
Мне надоело смотреть на прошлое. Есть много руководств по воссозданию внешнего облика исторических артефактов, но часто мы забываем, что это творческий акт. Возможно, мы слишком привязаны к своим экранам, слишком много значения придаём внешнему облику. Давайте вместо этого попробуем услышать что-то из прошлого.
Богатая литература по археоакустике и звуковым ландшафтам помогает воссоздать звук места, каким он был (например, см. Виртуальный Собор Святого Павла или работу Джеффа Вейча по древней Остии). Но мне интересно «озвучить» сами данные. Я хочу определить синтаксис для представления данных в виде звука, чтобы эти алгоритмы можно было использовать в исторической науке. Друкер сказал знаменитую фразу, что «данные» — это на самом деле не то, что дано, а скорее то, что захвачено, трансформировано, то есть 'capta'. При озвучивании данных я буквально воспроизвожу прошлое в настоящем. Поэтому на передний план выходят допущения и преобразования этих данных. Полученные звуки являются «деформированным исполнением», которое заставляет по-новому услышать современные пласты истории.
Я хочу услышать смысл прошлого, но знаю, что это невозможно. Тем не менее, когда я слышу инструмент, то могу физически представить музыканта; по отзвукам и резонансам могу различить физическое пространство. Я чувствую бас, могу двигаться в ритме. Музыка охватывает моё тело, всё воображение. Ассоциации со слышанными ранее звуками, музыкой и тонами создают глубокий темпоральный опыт, систему воплощённых взаимоотношений между мной и прошлым. Визуальность? У нас так давно существуют визуальные представления о прошлом, что эти грамматики почти потеряли художественную выразительность и перформативный аспект.
В этом уроке вы научитесь создавать некий шум из исторических данных. Значение этого шума, ну… зависит от вас. Частично смысл в том, чтобы снова сделать ваши данные незнакомыми. Транслируя, перекодируя, восстанавливая их, мы начинаем видеть элементы данных, которые оставались незаметными при визуальном рассмотрении. Эта деформация согласуется с аргументами, сделанными, например, Марком Сэмплом о деформации общества или Бетани Ноувиски о «сопротивлении материалов». Озвучивание ведёт нас от данных к «капте», от социальных наук к искусству, от глюка к эстетике. Давайте посмотрим, на что это похоже.
В этом уроке я рассажу о трёх способах генерации звука или музыки из ваших данных.
Сначала будем использовать свободную и открытую систему Musicalgorithms, разработанную Джонатаном Миддлтоном. В ней познакомимся с ключевыми проблемами и терминами. Затем возьмём небольшую библиотеку Python для «трансляции» данных на 88-клавишную клавиатуру и привнесём в работу некое творчество. Наконец, загрузим данные в программу обработки звука и музыки в реальном времени Sonic Pi, для которой опубликовано множество учебных пособий и справочных ресурсов.
Вы увидите, как работа со звуками перемещает нас из простой визуализации в реально эффективное окружение.
Озвучивание (sonification) — это метод трансляции некоторых аспектов данных в звуковые сигналы. В общем, метод можно назвать «озвучиванием», если он удовлетворяет определённым условиям. К ним относятся воспроизводимость (другие исследователи могут обработать те же данные теми же способами и получить такие же результаты) и то, что можно назвать «внятность» или «разборчивость», то есть когда значимые элементы исходных данных систематически отражаются в результирующем звуке (см. Херманн, 2008). В работе Марка Ласта и Анны Усыскиной (2015) описана серия экспериментов для определения, какие аналитические задачи можно выполнить при озвучивании данных. Их экспериментальные результаты показали, что даже неподготовленные слушатели (без формального обучения музыке) могут различать данные на слух и делать полезные выводы. Они обнаружили, что слушатели способны выполнять на слух общие задачи дата-майнинга, такие как классификация и кластеризация (в своих экспериментах они транслировали базовые научные данные в масштабе западной музыки).
