые умеют писать алгоритмы, а не качественный поддерживаемый код в своей области (на многие библиотеки гугла без слез не взглянешь).

rpiontik
19.03.2019 15:36+16Вообще, я не сильно понимаю тягу работать в гугле. Не… не… в целом то мне понятен смысл этого. Но какие у вас ожидания? Что там ТАКОГО будет? Что не позволяет ТАКОГО достичь самому?
У меня была пара случаев в жизни, когда предоставлялся шанс пройти стажировку в Microsoft. Тогда о гугле не знали даже. Когда я интересовался порядком приему на работу у меня все желание проходило сразу. Куча каких-то условностей, что-то там ты должен, что-то не должен. Че-то там раз в год я обязан менять должность, если я не росту я автоматом увольняюсь. Бла, бла, бла… политика и т.п.
Оба раза я отказался. После первого отказа даже какие-то сожаления были. Особенно когда друзья узнали и говорили, что я эм… не умный. Но второй раз (это было по окончанию 3го курса) я уже осмысленно это делал. У меня были интересные проекты и мне откровенно не хотелось заниматься тем, что скажет мне «дядя».
Я почитал статью, было потрачено много времени. Судя по тексту. Причем, с пониманием того, что вы делаете. То, что вы не ответили на простой вопрос, это ооооочень распространенная ситуация. И она зачастую игнорируется грамотным hr. Невозможно все в голове держать, с чем ты не работаешь постоянно. Скорее всего, вы столкнулись с корпоративной машиной. Скорее всего, вы рассматривались на уровне обычного кандидата. Такого же, как если закинуть резюме иными путями. Отсюда шаблонный подход к общению с вами.
Если есть суровое желание работать в гугле, просто продолжайте туда стучаться. Я уверен, что это вполне реальная цель при вашем подходе.
Но, ИМХО, это не стоит того. Самореализация на собственном проекте куда как интересней.andrei_mankevich Автор
19.03.2019 16:01+10Насчет корпоративной машины и шаблонного подхода так и было, но другого пути у них в принципе не существует.
Когда-то Макса Хоувел (разработчика Homebrew) не взяли в Google. Он по этому поводу такой твит выдал:
Google: 90% of our engineers use the software you wrote (Homebrew), but you can’t invert a binary tree on a whiteboard so fuck off.
Я уже немного наелся самореализации, хотелось обратно в уютный мир, где каждый месяц за работу платят деньги :) Увы, пока не сложилось.
KirutNdert
19.03.2019 20:42+3Прошел собеседования и отказался от предложения переехать в Дублин аналитиком данных, из-за того, что хотел дальше учиться в аспирантуре но главное — на этой работе я бы не смог расти, осваивать новые инструменты. Смог бы только работать с инструментами внутренними, которые не факт что выкинут на рынок. В итоге терял бы в рыночной стоимости и в долгосрочной перспективе остался бы в проигрыше. Да и за названием «аналитик данных» скрывалось полу-ручная проверка рекламы и сайтов 80% времени. Хотя зарплата разработчика, пакет акций в комплекте, переезд оплачен.
senya_z
20.03.2019 10:14В Гугл интересно сходить хотя бы для того, чтобы понимать, каково это — работать на лучшей в мире инфраструктуре. Где унифицирован тулсет — единый кодбэйз репозиторий (с парой-тройкой исключений), единая билд-система, единый тулинг для мониторинга, пуша в прод и прочее. Ну и плюс — работать с множеством умных людей, от которых постоянно можно чему-то учиться — тоже далеко не так часто встречается.
rpiontik
20.03.2019 11:11Несомненно. Но еще интересней это сделать самому. В проекте, который для тебя «родной» и ты в праве участвовать в его развитии. Практически все, что вами описано — вполне достижимые цели. Более того, они нужны для выпуска качественного продукта в заявленные сроки. Ко всему, стоит обратить внимание на путь развития гугла. Ведь он же интенсивно поглощает идеи. А рождаются они, за его периметром.
Все потому, что интегрировать в себя готовый продукт легко. Он понятен, документирован, есть четкие сроки, оценка трудозатрат и т.п.
Т.е. это скорее селектор и концентратор технологий, а не драйвер. Возможно я в этом ошибаюсь, но по той информации, которую я имею, складывается такое впечатление.senya_z
20.03.2019 21:57инфраструктура, о которой я говорю, как раз вся сделана внутри. «сделать все самому» означает работу над инфраструктурой вместо работы над продуктом. то есть, можно конечно все делать самому, а можно пользоваться инфраструктурой для работы над продуктами и фокусироваться именно на этой работе.
да и про легкость интеграции — это только кажется, что все это легко. посмотрите, к примеру, на майкрософт — сколько продуктов куплено и погублено (нокия, скайп, ...). казалось бы — что сложного?rpiontik
20.03.2019 23:07-1Инфраструктуру вместо работы...? не понимаю… Возможно я какой-то неправильный, но я не разделаю развитие одного от другого. Это обоюдно необходимые вещи. И инфраструктура, по хорошему, должна соответствовать продукту. Отсюда — развитие продукта = развитие инфраструктуры.
Если есть желание быть кодером, когда за тебя все решено… ну что ж, это тоже выбор, достойный уважения.
Что касается — только кажется и Микрософт. Загубить можно все. Не принимать в расчет очевидность параметров готового решения оправдывая это некомпетентностью процесса интеграции, не самый верный путь.senya_z
20.03.2019 23:20Инфраструктуру вместо работы...? не понимаю… Возможно я какой-то неправильный, но я не разделаю развитие одного от другого. Это обоюдно необходимые вещи.
Если у вас сотни продуктов, писать тулинг под каждый из них выходит слишком накладно. Мы ведь здесь говорим конкретно о Гугле — вот конкретно в Гугле инфраструктура общая для всех. Запустить примитивный сервис во множестве регионов на инфраструктуре Гугла у вас займет меньше часа. Ваша задача — делать сервис, а не решать проблемы деплоймента во множество датацентров, чекина кода в репозиторий только после прохождения каких-то тестов и получения апрувалов от ревьюеров, лоудбалансинга и прочих вещей. Вы все это получите бесплатно. Делать это все на уровне каждого продукта — просто неэффективно. Поэтому инфраструктура и продукты разделены. Но опять же — хотите работать над инфраструктурой — пожалуйста. Хотите работать над продуктами — милости просим. Хочется поделать одно, потом другое — можно менять команды, ну или тратить 20% своего времени на любые другие задачи помимо вашей основной работы (это сейчас реже практикуется, но все еще существует).
Если есть желание быть кодером… ну что ж, это тоже выбор.
