
В Zendesk мы используем Python для создания продуктов с машинным обучением. В приложениях с использованием машинного обучения одними из самых распространенных проблем, с которыми мы столкнулись, являются утечка памяти и всплески. Код на Python обычно выполняется в контейнерах с помощью фреймворков распределенной обработки, таких как Hadoop, Spark и AWS Batch. Каждому контейнеру выделяется фиксированный объем памяти. Как только выполнение кода превысит заданное ограничение памяти, контейнер прекратит свою работу из-за ошибок, возникающих по причине нехватки памяти.

Быстро исправить проблему можно выделением еще большего количества памяти. Тем не менее, это может привести к растрачиванию ресурсов и повлиять на стабильность работы приложений из-за непредсказуемых всплесков памяти. Причины утечки памяти могут быть следующими:
- Затяжное хранение больших объектов, которые не удаляются;
- Циклические ссылки в коде;
- Базовые библиотеки/расширения на С, приводящие к утечке памяти;
Полезной практикой считается профилирование использования памяти приложениями для получения лучшего понимания об эффективности использования пространства кода и используемых пакетов.
В этой статье рассматриваются следующие аспекты:
- Профилирование использования памяти приложений с течением времени;
- Как проверить использование памяти в определенной части программы;
- Советы по отладке ошибок, вызванных проблемами с памятью.
Профилирование памяти с течением времени
Вы можете взглянуть на переменное использование памяти в течение выполнения программы на Python, используя пакет memory-profiler.
# install the required packages
pip install memory_profiler
pip install matplotlib
# run the profiler to record the memory usage
# sample 0.1s by defaut
mprof run --include-children python fantastic_model_building_code.py
# plot the recorded memory usage
mprof plot --output memory-profile.png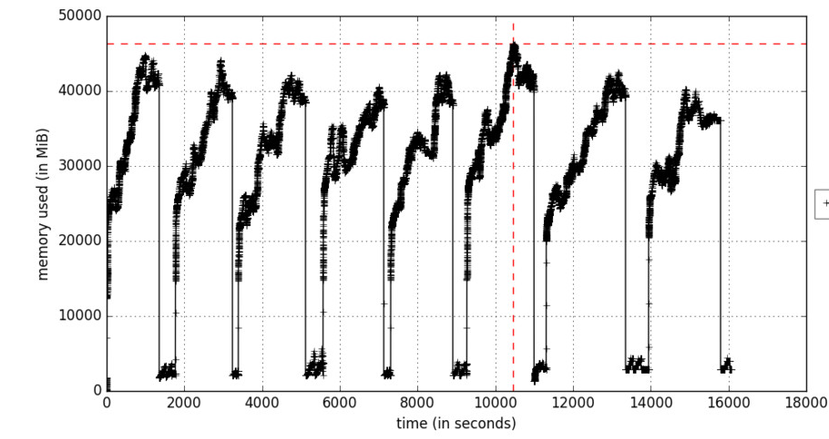
Рисунок А. Профилирование памяти, как функция от времени
Параметр include-children будет включать использование памяти любыми дочерними процессами, порожденными родительскими процессами. Рисунок А отражает итерационный процесс обучения, который вызывает увеличения памяти в циклах в те моменты, когда обрабатываются пакеты обучающих данных. Объекты удаляются во время сборки мусора.
