

Логика машин безупречна, они не совершают ошибок, если их алгоритм работает исправно и заданные параметры соответствуют необходимым стандартам. Попросите машину выбрать маршрут от точки А в точку Б, и она построит самый оптимальный, учитывая расстояние, расход топлива, наличие заправок и т.д. Это чистый расчет. Машина не скажет: «Поедем по этой дороге, я чувствую этот маршрут лучше». Может машины и лучше нас в скорости расчетов, но интуиция по-прежнему остается одним из наших козырей. Человечество потратило десятки лет на то, чтобы создать машину, подобную мозгу человека. Но так ли много между ними общего? Сегодня мы рассмотрим исследование, в котором ученые, усомнившись в непревзойденности машинного «зрения» на базе свёрточных нейронных сетей, провели эксперимент по одурачиванию системы распознавания объектов посредством алгоритма, задачей которого было создание «подставных» изображений. Насколько удачной была диверсионная деятельность алгоритма, справлялись ли люди с распознаванием лучше машины и что это исследование привнесет в будущее данной технологии? Ответы найдем в докладе ученых. Поехали.
Основа исследования
Технологии распознавания объектов, использующие свёрточные нейронные сети (СНС), позволяет машине, грубо говоря, отличить лебедя от цифры 9 или кота от велосипеда. Эта технология развивается достаточно стремительно и на данный момент уже применяется в разных сферах, самой очевидной из которых является производство беспилотного транспорта. Многие высказывают мнение, что СНС системы распознавания объектов могут рассматриваться как модель зрения человека. Однако это утверждение слишком громкое, ввиду человеческого фактора. Все дело в том, что одурачить машину оказалось проще, чем человека (по крайней мере в вопросах распознавания объектов). СНС системы очень уязвимы к воздействию вредоносных алгоритмов (враждебных, если хотите), которые будут всячески мешать им правильно выполнять свою задачу, создавая изображения, которые будут неверно классифицироваться СНС системой.
Исследователи разделяют такие изображения на две категории: «одурачивающие» (полностью изменяют целевой объект) и «смущающие» (частично изменяют целевой объект). Первые это бессмысленные изображения, которые распознаются системой как нечто знакомое. К примеру, набор линий может быть классифицирован как «бейсбольный мяч», а разноцветный цифровой шум как «броненосец». Вторая категория изображений («смущающие») это изображения, которые в нормальных условиях были бы классифицированы правильно, но вредоносный алгоритм слегка их искажает, утрировано говоря, в глазах СНС системы. Например, рукописное число 6 будет классифицировано как число 5 благодаря небольшому дополнению из нескольких пикселей.
Только представьте какой вред могут нанести подобные алгоритмы. Стоит поменять местами классификацию дорожных знаков для автономного транспорта и аварии будут неизбежны.
Ниже представлены «подставные» изображения, которые одурачивают СНС систему, обученную распознавать объекты, и как подобная система их классифицировала.

Изображение №1
Пояснение по рядам:
- а — косвенно закодированные «обманные» изображения;
- b — непосредственно закодированные «обманные» изображения;
- с — «смущающие» изображения, заставляющие систему классифицировать одну цифру как другую;
- d — атака LaVAN (локализованный и видимый состязательный/вредоносный шум) может привести к неправильной классификации, даже когда «шум» расположен только в одной точке (в нижнем правом углу).
- е — трехмерные объекты, которые неправильно классифицированы с разных ракурсов.
Самым же любопытным в этом является то, что человек может и не поддаться на одурачивание вредоносного алгоритма и классифицировать изображения верно, опираясь на интуицию. Ранее, как говорят ученые, никто не проводил практического сравнения способностей машины и человека в эксперименте на противодействие вредоносным алгоритмам подставных изображений. Именно это исследователи и решили сделать.
Для этого было подготовлено несколько изображений, сделанных вредоносными алгоритмами. Испытуемым было сказано, что эти изображения (подставные) машина классифицировала как знакомые объекты, т.е. машина их распознала неверно. Задачей испытуемых было определить как именно машина классифицировала эти изображения, т.е. что по их мнению увидела машина на изображениях, верна ли такая классификация и т.д.