Почему вы считаете работу над продуктом «желанием быть кодером» — тоже не очень ясно. Работа над продуктом включает множество составляющих. И сбор требований, и дизайн, и согласование разных моментов с партнерами (upstream callers, downstream service providers), и планирование, и релиз — далеко не только кодинг.
roman_kashitsyn
20.03.2019 22:22+1единый тулинг для мониторинга, пуша в прод и прочее.
Нет, тулинга в всегда как минимум два — один deprecated, а другой красивый, но пока толком не работает, причём вам нужно срочно на него переехать.
Ну и для пуша в прод вариантов гораздо больше, чем 2.senya_z
20.03.2019 22:33обычно да, два )) одно депрекэйтед, другое допиливается. но суть в том, что каждой команде не надо изобретать свой велосипед. ну и есть исключения. скажем, замены боргу не предвидится, код-ревью и билд — тоже в единственном экземпляре.

Dgolubetd
19.03.2019 15:39+5Я был бы очень зол если мне на ТЕЛЕФОННОМ интервью дали бы такой вопрос…
Побуду кэпом: нужно было при подготовке к собеседованию учесть специфику конкретного отдела, в данном случае DroidGuard. Видимо они там занимаются более низкоуровневой разработкой, поэтому и такой вопрос.andrei_mankevich Автор
19.03.2019 16:03+2Я вот об этом не подумал, поэтому такого вопроса не ожидал :) А вообще вопрос очень логичный в контексте проекта DroidGuard. Битовые операции, все дела.
Anton23
19.03.2019 19:06+1Кстати, вот статья про прием на работу в гугл. Вы можете кстати через год попробовать еще раз
habr.com/ru/company/google/blog/378507/#habracut
datacompboy
20.03.2019 02:01Кстати я пробовал задавать вопросы, подразумевающие битовые операции. Быстро перестал и ушел на более простую алгоритмику — графы, динамика.
Как мне кажется, довольно специфический навык.
Но учитывая, что резюме пришло через реверс, вполне вероятно тоже бы задал что-нибудь более низкоуровневое… Правда, не знаю как бы прошло. Есть интерес сыграть в ролевую игру тренировочного интервью? :D
Ставка: по приколу, так что нервов и напряга должно быть меньше

BalinTomsk
19.03.2019 19:04+2Мне по телефону предложили обяснять как бы я запрограмировал алгоритм решения игры пятнашки. Только позже я узнал что по алгоритмам игры написаны более десятка книг.

Julegg
20.03.2019 13:02А если не секрет, вы тогда к какому выводу самостоятельно пришли? Я пытался сам додуматься минувшей зимой и меня хватило лишь на A-Star, которую я в последствии попытался заменить на IDA-star (не смог с двух попыток в реализацию и отложил всё в ящик).
khim
20.03.2019 17:08Именно поэтому вам предложили описать, а не написать.
Это хорошая задачка на «поговорить». В пятнашках 20 триллионов вариантов, так что имея кластер её можно решить полностью.
А можно два поиска в ширину «навстречу друг другу» отправить. А можно тот, который «с конца» заранее рассчитать.
Там есть о чём поговорить! Именно этим задача и интересна: готового единственного «правильного» ответа нету и можно смотреть в какие области более склонен идти кандидат.
Никто не ожидал от вас, что вы знаете все теории, воздвигнутые вокруг этой задачи — как раз если бы вы их знали пришлось бы быстренько переключиться на что-то другое!
Anton23
19.03.2019 15:49+2Ребята, вы гении, если вы туда смогли попасть! Серьезно. Я не представляю, как можно пройти через эту полосу препятствий.
datacompboy что скажете?(я видел ваш пост про интервью, но все же)
Ну и про саму статью. Очень интересно услышать ваш комментарий.datacompboy
20.03.2019 02:05А что тут скажешь? Я уже писал всё что знаю по интервью :) Да, проходят не все.
Я проходил по приколу без ожиданий — подозреваю, это помогло =)
nsuvorov
19.03.2019 16:54+7Да и фиг с ним, с гуглом! Зато получили незабываемый опыт и наверняка ещё здесь напишут вам. Удачи!
kzhyg
19.03.2019 17:47+1В итоге, для чего нужна эта штуковина? Не слишком приятно иметь в телефоне такой чёрный ящик.
andrei_mankevich Автор
19.03.2019 21:08+1В двух словах — для проверки настоящий у вас телефон или это эмулятор.

andvary
19.03.2019 17:51+3Спасибо за статью!
Мне понравился ваш подход — хотел пройти собеседование, готовился, но не вышло. Так редко пишут, чаще бывает — «да не очень-то и хотелось, и вообще после отказа я понял, какие они дураки там».
А когда через год вам перезвонят и снова пригласят пройти собеседования — вы согласитесь?andrei_mankevich Автор
19.03.2019 20:36+5Честно говоря, я после отказа наоборот понял, что в таком интервью куда больше смысла, чем в стандартных вопросах про Android SDK и про всякий синтаксический сахар Kotlin. Мне хоть и обидно, но их подход вполне оправдан. Завтра выйдет новый фреймворк, а фундаментальные знания не устареют.
Я пока пару лет делал игры на Unity, так в Android успела революция произойти: вместо Java пришел Kotlin, RxJava стал золотым стандартом, Android SDK распался на Android Jetpack Components… Ничего, все можно довольно быстро освоить. Даже сертификат получил красивый от Google.
Насчет перезвонят я так скажу. Собеседование я проходил чуть больше года назад :) Не перезвонили. Но я им сам недавно повторно написал. Если посмотреть правде в глаза, они мне нужнее, чем я им: Google в резюме — он такой один, а из таких как я у них очередь стоит.
Aingis
20.03.2019 12:39+1Очередь может и стоит, но если бы там было всё так хорошо, вакансии быстро бы заполнились. Так что не надо оглядываться на очередь. Имеет смысл смотреть только на требования друг к другу — подходят они или нет.
khim
20.03.2019 17:11Вакансии не заполняются потому, что нет необходимости их быстро закрыть. Соответственно из сотни кандидатов берут 2-3 (но тут стоит учесть не только то, что требования высокие, но и то, что из-за громкого имени все, кого выгнали за то, что они три строчки написать не могут в Гугл тоже собеседования).
entilza
19.03.2019 18:33-3отлично отомстил )
andrei_mankevich Автор
19.03.2019 18:35+3А почему «отомстил»? Я свое обещание (не болтать лишнего) в целом-то сдержал. Кода виртуальной машины нет, как работает интерпретатор не рассказал… А вся остальная информация и так была в интернете — про запрос, про protobuf, про apk и так далее. Разве что про спрятанные сообщения никто не писал.
entilza
19.03.2019 18:40ну после публикации на хабре про эту пасхалку, народ может ринуться проходить тем же путем и что и ты прошел и посылать им запросы на устройство в гугл. получается их идея с привлечением гениев способных найти пасхалку будет не состоятельной и им придется придумывать другую.
andrei_mankevich Автор
19.03.2019 18:42+1А смысл? :) Это же не дает ровным счетом ничего, никаких преимуществ. Если нет знакомых работающих в Google, можно просто попробовать в linkedin написать кому-нибудь и попросить отправить резюме эйчарам. Будет ровно такой же результат.