Если использование памяти постоянно возрастает, это считается потенциальной угрозой утечки памяти. Здесь показан пример кода, отражающий это:
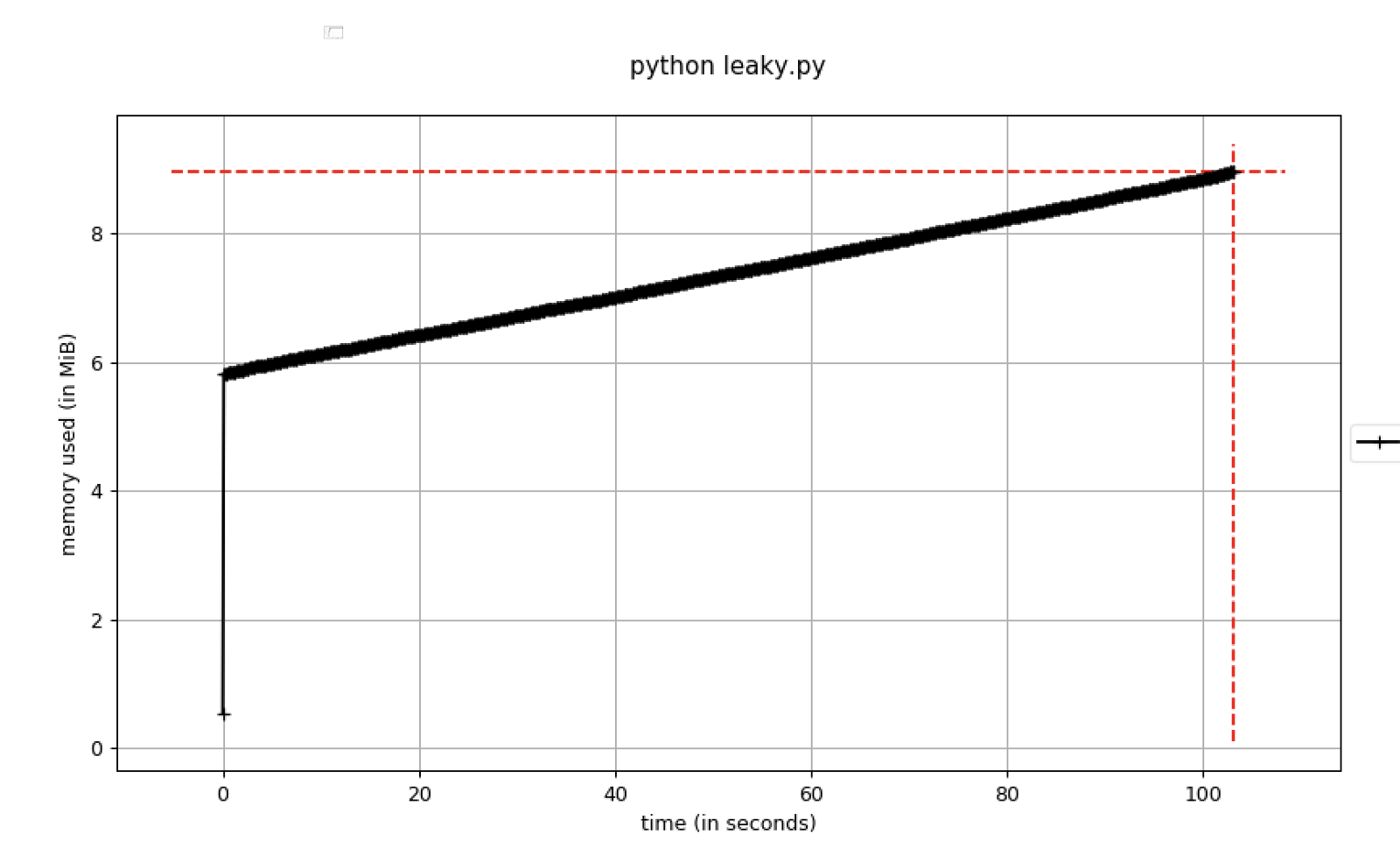
Рисунок В. Использование памяти, увеличивающееся со временем
Следует устанавливать точки останова в отладчике, как только использование памяти превышает определенный порог. Для этого можно пользоваться параметром pdb-mmem, который удобен во время устранения неполадок.
Дамп памяти в определенный момент времени
Полезно оценивать заранее ожидаемое количество больших объектов в программе и то, следует ли их дублировать и/или преобразовывать в различные форматы.
Для дальнейшего анализа объектов в памяти можно создавать дамп-кучу в определенных строках программы, используя muppy.