Всего было проведено 8 экспериментов, в которых использовалось 5 типов вредоносных изображений, созданных без учета человеческого зрения. Другими словами, они созданы машиной для машин. Результаты этих экспериментов получились весьма занятные, но не будем спойлерить и рассмотрим все по порядку.
Результаты экспериментов
Эксперимент №1: одурачивающие изображения с неверными метками
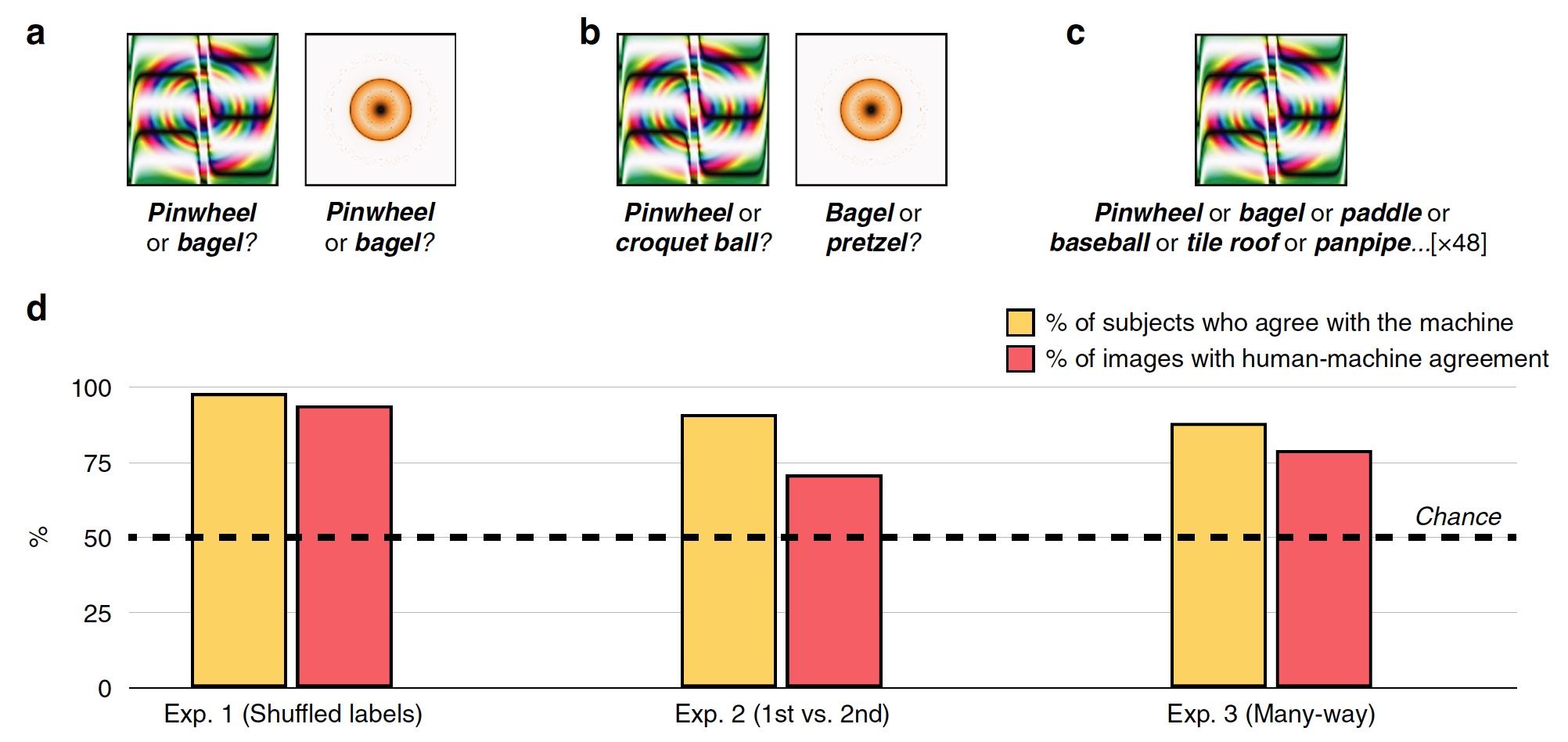
В первом эксперименте было использовано 48 одурачивающих изображений, созданных алгоритмом для противодействия системе распознавания на базе СНС под названием AlexNet. Данная система классифицировала эти изображения как «зубчатое колесо» и «бублик» (2а).