Knightt
19.03.2019 18:35+6А меня вот прям бесят такие вопросы на собеседованиях не_для_джуниоров…
Они написали человеку сами, значит нашли его по шагам той истории, когда он ковырял их продукт, и поковырял неплохо так. Т.е. у человека есть опыт решения задач, где-то сложных где-то не очень. И тут вопрос про реализацию base64… Если заглядывать под капот каждой функции которую используешь — то так и будешь под этим капотом сидеть, а не задачи бизнеса решать!
У меня опыт работы не большой, 5 лет примерно. Но когда мне на собеседовании на веб-разработчика(!) предложили на бумажке реализовать алгоритм поиска простых чисел и бинарную сортировку — я от туда убежал (после института, я эти алгоритмы с закрытыми глазами мог написать, НО за 5 лет коммерческой веб-разработки ни в одной задаче не было даже намеков на простые числа и на реализацию бинарной сортировки — и все забылось).tyomitch
19.03.2019 18:53+4Такие вопросы — это хорошо известная особенность Google.
Если вас такие вопросы прям бесят, значит Google для вас не подходит, а вы не подходите для них.

zodchiy
19.03.2019 19:37+5на бумажке реализовать алгоритм поиска простых чисел и бинарную сортировку
И правильно сделал. Все это жадность, получить мидла за денежку джуна, или сеньора за денежку мидла (я не про ваши конкретные вопросы).
У меня как-то, лет 5 назад было собеседование на позицию мидла .net в наших топ 5 интеграторах, я туда пошел уже просто для опыта собеседований (год шлялся, еле нашел). Стандартный набор — интерфейс vs абстрактный класс, boxing / unboxing, напиши пузырьковую сортировку, async/await, using, бла-бла-бла и прочий шлак из собеседований, думаю, чета они про шаблоны проектирования забыли, ан нет, напишите реализацию синглтона. Ок, пишу. И тут прорвало — напишите на бумажке еще 5 реализаций синглтона, назовите и опишите все паттерны из книги Desing patterns, бинарные деревья, какие-то реализации низкоуровневых блокировок, алгоритмы аппроксимации пиков, и все дальше и глубже.
Я не выдерживаю и спрашиваю — что, неужели они у них мидлы такие, все это знают?
В ответ, гордо — У нас все мидлы уровня сеньеров!
Я, офигевая — Что? А получают они как мидлы?
Не задумываясь, и еще гордее — Да!
Ясно-понятно, до свиданья.dtho-dtho
20.03.2019 13:01+1А я лучше бы на бумажке реализовывал алгоритмы.
Я как раз таки хорошо умею делать велосипеды и быстро разбираюсь в новых либах.
Но как то решил попробовать с С++ пересесть на С#. С ним я и до этого работал, но в основном с .Net core.
Тут предложили на одну фирму поработать. В итоге им все эти фундаментальные знания, знания алгоритмов и прочее — нафиг не нужно. Им нужно на зубок знать весь .Net винды.
ASP .Net, Entity Framework, MVVM, MFP, MVC и т.д.
А когда я говорил, что писал асинхронные сервера на .net core на сокетах, писал врапперы во круг собственных сишных либ — они смотрели как на иродиевого.
Ни о каких хэштаблицах, деревьев, сортировок, обход графа, алгоритмов поиска, методов оптимизации и прочего речи и близко не было.khim
20.03.2019 17:16В данном случае то, что вас не взяли — это ж не хорошо, это просто прекрасно!
Вы бы друг друга просто не поняли. Причём в обе стороны: вы бы пытались строить велосипеды там, где есть готовые функции, а ваши коллеги городили бы страшные многотонные конструкции, тем, где можно обойтись велосипедиком на 100 строк.
Эти два рода деятельности сегодня настолько разошлись, что вот то, что им было нужно — получило отдельное название: application engineer. И да, такие Гуглу тоже нужны — но это отдельная вакансия!
AlexSmall
19.03.2019 22:33+4предложили на бумажке реализовать алгоритм поиска простых чисел и бинарную сортировку
Такие вопросы задаются чтобы понять способны ли вы выражать свои мысли внятно и понятно. Есть ли у вас представление о «велосипедах» и можете ли вы их «изобретать». Я тоже в свои проекты набираю людей способных отвечать на такие вопросы. И они гораздо важнее мартышкиных знаний о фрейворках и конкретных методах библиотек.
Задача на интервью — понять способен ли человек мыслить, или он «конечный автомат» ;).Nexus7
19.03.2019 23:11+3Вот, я, например, могу пользоваться топором. Знаю, как сделать топорище, даже видел сам процесс его изготовления из берёзового полена. Видел по телевизору, как работают кузнецы, как резать и формировать металл вокруг наковальни. Смогу нажечь угля из дров или набрать каменного угля, я знаю, как он выглядит. Смогу сделать кирпичи, чтобы сложить небольшую доменную печь. Но вот загвоздка, я не знаю, как выглядит железная руда. Реально не знаю, может когда и видел, но не догадывался что это именно она.
Так кто вам больше нужен: лесорубы, которые делают конечный продукт, или кузнецы, шахтёры, металлурги, геологи? Если мне надо посмотреть на реализацию Base64, то я быстро найду Base64.java в том же Android. Но не каждый Senior, а тем более Middle знает, что бывают другие, более эффективные кодировки типа Base85, или более простые типа Hex. А уж вопрос какую где лучше применять сможет поставить в тупик даже интервьюера ;)
Чтобы проверить, что человек умеет мыслить, то ему надо дать задание по конкретной теме, например, тестировщикам я предлагал придумать 10 способов разбить стакан, стоящий на соседнем столе, а все без исключения разработчики делали тестовое задание очень близкое к тому, чем они потом будут заниматься. Сразу было видно, знает ли человек нужный нам язык или фреймворк.tyomitch
19.03.2019 23:22+2То задание проверяло не «заучил ли кандидат наизусть реализацию base64», а как раз наоборот — «как кандидат подойдёт к решению незнакомой задачи».
alsii
21.03.2019 18:21В таком случае «правильным» должен быть такой ответ: «я возьму готовую реализацию, а не буду заниматься строительством велосипеда за счет моего работодателя».
khim
21.03.2019 20:31+1Прекрасный, великолепный, достойный ответ для application enginer'а — но тогда уж, если вы ничего сами писать не хотите, вы должны знать готовые библиотеки, которые это умеют.
