
Мы в журнале The Economist очень серьёзно относимся к визуализации данных. Каждую неделю у нас публикуется около 40 графиков в печатной и онлайновой версиях, а также в приложениях. Мы везде стремимся точно представить цифры, чтобы они лучше всего иллюстрировали тему. Но иногда допускаем ошибки. Важно усвоить эти уроки, чтобы не повторять ошибки в будущем. Наверняка наш опыт окажется полезен и для вас.
Погрузившись в архивы, я нашла несколько поучительных примеров. Преступления против визуализации данных сгруппированы по трём категориям. Это графики, которые:
Для каждого показана исправленная версия, которая занимает столько же места — важный фактор для печатной публикации.
(Примечание: большинство «оригинальных» графиков опубликованы до редизайна. Улучшенные диаграммы составлены в соответствии с новыми спецификациями. Данные те же).
Начнём с худшего из преступлений: представление данных таким образом, что они вводят в заблуждение. Мы никогда специально так не делаем! Но иногда это происходит. Рассмотрим три примера из нашего архива.

(данные в csv)
Этот график показывает среднее количество лайков Facebook на страницах левых партий. Цель диаграммы состояла в том, чтобы показать разницу в лайках постов господина Корбина и других.
Оригинальный график не только преуменьшает количество лайков Корбина, но и преувеличивает показатели для других участников (вот ещё один пример такой ошибки). В переработанной версии столбец мистера Корбина указан полностью. Все остальные столбцы по-прежнему видимы.
Ещё одна странность — выбор цвета. В попытке подражать цветовой гамме лейбористов мы использовали три оттенка оранжевого/красного, присвоенные 1) Корбину, 2) другим депутатам и 3) партиям/группам. Это нигде не объясняется. Хотя логика может быть очевидна для многих, но она имеет мало смысла для тех, кто не очень знаком с британской политикой.
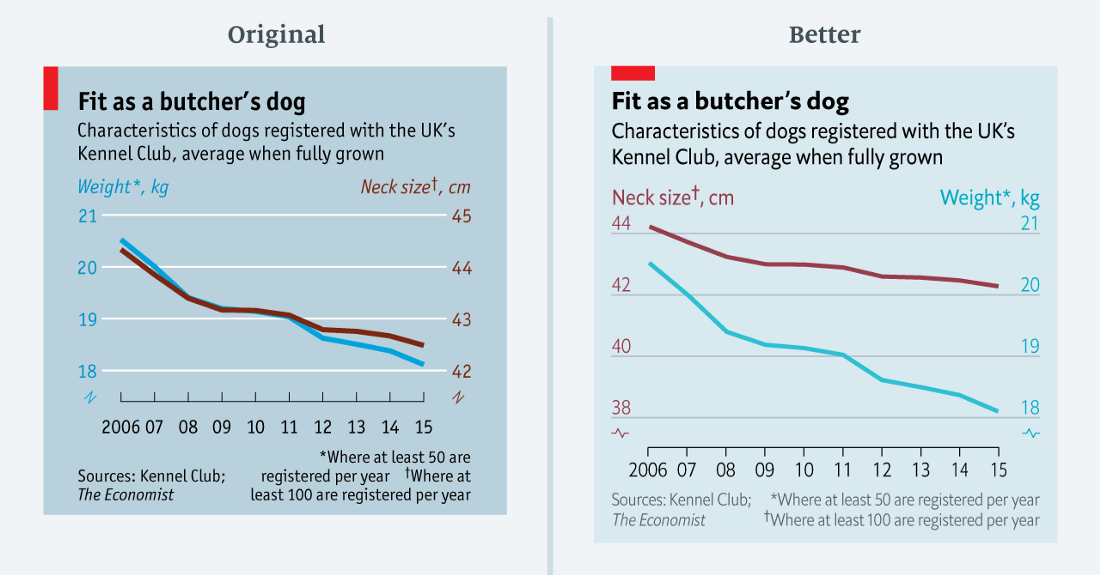
Редкий пример идеальной корреляции? Вообще-то нет (данные в csv)
Вышеприведённый график из статьи о снижении веса собак. На первый взгляд кажется, что вес и окружность шеи собаки прекрасно коррелируют. Но правда ли это? Только до некоторой степени.
