
Обычно для мониторинга и анализа работы Nginx используют коммерческие продукты или готовые open-source альтернативы, такие как Prometheus + Grafana. Это хороший вариант для мониторинга или real-time аналитики, но не слишком удобный для исторического анализа. На любом популярном ресурсе объем данных из логов nginx быстро растет, и для анализа большого объема данных логично использовать что-то более специализированное.
В этой статье я расскажу, как можно использовать Athena для анализа логов, взяв для примера Nginx, и покажу, как из этих данных собрать аналитический дэшборд, используя open-source фреймворк cube.js. Вот полная архитектура решения:

TL:DR;
Ссылка на готовый дэшборд.
Для сбора информации мы используем Fluentd, для процессинга — AWS Kinesis Data Firehose и AWS Glue, для хранения — AWS S3. С помощью этой связки можно хранить не только логи nginx, но и другие эвенты, а также логи других сервисов. Вы можете заменить некоторые части на аналогичные для вашего стэка, например, можно писать логи в kinesis напрямик из nginx, минуя fluentd, или использовать logstash для этого.
Собираем логи Nginx
По умолчанию, логи Nginx выглядят как-то так:
4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-up HTTP/2.0" 200 9168 "https://example.com/sign-in" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-in HTTP/2.0" 200 9168 "https://example.com/sign-up" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"Их можно распарсить, но гораздо проще поправить конфигурацию Nginx, чтобы он выдавал логи в JSON:
log_format json_combined escape=json '{ "created_at": "$msec", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"request": "$request", '
'"status": $status, '
'"bytes_sent": $bytes_sent, '
'"request_length": $request_length, '
'"request_time": $request_time, '
'"http_referrer": "$http_referer", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"http_user_agent": "$http_user_agent" }';
access_log /var/log/nginx/access.log json_combined;S3 для хранения
