

Компания Variti разрабатывает защиту от ботов и DDoS-атак, а также проводит стресс- и нагрузочное тестирование. На конференции HighLoad++ 2018 мы рассказывали, как обезопасить ресурсы от различного вида атак. Если коротко: изолируйте части системы, используйте облачные сервисы и CDN и регулярно обновляйтесь. Но без специализированных компаний с защитой вы все равно не справитесь :)
Перед прочтением текста можете ознакомиться с короткими тезисами на сайте конференции.
А если вы не любите читать или просто хотите посмотреть видео, запись нашего доклада ниже под спойлером.
Видеозапись доклада
Многие компании уже умеют делать нагрузочные тестирования, но не все делают стресс-тестирования. Некоторые наши заказчики думают, что их сайт неуязвим, потому что у них есть highload система, и она хорошо защищает от атак. Мы же показываем, что это не совсем правда.
Разумеется, перед проведением тестов мы получаем разрешение от заказчика, с подписью и печатью, и с нашей помощью DDoS-атаку сделать ни на кого нельзя. Тестирование проводится в выбранное заказчиком время, когда посещаемость его ресурса минимальна, а проблемы с доступом не отразятся на клиентах. Кроме того, поскольку в процессе тестирования всегда может пойти что-то не так, у нас есть постоянный контакт с заказчиком. Это позволяет не только сообщать о достигнутых результатах, но и что-то менять в ходе тестирования. При завершении тестирования мы всегда составляем отчет, в котором указываем на обнаруженные недостатки и даем рекомендации по устранению слабых мест сайта.
Как мы работаем
При проведении тестирования мы эмулируем ботнет. Поскольку мы работаем с клиентами, которые не располагаются в наших сетях, то для того, чтобы тест не закончился на первой же минуте из-за срабатывания лимитов или защиты, мы подаем нагрузку не с одного IP, а с собственной подсети. Плюс, для создания значительной нагрузки у нас есть свой достаточно мощный тестовый сервер.
Постулаты
Много — не значит хорошо
Чем меньшей нагрузкой мы сможем довести ресурс до отказа, тем лучше. Если получится сделать так, что сайт прекратит функционировать от одного запроса в секунду, или даже от одного запроса в минуту, это прекрасно. Потому что по закону подлости пользователи или злоумышленники случайно попадут именно в эту уязвимость.
Частичный отказ лучше, чем полный
Мы всегда советуем делать системы гетерогенными. Причем разделять их стоит именно на физическом уровне, а не только контейниризацией. В случае физического разделения, даже если на сайте что-то откажет, то велика вероятность, что он не прекратит работу полностью, и у пользователей сохранится доступ хотя бы к части функционала.
Правильная архитектура — основа устойчивости
Отказоустойчивость ресурса и его способность выдерживать атаки и нагрузки должны закладываться на этапе проектирования, фактически на этапе рисования первых блок-схем в блокноте. Потому что если закрадываются фатальные ошибки, исправить их в дальнейшем можно, но очень сложно.
Хорошим должен быть не только код, но и конфиг
Многие думают, что хорошая команда разработки это гарантия отказоустойчивости сервиса. Хорошая команда разработки действительно необходима, но должна быть еще и хорошая эксплуатация, хороший DevOps. То есть нужны специалисты, которые правильно сконфигурируют Linux и сеть, правильно напишут конфиги в nginx, настроят лимиты и прочее. В противном случае ресурс будет хорошо работать только на тесте, а в продакшене в какой-то момент все сломается.
Отличия нагрузочного и стресс-тестирования
Нагрузочное тестирование позволяет выявить пределы функционирования системы. Стресс-тестирование направлено на поиск слабых мест системы и используется для того, чтобы эту систему сломать и посмотреть, как она будет вести себя в процессе отказа тех или иных частей. При этом при характер нагрузки обычно остается неизвестным для заказчика до начала стресс-тестирования.
Отличительные черты L7 атак
Виды нагрузки мы обычно делим на нагрузки на уровне L7 и L3&4. L7 — это нагрузка на уровне приложения, чаще всего под ней понимают только HTTP, мы же подразумеваем любую нагрузку на уровне протокола TCP.
