
Иногда при разработке highload-продукта возникает ситуация, когда надо обработать не максимально большое количество запросов, а наоборот — ограничить количество запросов в единицу времени. В нашем случае это количество отправляемых push-уведомлений конечным пользователям. Подробнее об алгоритмах rate limiting, их плюсах и минусах — под катом.
Для начала немного о нас. Pushwoosh — это b2b сервис для коммуникации наших клиентов с их пользователями. Мы предоставляем бизнесам комплексные решения для общения с пользователями посредством push-уведомлений, email и других каналов коммуникации. Помимо собственно отправки сообщений, мы предлагаем инструменты для сегментации аудитории, сбора и обработки статистики, и многое другое. Для этого мы с нуля создали highload продукт на стыке множества технологий, лишь малой частью из которых являются PHP, Golang, PostgreSQL, MongoDB, Apache Kafka. Многие наши решения уникальны, например, high-speed нотификации. Мы обрабатываем более 2 миллиардов API-запросов в сутки, в нашей базе более 3 миллиардов устройств, а за всё время работы мы отправили более 500 миллиардов уведомлений на эти устройства.
И здесь мы приходим к ситуации, когда уведомления надо доставить на миллионы девайсов не как можно быстрее (как в уже упомянутом high-speed), а искусственно ограничив скорость, чтобы сервера наших клиентов, на которые перейдут пользователи, открыв уведомление, не легли под одномоментной нагрузкой.
Тут нам на помощь приходят различные алгоритмы rate limiting, которые позволяют ограничивать количество запросов в единицу времени. Как правило, это используется, например, при проектировании API, так как таким образом мы можем защитить систему от случайного или злонамеренного избытка запросов, в результате которого происходит задержка или отказ в обслуживании других клиентов. Если реализован rate limiting, все клиенты ограничены фиксированным количеством запросов в единицу времени. Кроме того, rate limiting может использоваться при доступе к частям системы, связанных с конфиденциальными данными; таким образом, если злоумышленник получит к ним доступ, то не сможет быстро получить доступ ко всем данным.
Существует много разных путей для реализации rate limiting. В данной статье мы рассмотрим плюсы и минусы различных алгоритмов, а также проблемы, которые могут возникнуть при масштабировании этих решений.
Алгоритмы ограничения скорости обработки запросов
Leaky Bucket (протекающее ведро)
Leaky Bucket — это алгоритм, который обеспечивает наиболее простой, интуитивно понятный подход к ограничению скорости обработки при помощи очереди, которую можно представить в виде «ведра», содержащего запросы. Когда запрос получен, он добавляется в конец очереди. Через равные промежутки времени первый элемент в очереди обрабатывается. Это также известно как очередь FIFO. Если очередь заполнена, то дополнительные запросы отбрасываются (или “утекают”).

Преимущество данного алгоритма состоит в том, что он сглаживает всплески и обрабатывает запросы примерно с одной скоростью, его легко внедрить на одном сервере или балансировщике нагрузки, он эффективен по использованию памяти, так как размер очереди для каждого пользователя ограничен.
Однако при резком увеличении трафика очередь может заполниться старыми запросами и лишить систему возможности обрабатывать более свежие запросы. Также он не дает гарантии, что запросы будут обработаны за какое-то фиксированное время. Кроме того, если для обеспечения отказоустойчивости или увеличения пропускной способности вы загружаете балансировщики, то вы должны реализовать политику координации и обеспечения глобального ограничения между ними.
Существует разновидность данного алгоритма — Token Bucket («ведро с токенами» или «алгоритм маркерной корзины»).
В такой реализации в «ведро» с постоянной скоростью добавляются токены, а при обработке запроса токен из «ведра» удаляется; если же токенов не достаточно, то запрос отбрасывается. В качестве токенов можно просто использовать timestamp.
Существуют вариации с использованием нескольких «вёдер», при этом как размеры, так и скорость поступления токенов в них могут быть разными у отдельных «вёдер». Если в первом «ведре» токенов для обработки запроса недостаточно, то проверяется их наличие во втором и т.д., но при этом приоритет обработки запроса понижается (как правило, это используется при проектировании сетевых интерфейсов, когда можно, например, изменить значение поля DSCP обрабатываемого пакета).
Ключевым отличием от реализации Leaky Bucket является то, что токены могут накопиться при простое системы, и дальше может случиться burst нагрузки, при этом запросы будут обработаны (т.к. имеется достаточное количество токенов), в то время как Leaky Bucket гарантированно будет сглаживать нагрузку даже в случае простоя.
Fixed Window (фиксированное окно)
В этом алгоритме для отслеживания запросов используется окно, равное n секундам. Обычно используются значения вроде 60 секунд (минута) или 3600 секунд (час). Каждый входящий запрос увеличивает счётчик для этого окна. Если счётчик превышает некое пороговое значение, запрос отбрасывается. Обычно окно определяется нижней границей текущего временного интервала, то есть при ширине окна в 60 секунд, запрос, пришедший в 12:00:03, попадёт в окно 12:00:00.