А если вы библиотек не знаете и как рашать задачу без них — тоже, тогда что же вы умеете? Произносить умные слова?alsii
22.03.2019 12:50+1Так в предыдущем комментарии написано, что проверяющему не интересно, «заучил ли кандидат наизусть реализацию base64». А интересно «как кандидат подойдёт к решению незнакомой задачи». Вот я и пишу, что прежде всего при поступлении задачи нужно изучить имеющиеся решения и оценить их применимость для нашего случая. И только если они по каким-то причинам неприменимы разрабатывать собственное решение. Это и есть «подход к решению». Ну по крайней мере нас так в институте учили. И да, по образованию я инженер-системотехник.
> вы должны знать готовые библиотеки
Такие знания статичны. Если всегда механически применять полученные когда-то знания, то в результате получится: «знаю один фреймворк (библиотеку) и сую его (ее) во все проекты».
AlexSmall
19.03.2019 23:31+1Интересный пример, но не релевантный. Речь идет о том, а умеете ли вы пользоваться топором, или только бензопилой? И более того, а способны ли вы заправить бензопилу когда в ней кончится бензин? Знаете ли вы что кроме бензина, туда еще и масло надо заливать? :).
Это если мне дровосеки нужны.
Ну и я не говорю еще о том, что сейчас часто встречаются люди не знающие что «руда» из вашего примера в принципе существует...
Что же касаемо программистов, сейчас развелось человеков, которые думают, что если они выучили пару языков, научились быстро гуглить готовые решения на «стэке» и заучили немного умных слов, то теперь они программисты. Вот таких мне и надо отсеять на интервью. Мне в проекте нужны люди способные решить поставленную задачу оптимальным способом придумав решение именно моей задачи. А не нагуглив его.
Давать на собеседовании реальные задачи из проектов нельзя, по многим причинам. Но главное это их нетривиальность — просто не успеешь обьяснить задачу :). Потому и придумыаются поостые шаблонные «всеми забытые» базовые задачи, при этом они темне менее показывают способность мыслить или помнить — если учился хорошо ;) в универе...Nexus7
20.03.2019 00:04Обычно в разговоре на собеседовании сразу становится понятно, надо ли давать человеку тестовое задание, которое лишь повторяет какой-то уже реализованный кусок реального проекта, но мы не рассказываем ему, откуда такая задача взялась.
А человеки с умными словами обычно отсеиваются ещё на стадии чтения этих слов в их резюме. Типа «сетевые протоколы: HTTP, JSON, XML» ;)
И ещё очень полезно посмотреть, на какие паблики они подписаны.
Всё это множество люков-автобусов и прочих пузырьковых сортировок происходят в основном из-за неспособности интервьюеров придумать что-то своё. Или хотя бы обратить внимание, как человек краснеет, двигает ногами, смотрит и говорит. То, что он не сумел решить какую-то теоретическую задачку не говорит о том, что он будет плохо работать. Тут уже было массу статей про плохие интервью. Меня самого один раз не взяли в довольно крупную контору из-за того, что зевнул пару раз, потому что было реально скучно проходить обследование у десятка человек, никак не связанных с моей будущей должностью.
Ну и на крайний случай, если промахнулись, есть испытательный срок, благо в этой стране он по закону достаточно длинный. Честно, ни разу не применялся, обычно люди уходили сами в более тёплые места.
PS. могу купить, разобрать и собрать бензопилу
PSS. могу точить цепи от бензопил ;)

TimsTims
20.03.2019 01:53а способны ли вы заправить бензопилу когда в ней кончится бензин? Знаете ли вы что кроме бензина, туда еще и масло надо заливать?
Нет, никогда не держал в руках бензопилу, никогда масло ей не менял, бензин не заливал.
Но я понимаю, зачем она нужна, как работает, где она применима, а где нет. И если вдруг, мне нужно будет ей вдруг(!) воспользоваться, я достану инструкцию, распилю несколько досок (возможно и кривовато), но выполню свою работу.
Да, я не задрот бензопилы, и опоры будут кривоваты, но зато работа будет выполнена. Если построенный дом окажется востребованным клиентами, то можно будет кривые доски и перезапилить ровнее. А если дом окажется ненужным(нет клиентов), то и не жалко было потраченного времени. MVP во всей красе. Вам шашечки(мастер бензопил), или ехать(человек, умеющий быстро осваиваться)?
Конечно же, если бы я работал на пилораме, то мне просто необходимо было бы владеть бензопилой. Но чаще всего, кроме бензопилы, нужно знать про 100500 инструментов, какие они бывают, и какой лучше где применить. Архитекторы зданий например, не все держали в руках инструменты, а кто держал — наверняка не все инструменты на свете. Но это не мешает им строить дома, и делать свою часть работы.
решить поставленную задачу придумав решение именно моей задачи. А не нагуглив его.
Стоп, вы платите людям, чтобы они ваши желания исполняли так, как вы желаете? Тогда это скорее ваши рабы. Или вы хотите, чтобы они делали вместе с вами работу, и зарабатывали для вас деньги? Если второе, то какая разница — нагуглили они, или взяли полуготовые библиотеки из гитхаба?
показывают способность помнить — если учился хорошо
Знаю много противоположных примеров, кто учился плохо, ничего с универа не помнит, но понимает, что нужно заказчику, выдаёт готовые продукты в короткие сроки, и именно так как просил заказчик. Поэтому у меня обратное мнение — тот, кто помнит отлично универ — либо гений, либо у него синдром отличника.khim
20.03.2019 06:49И если вдруг, мне нужно будет ей вдруг(!) воспользоваться, я достану инструкцию, распилю несколько досок (возможно и кривовато), но выполню свою работу.
А как вы поймёте, что ей нужно воспользоваться? Вам начальник скажет? Так в Гугле нет начальников, дающих вам техзадание описывающих в деалях какими подходами пользоваться…
Знаю много противоположных примеров, кто учился плохо, ничего с универа не помнит, но понимает, что нужно заказчику, выдаёт готовые продукты в короткие сроки, и именно так как просил заказчик.
Но у Гугла ведь нет заказчика…TimsTims
20.03.2019 09:03А как вы поймёте, что ей нужно воспользоваться?
Вот же писал:Но я понимаю, зачем она нужна, как работает, где она применима, а где нет.
Но у Гугла ведь нет заказчика…
Зато есть потребители, и если ты не понимаешь, что им нужно, то твой код никому не нужен.

Neikist
20.03.2019 09:34Если второе, то какая разница — нагуглили они, или взяли полуготовые библиотеки из гитхаба?
Я так понял человек пишет о том что нагуглить или взять полуготовое не выйдет так как его просто не существует.