У L7 атак есть определенные отличительные черты. Во-первых, они приходят непосредственно в приложение, то есть отразить их сетевыми средствами вряд ли получится. Такие атаки задействуют логику, и за счет этого очень эффективно и при небольшом трафике потребляют ЦПУ, память, диск, базу данных и прочие ресурсы.
HTTP Flood
В случае любой атаки нагрузку проще создать, чем обработать, и в случае с L7 это тоже верно. Трафик атаки не всегда просто отличить от легитимного, и чаще всего это удается сделать по частотности, но если все спланировано грамотно, то по логам понять, где атака, а где легитимные запросы, невозможно.
В качестве первого примера рассмотрим атаку HTTP Flood. Из графика видно, что обычно такие атаки очень мощные, в примере ниже пиковое число запросов превосходило 600 тысяч в минуту.

HTTP Flood — это самый простой способ создать нагрузку. Обычно для него берется какой-то инструмент нагрузочного тестирования, например, ApacheBench, и задаются запрос и цель. При таком простом подходе велика вероятность нарваться на кеширование сервера, но его легко обойти. Например, добавив случайные строки в запрос, что вынудит сервер постоянно отдавать свежую страницу.
Также не стоит забывать про user-agent в процессе создания нагрузки. Многие user-agent популярных инструментов тестирования фильтруются системными администраторами, и в таком случае нагрузка может просто не дойти до бэкенда. Значительно улучшить результат можно, вставляя в запрос более или менее валидный заголовок из браузера.
При всей простоте атаки HTTP Flood имеют и свои недостатки. Во-первых, для создания нагрузки требуются большие мощности. Во-вторых, такие атаки очень легко обнаруживаются, особенно если идут с одного адреса. В итоге, запросы сразу же начинают фильтроваться либо системными администраторами, либо даже на уровне провайдера.
Что искать
Чтобы снизить количество запросов в секунду и при этом не потерять в эффективности, нужно проявить немного фантазии и исследовать сайт. Так, нагружать можно не только канал или сервер, но и отдельные части приложения, например, базы данных или файловые системы. Также можно поискать места на сайте, которые делают большие вычисления: калькуляторы, страницы с подбором продуктов и прочее. Наконец, часто бывает, что на сайте есть некий php-скрипт, который генерирует страницу из нескольких сотен тысяч строк. Такой скрипт тоже в значительной степени нагружает сервер и может стать мишенью для атаки.
Где искать
Когда мы сканируем ресурс перед проведением тестирования, то в первую очередь смотрим, конечно, на сам сайт. Мы ищем всевозможные поля ввода, тяжелые файлы — в общем все, что может создать проблемы ресурсу и замедляет его работу. Здесь помогают банальные средства разработки в Google Chrome и Firefox, показывающие время ответов страницы.
Также мы сканируем поддомены. Например, есть некий онлайн-магазин, abc.com, и у него есть поддомен admin.abc.com. Скорее всего, это админка с авторизацией, но если в нее пустить нагрузку, то она может создать проблемы для основного ресурса.
У сайта может быть поддомен api.abc.com. Скорее всего, это ресурс для мобильных приложений. Приложение можно найти в App Store или Google Play, поставить специальную точку доступа, препарировать API и зарегистрировать тестовые аккаунты. Проблема в том, что зачастую люди думают, что все, что защищено авторизацией, неуязвимо для атак на отказ в обслуживании. Якобы авторизация это лучшая CAPTCHA, но это не так. Сделать 10-20 тестовых аккаунтов просто, а создав их, мы получаем доступ к сложному и неприкрытому функционалу.
Естественно, мы смотрим на историю, на robots.txt и WebArchive, ViewDNS, ищем старые версии ресурса. Иногда бывает так, что разработчики выкатили, скажем, mail2.yandex.net, а старая версия, mail.yandex.net, осталась. Этот mail.yandex.net перестает поддерживаться, на него не отводятся ресурсы разработки, но он продолжает потреблять базу данных. Соответственно с помощью старой версии можно эффективно задействовать ресурсы бэкенда и всего того, что стоит за версткой. Конечно, так происходит не всегда, но с подобным мы сталкиваемся все равно довольно часто.