Преимущество этого алгоритма состоит в том, что он обеспечивает обработку более свежих запросов, не зависая на обработке старых. Однако одиночный всплеск трафика вблизи границы окна может привести к удвоению количества обработанных запросов, поскольку он разрешает запросы как для текущего, так и для следующего окна в течение короткого промежутка времени. Кроме того, если много пользователей ждут сброса счётчика окна, например, в конце часа, они могут спровоцировать рост нагрузки в этот момент из-за того, что обратятся к API одновременно.
Sliding Log (скользящий журнал)
Данный алгоритм предполагает отслеживание временных меток каждого запроса пользователя. Эти записи сохраняются, например, в hash set или таблицу и сортируются по времени; записи за пределами отслеживаемого интервала отбрасываются. Когда поступает новый запрос, мы вычисляем количество записей, чтобы определить частоту запросов. Если запрос выходит за рамки допустимого количества, то он отбрасывается.
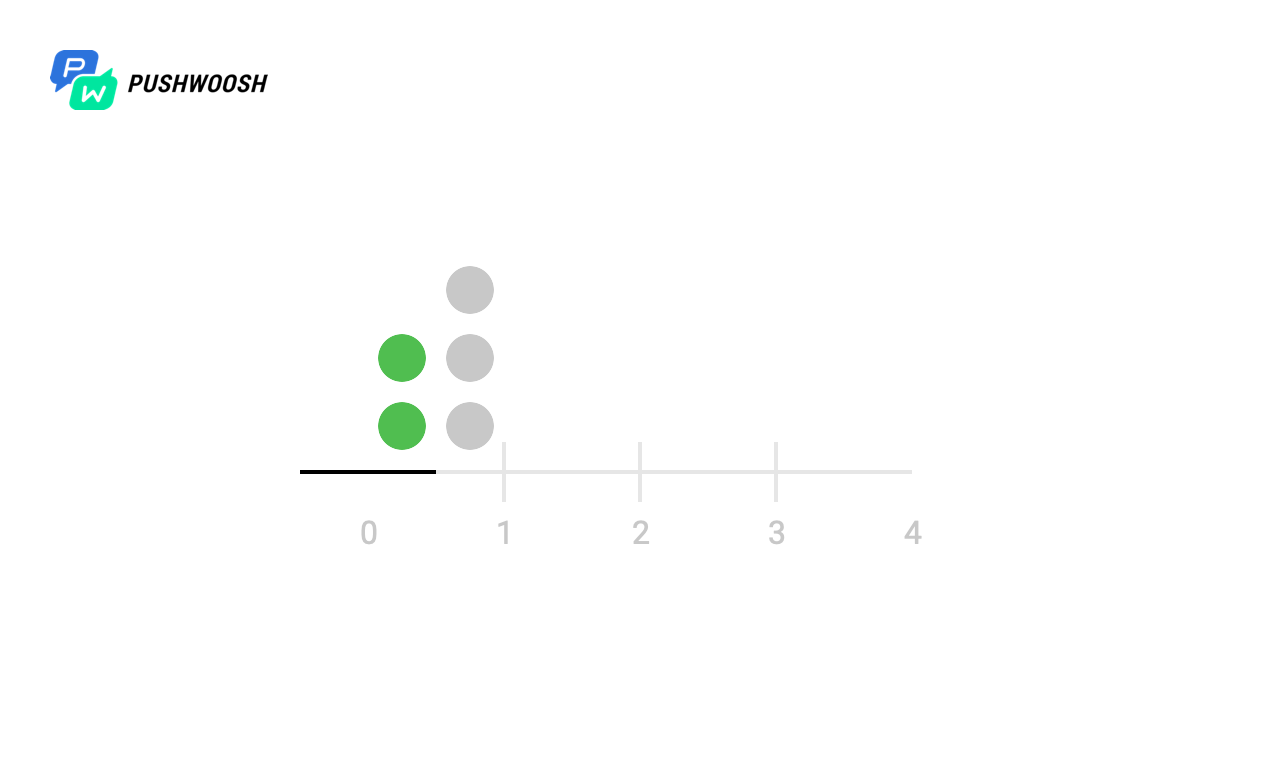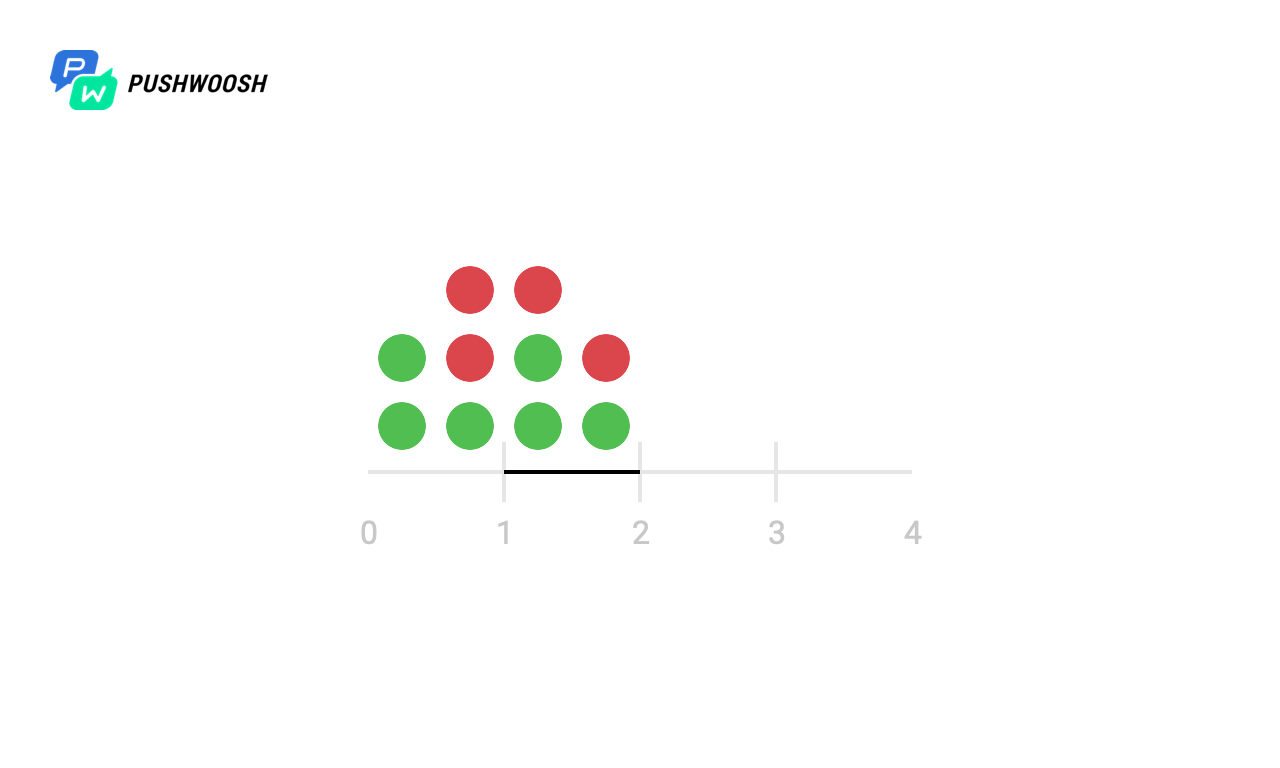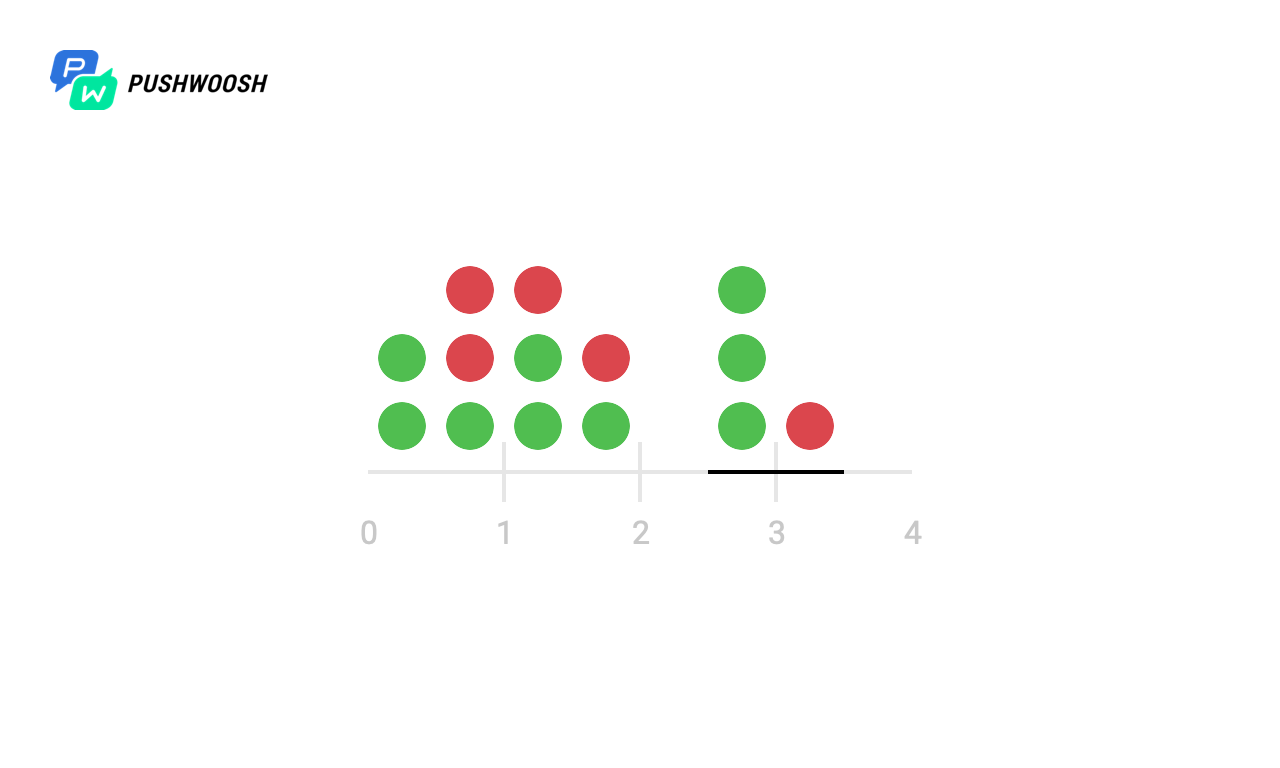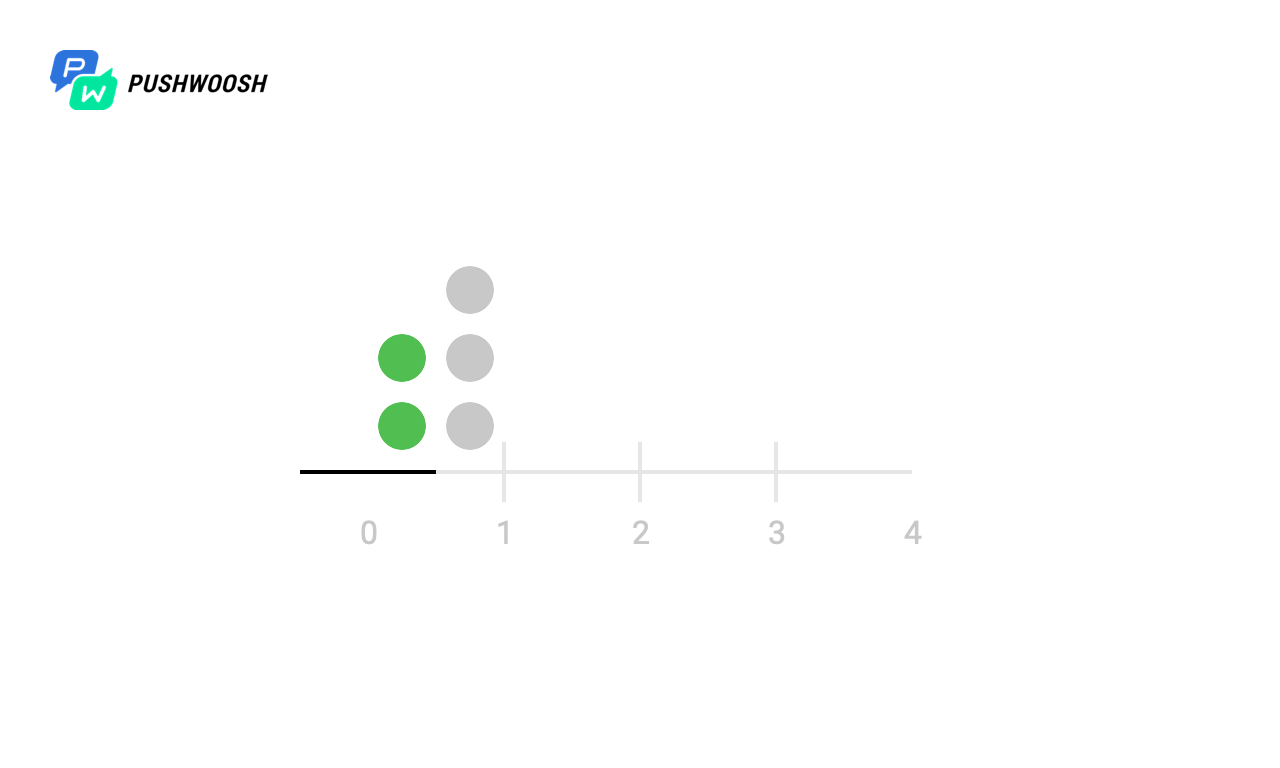
