
Компьютерное зрение. Сейчас о нём много говорят, оно много где применяется и внедряется. И как-то давненько на Хабре не выходило обзорных статей по CV, с примерами архитектур и современными задачами. А ведь их очень много, и они правда крутые! Если вам интересно, что сейчас происходит в области Computer Vision не только с точки зрения исследований и статей, но и с точки зрения прикладных задач, то милости прошу под кат. Также статья может стать неплохим введением для тех, кто давно хотел начать разбираться во всём этом, но что-то мешало ;)

Сегодня на Физтехе происходит активная коллаборация «академии» и индустриальных партнёров. В частности, в Физтех-школе Прикладной математики и информатики действуют множество интересных лабораторий от таких компаний, как Сбербанк, Biocad, 1С, Тинькофф, МТС, Huawei.
На написание этой статьи меня вдохновила работа в Лаборатории гибридных интеллектуальных систем, открытой компанией ВкусВилл. У лаборатории амбициозная задача — построить магазин, работающий без касс, в основном при помощи компьютерного зрения. За почти год работы мне довелось поработать над многими задачами зрения, о которых и пойдёт речь в этих двух частях.
Будем двигаться по плану:
В 2019 году все говорят про искусственный интеллект, четвёртую промышленную революцию и приближение человечества к сингулярности. Круто, классно, но хочется конкретики. Ведь мы с вами любопытные технари, которые не верят в сказки про ИИ, мы верим в формальную постановку задач, математику и программирование. В этой статье мы поговорим о конкретных кейсах применения того самого современного ИИ — о применении deep learning (а именно — свёрточных нейросетей) в множестве задач компьютерного зрения.
Да, мы будем говорить именно про сетки, иногда упоминая некоторые идеи из «классического» зрения (так будем называть набор методов в зрении, которые использовались до нейросетей, однако это ни в коем случае не значит, что сейчас они не используются).

На мой взгляд, первое действительно интересное применение нейросетей в зрении, которое было освещено в СМИ ещё в 1993 году, это распознавание рукописных цифр, реализованное Яном ЛеКуном. Сейчас он один из главных по ИИ в Facebook AI Research, их команда выпустила уже немало полезных Open Source вещей.
Сегодня же зрение применяется во многих сферах. Приведу лишь несколько ярких примеров:


Беспилотные автомобили Tesla и Яндекса

Анализ медицинских снимков и предсказание рака
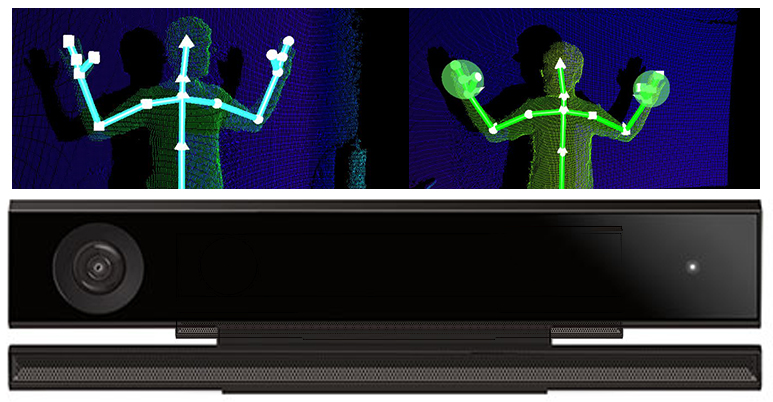
Игровые приставки: Kinect 2.0 (правда, там ещё используется информация о глубине, то есть RGB-D картинки)


Распознавание по лицу: Apple FaceID (при помощи нескольких датчиков)

Оценка точек лица: маски в Snapchat

Биометрия лица и движений глаз (пример из проекта ФПМИ МФТИ)
Поиск по картинке: Яндекс и Google

Распознавание текста на картинке (Optical Character Recognition)


Дроны и роботы: получение и обработка информации с помощью зрения

Одометрия: построение карты и планирование при перемещении роботов

Улучшение графики и текстур в видеоиграх

Перевод по картинке: Яндекс и Google


Дополненная реальность: Leap Motion (Project North Star) и Microsoft Hololens


Перенос стиля и текстур: Prisma, PicsArt
Я уже не говорю про многочисленные применения в различных внутренних задачах компаний. Facebook, к примеру, применяет зрение ещё и для того, чтобы фильтровать медиаконтент. В проверке качества/повреждений в промышленности тоже используются методы компьютерного зрения.
Дополненной реальности здесь нужно, на самом деле, уделить отдельное внимание, посколькуона не работает в скором времени это может стать одной из главных областей применения зрения.
Смотивировались. Зарядились. Поехали:

Как я уже говорил, в 90-е годы сетки в зрении выстрелили. Причём выстрелили в конкретной задаче — задаче классификации картинок рукописных цифр (знаменитый датасет MNIST). Исторически сложилось, что именно задача классификации изображений и стала основой при решении почти всех последующих задач в зрении. Рассмотрим конкретный пример:
Задача: На вход дана папка с фотографиями, на каждом фото тот или иной объект: либо кошка, либо собака, либо человек (пусть “мусорных” фоток нет, супер-не-жизненная задача, но надо с чего-то начать). Нужно разложить картинки по трём папкам:

Представим, что с компьютерным зрением мы пока не знакомы, но знаем machine learning. Изображения — это просто числовые тензоры в памяти компьютера. Формализуем задачу в терминах машинного обучения: объекты — это картинки, их признаки — это значения в пикселях, ответ для каждого из объектов — метка класса (кошка, собака или человек). Это в чистом виде задача классификации.
Можно взять какие-нибудь методы из “классического” зрения или “классического” машинного обучения, то есть не нейросети. В основном эти методы заключаются в выделении на изображениях неких особенностей (особых точек) или локальных регионов, которые будут характеризовать картинку (“мешок визуальных слов”). Обычно всё это сводится к чему-то типа SVM над HOG/SIFT.
Но мы здесь собрались, чтобы поговорить о нейросетях, поэтому не хотим использовать придуманные нами признаки, а хотим, чтобы сеть сделала всё за нас. Наш классификатор будет принимать на вход признаки объекта и возвращать предсказание (метку класса). Здесь в качестве признаков выступают значения интенсивности в пикселях (см. модель картинки в под
спойлером выше). Помним, что картинка — это тензор размера (Height, Width, 3) (если она цветная). Сетке при обучении на вход всё это обычно подаётся не по одной картинке и не целым датасетом, а батчами, т.е. небольшими порциями объектов (например, 64 картинки в батче).
Таким образом, сеть принимает на вход тензор размера (BATCH_SIZE, H, W, 3). Можно “развернуть” каждую картинку в вектор-строку из H*W*3 чисел и работать со значениями в пикселях прямо как с признаками в машинном обучении, обычный Multilayer Perceptron (MLP) так и поступил бы, но это, честно говоря, такой себе бейзлайн, поскольку работа с пикселями как с вектор-строкой никак не учитывает, например, трансляционную инвариантность объектов на картинке. Тот же кот может быть как в середине фото, так и в углу, MLP эту закономерность не выучит.
Значит нужно что-то по-умнее, например, операция свёртки. И это уже про современное зрение, про свёрточные нейронные сети:
Поскольку сейчас речь об обучении с учителем, для тренировки нейросети нам нужны несколько компонент:
В коде именно это и реализовано, сама свёрточная нейросеть описана в классе Net().
Если хочется не спеша и с начала узнать про свёртки и свёрточные сети, рекомендую лекцию в Deep Learning School (ФПМИ МФТИ) (на русском) на эту тему, и, конечно же, курс Стэнфорда cs231n (на английском).

