
1. Что такое парсинг?
По определению парсинг – это автоматизированный сбор неструктурированной информации, ее преобразование и выдача в структурированном виде. Довольно безобидно, не правда ли? Однако, общество относится к этому довольно своеобразно, как к подростковой мастурбации – многие этим занимались :), но никто об этом не говорит публично. Более того, парсинг часто осуждается и считается чем-то слегка постыдным. Причина как и в большинстве подобных случаев, в неправильном восприятии.
Раскрою вам тайну: парсингом занимаются все… По крайней мере, все крупные игроки на рынке. Пару лет назад в одной из статей в Ведомостях представители “М-видео”, “Связного” и “Ситилинка” даже в открытую говорили об этом в ответ на интерес ФАС (см. тут).
2. Для чего парсинг нужен?
В первую очередь, целью парсинга является ценовая «разведка», ассортиментный анализ, отслеживание товарных акций. “Кто, что, за сколько и в каких количествах продаёт?” – основные вопросы, на которые парсинг должен ответить. Если говорить более подробно, то парсинг ассортимента конкурентов или того же Яндекс.Маркет отвечает на первые три вопроса.
С оборотом товара несколько сложней. Однако, такие компании как “Wildberries”, “Lamoda“ и Леруа Мерлен, открыто предоставляют информацию об ежедневных объемах продаж (заказах) или остатках товара, на основе которой не сложно составить общее представлении о продажах (часто слышу мнение, мол эти данные могут искажаться намеренно — возможно, а возможно и нет). Смотрим, сколько было товара на складе сегодня, завтра, послезавтра и так в течении месяца и вот уже готов график и динамика изменения количества по позиции составлена (оборачиваемость товара фактически). Чем выше динамика, тем больше оборот.
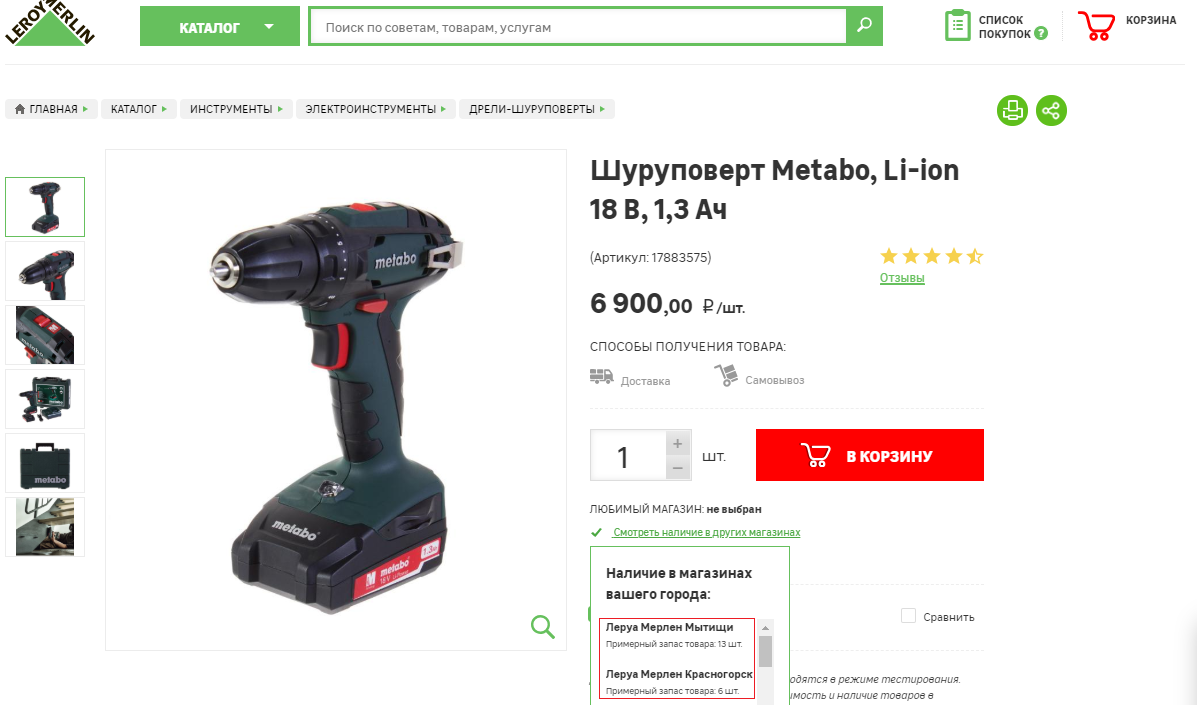
Потенциально возможный способ узнать оборачиваемость товаров с помощью ежедневного анализа остатков сайта Леруа Мерлен.
Можно, конечно, сослаться на перемещение товаров между точками. Но суммарно, если брать, например, Москву — то число не сильно изменится, а в существенные передвижения товара по регионам верится с трудом.
С объемами продаж ситуация аналогична. Есть, конечно, компании, которые публикуют информацию в виде много/мало, но даже с этим можно работать, и самые продаваемые позиции легко отслеживаются. Особенно, если отсечь дешёвые позиции и сфокусироваться исключительно на тех, что представляют наибольшую ценность. По крайней мере, мы такой анализ делали – интересно получалось.
Во-вторых, парсинг используется для получения контента. Здесь уже могут иметь место истории в стиле “правовых оттенков серого”. Многие зацикливаются на том, что парсинг – это именно воровство контента, хотя это совершенно не так. Парсинг – это всего лишь автоматизированный сбор информации, не более того. Например, парсинг фотографий, особенно с “водяными знаками” – это чистой воды воровство контента и нарушение авторских прав. Потому таким обычно не занимаются (мы в своей работе ограничиваемся сбором ссылок на изображения, не более того… ну иногда просят посчитать количество фотографий, отследить наличие видео на товар и дать ссылку и т.п.).
Касательно сбора контента, интересней ситуация с описаниями товаров. Недавно нам поступил заказ на сбор данных по 50 сайтам крупных онлайн-аптек. Помимо информации об ассортименте и цене, нас попросили “спарсить” описание лекарственных аппаратов – то самое, что вложено в каждую пачку и является т.н. фактической информацией, т.е. маловероятно попадает под закон о защите авторских прав. В результате вместо набора инструкций вручную, заказчикам останется лишь внести небольшие корректировки в шаблоны инструкций, и всё – контент для сайта готов. Но да, могут быть и авторские описания лекарств, которые заверены у нотариуса и сделаны специально как своего рода ловушки для воришек контента :).
Рассмотрим также сбор описания книг, например, с ОЗОН.РУ или Лабиринт.ру. Здесь уже ситуация не так однозначна с правовой точки зрения. С одной стороны, использование такого описания может нарушать авторское право, особенно если описание каждой карточки с товаром было нотариально заверено (в чём я сильно сомневаюсь — ведь может и не быть заверено, исключение — небольшие ресурсы, которые хотят затаскать по судам воров контента). В любом случае, в данной ситуации придётся сильно «попотеть», чтобы доказать уникальность этого описания. Некоторые клиенты идут еще дальше — подключают синонимайзеры, которые «на лету» меняют (хорошо или плохо) слова в описании, сохраняя общий смысл.
Ещё одно из применений парсинга довольно оригинально – “самопарсинг”. Здесь преследуется несколько целей. Для начала – это отслеживание того, что происходит с наполнением сайта: где битые ссылки, где описания не хватает, дублирование товаров, отсутствие иллюстраций и т.д. Полчаса работы парсера — и вот у тебя готовая таблица со всеми категориями и данными. Удобно! “Самопарсинг” можно использовать и для того, чтобы сравнить остатки на сайте со своими складскими остатками (есть и такие заказчики, отслеживают сбои выгрузок на сайт). Ещё одно применение “самопарсинга”, с которым мы столкнулись в работе — это структурирование данных с сайта для выгрузки их на Яндекс Маркет. Ребятам так проще было сделать, чем вручную этим заниматься.
Также парсятся объявления, например, на ЦИАН-е, Авито и т.д. Цели тут могут быть как перепродажи баз риелторам или туроператорам, так и откровенный телефонный спам, ретаргетинг и т.п. В случае с Авито это особенно явно, т.к. сразу составляется таблица с телефонами пользователей (несмотря на то, что Авито подменяет телефоны пользователей для защиты и публикует их в виде изображения, от поступающих звонков все равно никуда не уйти).
3. “Что в резюме тебе моем?” или парсинг HH.RU
В последнее время стали актуальны запросы на парсинг Headhunter-а. Правда сначала люди просят продать им “базу Хедхантера”. Но, когда уже понимают, что никакой базы у нас нет и быть не может, мы переходим к разговору о парсинге в их профиле (“под паролем”). Это своеобразное направление парсинга и, честно говоря, нам оно не особо интересно, однако рассказать о нём стоит.
В чём тонкость? Клиент предоставляет доступ к своему аккаунту и ставит задачу по сбору данных под свои нужды. Т.е. он уже оплатил доступ к базе HH и, подписывая с нами договор, ставит нам задачу на автоматический сбор информации в его интересах и под его аккаунтом, что находится полностью под его ответственностью. В случае, если HH зафиксирует ненормальную активность, аккаунт будет заблокирован. Потому мы стараемся как можно лучше сымитировать человеческую деятельность при сборе данных.
Если бы HH (насколько знаю “успешно” проваливший свои эксперименты с API) сам предоставлял (продавал) данные в табличке по регионам, скажем, контакты всех работающих в данный момент директоров по маркетингу в Москве, к нам бы никто и не приходил. А пока это приходится делать человеку “ручками”, к нам идут. Ведь, когда у тебя есть такая таблица, заниматься рекламным спамом – холодными звонками намного удобнее.
Подчеркну ещё раз, у нас нет базы HH, мы просто собираем данные для каждого клиента под его нужды, его аккаунтом и его ответственностью. И нарушение договора оферты не связано с использованием сайта парсящей стороной. Подписывая с нами договор, клиент получает за прогон контакты порядка 450-ти ЛПР-ов, которые мы положим к нему на сервер, и дальше уже его отдел продаж сам решит, что с этим делать. Эх, мы бы тоже “спамили”, если б у нас была такая база. Шучу :)
Хотя, лично я считаю, что нет перспектив в парсинге под паролем. А вот парсинг открытых ресурсов – это другое дело. Ты один раз настроил всё и парсишь постоянно, потом перепродаешь доступ ко всем собранным данным. Это более перспективно.
4. Парсинг вообще законен?
В российском законодательстве нет статьи, запрещающей парсинг. Запрещен взлом, DDOS, воровство авторского контента, а парсинг – это ни то, ни другое, не третье и, соответственно, он не запрещен.
Некоторые люди воспринимают парсинг как DDOS-атаку и относятся к нему с сомнением. Однако, это совершенно разные вещи, и при парсинге мы, напротив, стараемся как можно меньше нагружать целевой сайт и не навредить бизнесу. Как в случае со здоровым паразитизмом – мы не хотим, чтобы бизнес «отбросил копыта», иначе нам не на чем будет “паразитировать”.
Обычно просят парсить крупные сайты, из топа 300-500 сайтов России. На таких сайтах посещаемость, как правило, несколько миллионов в месяц, может даже и больше. И на таком фоне парсинг одного товара в секунду или в две практически незаметен (нет смысла чаще парсить, 1-2 секунды на товар — это оптимальная скорость для крупных сайтов). Соответственно, и намека на DDOS-атаку в наших действиях нет. Очень редко люди просят чтобы мы обновляли, например, весь сайт БЕРУ.РУ за сутки — это, скажем прямо, перебор и слишком высокая нагрузка на сайт… обычно занимает 3-4 дня.
Напомню, что парсинг – это лишь сбор того, что мы можем своими глазами увидеть на сайте и скопировать к себе руками. Таким образом, под статью об авторском праве могут попасть лишь действия с уже собранной информацией, т.е. действия самого заказчика. Просто человек это делает долго медленно и с ошибками, а парсер – быстро и не ошибается. Что же делать, когда речь касается сбора данных с AliExpress или Wildberies? Человеку просто не под силу такая задача, и парсинг – единственный выход.
Правда, недавно попросили парсить сайт государственной организации – суда, если не ошибаюсь. Там в открытом доступе вся информация, но мы (на всякий случай) отказались. :)
5. “Вы чего нас парсите, мы же заказчик” или в чем разница между парсингом и мониторингом цен?
Мониторинг цен – одно из наиболее востребованных направлений применения парсинга. Но с ним не всё так просто – поработать в данном случае придётся не только нам, но и самому клиенту.
При заказе на мониторинг цен мы сразу предупреждаем, что будем парсить не только конкурентов, но и заказчика. Это необходимо для получения схожих таблиц с товарами и ценами, которые мы сможем обновлять автоматически. Однако, сами по себе такие данные не несут ценность, пока они не связаны между собой (так называемый матчинг товаров). Некоторые позиции с разных сайтов мы можем сопоставить автоматически, но, к сожалению, на данный момент “машины” еще не так хороши, чтобы сделать это гарантированно без ошибок, и лучше человека (например, работающего удаленно на полставки сотрудника из регионов) это никто не сделает.
Если бы все выводили штрих-код на сайте, то вообще было бы замечательно, и мы могли бы делать все “связки” автоматически. Но, к сожалению, так это не так, и даже названия продуктов разные компании пишут по-разному.
Хорошо, что такую работу необходимо провести единожды, а потом периодически перепроверять и вносить небольшие корректировки, если требуется. При наличии связок мы уже можем обновлять такие таблицы автоматически. К тому же, обычно людям не требуется мониторить цены на всё: есть условно 3-5 тысяч позиций, которые в топе, а мелочь не представляет интерес. И оператор из региона легко сможет выполнять такую работу за деньги порядка 10 000 рублей в месяц.
Самый удачный и правильный кейс в данном случае, на мой взгляд, загружать полученный прайс лист конкурентов сразу к себе в 1С-ку (или другую ERP систему) и там уже выполнять сопоставление. Так мониторинг цен легче всего внедрить в ежедневную деятельность своих аналитиков. А без анализа такой парсинг никому и не нужен.
6. Как защититься от парсинга?
Да никак. И стоит ли вообще защищаться от парсинга? Я бы не стал. Работающей 100% защиты всё равно нет (точнее, мы еще не встречали), так что особого смысла пытаться защититься я не вижу. Лучшая защита от парсинга – это просто выложить готовую таблицу на сайте и написать – берите отсюда, обновляем раз в пару дней. Если люди так будут делать, то у нас хлеба не будет.
К слову говоря, недавно созванивались с IT директором крупной сети – они хотели протестировать свою защиту от парсинга. Я его напрямую спросил, почему они так не делают. Как технический специалист он прекрасно понимает, что никакая защита от парсинга не спасёт, лишь отпугнет дилетантов; а вот компании, которые зарабатывают на парсинге, вполне могут позволить себе исследовательскую деятельность в этом направлении – долго и мучительно разбираться в новой защите, и в итоге ее обойти…
Как правило, все используют однотипные защиты, и такое исследование пригодится еще не раз. Так вот, оказалось, что отдел маркетинга не готов к такому: “Зачем нам упрощать жизнь конкурентам?” Казалось бы, логично, но… В результате компания будет тратить деньги на защиту, которая не поможет, а паразитная нагрузка на сайт – останется. Хотя, справедливости ради, стоит отметить, что от «студентов» изучающих python и парсящих все что «шевелится» вполне может помочь.
Кстати, и “Яндекс”, и “Google” занимаются парсингом: они заходят на сайт и индексируют его – собирают информацию. Только все хотят, чтобы “Яндекс” и “Google” индексировали их сайты по понятным причинам, и никто не хочет, чтобы их парсили :)
7. “Я тут бесплатно поискал...” или история про авиабилеты
Однажды к нам обратились с интересным заказом на тестовый парсинг. Компания занимается авиабилетами и им были интересны цены конкурентов на пару самых популярных направлений. Задача оказалась нетривиальной, т.к. пришлось повозиться с подстановкой и сопоставлением рейсов. Занимательным оказалось то, что цены у “Onetwotrip”, “Aviasales” и “Skyscanner” на одни и те же рейсы немного отличаются (разброс около 5-7%).
Проект показался мне очень интересным, и я выложил пост об этом в соц.сетях. К моему удивлению дискуссия под постом оказалась довольно агрессивной, и я не сразу понял почему. Затем мне написал гендиректор одной из компаний лидера рынка продажи билетов в России, и ситуация прояснилась. Выяснилось, что запросы о ценах на билеты для таких компаний платные, т.к. они берут информацию с международных платных сервисов. И, помимо паразитной нагрузки, парсинг представляет для них еще и финансовую.
В любом случае, никто же с вас не требует оплаты, если вы подыскиваете себе лично билеты на этих сервисах, а запросов обычные люди тоже делают немало пока перебирают разные варианты… В общем тут такая бизнес-дилемма :)
8. “Рецепты шеф-парсера”. или как мы работаем?
Думаю, для большего понимания всех аспектов парсинга стоит приоткрыть завесу нашей “внутренней кухни”.
Всё начинается с заказа. Иногда клиенты связываются с нами сами, а иногда звоним мы. Особенно удачно получается с заказами на мониторинг цен. В этом случае нам приходится парсить не только конкурентов, но и самого заказчика. Поэтому мы порой звоним тем, кого так или иначе парсим, и в открытую об этом говорим, предлагая свои услуги – работа ведь нами уже и так выполняется. Сначала реакция очень негативная, но проходит пара дней, эмоции спадают, и заказчики сами перезванивают, говоря: “Чёрт с ним! Кого вы ещё парсите?”
Парсинг у ОЧЕНЬ многих владельцев посещаемых ресурсов вызывает эмоции. Сначала негативные, ведь он схож с подглядыванием в замочную скважину. Затем перерастает в интерес, а потом и в осознание необходимости. Бизнесмены – умные люди. Когда эмоции сходят на нет и остаётся холодный расчёт, всегда возникает вопрос: “А, может, мы где-то недоработали, и нам тоже это нужно?”
Благодаря этим эмоциям мы довольно активно растём и развиваемся. На данный момент мы парсим порядка 300 сайтов в день. Обычно у нас заказывают по 8-15 сайтов, а парсинг одного стоит от 5 до 9 тысяч рублей в месяц, в зависимости от сложности подключения, ведь каждый сайт приходится подключать индивидуально (уходит где-то 4-5 часов на ресурс). Сложность заключается в том, что некоторые защищаются. Борьба идёт не столько с парсингом, сколько с некой паразитной нагрузкой, которая не приносит им прибыль, но иногда приходится повозиться.
В любом случае ВСЁ ПАРСИТСЯ, даже если цена на товар публикуется на сайте как картинка :) Желающим попробовать свои силы в парсинге, рекомендую потренироваться на сайте «Аптеки Столички» и спарсить цены.
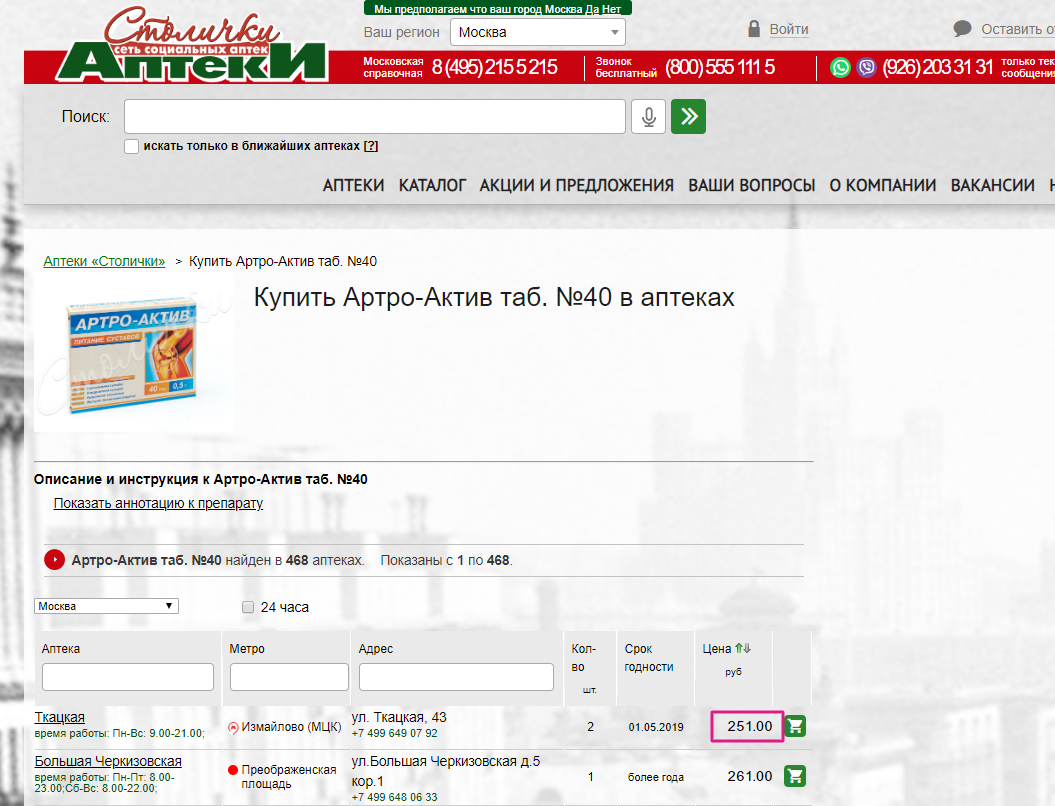
Интернет- магазин сети аптек «Столички» — цены пишутся внутренним шрифтом и чтобы их спарсить одним из решений будет формирование картинки и ее распознавание. Мы так делаем по крайне мере.
Собранные данные передаются клиенту. Обычно мы размещаем их на собственном облаке, постоянно обновляя, и предоставляем клиенту доступ к ним по API. Если с данными вдруг становится что-то не так (а это бывает редко – раз в 3-4 месяца), нам сразу звонят-пишут, и мы стараемся устранить проблему как можно быстрее. Такие сбои возникают при установки новой защиты или блокировки, а решаются с помощью исследований и прокси соответственно. В другом случае, когда на сайте что-то меняется, бот просто перестает понимать, где что находится, и нашему программисту приходится заново его настраивать. Но всё решаемо, и заказчики обычно относятся к таким проблемам с пониманием.
Отмечу, что в нашем деле личность заказчика никогда не разглашается – мы относимся к этому достаточно трепетно, да и пункты в договоре о неразглашении никто не отменял. Хоть в парсинге и нет ничего предосудительного, но многие стесняются.
Собственно, подводя итог- если вы растущий бизнес, торгуете широко распространенными товарами или работаете в быстро меняющейся среде (такой, как найм персонала или предложение специфических услуг для определенной категории авторов объявлений, резюме и содержимого других“досок объявлений” в Интернете), то рано или поздно столкнетесь с парсингом (как заказчик или как мишень).
P.S.: если статья понравится, будем писать уже про тех.сторону дела — как обходим защиту, какие мощности используем, на чем написано (спойлер .net) и т.п.
Максим Кульгин, xmldatafeed.com
Комментарии (396)

webdiktor
03.04.2019 15:31Выдачу Яндекса парсите как это делают множество SEO сервисов? На это спроса побольше, больше денег. Правда они в основном продают целую систему аналитики SEO.