На графике обе шкалы уменьшаются на три единицы (с 21 до 18 слева; с 45 до 42 справа). Но в процентном выражении левая шкала уменьшается на 14%, а правая — на 7%. В переработанной диаграмме я сохранила двойную шкалу, но скорректировала диапазоны, чтобы отразить сопоставимое пропорциональное изменение.
Учитывая весёлую тему этой диаграммы, ошибка может показаться относительно незначительной. В конце концов, смысл одинаковый в обеих версиях. Но важен вывод: если два графика слишком близко друг к другу, вероятно, нужно внимательнее посмотреть на шкалы.

Мнения о Brexit почти так же неустойчивы, как и переговоры о нём (данные в csv)
Мы опубликовали эту диаграмму с данными опроса в нашем новостном приложении Espresso. Она показывает отношение к результатам референдума ЕС в виде линейного графика. Судя по данным, респонденты сильно колеблются в своих взглядах: результаты скачут на несколько процентных пунктов.
Вместо сглаженной кривой для отображения тренда мы указали фактические значения каждого опроса. Это произошло прежде всего потому, что наш инструмент построения графиков не умел строить сглаженные линии. Только недавно мы освоили более продвинутые программы для обработки статистических данных (например, R) с более сложными методами визуализации. Сегодня любой может построить сглаженную кривую для опросов, как улучшенный вариант вверху.
Тут ещё можно отметить нарушение шкалы. Исходная диаграмма разбрасывает данные шире, чем следует. В переработанной версии я добавила немного пространства между началом шкалы и минимальной точкой данных. Фрэнсис Ганьон предлагает хорошую формулу для таких ситуаций: оставляйте свободной минимум 33% площади под линейным графиком, который не начинается с нуля.
Не такое серьёзное преступление, как введение в заблуждение, но если график трудно понять — это признак плохо выполненной работы по визуализации.
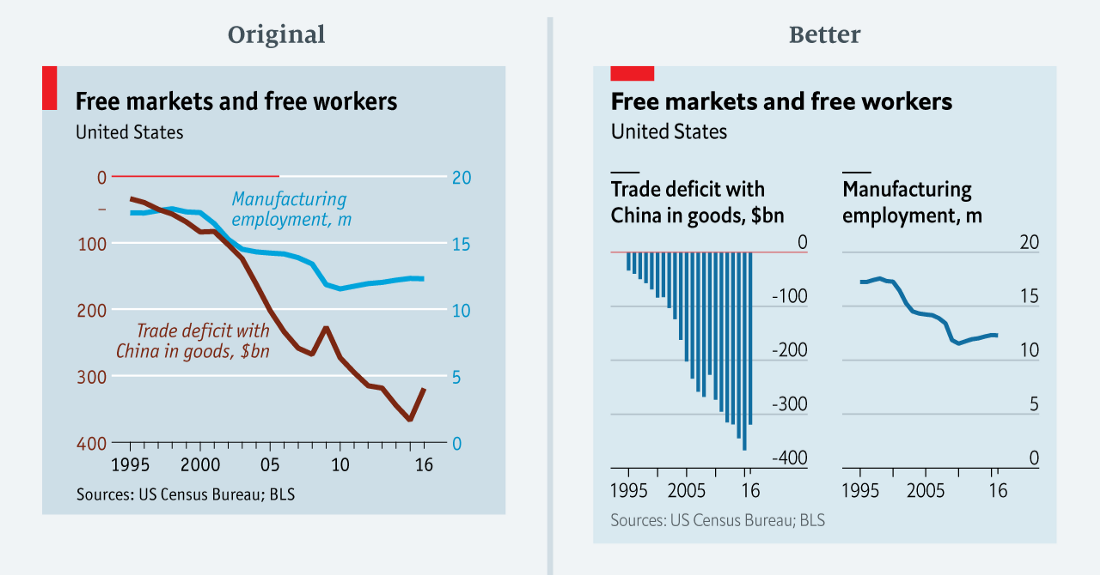
… что? (данные в csv)
Журналисты The Economist стремятся в хорошем смысле озадачить читателя. Но иногда мы заходим слишком далеко. На диаграмме вверху показан торговый дефицит США по товарам и число людей, занятых в обрабатывающей промышленности.
