
Не ORMом единым
Всем привет! Я руковожу отделом партнерской разработки (Partners Development) в сервисе бронирования отелей Ostrovok.ru. В этой статье я хотел бы рассказать про то, как на одном проекте мы использовали Django ORM.
На самом деле я слукавил, название должно было быть "Не ORMом единым". Если вам интересно, почему я так написал, а также если:
- У вас в стеке Django, и вам хочется выжать из ORM максимум возможностей, а не просто
Model.objects.all(), - Вы хотите перенести часть бизнес-логики на уровень баз данных,
- Или вы хотите узнать, почему самая частая отмазка разработчиков в B2B.Ostrovok.ru "так исторически сложилось",
… добро пожаловать под кат.

В 2014 году мы запустили B2B.Ostrovok.ru – сервис онлайн-бронирования отелей, трансферов, автомобилей и прочих туристических услуг для профессионалов туристического рынка (турагентов, операторов и корпоративных клиентов).
В B2B мы спроектировали и довольно успешно используем абстрактную модель заказов, основанную на GenericForeignKey – мета?заказ – MetaOrder.
Мета-ордер – это абстрактная сущность, которую можно использовать независимо от того, к какому типу заказа она относится: отель (Hotel), дополнительная услуга (Upsell) или автомобиль (Car). В будущем у нас могут появиться и другие типы.
Так было не всегда. Когда B2B-сервис запускался, через него можно было забронировать только отели, и вся бизнес-логика была ориентирована на них. Было создано много полей, например, для отображения курсов валют суммы продажи и суммы возврата бронирования. Со временем мы поняли, как можно лучше хранить и переиспользовать эти данные, учитывая мета-ордеры. Но весь код переписать не получилось, и часть этого наследия пришло в новую архитектуру. Собственно, это и привело к сложностям в расчетах, в которых используется несколько типов заказов. Что поделать ? так исторически сложилось...
Моя цель ? показать на нашем примере силу Django ORM.
Предыстория
Нашим B2B клиентам для планирования своих расходов очень не хватало информации о том, сколько им нужно заплатить сейчас/завтра/позже, есть ли у них задолженность по заказам и каков ее размер, а также сколько еще они могут тратить в пределах своих лимитов. Мы решили показывать эту информацию в виде дашборда – такая простая панелька с понятной диаграммой.

(все значения тестовые и не относятся к конкретному партнеру)
На первый взгляд, все довольно просто – фильтруем все заказы партнера, суммируем и показываем.
Варианты решения
Небольшое пояснение к тому, как мы производим расчеты. Мы международная компания, наши партнеры из разных стран проводят операции – покупают и перепродают бронирования – в разных валютах. При этом они должны получать финансовую отчетность в выбранной ими валюте (как правило, местной). Было бы глупо и непрактично хранить все возможные данные о курсах всех валют, поэтому нужно выбрать опорную валюту, например, рубль. Таким образом, можно хранить курсы всех валют только к рублю. Соответственно, когда партнер хочет получить сводку, мы конвертируем суммы по курсу, установленному на момент продажи.
"В лоб"
Фактически это Model.objects.all() и цикл с условиями:
def output(partner_id):
today = dt.date.today()
# query_get_one - об этом дальше
partner = query_get_one(Partner.objects.filter(id=partner_id))
# все заказы по какому-то контракту
query = MetaOrder.objects.filter(partner=partner)
result = defaultdict(Decimal)
for morder in query:
# специальные методы, которые под капотом обращаются
# к нужному связанному ордеру
payment_pending = morder.get_payment_pending()
payment_due = morder.get_payment_due()
# вот здесь происходит расчет в валюте контракта
# (та самая конвертация через опорную валюту)
payable = morder.get_payable_in_cur()
# заказы которые скоро нужно будет оплатить
if payment_pending > today:
result['payment_pending'] += payable
# заказы, которые нужно оплатить сейчас
if payment_pending < today and payment_due > today:
result['payment_due'] += payable
return resultЭтот запрос вернёт генератор, в котором потенциально содержится несколько сотен бронирований. На каждое из этих бронирований будет совершаться запрос в базу, и поэтому цикл будет отрабатывать очень долго.