makasin4ik Автор
03.04.2019 15:53нет, не парсим выдачу. Не просили, да и там через запросов 100 сразу будет капча, нужны чистые прокси, а их сложно достать или дорогие…

Tatikoma
03.04.2019 19:13Сделать собственные прокси не пробовали? — Есть масса вариантов.
В вашем бизнесе это чуть ли не основной компонент, который логично держать внутри компании.kuznitsin
04.04.2019 10:52По моему опыту у яндекс, гугл и подобных крупных корпораций существует некоторая база с подсетями датацентров. Таким образом, поднятая сеть прокси на ip адресах, выданных датацентрам, на отлично улетает в бан с выдачей капчи и другими причудами. По итогу остаются только незаконные варианты с закупом прокси у владельцев ботнетов и подобная грязь, в этом случае у тебя будет реальный пользовательский ip. И даже при этом(исследовал с личных ip) таким корпорациям очень нужно, чтобы у тебя были «отстоявшиеся» куки, с которыми ты уже «поползал» какое-то время по сайтам где они могут тебя трекать(к примеру, счетчики посещений).
Tatikoma
04.04.2019 11:39Это не все способы сделать собственные прокси. Есть вполне рабочие способы настроить чистые прокси годные для парсинга поисковых систем.

and7ey
04.04.2019 16:25Расскажите, плз, что за способы. Можно в отдельной статье :).
Tatikoma
04.04.2019 17:17Не хочу так напрямую сдавать козыри. Суть в правильной постановке задачи. Вам нужны адреса с которых сидят реальные юзеры и генерируют полезную активность.
ArsenAbakarov
04.04.2019 18:46пф, ферма 3g модемов, че за секретность то?)
Tatikoma
04.04.2019 19:04Это один из вариантов, да. Хороший вариант. 4Г модемы получше будут, разница заметна.

sumanai
04.04.2019 19:26И даже при этом(исследовал с личных ip) таким корпорациям очень нужно, чтобы у тебя были «отстоявшиеся» куки, с которыми ты уже «поползал» какое-то время по сайтам где они могут тебя трекать(к примеру, счетчики посещений).
Все ПС у меня в отдельных контейнерах Firefox, куки трутся при закрытии страницы. Проблем с капчами нет.
makasin4ik Автор
04.04.2019 10:53нет… мы раньше покупали прокси, а щас забили. берем бесплатные. Но мы НЕ парсим ГУГЛ и Яндекс. А для других ресурсов — подходят.
agarus
04.04.2019 15:45А как они вас вообще отличают от НАТов в спальных районах? Вы с одного и того же порта ими интересуетесь? 100 запросов это всего ничего.
makasin4ik Автор
04.04.2019 15:46базы прокси есть ведь, обновляются. думаю, что крупные игроки на них подписаны и банят. Но в реалии — да, банят очень быстро.

redpax
04.04.2019 10:18Азиаты разгадывающие капчу за еду, как это сделал Люстик из keycollector при парсинге wordstat, да и с прокси вопрос простейший.
abmanimenja
04.04.2019 21:37Правда они в основном продают целую систему аналитики SEO.
Выдача поисковиков давно уже индивидуализирована.
Продают довольно неточную аналитику в конечном итоге.
thebeginning
03.04.2019 15:38Насколько я понял, парсите именно веб-страницы. Альтернативные пути не рассматриваете? Пользуетесь каким-то своим софтом, или это браузеры (headless?) с BeautifulSoup-подобным (Selenium, Splinter) решением? На каком железе запускаете?
makasin4ik Автор
03.04.2019 15:54в 90% парсинг html страниц. 10% — chromium в особо тяжких случаях. Например, для парсинга я.Маркета мы используем хромиум. Надо отметить, что единицы сайтов защищаются так, что требуется хромиум.
thebeginning
03.04.2019 16:12Я разобрал ваш пример с аптекой и пришел к достаточно элегантному решению.
Картинка
NikR
04.04.2019 10:57Как вы вышли на JSON?

cry_san
04.04.2019 10:57Смотрел запросы к сайту
NikR
04.04.2019 15:54В Network нет ничего подходящего, а XHR только от счетчика Яндекса. Подскажете url и другие параметры, чтобы получить JSON? В каком файле нашли упоминание об этом?

TimsTims
05.04.2019 00:30Решалось загрузкой по байтам и обрывом соединения там, где кончался json
То есть json лежит в теле html. В любом случае, если вы хотите решить проблему, то просто банальным фильтром по xhr не обойтись, все может маскироваться глубже, ищите дальше. То, что вы бросили на полпути говорит о том, что вам это не особо и надо.

serafims
04.04.2019 20:01да сейчас полно сайтов, которые рисуют пользователю только интерфейс-шаблон, а уже потом аяксом в него заливают данные на стороне пользователя…
serafims
04.04.2019 20:04да сейчас полно сайтов, которые рисуют пользователю только интерфейс-шаблон, а уже потом аяксом в него заливают данные на стороне пользователя…
Zolg
05.04.2019 13:04подозреваю, что по ссылке 'Перейти на новый сайт'
где там json — не копал, но
1) там есть чудесная яндекс.карта с аптеками и ценами
2) а сам список отрендерен без всяких заморочек:
<div class="pharmacyList__items_mob">Цена</div> <ul class="tableListPrice"><li class="tableListPrice__item"> <div class="tableListPrice__col tableListPrice__col_1">Цена: </div> <div class="tableListPrice__col tableListPrice__col_2">251 <span class="tableListPrice____roubleIcon icon">?</span></div> </li></ul> </div>
olegator99
03.04.2019 19:23А зачем для маркета хромиум? Полгода назад он отлично утягивался без всяких ухищрений
makasin4ik Автор
03.04.2019 19:25Сейчас выдает быстро капчу. Только хромимум помогает нам.
olegator99
03.04.2019 19:28А рандомные прокси и UA уже не помогают?
makasin4ik Автор
03.04.2019 19:32прокси щас стали «грязные»… паленые :) не помогают. либо надо покупать очень дорогие, «белые».

xPomaHx
04.04.2019 02:34Скорее всего потому что отключен ssr в нужных местах, а js дешевле не выполнить.
kbaa
04.04.2019 16:10Сам занимаюсь парсингом (но не в рунете, а ловлю заказы на
любимом всемиupworke, там это обычно зовётся scraping, более подходящий термин, имхо) У меня немного другое соотношение, где-то 75 к 25. Но в целом да, если лень или сложно — то уж от selenium пока никто не уворачивался :) Но из нескольких сотен сайтов с которыми приходилось работать, ни разу не доходило до распознавания картинок, чтоб получить целевые данных. Обычно, если данных нет в html, от они всегда подтягиваются в каком нибудь json (ну, собственно, ниже уже показали пример)

LevOrdabesov
04.04.2019 23:03Ещё в VS есть System.Net, который фактически использует установленный в Windows IE. Тоже работает.
wegres
03.04.2019 15:46Интересно, какой ЯП используется для такого промышленного парсинга — 300 сайтов в день.
В p.s. автором статьи добавлено, что .net.makasin4ik Автор
03.04.2019 15:554 виртуалки, безлимитный трафик, 4 процессора на каждой, 8 гб памяти, windows server… Пока хватает, на каждую новую партию из условно 50 сайтов — нужна своя виртуалка. Но сильно зависит от самих сайтов.
vchslv13
04.04.2019 08:03Ну, например, я на прошлой работе (180+ сайтов в день разного размера от prisma.fi и verkkokauppa.com до какой-то мелочи с 3.5 продуктами) использовал Python/Scrapy/Splash. В конце прошлого года арендовали у Hetzner вот такой сервер (https://www.hetzner.com/dedicated-rootserver/ax60-ssd) с Ubuntu Server на борту. Большая часть вычислительных ресурсов пока что простаивает.
tuxi
03.04.2019 15:53Защититься от парсинга нельзя, но можно повысить порог затрат на него (и временных и денежных). Мы пошли именно по такому пути. В итоге, те данные которые мы защищаем (несколько разделов сайта), проще не парсить, а пойти и купить готовую БД, также как покупаем ее мы.
Вопрос кстати, selenium больше не отлавливается по аттрибуту «webdriver»?makasin4ik Автор
03.04.2019 15:56Да, можно защититься от «студентов». Факт. А по вашему вопросу — насколько знаю — нет. Мы запускаем Хромиум и все ОК, получается где-то 1 товар в 4-5 секунд можно брать, нас это устраивает…
tuxi
03.04.2019 16:00Нет, не только от студентов. Речь про использование типовых поведенческих моделей реальных посетителей, плюс систему адекватно идентифицирующую белых ботов (яндекс, гугл и тп). А чтобы подстроиться под реального посетителя, нужно знать набор типовых карт переходов :) простым пулом прокси тут не обойдешься. Система не на 100% защищает, но поставленную задачу решает.
makasin4ik Автор
03.04.2019 16:59можно еще смотреть были вообще клики :)
tuxi
03.04.2019 17:22В смысле, "не выплеснули ли мы вместе с водой и самого младенца"? Нет, все в порядке :) метрики же есть
makasin4ik Автор
03.04.2019 17:26я в том плане что парсер не кликает.

Skerrigan
04.04.2019 07:59В этом плане WebDriver — «наше все».
Я конечно не занимаюсь именно парсингом. Но занимаюсь в целом автоматизацией (куда уже и парсинг попадает)… на столько достоверной, на сколько это возможно (QA).
Хорошая рабочая станция, десяток-другой браузеров параллельно — на выходе очень злая-быстрая молотилка.
Понятное дело, что «точка назначения» в моем случае готова к таким гостям.
catBasilio
03.04.2019 15:54> рекомендую потренироваться на сайте «Аптеки Столички» и спарсить цены: stolichki.ru/present/27694
На вскоидку выглядит достаточно просто. По приведенной ссылке цены кодируются юникод символами:
0xef 0x81 0x80 -> '2'
0xef 0x83 0xa3 -> '6'
0xef 0x90 0x84 -> '9'
0xee 0xb9 0x82-> '.'
0xef 0x98 0x89 -> '0'
Декодируется это элементарно.
Или я что-то пропустил?
makasin4ik Автор
03.04.2019 15:54передам разработчикам :) может у нас «глаз замылился» мы пошли через распознование картинки, которую получали из шрифра.
unlor
03.04.2019 16:23-1Ну или в другом формате
firstChild: #text ??assignedSlot: null ??baseURI: "https://stolichki.ru/present/27694/" ??childNodes: NodeList [] ??data: "\uef4c\uf3e8\uf4ad\ueb5d\uf6f3\uf6f3"makasin4ik Автор
03.04.2019 16:58+1блин, хотел поставить лайк, рука дрогнула поставил минус, прошу прощения, вы правы. А отменить минус нельзя. блин

mclander
04.04.2019 12:53Возможно, что время от времени меняется шрифт ) Ну я бы по крайней мере так бы делал
Tatikoma
04.04.2019 13:07Более того, можно одной и той же цифре сделать соответствие нескольких глифов. Тогда будет недостаточно один раз вытащить соответствия в ручном режиме, а нужно будет парсить все глифы, распознавать цифры на них и запоминать соответствия для этого шрифта. По-сути это попутно обойдёт защиту от смены шрифта.
Контора которая этим зарабатывает может себе позволить 1-2 дня программиста на это потратить. От студентов, конечно, может помочь.
kbaa
04.04.2019 17:01а есть еще такой вариант, там помимо цен еще куча всякой инфы открытым текстом
FTOH
04.04.2019 12:46Декодируется это элементарно.
А можно поподробнее? Символы меняются при каждом обновлении страницы.catBasilio
04.04.2019 13:31Там используется кастомный шрифт, в которм символы с такими хитрыми кодами отображаются как цифры.
Конечно, все может меняться, но на это есть тестироваине, которое никто не отменял :)
neogenn
04.04.2019 14:26Один и тот же символ при каждом обновлении страницы дает разный код (хотя, иногда они повторяются)
Видать, еще в сессии какой-то рандом хранят. Так что, для такого подхода нужно набрать статистику, и он может незаметно начать выдавать не совсем верные значения когда разработчики чуть-чуть поменяют формулку.
Распознавание картинки надежней.sumanai
04.04.2019 19:33Так что, для такого подхода нужно набрать статистику, и он может незаметно начать выдавать не совсем верные значения когда разработчики чуть-чуть поменяют формулку.
Я бы заодно скачивал шрифт и считал его хеш, при его изменении выдавал алерт.
serafims
04.04.2019 20:07со своими шрифтами можно классный трюк делать — когда текст выглядит одним образом, а при копировании из PDF/сайта в нем кое-что меняется, например, числа.
inspector1985
03.04.2019 17:00Забавно, «нечто постыдное». Оказывается, парсить — стыдно. Стыдно, товарищи, стыдно.
makasin4ik Автор
03.04.2019 17:00ну говорить про это точно не принято всуе
inspector1985
04.04.2019 16:48-1был у меня опыт парсинга инфы с сайта МосБиржи, чтобы не покупать у них за деньги инфу по фьючам. Инфа специфичная, скачать бесплатно откуда-то типа yahoo.finance её нельзя, а биржи и брокеры предлагают её экспорт через свои API за деньги. Хорошая штука — парсинг.

