
На прошлой неделе я написал статью о бесполезности шаблона Репозиторий для Eloquent сущностей, однако пообещал рассказать как можно частично его использовать с пользой. Для этого попробую проанализировать как обычно используют этот шаблон в проектах. Минимально необходимый набор методов для репозитория:
<?php
interface PostRepository
{
public function getById($id): Post;
public function save(Post $post);
public function delete($id);
}Однако, в реальных проектах, если репозитории таки было решено использовать, в них часто добавляются методы для выборок записей:
<?php
interface PostRepository
{
public function getById($id): Post;
public function save(Post $post);
public function delete($id);
public function getLastPosts();
public function getTopPosts();
public function getUserPosts($userId);
}Эти методы можно было бы реализовать через Eloquent scopes, но перегружать классы сущностей обязанностями по выборке самих себя — не самая лучшая затея и вынос этой обязанности в классы репозиториев выглядит логичным. Так ли это? Я специально визуально разделил этот интерфейс на две части. Первая часть методов будет использована в операциях записи.
Стандартные операции записи это:
- конструирование нового обьекта и вызов PostRepository::save
- PostRepository::getById, манипуляции с сущностью и вызов PostRepository::save
- вызов PostRepository::delete
В операциях записи нет использования методов выборки. В операциях чтения же используются только методы get*. Если почитать про Interface Segregation Principle (буква I в SOLID), то станет понятно, что наш интерфейс получился слишком большим и выполняющим как минимум две разные обязанности. Пора делить его на два. Метод getById необходим в обоих, однако при усложнении приложения его реализации будут разными. Это мы увидим чуть позднее. Про бесполезность write-части я писал в прошлой статье, поэтому в этой я про нее просто забуду.
Read же часть мне кажется не такой уж и бесполезной, поскольку даже для Eloquent здесь может быть несколько реализаций. Как назвать класс? Можно ReadPostRepository, но к шаблону Repository он уже имеет малое отношение. Можно просто PostQueries:
<?php
interface PostQueries
{
public function getById($id): Post;
public function getLastPosts();
public function getTopPosts();
public function getUserPosts($userId);
}Его реализация с помощью Eloquent довольно проста:
<?php
final class EloquentPostQueries implements PostQueries
{
public function getById($id): Post
{
return Post::findOrFail($id);
}
/**
* @return Post[] | Collection
*/
public function getLastPosts()
{
return Post::orderBy('created_at', 'desc')
->limit(/*some limit*/)
->get();
}
/**
* @return Post[] | Collection
*/
public function getTopPosts()
{
return Post::orderBy('rating', 'desc')
->limit(/*some limit*/)
->get();
}
/**
* @param int $userId
* @return Post[] | Collection
*/
public function getUserPosts($userId)
{
return Post::whereUserId($userId)
->orderBy('created_at', 'desc')
->get();
}
}Интерфейс должен быть связан с реализацией, например в AppServiceProvider:
<?php
final class AppServiceProvider extends ServiceProvider
{
public function register()
{
$this->app->bind(PostQueries::class,
EloquentPostQueries::class);
}
}Данный класс уже полезен. Он реализует свою ответственность, разгрузив этим либо контроллеры, либо класс сущности. В контроллере он может быть использован так:
<?php
final class PostsController extends Controller
{
public function lastPosts(PostQueries $postQueries)
{
return view('posts.last', [
'posts' => $postQueries->getLastPosts(),
]);
}
} Метод PostsController::lastPosts просто просит себе какую-нибудь реализацию PostsQueries и работает с ней. В провайдере мы связали PostQueries с классом EloquentPostQueries и в контроллер будет подставлен этот класс.
Давайте представим, что наше приложение стало очень популярным. Тысячи пользователей в минуту открывают страницу с последними публикациями. Наиболее популярные публикации тоже читаются очень часто. Базы данных не очень хорошо справляются с такими нагрузками, поэтому используют стандартное решение — кеш. Кроме базы данных, некий слепок данных хранится в хранилище оптимизированном к определенным операциям — memcached или redis.