Чтобы хранить логи, мы будем использовать S3. Это позволяет хранить и анализировать логи в одном месте, так как Athena может работать с данными в S3 напрямую. Дальше в статье я расскажу, как правильно складывать и процессить логи, но для начала нам нужен чистый бакет в S3, в котором ничего больше храниться не будет. Стоит заранее подумать, в каком регионе вы создадите бакет, потому что Athena доступна не во всех регионах.
Создаем схему в консоли Athena
Создадим таблицу в Athena для логов. Она нужна и для записи, и для чтения, если вы планируете использовать Kinesis Firehose. Открываете консоль Athena и создаете таблицу:
CREATE EXTERNAL TABLE `kinesis_logs_nginx`(
`created_at` double,
`remote_addr` string,
`remote_user` string,
`request` string,
`status` int,
`bytes_sent` int,
`request_length` int,
`request_time` double,
`http_referrer` string,
`http_x_forwarded_for` string,
`http_user_agent` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION
's3://<YOUR-S3-BUCKET>'
TBLPROPERTIES ('has_encrypted_data'='false');Создаем Kinesis Firehose Stream
Kinesis Firehose запишет данные, полученные от Nginx, в S3 в выбранном формате, разбив по директориям в формате ГГГГ/ММ/ДД/ЧЧ. Это пригодится при чтении данных. Можно, конечно, писать напрямую в S3 из fluentd, но в этом случае придется писать JSON, а это неэффективно из-за большого размера файлов. К тому же, при использовании PrestoDB или Athena, JSON — самый медленный формат данных. Так что открываем консоль Kinesis Firehose, нажимаем "Create delivery stream", выбираем "direct PUT" в поле "delivery":
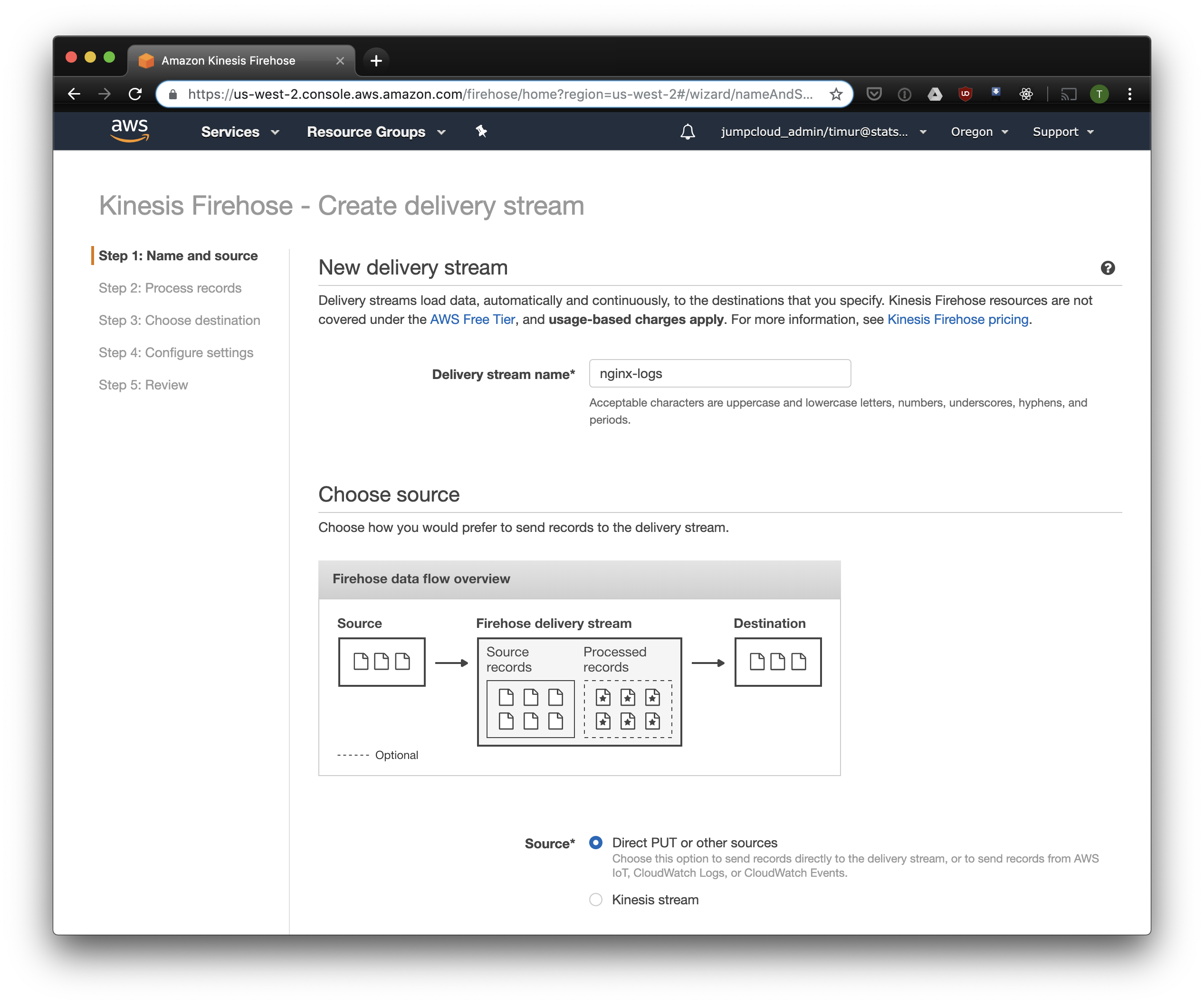
В следующей вкладке выбираем "Record format conversion" — "Enabled" и выбираем "Apache ORC" как формат для записи. Согласно исследованиям некоторого Owen O'Malley, это оптимальный формат для PrestoDB и Athena. В качестве схемы указываем таблицу, которую мы создали выше. Обратите внимание, что S3 location в kinesis можно указать любой, из таблицы используется только схема. Но если вы укажете другой S3 location, то прочитать из этой таблицы эти записи не получится.