superyarik
03.04.2019 17:14когда-то работал в таком проекте как webcollage, лет 10 назад. парсились сайты венторов(hp, sony и т.п.) собирлась инфа про товары и встраивалась потом на амазоны и бестбаи. Стэк был java + js + xslt. Так вот довольно быстро вендоры тупо стали предоставлять огромные xml файлы с описанием и ссылками на картинки, т.к. поняли что это им же нужно )
makasin4ik Автор
03.04.2019 17:21все верно. это самое правильное, но тогда у нас отнимут хлеб :)
khim
04.04.2019 04:15+1Ой вей. Если бы все люди всё делали по уму… Я думаю безработных было бы в 10 раз больше.
На ваш век хватит.
ZurgInq
03.04.2019 18:44+2С этической точки зрения — сплошные подмены понятий и попытки «отбелить» свою деятельность.
Многие зацикливаются на том, что парсинг – это именно воровство контента, хотя это совершенно не так. Парсинг – это всего лишь автоматизированный сбор информации, не более того.
Недавно нам поступил заказ на сбор данных по 50 сайтам крупных онлайн-аптек.… В результате вместо набора инструкций вручную, заказчикам останется лишь внести небольшие корректировки в шаблоны инструкций, и всё – контент для сайта готов.
Подглядывать в замочную скважину как минимум не красиво, а если клиент потом ещё и выдаёт спарсеное за своё — то это уже прямое воровство. Конечно понятно, что в сфере бизнеса все так делают. Но в приличном обществе всё же принято об этом молчать.makasin4ik Автор
03.04.2019 19:15+1Вы путаете мягкое и холодное. Мы действительно оказываем услугу по парсингу. Но ровно так же можно обвинять производителей, например, оружия в том, что с его помощью убивают. Мы делаем бизнес, а в бизнесе есть одно правило — законно это или нет. Моя точка зрения… Если к нам приходят клиенты и готовы платить много, что бы получить данные — это разве плохо… я вам примеров могу привести массу — производители сигарет например.
ZurgInq
03.04.2019 20:34+1Производство оружия, сигарет, алкоголя и других наркотиков, веществ, лекарств — регулируется законом. Когда производители начинают сбывать контрафакт или работать в обход правил — к ним предъявляют обоснованные претензии. А клиенты готовы платить много в первую очередь за то, что не всегда законно.
Вы сами пишите, что часто находитесь на грани закона, когда часть информации может быть защищена авторским правом.
Возможно, вы лучшие в своём деле, этим можно гордиться, рассказывать, привлекать клиентов. Но не нужно при этом делать вид, что вы белые и пушистые.
i8008
03.04.2019 21:18+5Давайте без лишних аналогий:
Некто создал базу товаров. Потратил кучу ресурсов на поиск информации, систематизацию этой информации, вынесение данных в базу.
Вы, по просьбе конкурента эту базу спарсиваете и за деньги отдаете тому самому конкуренту.
Вы считаете, что здесь нет этических проблем?
Касательно законности — не знаю как в РФ, но в Украине БД может быть объектом авторского права.
Pashkevich
04.04.2019 08:19Поддержу вас.
В свое время решил сделать приложение для сайта forbes.
Чтобы получать статьи с сайта — сделал парсинг страниц.
Настроил всё в автоматическом режиме и сделал приложение для Андроид.
Выложил приложение в маркет.
Через год со мной связался юрист и потребовал удалить приложение, потому что я нарушаю авторские права.
Спорить не стал. Обидно, что у самого forbes нет приложения по их же статьям с сайта.
Есть только сайт. А сайт у них тормозной, долго грузится и увешан рекламой.
Вот такая вот история.ferosod
04.04.2019 09:25Как можно сравнивать статьи с сайта и, например, цены или инструкции к лекартсвам?
Pashkevich
04.04.2019 09:30Контент — он и есть контент.
Я лишь хотел поддержать автора комментария в том, что любой контент — это некий труд. И не все хотят, чтобы этот труд забирался и использовался массово.
Это мое личное мнение.makasin4ik Автор
04.04.2019 10:2890% заказов — мониторинг цен, ассортимента. Если вы думаете, что все только и ждут чтобы украсть контент — это не так…
makasin4ik Автор
04.04.2019 10:45в России тоже. Мы оказываем услугу по сбору данных. И за эту услугу просим деньги. Мы не продаем сами данные. Я, к слову, всех клиентов предупреждаю, что они могут нарушить закон если будут использовать например описания.
Но опять же из опыта — 90% заказчиков ваши описания не интересуют вообще. Цены, ассортимент, акции. Все.
Occama
04.04.2019 11:53Не вынося личных оценочных суждений предмету обсуждения, всё же спрошу: чем это технически отличается от ситуации, когда конкурент нанял бы дюжину усидчивых индусов, которые просто перепечатали бы всё необходимое? В какой момент начинается неэтичное? Это может казаться софизмом, но мне действительно интересно, где на промежутке от «взять единственную ценю с одностраничного лендинга» до «спарсить Амазон целиком», по вашему мнению, заканчивается этичность происходящего?
Tatikoma
04.04.2019 12:00+1Как правило способ реализации не имеет значения, а имеет значение само деяние. Т.е. нет разницы убьёте вы человека ножом или роботом — ответственность одинаковая. Так же и здесь — нет разницы парсите вы индусами или роботами.
Это безотносительно этичности, — грань этичности будет стоять в одном месте и для индусов, и для роботов.Occama
04.04.2019 12:16А вторая часть? Вот работаете вы в сфере продаж каких-нибудь ошейников для пчёл. Всё мировое Р'н'Д потянуло пока сделать всего одну модель, да и конкурентов у вас всего трое. Вы заходите к каждому на сайт, смотрите, сколько они хотят за один ошейник, делаете выводы. Этично? Вполне.
Пример с другого края спектра я привести не могу, просто потому, что сам всё же считаю данную тему inherently этичной, но, судя по всему, вы где-то там начинаете видеть отсутствие этичности. Но мониторинг рынка был неотъемлемой частью экономики ещё со времён, когда пойманную рыбу меняли на шкуры мамонтов, просто потому, что, если ты вдруг запросишь десять шкур за одну рыбу, то и будешь, как дурак, с этой рыбой сидеть и мёрзнуть, потому что сосед отдаст за одну шкуру полсотни рыб и все будут довольны.Tatikoma
04.04.2019 12:27Как я и сказал «безотносительно этичности». Я лишь хотел отметить то, что нет смысла делить на индусов и роботов.
Касаемо этичности — я просто не задумывался. Мне нужно значительно больше времени, чтобы сформировать позицию по этому вопросу.Occama
04.04.2019 12:38Согласен, что нет смысла делить на индусов и роботов, в этом и посыл. Но как раз тут у нас встаёт вопрос этичности заказчика. А сами датафидовцы, в общем-то, действительно ничего не нарушают, более того, насколько я понял, они уведомляют заказчиков о том, какие конкретно в каком случае могут возникать спорные вопросы. Я свечку не держал, но, как минимум по описанию, они выглядят, как наиболее этичные по возможности представители ниши, которую бы кто-то занял в любом случае.
makasin4ik Автор
04.04.2019 12:17все верно. сидят операторы, собирают данные. Кстати, на те же авиа-билеты люди руками собирают данные, знаю 100%. Хотя можно и парсить.
i8008
04.04.2019 22:29чем это технически отличается от ситуации, когда конкурент нанял бы дюжину усидчивых индусов
с точки зрения «этичности» — ничем не отличаются, как уже заметили в комментариях выше
по вашему мнению, заканчивается этичность происходящего
Я не знаю. Но я знаю, как однозначно решить вопрос этичности в каждом конкретном случае – просто спорить разрешения у владельца ресурса (мы хотим спарсить вашу базу для таких-то целей). Возможно, и парсить не придется.
Как пример – владелец lamptest.ru провел огромную работу, составил уникальную базу и, при этом, выложил базу в открытый доступ.
anprs
05.04.2019 11:20Некто создал базу товаров. Потратил кучу ресурсов на поиск информации, систематизацию этой информации, вынесение данных в базу
И выложил, по сути, в общий доступ.haldagan
05.04.2019 12:44+1Общий доступ != общественное достояние.
То, что блоггеры, например, бесплатно выкладывают статьи собственного сочинения на всеобщее обозрение совершенно не означает, что статьи эти не защищены авторским правом.
1) Вы не можете присвоить их авторство себе.
2) Вы не можете публиковать их где-то еще, если такого разрешения вам не было дано. Обычно такое разрешение звучит как нечто вроде «разрешено к распространению с обязательной ссылкой на первоисточник».
То же касается и интеллектуальной собственности: если вы на гитхабе нашли нужный вам модуль «в общем доступе», это еще не дает вам права безвозмездно использовать его код (частично или полностью) в своем проекте.
OloloFine
03.04.2019 21:51Как я уже намекал в другой ветке, всё просто:
- Ваша деятельность как «водителя бота» этична ровно настолько, насколько Ваш бот соблюдает robots.txt посещаемого сайта. Не исходя из допущений вида «страницы товара не закрывают», а буквально накладывая маски allow и disallow на запрашиваемые URL. Отсутствует robots.txt — трактуйте в Вашу пользу, присутствует, но вы его нарушаете — однозначно Вы абьюзите сайт.
- Что делают с контентом Ваши заказчики — уже на их совести
Конечно robots.txt не имеет силы закона, но если действительно припечет, не факт что точно пройдет мимо юристов.areht
03.04.2019 23:47В магазинах вешают таблички «фото запрещено», и это незаконно. И неэтично. Просто традиция такая.
robots.txt — это технический прием. Он не про этику.
Если вы хотите обозначить, что не желаете парсинга — делаете раздел, вроде такого: account.habr.com/info/agreement
Не знаю будет ли такое ограничение законным, но, как минимум, свои пожелания можете там изложить человеческим языком (или упомянуть robots.txt), потом можно про этикуOloloFine
04.04.2019 00:12+1Странно, но почему тогда бот гугла ограничение на краулинг в этом agreement проигнорирует, мало того — цинично спарсит и в поиске покажет, а robots.txt еще как приймет во внимание??? Наверно потому что он бот, и что-бы с ним договориться о границах этичного ( очертить пожелания хозяина сайта о поведении на его территории ) и придумали этот «технический прием».
Попробуйте глянуть на ботов чуть «шире» чем боты топикстартера, которые работают по заданному списку УРЛ — боты могут бродить где попало, находя УРЛы для парсинга in the wild.areht
04.04.2019 00:47Потому, что бот гугла не руководствуется этикой вообще. А вот пусть Вы хотите поделиться, но не хотите нагрузку на сайт — запрещаете robots.txt, и разрешаете разово спарсить. Этично брать базу, даже против robots.txt? Этично.
Обсуждать этику применения абстрактных ботов в вакууме я не буду, у топикстартера индивидуальный подход к сайту, и метод «а если бы он вез патроны» к нему применять неэтично )
khim
04.04.2019 04:37Странно, но почему тогда бот гугла ограничение на краулинг в этом agreement проигнорирует, мало того — цинично спарсит и в поиске покажет, а robots.txt еще как приймет во внимание???
Потому что только соблюдение описаний в robots.txt позволяет Гуглу заявлять о том, что у него есть Implied license (и да, судебные процессы, где эта теория проверялась на прочность, отгремели много лет назад… и во многих юрисдикциях). Именно существование robots.txt и соответствующего описания позволяет сделать вывод, что данные с сайта предназначены не только для людей — но и для ботов… Если бы авторы сайта хотели бы иного, то запретить ботам сканировать сайт они могли бы создав файл с парой строк, а если они этого не делают — то, соответственно, приходим к выводу, что они хотят, чтобы их парсили.
diseaz
04.04.2019 15:47Когда очень надо, чихать хотел и Google, и Яндекс, и все прочие на robots.txt. Не только зайдут, но ещё и анонимно, маскируясь под пользователя. Просто потому, что иначе не сделать хоть сколько-нибудь работающий SafeBrowsing и не проконтролировать адекватность страниц, на которые ведут рекламные объявления. Если не ходить под robots.txt и не маскироваться, то первый же школьник догадается спрятать очередной «Internet speed booster» с трояном под robots.txt или отдавать заготовленный «хороший» landing только *bot'у, а всем остальным — какое-то говно, которое нарушает все правила рекламного сервиса.
Есть и другие легитимные активности, которые намеренно и в открытую игнорируют robots.txt для выполнения своей функции.khim
04.04.2019 16:44Там не всё так просто. Все описанные вами вещи действительно имеют место быть… вот только делают это не Гугл-боты автономно, а исключительно люди… ну с и некоторой помощью со стороны Гугла, не без этого. Которые используют Хром или, когда Хрома не было, Google Toolbar.
Или вы думаете зря Гугл так усиленно продвигал Google Toolbal пока Хрома не было, а как Хром появился — вдруг перестал? Вот теперь вы знаете ответ на вопрос «почему?»…diseaz
05.04.2019 09:37Я не понял, о какой именно городской легенде идёт речь:
- Гугл сделал из Хромов ботнет, через который «исключительно люди» посещают и вручную мониторят все бинарники и лендинги?
- Хром каждого пользователя отсылает в Гугл всё, что скачивает для «исключительно людей»?
- В Хроме есть какая-то доп. функциональность для «исключительно людей» в стиле «прокликай 1000 ссылок, которые мы предложим, и получи $1»?
Во-первых, это всё чушь (с вероятностью 99.9%). Во-вторых, это не опровержение, не подтверждение, и вообще никаким боком не связано с моим постом: куча вполне легитимных ботов в Сети вполне легитимно и открыто кладут с прибором на robots.txt.
khim
05.04.2019 14:33Хром отсылает в Гугл ссылки на помещённые страницы, которые тот проверяет на безопасность. Так посещает страницу обычный человек, то robots.txt его не касается.
А рассказы про то, что вы можете парсить что угодно и когда угодно невзирая на robots.txt — приберегите для суда. Они вам там понадобятся.
abmanimenja
05.04.2019 09:11Просто потому, что иначе не сделать хоть сколько-нибудь работающий SafeBrowsing и не проконтролировать адекватность страниц, на которые ведут рекламные объявления
Проверки в интересах рекламного бизнеса, который платит сайтам — это другое.
Парзить контент, созданный чужим трудно, чтобы выложить его на своем сайта — совсем другое дело.khim
05.04.2019 14:34Выборочные проверки попадают под пункт о «незначительном объёме» статьи 1335.1, ко всему прочему.
makasin4ik Автор
04.04.2019 10:46никоем образом такое ограничение не будет законным. Это не я сказал — наши юристы.
khim
04.04.2019 04:29Конечно robots.txt не имеет силы закона, но если действительно припечет, не факт что точно пройдет мимо юристов.
А ему и не нужно. Закон уже есть — это закон об авторском праве. Он запрещает парсинг и вообще любое копирование без разрешения правообладателя. И даже детский лепет про «фактические данные» вас не спасёт — специально для вас в ГК есть статья 1334, почитайте на досуге.
А вот robots.txt — спасти как раз может. Потому что он, фактически, является лицензий. Но для того, чтобы его можно было в таком качестве использовать — его таки надо соблюдать. Использовать уникальные и легко идентифицирующиеся названия для ботов, не пытаться выдавать себя за браузер и т.д. и т.п.
В противном случае — это уголовка и вопрос только в том, когда и кто первым сподобится потратить время и силы на то, чтобы отправить вас в «места не столь отдалённые»…
FRiMN
04.04.2019 11:28Каким образом парсинг стал равен нарушению авторских прав?
makasin4ik Автор
04.04.2019 12:16никоем. нарушение — это заказать у нас парсинг, а потом вывалить контент на свой сайт.
khim
04.04.2019 12:40Нарушение — парсить контент, владельцы которого сделали хотя бы самые минимальные телодвижения к тому, чтобы он был закрыт. Скажем robots.txt создали, где разрешили ходить только Гуглу и Яндексу.

vedenin1980
04.04.2019 13:00Скажем robots.txt создали
robots.txt это протокол рекомендаций, ни один суд не примит причину «закрыт в robots.txt», который многие легальные веб-сканеры (например веб архив) не соблюдают. Данные публичны пока они открыты для пользователей.
nikandr23
04.04.2019 17:11+3дивный маня мир.
люди Открыто выкладывают информацию в инторнеты,
заявляют что эту информацию можно читать Только Человеческими Глазами,
а иначе ай «воровство контента».
makasin4ik Автор
04.04.2019 17:28+1ну собственно так и есть. Руками собирать можно, а парсить роботом нельзя.
khim
04.04.2019 12:38Статью 1334 ГК РФ, я так понимаю, не читали? «Никто не вправе извлекать из базы данных материалы и осуществлять их последующее использование без разрешения правообладателя», однако.
И копирование этой статьи к вам на компьютер и парсинг сайта — нарушают «исключительные права» правообладателя… однако скачивание статьи к вам на компьютер — предполагается техническими средствами Web'а (см. Implied License), а парсинг — строго говоря, нет.vedenin1980
04.04.2019 12:53А вы статью 1335.1 ГК РФ.? Где оказывается, что в личных, научных, образовательных или в небольшими частями из публичной базы внезапно извлекать можно. А так же можно получать информацию, которая уже есть в других источниках.
Более того, анализировать цены в публичной базе это вполне нормальное использование этой базы, а значит ни один суд не может мне, как пользователю, использовать любые технические средства для такого анализа (ну вот не хочу я вручную искать где дешевле продают айфон). Так же ни одна лицензия не может запретить конкуренту зайти на ваш сайт и посмотреть там цены. Опять-таки, есть пункт про научные интересы (а анализ цен вполне научен).
Ну и до кучи, наказание определяется иском от реального убытка, а скачивание публичной базы без ее использование, очень сложно подвести под реальный убыток правообладатели.OlegAndr
04.04.2019 18:17+2>у вот не хочу я вручную искать где дешевле продают айфон
Это личное использование. Вот когда вы за это начнете брать деньги, наступает уже другая история.
abmanimenja
05.04.2019 09:17Где оказывается, что в личных, научных, образовательных или в небольшими частями из публичной базы внезапно извлекать можно.
Вся статья о парзинге для целей коммерции.
Ни научных, ни личных, ни образовательных целей.
Ни небольших частей — иначе бы и бизнеса этого не было, те кто сейчас заказывают вручную бы просмотрели небольшие объемы.
Опять-таки, есть пункт про научные интересы (а анализ цен вполне научен).
Если вы пишете диссертацию про колебания цен — да, конечно.
Но что-то мне подсказывает, что заказчики автора статьи заказывают мониторинг ради использования в коммерческих целях, а не для диссертаций.
Pashkevich
04.04.2019 11:37+2Парсинг != Нарушение авторских прав
Нарушение авторских прав == Незаконное Копирование и Использованиеkhim
04.04.2019 12:41Ну и каким же образом ваше копирование становится законным, в данном случае?
Pashkevich
04.04.2019 12:47Я не силен в юр.терминологии.
Возможно отдельно слово «копирование» и отдельно «использование» НЕ запрещено.
А вот с предлогом «И» — запрещено. Как-то так.