Естественно, мы препарируем все параметры запроса, структуру cookie. Можно, скажем, запулить в JSON массив внутри cookie какое-то значение, создать большую вложенность и заставить ресурс работать неразумно долго.
Нагрузка в поиск
Первое, что приходит в голову при исследовании сайта, это нагрузить базу данных, поскольку поиск есть почти у всех, и почти у всех он, к сожалению, защищен плохо. Почему-то разработчики не уделяют поиску достаточное внимание. Но тут есть одна рекомендация — не стоит делать однотипные запросы, потому что можно столкнуться с кешированием, как и в случае с HTTP flood.
Делать случайные запросы в базу данных тоже не всегда эффективно. Гораздо лучше создать список ключевых слов, которые относятся к поиску. Если возвращаться к примеру интернет-магазина: допустим, сайт торгует автомобильной резиной и позволяет задавать радиус шин, тип машины и прочие параметры. Соответственно комбинации релевантных слов заставят базу данных работать в намного более сложных условиях.
Кроме того, стоит использовать пагинацию: поиску гораздо сложнее отдать предпоследнюю страницу выдачи, чем первую. То есть с помощью пагинации можно немного разнообразить нагрузку.
На примере ниже показываем нагрузку в поиск. Видно, что с первой же секунды теста на скорости десять запросов в секунду сайт лег и не отвечал.
Если поиска нет?
Если поиска нет, то это не значит, что сайт не содержит в себе других уязвимых полей ввода. Таким полем может оказаться авторизация. Сейчас разработчики любят делать сложные хеши, чтобы защитить базу логинов от атаки по радужным таблицам. Это хорошо, но такие хеши потребляют большие ресурсы CPU. Большой поток ложных авторизаций приводит к отказу процессора, и как следствие, на выходе сайт перестает работать.
Присутствие на сайте всевозможных форм для комментариев и обратной связи — это повод отправить туда очень большие тексты или просто создать массовый флуд. Порой сайты принимают вложенные файлы, в том числе в формате gzip. В таком случае, мы берем файл размером 1Тб, с помощью gzip сжимаем его до нескольких байт или килобайт и отправляем на сайт. Дальше он разархивируется и получается очень интересный эффект.
Rest API
Хотелось бы уделить немного внимания таким популярным нынче сервисам, как Rest API. Защитить Rest API гораздо сложнее, чем обычный сайт. Для Rest API не работают даже банальные способы защиты от перебора паролей и прочей нелигитимной активности.
Rest API очень просто сломать, потому что он обращается непосредственно к базе данных. При этом вывод такого сервиса из строя влечет за собой достаточно тяжелые последствия для бизнеса. Дело в том, что на Rest API обычно завязан не только главный сайт, но и мобильное приложение, какие-то внутренние бизнес-ресурсы. И если это все падает, то эффект гораздо сильнее, чем в случае с выходом из строя простого сайта.
Нагрузка на тяжелый контент
Если нам предлагают тестировать какое-то обычное одностраничное приложение, лендинг, сайт-визитку, у которых нет сложного функционала, мы ищем тяжелый контент. Например, большие картинки, которые отдает сервер, бинарные файлы, pdf-документацию, — мы пробуем все это выкачивать. Такие тесты хорошо грузят файловую систему и забивают каналы, и поэтому эффективны. То есть даже если вы не положите сервер, скачивая большой файл на небольших скоростях, то вы просто забьете канал целевого сервера и тогда наступит отказ в обслуживании.
На примере такого теста видно, что на скорости 30 RPS сайт перестал отвечать, либо выдавал 500-е ошибки сервера.

Не стоит забывать и про настройку серверов. Часто можно встретить, что человек купил виртуалку, поставил туда Apache, настроил все по умолчанию, расположил php-приложение, и ниже можно увидеть результат.

Здесь нагрузка шла в корень и составляла всего 10 RPS. Мы подождали 5 минут, и сервер упал. До конца, правда, неизвестно, почему он упал, но есть предположение, что он просто объелся памяти, и поэтому перестал отвечать.