# install muppy
pip install pympler
# Add to leaky code within python_script_being_profiled.py
from pympler import muppy, summary
all_objects = muppy.get_objects()
sum1 = summary.summarize(all_objects)
# Prints out a summary of the large objects
summary.print_(sum1)
# Get references to certain types of objects such as dataframe
dataframes = [ao for ao in all_objects if isinstance(ao, pd.DataFrame)]
for d in dataframes:
print d.columns.values
print len(d)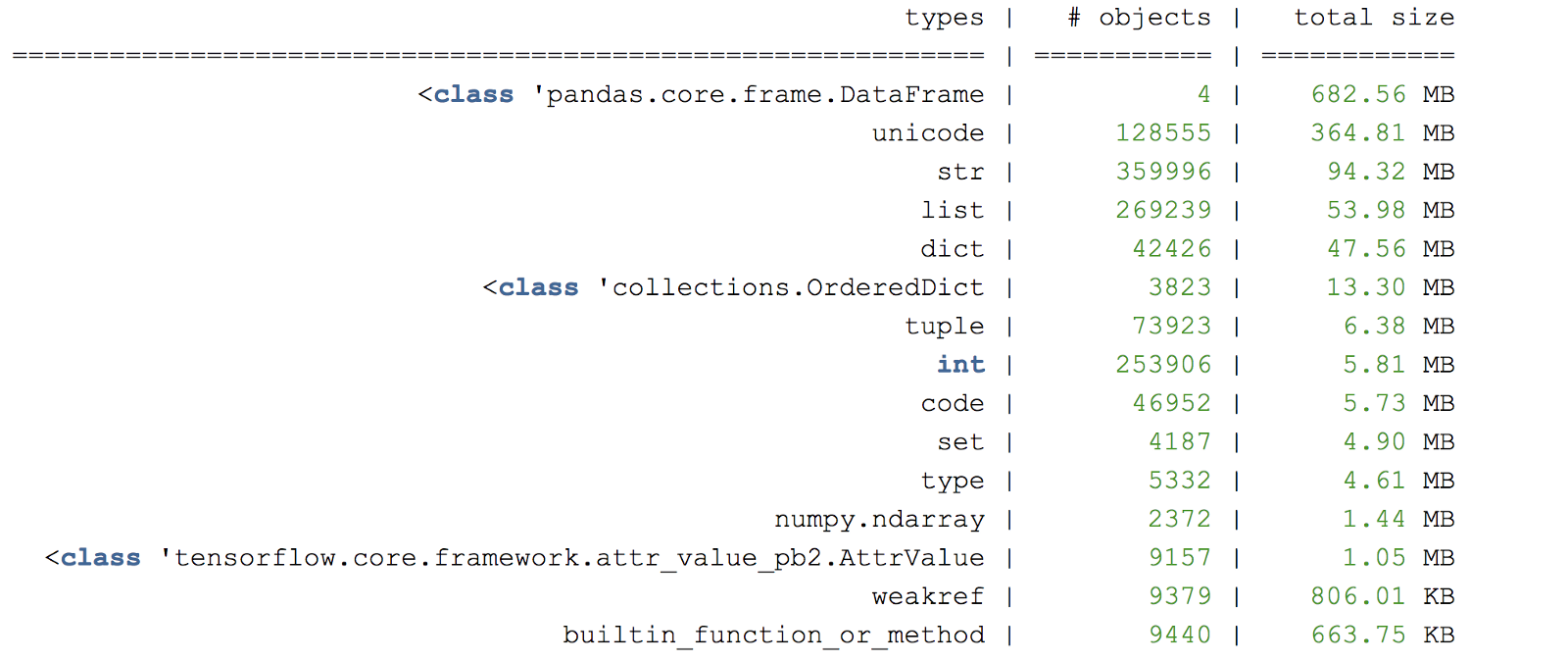
Рисунок С. Пример сводки дампа-кучи памяти
Другая полезная библиотека для профилирования памяти – это objgraph, которая позволяет генерировать графики для проверки происхождения объектов.
Полезные указатели
Полезным подходом является создание небольшого «тестового примера», который запускает соответствующий код, вызывающий утечку памяти. Рассмотрите возможность использования подмножества случайно выбранных данных, если полноценные входные данные будут заведомо долго обрабатываться.
Выполнение задач с большой загрузкой памяти в отдельном процессе
Python не обязательно освобождает память сразу же для операционной системы. Чтобы убедиться в том, что память была освобождена, после выполнения фрагмента кода необходимо запустить отдельный процесс. Больше информации о сборщике мусора в Python вы сможете узнать здесь.
Отладчик может добавлять ссылки на объекты
Если используется такой отладчик точек останова, как pdb, все созданные объекты, на которые вручную ссылается отладчик, будут оставаться в памяти. Это может создать ложное ощущение утечки памяти, поскольку объекты не удаляются своевременно.
Остерегайтесь пакетов, которые могут вызывать утечку памяти
Некоторые библиотеки в Python потенциально могут вызвать утечку, например
pandas имеет несколько известных проблем утечки памяти.Приятной охоты на утечки!