androidovshchik
04.04.2019 14:31К чему тогда ведет парсинг, кроме как не к незаконному копированию и использованию? Я думаю, здесь аналогия может быть с покрыванием преступников. Да, я не совершал преступление, но содействовал преступникам и, следовательно, тоже виновен (если, конечно, было преступление, но оно скорее будет)
Pashkevich
04.04.2019 14:40Может для личного пользования я могу использовать без разрешения и запретов? (мое предположение).
Вот пример. Персонажи Marvel (либо Angry Birds) — это защищенные торговые марки, которые нельзя без разрешения использовать и распространять.
Но никто не запрещает мне сделать дома фигурку Marvel и поставить на полку. Всё для личного пользования.
Возможно с парсингом «другая тема». И здесь вы упираете на то, что автор статьи не совсем для себя парсит данные, более того еще и зарабатывает на этом.khim
04.04.2019 14:47Там внизу цитату приводили. «В личных, научных, образовательных целях в объеме, оправданном указанными целями» — можно и без разрешения.
vedenin1980
04.04.2019 14:49если, конечно, было преступление, но оно скорее будет
Есть много причин, когда парсинг полностью легален. Например, marketing research это целая наука, которая включает анализ ценообразования конкурентов, она легальна во всех (вроде бы) странах.
Я занимался давным давно парсингом, но всегда просили делать вполне легально и морально правильный парсинг.
— Несколько раз посредники просили сделать парсинг оптовика (для продажи его же товаров), сам оптовик был не против, но вкладываться в разработку API совершенно не собирался (или не мог по тех.причинам),
— один раз посредник одного китайского магазина просил сделать интеграцию, но там api китайского магазина был настолько долбанутый и ограниченный, что частично приходилось получать инфу парсингом,
— Один раз автор и владелец сайта и форума хотел мигрировать с бесплатного сайта, который зажимал базу данных,
— Так же делал интеграцию сайта литературного конкурса и его же форума, чтобы при добавлении нового рассказа автоматически появлалась тема на форуме (по тех.причинам это невозможно было сделать иначе)
areht
04.04.2019 18:04> здесь аналогия может быть с покрыванием преступников
Вы про УК РФ Статья 316. Укрывательство преступлений? А вы её читали?
Если бы там ваша логика была применима, то надо было бы таксистов сажать, они скорее всего уголовников возили.androidovshchik
04.04.2019 19:36Ну знаете, если бы мне в машину странный тип, на чей счет были бы подозрения, то следовало бы обратиться в полицию. Когда заказывают парсинг, не предоставляя при этом какие-л. права на ресурс, то как минимум есть лишний повод усомниться в законности. Остается либо закрывать на это глаза, либо «ввести себя порядочно». Ничего не имею против ситуаций, описанных vedenin1980 выше. PS я сам пару раз делал не совсем чистые приложения и счастья это не принесло, только негатив остался
areht
04.04.2019 21:29> Ну знаете, если бы мне в машину странный тип, на чей счет были бы подозрения, то следовало бы обратиться в полицию.
Ну и вам там ответят «когда убьют — тогда и приходите».
> не предоставляя при этом какие-л. права на ресурс
Права, техпаспорт, справку в бассейн.
Попробуйте, для начала, хотя бы медкнижки у официантов проверять. Если этого мало покажется — приходите, расскажу про перестикеровку. Опасных преступников ловить будете, потенциальных убийц.androidovshchik
05.04.2019 10:15Это все примеры халатности. К сожалению, она везде, но если бы каждый хоть немного старался что-то исправить, то мир был бы куда лучше, чем сейчас. Никто никого не заставит, дело каждого решать, как ему поступать. Опять же, это только моральная точка зрения, по поводу закона — это головная боль уже соотв. органов власти
areht
05.04.2019 13:06Ну вот не будьте халатны. Каждый раз проходя мимо нарезки в универсаме Вы наблюдаете (и покрываете) нарушение. Там отсутствует дата производства и срок годности (есть только дата упаковки) — сообщайте в полицию, Роспотребнадзор и спортлото.
Если магазин круглосуточный и время упаковки около часа ночи — это просто гарантия того, что вчерашнюю нарезку переупаковали с новой датой, а свежую нарезку делают по утрам. В остальных — или парез закрытием, или после открытия. Процесс «пачками забирают старую нарезку и несут к весам и она появляется посвежевшей» особо не скрывают, достаточно в нужное время придти и посмотреть.
В отличии от «я таксист, я вам подозрительного человека привез, в чем виноват не знаю» это точно незаконно и доказуемо.
areht
04.04.2019 12:09Уголовка — в УК, а не в ГК
khim
04.04.2019 12:45Формально вы правы. Но в УК (статья 146я) описываются только масштабы нарушений, которые позволяют классифицировать нарушение авторских прав как уголовку. Сами по себе права описаны в ГК — а на масштабы, позволяющие классифицировать деяние как уголовку, регулярный парсинг, такой, что возникает вопрос «а не ляжет ли сайт», без проблем вытягиваются.
areht
04.04.2019 14:17+1Там «крупный размер» — это не в количестве спарсенных страниц, а в деньгах. Как вы вообще оцените парсинг (и его регулярность), как нарушение авторских прав (!), в деньгах?
Положить сайт — это другая статья.khim
04.04.2019 14:50Там «крупный размер» — это не в количестве спарсенных страниц, а в деньгах. Как вы вообще оцените парсинг (и его регулярность), как нарушение авторских прав (!), в деньгах?
А как обычно в таких случаях делают и откуда может штраф в сотни тысяч долларов за одну копию фильма взяться?
Высчитывается «упущенная прибыль» с соответствующим коэффициентом. Можно с каких-нибудь договоров просчитать — сколько будет стоит купить у вас ту же информацию легально и отсюда плясать.areht
04.04.2019 15:17> откуда может штраф в сотни тысяч долларов за одну копию фильма взяться?
Точно не из уголовного дела.
(и Вы не путайте штраф и ущерб. Вот вы по хулиганке разбили бутылку пива: Ущерб — 30 рублей, штраф — до 1000р, а по гражданскому иску потом хоть триллион отсуживайте за «упущенную выгоду», но это уже не штраф)
> сколько будет стоит купить у вас ту же информацию легально и отсюда плясать.
Ну, для начала, вы должны её изначально продавать (а не выкладывать в публичный доступ), выдумывать цифру задним числом не прокатитkhim
04.04.2019 16:48Ну, для начала, вы должны её изначально продавать (а не выкладывать в публичный доступ), выдумывать цифру задним числом не прокатит
Серьёзно? Не прокатит? Поинтересуйтесь вначале сколько стоит коммерческая лицензия на Консультат-Плюс какой-нибудь. Притом что та же инфрмация у них и на сайте лежит.
Всё, разумеется, будет зависеть от того, каких экспертов вы привлечёте, но вытянуть «ущерба» на уголовку для крупного магазина — не проблема. А у мелких и денег-то на приличного юриста не найдётся, так что там непринципиально.areht
04.04.2019 17:01нет, не лежит. Как только Вы полезете дальше десятка основных законов, вы быстро наткнетесь на предложение купить ту самую коммерческую версию.
Вы же прайс не продаете вообще, что эксперт то сочинять будет? Конкретно, а не «хороший юрист натянет без проблем»
vedenin1980
04.04.2019 12:16специально для вас в ГК есть статья 1334, почитайте на досуге.
А статью «Статью 1335.1» вы читали?
1. Лицо, правомерно пользующееся обнародованной базой данных, вправе без разрешения обладателя исключительного права — изготовителя базы данных и в той мере, в которой такие действия не нарушают авторские права изготовителя базы данных и других лиц, извлекать из базы данных материалы и осуществлять их последующее использование:
— в целях, для которых база данных ему предоставлена, в любом объеме, если иное не предусмотрено договором;
— в личных, научных, образовательных целях в объеме, оправданном указанными целями;
— в иных целях в объеме, составляющем несущественную часть базы данных.
…
4. Изготовитель базы данных не может запрещать использование отдельных материалов, хотя и содержащихся в базе данных, но правомерно полученных использующим их лицом из иных, чем эта база данных, источников.
Для открытых баз в инете это практически означает, что всякие мониторинги цен и т.п. действия парсинга вполне легальны, криминалом будет лишь публикация уникальных описаний товаров на сайте конкуренте. Более того тот кто выполняет парсинг не может знать нужна ли база заказчику для личных, научных, образовательных или других целей.
В противном случае — это уголовка и вопрос только в том, когда и кто первым сподобится потратить время и силы на то, чтобы отправить вас в «места не столь отдалённые»…
У вас смешались люди, кони… Ну какая уголовка и «места не столь отдалённые» в гражданском кодексе? Там вообще преступлений нет, только нарушения, штраф и иски. Если вы посмотрите, чем вам грозит нарушение интеллектуальных прав, то это… компенсация реально понесенного вреда правообладателем и прекращения использование интеллектуальных прав. Если вы только спарсили публичные данные с сайта и ничего с этим не делали, то реально понесенные потери правообладателя близки нулю и очень сложно будет убедить суд в обратном.khim
04.04.2019 12:59Вы бы хотя бы прочитали свою собственную цитату, а? Мониторинг цен скачивает существенную часть базы, так что под «иные цели в незначительных объёмах» явно не попадает. Личные, научные, образовательные цели? Мимо — мы ведём речь явно не о публикации научной статьи. Речь идёт о конкурентах, в основном. В целях, для которых база была предоставлена? Дык она для того, чтобы была возможность выбора у покупателя сделана! Сколько там товара закупил топикстартер?
Я видел случаи, когда люди дают ссылки на статьи, которые из слова опровергают… Но чтобы прямо их процитировать — это в первый раз…
Более того тот кто выполняет парсинг не может знать нужна ли база заказчику для личных, научных, образовательных или других целей.
А если не знает — то не имеет права парсить — прочитайте же, блин, то, что вы нацитировали ещё раз!
Если вы посмотрите, чем вам грозит нарушение интеллектуальных прав, то это…
принудительные работы на срок до пяти лет либо лишение свободы на срок до шести лет со штрафом… Откройте УК и почитайте же статью 146, блин!компенсация реально понесенного вреда правообладателем и прекращения использование интеллектуальных прав.
Да, это всё только в случае «особо крупного размера», натянуть на него запуск wget'а вам не удастся, а вот «промышленный» парсинг с арендованным серверами и прочим… вполне.dimm_ddr
04.04.2019 13:28+1В целях, для которых база была предоставлена? Дык она для того, чтобы была возможность выбора у покупателя сделана!
Это где-то указано? Если нет, то это всего лишь предположение, на него опираться нельзя.
А если не знает — то не имеет права парсить
А можно цитату где это написано?
vedenin1980
04.04.2019 13:36Мониторинг цен скачивает существенную часть базы, так что под «иные цели в незначительных объёмах» явно не попадает.
Нее, это надо доказывать в суде. Цена лишь незначительный процент среди остальной информации (фото, описаний), скачивание 1% от базы это незначительный объем. Нет, можете доказывать в суде, но тут у кого адвокаты лучше.
Личные, научные, образовательные цели? Мимо — мы ведём речь явно не о публикации научной статьи.
Кто сказал? Как вы докажите, что я во время скачивания не планировал публикацию научной статьи? Как мы можете доказать, что заказчик не хотел получить данные ради личных данных. Исполнитель не обязан узнавать цели по которым его просил скачать заказчик. Все претензии к заказчику.
Дык она для того, чтобы была возможность выбора у покупателя сделана! Сколько там товара закупил топикстарт. Речь идёт о конкурентах, в основном.
База это публичные данные, а цены это оферта. Вы не можете запретить конкуренту зайти на ваш сайт или в ваш магазин, он такой же пользователь сайта, как и остальные и может для своих личных целей бизнеса анализировать ваши цены. Ни один суд не согласится, что вы имеете право прятать цены от вашего конкурента, но показывать остальным покупателям.
Более того тот кто выполняет парсинг не может знать нужна ли база заказчику для личных, научных, образовательных или других целей.
А если не знает — то не имеет права парсить — прочитайте же, блин, то, что вы нацитировали ещё раз!
Докажите, заказчик сказал, что ему данные нужны для научной статьи, докажите, что исполнитель обязан требовать какие-то подтверждения (какие?).
Внимательно посмотрите пункт:
4. Изготовитель базы данных не может запрещать использование отдельных материалов, хотя и содержащихся в базе данных, но правомерно полученных использующим их лицом из иных, чем эта база данных, источников.
Раз вы выложили цены на сайт это публичные данные/оферта, которые так же можно получить позвонив в фирму или зайдя в магазин. Их нельзя по закону скрывать, более того они не могу являться защитой интеллектуальной собественности. В конце концов, моя соседка Люся могла зайти на ваш сайт и потом сказать мне, что у вас айфон дешевле чем у меня.
Да, это всё только в случае «особо крупного размера», натянуть на него запуск wget'а вам не удастся, а вот «промышленный» парсинг с арендованным серверами и прочим… вполне.
Нее, нужно показать именно реально понесенный ущерб, мало ли зачем арендованный сервер работает, а вот с этим сложно, судья спросит, а что секретарь конкурента не могла вручную зайти на сайт и получить все эти цены (ну ладно десяток офис менеджеров)? Могла, тогда где ущерб?
Вообще, цена на сайте это публичный договор, ее нельзя делать тайной и более того нельзя делать разной для разных потребителей. В том числе владелец фирмы конкурента должен иметь равное право узнать цену на ваш товар и купить товар по этой цене, иначе вы нарушаете ГК РФ Статья 426.khim
04.04.2019 17:09Ни один суд не согласится, что вы имеете право прятать цены от вашего конкурента, но показывать остальным покупателям.
Ага, конечно. А тысячи фирм, высылающих цены «по запросу» (некоторые имеют даже блоги на Хабре) — они все, конечно, «нарушители закона».
Внимательно посмотрите пункт:
А сами своему совету не пробовали последовать? Читаем внимательно: правомерно полученных использующим их лицом из иных, чем эта база данных, источников.
4. Изготовитель базы данных не может запрещать использование отдельных материалов, хотя и содержащихся в базе данных, но правомерно полученных использующим их лицом из иных, чем эта база данных, источников.
То есть использовать сведения — да ради бога. Докажите, что они появились у вас не в результате парсинга сайта, убедите в этом суд — и пользуйтесь на здоровье.
Да, если магазин — ваш конкурент сможет доказать, что пользовался не результатами парсинга сайтов, а «рассказами бабы Люси», то он — cможет соскочить с крючка. Вы — нет.
Докажите, заказчик сказал, что ему данные нужны для научной статьи, докажите, что исполнитель обязан требовать какие-то подтверждения.
Серьёзно? Ваш заказчик, представитель торговой сети, заказал вам получение данных под научное исследование, а том, что он будет их использовать в комменрческих целях вы даже не догадывались? Тут скорее психологическая экспертиза о вменяемости требуется.
(какие?)
Любые — но такие, которые смогли бы суд и присяжных (если они будут иметься) убедить в том, что коммерческая организация заказывает данные для проведения научного исследования, а не для коммерческой деятельности. С учётом того, что люди, странным образом, склонны предполагать, что коммерческая организация интересуется, в общем-то, в первую очередь коммерцией — это сделать непросто. Не «невозможно», но… непросто.
Цена лишь незначительный процент среди остальной информации (фото, описаний), скачивание 1% от базы это незначительный объем.
Ещё раз: не нужно считать судей идиотами. Они — не механиченский парсер текстов законов. И 1% и даже 0.01% могут оказаться значительными объёмами, если удастся показать, что они ощутимо уменьшают ценность самой базы. В случае с каталогом цен — это достаточно очевидно.
Нее, нужно показать именно реально понесенный ущерб, мало ли зачем арендованный сервер работает, а вот с этим сложно, судья спросит, а что секретарь конкурента не могла вручную зайти на сайт и получить все эти цены (ну ладно десяток офис менеджеров)?
И любая экспертиза вам покажет, что нет — не могла. Зайти на сайт — могла, собирать данные ежедневно по каталогу в полмиллиона наименований — не могла. Да и какая, собственно, разница? В законе нет исключений на тему: «с помощью компьютера базу данных копировать нельзя, а переписав на листочк бумажки — можно».
В том числе владелец фирмы конкурента должен иметь равное право узнать цену на ваш товар и купить товар по этой цене, иначе вы нарушаете ГК РФ Статья 426.
Если он его хочет купить — тогда да, разумеется. Но вам, опять-таки, придётся доказывать, что вы, владея конкурирующей фирмой, хотели-таки именно купить товар… это будет непросто, уверяю ваc.
P.S. Всё это, разумеется, касается только всяких хитрых штук типа «положите товар в корзину, чтобы узнать цену» (как на Amazon иногда бывает). Если вы парсите просто странички соблюдая robots.txt — то тут, как я уже писал выше, вы можете ссылаться на Implied License — и оспприть это будет непросто…
enzain
04.04.2019 22:27Как вы докажите, что я во время скачивания не планировал публикацию научной статьи? Как мы можете доказать, что заказчик не хотел получить данные ради личных данных.
Вот тут очень интересный вопрос. Так как это не УК, то доказывать придется вам свою невиновность, а не прокурору вашу виновность. Такая вот штука…
khim
05.04.2019 00:00О, с этой разницей вообще есть очень красивая пьесня. Когда вначале на вас заводят уголовное дело (что можно сделать, вообще говоря, и без правообладателя и его заявления), а потом, «после выяснения обстоятельств дела» — сумма ущерба уменьшается, дело переходит в разряд административных правонарушений… зато и бремя доказательства переходит от обвинителей к обвиняемым…
kbaa
04.04.2019 17:13+1УК РФ Статья 146. Нарушение авторских и смежных прав
1. Присвоение авторства (плагиат), если это деяние причинило крупный ущерб автору или иному правообладателю,
…
2. Незаконное использование объектов авторского права или смежных прав, а равно приобретение, хранение, перевозка контрафактных экземпляров произведений или фонограмм в целях сбыта, совершенные в крупном размере,
…
3. Деяния, предусмотренные частью второй настоящей статьи, если они совершены:
А каталог товаров на сайте каким боком относится к авторским и смежным правам? (исключая фото и авторские описания(которые не так часто встречаются) )khim
04.04.2019 20:17А каталог товаров на сайте каким боком относится к авторским и смежным правам?
База данных, однако. На них, удивительным образом, тоже авторские права распространяются.
Хороший примерг — это «Гарант». Там нет ничего, что отсутствует в «публичных источниках». Тем не менее если вы свою подписку на неё (а она весьма недёшева) «расширите» — получите хороший такой штраф. Именно за нарушение авторских прав.kbaa
04.04.2019 22:00Да, почитал побольше, не всё так просто, но и не всё предельно ясно тоже
Написание скрипта для сбора данных само по себе легально при любом раскладе, получается?khim
04.04.2019 23:05Написание скрипта для сбора данных само по себе легально при любом раскладе, получается?
Написание — да. Более того — использование «в личных, научных, образовательных» целях — тоже да.
И, как тут уже замечали: многие вполне не против того, чтобы их парсили. Ибо ну не могут они выдать информацию в более удобочитаемом виде.
Но если люди активно не хотят, чтобы их парсили и с вами борются — то тут уже повод задуматься. Причём о многих разных философских вопросах.
Потому что если компания большая — то может быть всякое. Например местный филиал скажет «да качайте что хотите — нам пофиг». А потом головной — подаст на вас в суд. На этот случай разрешение лучше иметь в каком-нибудь подаваемом в сут виде, а не просто «Вася по телефону разрешил».
areht
04.04.2019 22:35Вообще, называть сам сайт базой данных — это довольно свободное толкование. Судебная практика такая вообще есть?
> Там нет ничего, что отсутствует в «публичных источниках».
Ой, да ведь ОНИ ЖЕ ПАРСЯТ И ПЕРЕПРОДАЮТ!abmanimenja
04.04.2019 22:45Ой, да ведь ОНИ ЖЕ ПАРСЯТ И ПЕРЕПРОДАЮТ!
Они-то парзят бесплатное.
Вы путаете техническую возможность сделать это и юридический запрет этого не делать.
Так-то грабить в тихом переулке слабых девушек/стариков технически тоже несложно.
Вообще, называть сам сайт базой данных — это довольно свободное толкование. Судебная практика такая вообще есть?
Да, на этом рынке все очень жестко. Работал с дилером одной из подобных систем.
Сейчас не знаю, а раньше было 3 крупнейших игрока — в масштабах страны это огромные финансовые возможности у каждого и большие усилия на удержание доли рынка. В т.ч. и судебные разборки на взлом их систем, в которых «всего лишь общедоступная информация».areht
04.04.2019 23:57> Они-то парзят бесплатное.
Ну хоть согласились, что бесплатно выложенное в сеть парсить можно.
> в масштабах страны это огромные финансовые возможности у каждого и большие усилия на удержание доли рынка.
космические корабли бороздят… Вопрос был в том, можно ли сайт базой данных называть, а не про взлом.abmanimenja
05.04.2019 10:04Ну хоть согласились, что бесплатно выложенное в сеть парсить можно.
Вы путаете техническую возможность и юридическую.
В принципе, велосипед, если хозяин от него отошел, тоже угнать можно. Технически. Но не юридически.
Кстати, фактически, его и искать полиция не будет.
Но это не делает угон велосипеда законным.
areht
05.04.2019 15:33то есть роботам Консультанта угнать велосипед законно, а у них — нет? Ну… А почему?
abmanimenja
05.04.2019 16:48то есть роботам Консультанта угнать велосипед законно, а у них — нет? Ну… А почему?
Они не парзят, там не только роботы, но много и человеческой работы.
Берут из бесплатных источников.
'Российская газета' официальный источник принятых законовПосле публикации в этом издании вступают в силу государственные документы: федеральные конституционные законы, федеральные законы (в том числе кодексы), указы Президента России, постановления и распоряжения Правительства России, нормативные акты министерств и ведомствareht
05.04.2019 16:54а что, а законе какие-то исключения о «парсинге бесплатных источников»? Авторские права российской газеты отличаются?
Или добавление индекса и матчинга распарсенный сайт авторство меняет?abmanimenja
05.04.2019 17:11а что, а законе какие-то исключения о «парсинге бесплатных источников»? Авторские права российской газеты отличаются?
Никто не говорит про авторские права на сами тексты законов.
Речь об индексированных/подготовленных/обработанных данных из Консультанта.
И о сырых данных, простых текстах из Российской газеты.
Или добавление индекса и матчинга распарсенный сайт авторство меняет?
Авторства исходных данных — нет.
А вот права на обработанный материал — да.
Пример про аранжировку музыкальный произведений:
Аранжировка = переделка музыкального произведения, при которой основная музыкальная тема первоначального произведения остается узнаваемой.
Считается, что создатель вариации (аранжировщик), меняя ритм и такт, изменяя манеру и тональность, осуществляет творческое воздействие на гармонию и мелодический строй произведения, что приводит к созданию хотя и несамостоятельного, но охраняемого авторским правом произведения.areht
05.04.2019 17:54> И о сырых данных, простых текстах из Российской газеты.
Эк вас… Значит там «простые данные» и законом не охраняются, а в консультанте — «база данных». И при этом то и другое — сайт на html.
> Пример про аранжировку музыкальный произведений:
Нет уж, давайте про базы данных. Индексация права на безвозмездное использование базы распарсенного сайта даёт или нет?abmanimenja
05.04.2019 18:11И о сырых данных, простых текстах из Российской газеты.
Эк вас… Значит там «простые данные» и законом не охраняются
Мы говорим о вполне конкретной ситуации.
«Российская газета» — официальный источник законов (которые, напоминаю, вступают в силу после публикации в «Российской газете»). Сами по себе законы и пр. нормативные акты общедоступны и бесплатны (какие-то секретные постановления/указы могут быть, но это опять-таки ограничения на распространение в силу секретности, а не ограничения на распространение на основании авторских прав).
Непосредственно эти нормативные акты как раз можно свободно использовать.
А, скажем, книжка «Уголовный кодекс» вполне законно продается за деньги. Никто вам не обязан её бесплатно давать. Это плата за бумагу, а не за авторство.
А вот книжка «Уголовный кодекс с комментариями» — уже хоть не самостоятельное, но охраняемое произведение.areht
05.04.2019 18:55> Мы говорим о вполне конкретной ситуации.
Да. В этой ситуации боты консультанта цинично выкачивают базу данных Российской газеты с её сайта.
Права на использование каких-то отдельных актов из базы к этому отношения не имеют никакого.abmanimenja
05.04.2019 19:44+1Да. В этой ситуации боты консультанта цинично выкачивают базу данных Российской газеты с её сайта.
Еще раз:
«Российская газета» — не простая газета.
Законы вступают в силу после публикации в «Российской газете».
Это официальный источник с вполне свободным доступом к законам.
Понятие «охрана авторских прав» применим к «Российской газете» только в отношении публикуемых в ней статей. Но не публикуемых в ней нормативных актов.
Поэтому термин «цинично выкачивают» с сайта «Российской газеты» к данной ситуации не применим.
Её сайт как раз для того и существует, чтобы все имели доступ к текстам законов/нормативных актов.
areht
05.04.2019 20:24ФГБУ «Редакция «Российской газеты» также принадлежат исключительные права на подбор, расположение, систематизацию и преобразование данных, содержащихся на Сайте RG.RU. Сервисы Сайта RG.RU и контент «РГ» охраняются российским авторским правом и международным законодательством о защите авторских и смежных прав.
Никто не имеет права публиковать, передавать третьим лицам, участвовать в продаже или уступке, создавать производные продукты или иным образом использовать, частично или полностью, содержание Сайта RG.RU.
Использование (скачивание, загрузка, копирование, сохранение на диск, перепечатка в соцсетях) материалов «РГ» без получения разрешения правообладателя допускается только гражданами для личного использования. Иное использование, за исключением случаев свободного использования, предусмотренных статьями 1273-1279 Гражданского кодекса Российской Федерации, разрешается в порядке и на условиях, определенных ниже.abmanimenja
05.04.2019 20:43ФГБУ «Редакция «Российской газеты» также принадлежат исключительные права на подбор, расположение, систематизацию и преобразование данных, содержащихся на Сайте RG.RU
Но не на сами «исходники» законов, да?
Все так же как и в ситуации с Консультантом — тоже «систематизация» их, но исходники нет.
без получения разрешения правообладателя
Думаете, устойчивый бизнес, существующий не один десяток лет — не удосужился еще получить разрешения?
pravo.ru/review/view/37061
Основной способ пополнения СПС новыми документами — это договоры о предоставлении информации с государственными органами. Еще один источник — это различные издания, признанные официальными публикаторами соответствующих актов. Большинство органов власти имеют свои ведомственные издания, в которых публикуются принятые акты. В то же время, получение их текстов из соответствующего органа напрямую позволяет включать в базу тексты, которые не подлежат опубликованию (как правило, это различные информационные письма и прочие ненормативные документы).
areht
06.04.2019 01:42> Думаете, устойчивый бизнес, существующий не один десяток лет — не удосужился еще получить разрешения?
То есть оно таки нужно?
Думаю, нет. Там RSS, там и так удобно.
Вы бы не стали получать разрешение скачать прайс в .xls, хотя это явно чужая база данных.abmanimenja
06.04.2019 09:24То есть оно таки нужно?
Когда у вас устойчивый бизнес, вы принимаете меры, чтобы он продолжал оставаться устойчивым. Даже те меры, которые избыточны.
А пока вы мелкий и бедный — не делаете некоторые даже необходимые вещи. И полагаетесь в ряде случаев на авось. Ибо свободных ресурсов все равно нет.
Вы бы не стали получать разрешение скачать прайс в .xls, хотя это явно чужая база данных.
А как иначе его посмотреть, не скачивая?
Думаю, нет.
Зачем думать? Явно же видно:
Основной способ пополнения СПС новыми документами — это договоры о предоставлении информации с государственными органами
pravo.ru/review/view/37061
Это внесайтовый/безпарзинговый способ получения информации, не имеющий отношения к теме статьи.
areht
06.04.2019 14:25> А как иначе его посмотреть, не скачивая?
Получить разрешение, потом смотреть.
> Зачем думать? Явно же видно:
На левом сейте непонятными людьми на заборе написано? Ну, источник так себе.
Нет, договора с некоторым госорганами то как раз есть, конечно. Но мониторинг РГ это не отменяет.abmanimenja
06.04.2019 16:33На левом сейте непонятными людьми на заборе написано? Ну, источник так себе.
Ну ваши-то домыслы ничуть не более обоснованы.
А в той статье журналист, чувствуется, или имел доступ к реальным материалам или погуглил потщательнее нас с вами — исходя из мелких деталей про историю создания ПО — даты, названия фирм, этапы и пр…
Впрочем, вы можете написать туда и спросить откуда он это узнал.
areht
06.04.2019 16:54у вас статья из 2010, а сайт РГ официальным источником стал, кажется, в 2012.
за какие годы он там гуглил я не знаю — можете написать и спросить. Судя по статье, детали заканчиваются 1996.
источник так себе
makasin4ik Автор
04.04.2019 10:46Я совершенно с Вами согласен. Мы соблюдаем robots )) И да, что делают заказчики — их дело, мы их предупреждаем.
Tatikoma
03.04.2019 19:04+1Раз уж говорим о неприличном, я скажу про ещё более неприличное.
Так вот, — насчёт утверждения что от парсинга никак не защититься — я не соглашусь. Но вот цена защиты, скорее всего, — неподъёмная.
Желающие могут попробовать зарегистрировать пару тысяч аккаунтов в гугле (задача немного иная, но суть та же, — просто именно там стоит хорошая защита).
Там стоит botguard (его видно сразу в html-коде, его никто не прячет). На каждый запрос он собирает какие-то свойства из браузера, засекает разные таймеры (+ скорее всего таймеры на сервере), собирает события типа нажатий кнопок и движения мышки, скорее всего использует вариации canvas fingerprint (где-то натыкался на исследование, лет 5 назад, сейчас должно было всё стать намного хуже). Вы можете его разобрать (шифрование, обфускация, виртуальная машина, рандом всего — если не пугает, можете заглянуть), но даже это может не помочь.
А дальше, поскольку это гугл — он спокойно анализирует на сервере эти данные. Ваш хром вычисляется на раз, смена юзер-агента не поможет. Более того, вычисляется ваша виртуалка, может не помочь даже смена браузера…
И работает эта защита хорошо только потому, что у гугла огромная аудитория, — ему есть с чем сравнивать данные, чтобы отличать добро от зла.
Люди конечно как-то регистрируют там аккаунты, но насколько мне известно, это либо ручной процесс в малых количествах, либо регистрация со смартфонов.tuxi
03.04.2019 20:59+1скорее всего использует вариации canvas fingerprint (где-то натыкался на исследование, лет 5 назад, сейчас должно было всё стать намного хуже)
Browser Fingerprint – анонимная идентификация браузеров
На самом деле стало хуже для фингерпринта и лучше для тех, кто по другую сторону баррикад. Посмотрите например последние фишки в последних версиях фаерфокса.
засекает разные таймеры (+ скорее всего таймеры на сервере),
Вот только не надо палить неявные методы защиты публично :)OloloFine
03.04.2019 22:18Разве не только у Гугл-бота временнЫе аномалии?? Канвасы так вообще боян боянистый, я какое-то время не в теме, вроде сейчас рулит вытаскивать вкусное про видеокарту из webGL контекста. И что тут палить то, это на каждом углу в интернете лежит )))
thauquoo
04.04.2019 01:14+1Вот только не надо палить неявные методы защиты публично :)
Надо. Защита через неясность работает до поры до времени.
Tatikoma
04.04.2019 11:07Я имел в виду натыкался на исследование устройства botguard.
Хуже для фингерпринта — не критично, есть и другие фингерпринты, а гугл анализирует полученные данные комплексно и в сравнении с общей массой, — за счёт этого он действительно блокирует конечное оборудование, а не браузер (и это действительно работает, но там есть разные степени заблокированности, т.к. очевидно есть разные степени точности определения оборудования).
Честно говоря я не знаю как оно устроено полностью и у меня нет задачи разобраться в этом.
dimm_ddr
04.04.2019 13:24Разве так сложно — написать скрипт для создания аккаунтов, создающий 2-3 аккаунта в сутки, запустить несколько инстансов с разными браузерами, расширениями, может даже разной осью. Запилить переход по набору сайтов в промежутке, чтобы гугловый трекинг запомнил сущность. Копить базу аккаунтов и по необходимости ее продавать. Нет, я этим не занимался, это просто первое решение которое пришло мне в голову. Можно добавить рандома в промежутки между созданием аккаунтов и в набор посещаемых сайтов. Да, решение получится достаточно дорогостоящим, но работать же должно, нет?
Tatikoma
04.04.2019 13:31Надо проверять. Подозреваю, что сложности всё равно будут. Использовать фактически разные ОС и разные браузеры — скорее всего верное направление, но это не так дешёво.
Пара тысяч аккаунтов — я имел в виду зарегать за одни сутки. Вот и считайте, сколько разных ОС вам понадобится…
OloloFine
03.04.2019 19:13Вместо тысячи слов о этичности/неэтичности — скажите, Вы следуете инструкциям в robots.txt ???
makasin4ik Автор
03.04.2019 19:13в закрытые разделы сайта мы не лезем, если вы про это. Собирается только открытая для общественности информация.
Tatikoma
03.04.2019 19:17Т.е. делаем получение цены по ajax через URL запрещённый в robots.txt и вы не сможете обойти эту защиту, верно? :-)
makasin4ik Автор
03.04.2019 19:24+2я может не понимаю Вас. никто никогда не запрещает от индексации страницы с товарами.
Tatikoma
04.04.2019 11:04Вы изменили свой комментарий, нет смысла продолжать дискуссию. Изначально вы утвердительно ответили на то, что следуете инструкциям в robots.txt.
makasin4ik Автор
04.04.2019 11:06Я просто хотел пояснить, что следование или не следование инструкциям в robots — вопрос не сводится ДА или НЕТ. Мы следуем, но толку то в этом НЕТ! Наша цель — цены на товары. Их НЕ запрещают в robots. Никогда. Поэтому дал расширенный комментарий.
Tatikoma
04.04.2019 11:10Т.е. если я запрещу цены на товары в robots.txt — вы не сможете их спарсить, верно?
Я не говорю про запрет индексации страницы с товарами. Это совершенно другое. Я говорю о том чтобы подгружать цену аяксом или картинкой из директории, которая запрещена в robots.txt. Т.е. товары будут индексироваться, а цены — нет.thauquoo
04.04.2019 11:59Допустим, они не спарсят, так другие спарсят. На этом рынке есть полно игроков, которым плевать на robots.txt и любые принципы. Они просто парсят и продают данные. Это суровая реальность, с которой следует считаться.
Tatikoma
04.04.2019 12:05+1Я просто зануда. Автор скорее всего в этой ситуации спарсит забив на ограничения robots.txt. Соответственно верный ответ был бы, что они не следуют всем ограничениям robots.txt, но в данный момент их интересы не пересекаются.
makasin4ik Автор
04.04.2019 12:16факт. всем плевать. вы правы. и роботс.тхт это как прикладывать мох когда у человека острый аппендицит.
khim
04.04.2019 13:04Вы правы, конечно. Для того, чтобы robots.txt действовал кто-то должен в суд подавать и некоторое число фирм должно быть закрыто — без этого он действовать не будет. В Европе и США такие люди нашлись и потому robots.txt там уважают, в России — пока нет, потому на него плюют.
siziyman
04.04.2019 13:33От того, что сущность Х, ставшая, скажем так, техническим рекомендательным обычаем — в данном случае robots.txt — есть и работает именно в этом качестве, никак не следует то, что она может приводить к legally enforcible последствиям.
В этом смысле юридическая значимость robots.txt эквивалентна тому, что я у себя в ленте в соцсеточке напишу и закреплю пост «Все посты здесь являются объектом авторского права и не могут быть скопированы и процитированы никуда/нигде без моего письменного согласия». Пару раз такое видел, очень смешно.khim
04.04.2019 17:18От того, что сущность Х, ставшая, скажем так, техническим рекомендательным обычаем — в данном случае robots.txt — есть и работает именно в этом качестве, никак не следует то, что она может приводить к legally enforcible последствиям.
Почитайте про Implied license ещё раз.
В этом смысле юридическая значимость robots.txt эквивалентна тому, что я у себя в ленте в соцсеточке напишу и закреплю пост «Все посты здесь являются объектом авторского права и не могут быть скопированы и процитированы никуда/нигде без моего письменного согласия». Пару раз такое видел, очень смешно.
Смешно это ровно потому что это обычно вывешивают люди не имеющие юристов и не готовые защищать свои права в суде. Ещё и пишут неграмотно: запретить копировать они как раз могут, а цитировать — нет, это отдельно оговорено в законе.siziyman
04.04.2019 20:04Вот только robots.txt не работает, как implied license, ибо в руководствах того же Гугла явно написано, что пытаться «спрятать» от чего-либо (ну т.е. написано от Гугла, но про остальные веб-порталы это примерно в той же мере применимо) страницу с его помощью не стоит.
С постами всё куда тривиальнее: есть пользовательское соглашение соцсети, которое вас подобных прав, зачастую, в явном виде либо лишает, либо сильно ограничивает. Так что писать вы там можете хоть то, что публикацией этого сообщения объявляете себя CEO Фэйсбука, но в свете предыдущих соглашений+законодательства это так же бессмысленно, как попытки поместить зарплату под NDA в российском правовом поле.khim
04.04.2019 20:19Вот только robots.txt не работает, как implied license, ибо в руководствах того же Гугла явно написано, что пытаться «спрятать» от чего-либо (ну т.е. написано от Гугла, но про остальные веб-порталы это примерно в той же мере применимо) страницу с его помощью не стоит.
Где именно это написано и нельзя ли привести пример? Ибо внизу там уже приводили цитату, в которой всё перепутали.siziyman
04.04.2019 20:33khim
04.04.2019 23:11Опять та же самая цитата и та же самая ошибка.
Прочитать внимательно что написано по приведённой вами же ссылке — пробовали? Гугл ведь даже перевод сделал. И картинкой показал что бывает, еслиrobots.txtдоступ закрывает.
Гугл при этом на ваш сайт заходить не будет — ибо таки нету на это у него Implied License — а вот про адреса страничек — может узнать из других источников. И показать их — тоже может.
Rukis
04.04.2019 13:17Я лично ничего против парсинга открытых данных не имею, но, если уж вы говорите, что следуете директивам robots.txt, то зачем играть словами.
В этом файле ограничиваются доступ к определенным маршрутам для роботов и не только потому что там могут быть данные, которые нельзя парсить. Например, там могут быть очень «тяжелые» страницы, массовые запросы к которым нежелательны.
То есть, если вы соблюдаете директивы robots.txt, то вы не сможете получить цену с закрытой в нём странице, вы в этом случае на такую страницу вообще не будете слать запрос.nqooqoo
04.04.2019 13:22Правила из robots.txt не соблюдает даже гуглбот.
Rukis
04.04.2019 13:43Причем он тут? Автор статьи сказал, что они соблюдают, но потом пошли фразы, «правила соблюдаем, но там ведь не запрещено парсить цены»…
makasin4ik Автор
05.04.2019 11:28мы не идем в закрытые области :)
почему — т.к. там нет ЦЕН, а они нам нужны.
в 99.9% никто не закрывает в роботс цены и товары.Rukis
05.04.2019 11:38Устраним все неоднозначности. Если в robots страница с ценами закрыта от всех ботов, кроме яндекса и гугла, вы будете ее парсить?
makasin4ik Автор
05.04.2019 11:43да. я не вижу разницы между нами и яндексаом в части права доступа к данным. Мы не занимаемся взломом, перебором паролей, поиском уязвимостей и т.п. Нас интересуют открытые цены на товары и сам ассортимент. Остальное — не интересно вообще.
Rukis
05.04.2019 11:59+1Но речь то не о праве доступа к данным (ничего против сбора данных из открытых источников не имею), а о ваших ответах. То есть директивам robots не следуете — почему бы так и не сказать сразу. Выше по дискуссии вы просто вводите людей в заблуждение.
Juralis
04.04.2019 10:59+1robots.txt — это не столько про парсинг, сколько про дальнейшую публикацию (например, в поисковой выдаче). Если вы хотите, чтобы данные не были кем-либо получены, то вам следует ограничивать круг лиц, которые смогут их увидеть.
Если у вас не занавешены шторы на окнах, то не стоит ходить голым. Может быть специально смотреть в окна и не красиво, но без занавесок какие претензии?
Этичность парсинга — нейтральна. Не этичным может быть способ использования полученной информацией. В целом, чисто с точки зрения этики, каждый человек имеет право получить публичную информацию, которая не носит частный или специальный характер и не охраняется законом. Цены точно являются публичной информацией. Описания — тоже. Описания могут быть объектом авторского права и тогда их нельзя размещать без разрешения. Но никакая этика не нарушается, даже если я буду парсить сайты и делать свой публичный сайт, на котором будет отражаться динамика цен и сравнение конкурентов. Это даже этично, так как предоставляет общественно-полезную информацию.Tatikoma
04.04.2019 12:06+1Википедия говорит «файл ограничения доступа роботам к содержимому на http-сервере». Т.е. не про дальнейшую публикацию, а про доступ в принципе. Если желаете спорить с википедией, — это можно отлично делать на самой википедии =)
tuxi
04.04.2019 12:19По факту (как там у юристов принято, де-юре, де-факто...)… по факту поисковые системы запрашивают содержимое даже тех ресурсов, которые явно описаны в роботс в секции disallow… Есть только надежда, что в публичный индекс они не попадут, но «ходить» по таким ресурсам — они ходят и весьма частенько.
vedenin1980
04.04.2019 12:35Если уж смотреть Википедию, то исключительно английскую, так как robots.txt это явно не русская разработка. А там говорится, что это протокол общения с веб-сканерами поисковых системы, где владелец сайт может выдать «рекомендации» по тому какие именно страницы он хочет сделать публичными. При этом протокол исключительно опциональный и там только рекомендации причем в основном для поисковых ботов, а не явные запреты.
Tatikoma
04.04.2019 12:37Никто и не отрицает, что это рекомендации, т.к. при помощи текстового файлика невозможно ничего запретить. Запреты — это проверять в скрипте и возвращать 403.
От добавления слова «рекомендация» в формулировку — смысл не меняется совершенно.
Ну т.е. «файл рекомендации ограничения доступа роботам к содержимому», т.е. речь не про дальнейшую публикацию, а про доступ в принципе.khim
04.04.2019 13:09Запрет на парсинг прописан в законе об авторском праве. И потому файлик robots.txt — это не запрет на парсинг, а разрешение на него.
Вы можете на это всё «забить» — но от этого вы не перестанете быть уголовником. Robots.txt действует точно так же как простейший замок, который ножом открыть можно, собственно: его задача не предотвратить нарушение — сделать так, чтобы нарушитель не мог на своё «незнание» ссылаться.Tatikoma
04.04.2019 13:17Интересная формулировка.
Тут где-то в комментариях были утверждения, что гугл посещает страницы запрещённые к индексации. И это подтверждает официальная документация гугла.
Соответственно по вашему определению гугл уже уголовник. Ваша формулировка мне импонирует, но похоже она неверна.khim
04.04.2019 17:21И это подтверждает официальная документация гугла.
Цитату не приведёте? Там могут быть фразы про случаи, когдаrobots.txtможет быть случайно проигнорирован (например если ваш web-сайт на запрос проrobots.txtответ 500 Error, то Гугл посчитает, чтоrobots.txtна сайте отсуствует… это техническое ограничение — про него как раз всё понятно).
Также могут быть случаи, когдаrobots.txtи не должен соблюдаться, потому что у вас есть другая Implied License. Например Safe Browsing может смотреть на странички, которые люди скачивают — даже если туда GoogleBot смотреть не может.
Здесь же речь идёт не о случайном, а намеренном игнорированииrobots.txtи без всяких забот от Implied License — это таки большая разница.Tatikoma
04.04.2019 18:07Файл robots.txt не предназначен для блокировки показа веб-страниц в результатах поиска Google. Если на других сайтах есть ссылки на вашу страницу, содержащие ее описание, то она все равно может быть проиндексирована, даже если роботу Googlebot запрещено ее посещать. Чтобы исключить страницу из результатов поиска, следует использовать другой метод, например защиту паролем или директиву noindex.
khim
04.04.2019 20:06Это вы вообще тёплое с мягким перепутали. Я даже не знаю как тут можно не понять. Тут сказано следующее: если страница «закрыта» через robots.txt, то робот её не скачает. Однако информация о странице может быть доступна, так как на неё могут ссылаться другие страницы, а Гугл достаточно умён, чтобы понять, что речь идёт про описание.
Так что иногда можно такое увидеть: «о сепульках — secretsite/secretpage.html»… и всё… не сниппета, ни кеша. Вот это отсюда. Нарушений robots.txt тут нет…nqooqoo
04.04.2019 20:49Да ладно :) Если посмотреть в логи веб-сервера, видно что гуглбот на эту страницу заходил.
khim
04.04.2019 23:16Заходить — может, в некоторых случаях. Если ссылка на страницу попадёт в него до того, как он
robots.txtраспознает. Использовать — не должен. Всё на той же страничке, которую вы всё никак не удосужителсь прочесть до конца написано: Googlebot не будет напрямую индексировать контент, указанный в файле robots.txt, однако сможет найти страницы с ним по ссылкам с других сайтов. Таким образом, URL, а также другие общедоступные сведения, например текст ссылок на страницу, могут появиться в результатах поиска Google.nqooqoo
04.04.2019 23:22Всё на той же страничке, которую вы всё никак не удосужителсь прочесть до конца
Я практик, а не теоретик. Написано там много чего, но на практике гуглбот заходит на эти страницы.khim
04.04.2019 23:27Написано там много чего, но на практике гуглбот заходит на эти страницы.
И они потом появляются в результатах поиска с содержимым страницы?unlor
05.04.2019 11:00Да, появлялись. Не знаю как сейчас, но пару-тройку лет назад не было ничего сильно странного в наличии поискового трафика на страницы, закрытые в robots.
areht
04.04.2019 13:12> Если желаете спорить с википедией
Нет, не желаю. Спорить с википедией — это как спорить с шизофреником.
Фраза «файл ограничения доступа роботам к содержимому на http-сервере» вообще похожа не перевод чего-то сверхмозгом и смысла в себе не несёт, поэтому вам её трактовать (как вам хочется) приходится.
apapacy
03.04.2019 20:07+3Некоторые люди воспринимают парсинг как DDOS-атаку и относятся к нему с сомнением
Парсинг может действительно положить сайт даже запрашивая 1 запрос в две секунды.
Все дело в том что обычные клиенты (не боты) посещают преимущественно популярные страницы, которые при втором обращении берутся из кэша. Парсер перебирает все страницы подряд, поэтому все запросы непопулярных страниц идут на бэк приложения, который может быть тяжелым.
Во-вторых, парсинг используется для получения контента.
Я рассматриваю эту ситуацию чисто со стороны бизнеса. Описание товаров подробное, с характеристиками — это хорошее конкурентное преимущество сайта. Кто-то получает это затратив десятки тысяч человеко-часов, а кто-то просто покупает путем парсинга чужого контента. Путь это и трижды законно.
Да никак. И стоит ли вообще защищаться от парсинга? Я бы не стал
Я никогда не защищал сайты от парсинга, но от атак 7-го уровня — устанавливал защиту. Как правило, парсеры также отсекаются такой защитой как боты. Если, конечно, это не парсинг при помощи headless chrome — что встречается не так уж часто т.к. это очень затратно по ресурсам. Я не утверждаю, что Вы такую защиту не преодолеете. Но скорее всего ресурсов на это уйдет больше, чем на парсинг незащищенного сайта.makasin4ik Автор
04.04.2019 10:43Из практики — headless это уже норма (у нас). мы добились того, что хромиум потребляет 3-4% ресурсов, и можно их «клонировать» пачками. Я понимаю вас в части определенного недовольства с точки зрения бизнеса — но лучше уж обсуждать это открыто, как делаем мы, чем воровать втихую, как делают остальные.
Tatikoma
04.04.2019 12:07Делали что-то специально, для снижения нагрузки на CPU? Используете видеокарты в сервере или встроенное видео в CPU?
makasin4ik Автор
04.04.2019 12:15ничего особенного, 3 месяца ковыряния с настройками хромиума и вот, 4%.
Tatikoma
04.04.2019 12:32Вы говорили что-то про статью с техническим подробностями. Тогда буду ждать ответ в той статье, т.к. ваш комментарий — ни разу не ответ (не говоря уже о том, что непонятно 3-4% каких ресурсов).
У меня безголовый хром кушает примерно 0% ресурсов в режиме ожидания. Непонятно что вам понадобилось подкручивать.
dimm_ddr
04.04.2019 13:35Я рассматриваю эту ситуацию чисто со стороны бизнеса. Описание товаров подробное, с характеристиками — это хорошее конкурентное преимущество сайта. Кто-то получает это затратив десятки тысяч человеко-часов, а кто-то просто покупает путем парсинга чужого контента. Путь это и трижды законно.
Не совсем так. Просто иметь где-то в своей внутренней базе кучу подробных описаний никакого преимущества не дает, они полезны только если их использовать. Но использование — как раз незаконно. Поэтому да, кто-то заплатил много денег и получил себе крутые описания, а кто-то заплатил меньше и смог прочитать их все разом. Но вот выложить их себе на сайт и таки получить равное преимущество второй бизнес уже не сможет (при условии что первый описания защитил, я не уверен что оно по умолчанию работает как тут некоторые утверждают).