AlexSmall
21.03.2019 01:24Стоп, вы платите людям, чтобы они ваши желания исполняли так, как вы желаете? Тогда это скорее ваши рабы.
Да, я хочу чтобы они делали для меня работу наилучшим возможным образом и с первого раза. Потому что второго шанса «продать» не будет.
Есть такие работы, где во первых ничего нет на гуглах/гитхабах, во вторых вариант «и опоры будут кривоваты, но зато работа будет выполнена» вообще не допустим. Потому что от этого не какие-то там клиенты «не купят», а зависит чья нибудь жизнь.
ПС. Вас бы я на работу не взял :). Принцип «Good enough» у нас категорически не приветствуется.
bkar
20.03.2019 15:47+3— Наливаем в стакан кипящее масло из фритюрницы.
— Запускаем в комнату ребёнка, отбираем мобилку, запрещаем разбивать стакан.
— Достаём из кармана гранату. Бросаем её в стакан.
— Играем стаканом в футбол.
— Накрываем стол до конца. Играем свадьбу.
— Приглашаем жену и любовницу. Привязываем к поясам гантельки на верёвочках. Устраиваем весёлый свадебный конкурс – кто первым попадёт гантельной в стакан.
— Наливаем в стакан метиловой незамерзайки. Не разбился? Ну вот мы и прошли один из тестов, который стакан выдержал.
— Находим подходящий подшипник. Натягиваем в тугую на стакан. Кидаем их в жидкий азот.
— Берём перфоратор и высверливаем дырками имя любимой девушки.
— А теперь то же самое – только лазером. И помощнее.
— Загоняем в вибратор. Прогоняем по всем частотам.
— Используем в качестве изолятора. Хватит 40 киловольт.
— Кидаем стакан в бардачок теслы. Запускаем теслу в космос. Ждём.
— Просто ждём. Если ждать достаточно долго…
— Подходя с чисто философской точки зрения, стакан уже разбит.
— Хотя если по-настоящему абстрагироваться, то стакан не только уже разбит, но и ещё разбит.
— Нельзя наполовину разбить стакан. Или можно?
— Бросаем в стакан чёрную дыру.
— Запускаем в комнату трёх тестировщиков, трёх котов, трёх псов с привязанными к хвостам консервными банками, Киркорова и агил. Выключаем свет.
— Подгоняем танк.
— Осторожно, аккуратно, деликатно, выбрасываем стол в окно.
— Поджигаем стол.
— Ставим стакан в сейф Шредингера.
— Расплавляем стакан, отливаем из него стеклянный хер. Выдаём дураку под расписку его и пару защитных перчаток.
— Отпиливаем у стола все ножки. Тем самым защищаем объект от разбивания в состоянии «стояния на этом столе».
— Стучим по стакану карандашом, по звуку проверяем, а не разбит ли он уже.
— Спорим в пьяной компании, что стакан можно засунуть в … да что там… тут все программисты..., в сраку. При попытке извлечения стакан разбивается. Реальный случай. Я лежал в одной палате с человеком, который пострадал, поводя эксперимент. У него были сломаны нос, нога и челюсть. Так что соблюдайте технику безопасности, если соберётесь повторить.
— Становимся Президентом России. Жмём большую красную кнопку.
— Если не помог предыдущий пункт — отсылаем Креосану.
— Просто засовываем в посылку и посылаем почтой России.
— Засовываем в посылку, платим за объявленную ценность в 100 000р и посылаем почтой.
— Берём стакан на митинг по защите… ну вы меня поняли.
— Обеспечиваем в комнату свободный доступ. Каждую ночь наливаем в стакан 100 грамм водки. Повторяем до ожидаемого эффекта.
— Привязываем к ножке стола ноги секретарши будущего босса. Начинаем кидать в неё замороженные какахи. Или лучше незамороженные. Для чистоты эксперимента.
— Прибиваем стакан гвоздём к столу.
— Забиваем стаканом гвоздь в стол.
— Забиваем столом стакан в гвоздь.
— А у вас ещё есть стаканы? А то меня ещё столько вариантов осталось!
— Отдаём задание на аутсорс.
— Объявляем конкурс на поставку 10 битых стаканов.
— Делаем из стакана секундный маятник. Чтобы… да неважно, что, процесс изготовления так выбесит…
— Подгоняем 1000т пресс. Сбрасываем пресс на стакан.
— Берём две ровные сухие сосновые дощечки. Ставим между ними стакан. Сверху аккуратно ставим слона. Сбрасываем на них пресс.
— Вбиваем в стакан черенок лопаты. Доливаем пива по вкусу.
— Предлагаем просто взять, просто взять и сломать мой богатырский меч о стакан. Если возьмут на работу.
— Устраиваем в комнате просмотр инсталляции. Внезапно объявляем приз в 1000р за лучший перфоманс.
— Закладываем на вертолёте крутой вираж. Стакан соскальзывает со стола. Если не разбивается, делаем мёртвую петлю.
— Наполняем комнату водой. Одеваем акваланг. Ныряем. Обматываем стакан тухлым мясом. Выныриваем. Заныриваем в комнату акулу.Nexus7
20.03.2019 16:09Гениально!
И ведь некоторые из собеседуемых не могли придумать и пяти способов.
Передал тестировщикам, боюсь теперь они до конца дня будут хихикать ;)
greenhack
19.03.2019 19:52+2Знаете, по поводу неудачного (?) собеседования, пожалуй тут многое зависит от того, кто вас собеседует. Что-то мне подсказывает, что в гугл попадают люди и с куда меньше компетенцией, чем у вас.
А вообще после таких статей хочется забухать…
Maccimo
20.03.2019 20:48+2А вообще после таких статей хочется забухать…
Вы же понимаете, что желание «забухать» ненормально по определению, вне зависимости от надуманной причины?
Реверс виртуалки — интересная техническая задача, плюс.
Последующее собеседование — пища для размышлений, тоже плюс.
Прошли собеседование — отлично, не прошли — ну и фиг с ним. Проще нужно ко всему относиться.
У меня от прочтения статьи исключительно положительные впечатления.

lanseg
19.03.2019 20:19+2В Гугле в Цюрихе хорошо платят — гугл+швейцария стоило того, чтобы попробовать. Другое дело, что слишком хорошо выступить на собеседовании тоже чревато.

Antares19
19.03.2019 22:48+1Чем чревато?
lanseg
19.03.2019 23:22+5Испорченными нервами и заниженной профессиональной самооценкой. Я довольно неплохо прошёл собеседование и меня взяли, если подходить объективно, на уровень выше, чем я заслуживал и для меня «сказочный гугл» обернулся жуткой нервотрёпкой.
Лучше бы я поступил на уровень попроще, на зарплату поменьше и развивался бы до текущего уровня, получал бы удовольствие от новых знаний и сохранял нервы, а не держался бы через силу.