Можно немного ускорить дело, если добавить метод prefetch_related:
# object - это ссылка на объект из GenericForeignKey.
query = query.prefetch_related('object')Тогда запросов в базу (переходов по GenericForeignKey) будет чуть меньше, но все равно в итоге мы упремся в их количество, потому что запрос в базу данных все еще будет совершаться на каждую итерацию цикла.
Метод output можно (и нужно) кешировать, но все равно первый вызов отрабатывает порядка минуты, что совершенно неприемлемо.
Вот какие результаты дал такой подход:
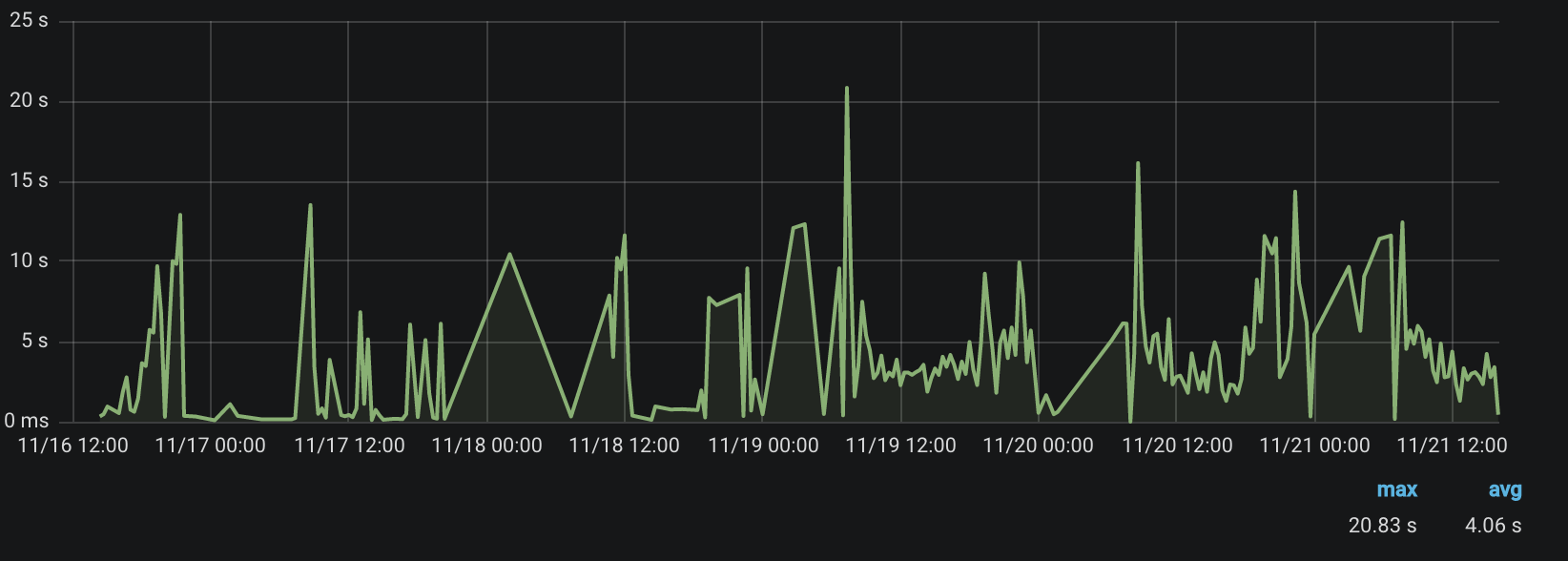
Среднее время ответа – 4 секунды, и есть пики, достигающие 21 секунды. Довольно долго.
Дашборд мы выкатили не для всех партнеров, и поэтому у нас было не так много запросов к нему, но все равно достаточно, чтобы понять, что такой подход не эффективен.