valemak
03.04.2019 21:21+1Как защитить свой интернет-магазин от парсинга
Мониторинг цен конкурентов особого напряжения ни у кого не вызывает. Самое обидное для владельца сайта, когда собирают его информацию именно для того, чтобы потом этим контентом наполнить чужой сайт.
Чтобы это пресечь в 95% случаев, обычно достаточно просто поставить свои водяные знаки на фотографии товаров. Причём, не где-то в уголочке изображения (в этом случае можно шлёпнуть поверх другой ватермарк), а в районе центра, чтобы не было возможности вывести без ухудшения качества всей картинки.
В подавляющем большинстве случаев текстовая составляющая (описание, характеристики, мета-теги) резко теряет ценность без прилагающихся к тексту изображений. Поставьте свои ватермарки на изображения продукции — и в плане парсинга к Вашему интернет-магазину будет потерян интерес.tuxi
03.04.2019 21:58+1С водяными знаками не так все просто, придется иметь 2 варианта, со знаком для сайта и без знака для выгрузки в тот же я.маркет. Ямаркет имеет право забанить предложения в которых есть ссылки на изображения с водяными знаками
valemak
03.04.2019 22:02Согласен, но всё равно, вполне эффективный и относительно простой способ как защитить сайт от парсинга (если точнее — сделать парсинг почти бессмысленным), как видим, есть.
Делая два варианта картинок (для публичного просмотра на страницах сайта и для маркетплейсов) стоит только позаботиться, чтобы по ссылке на публичную картинку с ватермарком нельзя было просто получить ссылку на изображение без ватермарка.
То есть, если файл с публичным изображением в галерее на странице товара называется example-800-800.jpg, а на оригинальную картинку без ватермарков example.jpg, то понятное дело, картинки без нашлёпок будут без проблем сграблены :)tuxi
03.04.2019 22:14+1чтобы по ссылке на публичную картинку с ватермарком нельзя было просто получить ссылку на изображение без ватермарка.
А я.маркет делает копии к себе на сервер, и иногда их потом использует в своих карточках товара.
Помимо контента, есть справочная информация, которую парсят охотно, так как она стоит реальных денег. Там картинки не всегда критичныvalemak
03.04.2019 22:28Парсить Яндекс-Маркет уже умеют не только лишь все. Скраппинг интернет-магазинчика по силам и студентику, а вот полноценно воевать с Яндексом, который вполне эффективно банит ботов, могут только немногочисленные профи.
Да, картинки не всегда нужны, но в подавляющем большинстве случае, прежде всего если речь о парсинге интернет-магазинов интересует именно текст вкупе с изображениями.
100% защиты от парсинга не существует, как нельзя свою квартиру уберечь на 100% от домушников экстра-класса. Но, по крайней мере, простыми и дешёвыми средствами существенно минимизировать риск парсинга своего сайта вполне возможно.tuxi
03.04.2019 23:04+1100% защиты от парсинга не существует
Да собственно говоря тоже такого же мнения. Я занимаюсь темой противодействия около 3-х лет, поддерживаю такой проект внутри другого большого веб-проекта. За это время я понял, что универсальной методики не существует, так как противодействие парсингу заключается в реализации набора различных решений, от простых, до сложных, которые существенно увеличивают стоимость парсинга как в материальном выражении, так и во временном. Причем большую часть этих кирпичиков придется делать и сопровождать самому, так как всякие TTFB никто не отменяет в угоду защите.
thauquoo
04.04.2019 01:20Вопрос в цене и налажености процесса. Ещё года два назад это было дорого, а сейчас у моих знакомых есть ферма с браузерами, которая парсит регулярно Яндекс и продает данные дешевле, чем многие конкуренты. Процесс поставлен и есть пара энтузиастов, которые не бьют баклуши, а постоянно разбирают защиты. Нравится им и деньги приносит.
ayevdoshenko
04.04.2019 12:45Банить не нужно — надо выявлять ip. А затем долбить по ним в ответ: ) Если при бане ip вы создаете парсерам проблему с одним ресурсом, то при ответном ударе — уже покрываете целый куст малины: )
Эм-м-м-м… или это неэтично?nqooqoo
04.04.2019 13:25А затем долбить по ним в ответ: )
Чем долбить и как именно? ddos? Это уголовно наказуемо.
enzain
04.04.2019 22:45Зачем долбить то?
Отправляйте в tarpit на файрволе и все дела… хай сессия висит до посинения.