Если вкратце, то операция свёртки позволяет находить паттерны на изображениях с учётом их вариативности. Когда обучаем свёрточные нейросети (eng: Convolutional Neural Networks), мы, по сути, находим фильтры свёрток (веса нейронов), которые хорошо описывают изображения, причём столь хорошо, чтобы можно было точно определить по ним класс. Способов построить такую сеть придумали много. Больше, чем вы думаете…

Да-да, ещё один обзор архитектур. Но здесь я постараюсь сделать его максимально актуальным!
Сначала была LeNet, она помогла Яну ЛеКуну распознавать цифры в 1998 году. Это была первая свёрточная нейросеть для классификации. Её основная фишка была в том, что она в принципе стала использовать convolution и pooling операции.

Далее было некоторое затишье в развитии сеток, однако «железо» не стояло на месте, развивались эффективные вычисления на GPU и XLA. В 2012 году появилась AlexNet, она выстрелила в соревновании ILSVRC (ImageNet Large-Scale Visual Recognition Challenge).
Обычно различные обзоры архитектур проливают свет на те, что были первыми на ILSVRC с 2010 до 2016 года, и на некоторые отдельные сети. Чтобы не загромождать рассказ, я поместил их под спойлер ниже, постаравшись подчеркнуть основные идеи:
Идеи всех этих архитектур (кроме ZFNet, её обычно мало упоминают) в своё время были новым словом в нейросетях для зрения. Однако и после 2015 было ещё очень много важных улучшений, например, Inception-ResNet, Xception, DenseNet, SENet. Ниже я постарался собрать их в одном месте.
Большинство из этих моделей для PyTorch можно найти здесь, а ещё есть вот такая классная штука.
Вы могли заметить, что всё это дело весит довольно много (хотелось бы 20 MB максимум, а то поменьше), в то время как сейчас повсеместно используют мобильные устройства и приобретает популярность IoT, а значит сетки хочется использовать и там.
Авторы многих статей пошли по пути изобретения быстрых архитектур, я собрал их методы под спойлером ниже:
Цифры во всех таблицахвзяты с потолка из репозиториев, из таблицы Keras Applications и из этой статьи.
Вы спросите: “Для чего ты написал про весь этот “зоопарк” моделей? И почему всё же задача классификации? Мы же хотим научить машины видеть, а классификация — лишь какая-то узкая задача..”. Дело в том, что нейросети для детектирования объектов, оценки позы/точек, ре-идентификации и поиска по картинке используют в качестве backbone именно модели для классификации, и уже от них зависит 80% успеха.
Но хочется как-то больше доверять CNN, а то напридумывали чёрных коробок, а что «внутри» — не очевидно. Чтобы лучше понимать механизм функционирования свёрточных сетей, исследователи придумали использовать визуализацию.
Важным шагом к осознанию того, что происходит внутри свёрточных сетей, стала статья «Visualizing and Understanding Convolutional Networks». В ней авторы предложили несколько способов визуализации того, на что именно (на какие части картинки) реагируют нейроны в разных слоях CNN (рекомендую также посмотреть лекцию Стэнфорда на эту тему). Результаты получились весьма впечатляющие: авторы показали, что первые слои свёрточной сети реагируют на какие-то «низкоуровневые вещи» по типу краёв/углов/линий, а последние слои реагируют уже на целые части изображений (см. картинку ниже), то есть уже несут в себе некоторую семантику.

Далее проект по глубокой визуализации от Cornell University и компании продвинул визуализацию ещё дальше, в то время как знаменитый DeepDream научился искажать внаркоманском интересном стиле (ниже картинка с deepdreamgenerator.com).

В 2017 году вышла очень хорошая статья на Distill, в которой они провели подробный анализ того, что «видит» каждый из слоёв, и совсем недавно (в марте 2019) Google изобрела активационные атласы: своеобразные карты, которые можно строить для каждого слоя сети, что приближает к понимаю общей картины работы CNN.

Если хочется самому поиграться с визуализацией, я бы рекомендовал Lucid и TensorSpace.
Окей, кажется, CNN и правда в некоторой степени можно верить. Нужно научиться использовать это и в других задачах, а не только в классификации. В этом нам помогут извлечение Embedding'ов картинок и Transfer Learning.
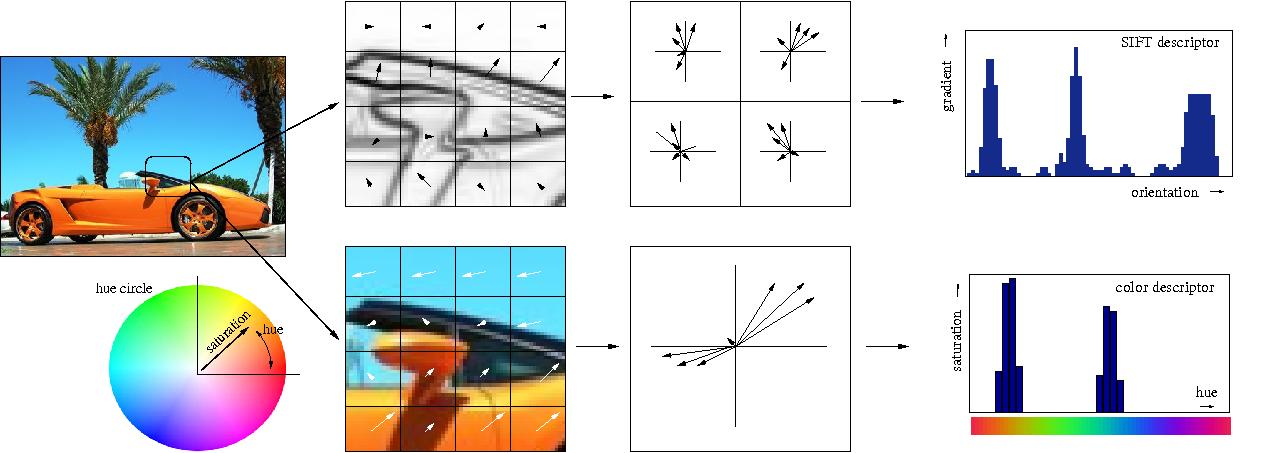
Представим, что есть картинка, и мы хотим найти похожие на неё визуально (так умеет, например, поиск по картинке в Яндекс.Картинки). Раньше (до нейросетей) инженеры для этого извлекали фичи вручную, например, придумывая что-то, что хорошо описывает картинку и позволит её сравнивать с другими. В основном, эти методы (HOG, SIFT) оперируют градиентами картинок, обычно именно эти штуки и называют «классическими» дескрипторами изображений. Особо интересующихся отсылаю к статье и к курсу Антона Конушина (это не реклама, просто курс хороший :)
Используя нейросети, мы можем не придумывать самому эти фичи и эвристики, а правильно обучить модель и потом взять за признаки картинки выход одного или нескольких слоёв сети.
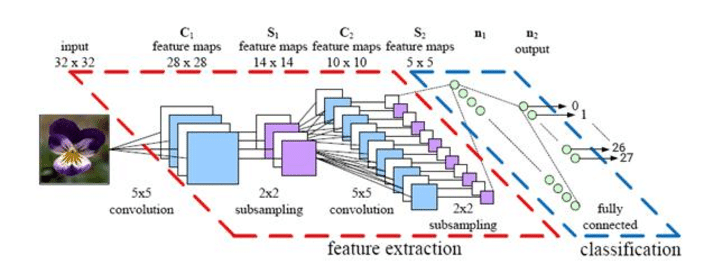
Посмотрев на все архитектуры выше поближе, становится понятно, что в CNN для классификации есть два этапа:
1). Feature extractor слои для выделения информативных фич из картинок с помощью свёрточных слоёв
2). Обучение поверх этих фич Fully Connected (FC) слоёв-классификаторов
Embedding'и картинок (фичи) — это как раз про то, что можно брать в качестве информативного описания картинок их признаки после Feature extractor’а свёрточной нейросети (правда их можно по-разному агрегировать). То есть обучили сеть на классификацию, а потом просто берём выход перед классификационными слоями. Эти признаки называют фичами, нейросетевыми дескрипторамиили эмбеддингами картинки (правда обычно эмбеддинги принято в NLP, так как это зрение, я чаще буду говорить фичи). Обычно это какой-то числовой вектор, например, 128 чисел, с которым уже можно работать.
Таким образом, пайплайн решения задачи поиска по картинке может быть устроен просто: прогоняем картинки через CNN, берём признаки с нужных слоёв и сравниваем эти фичи друг с другом у разных картинок. Например, банально считаем Евклидово расстояние этих векторов.