С «испытанием» я справился, но очень уж пришлось напрягаться.nanshakov
20.03.2019 11:39+1Не хотите рассказать подробнее?
lanseg
20.03.2019 12:24+1Нет. Как написал в комментах ниже — оклематься бы и нервы поправить, а то заклюют ведь — для многих Гугл это до сих пор сказочное место, куда набирают гениев, где задачи интересные, work-life balance идеален, а жизнь приятна и похожа на праздник.
Мои проблемы будут выглядеть нытьём зажравшегося «тракториста».Thahr
20.03.2019 13:33Про собеседование вы уже рассказали в комментарии habr.com/ru/post/419945/#comment_19016677 — за него огромное спасибо. А могли бы на организационные вопросы ответить?
1. Какие есть возможности релокации из Цюриха в штаты (L1/H1B), или не интересовались?
2. Про гугл много пишут что они предлагают средний total compensation, но с competitive offer могут сильно ее поднять. Так ли это?lanseg
20.03.2019 13:39+21. Я ни в коем случае не хочу в штаты и противился бы всеми силами, если бы меня туда отправляли. В Швейцарии намного лучше ситуация как с жильём, так и с транспортной доступностью офиса.
2. Даже не задумывался. Когда мне выдали оффер, зарплату сразу предложили даже больше той, за которую я планировал торговаться.senya_z
21.03.2019 00:09В Швейцарии намного лучше ситуация как с жильём, так и с транспортной доступностью офиса.
кроме калифорнийского кампуса есть еще вашингтонский (сиэтл-керкленд). там и с жильем, и с доступностью офиса пока получше калифорнийского. его тоже можно рассматривать в качестве варианта.
senya_z
20.03.2019 22:03+11. можно переехать по L1 через год, и на H1B тоже тут же подадут (там уже зависит от удачи — получишь или нет). и гринкард файлят сразу.
2. сложно сказать. выше среднего наверное, но не прям заоблачно. и да, оферы от других компаний очень сильно помогают с поднятием.

naething
21.03.2019 07:30Про гугл много пишут что они предлагают средний total compensation, но с competitive offer могут сильно ее поднять. Так ли это?
Да, это везде так, и гугл не исключение. Никто не будет вам сразу давать жирный офер (особенно если вы приходите не из FAANG) — надо немного поторговаться, и офер от другой компании лучшее для этого средство.
naething
20.03.2019 11:58+1Выше — это L5 против L4?
lanseg
20.03.2019 12:18+1Да нет, всего лишь L3-L4. Мне кажется, я тянул на «upper L3» — у меня было всё отлично с техническими навыками, но в области софт-скиллов и «бюрократии» — написании дизайн-доков, оценке приоритетов и планировании всё было так себе, потому что на предыдущем месте эти навыки пусть и требовались, но не так сильно. И импакт, конечно же, куда уж без импакта.
С командой и менеджером повезло — думаю, они довольно быстро смогли оценить мой реальный уровень, но решили, что я смогу подтянуться.
Об L5 я, пока, даже не задумываюсь — оклематься бы.naething
21.03.2019 06:30По-моему у вас классический impostor syndrome, как они это сами называют. Хороших технических навыков вполне достаточно должно быть на L4. Не дайте им себя запугать всеми этими формальными требованиями — это делается, чтобы вам было можно меньше платить :). Некоторые знакомые мне L5 совершенно не умеют писать дизайн-доки, оценивать приоритеты и планировать, но тем не менее стабильно получают meets expectations из года в год и не парятся.
То, что вас взяли на уровень выше, — это однозначно плюс, поскольку не надо лишний раз проходить через промо (вот там будет реальная нервотрепка). Еще, говорят, очень сложно уволить человека из гугла.senya_z
21.03.2019 06:43на пятом все же положено уметь и дизайн-доки писать, и приоритеты оценивать, и планировать. другое дело, что meets expectations внутри гугла хорошим рейтингом не считается. он как бы второй снизу (после needs improvement). хотя если особых амбиций нет, то можно в в принципе на meets expectations на пятом хоть всю жизнь провести.
naething
21.03.2019 07:35+1Всё так. Я просто к тому, что на деле эти формальные требования сильно относительны, и уважаемый lanseg слишком сильно парится и себя недооценивает, на мой взгляд. Хотя, конечно, я не знаю деталей его конкретной ситуации.
khayrov
21.03.2019 12:52+1Вот то же самое хотел написать, только постеснялся «диагноз по фотографии» ставить. Как можно понять в первые полгода из-за чего у тебя проблемы с планированием, от недостатка опыта или потому что любая простейшая задача требует длительных раскопок эзотерической инфраструктуры? Кроме того, если у lanseg нет конкретного инсайда от интервьюеров или комитета (надеюсь, что нет), то я очень сомневаюсь, что результаты интервью повиляли на hiring level.
senya_z
21.03.2019 19:40бывают случаи, где интервьюеров просят дать рекомендацию в том числе и по уровню, и в таких случаях результаты интервью влияют на уровень.
Thahr
20.03.2019 13:00Планирую активно начать подаваться в FAANG, было бы интересно узнать про ваш опыт. Как я понимаю, уровень определяется больше не на algorithms (leetcode-задачки), а на system design? Или ошибаюсь?
senya_z
20.03.2019 22:07+1уровень изначально определяется вашим опытом (количеством лет, над чем работали, и т.д.). дальше под уровень набирается набор интервьюеров — они должны быть способны понять, тянете ли вы на этот уровень или нет. на начальные уровни дизайна может и не быть. на высокие уровни — да, решает дизайн и в некотором роде behavioral. Хотя если окажется, что задачи вы решать совсем не умеете, то интервью тоже провалите.
в целом, полезно с рекрутером заранее про уровень все обговорить. если вас интересует 5-6 в гугле, то стоит заранее убедиться, что вам луп не на 3-4 устраивают.
geisha
19.03.2019 20:30+2Есть даже такая легенда: однажды один программист загуглил «mutex lock», а вместо результатов поиска попал на страницу foo.bar, решил все задачи и устроился на работу в Google.
У меня сейчас в закладках foo.bar висит. Никак не соберусь поиграть. На работу в гугл не собираюсь, к тому же, после этого фубара такая же головомойка как и у самых рядовых кандидатов.andrei_mankevich Автор
19.03.2019 20:39+1А его же вроде сейчас прикрыли (временно):
foobar is currently down for extended maintenance. If you'd like to be notified when we are back online, please sign up here.
Но вообще да, все эти приколюхи никаких преимуществ не дают. У Гугла все равны.
orion76
19.03.2019 20:59+1Хм… подобные вопросы для собеседования отлично подходят для тестирования студента, после прохождения соответсвующего курса, на качество усвоения этого самого курса.
