

Автор: Людмила Дежкина, Solution-архитектор, DataArt
Около полугода наша команда работает над Predictive Maintenance Platform — системой, которая должна предсказывать возможные ошибки и поломки оборудования. Это направление стоит на стыке IoT и Machine Learning, работать здесь приходится и с железом и, собственно, с программным обеспечением. О том, как мы строим Serverless ML с библиотекой Scikit-learn на AWS, и пойдет речь в этой статье. Я расскажу о сложностях, с которыми мы столкнулись, и об инструментах, используя которые, сэкономили время.
На всякий случай, немного о себе.
Программированием я занимаюсь уже более 12 лет, и за это время участвовала в самых разных проектах. В том числе, игровых, e-commerce, highload и Big Data. Около трех лет занимаюсь проектами, связанными с Machine Learning и Deep Learning.

Так выглядели требования, выдвинутые заказчиком с самого начала
Собеседование с клиентом было сложным, в основном мы говорили о машинном обучении, нас много спрашивали об алгоритмах и конкретном личном опыте. Но не буду скромничать — в этой части мы изначально разбираемся очень хорошо. Первым камнем преткновения стал кусок Hardware, который содержит система. Все-таки, опыт работы с железом лично у меня не такой разнообразный.
Заказчик объяснил нам: «Смотрите, у нас есть конвейер». Мне в голову сразу пришла лента транспортера на кассе в супермаркете. Что и чему там можно научить? Но довольно быстро выяснилось, что за словом конвейер скрывается целый сортировочный центр площадью 300–400 кв. м, и на самом деле, конвейеров там много. Т. е. между собой нужно связать множество элементов оборудования: датчиков, роботов. Классическая иллюстрация понятия «Индустриальной революции 4.0», в рамках которой как раз и сближаются IoT и ML.
Тема Predictive Maintenance точно будет на подъеме еще как минимум два-три года. Каждый конвейер раскладываются на элементы: от робота или мотора, движущего транспортную ленту, до отдельного подшипника. При этом, если из строя выходит любая из этих деталей, останавливается вся система, а в некоторых случаях час простоя конвейера может обойтись в полтора миллиона долларов (это не преувеличение!).
Один из наших заказчиков занимается грузоперевозками и логистикой: на его базе роботы разгружают 40 грузовиков за 8 минут. Никаких задержек здесь быть не может, машины должны прийти и уйти в соответствии с очень жестким расписанием, никто ничего не чинит в процессе разгрузки. Вообще на этой базе находятся всего два-три человека с планшетами. Но есть и немного другой мир, где все выглядит не настолько модным, и где непосредственно на объекте находятся механики в перчатках и без компьютеров.
Первый наш маленький проект-прототип состоял примерно из 90 сенсоров, и все шло отлично, пока проект не пришлось масштабировать. Чтобы экипировать самую маленькую отдельную часть реального сортировочного центра, сенсоров требуется уже около 550.
PLC и сенсоры
Programmable logic controller — маленький компьютер с вшитой циклической программой — чаще всего используют для автоматизации технологического процесса. Собственно, с помощью PLС мы и снимаем с сенсоров показания: например, ускорение и скорость, уровень напряжения, вибрацию по осям, температуру (в нашем случае — 17 показателей). Датчики при этом нередко ошибаются. Хотя нашему проекту уже более 8 месяцев, у нас до сих пор работает собственная лаборатория, где мы экспериментируем с сенсорами, подбирая наиболее подходящие модели. Сейчас, например, мы рассматриваем возможность использования ультразвуковых датчиков.
Лично я впервые увидела PLC, только попав на объект заказчика. Как разработчик я с ними прежде никогда не сталкивалась, и это было довольно неприятно: как только мы в разговоре углублялись дальше двух, трех и четырехфазных моторов, я начинала терять нить. Примерно 80 % слов по-прежнему были понятными, но общий смысл упорно ускользал. Вообще это серьезная проблема, корни которой в достаточно высоком пороге входа в программирование PLC — такой микрокомпьютер, где вы действительно сможете что-то сделать, стоит не меньше 200–300 долларов. Само программирование при этом несложное, и проблемы начинаются, только когда датчик крепится к реальному конвейеру или мотору.

