

На протяжении многих лет Netcracker является вендором продуктов для телеком-операторов, и в то же время выступает как интегратор всего комплекса операторского ПО. В этой работе неизбежно возникает задача синхронизации и координации большого количества версий продуктов и решений, в разных комбинациях, от разных разработчиков и с разным функционалом. Многие операторы сознательно избегают зависимости от одного поставщика, создавая зоопарк продуктов разных вендоров, так что в достаточно сложном сценарии может быть задействовано до пары десятков разрозненных систем и процессов.
Чтобы было понятно, о чем речь, представьте себе, что раз в неделю вам нужно реализовать процесс с применением набора разных инструментов и технологий: PL/SQL процедуры, bash-скрипты, Perl-скрипты, запуски отдельных приложений и обращение к daemon процессам. Это всё «благодаря» разнородности ИТ-ландшафта оператора. При этом для каждой процедуры будут свои параметры запуска, контроля выхода, а также набор возможных ошибок, влияющих на последующее исполнение сценария. Каждый такой запуск превращается в серьезную задачу, требующую нескольких часов или дней работы высококвалифицированных ИТ-инженеров – их обучение может занимать до трех лет, прежде чем их можно будет выпускать на продуктив телеком-оператора с десятками миллионов пользователей.
Понятно, что эти задачи нужно автоматизировать. Поэтому мы решили взять лучшее от BPMN-Оркестратора, планировщика процессов, системы мониторинга и обогатить данный набор умением разбирать логи и ошибки. Разумеется, были рассмотрены лучшие представители своего вида для каждого типа систем. Но подходящей под специфику отрасли квитэссенции найдено не было. Следовательно — делаем сами.
Если коротко о том, что делаем: разнородные процедуры упаковываются в «задачи» (tasks) с типовым набором интерфейсов и свойствами; определенная последовательность задач формирует «процесс» (например, биллинг-процесс для начислений за услуги связи). Далее по расписанию или вручную каждый процесс запускает свою последовательность процедур с необходимыми параметрами, контролирует исполнение, оценивает результаты вложенных задач, принимает решение о выборе сценариев. Взаимосвязь между задачами внутри процесса основана на стандартной логике BPMN, при этом в сервере управления мы заложили возможность вручную остановить исполнение процесса, поставить его на паузу, выйти из текущего сценария с сохранением уже обработанных данных. Управление процессами реализовано через веб-интерфейс с мониторингом в реальном времени, с оценкой аномалий, контролем определенных SLA для каждого процесса.
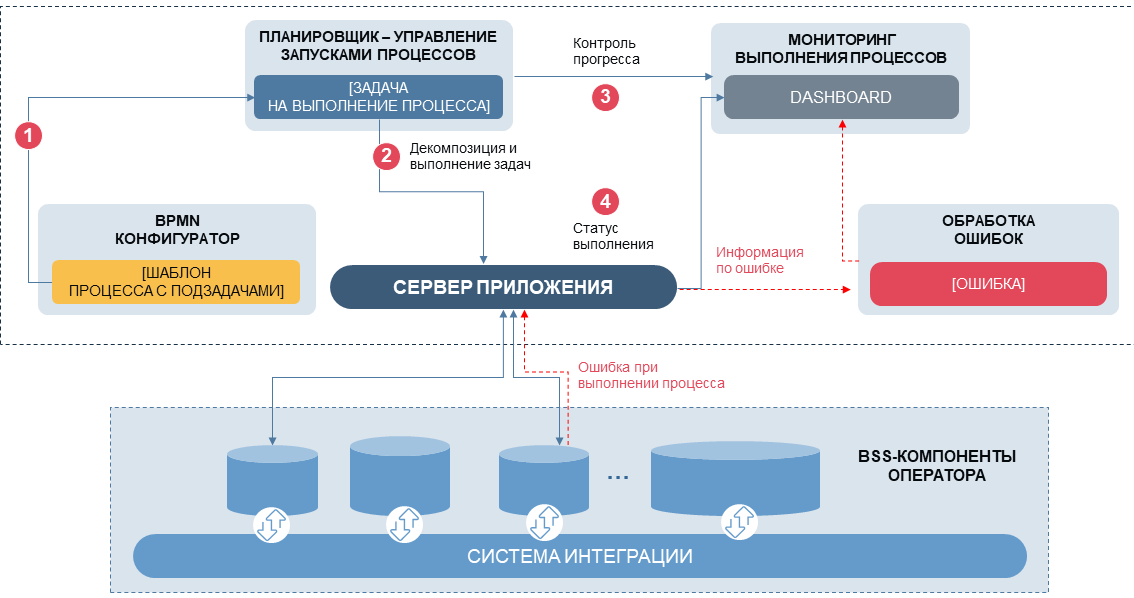
Теперь наш «менеджер процессов» может работать в полуавтоматическом режиме, но он практически не снижает нагрузки на ИТ-инженеров – при взаимодействии двух и более сложных систем многократно возрастает вариативность аномалий в процессах и основные усилия приходятся именно на обработку ошибок. Поэтому на следующем этапе мы должны были принять решение:
- Как мы хотим автоматизировать обработку ошибок?