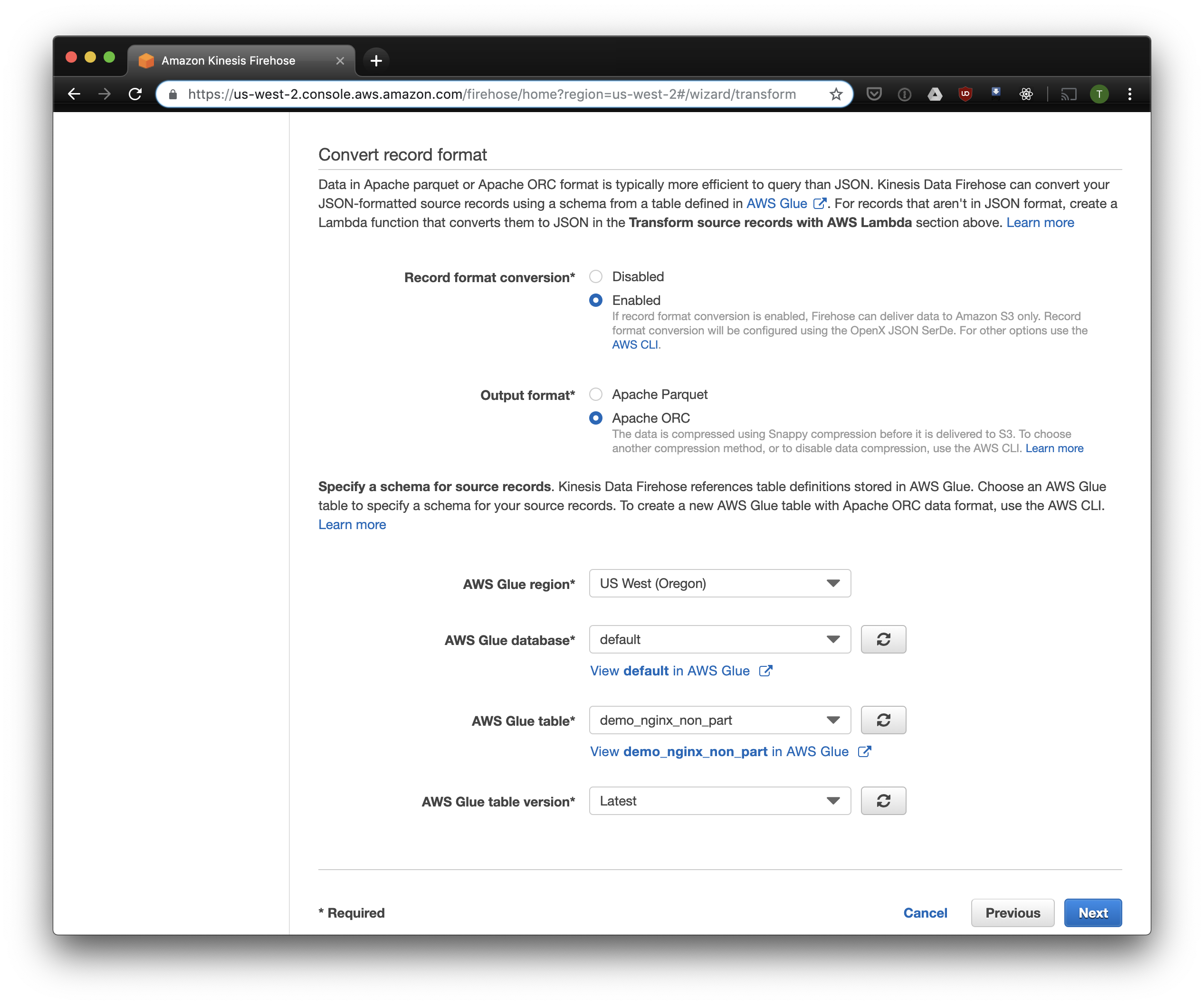
Выбираем S3 для хранения и бакет, который мы создали раньше. Aws Glue Crawler, про который я расскажу чуть позже, не умеет работать с префиксами в S3 бакете, так что его важно оставить пустым.

Остальные опции можно изменять в зависимости от вашей нагрузки, я обычно использую дефолтные. Обратите внимание, что сжатие S3 недоступно, но ORC использует собственное сжатие по умолчанию.