Wave based
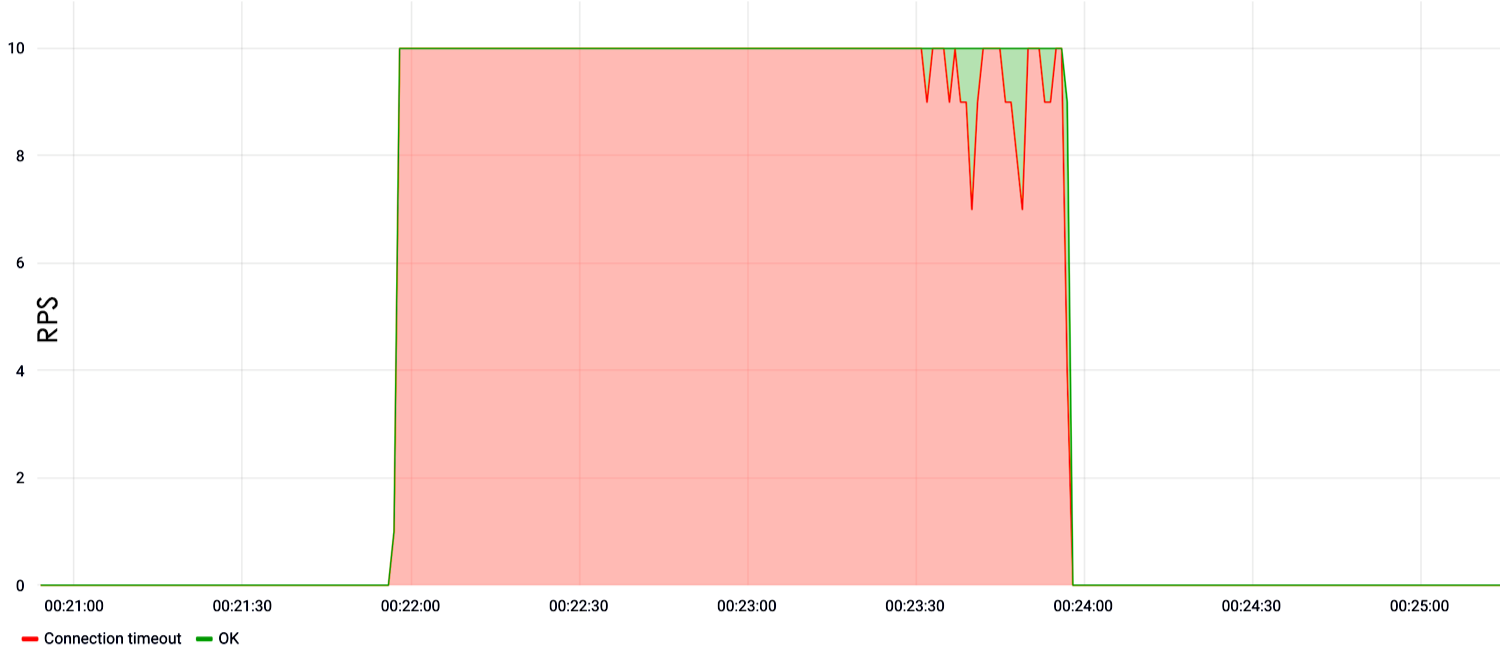
В последние год-два достаточно популярными стали волновые атаки. Это связано с тем, что многие организации покупают те или иные железки для защиты от DDoS, которые требуют определенного времени накопления статистики для начала фильтрации атаки. То есть они не фильтруют атаку в первые 30-40 секунд, потому что накапливают данные и обучаются. Соответственно в эти 30-40 секунд на сайт можно запустить столько, что ресурс будет лежать длительное время, пока не разгребутся все запросы.
В случае с атакой ниже был интервал 10 минут, после чего прилетела новая, видоизмененная порция атаки.

То есть защита обучилась, запустила фильтрацию, но прилетела новая, совершенно другая порция атаки, и защита снова начала обучение. Фактически, фильтрация перестает работать, защита становится неэффективной, и сайт недоступен.
