

ProxylessNAS напрямую оптимизирует архитектуры нейронных сетей для конкретной задачи и оборудования, что позволяет значительно увеличить производительность по сравнению с предыдущими прокси-подходами. На наборе данных ImageNet нейросеть проектируется за 200 GPU-часов (в 200?378 раз быстрее аналогов), а автоматически спроектированная модель CNN для мобильных устройств достигает того же уровня точности, что и MobileNetV2 1.4, работая в 1,8 раза быстрее.
Исследователи из Массачусетского технологического института разработали эффективный алгоритм для автоматического дизайна высокопроизводительных нейросетей для конкретного аппаратного обеспечения, пишет издание MIT News.
Алгоритмы для автоматического проектирования систем машинного обучения — новая область исследований в сфере ИИ. Такая техника называется «поиск нейронной архитектуры (neural architecture search, NAS) и считается трудной вычислительной задачей.
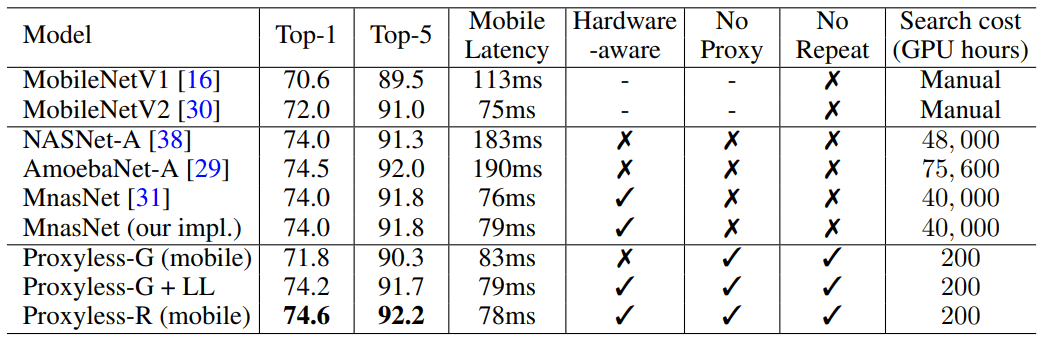
У автоматически спроектированных нейросетей более точный и эффективный дизайн, чем у тех, которые разработаны людьми. Но поиск нейронной архитектуры требует действительно огромных вычислений. К примеру, современный алгоритм NASNet-F, недавно разработанный Google для работы на графических процессорах, занимает 48 000 часов вычислений на GPU для создания одной свёрточной нейросети, которая используется для классификации и обнаружения изображений. Конечно Google может параллельно запустить сотни графических процессоров и другого специализированного оборудования. Например, на тысяче GPU такой расчёт займёт всего двое суток. Но подобные возможности есть далеко не у всех исследователей, а если запускать алгоритм в вычислительном облаке Google, то это может влететь в копеечку.
Исследователи MIT подготовили статью для Международной конференции по обучению (International Conference on Learning Representations, ICLR 2019), которая пройдёт c 6 по 9 мая 2019 года. В статье ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware описывается алгоритм ProxylessNAS, способный напрямую разрабатывать специализированные свёрточные нейросети для конкретных аппаратных платформ.
При запуске на массивном наборе данных изображений алгоритм спроектировал оптимальную архитектуру всего за 200 часов работы GPU. Это на два порядка быстрее, чем разработка архитектуры CNN по другим алгоритмам (см. таблицу).
Выгоду от алгоритма получат исследователи и компании, ограниченные в ресурсах. Более общая цель — «демократизировать ИИ», говорит соавтор научной работы Сон Хан (Song Han), доцент электротехники и информатики в лаборатории технологии микросистем (Microsystems Technology Laboratories) в MIT.
Хан добавил, что такие алгоритмы NAS никогда не заменят интеллектуального труда инженеров: «Цель состоит в том, чтобы разгрузить повторяющуюся и утомительную работу, которая приходит с проектированием и совершенствованием архитектуры нейронных сетей».
В своей работе исследователи нашли способы удаления ненужных компонентов нейронной сети, сокращения времени вычислений и использования только части аппаратной памяти для запуска алгоритма NAS. Это гарантирует, что разработанная CNN более эффективно работает на конкретных аппаратных платформах: CPU, GPU и мобильных устройствах.
Архитектура CNN состоит из слоёв с регулируемыми параметрами, называемыми «фильтрами», и возможных связей между ними. Фильтры обрабатывают пиксели изображения в квадратных сетках — таких как 3?3, 5?5 или 7?7 — где каждый фильтр покрывает один квадрат. По сути, фильтры перемещаются по изображению и объединяют цвета сетки пикселей в один пиксель. В различных слоях фильтры разного размера, которые по разному соединены для обмена данными. На выходе CNN получается сжатое изображение, скомбинированное со всех фильтров. Поскольку количество возможных архитектур — так называемое «пространство поиска» — очень велико, применение NAS для создания нейросети на массивных наборах данных изображений требует огромных ресурсов. Обычно разработчики запускают NAS на меньших наборах данных (прокси) и переносят полученные архитектуры CNN на целевую задачу. Однако такой метод снижает точность модели. Кроме того, одна и та же архитектура применяется ко всем аппаратным платформам, что приводит к проблемам эффективности.
Исследователи MIT обучили и протестировали новый алгоритм на задаче классификации изображений напрямую в наборе данных ImageNet, который содержит миллионы изображений в тысяче классов. Сначала они создали пространство поиска, которое содержит все возможные «пути» CNN-кандидатов, чтобы алгоритм нашёл среди них оптимальную архитектуру. Чтобы пространство поиска поместилась в память GPU, они использовали метод под названием «бинаризация на уровне пути» (path-level binarization), который сохраняет только один путь за раз и на порядок экономит память. Бинаризация сочетается с «обрезкой на уровне пути» (path-level pruning) — методом, который традиционно изучает, какие нейроны в нейросети можно безболезненно удалить без ущерба для системы. Только вместо удаления нейронов алгоритм NAS удаляет целые пути, полностью меняя архитектуру.
В конце концов, алгоритм отсекает все маловероятные пути и сохраняет только путь с наибольшей вероятностью — это и есть конечная архитектура CNN.
На иллюстрации показаны образцы нейросетей для классификации изображений, которые ProxylessNAS разработал для GPU, CPU и мобильных процессоров (сверху вниз, соответственно).

zim32
Кто ж работать то будет