
Предположим, вы оцениваете проект в 1 неделю. Предположим, есть три одинаково вероятных результата: либо он займёт 1/2 недели, либо 1 неделю, либо 2 недели. Медианный результат фактически такой же, как и оценка: 1 неделя, но среднее значение (aka average, aka expected value) составляет 7/6 = 1,17 недель. Оценка фактически откалибрована (беспристрастна) для медианы (которая равна 1), но не для среднего.
Разумной моделью для «фактора инфляции» (фактическое время, разделённое на оценочное время) будет что-то вроде логнормального распределения. Если оценка равна одной неделе, то смоделируем реальный результат как случайную величину, распределённую в соответствии с логнормальным распределением около одной недели. В такой ситуации медиана распределения составляет ровно одну неделю, но среднее значение намного больше:

Если взять логарифм коэффициента инфляции, мы получим простое нормальное распределение с центром около 0. Это предполагает медианный коэффициент инфляции 1x, и, как вы, надеюсь, помните, log(1) = 0. Однако в различных задачах могут быть разные неопределённости вокруг 0. Мы можем моделировать их путём изменения параметра ?, который соответствует стандартному отклонению нормального распределения:
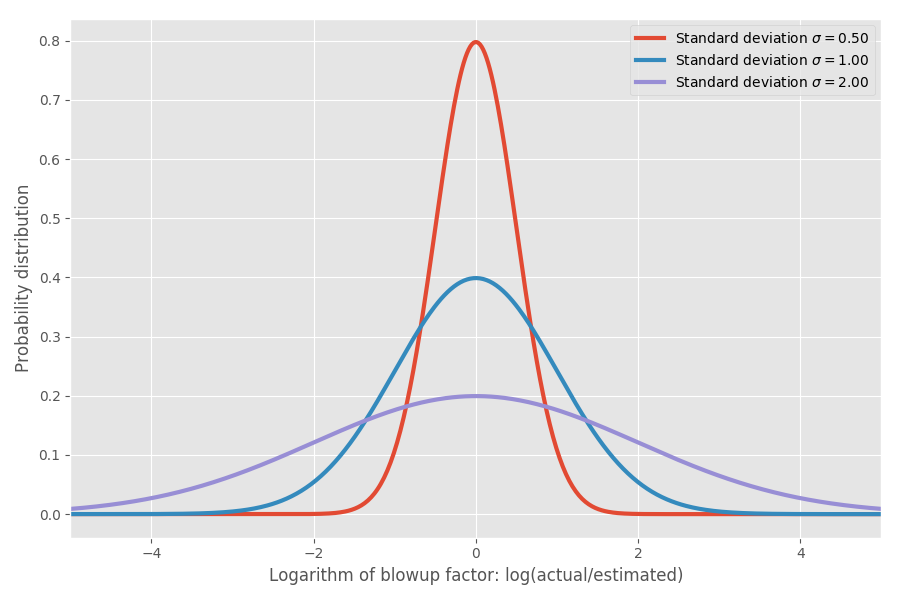
Просто чтобы показать реальные цифры: когда log(actual / estimated) = 1, то коэффициент инфляции exp(1) = e = 2.72. Одинаково вероятно то, что проект растянется в exp(2) = 7.4 раз, и то, что он завершится в exp (-2) = 0.14, т. е. в 14% от предполагаемого времени. Интуитивно причина, по которой среднее значение настолько велико, заключается в том, что задачи, которые выполняются быстрее, чем предполагалось, не могут компенсировать задачи, которые занимают гораздо больше времени, чем предполагалось. Мы ограничены 0, но не ограничены в другом направлении.
Это просто модель? Ещё бы! Но скоро я доберусь до реальных данных и на некоторых эмпирических данных покажу, что на самом деле она достаточно хорошо соответствует реальности.
Оценка сроков разработки программного обеспечения
Пока всё хорошо, но давайте действительно попробуем понять, что это значит с точки зрения оценки сроков разработки программного обеспечения. Предположим, мы смотрим на план из 20 различных программных проектов и пытаемся оценить: сколько времени потребуется, чтобы завершить их все.