trawl
04.04.2019 06:20Выгрузка в маркет — это другое. Это вы сами загружаете в меркет свой каталог, а не маркет парсит ваш сайт…
virtualsys
03.04.2019 21:37Своими словами «от парсинга не защититься» вы заинтриговали многих. Как говорится, что «самый мудрый зверь это тот которого никто и никогда не видел». Поэтому у меня возникают только мысли, что кто-то решил деверсифицировать бизнес и запустить сервис с «защитой от парсинга». Иначе не вижу логики (ну кроме клиентов найти). Т.к. любые честные мысли про коммерческое использование данной тематики пойдут не столько на рекламу для новых клиентов, сколько на формирование конкурентов (из студентов с питоном), или повышение квалификации противостоящих вам.
P.S. Вы еще не указали специфический рынок парсинга — БК и лив-трансляции со статистикой. Для энтузиастов.OloloFine
03.04.2019 22:38Кроме защиты, парсингом можно наслаждаться ))) Начиная от банального «result poisoning», дальше помайнить парсером крипту вроде монеры ( PhantomJS тут тормозит как не в себя, а вот хедлесс хром майнит на все бабки), во времена PhantomJS можно было проверить его на ламерский запуск с --disable-web-security и при удаче «спарсить парсер» ну или вообще отгрузить эксплойт…
makasin4ik Автор
04.04.2019 10:48ВК мы не парсим, вообще парсинг ресурсов под паролем — мне не нравится от слова вообще. Хотя спрос есть.
n0vnme
04.04.2019 12:14Часть функционала вк доступна и без пароля. Публичные группы, например, можно спокойно собирать не залогинившись
makasin4ik Автор
04.04.2019 12:14да. уже просят. но я как-то… сомневаюсь :)
n0vnme
04.04.2019 14:37ВК предоставляет нормально задокументированное публичное api для таких вещей, так что они явно не против. А вот с фейсбуком, например, могут быть трудности
khim
04.04.2019 13:33Как ни странно парсинг ресурсов под паролем — имеет меньше шансов вступить в противоречие с законом.
Простая житейская аналогия — если вы заявитесь в библиотеку, когда библиотекарь вышла и там никого нет и считаете оттуда дюжину-другую книг, то именно вы будете нарушителем — хотя вроде как доступ и был свободным.
А вот если вы приедете с машиной для перевозки тех же самых книг и вышедшая из квартиры жена попросит вас вынести из квартиры содержимое пары книжных шкафов — то вы особо раздумывать не будет и муж вас в «соучастники преступления» записать никак не сможет. Ибо само наличие у жены ключа обозначает, что она имеет право это делать.
То же самое с паролями: если вас просят о том, чтобы спарсить что-то люди, легально владеющие паролем для доступа — то все претензии к ним.Tatikoma
04.04.2019 13:38Много раз сталкивался с ситуациями, когда передача ключа запрещается правилами. Соответственно получив от заказчика ключ — вы владеете ключом уже нелегально и будете нести ответственность.
Ваша логика хороша, но не гарантирует отсутствия последствий.kbaa
04.04.2019 17:39Я всячески избегаю получения от заказчиков любых паролей и ключей, чтоб не было вопросов, просто делаю config файл и объясняю, что все данные для авторизации можете писать туда
Хотя, у топикстартера сервис немного по-другому организован, они на своём железе всё запускают, там так не прокатит
khim
04.04.2019 17:45Ваша логика хороша, но не гарантирует отсутствия последствий.
Для отстуствия последствий нужно явно упомянуть в договоре, что передача ключей вам происходит законно и т.д.
От суда это, впрочем, не защитит… потому что подать в суд можно всегда. Даже если закон 100 раз на вашей стороне. Вот выиграть его — может быть непросто…
Tatikoma
04.04.2019 11:46Сервис с защитой от парсинга — хорошая идея. Чем больше клиентов — тем больше данных для анализа, тем точнее можно выявлять ботов. Надо подумать над этим.

Tanner
03.04.2019 22:21У меня, как у бывшего «студента с Python», всякие «защиты от парсинга» вызывают такую ассоциацию:
No take! Only throw

berezuev
03.04.2019 22:47+3Всю статью можно сократить до одной фразы: «Все дилетанты, а мы — Д'Артаньяны».
Никаких технических подробностей, одно бахвальство.
Посмотрю я на вас, как вы будете парсить тот же Фейсбук, или какой-нибудь авто.ру (который целыми подсетями блочит прокси при минимальной активности). Накупить белых проксей за оверпрайс и парсить ими аптеки — это любой дурак справится.
В крайнем случае можно расковырять приложение (если оно есть) сервиса и достать оттуда «закрытый» API. Я так в реальном времени собирал курсы валют практически со всех современных онлайн обменников. Одним http-запросом.makasin4ik Автор
04.04.2019 10:49Я в заголовке написал — что статья маркетинговая. Технические подробности — будут, вижу, что статья понравилась.

drinkius
04.04.2019 10:50достать оттуда «закрытый» API
Вот это уже больше похоже на нарушение закона, чем обычный парсинг доступных всем страницmakasin4ik Автор
04.04.2019 10:59на некоторых крупных ресурсах это вариант — использовать их же АПИ.
Tatikoma
04.04.2019 11:24В РФ это законно, если я не ошибаюсь. Вообще это сложно запретить, т.к. реверсинг (кое-где незаконен, да..) + имплементация = создание эмулятора. Соответственно запрещаем это и тот же WINE становится незаконным. Придётся прописывать тысячами исключения, что не выглядит как хорошая затея.
makasin4ik Автор
04.04.2019 12:14законно, у нас сильная юридическая поддержка — мы работаем с компанией юристов, которые нам помогают советом + договором.