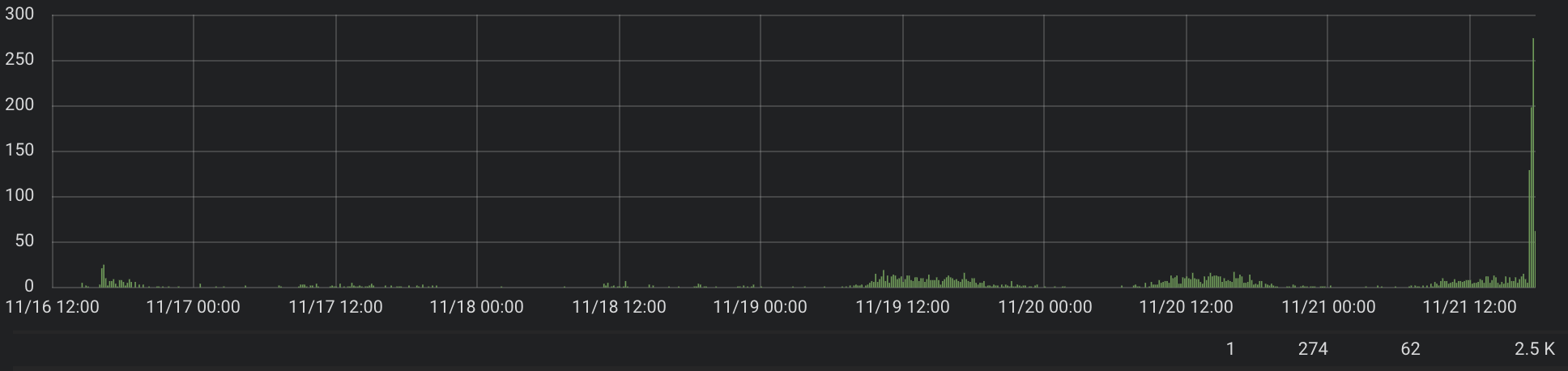
Цифры снизу справа – это количество запросов: минимум, максимум, среднее, общее.
С умом
Прототип "в лоб" был хорош для понимания сложности задачи, но неоптимален для использования. Мы решили, что гораздо быстрее и менее ресурсозатратно будет сделать несколько сложных запросов в базу данных, чем много простых.
План запроса
Широкими мазками план запроса можно обрисовать примерно так:
- собрать заказы по начальным условиям,
- подготовить поля для расчета через
annotate, - рассчитать значения полей,
- сделать
aggregateпо сумме и количеству,
Начальные условия
Партнеры, которые заходят на сайт, могут видеть информацию только по своему контракту.
partner = query_get_one(Partner.objects.filter(id=partner_id))На случай, когда мы не хотим показывать новые типы заказов/бронирований, нужно отфильтровать только поддерживаемые:
query = MetaOrder.objects.filter(
partner=partner,
content_type__in=[
Hotel.get_content_type(),
Car.get_content_type(),
Upsell.get_content_type(),
]
)Важен статус заказа (подробнее про Q):
query = query.filter(
Q(hotel__status__in=['completed', 'cancelled'])
# можно добавить фильтры по статусам, специфичным для тачек
# | Q(car__status__in=[...])
)Мы также часто используем заранее подготовленные запросы, например, для исключения всех заказов, которые невозможно оплатить. Там довольно много бизнес?логики, которая в рамках этой статьи не очень нам интересна, но по сути это просто дополнительные фильтры. Метод, который возвращает подготовленный запрос, может выглядеть так:
query = MetaOrder.exclude_non_payable_metaorders(query)Как видите, это метод класса, который также вернет QuerySet.
Еще подготовим пару переменных для условных конструкций и для хранения результатов вычислений:
import datetime as dt
from typing.decimal import Decimal
today = dt.date.today()
result = defaultdict(Decimal)Подготовка полей (annotate)
Из?за того, что нам приходится обращаться к полям в зависимости от типа заказа, мы будем применять Coalesce. Таким образом, мы сможем абстрагировать любое количество новых типов заказов в единственное поле.
Вот так выглядит первая часть annotate блока:
# намеренно опускаю большую часть импортов,
# кроме непонятных в данном контексте
from app.helpers.numbers import ZERO, ONE
query_annoted = query.annotate(
_payment_pending=Coalesce(
'hotel__payment_pending',
'car__payment_pending',
'upsell__payment_pending',
),
_payment_due=Coalesce(
'hotel__payment_due',
'car__payment_due',
'upsell__payment_due',
),
_refund=Coalesce(
'hotel__refund',
Value(ZERO)
),
_refund_currency_rate=Coalesce(
'hotel__refund_currency_rate',
Value(ONE)
),
_sell=Coalesce(
'hotel__sell',
Value(ZERO)
),
_sell_currency_rate=Coalesce(
'hotel__sell_currency_rate',
Value(ONE)
),
)Coalesce здесь работает на ура, потому что у отельных заказов есть несколько особых свойств, и во всех остальных случаях (дополнительные услуги и автомобили) нам эти свойства не важны. Так появляются Value(ZERO) для сумм и Value(ONE) для курсов валют. ZERO и ONE это Decimal('0') и Decimal(1), только в виде констант. Подход на любителя, но у нас в проекте принято так.