Вот где среднее становится решающим. Средние складываются, а медианы нет. Поэтому, если мы хотим получить представление о том, сколько времени потребуется для завершения суммы N проектов, нужно смотреть на среднее значение. Допустим, у нас три разных проекта с одинаковыми ? = 1:
| Медиана | Среднее | 99% | |
|---|---|---|---|
| Задача A | 1.00 | 1.65 | 10.24 |
| Задача B | 1.00 | 1.65 | 10.24 |
| Задача C | 1.00 | 1.65 | 10.24 |
| SUM | 3.98 | 4.95 | 18.85 |
Обратите внимание, что средние складываются и 4,95 = 1,65*3, но другие столбцы этого не делают.
Теперь сложим три проекта с разными сигмами:
| Медиана | Среднее | 99% | |
|---|---|---|---|
| Задача A (? = 0.5) | 1.00 | 1.13 | 3.20 |
| Задача B (? = 1) | 1.00 | 1.65 | 10.24 |
| Задача C (? = 2) | 1.00 | 7.39 | 104.87 |
| SUM | 4.00 | 10.18 | 107.99 |
Средние по-прежнему складываются, но реальность даже близко не соответствует наивной оценке в 3 недели, которую вы могли предположить. Обратите внимание, что сильно неопределённый проект с ?=2 доминирует над остальными по среднему времени завершения. А для 99-го процентиля он не просто доминирует, а буквально поглощает все остальные. Можем привести пример побольше.:
| Медиана | Среднее | 99% | |
|---|---|---|---|
| Задача A (? = 0.5) | 1.00 | 1.13 | 3.20 |
| Задача B (? = 0.5) | 1.00 | 1.13 | 3.20 |
| Задача C (? = 0.5) | 1.00 | 1.13 | 3.20 |
| Задача D (? = 1) | 1.00 | 1.65 | 10.24 |
| Задача E (? = 1) | 1.00 | 1.65 | 10.24 |
| Задача F (? = 1) | 1.00 | 1.65 | 10.24 |
| Задача G (? = 2) | 1.00 | 7.39 | 104.87 |
| SUM | 9.74 | 15.71 | 112.65 |
Опять же, единственная неприятная задача в основном доминирует в расчётах оценки, по крайней мере, для 99% случаев. Даже по среднему времени один сумасшедший проект в конечном итоге занимает примерно половину времени, потраченного на все задачи, хотя по медиане у них близкие значения. Для простоты я предположил, что все задачи имеют одинаковую оценку по времени, но разные неопределённости. Математика сохраняется при изменении сроков.
Забавно, но у меня давно такое чувство. Сложение оценок редко работает, когда у вас много задач. Вместо этого выясните, какие задачи имеют самую высокую неопределённость: эти задачи обычно будут доминировать в среднем времени выполнения.