Fluentd
Теперь, когда у нас настроено хранение и получение логов, надо настроить отправку. Мы будем использовать Fluentd, потому что я люблю Ruby, но вы можете использовать Logstash или отправлять логи в kinesis напрямую. Fluentd сервер можно запустить несколькими способами, я расскажу про docker, потому что это просто и удобно.
Для начала, нам нужен файл конфигурации fluent.conf. Создайте его и добавьте source:
type forward
port 24224
bind 0.0.0.0
Теперь можно запустить Fluentd сервер. Если вам нужна более продвинутая конфигурация, на Docker Hub есть подробный гайд, в том числе и о том, как собрать свой образ.
$ docker run -d -p 24224:24224 -p 24224:24224/udp -v /data:/fluentd/log -v <PATH-TO-FLUENT-CONF>:/fluentd/etc fluentd -c /fluentd/etc/fluent.conf
fluent/fluentd:stableЭта конфигурация использует путь /fluentd/log для кэширования логов перед отправкой. Можно обойтись без этого, но тогда при перезапуске можно потерять все закэшированное непосильным трудом. Порт тоже можно использовать любой, 24224 — это дефолтный порт Fluentd.
Теперь, когда у нас есть запущенный Fluentd, мы можем отправить туда логи Nginx. Мы обычно запускаем Nginx в Docker-контейнере, и в этом случае у Docker есть нативный драйвер логов для Fluentd:
$ docker run --log-driver=fluentd --log-opt fluentd-address=<FLUENTD-SERVER-ADDRESS>--log-opt tag=\"{{.Name}}\" -v /some/content:/usr/share/nginx/html:ro -d nginxЕсли вы запускаете Nginx иначе, вы можете использовать лог-файлы, в Fluentd есть file tail plugin.
Добавим в конфигурацию Fluent парсинг логов, настроенный выше:
<filter YOUR-NGINX-TAG.*>
@type parser
key_name log
emit_invalid_record_to_error false
<parse>
@type json
</parse>
</filter>И отправку логов в Kinesis, используя kinesis firehose plugin:
<match YOUR-NGINX-TAG.*>
@type kinesis_firehose
region region
delivery_stream_name <YOUR-KINESIS-STREAM-NAME>
aws_key_id <YOUR-AWS-KEY-ID>
aws_sec_key <YOUR_AWS-SEC_KEY>
</match>Athena
Если вы все правильно настроили, то через некоторое время (по-умолчанию Kinesis записывает полученные данные раз в 10 минут) вы должны увидеть файлы логов в S3. В меню "monitoring" Kinesis Firehose можно увидеть, сколько данных записано в S3, а так же ошибки. Не забудьте дать доступ на запись в бакет S3 для роли Kinesis. Если Kinesis что-то не смог распарсить, он сложит ошибки в том же бакете.
Теперь можно посмотреть данные в Athena. Давайте найдем свежие запросы, на которые мы отдали ошибки:
SELECT * FROM "db_name"."table_name" WHERE status > 499 ORDER BY created_at DESC limit 10;Сканирование всех записей на каждый запрос
Теперь наши логи обработаны и сложены в S3 в ORC, сжаты и готовы к анализу. Kinesis Firehose даже разложил их по директориям на каждый час. Однако, пока таблица не партицирована, Athena будет загружать данные за все время на каждый запрос, за редким исключением. Это большая проблема по двум причинам:
- Объем данных постоянно растет, замедляя запросы;
- Счет за Athena выставляется в зависимости от объема просканированных данных, с минимумом 10 МБ за каждый запрос.
Чтобы исправить это, мы используем AWS Glue Crawler, который просканирует данные в S3 и запишет информацию о партициях в Glue Metastore. Это позволит нам использовать партиции как фильтр при запросах в Athena, и она будет сканировать только директории, указанные в запросе.