Эту диаграмму невероятно трудно понять. У неё две основные проблемы. Во-первых, значения одного ряда (торговый дефицит) полностью отрицательные, в то время как другие (занятость в обрабатывающей промышленности) положительные. Сложно объединить такие разные данные в одной диаграмме. Очевидное «решение» приводит ко второй проблеме: два ряда данных не имеют общей базовой линии. Базовая линия торгового дефицита находится в верхней части графика (выделена красной линией, проохдит через половину графика). Базовая линия правой шкалы находится внизу.
Переработанная диаграмма показывает, что не было никакой необходимости объединять два ряда данных. Взаимосвязь между торговым дефицитом и занятостью в обрабатывающей промышленности остаётся ясной и занимает лишь чуть больше места.
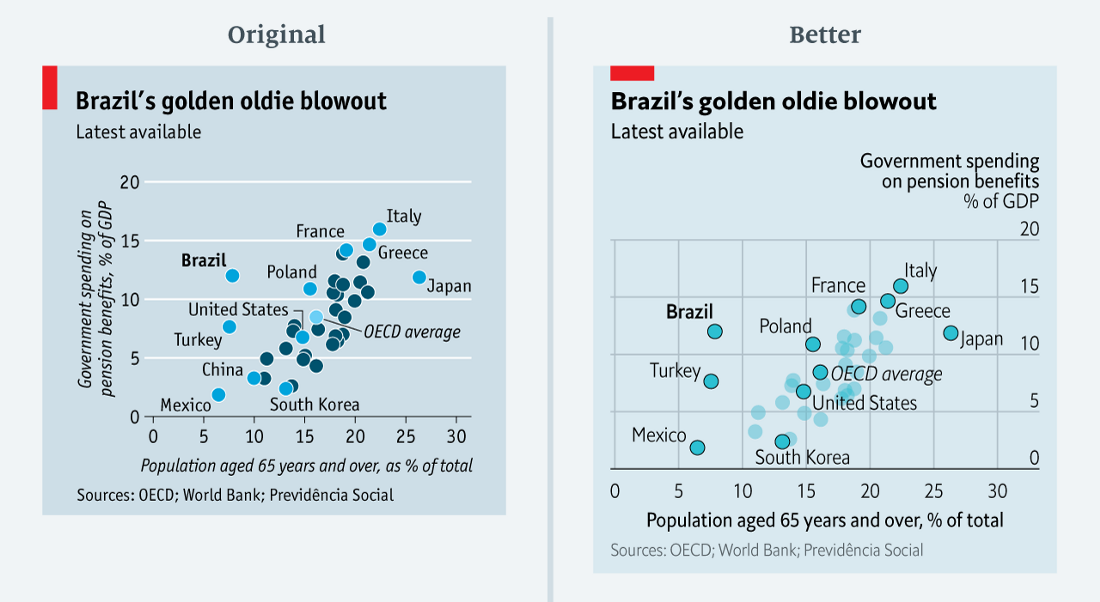
50 оттенков синего (данные в csv)
На этой диаграмме сравниваются государственные расходы на пенсионные пособия с долей людей старше 65 лет в ряде стран, с особым упором на Бразилию. Чтобы не раздувать диаграмму, визуализатор подписала только некоторые страны и выделил их голубым. Средний показатель по ОЭСР выделен светло-голубым.
Визуализатор (это была я!) проигнорировала тот факт, что изменение цвета часто подразумевает изменение категории. Здесь тоже у читателя может появиться такая мысль, что все синие страны как будто принадлежат к другой группе, чем голубые. Это не так. Единственное отличие — они просто не подписаны.