Диаграмма показывает среднее и 99-й процентиль как функцию неопределённости (?):
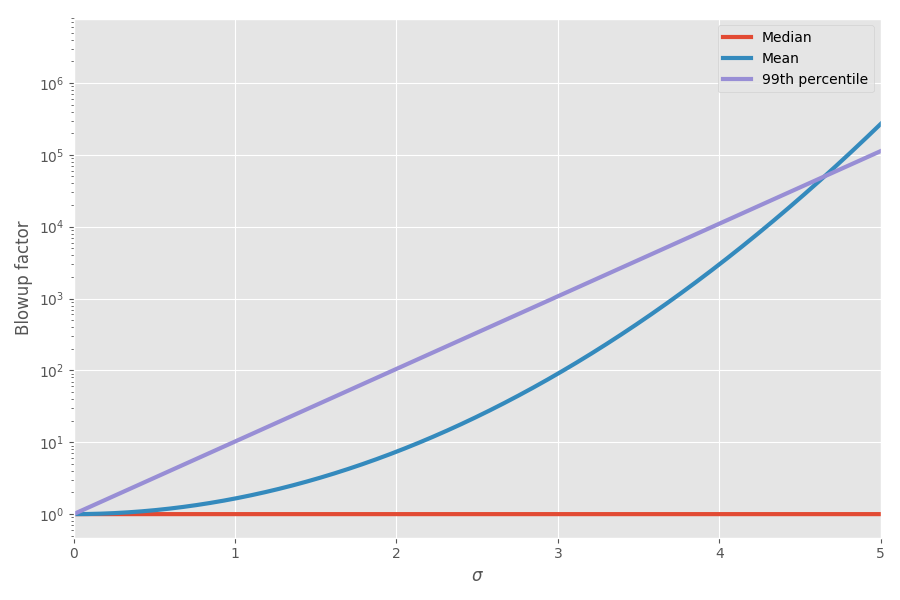
Теперь математика объяснила мои ощущения! Я начал учитывать это при планировании проектов. Я действительно думаю, что сложение оценок сроков выполнения задач сильно вводит в заблуждение и создаёт ложную картину, сколько времени займёт проект целиком, потому что у вас есть эти сумасшедшие перекошенные задачи, которые в конечном итоге отнимают всё время.
Где эмпирические данные?
Я долгое время хранил это в мозгу в разделе «любопытные игрушечные модели», иногда думая, что это аккуратная иллюстрация явления реального мира. Но однажды, бродя по сети, я наткнулся на интересный набор данных по оценке сроков проектов и фактическому времени их выполнения. Фантастика!
Давайте сделаем быстрый график разброса оценочного и фактического времени:
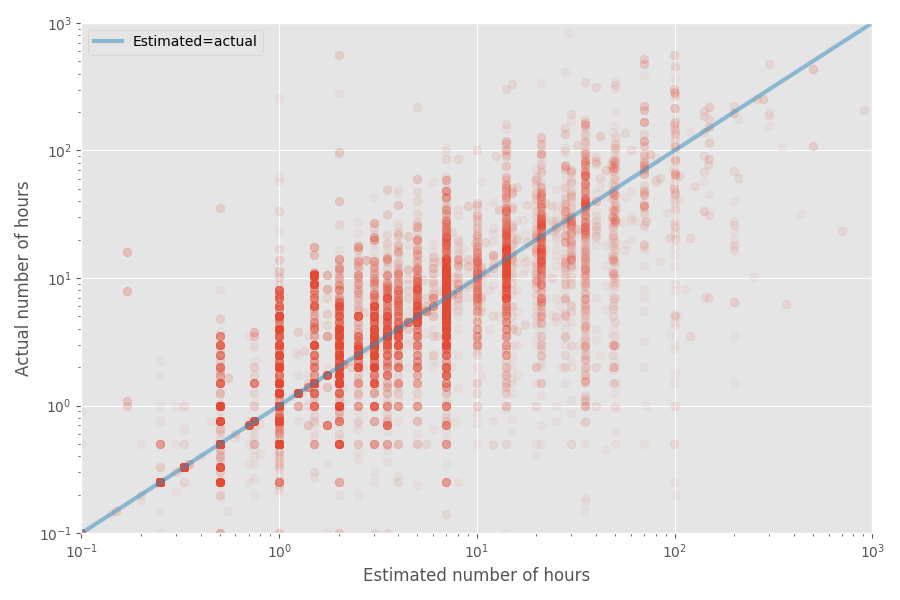
Медианный коэффициент инфляции для этого набора данных равен 1X, тогда как средний коэффициент равен 1,81x. Опять же, это подтверждает догадку, что разработчики хорошо оценивают медиану, но среднее значение оказывается намного выше.