Для волновых атак характерны очень высокие значения на пике, она может достигать ста тысяч или миллиона запросов в секунду, в случае с L7. Если говорить про L3&4, то там могут быть сотни гигабит трафика, или, соответственно, сотни mpps, если считать в пакетах.
Проблема же таких атак в синхронизации. Атаки идут с ботнета, и для того, чтобы создать очень большой разовый пик, требуется высокая степень синхронизации. И эта координация не всегда получается: иногда на выходе получается какой-то параболический пик, который выглядит довольно жалко.
Не HTTP единым
Помимо HTTP на уровне L7, мы любим эксплуатировать и другие протоколы. Как правило, у обычного веб-сайта, тем более у обычного хостинга, наружу торчат почтовые протоколы и MySQL. Почтовые протоколы подвержены нагрузкам в меньшей степени, чем базы данных, но их тоже можно нагружать достаточно эффективно и на выходе получать перегруженный CPU на сервере.
Мы вполне реально с помощью уязвимости SSH 2016 года добивались успеха. Сейчас эта уязвимость почти у всех поправлена, но это не значит, что в SSH нельзя подавать нагрузку. Можно. Просто подается огромная нагрузка авторизаций, SSH съедает почти весь CPU на сервере и дальше веб-сайт складывается уже от одного-двух запросов в секунду.
Соответственно эти один-два запроса по логам никак нельзя отличить от легитимной нагрузки.
Остаются актуальными и множество соединений, которые мы открываем в серверах. Раньше этим грешил Apache, сейчас этим фактически грешит и nginx, поскольку он часто настраивается по дефолту. Количество соединений, которые nginx может держать открытыми, лимитировано, соответственно мы открываем это количество соединений, новое соединение nginx уже не принимает, и на выходе сайт не работает.
Наш тестовый кластер обладает достаточным CPU, чтобы атаковать SSL handshake. В принципе, как показывает практика, ботнеты тоже иногда любят это делать. С одной стороны, понятно, что без SSL не обойтись, потому что выдача Google, ранжирование, безопасность. С другой стороны, у SSL, к сожалению, есть проблема с CPU.
L3&4
Когда мы говорим об атаке на уровнях L3&4, мы говорим, как правило, об атаке на уровне канала. Такая нагрузка почти всегда отличима от легитимной, если это не атака SYN-flood. Проблема SYN-flood атак для средств защиты заключается в большом объеме. Максимальная величина L3&4 составляла 1,5-2 Тбит/с. Такой трафик очень сложно обработать даже крупным компаниям, включая Oracle и Google.
SYN и SYN-ACK — это пакеты, которые используются при установке соединения. Поэтому SYN-flood и сложно отличить от легитимной нагрузки: непонятно, это SYN, который пришел на установку соединения, или часть флуда.
UDP-flood
Обычно у злоумышленников нет тех мощностей, которые есть у нас, поэтому для организации атак может использоваться амплификация. То есть злоумышленник сканирует интернет и находит либо уязвимые, либо неправильно настроенные серверы, которые, например, в ответ на один SYN-пакет, отвечают тремя SYN-ACK. Подделывая адрес источника с адреса целевого сервера, можно с помощью одного пакета увеличить мощность, скажем, в три раза, и перенаправить трафик на жертву.

Проблема амплификаций заключается в их сложном обнаружении. Из последних примеров можно привести нашумевший случай с уязвимым memcached. Плюс, сейчас появилось множество устройств IoT, IP-камер, которые тоже в основном настроены по дефолту, и по дефолту они настроены неправильно, поэтому через такие устройства злоумышленники и делают атаки чаще всего.

Непростой SYN-flood
SYN-flood, наверное, самый интересный вид из всех атак с точки зрения разработчика. Проблема в том, что зачастую системные администраторы используют для защиты блокировку по IP. Причем блокировкой по IP страдают не только сисадмины, которые действуют по скриптам, но и, к сожалению, некоторые системы защиты, которые покупаются за большие деньги.