Преимущество этого алгоритма в том, что он не подвержен проблемам, которые возникают на границах Fixed Window, то есть ограничение скорости будет строго соблюдаться. Кроме того, поскольку отслеживаются запросы каждого клиента в отдельности, не возникает пикового роста нагрузки в определенные моменты, что является ещё одной проблемой предыдущего алгоритма.
Однако хранить информацию о каждом запросе может быть дорого, кроме того, каждый запрос требует вычисления количества предыдущих запросов, потенциально — на всём кластере, в результате чего данный подход плохо масштабируется для обработки больших всплесков трафика и атак типа «denial of service».
Sliding Window (скользящее окно)
Это гибридный подход, который сочетает в себе низкую стоимость обработки Fixed Window и улучшенную обработку граничных ситуаций Sliding Log. Как и в простом Fixed Window, мы отслеживаем счётчик для каждого окна, а затем учитываем взвешенное значение частоты запросов предыдущего окна на основе текущей временной метки, чтобы сгладить всплески трафика. Для примера, если прошло 25% времени текущего окна, то мы учитываем 75% запросов предыдущего. Относительно небольшое количество данных, необходимых для отслеживания по каждому ключу, позволяет нам масштабироваться и работать в большом кластере.

Данный алгоритм позволяет масштабировать rate limiting, сохраняя хорошую производительность. Кроме того, это понятный способ донести клиентам информацию об ограничении количества запросов, а также позволяет избежать проблем, возникающих при реализации других алгоритмов rate limiting.
Rate Limiting в распределенных системах
Политики синхронизации
Если вы хотите установить глобальный rate limiting при обращении к кластеру, состоящему из нескольких узлов, то необходимо реализовать политику применения ограничений. Если бы каждый узел отслеживал только своё собственное ограничение, то пользователь мог бы обойти его, просто отправляя запросы на разные узлы. Фактически, чем больше число узлов, тем больше вероятность, что пользователь сможет превысить глобальный лимит.