Настраиваем Amazon Glue Crawler
Amazon Glue Crawler сканирует все данные в S3 бакете и создает таблицы с партициями. Создайте Glue Crawler из консоли AWS Glue и добавьте бакет, в котором вы храните данные. Вы можете использовать один краулер для нескольких бакетов, в этом случае он создаст таблицы в указанной базе данных с названиями, совпадающими с названиями бакетов. Если вы планируете постоянно использовать эти данные, не забудьте настроить расписание запуска Crawler в соответствии с вашими потребностями. Мы используем один Crawler для всех таблиц, который запускается каждый час.
Партицированные таблицы
После первого запуска краулера в базе данных, указанной в настройках, должны появиться таблицы для каждого просканированного бакета. Откройте консоль Athena и найдите таблицу с логами Nginx. Давайте попробуем что-нибудь прочитать:
SELECT * FROM "default"."part_demo_kinesis_bucket"
WHERE(
partition_0 = '2019' AND
partition_1 = '04' AND
partition_2 = '08' AND
partition_3 = '06'
);Этот запрос выберет все записи, полученные с 6 до 7 утра 8 апреля 2019 года. Но насколько это эффективнее, чем просто читать из не-партицированной таблицы? Давайте узнаем и выберем те же записи, отфильтровав их по таймстемпу:
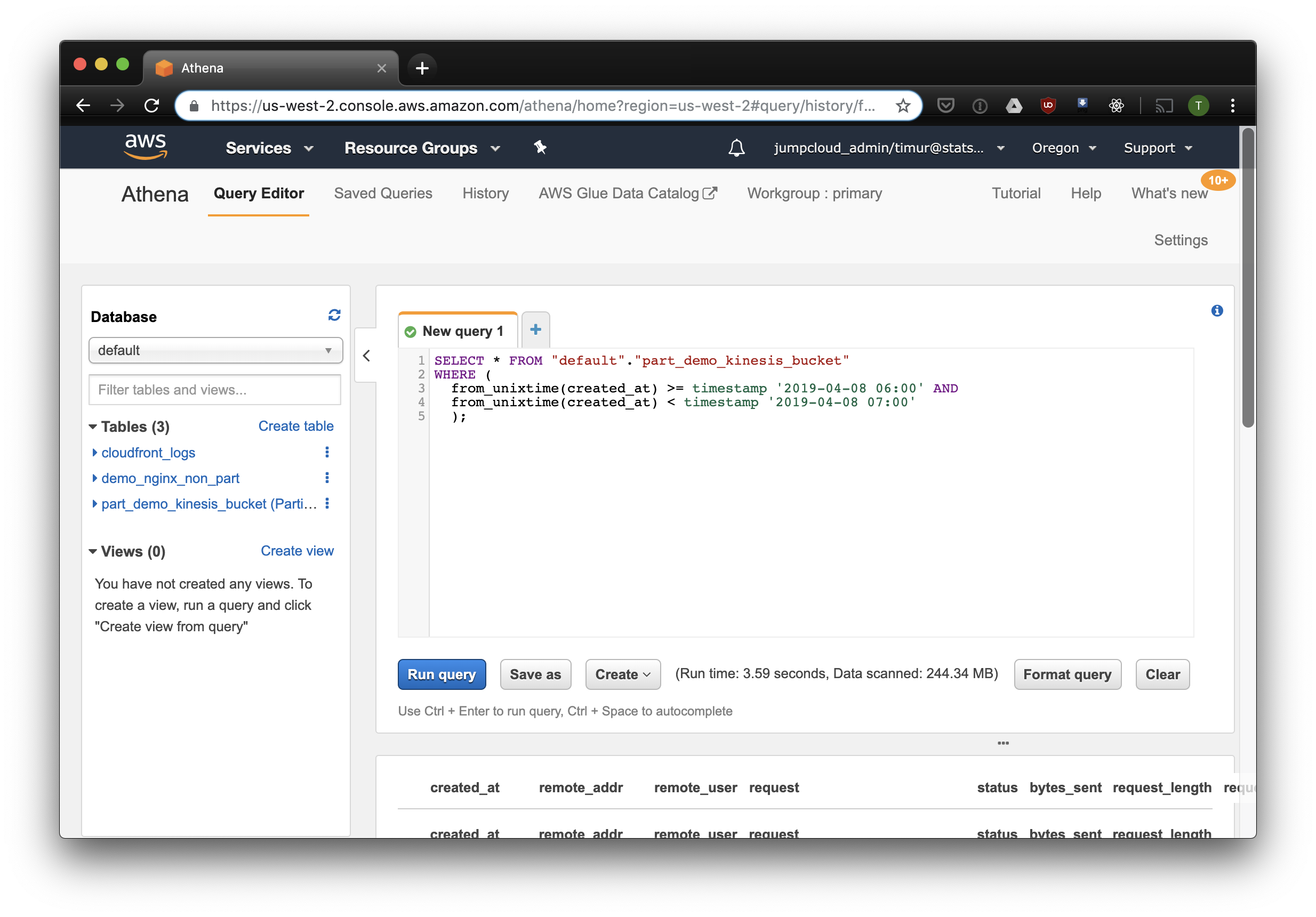
3.59 секунды и 244.34 мегабайт данных на датасете, в котором всего неделя логов. Попробуем фильтр по партициям:
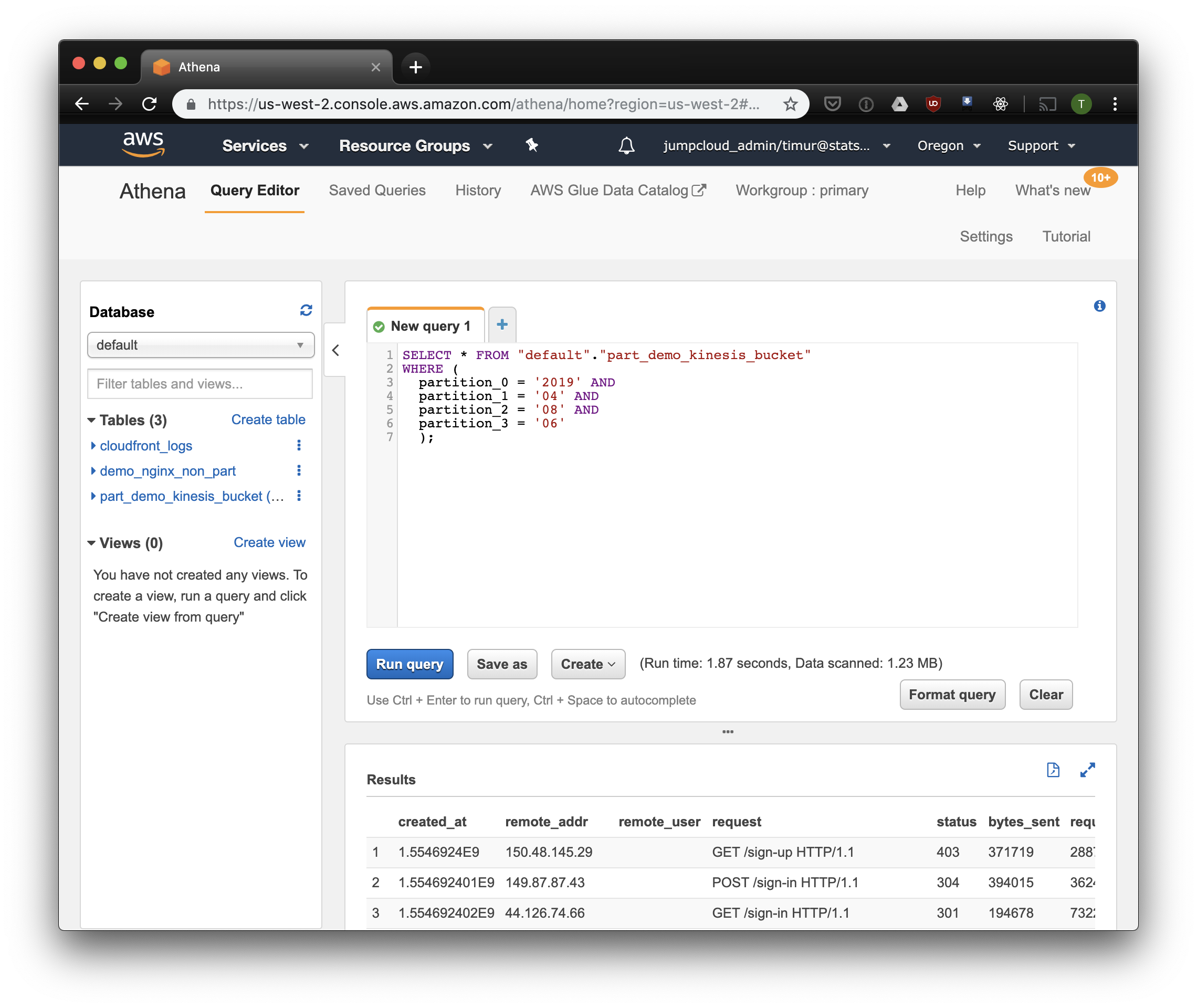
Чуть быстрее, но самое важное — всего 1.23 мегабайта данных! Это было бы гораздо дешевле, если бы не минимальные 10 мегабайт за запрос в прайсинге. Но все равно гораздо лучше, а на больших датасетах разница будет куда более впечатляющей.