В переработанном варианте цвет одинаков для всех. Я изменила только интенсивность для подписанных стран. Всё остальное делает типографика: Бразилия, страна фокуса, подписана жирным шрифтом, а средний показатель ОЭСР — курсивом.
Ошибки в этой последней категории менее очевидны. Подобные диаграммы не вводят в заблуждение и не очень сбивают с толку. Они просто не могут оправдать своё существование. Или их неправильно построили, или мы пытались втиснуть слишком много информации в слишком маленькое пространство.
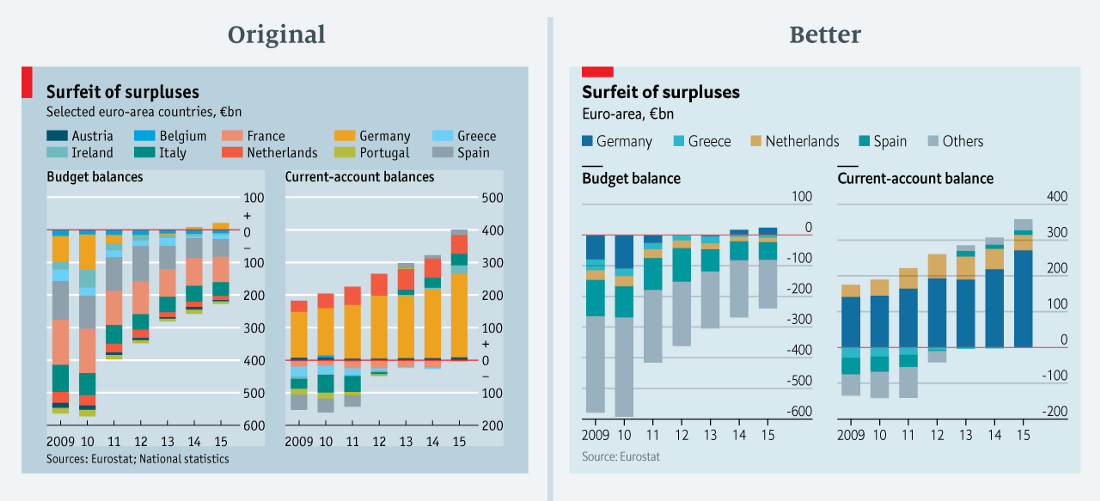
«Чем больше цветов, тем лучше!» (данные в csv)
Настоящая радуга! Мы опубликовали эту диаграмму в колонке о бюджетном профиците Германии. Она показывает баланс бюджета и текущий баланс десяти стран зоны евро. С таким количеством цветов — некоторые из которых довольно трудно различить или даже увидеть, потому что значения слишком малы — смысл диаграммы сложно понять. Это почти блокирует мозг, заставляя читателя пропустить график и двигаться дальше. И, что более важно, поскольку мы не приводим цифры по всем странам Еврозоны, нет никакого смысла складывать данные.
Я перечитала статью, чтобы найти вариант упрощения диаграммы. В тексте упоминаются Германия, Греция, Нидерланды, Испания и Еврозона. В переработанной версии диаграммы я решила выделить только их, а остальных поместила в категорию «Другие» (общий баланс текущего счета на переработанной диаграмме меньше, чем на исходной диаграмме, из-за пересмотра данных Евростатом).