Transfer Learning — широко известная техника эффективного дообучения нейросетей, которые уже обучены на каком-то определённом датасете, под свою задачу. Часто ещё говорят Fine Tuning вместо Transfer Learning, в конспектах Стэнфордского курса cs231n эти понятия разделяют, мол, Transfer Learning — это общая идея, а Fine Tuning — одна из реализаций техники. Нам это в дальнейшем не так важно, главное понимать, что мы просто можем дообучить сеть хорошо предсказывать на новом датасете, стартуя не со случайных весов, а с обученных на каком-нибудь большом по типу ImageNet. Это особенно актуально, когда данных мало, а задачу хочется решить качественно.
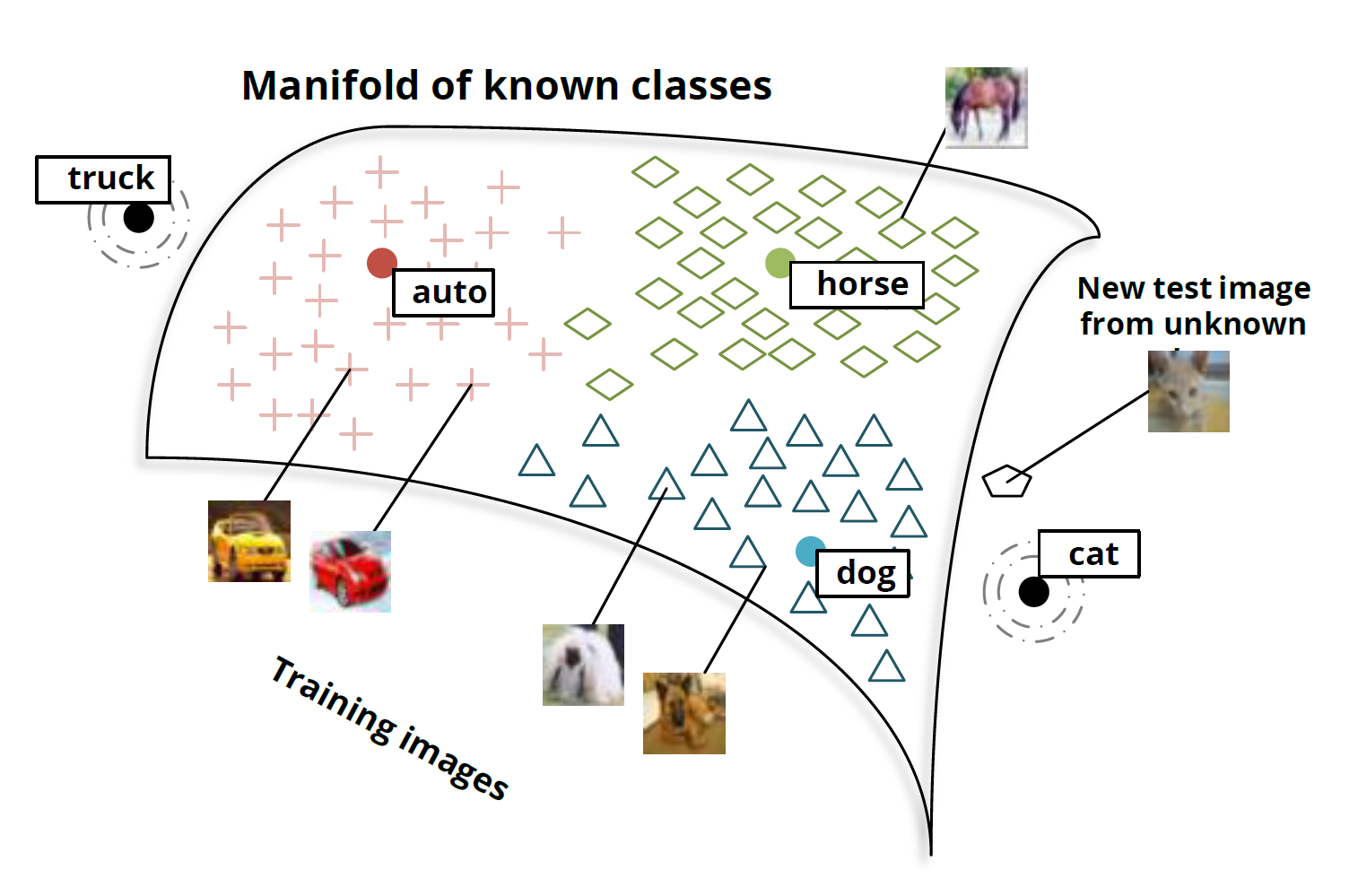
Однако просто брать нужные фичи и делать дообучение с датасета на датасет может быть недостаточно, например, для задач поиска похожих лиц/людей/чего-то специфичного. Фотографии одного и того же человека визуально иногда могут быть даже более непохожи, чем фотографии разных людей. Нужно заставить сеть выделять именно те признаки, которые присущи одному человеку/объекту, даже если нам это сделать глазами сложно. Добро пожаловать в мир representation learning.
Поставим задачи:
Первую задачу обычно называют распознаванием лиц, вторую — ре-идентификацией (сокращённо Reid). Я объединил их в один блок, поскольку в их решениях сегодня используются схожие идеи: для того, чтобы выучивать эффективные эмбеддинги картинок, которые могут справляться и с довольно сложными ситуациями, сегодня используют различные типы лоссов, такие как, например, triplet loss, quadruplet loss, contrastive-center loss, cosine loss.
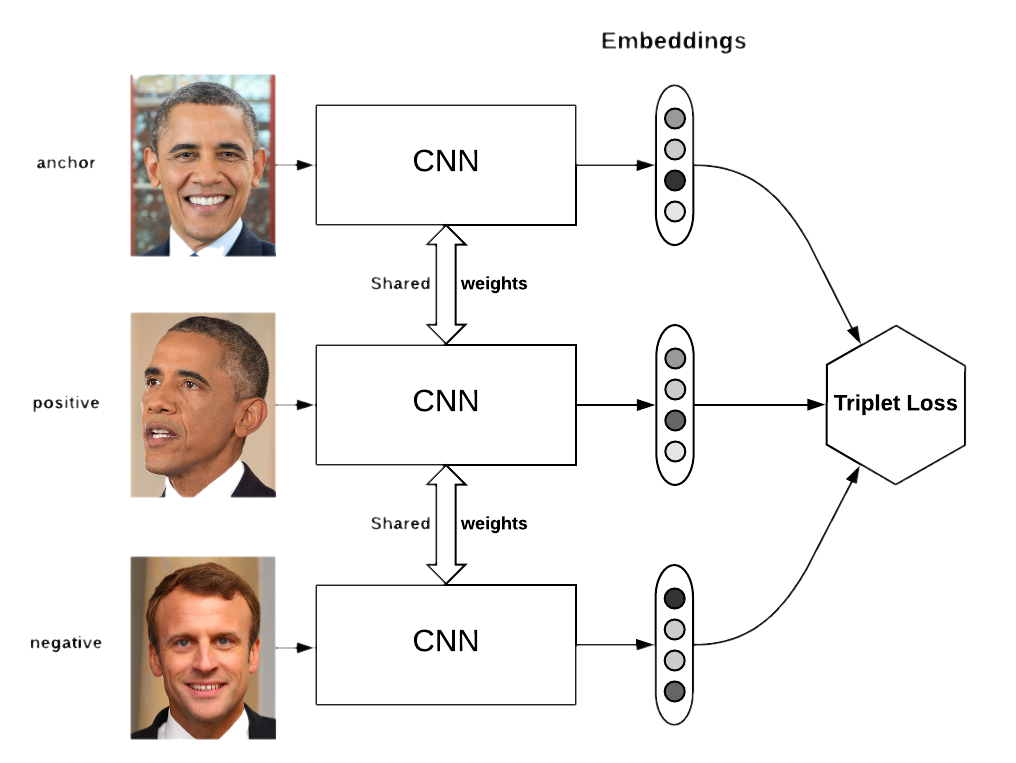
Ещё есть прекрасные сиамские сети, однако их я, честно, сам не использовал. Кстати, “решает” не только сам лосс, а то, как для него семплировать пары positive’ов и negative’ов, это подчёркивают авторы статьи Sampling matters in deep embedding learning.
Суть всех этих лоссов и сиамских сетей проста — хотим, чтобы картинки одного класса (человека) в латентном пространстве фич (эмбеддингов) были “близко”, а разных классов (людей) — “далеко”. Близость обычно меряется так: берутся эмбеддинги картинок из нейросети (например, вектор из 128 чисел) и либо считаем обычное Евклидово расстояние между этими векторами, либо косинусную близость. Как именно мерить — лучше подбирать на своём датасете/задаче.
Схематично пайплайн решения задач на representation learning выглядит примерно так:
Конкретно по распознаванию лиц есть несколько хороших статей: статья-обзор (MUST READ!), FaceNet, ArcFace, CosFace.
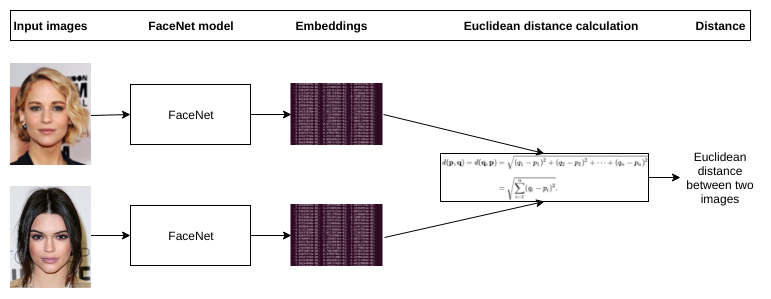
Реализаций тоже немало: dlib, OpenFace, FaceNet repo, да и на Хабре про это уже давно было рассказано. Кажется, за последнее время добавились только ArcFace и CosFace (пишите в комментарии, если я здесь что-то упустил, буду рад узнать что-то ещё).
Однако сейчас больше мода не на распознавание лиц, а на их генерацию, не так ли?