Логика кеширования обычно не такая сложная, но реализовывать ее в EloquentPostQueries не очень правильно (хотя бы из-за Single Responsibility Principle). Намного более естественно использовать шаблон Декоратор и реализовать кеширование как декорирование главного действия:
<?php
use Illuminate\Contracts\Cache\Repository;
final class CachedPostQueries implements PostQueries
{
const LASTS_DURATION = 10;
/** @var PostQueries */
private $base;
/** @var Repository */
private $cache;
public function __construct(
PostQueries $base, Repository $cache)
{
$this->base = $base;
$this->cache = $cache;
}
/**
* @return Post[] | Collection
*/
public function getLastPosts()
{
return $this->cache->remember('last_posts',
self::LASTS_DURATION,
function(){
return $this->base->getLastPosts();
});
}
// другие методы практически такие же
}Не обращайте внимания на интерфейс Repository в конструкторе. По непонятной причине так решили назвать интерфейс для кеширования в Laravel.
Класс CachedPostQueries реализует только кеширование. $this->cache->remember проверяет нет ли данной записи в кеше и если нет, то вызывает callback и записывает в кеш вернувшееся значение. Осталось только внедрить данный класс в приложение. Нам необходимо, чтобы все классы, которые в приложении просят реализацию интерфейса PostQueries стали получать экземпляр класса CachedPostQueries. Однако сам CachedPostQueries в качестве параметра в конструктор должен получить класс EloquentPostQueries, поскольку он не может работать без "настоящей" реализации. Меняем AppServiceProvider:
<?php
final class AppServiceProvider extends ServiceProvider
{
public function register()
{
$this->app->bind(PostQueries::class,
CachedPostQueries::class);
$this->app->when(CachedPostQueries::class)
->needs(PostQueries::class)
->give(EloquentPostQueries::class);
}
}Все мои пожелания довольно естественно описываются в провайдере. Таким образом, мы реализовали кеширование для наших запросов только написав один класс и поменяв конфигурацию контейнера. Код остального приложения не поменялся.
Разумеется, для полноценной реализации кеширования необходимо еще реализовать инвалидацию, чтобы удаленная статья не висела на сайте еще какое-то время а удалилась сразу. Но это уже мелочи.
Итог: мы использовали не один, а целых два шаблона. Шаблон Command Query Responsibility Segregation (CQRS) предлагает полностью разделить операции чтения и записи на уровне интерфейсов. Я пришел к нему через Interface Segregation Principle, что говорит о том, что я умело манипулирую шаблонами и принципами и вывожу один из другого как теорему :) Разумеется, не каждому проекту необходима такая абстракция на выборки сущностей, но я поделюсь с вами фокусом.На начальном этапе разработки приложения можно просто создать класс PostQueries с обычной реализацией через Eloquent:
<?php
final class PostQueries
{
public function getById($id): Post
{
return Post::findOrFail($id);
}
// другие методы
}Когда возникнет необходимость в кешировании, легким движением можно создать интерфейс (или абстрактный класс) на месте этого класса PostQueries, его реализацию скопировать в класс EloquentPostQueries и перейти к схеме, описанной мною ранее. Остальной код приложения менять не надо.
Однако, осталась проблема с тем, что используются те же сущности Post, которые могут изменять данные. Это не совсем CQRS.

Никто не мешает получить сущность Post из PostQueries, изменить ее и сохранить изменения с помощью простого ->save(). И это будет работать.
Через некоторое время команда перейдет на master-slave репликацию в базе данных и PostQueries будет работать с read-репликами. Операции записи на read-репликах принято блокировать. Ошибка вскроется, но придется много поработать чтобы исправить все такие косяки.