Посмотрим на распределение коэффициента инфляции (логарифм):
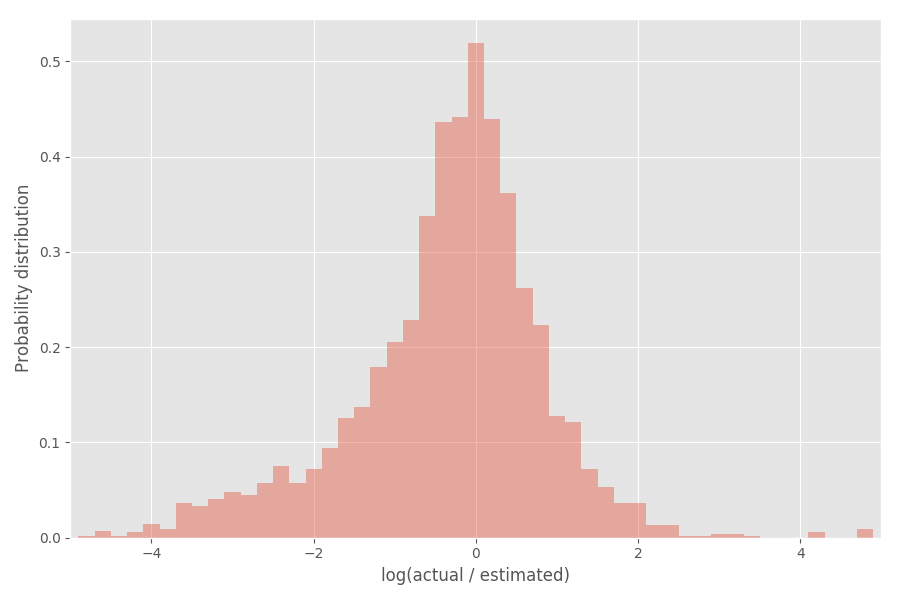
Как видите, он довольно хорошо центрирован вокруг 0, где коэффициент инфляции exp(0) = 1.
Возьмём статистические инструменты
Сейчас я собираюсь немного пофантазировать со статистикой — не стесняйтесь пропустить эту часть, если она вам не интересна. Что мы можем заключить из этого эмпирического распределения? Вы можете ожидать, что логарифмы коэффициента инфляции будут распределяться в соответствии с нормальным распределением, но это не совсем так. Обратите внимание, что ? сами случайны и варьируются для каждого проекта.
Один из удобных способов моделирования ? заключается в том, что они отбираются из обратного гамма-распределения. Если предположить (как и ранее), что логарифм коэффициентов инфляции распределён в соответствии с нормальным распределением, то «глобальное» распределение логарифмов коэффициентов инфляции завершается распределением Стьюдента.
Нанесём распределение Стьюдента на предыдущее:

Прилично сходится, на мой взгляд! Параметры распределения Стьюдента также определяют обратное гамма-распределение значений ?:
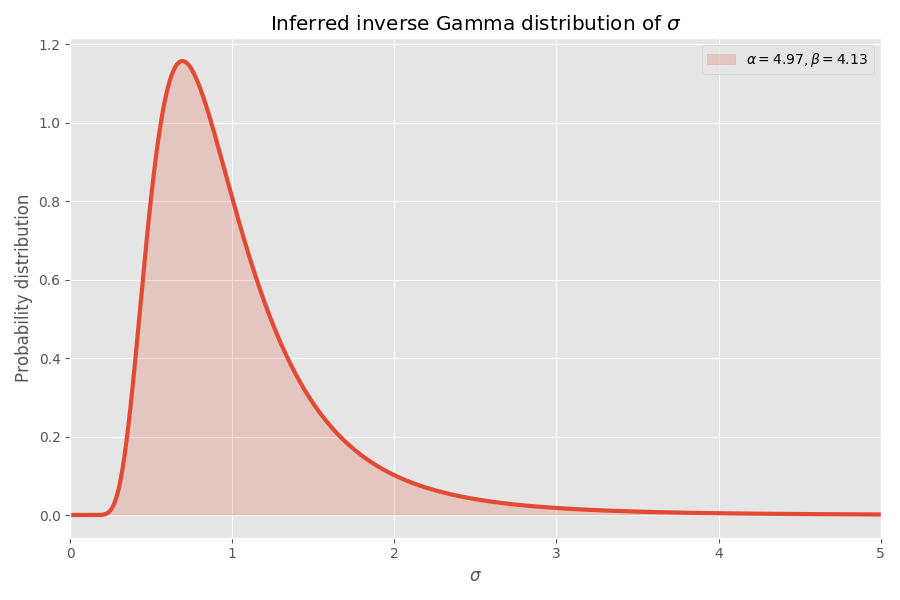
Обратите внимание, что значения ? > 4 очень маловероятны, но когда они происходят, то вызывают средний взрыв в несколько тысяч раз.