Стандартный набор датчиков «37 в 1»
Сенсоры, как вы понимаете, бывают разные. Самые простые, которые нам удалось найти, стоят от 18 долларов. Главная характеристика — “bandwidth and resolution” — сколько данных сенсор передает за минуту. По собственному опыту могу сказать, что если производителем заявлены, скажем, 30 датапойнтов в минуту, в реальности их количество вряд ли будет больше 15. И в этом тоже кроется серьезная проблема: тема модная, и некоторые компании стараются заработать на этом хайпе. Мы тестировали сенсоры стоимостью $ 158, пропускная способность которых теоретически позволяла просто выбросить часть нашего кода. Но на поверку они оказались абсолютным аналогом тех самых устройств по $ 18 за штуку.
Первый этап: крепим сенсоры, собираем данные
Собственно, первая фаза проекта заключалась в инсталляции hardware, сама установка — процесс долгий и нудный. Это тоже целая наука — от того как ты прикрепишь сенсор на мотор или бокс, могут зависеть данные, которые он в итоге соберет. У нас был случай, когда один из двух одинаковых сенсоров прикрепили внутри коробки, а другой — снаружи. Логика подсказывает, что внутри температура должна быть выше, но собранные данные говорили об обратном. Получалось, что система дала сбой, но когда разработчик приехал на завод, он увидел, что датчик стоит не просто в коробке, а прямо на вентиляторе, расположенном там же.
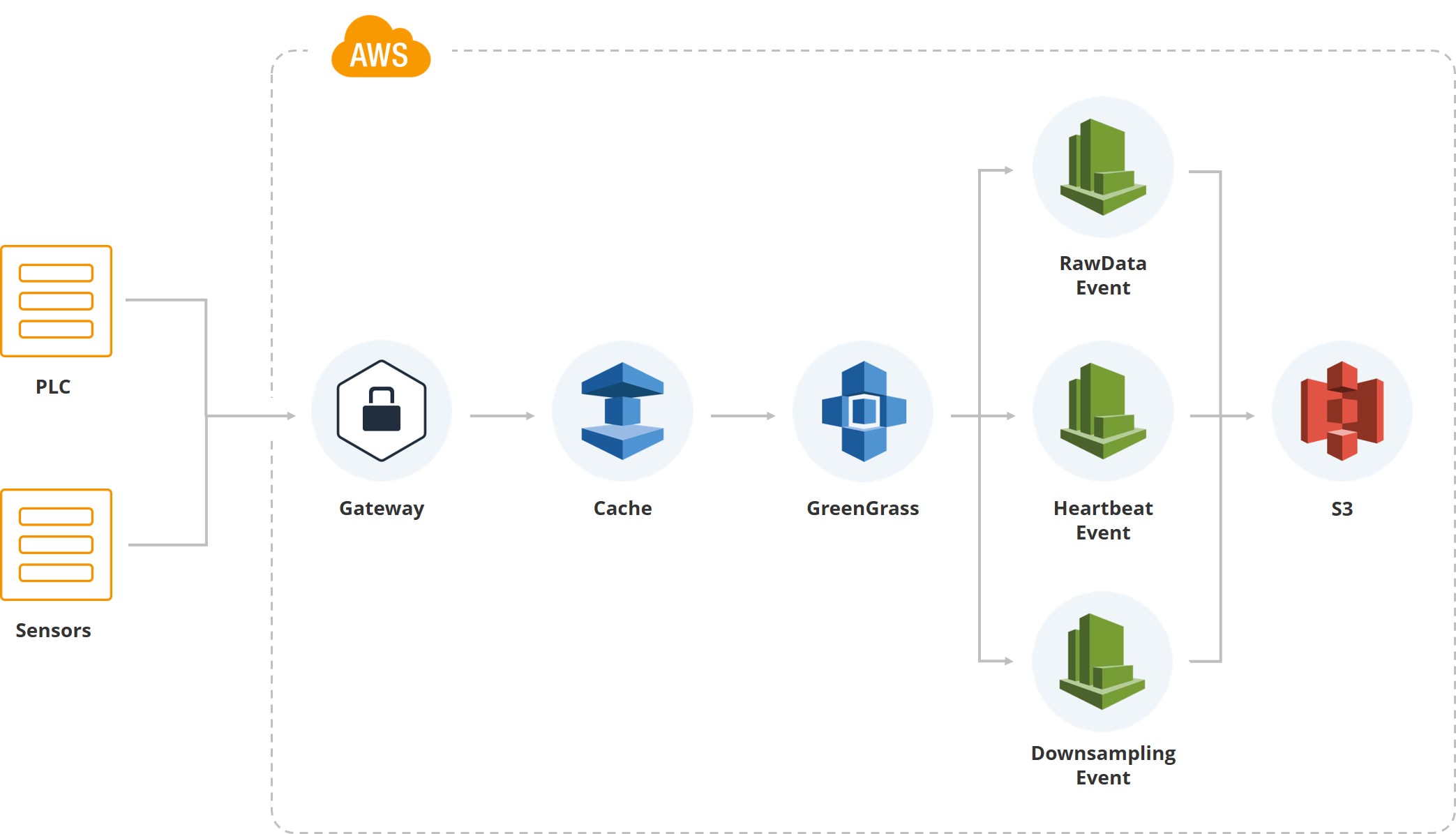
На этой иллюстрации показано, как первые данные попадали в систему. У нас есть gateway, есть PLC и сенсоры, связанные с ним. Дальше, естественно, кеш — оборудование как правило работает на мобильных карточках и все данные передаются через мобильный интернет. Т. к. один из сортировочных центров заказчика расположен в местности, где часто бывают ураганы, и соединение может обрываться, мы накапливаем данные на gateway, пока оно не восстановится.