В свою очередь, в задаче ре-идентификации сейчас бурная активность, статьи выходят каждый месяц, люди пробуют разные подходы, что-то работает уже сейчас, что-то пока ещё не очень.

Поясню суть задачи Reid на примере: есть галерея с кропами людей, например, 10 людей, у каждого по 5 кропов (могут быть с разных сторон), то есть 50 фотографий в галерее. Приходит новая детекция (кроп), и надо сказать, какой это человек из галереи или сказать, что его там нет и завести для него новый ID. Задача усложняется тем, что детекции человека приходят с разных ракурсов: спереди, сзади, сбоку,снизу, и плюс камеры, с которых фото приходят, тоже разные (разные освещения/балансы белого и т.д.).

К слову, в нашей лаборатории Reid — одна из ключевых задач. Статей выходит действительно немало, какие-то из них про новый более эффективный лосс, какие-то только про новый способ добычи negative'ов и positive'ов.
Хороший обзор старых методов по Reid есть в статье 2016 года. Сейчас, как я уже писал выше, применяются два подхода — классификация или representation learning. Однако есть специфика задачи, с ней исследователи борются по-разному, например, авторы Aligned Re-Id предложили специальным образом выравнивать фичи (да, они смогли улучшить сеть с помощью динамического программирования, Карл), в другой статье предложили применить Generative Adversarial Networks (GAN).
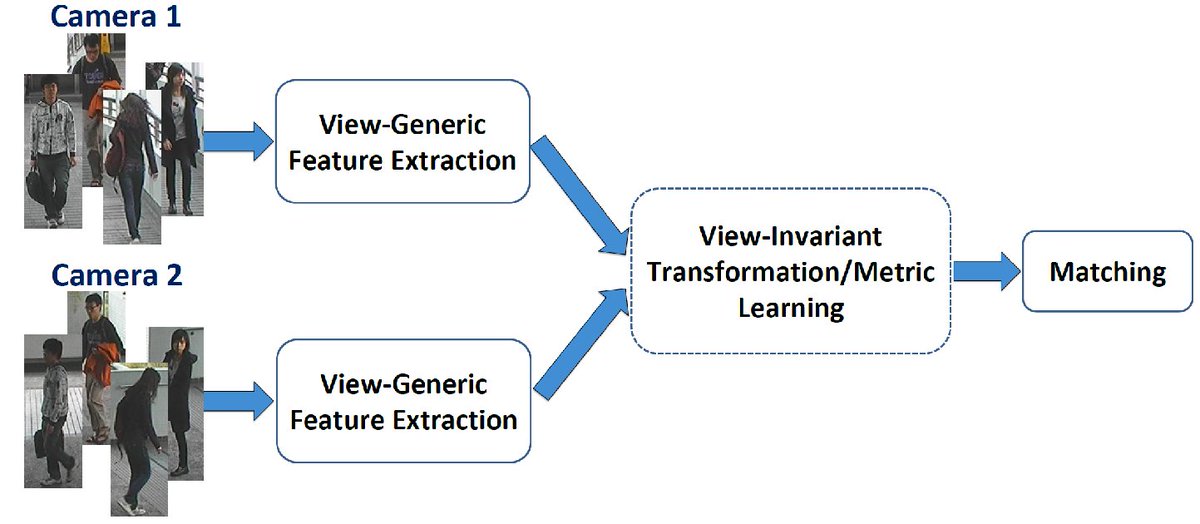
Из реализаций хочется обязательно упомянуть OpenReid и TorchReid. Обратите внимание на сам код — на мой взгляд, он написан грамотно с точки зрения архитектуры фреймворка, подробнее здесь. Плюс они оба на PyTorch, и в Readme есть много ссылок на статьи по Person Re-identification, это приятно.
Вообще особый спрос на face- и reid-алгоритмы сейчас в Китае (если вы понимаете, о чём я). Мы на очереди? Кто знает…
Мы уже говорили о том, что можно просто придумать легковесную архитектуру. Но как быть, если сеть уже обучена и она крута, а сжать её всё равно нужно? В таком случае может помочь один (или все) из следующих методов:
Ну и правило использовать не float64, а, например, float32 никто не отменял. Есть даже свежая статья про low-precision training. Недавно, кстати, Google представил MorphNet, которая (вроде как) помогает автоматически сжимать модель.

Мы обсудили действительно много полезных и прикладных вещей в DL и CV: классификация, архитектуры сетей, визуализация, эмбеддинги. Однако в современном зрении есть ещё и другие важные задачи: детектирование, сегментация, понимание сцены. Если речь про видео, то хочется объекты трекать во времени, распознавать действия и понимать, что на видео происходит. Именно этим вещам и будет посвящена вторая часть обзора.
Stay tuned!
Сегодня на Физтехе происходит активная коллаборация «академии» и индустриальных партнёров. В частности, в Физтех-школе Прикладной математики и информатики действуют множество интересных лабораторий от таких компаний, как Сбербанк, Biocad, 1С, Тинькофф, МТС, Huawei.
На написание этой статьи меня вдохновила работа в Лаборатории гибридных интеллектуальных систем, открытой компанией ВкусВилл. У лаборатории амбициозная задача — построить магазин, работающий без касс, в основном при помощи компьютерного зрения. За почти год работы мне довелось поработать над многими задачами зрения, о которых и пойдёт речь в этих двух частях.
Магазин без касс? Где-то я это уже слышал..
Наверное, дорогой читатель, Вы подумали про Amazon Go. В каком-то смысле стоит задача повторить их успех, однако наше решение больше про внедрение, нежели про построение такого магазина с нуля за огромные деньги.
Будем двигаться по плану:
- Мотивация и что вообще происходит
- Классификация как стиль жизни
- Архитектуры свёрточных нейросетей: 1000 способов достичь одной цели
- Визуализация свёрточных нейросетей: покажи мне страсть
- Я и сам своего рода хирург: извлекаем фичи из нейросетей
- Держись рядом: representation learning для людей и лиц
- Часть 2:
детектирование, оценка позы и распознавание действийбез спойлеров
Мотивация и что вообще происходит
Для кого статья?
Статья ориентирована в большей степени на людей, которые уже знакомы с машинным обучением и нейросетями. Однако советую прочитать хотя бы первые два раздела — вдруг всё будет понятно :)
В 2019 году все говорят про искусственный интеллект, четвёртую промышленную революцию и приближение человечества к сингулярности. Круто, классно, но хочется конкретики. Ведь мы с вами любопытные технари, которые не верят в сказки про ИИ, мы верим в формальную постановку задач, математику и программирование. В этой статье мы поговорим о конкретных кейсах применения того самого современного ИИ — о применении deep learning (а именно — свёрточных нейросетей) в множестве задач компьютерного зрения.
Да, мы будем говорить именно про сетки, иногда упоминая некоторые идеи из «классического» зрения (так будем называть набор методов в зрении, которые использовались до нейросетей, однако это ни в коем случае не значит, что сейчас они не используются).
Хочу изучить компьютерное зрение с нуля
Рекомендую курс Антона Конушина «Введение в компьютерное зрение». Лично я проходил его аналог в ШАДе, что заложило прочную основу в понимании обработки изображений и видео.
На мой взгляд, первое действительно интересное применение нейросетей в зрении, которое было освещено в СМИ ещё в 1993 году, это распознавание рукописных цифр, реализованное Яном ЛеКуном. Сейчас он один из главных по ИИ в Facebook AI Research, их команда выпустила уже немало полезных Open Source вещей.
Сегодня же зрение применяется во многих сферах. Приведу лишь несколько ярких примеров:
Беспилотные автомобили Tesla и Яндекса
Анализ медицинских снимков и предсказание рака
Игровые приставки: Kinect 2.0 (правда, там ещё используется информация о глубине, то есть RGB-D картинки)
Распознавание по лицу: Apple FaceID (при помощи нескольких датчиков)
Оценка точек лица: маски в Snapchat
Биометрия лица и движений глаз (пример из проекта ФПМИ МФТИ)
Поиск по картинке: Яндекс и Google
Распознавание текста на картинке (Optical Character Recognition)
Дроны и роботы: получение и обработка информации с помощью зрения
Одометрия: построение карты и планирование при перемещении роботов
Улучшение графики и текстур в видеоиграх
Перевод по картинке: Яндекс и Google
Дополненная реальность: Leap Motion (Project North Star) и Microsoft Hololens
Перенос стиля и текстур: Prisma, PicsArt
Я уже не говорю про многочисленные применения в различных внутренних задачах компаний. Facebook, к примеру, применяет зрение ещё и для того, чтобы фильтровать медиаконтент. В проверке качества/повреждений в промышленности тоже используются методы компьютерного зрения.
Дополненной реальности здесь нужно, на самом деле, уделить отдельное внимание, поскольку
Смотивировались. Зарядились. Поехали:
Классификация как стиль жизни
Как я уже говорил, в 90-е годы сетки в зрении выстрелили. Причём выстрелили в конкретной задаче — задаче классификации картинок рукописных цифр (знаменитый датасет MNIST). Исторически сложилось, что именно задача классификации изображений и стала основой при решении почти всех последующих задач в зрении. Рассмотрим конкретный пример:
Задача: На вход дана папка с фотографиями, на каждом фото тот или иной объект: либо кошка, либо собака, либо человек (пусть “мусорных” фоток нет, супер-не-жизненная задача, но надо с чего-то начать). Нужно разложить картинки по трём папкам:
/cats, /dogs и /leather_bags/humans, поместив в каждую папку только фото с соответствующими объектами.Что такое картинка/фотография?
Практически везде в зрении принято работать с картинками в RGB-формате. У каждой картинки есть высота (H), ширина (W) и глубина, которая равна 3 (цвета). Таким образом, одну картинку можно представить как тензор размерности HxWx3 (каждый пиксель — это набор из трёх чисел — значений интенсивности в каналах).
Практически везде в зрении принято работать с картинками в RGB-формате. У каждой картинки есть высота (H), ширина (W) и глубина, которая равна 3 (цвета). Таким образом, одну картинку можно представить как тензор размерности HxWx3 (каждый пиксель — это набор из трёх чисел — значений интенсивности в каналах).
Представим, что с компьютерным зрением мы пока не знакомы, но знаем machine learning. Изображения — это просто числовые тензоры в памяти компьютера. Формализуем задачу в терминах машинного обучения: объекты — это картинки, их признаки — это значения в пикселях, ответ для каждого из объектов — метка класса (кошка, собака или человек). Это в чистом виде задача классификации.
Если сейчас уже стало сложно..
… то лучше сначала прочитать первые 4 статьи из Открытого курса OpenDataScience по ML и ознакомиться с более вводной статьёй по зрению, например, хорошая лекция в Малом ШАДе.
Можно взять какие-нибудь методы из “классического” зрения или “классического” машинного обучения, то есть не нейросети. В основном эти методы заключаются в выделении на изображениях неких особенностей (особых точек) или локальных регионов, которые будут характеризовать картинку (“мешок визуальных слов”). Обычно всё это сводится к чему-то типа SVM над HOG/SIFT.
Но мы здесь собрались, чтобы поговорить о нейросетях, поэтому не хотим использовать придуманные нами признаки, а хотим, чтобы сеть сделала всё за нас. Наш классификатор будет принимать на вход признаки объекта и возвращать предсказание (метку класса). Здесь в качестве признаков выступают значения интенсивности в пикселях (см. модель картинки в под
спойлером выше). Помним, что картинка — это тензор размера (Height, Width, 3) (если она цветная). Сетке при обучении на вход всё это обычно подаётся не по одной картинке и не целым датасетом, а батчами, т.е. небольшими порциями объектов (например, 64 картинки в батче).
Таким образом, сеть принимает на вход тензор размера (BATCH_SIZE, H, W, 3). Можно “развернуть” каждую картинку в вектор-строку из H*W*3 чисел и работать со значениями в пикселях прямо как с признаками в машинном обучении, обычный Multilayer Perceptron (MLP) так и поступил бы, но это, честно говоря, такой себе бейзлайн, поскольку работа с пикселями как с вектор-строкой никак не учитывает, например, трансляционную инвариантность объектов на картинке. Тот же кот может быть как в середине фото, так и в углу, MLP эту закономерность не выучит.
Значит нужно что-то по-умнее, например, операция свёртки. И это уже про современное зрение, про свёрточные нейронные сети:
Код обучения свёрточной сети может выглядеть как-то так (на фреймворке PyTorch)
# взято из официального туториала:
# https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
Поскольку сейчас речь об обучении с учителем, для тренировки нейросети нам нужны несколько компонент:
- Данные (уже есть)
- Архитектура сети (самое интересное)
- Функция потерь, которая будет говорить, как нейросети учиться (здесь это будет кросс-энтропия)
- Метод оптимизации (будет менять веса сети в нужную сторону)
- Задать гиперпараметры архитектуры и оптимизатора (например, размер шага оптимизатора, количество нейронов в слоях, коэффициенты регуляризации)
В коде именно это и реализовано, сама свёрточная нейросеть описана в классе Net().
Если хочется не спеша и с начала узнать про свёртки и свёрточные сети, рекомендую лекцию в Deep Learning School (ФПМИ МФТИ) (на русском) на эту тему, и, конечно же, курс Стэнфорда cs231n (на английском).
Deep Learning School -- что это?
Deep Learning School при Лаборатории Инноватики ФПМИ МФТИ — это организация, которая активно занимается разработкой открытого русскоязычного курса по нейросетям. В статье я буду несколько раз ссылаться на эти видеоуроки.
Если вкратце, то операция свёртки позволяет находить паттерны на изображениях с учётом их вариативности. Когда обучаем свёрточные нейросети (eng: Convolutional Neural Networks), мы, по сути, находим фильтры свёрток (веса нейронов), которые хорошо описывают изображения, причём столь хорошо, чтобы можно было точно определить по ним класс. Способов построить такую сеть придумали много. Больше, чем вы думаете…
Архитектуры свёрточных нейросетей: 1000 способов достичь одной цели
Да-да, ещё один обзор архитектур. Но здесь я постараюсь сделать его максимально актуальным!
Сначала была LeNet, она помогла Яну ЛеКуну распознавать цифры в 1998 году. Это была первая свёрточная нейросеть для классификации. Её основная фишка была в том, что она в принципе стала использовать convolution и pooling операции.
Далее было некоторое затишье в развитии сеток, однако «железо» не стояло на месте, развивались эффективные вычисления на GPU и XLA. В 2012 году появилась AlexNet, она выстрелила в соревновании ILSVRC (ImageNet Large-Scale Visual Recognition Challenge).
Небольшое отступление про ILSVRC
К 2012 году был дан собран ImageNet, и для соревнования ILSVRC использовалась его подвыборка из тысяч картинок и 1000 классов. Сейчас в ImageNet ~14 миллионов картинок и 21841 класс (взято с оф. сайта), но для соревнования всё равно обычно выделяют лишь подмножество. ILSVRC тогда стал самым крупным ежегодным соревнованием по классификации изображений. Кстати, недавно придумали, как можно обучить на ImageNet'е за считанные минуты.
Именно на ImageNet (в ILSVRC) с 2010 по 2018 получали SOTA-нейросети в задаче классификации изображений. Правда уже с 2016 года более актуальны соревнования по локализации, детектирования и понимания сцены, а не классификацию.
Именно на ImageNet (в ILSVRC) с 2010 по 2018 получали SOTA-нейросети в задаче классификации изображений. Правда уже с 2016 года более актуальны соревнования по локализации, детектирования и понимания сцены, а не классификацию.
Обычно различные обзоры архитектур проливают свет на те, что были первыми на ILSVRC с 2010 до 2016 года, и на некоторые отдельные сети. Чтобы не загромождать рассказ, я поместил их под спойлер ниже, постаравшись подчеркнуть основные идеи:
Архитектуры с 2012 по 2015 год
| Год | Статья | Ключевая идея | Вес |
|---|---|---|---|
| 2012 | AlexNet | использовать две свёртки подряд; делить обучение сети на две параллельных ветки | 240 MB |
| 2013 | ZFNet | размер фильтров, число фильтров в слоях | -- |
| 2013 | Overfeat | один из первых нейросетевых детекторов | -- |
| 2014 | VGG | глубина сети (13-19 слоёв), использование нескольких блоков Conv-Conv-Pool с меньшим размером свёрток (3х3) | 549MB (VGG-19) |
| 2014 | Inception (v1) (она же GoogLeNet) | 1х1-свёртка (идея из Network-in-Network), auxilary losses (или deep supervision), стекинг выходов нескольких свёрток (Inception-блок) | -- |
| 2015 | ResNet | residual connections, очень большая глубина (152 слоя..) | 98 MB (ResNet-50), 232 MB (ResNet-152) |
Идеи всех этих архитектур (кроме ZFNet, её обычно мало упоминают) в своё время были новым словом в нейросетях для зрения. Однако и после 2015 было ещё очень много важных улучшений, например, Inception-ResNet, Xception, DenseNet, SENet. Ниже я постарался собрать их в одном месте.
Архитектуры с 2015 по 2019 год
| Год | Статья | Ключевая идея | Вес |
|---|---|---|---|
| 2015 | Inception v2 и v3 | разложение свёрток в свёртки 1хN и Nx1 | 92 MB |
| 2016 | Inception v4 и Inception-ResNet | совмещение Inception и ResNet | 215 MB |
| 2016-17 | ResNeXt | 2 место ILSVRC, использование многих веток ( “обобщённый” Inception-блок) | -- |
| 2017 | Xception | depthwise separable convolution, меньше весит при сравнимой с Inception точности | 88 MB |
| 2017 | DenseNet | Dense-блок; лёгкая, но точная | 33 MB (DenseNet-121), 80 MB (DenseNet-201) |
| 2018 | SENet | Squeeze-and-Excitation блок | 46 MB (SENet-Inception), 440 MB (SENet-154) |
Большинство из этих моделей для PyTorch можно найти здесь, а ещё есть вот такая классная штука.
Вы могли заметить, что всё это дело весит довольно много (хотелось бы 20 MB максимум, а то поменьше), в то время как сейчас повсеместно используют мобильные устройства и приобретает популярность IoT, а значит сетки хочется использовать и там.
Связь веса модели и скорости работы
Поскольку нейросети внутри себя лишь перемножают тензоры, то количество операций умножения (читай: количество весов) напрямую влияет на скорость работы (если не используются трудоёмкие пост- или предобработка). Сама скорость работы сети зависит от реализации (фреймворка), железа, на котором выполняется, и от размера входной картинки.
Авторы многих статей пошли по пути изобретения быстрых архитектур, я собрал их методы под спойлером ниже:
Легковесные архитектуры CNN
| Год | Статья | Ключевая идея | Вес | Пример реализации |
|---|---|---|---|---|
| 2016 | SqueezeNet | FireModule сжатия-разжатия | 0.5 MB | Caffe |
| 2017 | NASNet | получена нейронным поиском архитектур, это сеть из разряда AutoML | 23 MB | PyTorch |
| 2017 | ShuffleNet | pointwise group conv, channel shuffle | -- | Caffe |
| 2017 | MobileNet (v1) | depthwise separable convolutions и много других трюков | 16 MB | TensorFlow |
| 2018 | MobileNet (v2) | рекомендую эту статью на Хабре | 14 MB | Caffe |
| 2018 | SqueezeNext | см. картиночки в оригинальном репозитории | -- | Caffe |
| 2018 | MnasNet | нейропоиск архитектуры специально под мобильные устройства с помощью RL | ~2 MB | TensorFlow |
| 2019 | MobileNet (v3) | она вышла, пока я писал статью :) | -- | PyTorch |
Цифры во всех таблицах
Вы спросите: “Для чего ты написал про весь этот “зоопарк” моделей? И почему всё же задача классификации? Мы же хотим научить машины видеть, а классификация — лишь какая-то узкая задача..”. Дело в том, что нейросети для детектирования объектов, оценки позы/точек, ре-идентификации и поиска по картинке используют в качестве backbone именно модели для классификации, и уже от них зависит 80% успеха.
Но хочется как-то больше доверять CNN, а то напридумывали чёрных коробок, а что «внутри» — не очевидно. Чтобы лучше понимать механизм функционирования свёрточных сетей, исследователи придумали использовать визуализацию.
Визуализация свёрточных нейросетей: покажи мне страсть
Важным шагом к осознанию того, что происходит внутри свёрточных сетей, стала статья «Visualizing and Understanding Convolutional Networks». В ней авторы предложили несколько способов визуализации того, на что именно (на какие части картинки) реагируют нейроны в разных слоях CNN (рекомендую также посмотреть лекцию Стэнфорда на эту тему). Результаты получились весьма впечатляющие: авторы показали, что первые слои свёрточной сети реагируют на какие-то «низкоуровневые вещи» по типу краёв/углов/линий, а последние слои реагируют уже на целые части изображений (см. картинку ниже), то есть уже несут в себе некоторую семантику.
Далее проект по глубокой визуализации от Cornell University и компании продвинул визуализацию ещё дальше, в то время как знаменитый DeepDream научился искажать в
В 2017 году вышла очень хорошая статья на Distill, в которой они провели подробный анализ того, что «видит» каждый из слоёв, и совсем недавно (в марте 2019) Google изобрела активационные атласы: своеобразные карты, которые можно строить для каждого слоя сети, что приближает к понимаю общей картины работы CNN.
Если хочется самому поиграться с визуализацией, я бы рекомендовал Lucid и TensorSpace.
Окей, кажется, CNN и правда в некоторой степени можно верить. Нужно научиться использовать это и в других задачах, а не только в классификации. В этом нам помогут извлечение Embedding'ов картинок и Transfer Learning.
Я и сам своего рода хирург: извлекаем фичи из нейросетей
Представим, что есть картинка, и мы хотим найти похожие на неё визуально (так умеет, например, поиск по картинке в Яндекс.Картинки). Раньше (до нейросетей) инженеры для этого извлекали фичи вручную, например, придумывая что-то, что хорошо описывает картинку и позволит её сравнивать с другими. В основном, эти методы (HOG, SIFT) оперируют градиентами картинок, обычно именно эти штуки и называют «классическими» дескрипторами изображений. Особо интересующихся отсылаю к статье и к курсу Антона Конушина (это не реклама, просто курс хороший :)
Используя нейросети, мы можем не придумывать самому эти фичи и эвристики, а правильно обучить модель и потом взять за признаки картинки выход одного или нескольких слоёв сети.
Посмотрев на все архитектуры выше поближе, становится понятно, что в CNN для классификации есть два этапа:
1). Feature extractor слои для выделения информативных фич из картинок с помощью свёрточных слоёв
2). Обучение поверх этих фич Fully Connected (FC) слоёв-классификаторов
Embedding'и картинок (фичи) — это как раз про то, что можно брать в качестве информативного описания картинок их признаки после Feature extractor’а свёрточной нейросети (правда их можно по-разному агрегировать). То есть обучили сеть на классификацию, а потом просто берём выход перед классификационными слоями. Эти признаки называют фичами, нейросетевыми дескрипторамиили эмбеддингами картинки (правда обычно эмбеддинги принято в NLP, так как это зрение, я чаще буду говорить фичи). Обычно это какой-то числовой вектор, например, 128 чисел, с которым уже можно работать.
А как же автоэнкодеры?
Да, на самом деле фичи можно получить и автоэнкодерами. На моей практике делали по-разному, но, например, в статьях по ре-идентификации (о которой речь будет дальше), чаще всё же берут фичи после extractor'a, а не обучают для этого автоэнкодер. Мне кажется, стоит провести эксперименты в обоих направлениях, если стоит вопрос о том, что работает лучше.
Таким образом, пайплайн решения задачи поиска по картинке может быть устроен просто: прогоняем картинки через CNN, берём признаки с нужных слоёв и сравниваем эти фичи друг с другом у разных картинок. Например, банально считаем Евклидово расстояние этих векторов.
Transfer Learning — широко известная техника эффективного дообучения нейросетей, которые уже обучены на каком-то определённом датасете, под свою задачу. Часто ещё говорят Fine Tuning вместо Transfer Learning, в конспектах Стэнфордского курса cs231n эти понятия разделяют, мол, Transfer Learning — это общая идея, а Fine Tuning — одна из реализаций техники. Нам это в дальнейшем не так важно, главное понимать, что мы просто можем дообучить сеть хорошо предсказывать на новом датасете, стартуя не со случайных весов, а с обученных на каком-нибудь большом по типу ImageNet. Это особенно актуально, когда данных мало, а задачу хочется решить качественно.
Подробнее про Transfer Learning
Однако просто брать нужные фичи и делать дообучение с датасета на датасет может быть недостаточно, например, для задач поиска похожих лиц/людей/чего-то специфичного. Фотографии одного и того же человека визуально иногда могут быть даже более непохожи, чем фотографии разных людей. Нужно заставить сеть выделять именно те признаки, которые присущи одному человеку/объекту, даже если нам это сделать глазами сложно. Добро пожаловать в мир representation learning.
Держись рядом: representation learning для людей и лиц
Примечание по терминологии
Если почитать научные статьи, то иногда складывается впечатление, что некоторые авторы понимают словосочетание metric learning по-разному, и нет какого-то единого мнения на счёт того, какие методы называть metric learning, а какие нет. Именно поэтому в данной статье я решил избежать именно этого словосочетания и использовал более логичное representation learning, некоторые читатели могут с этим не согласиться — буду рад обсудить в комментариях.
Поставим задачи:
- Задача 1: есть галерея (набор) фотографий лиц людей, хотим, чтобы по новому фото сеть умела отвечать либо именем человека из галереи (мол, это он), либо говорила, что такого человека в галерее нет (и, возможно, добавляем в неё нового человека)

- Задача 2: то же самое, но работаем не с фотографиями лиц, а с кропами людей в полный рост

Первую задачу обычно называют распознаванием лиц, вторую — ре-идентификацией (сокращённо Reid). Я объединил их в один блок, поскольку в их решениях сегодня используются схожие идеи: для того, чтобы выучивать эффективные эмбеддинги картинок, которые могут справляться и с довольно сложными ситуациями, сегодня используют различные типы лоссов, такие как, например, triplet loss, quadruplet loss, contrastive-center loss, cosine loss.
Ещё есть прекрасные сиамские сети, однако их я, честно, сам не использовал. Кстати, “решает” не только сам лосс, а то, как для него семплировать пары positive’ов и negative’ов, это подчёркивают авторы статьи Sampling matters in deep embedding learning.
Суть всех этих лоссов и сиамских сетей проста — хотим, чтобы картинки одного класса (человека) в латентном пространстве фич (эмбеддингов) были “близко”, а разных классов (людей) — “далеко”. Близость обычно меряется так: берутся эмбеддинги картинок из нейросети (например, вектор из 128 чисел) и либо считаем обычное Евклидово расстояние между этими векторами, либо косинусную близость. Как именно мерить — лучше подбирать на своём датасете/задаче.
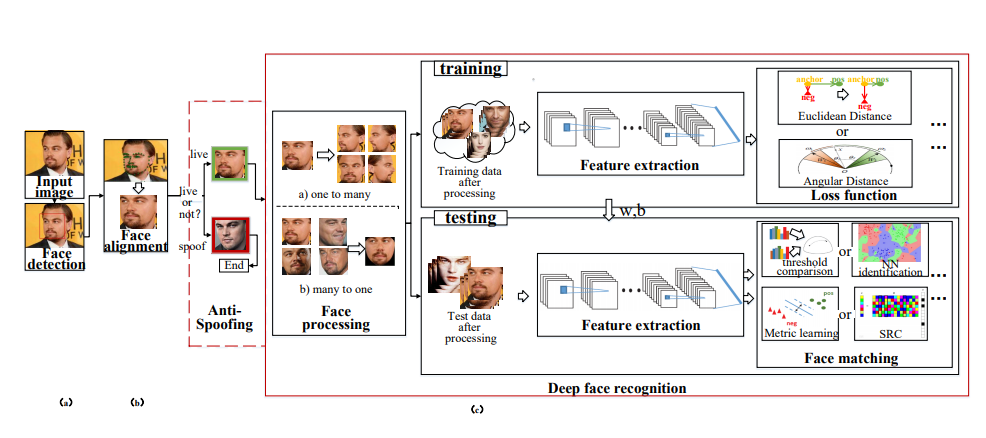
Схематично пайплайн решения задач на representation learning выглядит примерно так:
Но если быть более точным, то вот так
На стадии обучения: обучаем нейросеть либо на классификацию (Softmax + CrossEntropy), либо с помощью специального лосса (Triplet, Contrastive, etc.). Во втором случае ещё нужно правильно подбирать positive'ы и negative'ы в каждом батче
На стадии предсказания: если это был именно какой-то особый лосс по типу триплета, то он на вход принимал уже эмбеддинги — их и берём. Если была классификация, то тут нужно экспериментировать — можно брать фичи с какого-то из свёрточных слоёв, а можно и вероятности после классификатора (да, так делают и это работает). Далее ищем расстояние от пришедшей в тесте картинки до всех картинок из галереи и выдаём метку ближайшей. Расстояние меряем косинусом или Евклидовой метрикой
На стадии предсказания: если это был именно какой-то особый лосс по типу триплета, то он на вход принимал уже эмбеддинги — их и берём. Если была классификация, то тут нужно экспериментировать — можно брать фичи с какого-то из свёрточных слоёв, а можно и вероятности после классификатора (да, так делают и это работает). Далее ищем расстояние от пришедшей в тесте картинки до всех картинок из галереи и выдаём метку ближайшей. Расстояние меряем косинусом или Евклидовой метрикой
Конкретно по распознаванию лиц есть несколько хороших статей: статья-обзор (MUST READ!), FaceNet, ArcFace, CosFace.
Реализаций тоже немало: dlib, OpenFace, FaceNet repo, да и на Хабре про это уже давно было рассказано. Кажется, за последнее время добавились только ArcFace и CosFace (пишите в комментарии, если я здесь что-то упустил, буду рад узнать что-то ещё).
Однако сейчас больше мода не на распознавание лиц, а на их генерацию, не так ли?
В свою очередь, в задаче ре-идентификации сейчас бурная активность, статьи выходят каждый месяц, люди пробуют разные подходы, что-то работает уже сейчас, что-то пока ещё не очень.
Поясню суть задачи Reid на примере: есть галерея с кропами людей, например, 10 людей, у каждого по 5 кропов (могут быть с разных сторон), то есть 50 фотографий в галерее. Приходит новая детекция (кроп), и надо сказать, какой это человек из галереи или сказать, что его там нет и завести для него новый ID. Задача усложняется тем, что детекции человека приходят с разных ракурсов: спереди, сзади, сбоку,
К слову, в нашей лаборатории Reid — одна из ключевых задач. Статей выходит действительно немало, какие-то из них про новый более эффективный лосс, какие-то только про новый способ добычи negative'ов и positive'ов.
Хороший обзор старых методов по Reid есть в статье 2016 года. Сейчас, как я уже писал выше, применяются два подхода — классификация или representation learning. Однако есть специфика задачи, с ней исследователи борются по-разному, например, авторы Aligned Re-Id предложили специальным образом выравнивать фичи (да, они смогли улучшить сеть с помощью динамического программирования
Есть ещё несколько трюков
Демотиватор
Несмотря на все эти продвинутые методы, в моих экспериментах, почему-то, лучше всего себя показал именно подход с классификацией. Возможно, я что-то не учёл, но пока что немного грустно, что придумали столько всего, а в итоге работает старая добрая логистическая регрессия классификация. Но главное — пробовать и не сдаваться!
Из реализаций хочется обязательно упомянуть OpenReid и TorchReid. Обратите внимание на сам код — на мой взгляд, он написан грамотно с точки зрения архитектуры фреймворка, подробнее здесь. Плюс они оба на PyTorch, и в Readme есть много ссылок на статьи по Person Re-identification, это приятно.
Вообще особый спрос на face- и reid-алгоритмы сейчас в Китае (если вы понимаете, о чём я). Мы на очереди? Кто знает…
Слово про ускорение нейросетей
Мы уже говорили о том, что можно просто придумать легковесную архитектуру. Но как быть, если сеть уже обучена и она крута, а сжать её всё равно нужно? В таком случае может помочь один (или все) из следующих методов:
Ну и правило использовать не float64, а, например, float32 никто не отменял. Есть даже свежая статья про low-precision training. Недавно, кстати, Google представил MorphNet, которая (вроде как) помогает автоматически сжимать модель.
А что дальше?
Мы обсудили действительно много полезных и прикладных вещей в DL и CV: классификация, архитектуры сетей, визуализация, эмбеддинги. Однако в современном зрении есть ещё и другие важные задачи: детектирование, сегментация, понимание сцены. Если речь про видео, то хочется объекты трекать во времени, распознавать действия и понимать, что на видео происходит. Именно этим вещам и будет посвящена вторая часть обзора.
Stay tuned!
P. S.: Какое образование сейчас предлагает Физтех-школа ПМИ МФТИ?
ФПМИ МФТИ организует программу бакалавриата (кстати, теперь и на английском, для иностранных студентов), однако сейчас активно развиваются и магистерские программы, причём как очные, так и онлайн. Со всем списком образовательных возможностей ФПМИ МФТИ можно ознакомиться здесь. Если вам интересно, буду рад обсудить конкретные программы в комментариях или личных сообщениях, а то ведь Физтех уже не тот (в хорошем смысле).
Комментарии (5)

izakharkin Автор
21.05.2019 16:01В статье использованы изображения из открытых источников, все ссылки на них указаны здесь: bit.ly/2YIVokO
gkorepanovgk
23.05.2019 11:31+1Спасибо, прекрасная статья для ознакомления с совеременным состоянием DL (и отдельное спасибо за ссылки)!
Ждем вторую часть (надеюсь, техническую и понятную, а то сейчас все больше поверхностных обзоров успешных архитектур и проектов, а не статей с серьезным их описанием и анализом).izakharkin Автор
23.05.2019 12:40Спасибо! Рад, что статья оказалась полезной
Постараюсь сделать вторую часть достаточно подробной
djinninia
Спасибо за статью.
Какое аппаратное обеспечение вы используете в лаборатории?
izakharkin Автор
Спасибо!
Если речь идёт о видеокартах, то мы используем Nvidia GeForce GTX 1080 Ti. Если интересует более подробно, могу поделиться в личных сообщениях