Наверное и вопросы сплагиатили из тестовых вопросов этих самих курсов.
После десятка лет работы в специфичных предметных областях, большая часть неиспользуемой в работе «теории» забывается, зато в предметных областях ориентируешься так, как будто получил соответствующее образование в данной области.
А про кодирование последовательности байт в 6-ти битную «символьную кодировку» и про прочие сортировки пузырьками можно за пару минут и википедии прочитать.tbl
19.03.2019 21:21+4В жизни всякое встречается в прикладной разработке (в том числе и в кровавом ынтерпрайзе, не говоря уже о гуглах): редко, но за свою карьеру мне пригождались знания, полученные в институте по курсам: "стохастические процессы", "теоретическая механика", "теория управления", "линейная алгебра". Не думаю, что я смог бы решить те задачи, не имея знаний, и даже не зная, что искать в википедии.
wataru
20.03.2019 14:09+1А про кодирование последовательности байт в 6-ти битную «символьную кодировку» и про прочие сортировки пузырьками можно за пару минут и википедии прочитать.
Проблема с алгоритмами в том, что не зная их, разработчик даже не подумает, что эту задачу можно решить таким-то методом. Будет какой-нибудь полный перебор всобачивать. Или сортировать списки квиксортом, ведь в вики написано, что это быстая сортировка.
А про кодирование последовательности байт в 6-ти битную «символьную кодировку» и про прочие сортировки пузырьками можно за пару минут и википедии прочитать.
А когда нужно не 6 бит, а какие-нибудь 5 бит? Надо представлять как это работает, чтобы хотя бы знать, что можно адаптировать base64, только не 3 байта в 4 перобразовывать, а 5 в 8.
Если человек не может понять, что как тут можно битовую последовательность нарезать на кусочки для base64, то и эта новая, уникальная задача займет слишком много времени или вообще будет неподъемна.orion76
22.03.2019 12:39Возможно я не совсем понятно «сформулировал».
Я не имел ввиду что можно начать программировать, прочитав по данной теме пару статей в википедии.
Каждый «мастер» должен знать если не все то почти все про возможности «инструмента», которым работает.
А вот тонкости-подробности способа решения какой-либо, редко встречающейся, задачи можно «освежить» и в соответствующей документации.wataru
22.03.2019 12:47+1Ну какие тут тонкости? Или человек додумается до разбиения на биты, хоть и с подсказками, или — нет. А тонкости особо не важны. Если кандидат -1 где-то в коде не поставит, пустит 2 последовательных цикла вместа одного, или забудет про граничное условие, то я подскажу. Это минус, но не красный флаг.
Nick_Shl
19.03.2019 21:11+1Через 3 дня после звонка я получил письмо, в котором мне сообщали, что собеседовать дальше меня не хотят
Ну не хотят — как хотят. На работу не взяли, NDA не подписали! Можно смело выкладывать исходники!tyomitch
19.03.2019 22:05+1Ради чего их выкладывать? Просто чтоб напакостить?
Лучше их продать плохим парням!Nick_Shl
21.03.2019 01:23-1Не напакостить, а отомстить! Не хотят, что бы распространялась — могли принять на работу(человек-то согласен и явно способный) и подписать NDA. А хорошая статья на английском с сырцами вполне может принести вакансию в какой-нибудь фирме занимающейся безопасностью.
SiliconValleyHobo
19.03.2019 23:24-6Инженеры-программисты делятся на два типа:
1) Неосиляторы — те, кто ноют, что в гугле (подставить любую компанию из Долины) спрашивают задачки на простенькие алгоритмы для джунов
2) Разумные — те, кто понимают, как на самом деле проходят интервью в топ кампании, зачем они имеют такой формат и как они на самом деле оцениваются.
Разумные легко попадают в желаемую компанию если не с первого, то со второго или, на худой конец, с третьего раза.
Неосиляторы ноют. В редких случаях из-за сильного университетского бекграунда они попадают в желаемую компанию. ЧСХ, потом они оттуда валят, потому что «все не то и все не так».

LevOrdabesov
20.03.2019 01:25+1Весьма интересно!
Вам не приходило в голову, что это послание – не приглашение? Вы копали код защиты. Можно предположить, что вы нашли ещё один слой защиты, только на этот раз – психологический. Потенциально вас могли и взять, но главная цель, вполне возможно, была иная – отвлечь от взлома некоторую часть ломающих, используя в качестве наживки авторитет компании. Проверить и «отсобеседовать» их, взять на заметку, убедительно попросить не разглашать.
Главное, вполне сработало.orion76
20.03.2019 08:28Кстати до, очень похоже, сразу обратил внимание что «приглашения» чересчур восторженно-навязчивы.
Определенно тут приложили руку психологи «отдела безопасности»-)LevOrdabesov
20.03.2019 10:52+1Наверняка об этом знать нельзя, конечно. Разве что сотрудник-ренегат через сто лет в мемуарах расскажет.
Но, судя по фактам, получилось именно так.
На мысли наводят даже не приглашения, а холодный приём сразу после них.
Письмо от члена команды DroidGuard было довольно лаконичным: «Зачем ты этим вообще занимаешься?»
Совсем не похоже на «О, это наш человек!». Это «прям-очень-сильно-занятый-сотрудник-боооольшой-сеееерьёзной-компании» хмуро смотрит «ну кто там опять ковыряется, задолбали».andrei_mankevich Автор
20.03.2019 12:53+1Я все-таки должен отметить, что само общение было очень вежливым и корректным :) Но общение ограничилось вопросом «зачем», взыванию к совести и благоразумию и просьбой не шарить наработки с плохими людьми.
andrei_mankevich Автор
20.03.2019 12:50+1Скажем так, я немного дальше зашел, чем эти сообщения. Дальше там тоже ничего интересного нет, к сожалению. Цели полностью симулировать работу DroidGuard у меня не было. Плюс у Google есть отличная возможность ответного хода — просто обновить эту нативную библиотеку, и все наработки по реверсу превратятся в тыкву.
anprs
20.03.2019 08:41Ребята, вы гении, если вы туда смогли попасть! Серьезно. Я не представляю, как можно пройти через эту полосу препятствий.
У меня знакомый туда таки попал. Они выкупили стартапчик вместе с конторой, и сотрудниками которые его пилили.roman_kashitsyn
20.03.2019 15:36+1Они выкупили стартапчик
Есть такая полу-шутка, что единственный способ заниматься чем-то действительно интересным в Гугле — пилить интересный стартап, который потом купит Гугл.
senya_z
20.03.2019 23:31это способ стать богатым. а если интересного хочется — ну так переходите в другую команду, продуктов же море. да, далеко не все есть в цюрихе, возможно, придется переехать, но выбор все же огромный.
roman_kashitsyn
20.03.2019 23:40Не, мне и в Цюрихе хорошо. Проект у меня вполне себе интересный, грех жаловаться.