- Как корректировать сценарии на основе анализа аномалий?
- Вообще, насколько человек должен вмешиваться в работу такой системы, в каких объемах и в каких местах?
Замечу еще раз, что делать все это нужно в реальном времени на продуктиве mission-critical системы, обслуживающей десятки и сотни тысяч транзакций в секунду. И вот здесь предстояло решать задачу по нахождению и устранению неисправностей (так называемый troubleshooting) в условиях:
- периодических обновлений в процессах
- развивающейся операторской базы
- изменений в наборе телеком-услуг
Да, и еще одной немаловажное условие, которое нам следовало соблюсти – не навредить. Или говоря языком официальных документов – сократить временные и трудовые издержки в процессах эксплуатации ИТ-систем телеком-провайдера.
Возник вопрос – в какой пропорции смешать автоматическую обработку ошибок и участие экспертов в подобном troubleshooting. Далее поговорим об опциях.
ИИ
Поскольку мы живем в эпоху вечного хайпа, мы решили сделать разработку базе искусственного интеллекта – чтобы этот интеллект распознавал ошибки и аномалии, предсказывал сбои и тут же их исправлял. Крупные компании и небольшие стартапы уже создают такие и даже внедряют похожие решения. Основная область их применения: операции по построению, обслуживанию и поддержке ИТ-инфраструктуры. Называется это словом AIOps – Aritificial Intelligence (for IT) Operations, а самое популярное buzzword – NoOps, т.е., полностью автоматизированные ИТ-операции.
Обучение системы будет непростым, поскольку набор исторических данных ограничен, строить точную копию продуктива дорого, а обучать примерами (active learning) – слишком долго и, в нашем случае, неточно. Можно попробовать метод bootstrap aggregating – смоделировать конечный набор сценариев для известных и предполагаемых случаев и создать на его базе дерево принятия решений, к примеру, Classification and Regression Tree, но это тоже довольно затратный метод. Но если мы все это сделаем, мы заставим программу думать за нас и сэкономим кучу полезных ресурсов (что в переводе с менеджерского на человеческий означает «уволим самых надоедливых сисадминов»).
Минусы:
- Из-за сложности систем и их взаимодействия практически невозможно создать и обучить некий «коробочный» вариант такого решения для всех возможных ситуаций. Для каждого нового проекта это будет свой отдельный «курс обучения», с узнаванием специфичных ошибок, аномалий и подходящими способами их решения.
- Мы проектируем не массовое решение, а внутреннее, на ограниченное число внедрений (потому что в мире совсем немного операторов такого масштаба). Легко может получиться так, что будет экномически эффективнее предложить нашим клиентам соответствующий «человеский» аутсорс для решения таких вопросов.
- Возможно наши клиенты скорее смирятся с расходами на новых высококвалифицированных инженеров, чем примут риски от передачи поддержки продуктива на откуп искуственному интеллекту. Мягко говоря, это может вызвать некоторые опасения.
Не ИИ мне мозги
Раз без вмешательства человека не получается обойтись, мы пошли старомодным путем. Помните, когда-то мы считали, что «машина должна работать, а человек – думать»? Мы это переформулировали: «программа должна решать известные проблемы, а инженер – неизвестные».
Мы создали алгоритмическую систему, организованную в концепции reinforced learning, но с четкой логикой. Обучение системы происходит в узком и контролируемом объеме, правила прозрачно сохраняются, их можно отредактировать, расширить, конкретизировать, отключить и т.д. Такая разработка ненамного сложней, чем простая «полуавтоматизация». Для эксплуатации по-прежнему нужен квалифицированный инженер, однако его ресурсы используются исключительно для идентификации и решения новых проблем. Если мы будем твердо придерживаться принципа «человек не должен решать известные проблемы», можно предположить, что через некоторое время запас неизвестных проблем начнет иссякать, а функциональность разрабатываемой системы приблизится к ИИ для данной конкретной области применения.