Собираем дэшборд с помощью Cube.js
Чтобы собрать дэшборд, мы используем аналитический фреймворк Cube.js. У него довольно много функций, но нас интересуют две: возможность автоматически использовать фильтры по партициям и пре-агрегации данных. Он использует схему данных data schema, написанную на Javascript, чтобы сгененрировать SQL и исполнить запрос к базе данных. От нас требуется лишь указать, как использовать фильтр по партициям в схеме данных.
Создадим новое приложение Cube.js. Так как мы уже используем AWS-стэк, логично использовать Lambda для деплоя. Вы можете использовать express-шаблон для генерации, если планируете хостить Cube.js бэкенд в Heroku или Docker. В документации описаны другие способы хостинга.
$ npm install -g cubejs-cli
$ cubejs create nginx-log-analytics -t serverless -d athenaДля настройки доступа к базе данных в cube.js используются переменные окружения. Генератор создаст файл .env, в котором вы можете указать ваши ключи для Athena.
Теперь нам потребуется схема данных, в которой мы укажем, как именно хранятся наши логи. Там же можно указать, как считать метрики для дэшбордов.
В директории schema, создайте файл Logs.js. Вот пример модели данных для nginx:
const partitionFilter = (from, to) => `
date(from_iso8601_timestamp(${from})) <= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') AND
date(from_iso8601_timestamp(${to})) >= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d')
`
cube(`Logs`, {
sql: `
select * from part_demo_kinesis_bucket
WHERE ${FILTER_PARAMS.Logs.createdAt.filter(partitionFilter)}
`,
measures: {
count: {
type: `count`,
},
errorCount: {
type: `count`,
filters: [
{ sql: `${CUBE.isError} = 'Yes'` }
]
},
errorRate: {
type: `number`,
sql: `100.0 * ${errorCount} / ${count}`,
format: `percent`
}
},
dimensions: {
status: {
sql: `status`,
type: `number`
},
isError: {
type: `string`,
case: {
when: [{
sql: `${CUBE}.status >= 400`, label: `Yes`
}],
else: { label: `No` }
}
},
createdAt: {
sql: `from_unixtime(created_at)`,
type: `time`
}
}
});Здесь мы используем переменную FILTER_PARAMS, чтобы сгенерировать SQL запрос с фильтром по партициям.
Мы также задаем метрики и параметры, которые хотим отобразить на дэшборде, и указываем пре-агрегации. Cube.js создаст дополнительные таблицы с пре-агрегированными данными и будет автоматически обновлять данные по мере поступления. Это позволяет не только ускорить запросы, но и снизить стоимость использования Athena.
Добавим эту информацию в файл схемы данных:
preAggregations: {
main: {
type: `rollup`,
measureReferences: [count, errorCount],
dimensionReferences: [isError, status],
timeDimensionReference: createdAt,
granularity: `day`,
partitionGranularity: `month`,
refreshKey: {
sql: FILTER_PARAMS.Logs.createdAt.filter((from, to) =>
`select
CASE WHEN from_iso8601_timestamp(${to}) + interval '3' day > now()
THEN date_trunc('hour', now()) END`
)
}
}
}Мы указываем в этой модели, что необходимо пре-агрегировать данные для всех используемых метрик, и использовать партицирование по месяцам. Партицирование пре-агрегаций может значительно ускорить сбор и обновление данных.