Дальше используем сервис Greengrass от Amazon, который пускает данные внутрь облачной системы (AWS).
Как только данные оказались внутри облака, срабатывает куча ивентов. Например, у нас есть ивент для raw data, который сохраняет данные файловой системы. Есть “heartbeat” для индикации нормальной работоспособности системы. Есть “downsampling”, который используется для показа на UI, и для обработки (берется среднее значение, допустим, за минуту по определенному показателю). Т. е., кроме сырых данных, у нас есть даунсемпл-данные, которые попадают на экраны пользователей, мониторящих систему.
Raw data хранятся в Parquet-формате. Вначале мы выбрали JSON, потом попробовали CSV, но в итоге пришли к тому, что и команду аналитиков, и команду разработчиков удовлетворяет именно «паркет».
Собственно, первая версия системы была построена на DynamoDB, и ничего плохого сказать про эту базу данных я не хочу. Просто, как только у нас появились аналитики — математики, которые должны работать с полученными данными — выяснилось, что язык запросов на DynamoDB для них слишком сложен. Им приходилось специально готовить данные для ML и аналитики. Поэтому мы остановились на Athena — редакторе запросов в AWS. Для нас его преимущества заключаются в том, что он позволяет читать данные Parquet, писать SQL, а результаты собирать в CSV-файл. Как раз то, что нужно команде аналитиков.
Второй этап: что мы анализируем?
Итак, с одного маленького объекта мы собрали примерно 3 Гб сырых данных. Теперь нам известно многое о температуре, вибрации и ускорении по осям. Значит, наступило время собираться нашим математикам, чтобы понять, как и, собственно, что мы пытаемся предсказать на основе этой информации.
Цель — минимизировать время простоя оборудования.