la0
03.04.2019 22:49+3У меня есть большой релевантный опыт (около 5 лет суммарно в разных местах) с двух сторон этих баррикад и вот что я вам скажу:
0. подтверждаю тезис про «всё можно спарсить», просто вопрос борьбы брони и меча. И чтобыгражданскиепокупатели не пострадали.
1. Многие (>70%) парсеры берут партнёрские фиды полученные из адмитада(и прочих cpa) или по коммерческому api я.маркета и аналогов и с умным видом выдают за свои.
Проверялось так: завышаем в этих фидах цену на 10-20 товаров на 1-50 рублей и смотрим где всплывёт. Ответ: почти везде
2. В большом % случаев возможно точно определить бота и отдавать конкретно этому боту «немного кривые» цены.
Входные данные: условный конкурент закупается в том же месте, и пытается бороться за трафик маркета ценой, для чего мониторит цену на ресурсе А и автоматически управляет своей ценой.
Вычисляем боты этого конкурента и начинаем им и только им системно занижать. Результат: конкурент торугет в убыток и понимает это не сразу. Один раз меня встретили у промозоны и обещали в случае повторения подобного занижения сломать челюсть так как «это нечестно и нам надо кормить семьи». Даже без обещаний по IP вычислить. Ох уж эти маленькие локальные розничные конторки.
Угрозы на мыло за tarpit/delude в направлении чьей-то инфры парсинга на этом фоне кажутся мелочами.
3. Некоторые вполне отдают свои цены любому заинтересованному лицу. В HTML-коде сайта даже ссылку ставили куда писать чтобы получить фид с актуальными ценами, но таки нет, всё равно парсеры будут парсить, а получать фид официально никто не захочет, проще же по прекрасному упороться.
4. а ещё можно просто перестать конкурировать по цене и я уверен что мы это увидим в ближайшее время (сошлюсь на GFK: миграция массового покупателя от цены к ценности).
5. от ботов есть и польза: они делают искусственный прогрев кешей излишним и греют его для и вместо реальных посетителей. жму им их мужественный сетевой интерфейс за это.
немного аккуратных усилий по «борьбе» с ботами дают 80% результата. не точно так, но близко к истине. Если принято решение бороться, достаточно просто чуть поднять стоимость массового парсинга что в принципе должно полностью устраивать автора этого поста так и владельцев необходимой информации.
Предположим бота зовут Джо. Все помнят почему «неуловимый Джо такой неуловимый»?eugene_bx
03.04.2019 23:20#2 Притворится ботом и покупать по заниженным ценам — профит. Борцам с ботами надо не забыть использовать такие цены только для показа.
А тем кто пишет ботов, притворится краулером гугла и приходить с google app engine, все любят когда их гугл индексирует.
Еще вариант парсить не сам сайт, а кэш с гугл поиска (если конечно он там есть).la0
03.04.2019 23:27Притворится ботом и покупать по заниженным ценам — профит
Всё несколько сложнее.
притворится краулером гугла
В доках гугла и яндекса очень подробно написано что делать и как проверять user-agent их ботов. Быстро, просто, а если еще и кеширование результата проверки сделать…
парсить не сам сайт, а кэш с гугл поиска
… и разгадывать рекапчу ради цен N-месячной давностиeugene_bx
03.04.2019 23:34Про профит это шутка, но в каждой шутке есть доля шутки, главное чтобы потом не перекрутить случайно.
А про гугл, у них же есть search api, что-то типа $5 за тысячу запросов, может они рекапчу своим платным пользователям не будут подсовывать.
Тем более если у гугла данные есть, то точно robots.txt уважают
Плюс можно на какой нибудь Толоке или Mechanical Turk выдать задание, которое потихому переиспользует их оборудование/браузер.
Типа полу-ручной прокси, по идее за смешные деньги может довольно хорошо получиться.
apapacy
03.04.2019 23:41Под бота google подделываются довольно часто. (подделка User-Agent)
Их бы дополнительно проверять по ip-адресу но к сожалению у googlebot нет определенного постоянного диапазона адресов. Зато есть в документации оговорка что запросов они не будут давать больше одного в 10 секунд (или что-то вроде этого).
Так что по количеству запросов модно выявить поддельного бота. Парсить же сайт 1 запрос в 10 секунд просто долго и невыгодно.tuxi
04.04.2019 00:04смотреть на UA плохая идея
надо хотя бы сначала reverse lookup делать
кусочек из наших бело-серо-черных листов.........
2018-11-09 00:05:06 66.249.70.15 crawl-66-249-70-15.googlebot.com
2018-11-09 00:06:42 66.249.70.17 crawl-66-249-70-17.googlebot.com
2018-11-09 00:37:00 66.249.70.19 crawl-66-249-70-19.googlebot.com
2018-11-09 01:27:16 66.249.69.207 crawl-66-249-69-207.googlebot.com
2018-11-10 01:36:34 66.249.65.77 crawl-66-249-65-77.googlebot.com
2018-11-10 05:20:19 66.249.76.122 crawl-66-249-76-122.googlebot.com
2018-11-10 11:16:12 66.249.79.177 crawl-66-249-79-177.googlebot.com
2018-11-13 16:28:29 66.249.70.13 crawl-66-249-70-13.googlebot.com
2018-11-13 16:30:26 66.249.70.25 crawl-66-249-70-25.googlebot.com
2018-11-15 03:29:54 66.249.66.207 crawl-66-249-66-207.googlebot.com
.........
2019-01-09 09:03:41 66.249.66.217 crawl-66-249-66-217.googlebot.com
2019-01-09 09:16:55 66.249.66.219 crawl-66-249-66-219.googlebot.com
2019-01-09 09:26:30 66.249.66.221 crawl-66-249-66-221.googlebot.com
.........khim
04.04.2019 04:49Их бы дополнительно проверять по ip-адресу но к сожалению у googlebot нет определенного постоянного диапазона адресов.
Зато есть доменное имя. Если очень нужно — можно настроить кеширование, чтобы работало надёжно… Но вообще — для суда будет достаточно логов, скорее всего.tuxi
04.04.2019 12:31Зато есть доменное имя.
Да, но есть пара неприятных вещей. Например, анонимный чекинг поисковыми машинами. Это когда делается запрос от бота, который можно пробить по dns и владельцу подсети, и второй запрос, который при lookup-е и dns записям не дает никакой внятной информации «кто это к нам пришел». Ответы сравниваются и поисковой машиной делается вывод по теме «не подсовывают ли нам другой контент в отличии от простого юзера». Частично, это решаемо, плюс, такой чекинг не носит массового характера. Но проблема имеет место быть
khim
04.04.2019 04:46+1А тем кто пишет ботов, притворится краулером гугла и приходить с google app engine, все любят когда их гугл индексирует.
Рекомендую только не забывать, что подобные действия — это уголовка… Впрочем пока вроде никого показательно не выпороли (в смысле не посадили), так что какое-то время для развлечений у вас есть…vedenin1980
04.04.2019 12:38подобные действия — это уголовка… Впрочем пока вроде никого показательно не выпороли (в смысле не посадили)
Ссылку на закон в уголовном кодексе. Если вы про гражданский кодекс, то там вообще нет уголовных наказаний, только иски и штраф.khim
04.04.2019 13:37Статья 146. Действует уже лет 10 как (может чуть меньше). Когда нарушение авторских прав стало уголовным преступление — много шума было, не понимаю как вы это пропустили.
sumanai
04.04.2019 19:47В статье 146 ничего пр осам парсинг, только про незаконное использование полученной информации.
khim
04.04.2019 20:09Сам парсинг — это доступ к базе данных. Он, без специальной лицензии, незаконен. Статья 1334. За исключением случаев, описанных в статье 1335.1.
siziyman
04.04.2019 20:35Это доступ к сайту, а не самой базе данных.
khim
04.04.2019 23:18А что такое, извините, база данных? И почему вы считаете, что сайт ей не является?
Напомнаю что юридичеки базой данных является представленная в объективной форме совокупность самостоятельных материалов (статей, расчетов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины (ЭВМ)vlivyur
05.04.2019 11:38Т.е. это любой веб-сайт?
khim
05.04.2019 14:38С точки зрения закона — да. А почему вас это удивляет?
P.S. Вообще беда очень многих людей, пытающихся разобраться в законах — в том, что они не читают определений. И пытаются интерпретировать их интуитивно. А в законе — часто вещи определены не так, как у них в профессиональном сленге. Пример с базой данных вы уже видели. Другой пример — это «воспроизведение музыкальной записи». Очень многие «журнализды», обнаружив, что воспроизведение требует письменной лицензии офигевают и начинают писать статьи про то, что CD теперь нужно слушать только тайно… не удосужившись прочитать определения и выяснить, что «воспроизведение» — это создание копии. А то, о чём они подумали — это «исполнение». Там тоже есть ограничения… но другие.
sumanai
04.04.2019 20:58Смотреть сайт через браузер тоже нельзя?
khim
04.04.2019 23:22Можно, разумеется. Это действие попадает почти под все пункты пресловутой статьи 1335.1.
И обращение «в целях, для которых база данных ему предоставлена» и «в личных целях » и даже в «в объеме, составляющем несущественную часть базы данных»! Всё подходит.
А вот парсинг — «пролетает» мимо всех этих пунктов.sumanai
05.04.2019 00:24Всё подходит.
Если на сайте 3 статьи, и я, гад эдакий, прочёл их все, то всё, я вор и подлежу преследованию?
makasin4ik Автор
04.04.2019 10:51я так скажу — еще ни разу не сталкивались ситуации когда кто-то завышал цены для парсеров. Видимо, это настолько технически сложно, что люди просто не хотят заморачиваться. В 90% ИТ специалисты заняты другими более важными делами, чем создавать такие ловушки.
CactusKnight
03.04.2019 23:18+1Неприличное, неприличное… Действительно неприличное — это когда ты заходишь на какой-то сайт (обычно производителя/перепродавца какой-то гравицапы), а тебе потом вконтакте начинает в личку спам сыпаться «вы заходили на сайт с гравицапой, у нас они самые лучшие, купите прямо сегодня бла-бла-бла»…
technik
04.04.2019 00:55А парсите сайты IKEA и HOFF? На вашем сайте не нашёл информации об этом.
makasin4ik Автор
04.04.2019 10:32HOFF да. Вообще, можно бесплатно зарегистрироваться и посмотреть всех, кого парсим ru.xmldatafeed.com — там есть демо-данные.
Hrrrr
04.04.2019 15:14Скажите, а зачем вы парсите DNS-SHOP? У них же на сайте в открытую опубликован прайслист в виде XLS-файла.
Или в данном случае под парсингом понимается матчинг с остальными прайсами?makasin4ik Автор
04.04.2019 15:14парсинг отличается от матчинга — две разные задачи. Парсинг это сбор данных, матчинг — уже попытка сделать отчет по ценам.
Hrrrr
04.04.2019 16:54Спасибо за объяснение.
Вы не ответили по сути. Извините за настойчивость, но у меня профессиональное любопытство, так как я связан с DNS-ом.
Вам не удобен опубликованный XLS-файл? Вы не знали о такой возможности? Какая-то иная причина?Skerrigan
05.04.2019 05:40О, вы связаны с DNS?
Отлично, тогда я иду к вам! На сайте была форма первичного логина. И вот там, в качестве логина указывался Email.
Так вот, символы после знака @ принимает только в нижнем регистре. И как быть тем, у кого есть символ в верхнем? Правильно, по Email не зайти.
Я писал в саппорт году кажется в 2016-ом — починили. Однако на следущий год кто-то сделал откат фикса. И потом, на сколько мне известно, этот косяк так и остался. Ув. «сотрудник DNS» — если эта ошибка до сих пор в наличии, стукните кого-то уже а? Спасибо.
Wesha
05.04.2019 18:06+1Так вот, символы после знака @ принимает только в нижнем регистре. И как быть тем, у кого есть символ в верхнем?
Курить RFC, в котором написано, что всё, что после знака @ — это имя домена, а оно регистронезависимо, то есть "тех, у кого есть символ в верхнем" просто не существует. (Вернее, строго говоря, можно писать и в верхнем, и в нижнем, и в вЕрБлЮжЬеМ, и это будет один и тот же домен, так что программеры вообще имеют право принудительно переводить домен в lowercase и так и хранить и сравнивать).
dimm_ddr
05.04.2019 20:56так что программеры вообще имеют право принудительно переводить домен в lowercase и так и хранить и сравнивать
Единственный разумный вариант же, разве нет? Ну не считая совершенно аналогичного «приводить в uppercase». Но раз символы в верхнем регистре у автора комментария не проходили, значит кто-то что-то сделал не так среди программистов.Wesha
06.04.2019 01:01+1Нет-нет, я не спорю, что кто-то из программистов явно что-то там нафакапил; я наехал на высказывание
как быть тем, у кого есть символ в верхнем?
Для них решение очень простое: не выделывайтесь и
слушайте вашу любимую песню "Валенки"пишите домен строчными буквами — проблема пропадёт.
Zwieback
04.04.2019 16:03А для чего вообще парсить этот магазин? У них же есть API, хоть и не совсем публичный.
Можно расковырять Android-версию и достать оттуда необходимые запросы/ответы. В ответах есть все товары с ценами.
pyrk2142
04.04.2019 01:36+3Кажется, что все уверения в законности парсинга чего-то упираются в это:
Правда, недавно попросили парсить сайт государственной организации – суда, если не ошибаюсь. Там в открытом доступе вся информация, но мы (на всякий случай) отказались. :)
Это довольно похоже на «Мы можем придумать аргументы, почему мы считаем себя правыми, но на самом деле не уверены в этом, поэтому лучше не будем злить того, кто может навалять».haldagan
04.04.2019 08:54Про легальность парсинга — вопрос сложный, и ИМХО в первую очередь должен рассматриваться с точки зрения авторского права. Чисто технически парсинг (из открытых источников) сам по себе не незаконен, однако информация достаточно часто собирается именно для того, чтобы стянуть контент и объявить его своим.
Однако что касается сайтов госорганов — из (почти) личного опыта не рекомендую делать ничего, что может им хоть отдаленно показаться противозаконным. Даже если вы на 100% уверены, что ни один закон не нарушаете.
Чисто теоретически в этой организации может оказаться человек, который, услышав от админа «О, нас бот какой-то парсит… Нафига ему это?» может решить, что это неплохая возможность показать свою инициативность и натянутьсовузакон про DoS на этот случай, даже если бот запрашивает по одной странице в минуту. Плюс, в силу некоторых обстоятельств, я склонен считать, что у сотрудника подобного органа это натягивание может получиться удачнее, чем у юриста коммерческой организации небольшого размера.makasin4ik Автор
04.04.2019 10:59вы правы. Мы берем только открытые данные. И только на коммерческих ресурсах.
makasin4ik Автор
04.04.2019 15:16Вы если делали бизнес в России будете на всякий случай тоже осторожны. Можно минусовать этот коммент или нет, но это правда жизни, а не уютные комментарии. С государством лучше не связываться. И про это честно написал.
scam
04.04.2019 02:25Парсить сайты — это примитивный фронт работ на фоне всего остального. Занимаюсь написанием парсеров больше 10 лет. И фейсбук тот же парсил в azure облако (PostgreSQL) (десятки миллионов fb аккаунтов с сотней ротирующихся проксей — вообще не проблема, по крайней мере лет 6 назад). Противопоказано только тем, кто регулярные выражения и xpath не переваривает.
n0vnme
04.04.2019 14:41Фейсбук сейчас периодически меняет верстку страницы и очень хорошо банит ботов даже с selenium и залогинившись. Есть лазейка через закрытое api, но тут уже вопрос законности
xPomaHx
04.04.2019 03:07Сталкивались с сайтами под защитой Distil Networks? для меня это первый случай когда я не смог решить задачу.
headless браузер в режиме без headless, то есть полностью рисуется, с чистого ip на первый же запрос срабатывает защита.411
04.04.2019 07:34Я с ними не сталкивался, но опыт подсказывает, что если все заголовки идентичны обычному запросу и разрешение рендеринга реальное, то вероятно у них навешаны эвенты на мышку или просто проверка позиции курсора.
Встречал ещё сайты, в которых обязательно надо сначала зайти на главную, получить куки, а потом уже заходить на страницы ценами.Tatikoma
04.04.2019 11:34Скорее всего заголовки и разрешение не в порядке. Иначе защита не могла бы сработать на первый же запрос.
Встречал ещё сайты, в которых обязательно надо сначала зайти на главную, получить куки, а потом уже заходить на страницы ценами.
Вот им прикольно с аудиторией из поисковых систем… Хотя наверное у них было какое-то решение для этого.xPomaHx
04.04.2019 12:40Заголовки вполне могут быть, хотя я естественно к ним первым же побежал на проверку идентичности с обычным хромом, я не поднимал прокси, смотрел тока через девтулз, так что вполне может быть что есть какие то скрытые еще, я уже с таким сталкивался, что дефтулз не всё показывает.
Tatikoma
04.04.2019 12:45Есть ссылка куда заходить, чтобы словить ошибку?
Нашёл у них онлайн-демо. Там явно не один запрос. Штука в том, что headless браузер отличается от полноценного.tuxi
04.04.2019 14:18Проверить не сложно же. Создайте хттп сервер и выводите заголовки. Анализируйте порядок следования заголовков. Если есть интернет магазин, делайте слепки реальных клиентов, которые оформили заказ, их UA, порядок заголовков, их содержимое (например Accept-Language может многое рассказать в сочетании с другими полями).
Но подделать запросы на самом деле не сложно, для этого просто берется живой работающий веб проект, делается зеркалирование запросов, и из этого потока берутся хидеры, которые уже транслируются парсеру, который парсит нужный сайт.
Tatikoma
04.04.2019 13:03JavaScript'ом определяют поля характерные для безголового хрома и отрубают по этому признаку.
Варианты:
1. Запускать хром с головой (для мультипоточности использовать chroot, т.к. с головой он не даёт изолированные сессии). У меня это сработало, подключенный devtools-клиент они не заметили.
2. Анализировать алгоритм, смотреть какие поля проверяют, сравнивать значения полей в безголовом и головном режиме, подменять для безголового режима значения полей. Либо хитрее, — сгенерировать все значения всех атрибутов в двух режимах, сравнить и пофиксить.
3. Искать уязвимость с защите в комплексе. Мне кажется перспективным будет что-то из серии один раз взять рабочую куку и на все инстансы раскопировать (скорее всего не все куки одинаково полезны).
Собственно говоря, — совершенно ничего удивительного и сложного. Максимум неделя одному специалисту, если заниматься таким каждый день — то и дня хватит.
khim
04.04.2019 13:40Если человек приходит из поисковой системы — у него referer будет, так что он легко отлавливается.
xPomaHx
04.04.2019 12:35Мышка вряд ли ведь это легко проверить открыть вкладку и убрать мышку из вью порта и через адресную строку зайти.
OloloFine
04.04.2019 17:25Я сталкивался с Distil какое-то время назад, инфа может быть устаревшая. Что они тогда делали: выгружали в браузер обсфуцированный JS, который выполнял фингерпринтинг основанный на особенностях CSS свойств DOM HTML элементов. Грубо говоря делали
а потом итерировали объект el.style. В разных движках/браузерах там получался разный набор CSS свойств, и в разном порядке.var el = document.createElement('div')
cry_san
04.04.2019 03:30Откуда такие цены?
На кворке парсят за тарелку супа )makasin4ik Автор
04.04.2019 10:313 программиста хотят кушать именно такую тарелку. А если серьезно, то крупным заказчикам важен договор, поддержка, отзывчивость, скорость реакции, безнал и т.п.

chuprun
04.04.2019 09:02скажу как заказчик.
цены на мониторинг цен ломят запредельные. Прикрываясь расчетом на каждый наблюдаемый сайт + кол-во товаров+ кол-во обращений в сутки. При этом часто берут нереальную цену за так называемую настройку — разбор источника для паркинга. А на самом деле настройка в 90% случаев 10 минут работы на типовой сайт мониторинга) и фактически никаких трат по количеству обращений в сутки. У вас ведь оплата не за нагрузку оборудования.
В итоге приходишь к тому, что дешевле сделать все через визуальный сервис парсинга, коих куча на западе.
для примера, потянуть анализ дилерских цен с аналитикой и уведомлениями на 50-100 сайтов вендор часто просто себе не может позволить, вылетает в сотку абонентки в мес. Не жирно ли?
makasin4ik Автор
04.04.2019 10:30У нас цена на 1 ресурс 5 000 р. И есть тариф 50 000 р. в месяц безлимитка :) — сколько хочешь, столько и парсим (только планово, чтобы мы успевали подключать). И да, некоторые клиенты у нас на таком тарифе и работают.
chuprun
04.04.2019 18:51ну я и говорю — прокомментируйте ценообразование. Откуда такие цены? Всего 3 составляющих в цене — цена за первую настройку-разбор сайта, цена за поддержку (при смене верстки) и цена за оборудование в мес, включая прокси. Есть расходы постоянные и переменные, у вас чистый аутсорс, не нужен офис, печеньки, аренда, стулья, бумага, свет, вода — все свое, домашнее:) Безнал не может удорожить услугу на столько, сколько за нее хотят. Может, я что-то не знаю?
Вот например товарная матрица, 50 первых сайтов из выдачи, цель — парсинг и мониторинг цен, по товарной группе в 100 наименований, периодичность снятия данных — 2 раза в сутки. Извещения о резкой смене цен, график и анализ по дням со сменой цен. Провалы, пики.makasin4ik Автор
04.04.2019 18:54Мы не парсим выдачу, я писал выше. Мы настраиваем парсер на сам сайт. Разбирая его верстку html. То есть мы идем от ресурса, а не от товара. Ну а цены — скажу честно — так сложилось, на первых клиентах обкатали, поняли — что цены разумные.
chuprun
04.04.2019 19:06Сайты-конкуренты берутся из выдачи, это логично. Если у вас функционал только по списку заказчика, то он попросту ограничен. К примеру, дистрибьютору для контроля МРЦ пофигу на мониторинг сайтов из второй сотни, ему важен демпинг тех, кто вначале. Вы заставляете собирать его каждый раз эти сайты снова и снова, а потом снимать деньги за добавление новых источников на настройку? Удобно…
vedenin1980
04.04.2019 19:16Вы заставляете собирать его каждый раз эти сайты снова и снова, а потом снимать деньги за добавление новых источников на настройку? Удобно…
Странная логика, то есть обработка парсинга все новых сайтов должна делатся бесплатно? А если там сложная и многоуровневая защита на несколько дней тоже?
Помоему все логично, заказчик договорился про 20 важных ему сайтов, оплатил и получил результат. Бесконечно парсить новые сайты вряд ли интересно бесплатно исполнителю, а платно вряд ли интересно заказчику.
не может удорожить услугу на столько, сколько за нее хотят. Может, я что-то не знаю
Услуга стоит столько сколько за нее платят, какой смысл спрашивать о себестоимости, если вам дешевле делать в другом сервисе — так делайте. Очевидно у компании автора хватает заказов, это равносильно спрашивать о ценообразовании айфонов, к примеру.
Вам Apple не будет отчитываться почему цена айфона именно такая, если есть китайские ноунеймы в десять раз дешевле с похожими характеристиками.chuprun
05.04.2019 09:50Именно сторонние ресурсы на разборе и отчитываются по стоимости компонентов телефонов и Apple в том числе, разбирая устройства и вынося вердикт, какова примерная себестоимость.
Смысл спрашивать про себестоимость как раз таков — потому что это рынок. Если с тебя за настройку 1 сайта берут от 5к, а там не то, что защиты, там просто xpath визуально подобрать в 2 клика надо — это не рыночные отношения:) просто потому, что клиент не знает, сколько это должно стоить.
Это сейчас все знают, что хостинг стоит столько, админ в месяц на удаленке — столько. А в этой нише просто клиент не понимает, за что он платит. Непрозрачное ценообразование не ведет к успеху, это доказано примерами. А уж «загибать» цены так вообще моветон. Хотя с точки зрения бизнеса хорошо:)
Странная логика, то есть обработка парсинга все новых сайтов должна делатся бесплатно? А если там сложная и многоуровневая защита на несколько дней тоже?
За сложную защиту всегда берут отдельные деньги:) они хитрые:)
По поводу бесплатно — так а почему нет? Я привел пример аналогии, только теперь со стороны клиента. Ведь берут деньги за каждую проверку, 2 раза в сутки проверка — фигак, сразу ценник в 2 раза больше, а между тем это бесплатно, себестоимость проверки 0р. Нагрузка на оборудование у нас, слаба богу, пока не тарифицируется.
Очевидно у компании автора хватает заказов, это равносильно спрашивать о ценообразовании айфонов, к примеру.
ну раз автор не побоялся пропиарить свой сайт и сервис тут, то почему бы и не спросить за ценообразование. Если бы он не пиар выложил, а чтонить полезное, кейс разбора детальный там, другое дело. А за пиар можно и на вопросы о цене ответить, я так считаю.areht
05.04.2019 14:13> просто потому, что клиент не знает, сколько это должно стоить.
У вас на ногах ботинки — покажите их себестоимость?
Что бы рассуждать о себестоимости, надо быть не просто покупателем, а специалистом (товароведом). Что-то мне подсказывает, что вы и 1% своих денег не тратите как специалист, на хостинг.
> Непрозрачное ценообразование не ведет к успеху, это доказано примерами. А уж «загибать» цены так вообще моветон. Хотя с точки зрения бизнеса хорошо:)
предлагаете загибать цены прозрачно?chuprun
05.04.2019 20:25Что бы рассуждать о себестоимости, надо быть не просто покупателем, а специалистом (товароведом)
для этого надо просто быть обьективным человеком, владеющим информацией. Тем более в вещах или услугах, основная составляющая которых это час работы программиста-настройщика, цена которого есть в свободных данных HH и выкладках-срезах аналитических компаний
предлагаете загибать цены прозрачно?
тут все просто — не можешь обьяснить ценообразование — значит, есть чт0-то неудобное, что при раскрытии клиенту не понравится, есть что скрывать условно. Поэтому предлагаю просто рассказать, почему это стоит столько, а вот за это берутся деньги. Хотя бы логически, потому как в некоторых осмеченных вариантах я даже логически не понимаю, за что платить.
Что-то мне подсказывает, что вы и 1% своих денег не тратите как специалист, на хостинг.
я не знаю, что там вам и где подсказывает, но ценообразование хостинга довольно прозрачно и всем известно, если говорить об аренде стойки или физической машины.
Если вы про создание своего дата-центра, то это более сложный процесс и увы, сравнивать его по сложности с цепочкой действий и затрат на услуги парсинга попросту глупо, согласитесь. Тут сравнение ближе к услугам seo или таргетолога, но те прозрачны, а эти нет, потому как рынок(хотя язык не повернется называть это рынком, скорее ниша) дикий, полулегальный зачастую.abmanimenja
05.04.2019 20:48Поэтому предлагаю просто рассказать, почему это стоит столько, а вот за это берутся деньги.
Стоит столько — потому что за столько покупают.
Это всё.
Вопрос себестоимости — это о другом.
Это о том, какую минимальную цену можно будет выставить когда-нибудь потом, когда рынок (возросшая конкуренция и пр. факторы) заставит это сделать.
Но бежать впереди паровоза рынка в вопроса снижения цены — резона нет.
Впрочем, если вы считаете что это стоит копейки — просто наймите программиста напрямую.
areht
05.04.2019 22:16Так себестоимость ботинок вы не знаете, вы только про очевидность/прозрачность себестоимости хостинга рассуждать можете? Единственный рыночный ценник в этой вселенной — на хостинг?
abmanimenja
06.04.2019 09:29тут все просто — не можешь обьяснить ценообразование — значит, есть чт0-то неудобное, что при раскрытии клиенту не понравится, есть что скрывать условно.
Это бизнес, это деньги. Зачем открывать вещи, связанные с внутренней кухней бизнеса?
Да еще и публично?
Для удобства конкурентов?chuprun
06.04.2019 20:47да какое ноу-хау, я просто спросил про ценообразование. К примеру, какие такие затраты в 100% несет компания, когда берет сумму за каждую проверку одной страницы. 2 проверки — 2xN соответственно.
Это нормальный вопрос заказчика, могу переформулировать: «а что вы делайте за эти деньги, когда я вам их плачу?»abmanimenja
06.04.2019 21:26Это нормальный вопрос заказчика, могу переформулировать: «а что вы делайте за эти деньги, когда я вам их плачу?»
Нормальный вопрос заказчика звучит так: «что я получу за свои деньги»?
Результат интересует заказчика — и только.
А как именно процесс — интересует других. Например, тех, кто в этом бизнес собирается войти.chuprun
06.04.2019 22:17удивителен. Ну те времена, когда заказчика интересовал результат, который вешают на уши, давно прошел. Пример — SEO. Раньше была практика обещания позиций, в точности повторяет ваше «нормальное», т.е. ему обещали результат — позиции, и его не интересовал ни процесс ни то, зачем они ему вообще.
Те времена давно прошли, сейчас каждый хочет вникнуть в суть, пытается разобраться в процессах, чтобы не быть тем, на ком воду возят и эффективно потратить свои деньги. И поэтому именно «что вы делайте за эти деньги и как это происходит» — нормальный. А вот ваш вопрос странно задавать логически, приходя к исполнителю. Ведь вы приходите к нему уже с конкретной целью и задачей, вашей задачей, которую надо решить. И если вы спрашивайте его «что я получу», значит, вы не понимаете, чем он занимается и что он предлагает или продает.
chuprun
07.04.2019 11:24вот вам пример более доступный и наглядный, по нтв передача чудо техники, в ней есть рубрика "за что такие деньги". Эфир строится на востребованности и рейтингах зрителей. Очевидно, людям все же ооочень интересно, за что и как платить
abmanimenja
07.04.2019 14:54вот вам пример более доступный и наглядный, по нтв передача чудо техники, в ней есть рубрика «за что такие деньги». Эфир строится на востребованности и рейтингах зрителей. Очевидно, людям все же ооочень интересно, за что и как платить
Вы свой интерес ставите во главе угла, забывая про интересы других сторон. А жизнь — это компромисс.
Как НТВ на этом зарабатывает — это понятно.
А зачем это рассказывать автору статьи?chuprun
07.04.2019 15:23не понял, при чем тут зарабатывает. Я вам показал связь в ожиданиях потребителя. То есть ему показывают то, что он хочет знать, хочет видеть. Это значит, ему интересно. Я просто показал, что это ошибочное суждение:
«что я получу за свои деньги»?
Результат интересует заказчика — и только.
А как именно процесс — интересует других
Зачем это рассказывать я уже сказал — если уж идет пиар, то почему не ответить на вопросы, тем более вполне обычные. Вы так интересно сформулировали:)
А зачем это рассказывать автору статьи?
Под это можно подвести и — а зачем вообще рассказывать, чего будет делаться и что будет в итоге? Зачем вообще вопросы задавать, поганый заказчик, мешок с деньгами. Просто плати бабло да и все… Звучит для меня именно так.
Вы свой интерес ставите во главе угла, забывая про интересы других сторон. А жизнь — это компромисс.
Да я ж цену не прогибаю, тут нет моего интереса прямого, я всего лишь спросил, как происходит ценообразование, почему при 0р себестоимости каждой следующей проверки с меня берут N каждый следующий раз.
И да, интерес для потребителя всегда во главе угла, вы не знали? Ну тогда в след раз, когда в узком проходе магазина Красное и белое вы разобьете бутылку коньяка за 3К к примеру, то заплатите им. И не ищите в законодательстве норм ширины прохода, который они нарушили.
А когда вас на переходе авто подкинет, встаньте и идите дальше, забудьте про ваш «интерес», ведь у него капот тоже помят, чего его мучить
abmanimenja
05.04.2019 14:51Смысл спрашивать про себестоимость как раз таков — потому что это рынок. Если с тебя за настройку 1 сайта берут от 5к, а там не то, что защиты, там просто xpath визуально подобрать в 2 клика надо — это не рыночные отношения:) просто потому, что клиент не знает, сколько это должно стоить.
Это должно стоить ровно столько за сколько это купят. Вопросы себестоимости тут значения не имеют (ну разве что дешевле себестоимости вам не продадут, а дороже во сколько угодно раз — запросто).
Если вы считаете, что там работы на 3 копейки, то что вам мешает провести её самостоятельно (ну или нанять кого нибудь дешевого, кто сможет это сделать).makasin4ik Автор
05.04.2019 14:52да, рынок готов платить такие деньги, не вижу смысла брать больше или меньше. Мне кажется, это разумная цена
chuprun
06.04.2019 20:57что я считаю, я уже сказал, это дорого. И сказал, что рекомендую обычным клиентам пользоваться сервисами визуального парсинга, причем западного. Это как с live чатами лет 5 назад, наши умники такие цены на них загибали, что диву даешься. А не имели даже банальных триггеров в настройках. При этом zopim стоил просто копейки и имел функционал в 20 раз выше. А как только таких умников расплодилось 40 в РФ, тут уже и начали снижать цены.
Что сий пример значит? Правильно, что адекватной то причины не было, была просто накрутка в отсутствие альтернатив. Поэтому объяснение про «рынок готов платить» попросту говорит о том, что дерут с три шкуры, пока могут:) Это конечно бизнес. Только чего же удивляться, когда кто-то на стройке века — космодрома или на Зенит арене стыбрил чуток или когда компы для военных в закупке по 250к с сертификацией фсб, хотя там железа на 30к в магазине. Это бизнес, детка:) Так и тут.
Я всего лишь чего спросил — обьясните, почему это столько стоит и за что вы хотите эти деньги. Так спрашивает каждый наш клиент и это нормально. А тем более, если человек пиарится.abmanimenja
07.04.2019 15:01Я всего лишь чего спросил — обьясните, почему это столько стоит и за что вы хотите эти деньги.
Вам уже ответили:
Это стоит столько — потому что на это есть покупатель.
Именно на эту цену, именно сейчас.
Цена — это баланс спроса и предложения.
Никакой справедливой или честной цены не бывает.
А любые расчеты, это только себестоимость.
Которая к цене продажи отношения не имеет (ну кроме того факта, что себестоимость всегда ниже цены продажи, а иначе и смысла в бизнесе нет).
Ровно так же и в вашей собственной сфере деятельности происходит.
chuprun
07.04.2019 15:39так раз ответили, зачем вы пытаетесь меня убедить, что такие вопросы нельзя задавать и ответы вы, мол, не получите. У этого — не получу, а нормальный поставщик услуг расскажет, потому что ему нечего скрывать.
В моей сфере деятельности действительно раньше было очень непрозрачное ценообразование. Дикий рынок. Но все давно изменилось, теперь такое не проканает. Изменился и рынок и, главное, заказчик-потребитель. Тут просто еще «доят коров», видимо.
abmanimenja
04.04.2019 22:36Откуда такие цены?
Как и везде: потому что могут и заказчики согласны.
Зачем брать денег меньше, чем можешь в данных условиях сегодняшнего рынка?
chuprun
04.04.2019 19:01пошел посмотреть список конкурентов с год назад, что мы собирали. Вы там тоже фигурируйте, но не указано, почему отсеяли, хотя варианта два — или цена или функционал.
abmanimenja
04.04.2019 22:08У нас цена на 1 ресурс 5 000 р
Это первоначальная настройка парзера или стоимость месячной услуги настроенного парзера?
kbaa
04.04.2019 19:10+1ну так это рынок же
кто ленивый — идет к топикстартеру и платит по 5к за ресурс
кто хочет сэкономить — выбирает альтернативный сервис или заказывает утилиту под себя у фрилансера, благо дело это не особо сложное и предложений полно
abmanimenja
04.04.2019 22:14При этом часто берут нереальную цену за так называемую настройку — разбор источника для паркинга. А на самом деле настройка в 90% случаев 10 минут работы на типовой сайт мониторинга) и фактически никаких трат по количеству обращений в сутки.
Нет никаких «справедливых» или «честных» или «реальных» цен.
Есть только цена как баланс спроса и предложения.