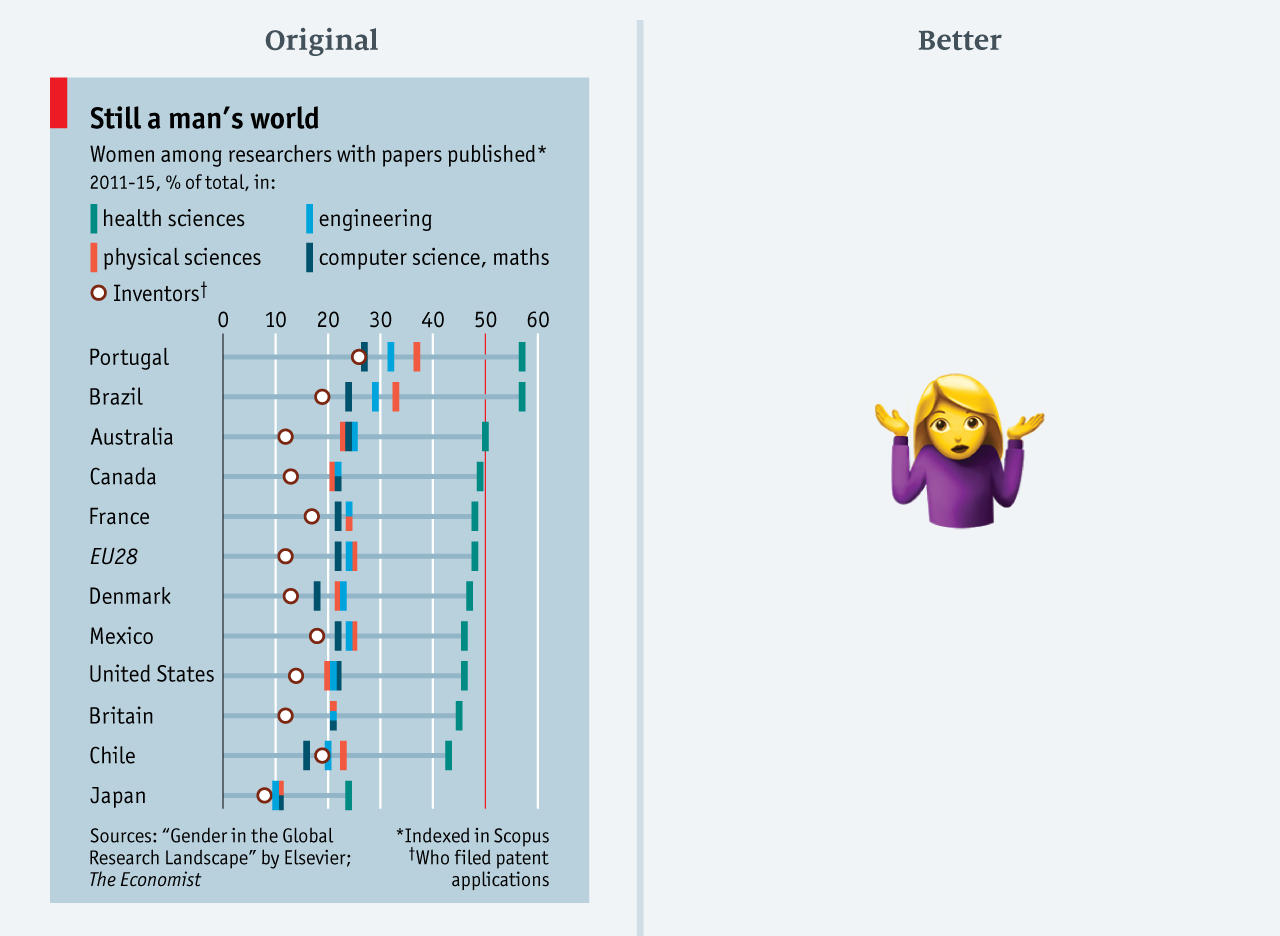
Я сдаюсь (данные в csv)
Ограниченные пространством на странице, мы часто испытываем соблазн загнать все данные в слишком маленький слот. Хотя это экономит ценное место на странице, но есть и последствия, как видно на этом графике от марта 2017 года. Это график к статье о том, что мужчины доминируют в науке. Все позиции одинаково интересны и актуальны для статьи. Но, такое количество данных трудно усвоить: здесь указаны четыре категории областей исследования, а также доля авторов патентов в каждой стране.