У вас мог возникнуть вопрос, почему бы некоторые поля не вынести на уровень выше в мета-ордер? Например, payment_pending, который есть везде. Действительно, подобные поля мы со временем переносим в мета-ордер, но сейчас код работает хорошо, поэтому такие задачи у нас не в приоритете.
Еще одна подготовка и расчеты
Теперь нужно произвести некоторые расчеты с суммами, которые мы получили в прошлом annotate блоке. Заметьте, здесь уже не нужно завязываться на тип заказа (кроме одного исключения).
.annotate(
# суффикс _base говорит об опорной валюте
_sell_base=(
F('_sell') * F('_sell_currency_rate')
),
_refund_base=(
F('_refund') * F('_refund_currency_rate')
),
_payable_base=(
F('_sell_base') - F('_refund_base')
),
_reporting_currency_rate=Case(
When(
content_type=Hotel.get_content_type(),
then=RawSQL(
'(hotel.currency_data->>%s)::numeric',
(partner.reporting_currency,),
),
),
output_field=DecimalField(),
default=Decimal('1'),
),
)Самая интересная часть этого блока – поле _reporting_currency_rate, или курс валюты к опорной валюте на момент продажи. Данные по курсам всех валют к опорной валюте для отельного заказа хранятся в currency_data. Это просто JSON. Почему мы так храним? Так исторически сложилось.
И здесь, казалось бы, почему бы не воспользоваться F и не подставить значение валюты контракта? То есть было бы круто, если бы можно было сделать так:
F(f'currency_data__{partner.reporting_currency}')Но f-strings не поддерживаются в F. Хотя тот факт, что в Django ORM уже есть возможность обращения к вложенным json-полям, сильно радует — F('currency_data__USD').
И последний annotate блок – это расчет _payable_in_cur, который будет суммироваться для всех заказов. Это значение должно быть в валюте контракта.
.annotate(
_payable_in_cur=(
F('_payable_base') / F('_reporting_currency_rate')
)
)Особенность работы метода annotate заключается в том, что он генерирует очень много конструкций SELECT something AS something_else, которые напрямую в запросе не участвуют. Это можно увидеть, выгрузив SQL запроса — query.__str__().
Так выглядит SQL-код, сгенерированный Django ORM для base_query_annotated. Его довольно часто приходится читать, чтобы понять, где можно оптимизировать запрос.
Заключительные подсчеты
Здесь будет небольшая обертка для aggregate, чтобы в будущем, если партнеру потребуется какая-то другая метрика, её можно было легко добавить.

def _get_data_from_query(query: QuerySet) -> Decimal:
result = query.aggregate(
_sum_payable=Sum(F('_payable_in_cur')),
)
return result['_sum_payable'] or ZEROИ еще один момент – это последняя фильтрация по бизнес-условию, например, нам нужны все заказы, которые скоро нужно будет оплатить.

before_payment_pending_query = _get_data_from_query(
base_query_annotated.filter(_payment_pending__gt=today)
)Отладка и проверка
Очень удобный способ проверки правильности созданного запроса – сверить его с более читаемой версией расчетов.
for morder in query:
payable = morder.get_payable_in_cur()
payment_pending = morder.get_payment_pending()
if payment_pending > today:
result['payment_pending'] += payableУзнаете метод "в лоб"?