Изображение №2
Во время каждой попытки испытуемый человек, коих было 200, видел одно одурачивающее изображение и две метки, т.е. классификационные ярлыки: метка СНС системы и случайная из других 47 изображений. Испытуемые должны были выбрать ту метку, которая была создана именно машиной.
В результате большинство испытуемых предпочли выбрать метку, созданную машиной, а не метку вредоносного алгоритма. Точность классификации, т.е. степень согласия испытуемого с машиной, составила 74%. Статистически, 98% испытуемых выбирали машинные метки на уровне выше статистической случайности (2d, «% испытуемых, согласных с машиной»). 94% изображений показали очень высокое согласование человек-машина, то есть из 48 только 3 изображения классифицировались людьми не так, как машиной.
Таким образом, испытуемые показали, что человек способен разделять реальное изображение и одурачивающее, то есть действовать по программе на базе СНС.
Эксперимент №2: первый выбор против второго
Исследователи задались вопросом — за счет чего испытуемые смогли так хорошо распознать изображения и отделить их от ошибочных меток и одурачивающих изображений? Возможно испытуемые отмечали оранжево-желтое кольцо как «бублик», потому что в реальности бублик именно такой формы и примерно такого же цвета. В распознавании человеку могли помогать ассоциации и интуитивный выбор, основанный на опыте и знаниях.
Для проверки этого случайную метку заменили на ту, что была выбрана машиной как второй возможный вариант классификации. Например, AlexNet классифицировал изображение оранжево-желтого кольца как «бублик», а второй вариант у этой программы был «крендель».
Перед испытуемыми стояла задача выбрать первую метку машины или ту, что занимала второе место, для всех 48 изображений (2с).
График по центру на изображении 2d показывает результаты данного теста: 91% испытуемых выбрали именно первый вариант метки, а уровень согласования человек-машина составил 71%.
Эксперимент №3: многопотоковая классификация
Вышеописанные эксперименты достаточно просты ввиду того, что у испытуемых есть выбор между двумя вариантами ответа (метка машины и случайная метка). В действительности же, машина в процессе распознавания изображения перебирает сотни и даже тысячи вариантов меток, прежде чем выбрать самую подходящую.
В данном тесте перед испытуемыми были сразу все метки для 48 изображений. Им необходимо было из этого множества выбрать самые подходящие для каждого изображения.
В результате 88% испытуемых выбирали именно те метки, что и машина, а степень согласования составила 79%. Любопытным является и тот факт, что даже при выборе не той метки, что выбрала машина, испытуемые в 63% таких случаев выбирали одну из 5 самых топовых меток. То есть, у машины все метки упорядочены в виде списка от самой подходящей до самой неподходящей (утрированный пример: «бублик», «крендель», «надувной круг», «шина» и т.д. вплоть до «ястреб в ночном небе»).
Эксперимент №3b: «что это?»
В данном тесте ученые немного изменили правила. Вместо просьбы «угадать», какую метку для того или иного изображения выберет машина, испытуемых просто спрашивали что они видят перед собой.
Системы распознавания на базе сверточных нейронных сетей выбирают подходящую метку для определенного изображения. Это достаточно четкий и логичный процесс. В данном же тесте испытуемые проявляют интуитивное мышление.
В результате 90% испытуемых выбрали метку, которую также выбрала и машина. Уровень согласования человек-машина среди изображений составил 81%.