Поразмыслив, я решила не изменять эту диаграмму. Если сохранить все данные, диаграмма будет слишком большой для маленькой статьи. В таких случаях лучше что-нибудь вырезать. В качестве альтернативы можно показать некий средний показатель: например, среднюю долю статей женщин во всех областях. (Пожалуйста, дайте знать, если у вас есть идеи, как визуализировать это в тесном пространстве!)
Лучшие практики быстро развиваются: что приемлемо сегодня, осудят завтра. Всё время появляются новые и более совершенные методы. Вы когда-нибудь совершали «инфографическое преступление», которое можно легко исправить?
Погрузившись в архивы, я нашла несколько поучительных примеров. Преступления против визуализации данных сгруппированы по трём категориям. Это графики, которые:
- вводят в заблуждение;
- сбивают с толку;
- не могут довести смысл.
Для каждого показана исправленная версия, которая занимает столько же места — важный фактор для печатной публикации.
(Примечание: большинство «оригинальных» графиков опубликованы до редизайна. Улучшенные диаграммы составлены в соответствии с новыми спецификациями. Данные те же).
Графики, которые вводят в заблуждение
Начнём с худшего из преступлений: представление данных таким образом, что они вводят в заблуждение. Мы никогда специально так не делаем! Но иногда это происходит. Рассмотрим три примера из нашего архива.
Ошибка: усечение шкалы
(данные в csv)
Этот график показывает среднее количество лайков Facebook на страницах левых партий. Цель диаграммы состояла в том, чтобы показать разницу в лайках постов господина Корбина и других.
Оригинальный график не только преуменьшает количество лайков Корбина, но и преувеличивает показатели для других участников (вот ещё один пример такой ошибки). В переработанной версии столбец мистера Корбина указан полностью. Все остальные столбцы по-прежнему видимы.
Ещё одна странность — выбор цвета. В попытке подражать цветовой гамме лейбористов мы использовали три оттенка оранжевого/красного, присвоенные 1) Корбину, 2) другим депутатам и 3) партиям/группам. Это нигде не объясняется. Хотя логика может быть очевидна для многих, но она имеет мало смысла для тех, кто не очень знаком с британской политикой.
Ошибка: эффект взаимосвязи за счёт подгонки шкал
Редкий пример идеальной корреляции? Вообще-то нет (данные в csv)
Вышеприведённый график из статьи о снижении веса собак. На первый взгляд кажется, что вес и окружность шеи собаки прекрасно коррелируют. Но правда ли это? Только до некоторой степени.
На графике обе шкалы уменьшаются на три единицы (с 21 до 18 слева; с 45 до 42 справа). Но в процентном выражении левая шкала уменьшается на 14%, а правая — на 7%. В переработанной диаграмме я сохранила двойную шкалу, но скорректировала диапазоны, чтобы отразить сопоставимое пропорциональное изменение.
Учитывая весёлую тему этой диаграммы, ошибка может показаться относительно незначительной. В конце концов, смысл одинаковый в обеих версиях. Но важен вывод: если два графика слишком близко друг к другу, вероятно, нужно внимательнее посмотреть на шкалы.
Ошибка: неправильный метод визуализации
Мнения о Brexit почти так же неустойчивы, как и переговоры о нём (данные в csv)
Мы опубликовали эту диаграмму с данными опроса в нашем новостном приложении Espresso. Она показывает отношение к результатам референдума ЕС в виде линейного графика. Судя по данным, респонденты сильно колеблются в своих взглядах: результаты скачут на несколько процентных пунктов.
Вместо сглаженной кривой для отображения тренда мы указали фактические значения каждого опроса. Это произошло прежде всего потому, что наш инструмент построения графиков не умел строить сглаженные линии. Только недавно мы освоили более продвинутые программы для обработки статистических данных (например, R) с более сложными методами визуализации. Сегодня любой может построить сглаженную кривую для опросов, как улучшенный вариант вверху.
Тут ещё можно отметить нарушение шкалы. Исходная диаграмма разбрасывает данные шире, чем следует. В переработанной версии я добавила немного пространства между началом шкалы и минимальной точкой данных. Фрэнсис Ганьон предлагает хорошую формулу для таких ситуаций: оставляйте свободной минимум 33% площади под линейным графиком, который не начинается с нуля.