На этот завод Coca-Cola люди заходят только тогда, когда получают сигнал о поломке, утечке масла или, скажем, луже на полу. Стоимость одного робота начинается с $ 30 000 долларов, зато на них строится практически все производство

На шести заводах Tesla работает порядка 10 000 человек, и для производства такого масштаба это совсем немного. Интересно, что заводы Mercedes автоматизированы в еще гораздо большей степени. Понятно, что все задействованные роботы нуждаются в постоянном мониторинге
Чем дороже робот, тем меньше вибрирует его рабочая часть. При простых действиях это может не иметь решающего значения, но более тонкие операция, скажем, с горлышком бутылки, требуют свести ее к минимуму. Конечно, уровень вибрации дорогостоящих машин нужно постоянно контролировать.
Сервисы, которые экономят время
Мы запустили первую инсталляцию чуть более чем за три месяца, и я считаю, что это быстро.

Собственно, это основные пять пунктов, которые позволили сэкономить девелоперские усилия
Первое, за счет чего мы сократили сроки, — большая часть системы построена на AWS, которая масштабируется сама по себе. Как только количество пользователей превышает определенный рубеж, срабатывает автоскейлинг, и никому из команды не приходится тратить на это времени.
Я хотела бы обратить внимание на два нюанса. Первое — мы работаем с большими объемами данных, и в первой версии системы у нас были пайплайны, для того, чтобы делать бекапы. Через какое-то время данных стало слишком много, и держать копии для них стало слишком затратным. Тогда мы просто оставили Raw data, лежащие в bucket, доступными только для чтения, запретив их удалять, и отказались от бекапов.
Наша система предполагает непрерывную интеграцию, для поддержки нового сайта и на новую инсталляцию уходит не так много времени.
Понятно, что реалтайм построен на ивентах. Хотя, конечно, возникают сложности из-за того, что некоторые ивенты срабатывают по два раза или система теряет связь, например, из-за погодных условий.
Шифрование данных, а этого в обязательном порядке требовал заказчик, автоматически происходит в AWS. У каждого клиента свой бакет, и мы вообще не занимаемся тем, что шифруем данные.
Встреча с аналитиками
Самый первый код мы получали в формате PDF вместе с просьбой имплементировать ту или иную модель. Пока мы не начали получать код в виде .ipynb, было тревожно, но дело в том, что аналитики — математики, далекие от программирования. Все наши операции происходят в облаке, скачивать данные мы не разрешаем. Вместе все эти моменты подтолкнули нас к тому, чтобы попробовать платформу SageMaker.
SageMaker позволяет «из коробки» использовать около 80 алгоритмов, он включает фреймворки: Caffe2, Mxnet, Gluon, TensorFlow, Pytorch, Microsoft cognitive tool kit. На данный момент мы пользуемся Keras+ TensorFlow, но все, кроме Microsoft cognitive toolkit, успели попробовать. Такой широкий охват позволяет нам не ограничивать собственную аналитическую команду.

Первые три-четыре месяца всю работу делали люди при помощи простой математики, никакого ML по-настоящему еще не было. Часть системы базируется на сугубо математических закономерностях, и она рассчитана на статистические данные. Т. е. мы мониторим средний уровень температуры, и если видим, что он зашкаливает, срабатывают оповещения.
Затем следует обучение модели. Все выглядит легко и просто, таким и кажется до начала имплементации.
Build, train, deploy…

Вкратце расскажу, как мы выходили из положения. Посмотрите на второй столбец: собираем данные, обрабатываем, чистим, используется S3 bucket и Glue для запуска ивентов и создания “partitions”. У нас все данные разложены по партициям для Athena, это тоже важный нюанс, потому что Athena строится поверх S3. Сама по себе Athena очень дешевая. Но мы платим за то, что читаем данные и достаем их из S3, т. ч. каждый запрос может обойтись очень дорого. Поэтому у нас большая система partitions.
У нас есть даунтсемплер. И Amazon EMR, который позволяет быстро собирать данные. Собственно, для feature engineering у нас в клауде для каждого аналитика поднят Jupyter Notebook — это их собственный инстанс. И анализируют они все непосредственно в самом облаке.