Почему программные задачи всегда занимают больше времени, чем вы думаете
Предполагая, что этот набор данных является репрезентативным для разработки программного обеспечения (сомнительно!), мы можем сделать ещё несколько выводов. У нас параметры для распределения Стьюдента, поэтому мы можем вычислить среднее время, необходимое для выполнения задачи, не зная ? для этой задачи.
В то время как медианный коэффициент инфляции из этой подгонки равен 1x (как и раньше), коэффициент инфляции 99% составляет 32x, но если вы перейдёте к 99,99-му процентилю, это колоссальные 55 миллионов! Одна (вольная) интерпретация заключается в том, что некоторые задачи в конечном итоге практически невозможны. Фактически, эти самые крайние случаи оказывают такое огромное влияние на среднее, что средний коэффициент инфляции любой задачи становится бесконечным. Это довольно плохие новости для тех, кто пытается уложиться в сроки!
Резюме
Если моя модель верна (большое если), то вот что мы можем узнать:
- Люди хорошо оценивают медианное время выполнения задачи, но не среднее.
- Среднее время оказывается значительно больше медианы из-за того, что распределение искажено (логнормальное распределение).
- Когда вы складываете оценки для n задач, всё становится ещё хуже.
- Задачи наибольшей неопределённости (скорее, наибольшего размера) часто могут доминировать по среднему времени, необходимому для выполнения всех задач.
- Среднее время выполнения задачи, о которой мы ничего не знаем, на самом деле бесконечно.
Примечания
- Очевидно, выводы основаны только на одном наборе данных, который я нашёл в интернете. Другие наборы данных могут дать другие результаты.
- Моя модель, конечно, тоже очень субъективна, как и любая статистическая модель.
- Я был бы рад применить модель к гораздо большему набору данных, чтобы увидеть, насколько она устойчива.
- Я предположил, что все задачи самостоятельны. На самом деле у них может быть корреляция, которая сделает анализ намного более раздражающим, но (я думаю) в конечном итоге с аналогичными выводами.
- Сумма логнормально распределённых значений не является другим логнормально распределённым значением. Это слабость данного распределения, так как вы можете утверждать, что большинство задач — это просто сумма подзадач. Неплохо, если бы наше распределение было устойчивым.
- Я удалил из гистограммы маленькие задачи (расчётное время меньше или равно 7 часам), так как они искажают анализ и там был странный всплеск ровно на 7.
- Код лежит на Github, как обычно.
Комментарии (24)

aivs
26.04.2019 21:42Думал все программисты руководствуются правилом: оцени время, умножь на Пи.

helgihabr
26.04.2019 21:57Вообще-то: оцени время, подели на два и умножь на пи.
nad_oby
26.04.2019 22:35Ну вот теперь я знаю откуда в моей голове взялся коэффициент 1.6 который я обычно использую при оценке длительности задачи.
Но откуда само правило?helgihabr
26.04.2019 23:06+2Представьте, что программист видит решение задачи как прямую (сверху вниз), обозначим D.
Но в реальности будут вопросы, уточнения, недопонимание и все такое, т.е. реально время на решение задачи пойдет по окружности, диаметр который мы уже обозначили D.