Выход очевидный — разделить read и write части полностью. Можно продолжать использовать Eloquent, но создав класс для моделей "только для чтения". Пример: https://github.com/adelf/freelance-example/blob/master/app/ReadModels/ReadModel.php Все операции изменения данных заблокированы. Создать новую модель, например ReadPost (можно оставить Post, но переместив в другой namespace):
<?php
final class ReadPost extends ReadModel
{
protected $table = 'posts';
}
interface PostQueries
{
public function getById($id): ReadPost;
}Такие модели могут быть использованы только для чтения и их можно безопасно кешировать.
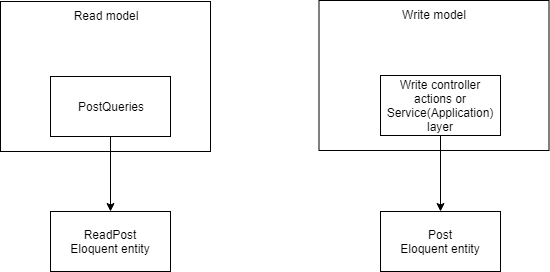
Другой вариант: отказаться от Eloquent. Причин этому может быть несколько:
- Все поля таблицы почти никогда не нужны. Для lastPosts запроса обычно необходимы только id, title и, например, published_at поля. Запрашивать несколько тяжелых текстов публикаций лишь даст ненужную нагрузку на базу или кеш. Eloquent умеет выбирать только нужные поля, но все это очень неявно. Клиенты PostQueries не знают точно какие поля выбраны, без залезания внутрь реализации.
- Кеширование по умолчанию использует сериализацию. Eloquent классы занимают чрезмерно много места в сериализованном виде. Если для простых сущностей это не особо заметно, то для сложных сущностей со связями это становится проблемой (как вам таскать даже из кеша объекты размером в мегабайт?). На одном проекте обычный класс с публичными полями в кеше занимал раз в 10 меньше места, чем Eloquent вариант (там было много мелких подсущностей). Можно при кешировании кешировать только attributes, но это сильно усложнит процесс.
Простой пример как это может выглядеть:
<?php
final class PostHeader
{
public int $id;
public string $title;
public DateTime $publishedAt;
}
final class Post
{
public int $id;
public string $title;
public string $text;
public DateTime $publishedAt;
}
interface PostQueries
{
public function getById($id): Post;
/**
* @return PostHeader[]
*/
public function getLastPosts();
/**
* @return PostHeader[]
*/
public function getTopPosts();
/**
* @var int $userId
* @return PostHeader[]
*/
public function getUserPosts($userId);
}Разумеется, все это кажется диким переусложнением логики. "Возьми Eloquent scopes и все будет хорошо. Зачем придумывать все это?" Для проектов попроще это правильно. Совершенно не нужно переизобретать scopes. Но когда проект большой и разработкой занимаются несколько разработчиков, которые часто меняются (увольняются и приходят новые), правила игры становятся немного иными. Код необходимо писать защищенным, чтобы новый разработчик через несколько лет не смог сделать что-то неправильно. Совсем исключить такую вероятность, конечно, невозможно, но необходимо уменьшать ее вероятность. Кроме того, это обычная декомпозиция системы. Можно собрать все кеширующие декораторы и классы для инвалидации кеша в некий "модуль кеширования", таким образом избавив остальное приложение об информации про кеширование. Мне приходилось рыться в больших запросах, которые были окружены вызовами кеша. Это мешает. Особенно, если логика кеширования не такая простейшая, как описано выше.
Комментарии (19)

evgwed
26.03.2019 22:45Спасибо за статью, было полезно, но есть вопрос.
Если мы говорим о SOLID, то принцип Single Responsibility мы нарушаем при использовании репозиториев вместе с Eloquent.
Ведь при изменении логики модели, нам придется поменять и модель и сам репозиторий ( queries). В итоге, при таком подходе, получаем код, который сложно поддерживать, так так при правке бд придется править и смотреть все в куче мест.
Как быть с этим?
Сам же подход Repository позволяет модели не заморачиваться о том, как ее и где сохраняют. А тут не совсем этого добивается автор статьи. По факту, получились чуть более навороченные scopes.