Самый простой способ установить ограничения — настроить «sticky session» на балансировщике, чтобы пользователь направлялся на один и тот же узел. Недостатки этого способа — отсутствие отказоустойчивости и проблемы с масштабированием, когда узлы кластера перегружены.
Лучшим решением, которое допускает более гибкие правила распределения нагрузки, является использование централизованного хранилища данных (на ваш выбор). В нём можно хранить счётчики количества запросов для каждого окна и пользователя. Основные проблемы этого подхода — это увеличение времени ответа из-за запросов к хранилищу и «race conditions».
Race conditions
Одной из самых больших проблем с централизованным хранилищем данных является возможность возникновения race conditions при конкурентных запросах. Это случается, когда вы используете естественный подход «get—then—set», при котором извлекаете текущий счётчик, увеличиваете его, а затем отправляете полученное значение обратно в хранилище. Проблема такой модели заключается в том, что за время, необходимое для выполнения полного цикла этих операций (то есть чтения, инкремента и записи), могут поступать другие запросы, при каждом из которых счётчик будет сохраняться с недопустимым (более низким) значением. Это позволяет пользователю отправлять большее количество запросов, чем предусмотрено алгоритмом rate limiting.
Один из способов избежать этой проблемы — установить блокировку вокруг рассматриваемого ключа, предотвращая доступ на чтение или запись любых других процессов в счётчик. Однако это может быстро стать узким местом в производительности и плохо масштабируется, особенно при использовании удалённых серверов, например Redis, в качестве дополнительного хранилища данных.
Гораздо лучшим подходом является «set—then—get», опирающийся на атомарные операторы, что позволяет быстро увеличивать и проверять значения счётчика, не мешая атомарным операциям.
Оптимизация производительности
Другим недостатком использования централизованного хранилища данных является увеличение времени ответа из-за задержки на проверку счётчиков, используемых для реализации rate limiting (round-trip time, или «круговая задержка»). К сожалению, даже проверка быстрого хранилища, такого как Redis, приведет к дополнительным задержкам в некоторое количество миллисекунд на каждый запрос.

Чтобы сделать определение ограничения с минимальной задержкой, необходимо выполнять проверки в локальной памяти. Это можно сделать, ослабив условия проверки скорости и используя в конечном итоге последовательную модель.
Например, каждый узел может создать цикл синхронизации данных, в котором будет синхронизироваться с хранилищем. Каждый узел периодически передает значение счетчика для каждого пользователя и окна, которое затрагивал, в хранилище, которое будет атомарно обновлять значения. Затем узел может получить новые значения и обновить данные в локальной памяти. Этот цикл в конце концов позволит всем узлам кластера находиться в актуальном состоянии.
Период, в течение которого узлы синхронизируются, должен быть настраиваемым. Более короткие интервалы синхронизации приведут к меньшему расхождению данных, когда нагрузка равномерно распределяется по нескольким узлам кластера (например, в случае когда балансировщик определяет узлы по принципу «round-robin»), тогда как более длинные интервалы создают меньше нагрузки на чтение/запись для хранилища и уменьшают издержки на каждом узле на получение синхронизированных данных.
Сравнение алгоритмов Rate Limiting
Конкретно в нашем случае, мы должны не отклонять запросы клиента к API, а на основе данных, наоборот, не создавать их; при этом “терять” запросы мы не имеем права. Для этого при рассылке уведомления у нас используется параметр send_rate, в котором и указывается максимальное количество уведомлений, которое мы будем отправлять в секунду при рассылке.
Таким образом, у нас есть некий Worker, выполняющий работу в отведенное ему время (в моём примере, чтение из файла), который принимает на вход интерфейс RateLimitingInterface, сообщающий можно ли в данный момент времени выполнить запрос и как долго он будет выполняться.
interface RateLimitingInterface
{
/**
* @param int $rate Expected send rate
*/
public function __construct(int $rate);
/**
* @param float $currentTime Current timestamp in microseconds
* @return bool
*/
public function canDoWork(float $currentTime): bool;
}
Все примеры кода можно найти на GitHub тут.
Сразу поясню, зачем нужно передавать квант времени в Worker. Дело в том, что запускать для обработки отправки одного сообщения с ограничением скорости отдельный экземпляр демона — слишком дорого, поэтому реально send_rate используется как параметр «количество нотификаций в единицу времени», которая составляет 0.01 — 1 секунда в зависимости от загруженности.
Фактически, мы за секунду обрабатываем до 100 различных запросов с send_rate, выделяя на обработку каждого квант времени в 1 / N секунд, где N — это количество пушей, обрабатываемых данным демоном. Самый интересующий нас параметр при обработке — будет ли соблюдаться send_rate (допускаются небольшие погрешности в ту или другую сторону) и нагрузка на наше железо (минимальное количество обращений к хранилищам, потребление CPU и памяти).