Т.е. это будет пол окружности. Длина половины окружности будет: 2 * pi * R / 2
Т.к. R — это наше время D/2, то выходит, что наше время задачи, в реальности, выльется:
(2 * pi * D / 2) / 2 = pi * D / 2
Как-то так ))
Sergei_Erjemin
29.04.2019 11:13Иногда решение задачи надо обойти со всех сторон (вдруг она не симметричная) — pi * D…
Опять же нужно еще и сам радиус добавить — pi * D + D / 2…
А еще можно сделать несколько обходов (чтобы лучше разглядеть и полюбоваться видами). А на налюбовавшись понять, что может и не стоит ее решать… :))

tmteam
27.04.2019 03:461) Оцени время
2) Умножь на пи и прибавь неделю
3) Позови скрам-мастера
4) Декомпозируй
5) Повтори с п2 для каждой подзадачи


fralik
26.04.2019 23:55+1Есть целая книга на эту тему, Time Predictions. Ее можно бесплатно почитать через Google Play.
В книге много букв, но, по-моему, она довольно интересна. Там подробно все разбирают и показывают, в том числе распределения и формулы оценки времени.

DmitryKoterov
27.04.2019 09:25-1Оценка сроков — это не самоцель, а просто инструмент, который стимулирует участников декомпозировать задачи и начинать обсуждение деталей еще на ранней стадии, а также придает процессу ощущение конечности/коммитности, убрает эффект рассусоливания. Вот и все. Не так важно, какая именно оценка получается, там плюс-минус километр всегда.
Неточная оценка сроков в любом случае гораздо лучше, чем вообще отсутствие оценки.
akurilov
27.04.2019 12:30Спасибо! Теперь когда руководство меня спросит о сроках выпоонения задачи, будет много встречных вопросов :)
- для какого перцентиля оцениваем срок;
- зачем перцентили, когда вам нужно среднее;
- согласны ли вы, что среднее вовсе не означает 100% вероятности выполнения в указанный срок; и даже 75% вероятности, скорее всего тоже
:)
arTk_ev
27.04.2019 13:21Для оценки использую PERT. В результате вы сразу же получаете роадмапу, майлстоуны, критические места, 4 оценки времени на каждую подзадачу, и распаралеленые задачи для команды. Даже если несколько задач профакапятся, то это не повлияет на сроки.
Необоснованная оценка времени из головы — это чушь. Она годиться лишь для предварительной оценки. Чтобы оценить сроки сложной задачи — ее нужно декомпозировать на мелкие задачи, сроки которых известны. Для сложных для которых опыта не хватает — нужно делать ресерч и прототипирование, чтобы дать оценку. Ни разу еще не профакапился по срокам
Gorthauer87
28.04.2019 04:41Это еще зависит от глубины кроличьей норы, в некоторых из них может целая страна чудес оказаться.

AndreySitaev
27.04.2019 13:30+3Менеджеру интересен, как правило, ответ на вопрос:
— за какой срок задача Х будет завершена?
Программист же отвечает на вопрос:
— сколько требует времени решение задачи Х.
Зачастую, решение задачи Х прерывается решением других задач, как учитываемых в графике (прерваться на устранение критической ошибки ...), так и нет (помочь коллеге ...)
Менеджер, конечно, всё понимает… но вот задача Х оказывается не решенной к сроку, зачастую при том, что оценка была корректна.
firedragon
27.04.2019 13:42Часто бывает что задание не детализировано, привет кстати Аджайлу.