Благодаря SageMaker мы, прежде всего, смогли пропустить этап Training Clusters. Если бы мы этой платформы не использовали, нам бы пришлось поднимать кластеры в Amazon, и кто-то из DevOps-инженеров был бы должен за ними следить. SageMaker позволяет при помощи параметров метода, имиджа на Docker поднимать кластер, остается просто указывать количество инстансов в параметре, которое вы хотите использовать.
Далее нам не приходится заниматься масштабированием. Если мы хотим обработать какой-то большой алгоритм или нам нужно срочно что-то подсчитать, мы включаем автоскейлинг (там уже все зависит от того, что вы хотите использовать CPU или GPU).
Кроме того, все модели у нас зашифрованы: это тоже идет из коробки в SageMaker — бинарники, которые лежат в S3.
Model Deployment
Мы подбираемся к первой модели, развернутой в окружении. Собственно, SageMaker позволяет сохранять артефакты модели, но как раз на этом этапе у нас было много споров, потому что у SageMaker есть собственный формат модели. Мы хотели уйти от него, избавляясь от ограничений, поэтому наши модели хранятся в формате pickle, чтобы при желании мы могли использовать хоть Keras, хоть TensorFlow или что-то еще. Хотя мы и использовали первую модель именно от SageMaker, как она есть — через нативный API.
SageMaker позволяет упростить работу еще на трех этапах. Каждый раз, когда вы пытаетесь что-то предсказать, вы должны запустить некий процесс, отдать данные и получить prediction-значения. С этим все шло хорошо, пока не понадобились кастомные алгоритмы.

Аналитики знают, что у них есть CI и репозиторий. В CI-репозитории есть папка, куда они должны выложить три файла. Serve.py — файл, который позволяет на SageMaker поднять Flask-сервис и общаться с самим SageMaker. Train.py— класс с методом train, в который они должны сложить все, что нужно для модели. Наконец, predict.py — с его помощью они поднимают этот класс, внутри которого есть метод. Имея доступ, они поднимают оттуда всевозможные ресурсы с S3 — внутри SageMaker у нас есть имидж, который позволяет запускать все что угодно с интерфейса и программно (мы их не ограничиваем).
Из SageMaker мы получаем доступ к predict.py — внутри image — это просто приложение на Flask, которое позволяет вызывать predict или train c определенными параметрами. Все это привязано к S3 и, помимо этого, у них есть возможность сохранять модели из Jupyter Notebook. Т. е. в Jupyter Notebook у аналитиков есть доступ ко всем данным, и они могут делать какие-то эксперименты.
В продакшен все это попадает следующим образом. У нас есть юзеры, есть predict values endpoint. Данные лежат на S3 и достаются Athena. Каждые два часа запускается алгоритм, который считает предикт на следующие два часа. Такой шаг по времени обусловлен тем, что в нашем случае примерно 6 часов аналитики достаточно для того, чтобы сказать, что с мотором что-то не так. Даже в момент включения мотор греется от 5–10 минут, и резких скачков не происходит.
В системах критически важных, скажем, когда Air France проверяет турбины самолетов, предикшен делается из расчета 10 минут. В этом случае точность составляет 96,5 %.
Если мы видим, что что-то идет не так, включается система нотификаций. Тогда кому-то из множества пользователей на часы или другое устройство приходит уведомление, что конкретный мотор ведет себя аномально. Он идет и проверяет его состояние.
Manage Notebook Instances
На самом деле, все очень просто. Приходя на работу, аналитик запускает инстанс на Jupyter Notebook. Он получает роль и сессию, так что два человека не могут редактировать один и тот же файл. Собственно, у нас сейчас для каждого аналитика есть свой инстанс.