Графики, которые сбивают с толку
Не такое серьёзное преступление, как введение в заблуждение, но если график трудно понять — это признак плохо выполненной работы по визуализации.
Ошибка: слишком заумные диаграммы
… что? (данные в csv)
Журналисты The Economist стремятся в хорошем смысле озадачить читателя. Но иногда мы заходим слишком далеко. На диаграмме вверху показан торговый дефицит США по товарам и число людей, занятых в обрабатывающей промышленности.
Эту диаграмму невероятно трудно понять. У неё две основные проблемы. Во-первых, значения одного ряда (торговый дефицит) полностью отрицательные, в то время как другие (занятость в обрабатывающей промышленности) положительные. Сложно объединить такие разные данные в одной диаграмме. Очевидное «решение» приводит ко второй проблеме: два ряда данных не имеют общей базовой линии. Базовая линия торгового дефицита находится в верхней части графика (выделена красной линией, проохдит через половину графика). Базовая линия правой шкалы находится внизу.
Переработанная диаграмма показывает, что не было никакой необходимости объединять два ряда данных. Взаимосвязь между торговым дефицитом и занятостью в обрабатывающей промышленности остаётся ясной и занимает лишь чуть больше места.
Ошибка: запутанные цвета
50 оттенков синего (данные в csv)
На этой диаграмме сравниваются государственные расходы на пенсионные пособия с долей людей старше 65 лет в ряде стран, с особым упором на Бразилию. Чтобы не раздувать диаграмму, визуализатор подписала только некоторые страны и выделил их голубым. Средний показатель по ОЭСР выделен светло-голубым.
Визуализатор (это была я!) проигнорировала тот факт, что изменение цвета часто подразумевает изменение категории. Здесь тоже у читателя может появиться такая мысль, что все синие страны как будто принадлежат к другой группе, чем голубые. Это не так. Единственное отличие — они просто не подписаны.
В переработанном варианте цвет одинаков для всех. Я изменила только интенсивность для подписанных стран. Всё остальное делает типографика: Бразилия, страна фокуса, подписана жирным шрифтом, а средний показатель ОЭСР — курсивом.
Диаграммы, которые не могут довести смысл
Ошибки в этой последней категории менее очевидны. Подобные диаграммы не вводят в заблуждение и не очень сбивают с толку. Они просто не могут оправдать своё существование. Или их неправильно построили, или мы пытались втиснуть слишком много информации в слишком маленькое пространство.
Ошибка: слишком много деталей
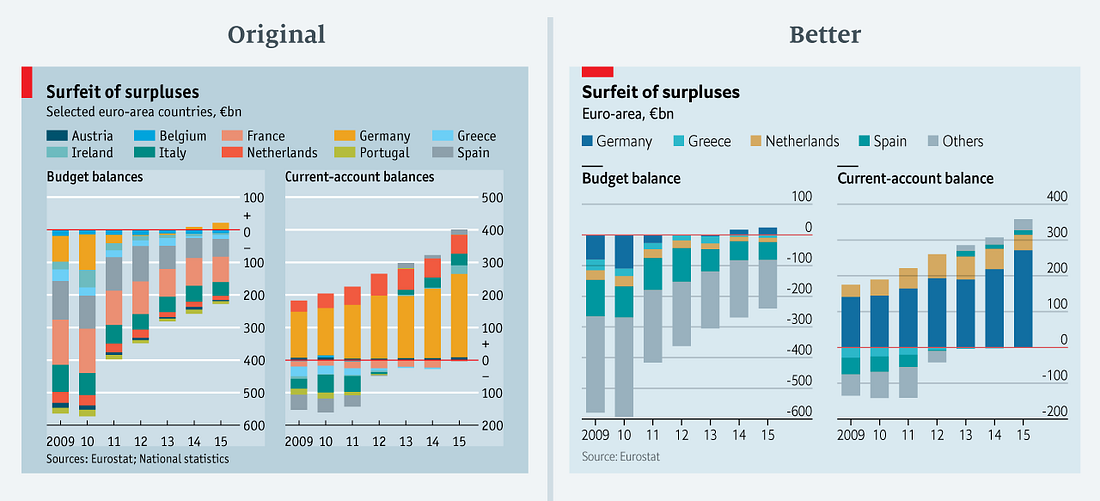
«Чем больше цветов, тем лучше!» (данные в csv)
Настоящая радуга! Мы опубликовали эту диаграмму в колонке о бюджетном профиците Германии. Она показывает баланс бюджета и текущий баланс десяти стран зоны евро. С таким количеством цветов — некоторые из которых довольно трудно различить или даже увидеть, потому что значения слишком малы — смысл диаграммы сложно понять. Это почти блокирует мозг, заставляя читателя пропустить график и двигаться дальше. И, что более важно, поскольку мы не приводим цифры по всем странам Еврозоны, нет никакого смысла складывать данные.