Чтобы стать богатым, достаточно запромоутиться до L7.
Fafnir
20.03.2019 09:02Мне повезло, мне попался вопрос, который я заранее видел в интернете и который я уже решал перед собеседованием.
Не могу сказать наверняка, но, скорее всего, в этом и была проблема. Надо было честно об этом сказать. Интервьюэр работает с этим вопросом и представляет насколько сложно в него врубиться с первого раза. На телефонном интервью не оценивают ваши навыки, смотрят на потенциал и на очевидные red flags. Если умолчать, что знаете вопрос — это сразу red flag. Вам самому нравится работать с людьми, которым не доверяешь?
Нет никакой проблемы в том, чтобы не решить задачку, тут важен процесс. Насколько вы были вовлечены, насколько задавали хорошие вопросы. Как у вас вообще с софт скиллз? Возможно, вы недооцениваете этот компонент.andrei_mankevich Автор
20.03.2019 12:41+2Хороший вопрос про софт скиллз. Недооцениваю, факт :) Я все время считал, что главное — это техническая часть и решить все задачи. Но мне уже объяснили, что не совсем так (особо для Google).
Ghost_nsk
20.03.2019 10:21+1Никто не заметил что задача была сериализовать массив строк?
Решение:
1. придумать разделитель
2. экранировать в строках этот разделитель и возможно спец символы (если есть)
3. склеить строки с этим разделителем
Использование base64 для строк даст только экранирование спец симвлов (если они вообще есть) и увеличение размера на треть. Дальше интервьюер пытается направить на правильный путь, зная как работает предложенный вариант можно было бы понять что это так себе решение, но и тут пустота. Два вопроса — два не правильных ответа, есть смысл продолжать?andrei_mankevich Автор
20.03.2019 12:39+1Так я вроде и не писал, что я — недооцененный гений, а интервьюер спрашивает какую-то ерунду :) Все было честно и справедливо, а Google — просто не мой уровень. Это нормально, люди разные. Если бы все были одинаково умные, то как бы в Google попадали лучшие?
geisha
20.03.2019 17:08Знание base64 — не показатель уровня, скорее всего дело было в другом.
А вообще, в качестве разделителя можно использовать нуль-символ, так что мудрить с base64 необязательно.tyomitch
20.03.2019 17:37Это если нуль-символа нет внутри строки.
geisha
20.03.2019 18:38Зачем тогда их называть строками? Если нет символа конца данных — просто по ходу хэша считаем размеры, добавляем в конце каждого из массивов.
tyomitch
20.03.2019 18:59+2Зачем тогда их называть строками?
Кроме Си, на свете есть и другие языки.
добавляем в конце каждого из массивов
В начале. А иначе вы этот конец потом не найдёте.geisha
20.03.2019 19:39В конце тоже можно, инфа 100%. Если найдёте коллизию — отправлю 500 рублей вотпрямщас.
Почему это важно? Хотя бы потому, что если приходит 30 Тб строк — вам не нужно ничего сохранять и хэш считается на лету как ему и положено.
Чувствую себя собеседующим в гугле.tyomitch
20.03.2019 19:52+1Не понимаю, при чём тут хэш, вроде бы никто до вас о хэшах не говорил.
Но не важно. Вот вам две строки:
"\0\1\2" + 30 Тб повторений '\2'
"\0\1\2" + 30 Тб повторений '\2' + "\1"
Первая — это "\0\1" (длиной 2 символа) и за ней 10 трлн строк "\2\2" (длиной 2 символа каждая).
Вторая — это "\0" (длиной 1 символ), за ней 10 трлн строк "\2\2" (длиной 2 символа каждая), и в конце "\2" (длиной 1 символ).
Результат — вы не можете вычленить первую из сериализованных строк до того, как прочитаете все 30 Тб.
Sergery8205
20.03.2019 11:56Все равно вы молодец — такую работу проделать. Желаю вам удачи в будущем!
speshuric
20.03.2019 20:18+1Просто любопытно стало, что именно имеется в виду под «программа похожая на Hex-Rays IDA»? Это конкретная программа, которую вы почему-то не хотите называть или IDA, которой у вас «как бы нет»? :)
Thahr
21.03.2019 14:54Мне повезло, мне попался вопрос, который я заранее видел в интернете и который я уже решал перед собеседованием.
Если не сложно, какой вопрос был первый? Не точная формулировка, а примерно.andrei_mankevich Автор
21.03.2019 16:40+1Задача была всегда одна — сериализовать массив строк.
Thahr
21.03.2019 17:22+1Сорри, невнимательно прочитал. Спасибо еще раз за описание вашего опыта.
Конечно жалко, что рускоязычное комьюнити мертвое в плане взаимопощи в подготовке к подобным собеседованиям. Крохи на dou.ua и здесь не в счет. Китайцы, например, подробно описывают как они проходят интервью, решают вместе задачки, делятся опытом как выбить больше денег и т. п. и т. д. Ваша задачка кстати в топ 70 на литкоде по тегу Гугл, если по частоте попадания на интервью отсортировать за 2 года. Но вы наверняка даже не знаете про литкод, т. к. смотрите выше про мертвое комьюнити.datacompboy
21.03.2019 17:39+2как видите, задача простая, решение известное, но все эти задачи имеют бесконечную глубину и отростки — всегда можно найти точку где человек не знает и начать смотреть как он будет решать её, а не вспоминать.
Thahr
21.03.2019 17:55+1В идеальном интервью вопрос будет, например, такой. Но я много читал про случаи, когда просто требуют написать быстро код для решения конкретной задачи уровня medium+/hard без особых follow up questions
datacompboy
21.03.2019 23:57У меня получается без follow up только если совсем во время не вписываемся, но при этом кандидат хорошо описывает что думает. Тогда лучше дослушаю, чем дам решение.
Если кандидат знает задачу, она так легко идёт, что я уверен, не все могут заметить смену курса. :) надеюсь, по крайней мере.
andrei_mankevich Автор
21.03.2019 17:56+1вы наверняка даже не знаете про литкод
Да не то чтобы я был прям такой дремучий :)
Вот сейчас открыл глянуть свою статистику — 60 задачек на литкоде я решил, пока готовился. Много информации о прохождении собеседования, в том числе и на русском языке. На английском еще больше, это же не проблема.
Ну и может не совсем насчет комьюнити… Но мне уже два человека отписались из Цюрихского офиса Google, посоветовали как лучше готовиться и т. д. Так что взаимопомощь есть.
barbanel
Follow the
white rabbitgreen droid, Neo.