Create Training Job
У SageMaker есть понимание трейнинг-джобы. Ее результат, если вы используете просто API — бинарник, который сохраняется на S3: из параметров, которые вы предоставляете, получается ваша моделька.
sagemaker = boto3.client('sagemaker')
sagemaker.create_training_job(**create_training_params)
status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus']
print(status)
try:
sagemaker.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_name)
finally:
status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus']
print("Training job ended with status: " + status)
if status == 'Failed':
message = sagemaker.describe_training_job(TrainingJobName=job_name)['FailureReason']
print('Training failed with the following error: {}'.format(message))
raise Exception('Training job failed')Training Params Example
{
"AlgorithmSpecification": {
"TrainingImage": image,
"TrainingInputMode": "File"
},
"RoleArn": role,
"OutputDataConfig": {
"S3OutputPath": output_location
},
"ResourceConfig": {
"InstanceCount": 2,
"InstanceType": "ml.c4.8xlarge",
"VolumeSizeInGB": 50
},
"TrainingJobName": job_name,
"HyperParameters": {
"k": "10",
"feature_dim": "784",
"mini_batch_size": "500",
"force_dense": "True"
},
"StoppingCondition": {
"MaxRuntimeInSeconds": 60 * 60
},
"InputDataConfig": [
{
"ChannelName": "train",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": data_location,
"S3DataDistributionType": "FullyReplicated"
}
},
"CompressionType": "None",
"RecordWrapperType": "None"
}
]
}Параметры. Первое — роль: вы должны указать, к чему ваш SageMaker-инстанс имеет доступ. Т. е. в нашем случае, если аналитик работает с двумя разными продакшенами, он должен видеть один бакет и не видеть другой. Output config — то, куда вы сохраните все метаданные модели.
Мы пропускаем autoscale и можем просто указать количество инстансов, на которых вы хотите запустить эту training-джобу. На первых порах мы вообще использовали мидл-инстансы без TensorFlow или Keras, и этого было достаточно.
Гиперпараметры. Вы указываете Docker-имидж, в котором хотите запуститься. Как правило, Amazon предоставляет список алгоритмов и с ними имиджи, т. е. вы должны указать hyperparameters — параметры самого алгоритма.
Create Model
%%time
import boto3
from time import gmtime, strftime
job_name = 'kmeans-lowlevel-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
print("Training job", job_name)
from sagemaker.amazon.amazon_estimator import get_image_uri
image = get_image_uri(boto3.Session().region_name, 'kmeans')
output_location = 's3://{}/kmeans_example/output'.format(bucket)
print('training artifacts will be uploaded to: {}'.format(output_location))
create_training_params = {
"AlgorithmSpecification": {
"TrainingImage": image,
"TrainingInputMode": "File"
},
"RoleArn": role,
"OutputDataConfig": {
"S3OutputPath": output_location
},
"ResourceConfig": {
"InstanceCount": 2,
"InstanceType": "ml.c4.8xlarge",
"VolumeSizeInGB": 50
},
"TrainingJobName": job_name,
"HyperParameters": {
"k": "10",
"feature_dim": "784",
"mini_batch_size": "500",
"force_dense": "True"
},
"StoppingCondition": {
"MaxRuntimeInSeconds": 60 * 60
},
"InputDataConfig": [
{
"ChannelName": "train",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": data_location,
"S3DataDistributionType": "FullyReplicated"
}
},
"CompressionType": "None",
"RecordWrapperType": "None"
}
]
}
sagemaker = boto3.client('sagemaker')
sagemaker.create_training_job(**create_training_params)
status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus']
print(status)
try:
sagemaker.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_name)
finally:
status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus']
print("Training job ended with status: " + status)
if status == 'Failed':
message = sagemaker.describe_training_job(TrainingJobName=job_name)['FailureReason']
print('Training failed with the following error: {}'.format(message))
raise Exception('Training job failed')
%%time
import boto3
from time import gmtime, strftime
model_name=job_name
print(model_name)
info = sagemaker.describe_training_job(TrainingJobName=job_name)
model_data = info['ModelArtifacts']['S3ModelArtifacts']
print(info['ModelArtifacts'])
primary_container = {
'Image': image,
'ModelDataUrl': model_data
}
create_model_response = sagemaker.create_model(
ModelName = model_name,
ExecutionRoleArn = role,
PrimaryContainer = primary_container)
print(create_model_response['ModelArn'])
Создание модели — результат трейнинг-джобы. После завершения последней, и когда вы ее промониторили, она сохраняется на S3, и вы можете ее использовать.