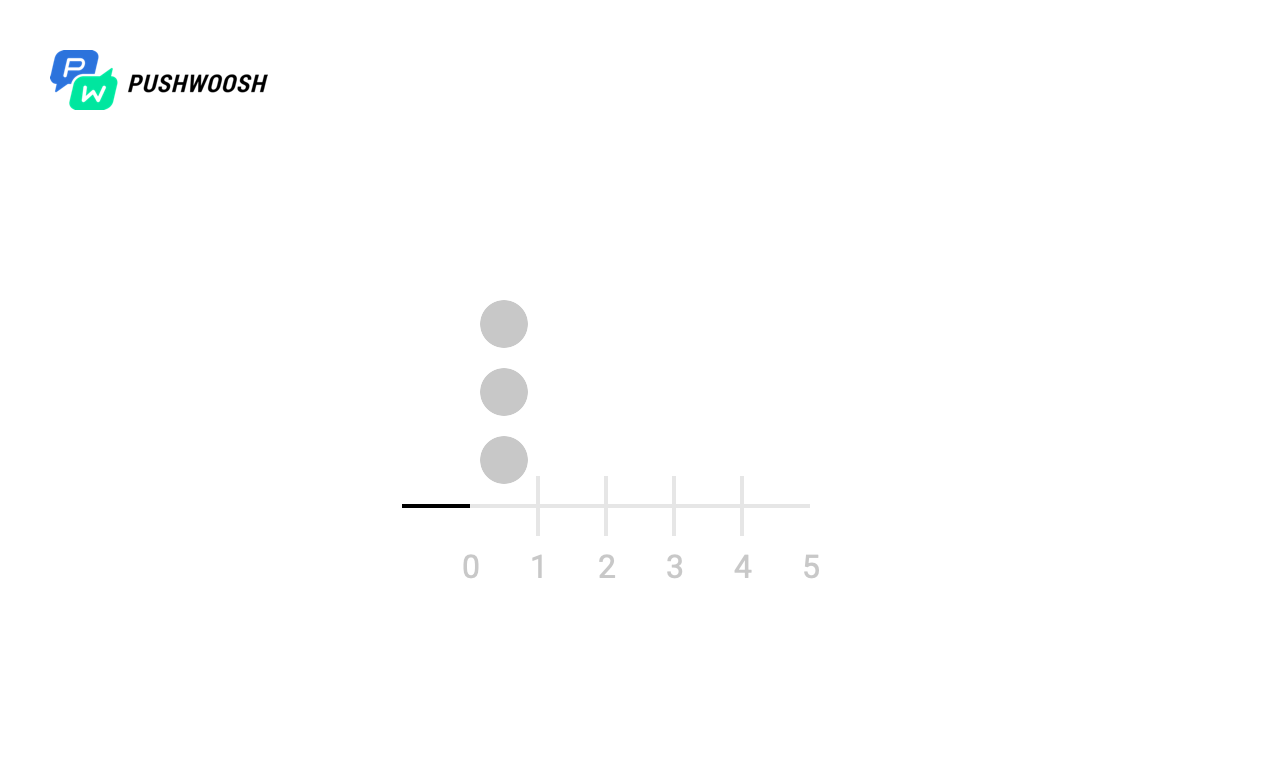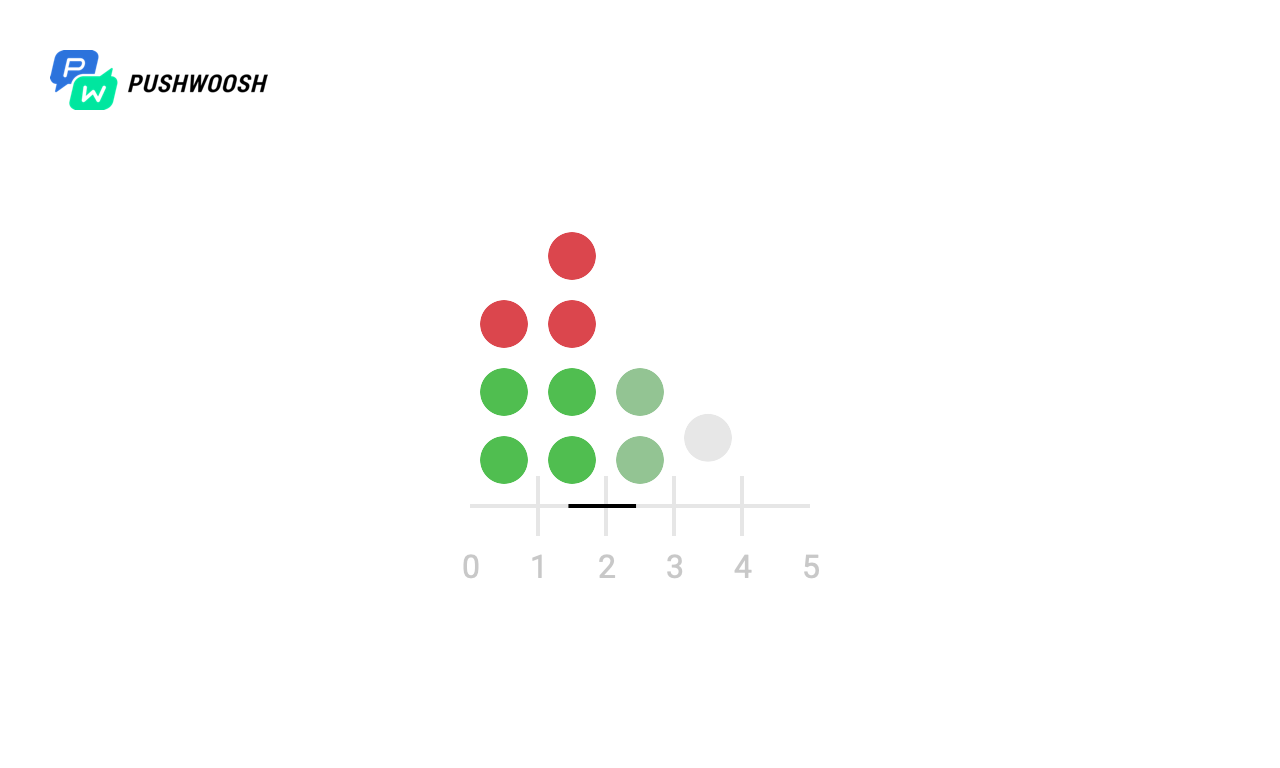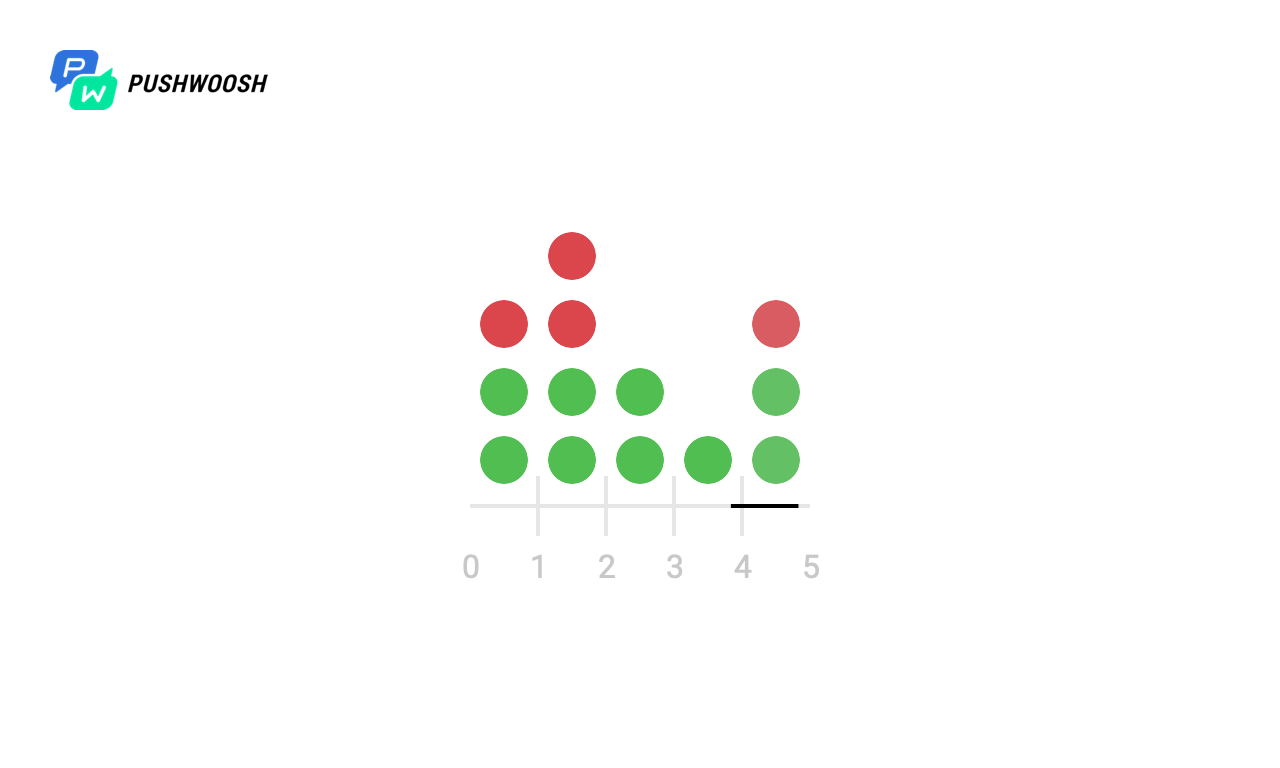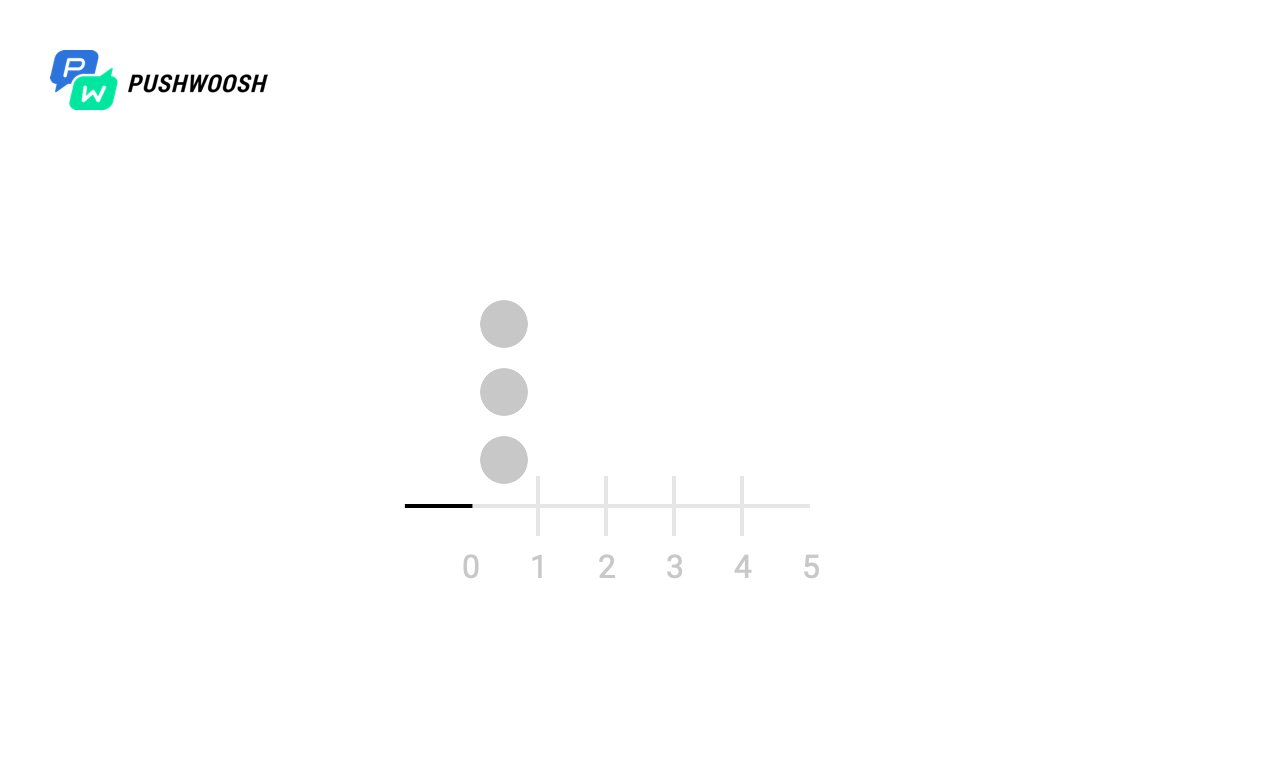
Для начала разберемся, в какие моменты времени Worker реально работает. Для простоты в данном примере обрабатывался 10000-строчный файл с send_rate = 1000 (то есть мы читали из файла по 1000 строк в секунду).
На скриншотах маркерами отмечены моменты и количество вызова fgets для всех алгоритмов. В реальности это может быть обращение к базе данных, стороннему ресурсу или любые другие запросы, количество которых в единицу времени мы хотим ограничить.
По шкале Х — время с момента старта обработки, от 0 до 10 секунд, каждая секунда разбита на десятые доли, поэтому график от 0 до 100).




Мы видим, что несмотря на то, что с соблюдением send_rate справляются все алгоритмы (для того они и предназначены), Fixed Window и Sliding Log всю нагрузку “выдают” практически одномоментно, что нас не очень устраивает, в