Финальный код
В итоге получили примерно следующее:
def _get_data_from_query(query: QuerySet) -> tuple:
result = query.aggregate(
_sum_payable=Sum(F('_payable_in_cur')),
)
return result['_sum_payable'] or ZERO
def output(partner_id: int):
today = dt.date.today()
partner = query_get_one(Partner.objects.filter(id=partner_id))
query = MetaOrder.objects.filter(partner=partner, content_type__in=[
Hotel.get_content_type(),
Car.get_content_type(),
Upsell.get_content_type(),
])
result = defaultdict(Decimal)
query_annoted = query.annotate(
_payment_pending=Coalesce(
'hotel__payment_pending',
'car__payment_pending',
'upsell__payment_pending',
),
_payment_due=Coalesce(
'hotel__payment_due',
'car__payment_due',
'upsell__payment_due',
),
_refund=Coalesce(
'hotel__refund',
Value(ZERO)
),
_refund_currency_rate=Coalesce(
'hotel__refund_currency_rate',
Value(Decimal('1'))
),
_sell=Coalesce(
'hotel__sell',
Value(ZERO)
),
_sell_currency_rate=Coalesce(
'hotel__sell_currency_rate',
Value(Decimal('1'))
),
).annotate(
# Calculated fields
_sell_base=(
F('_sell') * F('_sell_currency_rate')
),
_refund_base=(
F('_refund') * F('_refund_currency_rate')
),
_payable_base=(
F('_sell_base') - F('_refund_base')
),
_reporting_currency_rate=Case(
# Only hotels have currency_data, therefore we need a
# check and default value
When(
content_type=Hotel.get_content_type(),
then=RawSQL(
'(hotel.currency_data->>%s)::numeric',
(partner.reporting_currency,),
),
),
output_field=DecimalField(),
default=Decimal('1'),
),
)
.annotate(
_payable_in_cur=(
F('_payable_base') / F('_reporting_currency_rate')
)
)
before_payment_pending_query = _get_data_from_query(
base_query_annotated.filter(_payment_pending__gt=today)
)
after_payment_pending_before_payment_due_query = _get_data_from_query(
base_query_annotated.filter(
Q(_payment_pending__lte=today) & Q(_payment_due__gt=today)
)
)
Вот так это работает теперь:
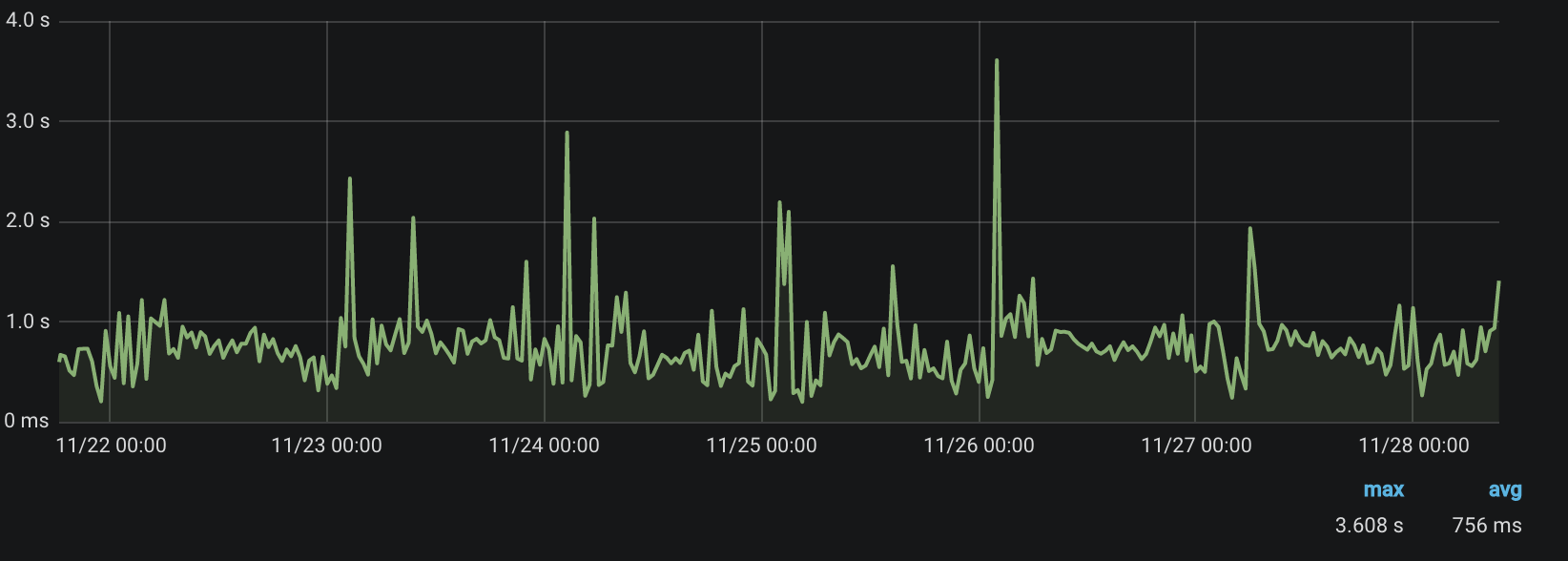

Выводы
Переписав и оптимизировав логику, нам удалось сделать довольно быструю ручку для партнерских метрик и сильно сократить количество запросов в базу данных. Решение оказалось хорошим и мы будем переиспользовать эту логику в других частях проекта. ORM — наше всё.