Полезные ссылки:
docs.python.org/3/c-api/memory.html
docs.python.org/3/library/debug.html
Пишите в комментарии была ли эта статья полезной для вас. А тех, кто хочет подробнее узнать о нашем курсе, приглашаем на день открытых дверей, который пройдёт уже 22 апреля.
Комментарии (12)


armid
19.04.2019 14:27Чисто из любопытства захотел пройти тест у вас на сайте. Сначала имя введи, потом фамилию, потом имейл, потом номер телефона. Забросил эту идею.

MaxRokatansky Автор
19.04.2019 14:42Входное тестирование подразумевает Ваше желание пройти обучение и создано для проверки базовых знаний, чтобы понять потянет ли человек программу. То есть человек проходящий тест является потенциальным кандидатом в студенты, именно поэтому нам нужно знать как Вас зовут и как можно с Вами связаться. Никаким назойливым спамом мы не занимаемся).
armid
19.04.2019 14:51+1Странная у вас логика. Прохождение мной теста, подразумевает желание пройти тест. Не нужно додумывать за меня и манипулировать. Прохождение теста не равно желанию обучаться у вас. А может после вашего теста, я не захочу к вам идти. По вашей логике, скиньте мне пожалуйста номер телефона вашего директора у меня к нему потенциальный разговор. Никаким назойливым спамом я не занимаюсь.
roryorangepants
Это уже третий или четвертый раз, когда я читаю статью Отуса в хабе «Машинное обучение», и в ней, разумеется, нет ни слова про машинное обучение. И перевод как обычно не очень хороший.
MaxRokatansky Автор
В самом начале публикации автор говорит о проблемах, с которыми ему довелось столкнуться в приложениях с использованием машинного обучения, поэтому был указан данный хаб. Спасибо, за комментарий, учтем на будущее и будем размещать в хабе «машинное обучение» более технические материалы.
iroln
Вы с другой планеты что ли? Надо размещать материалы не "более технические", а конкретно про машинное обучение.
MaxRokatansky Автор
Именно это я и имел ввиду. Еще раз благодарю за Ваше замечание)
iroln
Про memory_profiler можно было дополнить перевод и подробнее расписать, про декоратор profile, про то как его надо использовать и т. п. А так статья получилась очень поверхностная и не раскрывает многих деталей профилирования и поиска утечек памяти.
immaculate
Более того, ничего не рассказано о том, как искать утечки памяти, кроме общих слов.
Два раза в жизни я сталкивался с утечками памяти в приложениях на Python. Первый раз это был развесистый сайт на Django. Объем кода очень большой. Недельные поиски не увенчались успехом, было перепробовано все. Проблема была «решена» добавлением параметра, который рестартит воркеры после нескольких сотен запросов.
Второй раз это был не очень большой демон на Python. Потребление памяти росло очень быстро. Практически переписал его два раза, проверил каждую строчку, что нигде не создается циклических ссылок. Использовал все существующие инструменты для поиска утечек памяти. Так и не смог найти.
Так что толковая статья на эту тему не помешала бы. В теории оно все просто. На практике, приходится смотреть в дамп памяти, в котором находятся миллионы примитивных объектов, типа tuple, str, и понять, какие из них должны были быть освобождены, и откуда они вообще взялись, бывает очень сложно.
В обоих случаях подозрение падало на расширения на C. Но данные расширения используются многими проектами, и, насколько я понимаю, ни один из инструментов для поиска утечек в Python, не помогает, если память течет в расширении на C.
willyd
Тоже искал утечки, и читал эту статью. На практике все намного сложнее.
lgorSL
Я нашёл забавный способ — форкать и производить действия в дочеренем процессе.
(минутка машинного обучения) У меня утекала память где-то в keras, причём не обычная, а та что на GPU. Скрипт одну за другой обучал много различных сеточек, и в какой-то момент всё падало из-за нехватки свободной памяти на видеокарте. Рабочим решением оказалось форкать процесс, обучать сеточку и сохранять результаты в дочернем, а в родительском ждать совершения дочернего и снова так делать для каждой следующей сетки. У меня были некоторые сомнения относительно того, как это будет сочетаться с использованием cuda (keras импортировалась раньше, чем я форкал процесс, и tensorflow сразу занимала почти всю память на GPU), но это всё нормально работало.