Такой метод может обернуться катастрофой, ведь если злоумышленники подменят IP-адреса, то компания заблокирует собственную подсеть. Когда Firewall заблокирует собственный кластер, на выходе будут рушиться внешние взаимодействия, и ресурс сломается.
Причем добиться блокировки собственной сети несложно. Если в офисе клиента есть WI-Fi-сеть, или если работоспособность ресурсов измеряется с помощью различных мониторингов, то мы берем IP-адрес этой системы мониторинга или офисного Wi-Fi клиента, и используем его в качестве источника. На выходе ресурс вроде бы доступен, но целевые IP-адреса заблокированы. Так, может быть заблокирована Wi-Fi-сеть конференции HighLoad, где презентуется новый продукт компании, — и это влечет определенные бизнес- и экономические издержки.
Во время тестирования мы не можем использовать амплификацию через memcached какими-то внешними ресурсами, потому что есть договоренности по подаче трафика только в разрешенные IP-адреса. Соответственно мы используем амплификацию через SYN и SYN-ACK, когда на отправку одного SYN система отвечает двумя-тремя SYN-ACK, и на выходе атака умножается в два-три раза.
Инструменты
Один из основных инструментов, которым мы пользуемся для нагрузки на уровне L7, — это Yandex-tank. В частности, в качестве пушки используется фантом, плюс есть несколько скриптов для генерации патронов и для анализа результатов.
Для анализа сетевого трафика используется Tcpdump, для анализа сервера — Nmap. Для создания нагрузки на уровне L3&4 используется OpenSSL и немного собственной магии с библиотекой DPDK. DPDK — это библиотека от Intel, которая позволяет работать с сетевым интерфейсом, минуя стек Linux, и тем самым повышает эффективность. Естественно, DPDK мы используем не только на уровне L3&4, но и на на уровне L7, потому что она позволяет создавать очень высокий поток нагрузки, в пределах нескольких миллионов запросов в секунду с одной машины.
Также мы используем определенные трафик-генераторы и специальные инструменты, которые пишем под специфические тесты. Если вспомнить уязвимость под SSH, то приведенным выше набором она не может быть проэскпулатирована. Если мы атакуем почтовый протокол, то берем почтовые утилиты или просто пишем на них скрипты.
Выводы
В качестве итогов хотелось бы сказать:
- Помимо классического нагрузочного тестирования нужно обязательно проводить и стресс-тестирование. У нас есть реальный пример, когда субподрядчик партнера провел только нагрузочное тестирование. Оно показало, что ресурс выдерживает штатную нагрузку. Но затем появилась нештатная нагрузка, посетители сайта стали немного иначе использовать ресурс, — и на выходе субподрядчик лег. Таким образом, искать уязвимости стоит, даже если вы уже защищены от DDoS-атак.
- Необходимо изолировать одни части системы от других. Если у вас есть поиск, его надо вынести на отдельные машины, то есть даже не в докер. Потому что если откажет поиск или авторизация, то хотя бы что-то продолжит работать. В случае с интернет-магазином пользователи продолжат находить товары по каталогу, переходить с агрегатора, покупать, если они уже авторизованы, или авторизовываться через OAuth2.
- Не стоит пренебрегать всевозможными облачными сервисами.
- Используйте CDN не только для оптимизации сетевых задержек, но и как средство защиты от атак на исчерпание канала и просто флуда в статику.
- Необходимо использовать специализированные сервисы защиты. От L3&4 атак на уровне канала сами вы не защититесь, потому что у вас, скорее всего, просто нет достаточного канала. От L7 атак вы тоже вряд ли отобьетесь, поскольку они бывают очень большими. Плюс, поиск маленьких атак это все-таки прерогатива специальных сервисов, специальных алгоритмов.
- Регулярно обновляйтесь. Это касается не только ядра, но и SSH daemon, особенно если они у вас открыты наружу. В принципе, обновлять надо вообще все, потому что отслеживать те или иные уязвимости самостоятельно вы вряд ли сможете.
Комментарии (6)

Brain_Overload
19.04.2019 17:31был я на данном докладе на H++)
Отличия нагрузочного и стресс-тестирования
почему проводите данное разделение? стерсс-тестировани просто один из подвидов нагрузочных тестов, на равне с тем же тестированием на стабильность, объем и тд.