rapita
27.03.2019 00:10А какой профит вы получаете от использования такого «Repository» + ActiveRecord (паттерн + антипаттерн)?
Может ошибаюсь, но ваш solid от части не solid, во всех местах где вы используете ActiveRecord и тем более Eloquent реализацию ActiveRecord.rapita
27.03.2019 12:29Отвечу сам себе.
Профита — нет.
Это просто проявление творчества над инструментом Laravel и Eloquent в частности. Усложнение восприятия кода, поскольку разработчику могут быть не очевидны мотивы такого решения.
Дублирование точек вызова save и delete, теперь его можно сделать $activeRecord->save() и $repository->save($activeRecord), при чем, repository->save объявлен в коде проекта. У кого то может появится желание его расширить…
Допустим такие репозитории имеют право на жизнь, только без save и delete. Тогда можно подумать, а зачем они в Laravel проекте? Есть же решение которое предоставляет сам Eloquent — это scopes, любому Laravel разработчику будет понятно как работают scopes а если нет, то он сможет почитать об этом в документации.
Извините если я вас как то задел. Может мне слишком накипело за всё время разработки на yii, laravel, symfony. Поддержки проектов после нескольких разработчиков, где первый — использовал свой придуманный Repository, второй — после ухода первого, счел это неуместным, и начал писать что попало и где попало. А ты смотришь на это все спустя какое то время и вспоминаешь их не злым тихим словом. Я и сам не раз пытался применить Repository в yii и laravel, но после знакомства с symfony и doctrine мне перехотелось это делать.
К желающим использовать Repository + ActiveRecord(Eloquent), есть маленькая просьба. Пожалуйста, выбирайте и используйте инструменты по назначению — ведь с проектом над которым вы работаете, будет работать такой же человек как вы, только с другими взглядами на эти инструменты.
Adelf Автор
27.03.2019 13:01Не задели. Написал большое добавление к статье. Может как-то обьяснит мою мысль :)

L0NGMAN
27.03.2019 00:59С удовольствием прочитал бы пост о инвалидации кеша, особенно когда используется паттерн декоратор
Adelf Автор
27.03.2019 01:03Декоратор никак не связан с инвалидацией. Самое простое — генерить нормальные доменные эвенты(PostPublished, PostDeleted) и сбрасывать нужные кеши. Но это не всегда просто. Особенно если закешированы прям целые коллекции сущностей. Поэтому, вероятно лучше для например last posts хранить только id записей и потом делать multi-get к кешу.
L0NGMAN
27.03.2019 01:11Если при генерации кеша в декоратрое создается уникальние ключи per user? Потом где правильно сбрасивать эти ключи? На каком слое, в ивент листенерах? Ну не знаю…
Не зря говорят что инвалидации кеша это один из самых сложных задач для программистаAdelf Автор
27.03.2019 01:18Про ключи per user ничего сказать не могу. Не делал такое. У меня ключ формировался довольно четко и эвент листенер и декоратор спокойно их использовали. Но нужно их генерацию вынести в отдельные классы. А то бывали у нас… несовпадения ключей тех, которые юзали декораторы и тех которые «инвалидировали»

BoShurik
27.03.2019 12:27
Torrion
27.03.2019 15:45Лично для себя я выбрал, возможно громоздкий, но наиболее правильный, на мой взгляд, способ: кеширующий декоратор должен работать не с самим кешом, а с его адаптером, заточенным под конкретную сущность/задачу. Задача инвалидации перекладывается либо на сам адаптер(удобно при активном кеше), либо вобще на отдельный класс, которыей знает про адаптер и декорируемый обьект (удобно при пассивном кеше).
PerlPower
27.03.2019 01:07Бегло прочитал обе статьи и это какое-то наведение тени на плетень. В чем проблема репозитория я так и не понял кроме, того что некоторые их создают там где хватило бы пары строчек выборки в контроллере. Рассуждения про SOLID и CQRS мне кажутся обычным булшитом, под который можно подвести все что угодно. Можно было бы вместо шаблона декоратор сделать шаблон provider, который бы дергал репозиторий или кэш, и к тому же был бы гораздо меньше прибит гвоздями к Laravel.