Эксперимент №4: телевизионный статический шум
Ученые отмечают, что в предыдущих экспериментах изображения хоть и необычны, но обладают различимыми чертами, которые могут натолкнуть испытуемых на правильный (или неправильный) выбор метки. К примеру, изображение «бейсбольный мяч» мячом не является, но на нем имеются линии и цвета, которые присутствуют на реальном бейсбольном мяче. Это яркая отличительная черта. Но если изображение не имеет таких черт, а является по сути статическим шумом, может ли человек распознать на нем хоть что-то? Именно это и было решено проверить.

Изображение №3а
В данном тесте перед испытуемыми было 8 изображений со статикой, которые СНС системы распознают как определенный объект (например, птичка зарянка). Также перед испытуемыми была метка и нормальные изображения, относящиеся к ней (8 изображений статики, 1 метка «зарянка» и 5 фото этой птицы). Испытуемый должен был выбрать 1 из 8 изображений статики, которое наилучшим образом подходит к той или иной метке.
Вы можете проверить себя сами. Выше вы видите пример такого теста. Какое из трех изображений наилучшим образом подходит к метке «зарянка» и почему?
81% испытуемых выбрали метку, которую выбрала машина. При этом 75% изображений были помечены испытуемыми самой подходящей меткой по мнению машины (из ряда вариантов, о чем мы уже говорили ранее).
К данному конкретному тесту у вас могут быть вопросы, как и у меня. Дело в том, что в предложенных изображениях статики (выше) я, лично, вижу три ярко выраженные черты, которые их отличают друг от друга. И только у одного изображения эта черта сильно напоминает ту самую зарянку (я думаю, вы понимаете какое именно изображение из трех). Посему мое личное и очень субъективное мнение заключается в том, что такой тест не особо показателен. Хотя возможно среди других вариантов статических изображений были действительно неотличимые и нераспознаваемые.
Эксперимент №5: «сомнительные» цифры
Вышеописанные тесты были основаны на изображениях, которые нельзя сразу полноценно и без капли сомнения классифицировать как тот или иной объект. Всегда остается доля сомнений. Одурачивающие изображения достаточно прямолинейны в своем деле — испортить изображение до неузнаваемости. Но есть и второй тип вредоносных алгоритмов, которые добавляют (или убирают) лишь малую деталь на изображении, что может полностью нарушить процедуру распознавания его системой СНС. Добавляем несколько пикселей, и число 6 магическим образом превращается в число 5 (1с).
Ученые считают подобные алгоритмы одними из самых опасных. Можно немного изменить изображение-метку, и беспилотный автомобиль неправильно считает знак ограничения скорости (например, 75 вместо 45), что может привести к печальным последствиям.

Изображение №3b
В данном тесте ученые предложили испытуемым выбрать не правильный ответ, а наоборот — ошибочный. В тесте использовалось 100 измененных вредоносным алгоритмом изображений цифр (СНС система LeNet изменила их классификацию, то есть вредоносный алгоритм сработал успешно). Испытуемые должны были сказать какую цифру по их мнению увидела машина. Как и ожидалось, 89% испытуемых успешно прошли данный тест.
Эксперимент №6: фото и локализованные «искажения»
Ученые отмечают, что развиваются не только системы распознавания объектов, но и вредоносные алгоритмы, мешающие им в этом. Ранее, чтобы изображение было классифицировано неверно, необходимо было исказить (изменить, удалить, повредить и т.д.) 14% от всех пикселей на целевом изображении. Сейчас эта цифра стала значительно меньше. Достаточно добавить небольшое изображение внутрь целевого и классификация будет нарушена.

Изображение №4
В данном тесте использовался достаточно новый вредоносный алгоритм LaVAN, который размещает на целевом фото маленькое изображение, локализованное в одной точке. В результате система распознавания объектов может распознать поезд метро как банку молока (4а). Самыми значимыми особенностями этого алгоритма является именно малая доля повреждаемых пикселей (всего 2%) целевого изображение и отсутствие необходимости искажать его целиком или основную (самую значимую) его часть.
В тесте использовались 22 изображения, поврежденных LaVAN (СНС система распознания Inception V3 была успешно взломана этим алгоритмом). Испытуемые должны были классифицировать вредоносную вставку на фото. 87% испытуемых смогли успешно это сделать.