У нас есть реальный пример, когда субподрядчик партнера провел только нагрузочное тестирование.
видимо имеется ввиду тестирование производительности или стабильности?
Чем меньшей нагрузкой мы сможем довести ресурс до отказа, тем лучше. Если получится сделать так, что сайт прекратит функционировать от одного запроса в секунду
не совсем понятен смысл сказанного.
если сервис падает от 1rps, то его надо брать и выбрасывать на свалку.
barabanof
19.04.2019 17:50Мы проводим такое разделение потому, что в основном сейчас нагрузочное тестирование воспринимается исключительно как тестирование на максимальное количество условных пользователей. Т.е. производится эмуляция поведения пользователей на сайте.
видимо имеется ввиду тестирование производительности или стабильности?
Имеется ввиду как раз тестирование с помощью одного из распространенных бесплатных веб-инструментов.
не совсем понятен смысл сказанного.
если сервис падает от 1rps, то его надо брать и выбрасывать на свалку.
А если 10? а 20? Очевидно, что если стрелять в корень — то отказ будет на одном потоке, если спамить комментариями — совсем на другом. Речь идет о поиске запроса (или их комплекса), который максимально нагружает ресурс.Brain_Overload
19.04.2019 18:58Мы проводим такое разделение потому, что в основном сейчас нагрузочное тестирование воспринимается исключительно как тестирование на максимальное количество условных пользователей. Т.е. производится эмуляция поведения пользователей на сайте.
мысль понятна, увы но такое действительно встречается часто, у людей нет понимания, что НТ это не взять условный гатлинг и потыкать, а сервис, который предусматривает определенный минимальный набор кейсов, таких как поиск максимума, тест надежности, интеграционные тесты и конечно стресс.
Имеется ввиду как раз тестирование с помощью одного из распространенных бесплатных веб-инструментов.
вопрос не в инструменте, а в кейсе тестирования выполненого субподрядчиком. PS. вопрос выверенности линейки инструмента тестирования, лучше не поднимать, это надолго)))
А если 10? а 20? Очевидно, что если стрелять в корень — то отказ будет на одном потоке, если спамить комментариями — совсем на другом.
все конечно от нефункциональных требований зависит, мне просто сложно представить требования на 1rps)))
Речь идет о поиске запроса (или их комплекса), который максимально нагружает ресурс.
без анализа НТ бесполезно.
tuxi
Ой как мне близка эта тема. С другой стороны баррикад :)
Потому что систему писали люди, которые не удосужились разобраться в предметной области. И сделали подбор по той же технологии, как и на сайтах торгующих айфонами.Я бы еще добавил бы тесты на тему «персистенс сессий». Некоторые аппликейшен сервера чувствительны к такого рода атакам.
Блокировка по айпи, это же какой то каменный век. Мало того, я видел атаки, которые как раз и имели перед собой цель, заставить заблокировать большие диапазоны адресов.
Вопрос: механизм обнаружения хонипотов у вас реализован? Не было случаев, когда вместо блокировок, тестируемая система, накопив аналитику, редиректерила ваших ботов на уровне l7 на внешние ссылки размером под многие сотни мегабайт? :)
barabanof
Собственно мы и сами с другой стороны баррикад.
По поводу хонипотов — нет, не сталкивались. Но это не будет проблемой, так как мы специально ограничиваем атаку, и перенаправить её редиректами на внешние ресурсы нельзя. А со своих начать отдавать сотни мегабайт — не самая хорошая идея, так как наши каналы заведомо толще. Или, в случае с реальной атакой, каналы ботнета.
tuxi
Редирект только 1 раз делал, какой то «студент» пришел парсить, не получилось, разозлился и стал долбить нас уж очень настойчиво через прокси сеть.
В обычном случае, обнаружив бота, мы начинаем ему вместо динамики, статику правдоподобную отдавать, и не пускаем на уровень бекенда, отдаем на фронтсервере. Не самое лучшее решение, но в комплексе (бюджет, людские ресурсы, типовые атаки) — работает.