vlreshet
04.04.2019 09:52Парсить сайты с «защитой» всегда весело. Смотришь — а там навешали какие-то токены на аяксы, тянут всё с «шифрованием», хитро собирают. Только токены эти парсятся с исходника даже без использования регулярки, «шифрование» это base64, а сборку легко выпалить через devtools. Становится смешно — кто-то ведь разрабатывает всё это, ежедневно стреляет себе в ногу чтобы правильно всё подвязать и прокинуть. А в итоге «защита» обходится за 20 минут с чашкой чая.
abmanimenja
04.04.2019 22:03+2А в итоге «защита» обходится за 20 минут с чашкой чая
«Дня за 2» еще поверю.uralmas
04.04.2019 10:29А зачем вы парсите магазины, которые сами размещают свои прайс-листы в CPA-сетях? Им ведь есть смысл отдавать только правильные и полные прайсы. А парсить xml-выгрузку можно хоть каждый час.
makasin4ik Автор
04.04.2019 10:29вы удивитесь, но есть проблема у СРА сеток в качестве xml фидов и мы даже обсуждали возможность оказания им услуги парсинга :)
Fort_Ross
04.04.2019 10:51Я руковожу разработкой информационного сайта с несколькими млн визитов в месяц, с несколькими млн внутренних страниц. Пришлось принимать меры против парсинга, т.к. до 3/4 всей нагрузки генерировалось ботами. Ключевые моменты — нет как таковой блокировки, есть показ капчи вместо запрашиваемой страницы, строгость регулируются частотой выдачи капчи. White list для поисковых ботов (по домену и уже известным диапазонам ip). Несколько паттернов поведения для выявления парсера. Для хранения активных правил, сбора и анализа статистики отлично подошёл Redis. В конце концов получилась система, требующая минимального контроля.
makasin4ik Автор
04.04.2019 10:52К сожалению вы правы. И ко мне лично не один раз обращались люди с просьбой дать совет как снизить нагрузку от парсеров. Совета два — выложить ХМЛ с данными + поставить защиту от «студентов».
Tatikoma
04.04.2019 13:23Тут в комментариях проскакивал Distil Networks, у них вполне достойная защита. Почему не советуете эту компанию?
kolu4iy
04.04.2019 12:33Мда… В нашем случае проще попросить доступ к API. Мы уже сто лет всем желающим отгружаем либо прайсы, либо API. Ну и вообще, бизнес вокруг нас давно уже пользуется цивилизованными методами. Хотя мы и не аптеки и не билеты, автозапчасти продаём.
А парсить нас всё равно продолжают все кому не лень. Защищаться не стали, только по кол-ву запросов в минуту с одного IP ограничили без фанатизма — ну чтоб не перегружать ресурсы. Защищаться особо нет смысла, кто надо тот всё равно доберётся, да и информация собственно не секретная :)abmanimenja
04.04.2019 21:50А парсить нас всё равно продолжают все кому не лень.
Разработчики тех парзеров наловчились, а через API — нужно переучиваться.
К автору статьи, судя по технологиями, сие не относится, но основная масса — это джуны с еще пока скудным набором навыков. Им проще по накатанной дороге. Тем, чем уже умеют.
P.S.:
Впрочем, и автору статьи проще именно что привычными ему технологиями (хотя он и знает и больше, чем простой джун).
habr.com/ru/post/446488/#comment_19985144
andi123
04.04.2019 14:22Когда-то имел работу по поддержке агрегатора мессенджеров от одного «медиагиганта». Он собирал все сообщения из однокласников, моего мира, вконтактика и т. д.
То же все тупо парсилось, причем регулярками. На сайте чуток поменяли верстку — все, надо опять заново регулярку править и выкатывать обновления.
epanov
04.04.2019 15:57Как обходите Incapsula (https://www.incapsula.com)?
StanislavMagn
04.04.2019 16:09Не обходим. Скорее условно обходим. Берем куки которые сформировал хром, потом подсовываем в наш парсер. Если сделать паузы между запросами в секунду, то можно пользоваться примерно месяц. Потом заново. Так парсится озон.
and7ey
04.04.2019 16:46Проект показался мне очень интересным, и я выложил пост об этом в соц.сетях.
где найти ссылку?makasin4ik Автор
04.04.2019 17:30собственно в моем профиле… www.facebook.com/mkulgin я не знаю как давать ссылку на пост в ФБ. Но в истории найти легко
vchslv13
04.04.2019 17:50+1я не знаю как давать ссылку на пост в ФБ
Кликайте по времени и/или дате публикации поста — это прямая ссылка на него.
and7ey
04.04.2019 17:53Найти не удалось, дайте ссылку, пожалуйста (инструкцию выше уже написали).
makasin4ik Автор
04.04.2019 18:27www.facebook.com/mkulgin/posts/2052657298159354
пожалуйста.
Кстати, сегодня пришла одна авиа-компания, тоже с подобной задачей — парсить цены на направления.and7ey
04.04.2019 18:54Спасибо! Ожидал, что там гораздо больше инфы — какие сайты умеете парсить, исходники ;), может, скачанные данные.
Интересно, а зачем это авиакомпании? У нее доступ к сирене и прочим ведь есть. Или хотят контролировать, что их же билеты без комиссии продаются?
makasin4ik Автор
04.04.2019 18:59Да собственно любые. Какая разница. Я не знаю зачем — не знаю этого рынка, сам из торговли. Но просят — полагаю что людям надо.
abmanimenja
04.04.2019 21:43Интересно, а зачем это авиакомпании? У нее доступ к сирене и прочим ведь есть.
В Сирене же не цена конечного покупателя.
Продавцов одного и того же рейса много. И розницы цены у них не едины.
На этих плясках с ценами можно подзаработать побольше — скажем, подняв цену. Но насколько допустимо поднять? Или же дав скидку — но сколько дать?
Для этого нужно знать ситуацию по всему рынку.
abmanimenja
04.04.2019 21:12открыто предоставляют информацию об ежедневных объемах продаж (заказах) или остатках товара, на основе которой не сложно составить общее представлении о продажах (часто слышу мнение, мол эти данные могут искажаться намеренно — возможно, а возможно и нет)
Искажают. Не все, не часто. Но были у меня такие заказы — система должна была публиковать цифры остатков по хитрому нелинейному алгоритму пересчитывая.
Отслеживанием остатков в современном мире с отлаженной логистикой, где все стремятся сократить замороженные в товаре деньги, — когда подвозят товар понемногу, а иногда даже и ежедневно поштучно — вы не сможете вычислить продажи/обороты.
Если продавец заказывает товар очень издалека и товар поступает большими партиями изредка, что сразу в один какой то день влияет на остатки значительно — другое дело.
abmanimenja
04.04.2019 21:21то самое, что вложено в каждую пачку и является т.н. фактической информацией, т.е. маловероятно попадает под закон о защите авторских прав. В результате вместо набора инструкций вручную, заказчикам останется лишь внести небольшие корректировки в шаблоны инструкций, и всё – контент для сайта готов. Но да, могут быть и авторские описания лекарств, которые заверены у нотариуса и сделаны специально как своего рода ловушки
В этом случае чужой труд по наполнению контентом вы однозначно уворовали. Как минимум с моральной точки зрения это плохо.
Насчет авторского права — у нотариуса заверять не нужно, это облегчает дальнейшее судебное разбирательство, но обязательным требованием не является.khim
04.04.2019 23:37Все эти заверения у нотариуса ничего не меняют. Потому что «как бы разрешение» использовать даже фактическую информацию звучит следующим образом: изготовитель базы данных не может запрещать использование отдельных материалов, хотя и содержащихся в базе данных, но правомерно полученных использующим их лицом из иных, чем эта база данных, источников (выделение моё).
Уж извините — но это не «разрешение», а прямой запрет. И предназначен он не для людей, пытающися спарсить TuTu.Ru, а, наоборот, к самим TuTu.Ru: если кто-то возьмёт брошюрку с расписанием электричек и выложит её на сайте — то TuTu.Ru аж никак не смогут ему это запретить (хотя там будет та же информация, что и на сайте!)… а вот создатели брошюрки — могут.
abmanimenja
04.04.2019 21:26+1При заказе на мониторинг цен мы сразу предупреждаем, что будем парсить не только конкурентов, но и заказчика. Это необходимо для получения схожих таблиц с товарами и ценами, которые мы сможем обновлять автоматически
Почему бы не попросить у заказчика выгрузку нужных вам данных, непосредственно сделанную из его базы данных?khim
04.04.2019 23:39Потому что это приводит к куда большему геморою: вам нужно будет учитывать то, что моменты, когда вы парсите сайч и погда происходит выгрузка могут не совпадать, что базу данных, внезапно, тоже нужно парсить — так что в конечно итогда парсить параллельно просто удобнее для них, я думаю.
enzain
04.04.2019 21:46Как защититься от парсинга?
Да никак. И стоит ли вообще защищаться от парсинга?Ну как же никак?
Каждый запрос отдавать случайным стилем и форматированием, с различным расположением данных. Идеальный вариант. Ибо нефиг… Нужны данные? Придите и попросите. Купите. Не продают — значит не нужны :)
В другом случае, когда на сайте что-то меняется, бот просто перестает понимать, где что находится, и нашему программисту приходится заново его настраивать.
Вооот… и так должно быть каждый день… А лучше на каждый запрос :)
abmanimenja
04.04.2019 21:55+1Каждый запрос отдавать случайным стилем и форматированием, с различным расположением данных. Идеальный вариант. Ибо нефиг… Нужны данные? Придите и попросите. Купите. Не продают — значит не нужны :)
А пользователи вам не нужны?
Если каждый раз очередная страница или перезагрузка страницы идёт с новым стилем — пользователи скажут «адьёс, амиго» и помашут ручкой.enzain
04.04.2019 22:54Это было — "например"
Стили понятно трогать смысла нет — игнорируются они достаточно просто.
Замена структуры страницы — не проблема как мне кажется при каждом запросе.
Цена в картинке формата проверки на дальтонизм, сомневаюсь что автоматом получится распознать (опять про клиентов не надо, это опять — пример, всегда можно найти подходящий вариант, не напрягающий живого человека, но достаточно сложный для программной обработки чтобы отказаться от неё)
PavelBelyaev
05.04.2019 13:59А есть ли способы детектить Selenium? Где-то читал, что человек сталкивался с таким, что на сайте определялось что плагнин селениум стоит в браузере, что там какой-то заголовок передается или скрипт подгружен.
Еще как идея — аналогично вебвизору анализировать движение мышки или прикосновения тача.Tatikoma
05.04.2019 14:05Можно детектить, в гугле есть информация, есть различия в зависимости от используемого драйвера. Если используете безголовый режим браузера, — детектить ещё проще.
Анализировать движения мышки и прикоснования тача — в первую очередь, да. Так же анализировать нажатия на клавиши, там на самом деле довольно много полезной информации.



akura13
Было время когда я бы вам сказал — это невозможно! А это круто!
makasin4ik Автор
да. два года назад я и сам бы сказал, что парсить 300+ сайтов ежедневно — невозможно :)
Z10yTap0k
Ферма selinium и в перед. Я так написал маленький сайт на кластере docker swarm жене для мониторинга продавцов (она импортер), чтобы те не нарушали ррц\мрц. Всё работает стабильно. Все затраты 4 ноды по 3$. Правда товаров всего около тысячи и сайтов десяток не больше :)
PS. Увидел в комментах, что у Вас тоже ферма selinium и тоже .net :)
aPiks
Вы немного лукавите в том, что защититься от парсинга невозможно. Во-первых, условно говоря, по статистике просмотра можно понять когда весь сайт отсканили. Так делают либо парсеры, либо поисковые системы. Но поисковые системы реагируют на robots, а парсеры нет. К тому же, в сети валяются таблицы ip адресов парсеров, показывать этому списку капчу при входе — не проблема. Аналогично и генерить id и классы, как делает тот-же mail.ru тоже не проблема и не требует каких-то больших затрат. Новая капча от гугла вообще очень точно определяет робот или нет. Если есть подозрения, выпилить пользователя и попросить ввести капчу — просто. В конце концов Honey Pot никто не отменял. Ну и классика, заменять буквы в тексте, делать маски и тд, и даже селениум не поможет.
Возможно, по отдельности это всё не поможет, но все вместе осложнит вам жизнь настолько, что станет нецелесообразным. При этом все эти техники вообще не требуют больших затрат.
remzalp
Просто заказчику парсинга будет дороже эта услуга :)) В любом случае — честный человек должен всё видеть без больших проблем.
В особо крайнем случае нанять толпу китайцев, которые будут ходить по страницам, а фоново будут фоткаться страницы.
aPiks
Толпа китайцев будет ходить с китайских же IP. Такой трафик вообще вычислить и забанить не проблема. Если все через прокси пойдут или VPN, то отследить ещё проще. В обшем то, что вебмастеру закрыть 1 час работы, заказчику будет стоить дороже, чем нанять копирайтера…
Кстати, китайцы уже не такие и дешёвые.
abmanimenja
И начиная с какой-то суммы потенциальный заказчик от услуги откажется.
kbaa
Но все эти техники прекрасно обходятся, так что по сути — защиты нет. Динамические прокси, сервисы распознающие капчи индусами, и selenium с хорошо прописанным алгоритмом действий.
Всё, чего можно добиться — разработка парсера будет стоить подороже, возможно кого-то это и отпугнет, но если целевой сайт — это не каталог на полторы страницы местного ооо «рога и копыта», то повышение затрат мало кого отпугивает.
aPiks
Вы просто себе не совсем представляете как можно блокировать парсеров. Но я вас уверяю, что любой парсинг можно остановить. Автоматический — очень просто. Неавтоматический — сложнее. Но тоже можно.
Короче, было бы желание, а средства защиты есть и они работают, при этом не стоят баснословных денег.
kbaa
Возможно я пока с таким не сталкивался, а можно чуть подробнее, если не сложно? хотя бы в личку, потому что очень любопытно.
Сайтов с разной защитой от ботов навидался полно, но находил способы обойти (если бюджет позволял) всегда
KMiNT21
Дополню — если добавить немного рандома, то вообще труба будет. :) Это настолько запутает и усложнит поиск всех подводных камней, что платить столько никто не захочет.
Помню, я в 2001-м свой первый шароварный продукт похожим образом защищал от взлома. В итоге так и наблюдал вышедший потом недо-crack.
wegres
_
wegres
_
makasin4ik Автор
3 fulltime ))
istinspring
сколько миллионов страниц в сутки? количество сайтов ни о чем не говорит.