Вот так это выглядит с точки зрения аналитиков. Наши аналитики заходят на модельки, и говорят: вот в этом имидже я хочу запустить эту модель. Они просто указывают на S3 папку, Image и вводят в графический интерфейс параметры. Но там есть нюансы и сложности, поэтому мы перешли к кастом-алгоритмам.
Create Endpoint
%%time
import time
endpoint_name = 'KMeansEndpoint-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
print(endpoint_name)
create_endpoint_response = sagemaker.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name)
print(create_endpoint_response['EndpointArn'])
resp = sagemaker.describe_endpoint(EndpointName=endpoint_name)
status = resp['EndpointStatus']
print("Status: " + status)
try:
sagemaker.get_waiter('endpoint_in_service').wait(EndpointName=endpoint_name)
finally:
resp = sagemaker.describe_endpoint(EndpointName=endpoint_name)
status = resp['EndpointStatus']
print("Arn: " + resp['EndpointArn'])
print("Create endpoint ended with status: " + status)
if status != 'InService':
message = sagemaker.describe_endpoint(EndpointName=endpoint_name)['FailureReason']
print('Training failed with the following error: {}'.format(message))
raise Exception('Endpoint creation did not succeed')Вот столько кода надо, чтобы создать Endpoint, который дергается из любой лямбды и извне. Каждые два часа у нас срабатывает событие, который дергает Endpoint.
Endpoint View

Так это видят аналитики. Они просто указывают алгоритм, время и дергают его руками с интерфейса.
Invoke Endpoint
import json
payload = np2csv(train_set[0][30:31])
response = runtime.invoke_endpoint(EndpointName=endpoint_name,
ContentType='text/csv',
Body=payload)
result = json.loads(response['Body'].read().decode())
print(result)
А это то, как это выполняется из лямбды. Т. е. у нас есть внутри Endpoint, и мы каждые два часа посылаем пейлоад, для того, чтобы сделать предикшен.
Useful SageMaker Links: ссылки на github
Это очень важные ссылки. Честно говоря, после того как мы начали использовать обычный Sagemaker GUI, все понимали, что рано или поздно мы придем к кастомному алгоритму, и все это будет собираться руками. По этим ссылкам можно найти не только использование алгоритмов, но еще и сборку кастомных имиджей:
github.com/awslabs/amazon-sagemaker-examples
github.com/aws-samples/aws-ml-vision-end2end
github.com/juliensimon
github.com/aws/sagemaker-spark
Что дальше?
Мы подошли к четвертому продакшену и сейчас, кроме аналитики, у нас два пути развития. Во-первых, мы пытаемся получить логи от механиков, т. Е. пытаемся прийти к обучению с поддержкой. Первые Mantainence-логи, которые мы получили, выглядит так: что-то сломалось в понедельник, я пришел туда в среду, начал чинить в пятницу. Мы сейчас пытаемся поставить заказчику CMS — систему управления контентом, которая позволит логировать события поломок.
Как это делается? Как правило, как только случается поломка, механик приходит и очень быстро меняет деталь, но всякие бумажные формы он может заполнить, скажем, через неделю. К этому времени человек просто забывает, что именно произошло с деталью. CMS, конечно, выводит нас на новый уровень взаимодействия с механиками.
Во-вторых, мы собираемся установить на моторы ультразвуковые сенсоры, которые считывают звук и занимаются спектральным анализом.
Вполне возможно, что от Athena откажемся, потому что на больших данных, использовать S3 оказывается дорого. При этом собственные сервисы недавно анонсировал Microsoft, и один из наших клиентов хочет попробовать сделать примерно то же уже на Azure. Собственно, одно из достоинств нашей системы в том, что ее можно разобрать и собрать в другом месте, как из кубиков.