Я перечитала статью, чтобы найти вариант упрощения диаграммы. В тексте упоминаются Германия, Греция, Нидерланды, Испания и Еврозона. В переработанной версии диаграммы я решила выделить только их, а остальных поместила в категорию «Другие» (общий баланс текущего счета на переработанной диаграмме меньше, чем на исходной диаграмме, из-за пересмотра данных Евростатом).
Ошибка: много данных, мало места
Я сдаюсь (данные в csv)
Ограниченные пространством на странице, мы часто испытываем соблазн загнать все данные в слишком маленький слот. Хотя это экономит ценное место на странице, но есть и последствия, как видно на этом графике от марта 2017 года. Это график к статье о том, что мужчины доминируют в науке. Все позиции одинаково интересны и актуальны для статьи. Но, такое количество данных трудно усвоить: здесь указаны четыре категории областей исследования, а также доля авторов патентов в каждой стране.
Поразмыслив, я решила не изменять эту диаграмму. Если сохранить все данные, диаграмма будет слишком большой для маленькой статьи. В таких случаях лучше что-нибудь вырезать. В качестве альтернативы можно показать некий средний показатель: например, среднюю долю статей женщин во всех областях. (Пожалуйста, дайте знать, если у вас есть идеи, как визуализировать это в тесном пространстве!)
Лучшие практики быстро развиваются: что приемлемо сегодня, осудят завтра. Всё время появляются новые и более совершенные методы. Вы когда-нибудь совершали «инфографическое преступление», которое можно легко исправить?
BeardedBeaver
Вообще-то корреляция хорошая, что можно проиллюстрировать обычным кроссплотом:
Ghost_nsk
Читатели популярных изданий не факт что знают что такое корреляция, а если и знаю то скорее на уровне «графики похожи». А вообще подгонкой шкал можно многое друг к другу подогнать, где то была статья с хорошими примерами.
pallada92
Ваш комментарий заставил меня задуматься. Это правда, что любые две не связанные величины, которые изменяются во времени строго линейно, будут иметь полную корреляцию?
Pand5461
Две величины, которые обе меняются по времени строго линейно, не связанными быть не могут :)
BeardedBeaver
Получается, что так. Но надо заметить, что корреляция двух величин не говорит об их связи между собой.
Pand5461
Вообще-то, говорит.
Независимые случайные величины обязаны быть нескоррелированными.
Обратное неверно — нескоррелированные случайные величины могут быть зависимыми. Например, sin(x) и cos(x) для x, случайно распределённого на [0; 2?).
BeardedBeaver
Мы, возможно, немного о разном говорим. Вот тут обнаружили корреляцию между количеством денег, потраченных в штатах на космическую программу и количеством самоубийств через повешение. Или между количеством фильмов с Николасом Кейджем и количеством людей, утонувших в бассейне. Мы же не будем пытаться утверждать, что это связанные параметры?
SLASH_CyberPunk
Первые два графика перепутаны между Original <-> Better
pdima
да и последний, заменить полезную информацию emoji…