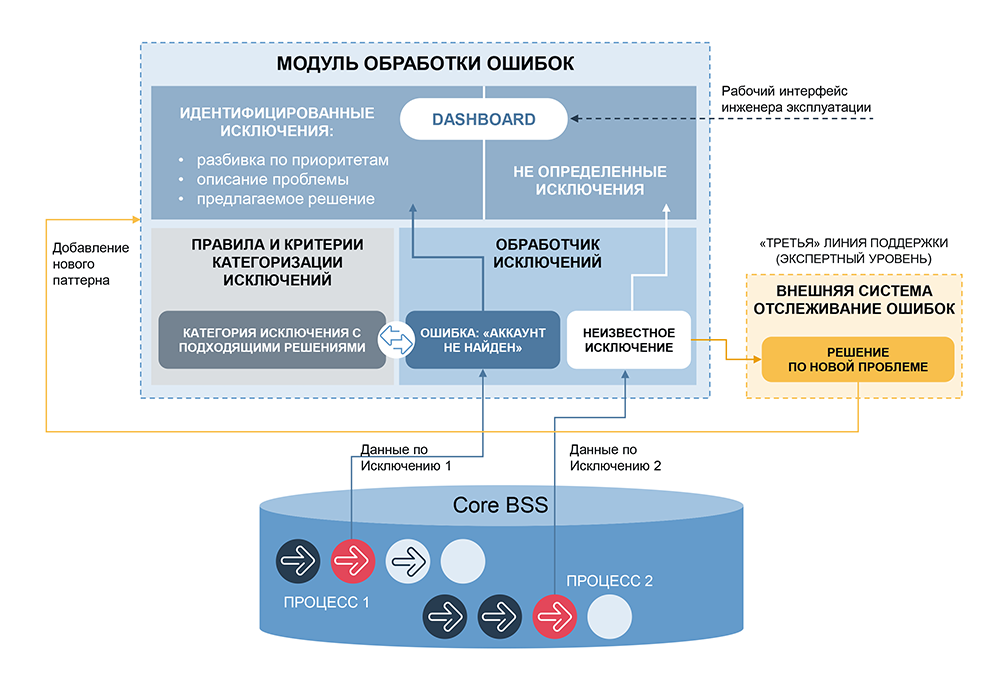
Самая важная часть такой системы – категоризация, повторная идентификация аномалий. В нашей компании уже есть подобная система – Order Tracker, используется для мониторинга бизнес-процессов сотового оператора по управлению заказами. Order Tracker анализирует сотни событий в секунду, выявляет аномалии как в отдельных рядах, так и в комбинациях событий, дает возможность пользователю группировать их, устанавливать максимальные и минимальные значения, определять ошибки разного уровня критичности, и предлагать действия по разрешению проблем. Система работает давно, много граблей уже успешно пройдено, поэтому мы ее взяли как инструмент для категоризации.
Теперь нужно было автоматизировать решение проблем. В отличие от управления заказами, где часто требуется вмешательство операторов (например, когда нужно привлечь отдел финансов, клиентскую службы и пр.), у нас есть возможность автоматически решать значительную часть инцидентов и есть готовый инструмент для проектирования этих решений – сценарии из готовых блоков, которые можно дополнять, расширять логику, включать дополнительные проверки и связывать с каждой распознанной категорией ошибок.
Что может пойти не так?
Всё!
Система мониторинга заказов обычно не требует принятия решений и исправления в реальном времени, а любая аномалия влияет на ограниченное количество клиентов, от одного до нескольких сотен. Мы же пытаемся внедрить автоматическую обработку ошибок на процессах, которые затрагивают сотни тысяч и миллионы абонентов и требуют решения в реальном времени или в течение нескольких часов. Это огромный риск для любого оператора, с которым мы работаем, а, значит, и для нас, для нашей репутации.
Нам пришлось существенно повысить гибкость сценариев, внедрить систему управления версиями, добавить сущность «экземляр сценария», т.е., для каждого сценария теперь можно создать множество подклассов с определенными комбинациями параметров, порогами значений, дополнительными проверками и т.д. Пришлось повысить гибкость многих задач, введя дополнительные проверки входных и выходных параметров.
Другое направление развития – повышение гранулярности категорий анализируемых событий и создание мета-категорий, т.е. комбинаций разных событий, определенных категоризатором. Мы добавил оценку последовательности аномалий и совпадения разных аномалий по времени. Система становилась все сложнее, но по-прежнему сохраняла четкую логику – для любой пары «категория аномалии – выбранный сценарий» по-прежнему сохраняются причинно-следственные связи.
По многим комбинациям мы уже получили достоверные и надежные результаты и выпустили в продуктив. Ошибки, поиск и исправление которых раньше занимало часы, теперь решаются в автоматическом режиме. По другим типам аномалий мы еще еще продолжаем тестирование: где-то на тестовых данных, где-то в режиме ручной проверки и подтверждения выбранного сценария.
И тут оказалось…
Мы только недавно поняли, что от этих работ получили результат, который совершенно не ожидали на старте – высокоэффективный инструмент для реверс-инжениринга чужих решений, в том числе, тех, для которых у нас нет ни поддержки разработчиков, ни даже внятной документации. Непреднамеренно был проведён так называемый «business process discovery». Мы научились на практике анализировать логику работы приложений, выявлять внутренние ошибки и проблемы интеграции с другими системами. Теперь мы можем не просто оркестрировать чужие приложения – мы можем разрабатывать фиксы для них, улучшать интеграцию, а самое ценное – предлагать наши продукты на замену существующего легаси.
На следующем этапе мы хотим попробовать реализовать наше решение в виде комплексного продукта для интеграционных тестирований, который будет автоматически выявлять ошибки и аномалии, учиться на лету, предоставлять инструменты для симптоматического исправления и для поиска и анализа проблем в логике приложений. У этого решения эффективность будет не меньше, чем у модных AIOps и NoOps, при этом мы сохраним прозранчую и управляемую логику принятия решений. Так что если вы через пару лет встретите на рынке такое решение от компании Netcracker, имейте в виду – все это когда-то начиналось с bash-скриптов…