Теперь мы можем собрать дэшборд!
Бэкенд Cube.js предоставляет REST API и набор клиентских библиотек для популярных фронтенд-фреймворков. Мы воспользуемся React-версией клиента для сборки дэшборда. Cube.js предоставляет лишь данные, так что нам потребуется библиотека для визуализаций — мне нравится recharts, но вы можете использовать любую.
Сервер Cube.js принимает запрос в JSON формате, в котором указаны необходимые метрики. Например, чтобы посчитать, сколько ошибок отдал Nginx по дням, нужно отправить такой запрос:
{
"measures": ["Logs.errorCount"],
"timeDimensions": [
{
"dimension": "Logs.createdAt",
"dateRange": ["2019-01-01", "2019-01-07"],
"granularity": "day"
}
]
}Установим Cube.js клиент и библиотеку React-компонет через NPM:
$ npm i --save @cubejs-client/core @cubejs-client/reactИмпортим компонетны cubejs и QueryRenderer, чтобы выгрузить данные, и собираем дэшборд:
import React from 'react';
import { LineChart, Line, XAxis, YAxis } from 'recharts';
import cubejs from '@cubejs-client/core';
import { QueryRenderer } from '@cubejs-client/react';
const cubejsApi = cubejs(
'YOUR-CUBEJS-API-TOKEN',
{ apiUrl: 'http://localhost:4000/cubejs-api/v1' },
);
export default () => {
return (
<QueryRenderer
query={{
measures: ['Logs.errorCount'],
timeDimensions: [{
dimension: 'Logs.createdAt',
dateRange: ['2019-01-01', '2019-01-07'],
granularity: 'day'
}]
}}
cubejsApi={cubejsApi}
render={({ resultSet }) => {
if (!resultSet) {
return 'Loading...';
}
return (
<LineChart data={resultSet.rawData()}>
<XAxis dataKey="Logs.createdAt"/>
<YAxis/>
<Line type="monotone" dataKey="Logs.errorCount" stroke="#8884d8"/>
</LineChart>
);
}}
/>
)
}Исходники дэшборда доступны на CodeSandbox.
Комментарии (4)

phikus
14.04.2019 12:21По сравнению с ELK/Graylog как-то очень всё сложно. Возможно за счёт узкой специализации оно быстрее/экономичнее эластика?
timurminulin Автор
14.04.2019 12:37Я ориентируюсь на блог Mark Litwintschik, если ему верить, то prestodb/athena и elastic в разных лигах играют. Но для нас самое важное преимущество Athena — именно per-request pricing, как в Google BigQuery. Хостить/арендовать что-то свое после этого не хочется.
Почему сложно? Таблица в SQL + конфиг fluentd + бакет в S3, если по шагам пройтись, можно минут в 10 уложиться. Дэшборд собрать сложнее конечно, но тут nginx как пример, мы и эвентовую аналитику собираем, и другие логи, а такой кастом ни одно готовое решение не вытягивает
random1st
Вопрос — а почему Nginx? Не проще ли использовать ALB/NLB и забирать логи сразу на S3? Странно как-то, так сильно залоченый на AWS технический стек и вдруг nginx и S3. Почему не ELK опять же? На какой объем данных такая стрельба по воробьям из пушек? Athena опять же крутая штука, как и Firehose но вот если посчитать TCO, как то не очень весело становится.
timurminulin Автор
Мы все логи собираем так, не только nginx + продуктовую аналитику так же считаем. Nginx — самый простой пример, с которым сталкиваются +- все. По ELK — очень нравится per-query pricing, потому что хостить свой стэк с таким же перформансом у нас получалось заметно дороже. А объемы данных IRL там совсем другие естественно, я просто для примера недельный датасет сгенерил.