Так что чепуховая задача, выливается в огромный срок. Типичный кейс это внедрение локализации после начала работы над приложением. Или в мобильных приложениях добавление бэджика непрочитанных сообщений.
nmrulin
27.04.2019 14:39На самом деле логика бизнеса диктует указывать минимальный срок(если всё пойдёт гладко) + некоторый коэффициент запаса. Допустим человек 2 раза подряд укажит срок n, но в принципе всё пошло гладко и проект решён за n/2 времени. Естественно начальник скажет, что ты дурак не умеешь правильно оценивать время на проекты. И будет сам тебе сроки ставить. И наоборот, если сказал n/2 то может редко случитсья, что по факту выполнил за n. В этом случае либо удаётся сослаться на объективные обстоятельства либо от начальника получаешь минус в карму. Т.к. срывы сроков по такой причине редки, то человек может 5 лет и больше проработать. Потом программист А увольняется вместо него нанимается программист Б, который на соседнем предприятии имел такой срыв сроков и тоже имеет некий минус в карме. Итог — система работает, сроки периодически срываются. А иногда и не срываются — т.к. программиста застравляют работать сверурочно за минимальную доплату. Кто постоянно работает сверхурочно и не срывает сроки идёт на повышение(иногда).
Daddy_Cool
27.04.2019 14:56+1… причина, по которой среднее значение настолько велико, заключается в том, что задачи, которые выполняются быстрее, чем предполагалось, не могут компенсировать задачи, которые занимают гораздо больше времени, чем предполагалось.
Суть статьи!
propell-ant
27.04.2019 15:45+2Как-то автор не сделал главный вывод — на проектах с высокой неопределенностью нужно управлять сигмами.
Уже на начальном этапе становится понятно, что у части задач неопределенность выше, чем у большинства остальных. Если ничего не предпринимать, то высокая неопределенность никуда не денется, и при наличии опоздания (допустим) на 50% исполнитель будет всё так же не в состоянии сделать достоверную оценку времени, требующегося для завершения.
На таких задачах требуется вложить время и силы не в работу по существу задачи, а в понимание, что этот исполнитель (или исполнители) не учитывают или не понимают. В терминах статьи — разобраться в том, почему сигма такая большая.
Дальше возможны варианты — либо после разбора становится ясно, как сигму уменьшить до средних по проекту величин, либо прикинуть ту самую сигму и дальше ее закладывать в оценки сроков.
kluwert
27.04.2019 17:21Редкостный пример, когда автор открыл для себя инструмент (элементарную теорию вероятности), но совершенно не понимает как им пользоваться и, в рез-те, притянул его за уши к совершенно не подходящей задаче. Начнём с того, что процесс разработки — ни разу не стационарный и, уже, тем более — не эргодический процесс. Тогда уж, автор, давай жги до конца, подтаскивай теорию нестационарных случайных процессов! А если серъёзно, то, как правильно абсолютно выше написали, реальная разработка — это процесс, к-рый зависит от уймы слабопредсказуемых пар-ров. Вы можете сложный кусок сделать на удивление быстро, а на простом месте забуксовать на недели. А что-то и не сделать никогда. С этим нужно просто смириться, увы.
Dmitri-D
27.04.2019 19:36Проблема в том, что любое непредвиденное обстоятельство, т.е. в данном контексте «случайность», в 99% случаев приводит не к сокращению времени, а к его увеличению. Т.е. распределение резко ассиметрично.
Умножение на 3 — довольно распространенное правило. На моей практике оно почти всегда дает достаточноый запас чтобы выполнить всё в хорошем качестве и выпустить в продакшн.Akela_wolf
27.04.2019 19:50Так логнормальное распределение, которое показывает автор статьи именно этим и характерно — мы видим ограниченность нулем слева и длинный «хвост» справа.
nrgian
28.04.2019 11:50Еще в 1975 году про неточность сроков обратили внимание:
«Мифический человеко-месяц, или Как создаются программные системы» (англ. The Mythical Man-Month: Essays on Software Engineering), автор Фредерик Брукс.
dipsy
Задачи занимают больше времени, потому что много случайных и неизвестных факторов, влияющих на конечный результат. Оценивать сколь-нибудь точно можно только «типовые» задачи. Плюс ещё необходимо определиться, что мы понимаем под выполнением задачи, это тоже крайне размытое понятие, от непокрытого тестами лапшекода до продуманного архитектурно решения. Сроки отличаются в разы, зачастую под выбранный заранее срок решение можно подогнать, но далеко не с 100% качеством.