то время как Token Bucket и Sliding Window равномерно распределяют её на единицу времени (за исключением пиковой нагрузки в момент старта, вызванной отсутствием данных о нагрузке в предыдущие моменты времени).
Ввиду того, что в реальности код обычно работает не с локальной файловой системой, а со сторонним хранилищем, ответ может затянуться, могут возникнуть проблемы с сетью и множество других проблем, попытаемся проверить как поведет себя тот или иной алгоритм, когда запросов какое-то время не было. Для примера — после 4 и 6 секунд.


Здесь может показаться, что Fixed Window отработал некорректно и обработал в 2 раза больше положенного запросов в первую и с 7 по 8 секунду, но на самом деле это не так, поскольку на графике время отсчитывается с момента запуска, а в алгоритме используется текущий unix timestamp.


В целом, принципиально ничего не изменилось, но мы видим, что Token Bucket более гладко сглаживает нагрузку и никогда не превышает заданный rate limit, а вот Sliding Log в случае простоя может превысить допустимое значение.
Заключение
Мы рассмотрели все основные алгоритмы реализации rate limiting, каждый из которых имеет свои плюсы и минусы и подходит для различных задач. Надеемся, что, ознакомившись с данной статьёй, вы выберете наиболее подходящий алгоритм для решения вашей задачи.
mayorovp
Одному мне кажется, что полезные уведомления нельзя так просто выбрасывать при превышении лимита, и их надо ставить в очередь? Таким образом, все алгоритмы без очереди FIFO сразу же оказываются бесполезными.
Anexroid Автор
Разумеется, что они ставятся в очередь, а не теряются. Точнее даже «ждут своей очереди». Здесь больше идет речь про то что при помощи алгоритма проверяется «можем ли мы в данный момент отправить сообщение». Если нет, то ждём следующую итерацию, в противном случае — отправляем.
mayorovp
А как же эта цитата?
Anexroid Автор
Это лишь описание алгоритмов и логики их работы, а не примеры из нашего кода :)