Пишите комментарии, задавайте вопросы – постараемся ответить! Спасибо!
Комментарии (12)

voron3x
12.04.2019 14:09Да, django ORM мощная штука. Мы также юзаем всю мощь annotate/aggregate для всяких вычисляемых полей (для соблюдения нормальной формы БД). Но ИМХО сложность этого запроса очень высока, и поддержка его в дальнейшем будет очень дорогой. И скорость для ручки в 3 секунды тоже так себе результат.
Мы в своей практики для такого юзаем OLAP решения. Если данные как-то связанны с временем то timeseries DB, если случай как у вас то чтонить типа Vertica. И в этих таблицах уже храним денормализированные представления которое легко и удобно обсчитывать.
Конечно у такого подхода тоже есть минусы, это цена поддержки. Но такой подход нам больше нравится так как позволяет быть немного гибче в основной БД.
cvaynex Автор
12.04.2019 17:39OLAP
Vertica
timeseries DBУ нас всё это тоже есть, но больше используется для аналитики. Думаю стоит попробовать внедрить и в продукте.
И скорость для ручки в 3 секунды тоже так себе результат.
Это только первый ответ для большого партнера с сотнями бронирований. После
первого запроса кешируем результат на несколько минут и ручка отвечает в пределах 100 мс. За последние 90 дней среднее время ответа ручки — 600 мс. Для нас приемлемо, тем более, что это не ключевой функционал сервиса.voron3x
12.04.2019 17:58А почему бы еще не использовать решение в лоб но в фоне? Данные не выглядят как realtime можно формировать их раз в сутки и отдавать готовые на дашборд.
Плюсы:
* Проще код, проще поддержка
* Дешевле изменения
* Быстрая отдача
* Легче тестировать
* Нагрузка в вeчернее или ночное время на один slave
Минусы:
* Не реалтайм
* Инфраструктуры для бэкграунд подсчета (разработка, поддержка)
* Доп. данные для хранения

Tiendil
12.04.2019 14:32Не видел ничего тормазнутее Django ORM. Лет 5 нада это был полный адище с кучей клонирований query при конструировании сложного запроса, сейчас это исправили и стало просто медленно.
Если есть возможность использовать сырой SQL, используйте его. Он не сложнее ORM и это позволит исключить огромный непрозрачный слой абстракций.
Django ORM можно использовать для админок, простых и/или редких запросов и прототипов. Для остального лучше не надо.

veesot
12.04.2019 17:24Наверное джанго можно использовать не только для простых запросов.
К примеру с использованием поддержки JSON(B), кастомного Manager/переопределением objects + RawSQL можно делать уже вещи поинтересней. В джанге очень много основано на переопределении и сделав свой собственный QuerySet на основе стандартного, можно написать свою альтернативу взамен EAV.
А «сырой» SQL… да, может он и очевиден, но зачастую не так удобно поддерживать его после тех кто писал этот SQL.
007913
12.04.2019 17:05А не практичнее для сложных запросов использовать SQLalchemy? Ведь посути она может работать парралельно джанговскому ORM по тем-же моделькам той-же базы если речь идет о только выборках без блокировки?
ArsenAbakarov
12.04.2019 17:31ага, и создать гемор с поддержкой двух параллелных линий одних и тех же моделей
cvaynex Автор
12.04.2019 18:07А не практичнее для сложных запросов использовать SQLalchemy?
Соглашусь с ArsenAbakarov, чем меньше поддерживать технологий и описаний моделей, тем лучше.
Vasia529
А почему
RawSQL, а неdjango.contrib.postgres.fields.KeyTextTransform?cvaynex Автор
Не
KeyTextTransform, потому что очень мало про это документации, проглядели.Сейчас попробовал, и он не приводит правильно, типы, взрывается на
nullзначениях, даже если явно прописатьCastвDecimalField: