
Меня зовут Марат Гаянов, я хочу поделиться с вами моим решением задачи с конкурса Best Reverser, показать, как сделать кейген для этого кейса.
Описание
В этом конкурсе участникам предоставляется ROM игры для Sega Mega Drive (best_reverser_phd9_rom_v4.bin).
Задача: подобрать такой ключ, который в паре с email-адресом участника будет признан валидным.
Итак, решение…
Инструменты
- IDA Pro 6.8
- Плагин smd_ida_tools
Проверка длины ключа
Программа принимает не всякий ключ: нужно заполнить поле целиком, это 16 символов. Если ключ короче, то вы увидите сообщение: «Wrong length! Try again…».
Попробуем найти эту строчку в программе, для чего воспользуемся бинарным поиском(Alt-B). Что мы найдем?
Найдем не только эту, но и рядом остальные служебные строки: «Wrong key! Try again…» и «YOU ARE THE BEST REVERSER!».


Ярлыки
WRONG_LENGTH_MSG, YOU_ARE_THE_BEST_MSG и WRONG_KEY_MSG поставил я, чтобы было удобно.Поставим брейк на чтение адреса
0x0000FDFA — выясним, кто работает с сообщением «Wrong length! Try again…». И запустим отладчик(он несколько раз остановится еще до того как можно будет вводить ключ, просто жмем F9 на каждой остановке). Вводим свой email, ключ ABCD.Отладчик приводит на
0x00006FF0 tst.b (a1)+: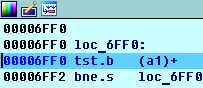
Ничего интересного в самом блоке нет. Гораздо интереснее, кто передает управление сюда. Смотрим колл стэк:

Жмем и попадем сюда — на инструкцию
0x00001D2A jsr (sub_6FC0).l:
Видим, что все возможные сообщения нашлись в одном месте. Но давайте узнаем, откуда передается управление в блок
WRONG_KEY_LEN_CASE_1D1C. Не будем ставить брейки, просто наведем курсор на стрелку, идущую к блоку. Вызывающий расположился на адресе 0x000017DE loc_17DE(который я переименую в CHECK_KEY_LEN):
Поставим брейк на адрес
0x000017EC cmpi.b 0x20 (a0, d0.l)(инструкция в этом контексте смотрит, нет ли пустого символа в конце массива символов ключа), перезапустимся, снова введем почту и ключ ABCD. Отладчик останавливается и показывает, что по адресу 0x00FF01C7(хранящемуся в этот момент в регистре a0) находится введенный ключ:
Это хорошая находка, через нее мы выцепим вообще все. Но сначала разметим байты ключа для удобства:

Прокрутив вверх с этого места, увидим что почта хранится рядом с ключом:

Мы погружаемся все глубже и глубже, и пришло время найти критерий правильности ключа. Вернее, первой половины ключа.
Критерий правильности первой половины ключа
Предварительные вычисления
Логично предположить, что сразу после проверки длины последуют другие операции с ключом. Рассмотрим блок сразу за проверкой:

В этом блоке идет предварительная работа. Функция
get_hash_2b(в оригинале было sub_1526) вызывается дважды. Сначала ей передается адрес первого байта ключа(регистр a0 содержит адрес KEY_BYTE_0), во второй раз — пятого(KEY_BYTE_4).Я назвал функцию так, потому что она считает что-то типа хэша размером 2 байта. Это самое понятное название, которое я подобрал.
Саму функцию рассматривать я не буду, а сразу напишу ее на питоне. Она делает простые вещи, но ее описание со скринами займет много места.
Самое важное, что о ней нужно сказать: на вход подается начальный адрес, а работа идет над 4-мя байтами от этого адреса. То есть подали на вход первый байт ключа, а функция будет работать с 1,2,3,4-ым. Подали пятый, функция работает с 5,6,7,8-ым. Иными словами, в этом блоке идут вычисления над первой половиной ключа. Результат пишется в регистр
d0.Итак, функция
get_hash_2b:# key_4s - четыре символа ключа
def get_hash_2b(key_4s):
# Правило преобразования байта
def transform(b):
# numbers -.
if b <= 0x39:
r = b - 0x30
# Letter case and @
else:
# @ABCDEF
if b <= 0x46:
r = b - 0x37
else:
# WXYZ
if b >= 0x57:
r = b - 0x57
# GHIJKLMNOPQRSTUV
else:
r = 0xff - (0x57 - b) + 1 # a9+b
return r
# Перевод в байты
key_4b = bytearray(key_4s, encoding="ascii")
# Каждый байт аргумента трансформируется
codes = [transform(b) for b in key_4b]
# А здесь они просто склеиваются
part0 = (codes[0] & 0xff) << 0xc
part1 = (codes[1] << 0x8) & 0xf00
part2 = (codes[2] << 0x4) & 0xf0
hash_2b = (part0 | part1) & 0xffff
hash_2b = (hash_2b | part2) & 0xffff
hash_2b = (hash_2b | (codes[3] & 0xf))
return hash_2bСразу напишем функцию декодирования хэша:
# Возвращает строку из 4-х символов
def decode_hash_4s(hash_2b):
# Правило преобразования байта
def transform(b):
if b <= 0x9:
return b + 0x30
if b <= 0xF:
return b + 0x37
if b >= 0x0:
return b + 0x57
return b - 0xa9
# Нарезаем отдельные байты из переданного хэша и переводи
b0 = transform(hash_2b >> 12)
b1 = transform((hash_2b & 0xfff) >> 8)
b2 = transform((hash_2b & 0xff) >> 4)
b3 = transform(hash_2b & 0xf)
# Склеиваем
key_4s = [chr(b0), chr(b1), chr(b2), chr(b3)]
key_4s = "".join(key_4s)
return key_4sЛучше функцию декодирования я не придумал, и она не совсем правильная. Поэтому я буду ее проверять так(не прямо сейчас, а значительно позже):
key_4s == decode_hash_4s(get_hash_2b(key_4s))Проверим работу
get_hash_2b. Нас интересует состояние регистра d0 после выполнения функции. Ставим брейки на 0x000017FE, 0x00001808, ключ вводим ABCDEFGHIJKLMNOP.

В регистр
d0 заносятся значения 0xABCD, 0xEF01. А что выдаст get_hash_2b?>>> first_hash = get_hash_2b("ABCD")
>>> hex(first_hash)
0xabcd
>>> second_hash = get_hash_2b("EFGH")
>>> hex(second_hash)
0xef01Проверка пройдена.
Далее производится
xor eor.w d0, d5, результат заносится в d5:>>> hex(0xabcd ^ 0xef01)
0x44cc
В получении такого хэша
0x44CC и состоят предварительные вычисления. Далее все только усложняется.Куда уплывает хэш
Нам никак не пройти дальше, если мы не узнаем как программа работает с хэшем. Наверняка он перемещается из
d5 в память, т.к. регистр пригодится где-нибудь еще. Отыскать такое событие мы можем через трассировку(наблюдая за d5), но не ручную, а автоматическую. Поможет такой скрипт:#include <idc.idc>
static main()
{
auto d5_val;
auto i;
for(;;)
{
StepOver();
GetDebuggerEvent(WFNE_SUSP, -1);
d5_val = GetRegValue("d5");
// Ловим факт изменения d5
if (d5_val != 0xFFFF44CC){
break;
}
}
}Напомню, что мы сейчас находимся на последнем брейке
0x00001808 eor.w d0, d5. Вставляем скрипт(Shift-F2), жмем RunСкрипт остановится на инструкции
0x00001C94 move.b (a0, a1.l), d5, но к этому моменту d5 уже очищен. Однако мы видим, что значение из d5 перемещается инструкцией 0x00001C56 move.w d5,a6: оно пишется в память по адресу 0x00FF0D46(2 байта).Запомним: хэш хранится по адресу
0x00FF0D46.
Отловим инструкции, которые читают из
0x00FF0D46-0x00FF0D47(ставим брейк на чтение). Попались 4 блока:



Как выбрать из них правильный/правильные?
Возвращаемся в начало:
Этот блок определяет, пойдет ли программа в
LOSER_CASE или в WINNER_CASE:
Видим, что в регистре
d1 должен быть ноль для победы.Где ставится ноль? Просто прокрутим наверх:
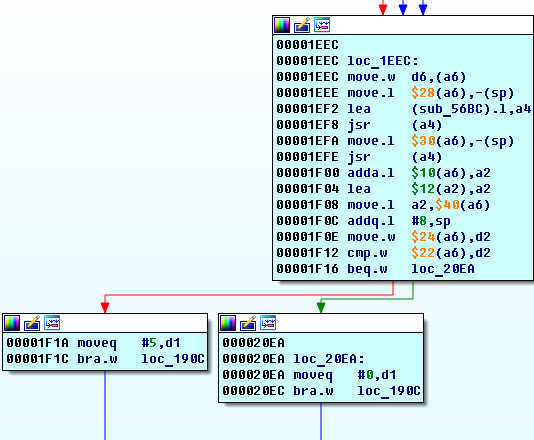
Если в блоке
loc_1EEC выполняется условие:*(a6 + 0x24) == *(a6 + 0x22)то мы получим ноль в
d5.Если мы поставим брейк на инструкцию
0x00001F16 beq.w loc_20EA, то увидим, что a6 + 0x24 = 0x00FF0D6A и там хранится значение 0x4840. А в a6 + 0x22 = 0x00FF0D68 хранится 0xCB4C.Если мы будем вводить разные ключи, почты, то увидим, что
0xCB4C - константа. Первая половина ключа будет принята, только если в 0x00FF0D6A будет тоже 0xCB4C. Это критерий правильности первой половины ключа.Узнаем, какие блоки пишут в
0x00FF0D6A — ставим брейк на запись, снова вводим почту и ключ.И вот этот блок
loc_EAC мы обнаружим(на самом деле их 3, но первые два просто обнуляют 0x00FF0D6A):
Этот блок принадлежит функции
sub_E3E.Через колл стэк выясняем, что функция
sub_E3E вызывается в блоках loc_1F94, loc_203E: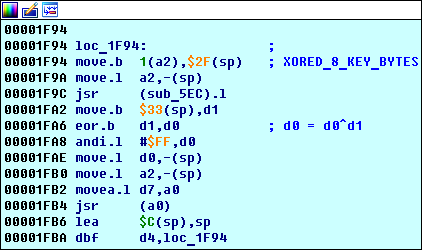

Помните, мы нашли 4 блока ранее?
loc_1F94 мы там видели — это начало главного алгоритма обработки ключа.Первый важный цикл loc_1F94
То, что
loc_1F94 является циклом видно из кода: он выполняется d4 раз (см. инструкцию 0x00001FBA d4,loc_1F94):На что обратить внимание:
- Есть функция
sub_5EC. - Инструкция 0x00001FB4 jsr (a0) вызывает функцию sub_E3E(это можно увидеть простой трассировкой).
Что здесь происходит:
- Функция
sub_5ECпишет результат своего выполнения в регистрd0(этому посвящена отдельный раздел ниже). - В регистр
d1сохраняется байт по адресуsp+0x33(0x00FFFF79, говорит нам отладчик), он равен второму байту из адреса хэша ключа(0x00FF0D47). Это легко доказать, если поставить брейк на запись по адресу0x00FFFF79: он сработает на инструкции0x00001F94 move.b 1(a2), 0x2F(sp). В регистреa2в этот момент хранится адрес0x00FF0D46— адрес хэша, то есть0x1(a2) = 0x00FF0D46 + 1— адрес второго байта хэша. - В регистр
d0пишетсяd0^d1.
- Получившийся результат xor'a отдается в функцию
sub_E3E, поведение которой зависит от своих прежних вычислений(показано ниже). - Повторить.
Сколько же раз этот цикл выполняется?
Выясним это. Запустим такой скрипт:
#include <idc.idc>
static main()
{
auto pc_val, d4_val, counter=0;
while(pc_val != 0x00001F16)
{
StepOver();
GetDebuggerEvent(WFNE_SUSP, -1);
pc_val = GetRegValue("pc");
if (pc_val == 0x00001F92){
counter++;
d4_val = GetRegValue("d4");
print(d4_val);
}
}
print(counter);
}0x00001F92 subq.l 0x1,d4 — здесь определяется, что будет в d4 непосредственно перед циклом:
Разбираемся с функцией sub_5EC.
sub_5EC
Значимый кусок кода:

где
0x2c(a2) всегда 0x00FF1D74.Этот кусок можно переписать так на псевдокоде:
d0 = a2 + 0x2C
*(a2+0x2C) = *(a2+0x2C) + 1 #*(0x00FF1D74) = *(0x00FF1D74) + 1
result = *(d0) & 0xFFТо есть 4 байта из
0x00FF1D74 являются адресом, т.к. с ними обращаются как с указателем.Как переписать функцию
sub_5EC на питоне?- Либо сделать дамп памяти и работать с ним.
- Либо просто записать все выдаваемые значения.
Второй способ мне нравится больше, но что, если при разных данных авторизации выдаваемые значения разные? Проверим это.
Поможет в этом скрипт:
#include <idc.idc>
static main()
{
auto pc_val=0, d0_val;
while(pc_val != 0x00001F16){
pc_val = GetRegValue("pc");
if (pc_val == 0x00001F9C)
StepInto();
else
StepOver();
GetDebuggerEvent(WFNE_SUSP, -1);
if (pc_val == 0x00000674){
d0_val = GetRegValue("d0") & 0xFF;
print(d0_val);
}
}
}Я просто сравнивал выводы в консоль при разных ключах, почтах.
Запустив скрипт несколько раз при разных ключах, мы увидим, что функция
sub_5EC всегда возвращает очередное значение из массива:def sub_5EC_gen():
dump = [0x92, 0x8A, 0xDC, 0xDC, 0x94, 0x3B, 0xE4, 0xE4,
0xFC, 0xB3, 0xDC, 0xEE, 0xF4, 0xB4, 0xDC, 0xDE,
0xFE, 0x68, 0x4A, 0xBD, 0x91, 0xD5, 0x0A, 0x27,
0xED, 0xFF, 0xC2, 0xA5, 0xD6, 0xBF, 0xDE, 0xFA,
0xA6, 0x72, 0xBF, 0x1A, 0xF6, 0xFA, 0xE4, 0xE7,
0xFA, 0xF7, 0xF6, 0xD6, 0x91, 0xB4, 0xB4, 0xB5,
0xB4, 0xF4, 0xA4, 0xF4, 0xF4, 0xB7, 0xF6, 0x09,
0x20, 0xB7, 0x86, 0xF6, 0xE6, 0xF4, 0xE4, 0xC6,
0xFE, 0xF6, 0x9D, 0x11, 0xD4, 0xFF, 0xB5, 0x68,
0x4A, 0xB8, 0xD4, 0xF7, 0xAE, 0xFF, 0x1C, 0xB7,
0x4C, 0xBF, 0xAD, 0x72, 0x4B, 0xBF, 0xAA, 0x3D,
0xB5, 0x7D, 0xB5, 0x3D, 0xB9, 0x7D, 0xD9, 0x7D,
0xB1, 0x13, 0xE1, 0xE1, 0x02, 0x15, 0xB3, 0xA3,
0xB3, 0x88, 0x9E, 0x2C, 0xB0, 0x8F]
l = len(dump)
offset = 0
while offset < l:
yield dump[offset]
offset += 1Итак, функция
sub_5EC готова.На очереди
sub_E3E.sub_E3E
Значимый кусок кода:
Расшифруем:
Эта конструкция выдает адрес, куда сохранять d2, который сейчас содержит входной аргумент.
Регистр a2 хранит значение 0xFF0D46, a2 + 0x34 = 0xFF0D7A
d0 = *(a2 + 0x34)
*(a2 + 0x34) = *(a2 + 0x34) + 1
Входной аргумент сохраняется, в регистре a0 адрес этого сохранения
a0 = d0
*(a0) = d2
Здесь вычисляется некий offset, который сохраняется в регистре d2.
Регистр a2 хранит значение 0xFF0D46, a2 + 0x24 = 0xFF0D6A - это место, где хранится
предыдущий результат функции(см. конец) либо 0x00000000, если функция вызывается впервые
d0 = *(a2 + 0x24)
d2 = d0 ^ d2
d2 = d2 & 0xFF
d2 = d2 + d2
Вытаскиваются какие-то 2 байта по адресу 0x00011FC0 + d2, это область ROM, поэтому
содержимое 0x00011FC0 + d2 постоянно
a0 = 0x00011FC0
d2 = *(a0 + d2)
Предыдущий результат этой функции сдвигается на 8 бит
d0 = d0 >> 8
Результат
d2 = d0 ^ d2
Записывается текущий результат функции
*(a2 + 0x24) = d2Функция
sub_E3E сводится к таким шагам:- Сохранить входной аргумент в массив.
- Рассчитать смещение offset.
- Вытащить 2 байта по адресу
0x00011FC0 + offset(ROM). - Результат =
(предыдущий результат >> 8) ^ (2 байта 0x00011FC0 + offset).
Представим функцию
sub_E3E в таком виде:def sub_E3E(prev_sub_E3E_result, d2, d2_storage):
def calc_offset():
return 2 * ((prev_sub_E3E_result ^ d2) & 0xff)
d2_storage.append(d2)
offset = calc_offset()
with open("dump_00011FC0", 'rb') as f:
dump_00011FC0_4096b = f.read()
some = dump_00011FC0_4096b[offset:offset + 2]
some = int.from_bytes(some, byteorder="big")
prev_sub_E3E_result = prev_sub_E3E_result >> 8
return prev_sub_E3E_result ^ somedump_00011FC0 — это просто файл, куда я сохранил 4096 байт из [0x00011FC0:00011FC0+4096].Активность около 1FC4
Адрес
0x00001FC4 мы еще не видели, но его легко найти, потому что блок идет почти сразу за первым циклом.
Этот блок меняет содержимое по адресу
0x00FF0D46 (регистр a2), а именно там хранится хэш ключа, поэтому мы сейчас и изучаем этот блок. Посмотрим, что здесь происходит.- Условие, которое определяет, будет выбрана левая или правая ветка, такое:
(хэш первой половины ключа) & 0b1 != 0. То есть проверяется первый бит хэша. - Если присмотреться к обоим веткам, станет видно:
- В обоих случаях происходит сдвиг вправо на 1 бит.
- В левой ветке над хэшем производится операция
ИЛИ 0x8000. - В обоих случаях по адресу
0x00FF0D46записывается обработанное значение хэша, то есть хэш заменяется на новое значение. - Дальнейшие вычисления некритичны, потому что, грубо говоря, нет операций записи в
(a2)(нет инструкции, где вторым операндом был бы(a2)).
Представим блок так:
def transform(hash_2b):
new = hash_2b >> 1
if hash_2b & 0b1 != 0:
new = new | 0x8000
return newВторой важный цикл loc_203E
loc_203E — цикл, т.к. 0x0000206C bne.s loc_203E.Этот цикл досчитывает хэш и вот его главная особенность:
jsr (a0) — это вызов функции sub_E3E, которую мы уже рассмотрели — она опирается на предыдущий результат своей же работы и на некий входной аргумент(выше он передавался через регистр d2, а здесь через d0).Давайте выясним, что передается ей через регистр
d0.Мы уже встречались с конструкцией
0x34(a2) — туда функция sub_E3E сохраняет переданный аргумент. Значит, в этом цикле используются ранее переданные аргументы. Но не все.Расшифруем часть кода:
Здесь берется 2 байта из адреса a2+0x1C
move.w 0x1C(a2), d0
Инвертируется
neg.l d0
В регистр a0 пишется адрес последнего сохраненного аргумента функции sub_E3E
movea.l 0x34(a2), a0
Наконец, в d0 пишутся 2 байта по адресу a0-d0(вычитание потому что d0 инвертирован)
move.b (a0, d0.l), d0
Суть сводится к простому действию: на каждой итерации взять
d0 сохраненный аргумент с конца массива. То есть если в d0 хранится 4, то берем четвертый с конца элемент.Раз так, то какие конкретно принимает значения
d0? Здесь я обошелся без скриптов, а просто выписал их, поставив брейк на начало этого блока. Вот они: 0x04, 0x04, 0x04, 0x1C, 0x1A, 0x1A, 0x06, 0x42, 0x02.Теперь у нас есть все, чтобы написать полную функцию вычисления хэша ключа.
Полная функция вычисления хэша
def finish_hash(hash_2b):
# Правило преобразования хэша
def transform(hash_2b):
new = hash_2b >> 1
if hash_2b & 0b1 != 0:
new = new | 0x8000
return new
main_cycle_counter = [17, 2, 2, 3, 4, 38, 10, 30, 4]
second_cycle_counter = [2, 2, 2, 2, 2, 4, 2, 4, 28]
counters = list(zip(main_cycle_counter, second_cycle_counter))
d2_storage = []
storage_offsets = [0x04, 0x04, 0x04, 0x1C, 0x1A, 0x1A, 0x06, 0x42, 0x02]
prev_sub_E3E_result = 0x0000
sub_5EC = sub_5EC_gen()
for i in range(9):
c = counters[i]
for _ in range(c[0]):
d0 = next(sub_5EC)
d1 = hash_2b & 0xff
d2 = d0 ^ d1
curr_sub_E3E_result = sub_E3E(prev_sub_E3E_result, d2, d2_storage)
prev_sub_E3E_result = curr_sub_E3E_result
storage_offset = storage_offsets.pop(0)
for _ in range(c[1]):
d2 = d2_storage[-storage_offset]
curr_sub_E3E_result = sub_E3E(prev_sub_E3E_result, d2, d2_storage)
prev_sub_E3E_result = curr_sub_E3E_result
hash_2b = transform(hash_2b)
return curr_sub_E3E_resultПроверка работоспособности
- В отладчике ставим брейк на адрес
0x0000180A move.l 0x1000,(sp)(сразу после вычисления хэша). - Брейк на адрес
0x00001F16 beq.w loc_20EA(сравнение окончательного хэша с константой0xCB4C). - В программе вводим ключ
ABCDEFGHIJKLMNOP, жмемEnter. - Отладчик останавливается на
0x0000180A, и мы видим, что в регистрd5записалось значение0xFFFF44CC,0x44CC— первый хэш. - Запускаем отладчик дальше.
- Останавливаемся на
0x00001F16и видим, что по адресу0x00FF0D6Aлежит0x4840— окончательный хэш
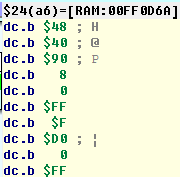
- Теперь проверям нашу функцию finish_hash(hash_2b):
>>> r = finish_hash(0x44CC) >>> print(hex(r)) 0x4840
Ищем правильный ключ 1
Правильный ключ — этот ключ, у которого окончательный хэш равен
0xCB4C(выясняли выше). Отсюда вопрос: каким должен быть первый хэш, чтобы окончательный стал 0xCB4C?Теперь это просто выяснить:
def find_CB4C():
result = []
for hash_2b in range(0xFFFF+1):
final_hash = finish_hash(hash_2b)
if final_hash == 0xCB4C:
result.append(hash_2b)
return result
>>> r = find_CB4C()
>>> print(r)Вывод программы говорит о том, что вариант один: первый хэш должен быть
0xFEDC.Какие символы нам нужны, чтобы их первый хэш был
0xFEDC?Так как
0xFEDC = хэш_первых_4_символов ^ хэш_вторых_4_символов, то найти нужно только хэш_первых_4_символов, потому что хэш_вторых_4_символов = хэш_первых_4_символов ^ 0xFEDC. А затем декодировать оба хэша.Алгоритм такой:
def get_first_half():
from collections import deque
from random import randint
def get_pairs():
pairs = []
for i in range(0xFFFF + 1):
pair = (i, i ^ 0xFEDC)
pairs.append(pair)
pairs = deque(pairs)
pairs.rotate(randint(0, 0xFFFF))
return list(pairs)
pairs = get_pairs()
for pair in pairs:
key_4s_0 = decode_hash_4s(pair[0])
key_4s_1 = decode_hash_4s(pair[1])
hash_2b_0 = get_hash_2b(key_4s_0)
hash_2b_1 = get_hash_2b(key_4s_1)
if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]:
return key_4s_0, key_4s_1Вариантов куча, выбирайте любой.
Ищем правильный ключ 2
Первая половина ключа готова, что со второй?
Эта самая легкая часть.
Ответственный кусок кода располагается на
0x00FF2012, до него я добрался ручной трассировкой, начав с адреса 0x00001F16 beg.w loc_20EA(валидация первой половины ключа). В регистре a0 находится адрес почты, loc_FF2012 является циклом, т.к. bne.s loc_FF2012. Он выполняется до тех пор, пока есть *(a0+d0)(очередной байт почты).А инструкция
jsr (a3) вызывает уже знакомую функцию get_hash_2b, которая теперь работает со второй половиной ключа.
Сделаем код понятнее:
while(d1 != 0x20){
Подсчитывается длина почты
d2++
d1 = d1 & 0xFF
Подсчитывается сумма байтов почты
d3 = d3 + d1
d0 = 0
d0 = d2
Очередной байт почты
d1 = *(a0+d0)
}
d0 = get_hash_2b(key_byte_8)
d3 = d0^d3
d0 = get_hash_2b(key_byte_12)
d2 = d2 - 1
d2 = d2 << 8
d2 = d0^d2
if (d2 == d3)
success_branchВ регистре
d2 — (длина почты-1) << 8. В d3 — сумма байтов символов почты.Критерий корректности получается таким:
третья_четверть_ключа ^ d2 == последняя_четверть_ключа_2 ^ d3.Напишем функцию подбора второй половины ключа:
def get_second_half(email):
from collections import deque
from random import randint
def get_koeff():
k1 = sum([ord(c) for c in email])
k2 = (len(email) - 1) << 8
return k1, k2
def get_pairs(k1, k2):
pairs = []
for a in range(0xFFFF + 1):
pair = (a, (a ^ k1) ^ k2)
pairs.append(pair)
pairs = deque(pairs)
pairs.rotate(randint(0, 0xFFFF))
return list(pairs)
k1, k2 = get_koeff()
pairs = get_pairs(k1, k2)
for pair in pairs:
key_4s_0 = decode_hash_4s(pair[0])
key_4s_1 = decode_hash_4s(pair[1])
hash_2b_0 = get_hash_2b(key_4s_0)
hash_2b_1 = get_hash_2b(key_4s_1)
if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]:
return key_4s_0, key_4s_1Кейген
Почта обязательно капсом.
def keygen(email):
first_half = get_first_half()
second_half = get_second_half(email)
return "".join(first_half) + "".join(second_half)
>>> email = "M.GAYANOV@GMAIL.COM"
>>> print(keygen(email))
2A4FD493BA32AD75
Спасибо за внимание! Весь код доступен здесь.
Комментарии (13)

vient
24.05.2019 17:37+2Достаточно подробно и понятно описано, спасибо. Замечу несколько вещей:
1. В функцияхdecode_hash_4sиget_hash_2bописана просто кодировка/декодировка байтов в hex
2. То, что у вас описано вsub_E3E, является, на самом деле, вычислением CRC-16 в варианте CRC-16-IBM.
3. В целом, вся вторая часть была архивом известного формата, как я понял, и тулзы для работы с ним можно найти у того же человека, который делал модули для иды, и который разработал задание: rnc_propack_source. Я нашёл этот репозиторий только после сдачи задания, и не проверял, что эти сорцы действительно полезные, но формат архива явно тот же самый, совпадает magic.
Если интересно, моё решение можно найти тут. Я там зачем-то переписал всю логику работы с этим RNC архивом, надо было тоже из дебаггера вытащить сразу нужные оффсеты, конечно.
DrMefistO
24.05.2019 17:39+1Да, мой расчёт был на то, что поищут утилиты и код, который уже есть)
Но, даже круче, что решение было сделано иным способом!

xoo Автор
24.05.2019 22:53Я все это время подозревал, что где-то можно сделать решение по-проще. И ждал тут тех, кто подскажет, спасибо, что поделились решением)
0ri0n
Молодец!..
Жалко что реверсил не на гидре. Хотелось бы посмотреть как на ней справляться с такими задачами и осилила бы она ее. (Гидра)
xoo Автор
Я начал на гидре на самом деле, но как-то пока непривычно)