Обе переведенные статьи выглядят как контент для пиара книги автора, лишь бы написать. Но зачем такое переводить?
symbix
Раз уж мы легким движением руки пришли к CQRS, предлагаю немного продолжить рассуждения на эту тему.
Для меня основной смысл в разделении на команды и запросы с точки зрения работы с базой такой:
1) Write model у нас для некоей сущности Foo одна, которая Aggregate Root в терминах DDD. Это "толстая" модель, содержащая методы бизнес-логики. Типичная команда выглядит как-то так (во избежание холивора опустим вопрос способа работы с domain events):
Никаких геттеров и тем более публичных свойств тут нет за ненадобностью.
2) Read models для ровно того же "foo" у нас от 1 до N, причем более одной запросто может быть даже в одном bounded context-е. А вот здесь нам нужен максимум Query Builder (и, возможно, пригодится примитивный односторонний маппер, умеющий только гидрацию — просто чтобы писать меньше букв, хотя это спорный вопрос, возможно, получится столько же букв в другом месте).
Выходит, и Active Record, и Data Mapper для Read models будут только мешать: нам на выходе все, что нужно, это банальная readonly-структура — и они для разных Read models сильно разные.
Возьмем для примера Хабр, чтобы далеко не ходить. Вот у нас список постов в ленте, а вот у нас список постов справа в блоке "что обсуждают". Что, для того, чтобы вывести количество комментариев, нам разве нужен aggregate root, в котором будет все комментарии? Нет, конечно, мы просто сделаем join, group by и count(), либо подзапрос (оставим в стороне вопрос денормализации). Так зачем нам тут вообще Eloquent model или Doctrine Entity, и куда мы там, простите, засунем comments_count и views_count? Вопрос риторический. А раз для read models они не нужны, то и Repository тут ни к чему, не так ли?
Adelf Автор
Посыл верный. На моем проекте по многим причинам мы перешли к POPO классам для read моделей. В статье же посыл немного иной — «если хочется поиграться с паттернами — то лучше так, а не бесполезный Репозиторий». Не стал статью перегружать ещё и этим. Возможно, зря.
symbix
Я как-то не уловил пользу от таких "репозиториев", которые и не репозитории вовсе, а непонятно что. Никакого принципиального отличия от Eloquent scopes я не вижу — просто зачем-то вынесли скоупы в отдельный класс, как будто это решит проблему нарушения SRP самим (анти)паттерном Active Record (не решит). Аргумент про кэширование вроде бы как бы валиден, но тут все сразу развалится на вопросе инвалидации в случаях чуть сложнее тривиальных.
Единственная польза от таких упражнений, на мой взгляд, в том, чтобы осознать, что присущие Active Record проблемы никакими костылями не исправить, и перестать даже пытаться. :-)
Adelf Автор
Написал большое добавление к статье. Спасибо что подтолкнули.
symbix
По поводу дополнения.
Я не видел еще ни одного крупного проекта с использованием Active Record, который бы не превратился через пару лет в неподдерживаемое месиво, и скоупы с кэшами здесь наименьшая из проблем. Впрочем, и в проектах с Доктриной часто происходит то же самое. Корень проблемы тут я вижу не столько в Active Record vs. Data Mapper, сколько в порочности анемичных моделей как таковых.
Adelf Автор
Ну read-модели по определению анемичны. А write-модели… да. Сложно команду научить и заставить делать write-сущности без геттеров и сеттеров. У меня не получилось.
symbix
Я про write-модели, конечно же.
Без CQRS обойтись без геттеров и не получится, но у вас, вроде как, вон, Read-модели есть. Если и с CQRS не получается, то надо разобраться в том, что мешает.
Fantyk
С удовольствием бы прочел ваше видение применения read/write моделей. В частности как вы видите обновление сложных write сущностей