Эксперимент №7: трехмерные объекты
Изображения, которые мы видели раньше, двумерные, как и любое фото, картина или вырезка из газеты. Большинство вредоносных алгоритмов успешно манипулируют именно такими изображениями. Однако работать эти вредители могут только при определенных условиях, то есть обладают рядом ограничений:
- сложность: только двухмерные изображения;
- практическое применение: вредоносные изменения возможны только на системах, которые считывают полученные цифровые изображения, а не изображения с датчиков и сенсоров;
- устойчивость: вредоносная атака теряет силу, если двумерное изображение повернуть (изменить размер, кадрировать, изменить резкость и т.д.);
- человек: мы видим мир и объекты вокруг нас в 3D под разными углами, освещением, а не в виде двумерных цифровых снимков, сделанных с одного ракурса.
Но, как мы знаем, прогресс не обошел стороной вредоносные алгоритмы. Среди них появился тот, кто способен не только искажать двухмерные изображения, но и трехмерные тоже, что приводит к неверной классификации системой распознавания объектов. При использовании программного обеспечения для трехмерной графики такой алгоритм вводит в заблуждение классификаторы на основе СНС (в данном случае программу Inception V3) с разных расстояний и углов обзора. Самое удивительное, что подобные одурачивающие 3D изображения можно распечатать на соответствующем принтере, т.е. создать реальный физический объект, и система распознавания объектов все равно будет ошибочно его классифицировать (например, апельсин как электродрель). А все благодаря незначительным изменениям текстуры на целевом изображении (4b).
Для системы распознавания объектов такой вредоносный алгоритм это серьезный противник. Но человек — не машина, он видит и мыслит иначе. В данном тесте перед испытуемыми были изображения трехмерных объектов, в которых имелись вышеописанные изменения текстуры, с трех ракурсов. Также испытуемым были предоставлены метки верные и ошибочные. Они должны были определить какие метки верные, какие нет и почему, т.е. видят ли испытуемые изменения текстур на изображениях.
В результате 83% испытуемых успешно справились с поставленной задачей.
Для более детального ознакомления с нюансами исследования настоятельно рекомендую заглянуть в доклад ученых.
А по этой ссылке вы найдете файлы изображений, данных и кода, которые применялись в исследовании.
Эпилог
Проведенная работа дала ученым возможность сделать простой и достаточно очевидный вывод — человеческая интуиция может быть источником очень важных данных и инструментом в принятии правильного решения и/или восприятия информации. Человек способен интуитивно понять как будет вести себя система распознавания объектов, какие метки она выберет и почему.
Причин почему человеку проще увидеть реальное изображение и правильно его распознавать несколько. Самой очевидной является метод получения информации: машина получает изображение в цифровом виде, а человек видит ее своими собственными глазами. Для машины картинка это набор данных, внеся изменения в которые, можно исказить ее классификацию. Для нас же изображение поезда метро всегда будет поездом метро, а не банкой молока, потому как мы видим это.
Ученые также делают ударение на том, что подобные тесты достаточно сложно оценивать, ибо человек это не машина, а машина — не человек. К примеру, исследователи говорят о тесте с «бубликом» и «колесом». Эти изображения похожи на «бублик» и «колесо», потому система распознавания так их и классифицирует. Человек же видит, что они похожи на «бублик» и «колесо», но ими не являются. В этом заключается фундаментальная разница восприятия визуальной информации между человеком и программой.
Благодарю за внимание, оставайтесь любопытствующими и хорошей всем рабочей недели, ребята.
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps до лета бесплатно при оплате на срок от полугода, заказать можно тут.
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Комментарии (2)

Alonerover
29.03.2019 15:32+1«Причин почему человеку проще увидеть реальное изображение и правильно его распознавать несколько. Самой очевидной является метод получения информации: машина получает изображение в цифровом виде, а человек видит ее своими собственными глазами.»
— Вопрос из категории глупых — чем электрическая импульсация, идущая от зрительного нерва, принципиально отличается от цифровых сигналов внутри машинного интеллекта?
kahi4
Такую цифру 5 и я бы распознал как что угодно, но не цифру 5.