Ласт и Усыскина сосредоточились на временных рядах. Согласно их выводам, данные временных рядов особенно хорошо подходят для озвучивания, поскольку здесь естественные параллели. Музыка последовательна, у неё есть длительность, и она развивается со временем; так же и с данными временных рядов (Ласт, Усыскина 2015: стр. 424). Остаётся сопоставить данные с соответствующими звуковыми выходами. Для объединения аспектов данных по различным слуховым измерениям, таким как высота, вариационная форма и интервал (onset), во многих приложениях используется метод «трансляция параметров» (parameter mapping). Проблема с этим подходом в том, что если между исходными точками данных нет временной связи (или, скорее, нелинейной связи), результирующий звук может получиться «запутанным» (2015: 422).
Слушая звук, человек заполняет моменты тишины своими ожиданиями. Рассмотрим видео, где mp3 преобразован в MIDI и обратно в mp3; музыка «сплющена», так что вся звуковая информация воспроизводится одним инструментом (эффект похож на сохранение веб-страницы как .txt, открытии её в Word, а затем повторном сохранении в формате .html). Все звуки (включая вокал) переводятся в соответствующие значения нот, а затем снова в mp3.
Это шум, но смысл можно уловить:
Что здесь происходит? Если эта песня была вам известна, вероятно, вы поняли настоящие «слова». Но в песне нет слов! Если вы её раньше не слышали, то она звучит как бессмысленная какофония (больше примеров на сайте Энди Байо). Этот эффект иногда называют «звуковыми галлюцинациями» (auditory hallucination). Пример показывает, как в любом представлении данных мы можем слышать/видеть то, чего, строго говоря, нет. Мы заполняем пустоты собственными ожиданиями.
Что это значит для истории? Если мы озвучиваем наши данные и начинаем слышать паттерны в звуке или странные выбросы, то наши культурные ожидания о музыке (воспоминания о похожих фрагментах музыки, услышанных в определённых контекстах), окрасят нашу интерпретацию. Я бы сказал, что это верно для всех представлений о прошлом, но озвучивание достаточно сильно отличается от стандартных методов, поэтому такое самосознание помогает идентифицировать или выразить некие критические паттерны в (данных о) прошлом.
Рассмотрим три инструмента для озвучивания данных и отметим, как выбор инструмента влияет на результат, и как решить эту проблему путём переосмысления данных в другом инструменте. В конечном счёте, озвучивание не объективнее визуализации, поэтому исследователь должен быть готов оправдать свой выбор и сделать этот выбор прозрачным и воспроизводимым. (Чтобы никто не думал, что озвучивание и алгоритмически генерируемая музыка — это нечто новое, направляю заинтересованного читателя к Хеджесу, 1978).
Каждый раздел содержит концептуальное введение, а затем пошаговое руководство с использованием образцов археологических или исторических данных.
Существует широкий спектр инструментов для озвучивания данных. Например, пакеты для популярной статистической среды R, такие как playitbyR и AudiolyzR. Но первый не поддерживается в текущей версией R (последнее обновление было несколько лет назад), а чтобы заставить второй работать должным образом, требуется серьёзная конфигурация дополнительного программного обеспечения.
В отличие от них, сайт Musicalgorithms довольно прост в использовании, он работает уже более десяти лет. Хотя исходный код не опубликован, это долгосрочный исследовательский проект по вычислительной музыке от Джонатана Миддлтона. В настоящее время он в третьей крупной версии (прежние итерации доступны в интернете). Начнём с Musicalalgorithms, потому что это позволяет быстро загрузить и настроить наши данные для выпуска представления в виде MIDI-файлов. Перед началом работы обязательно выберите третью версию.
Сайт Musicalgorithms по состоянию на 2 февраля 2016 года
Musicalgorithms производит ряд преобразований с данными. В приведённом ниже примере (по умолчанию на сайте) только одна строка данных, хотя она выглядит как несколько строк. Этот образец состоят из полей, разделённых запятыми, которые внутри разделены пробелами.
Эти цифры представляют исходные данные и их преобразования. Совместный доступ к файлу позволяет другому исследователю повторить работу или продолжить обработку другими инструментами. Если начинать с самого начала, то нужны только исходные данные ниже (список точек данных):
Для нас ключевым является поле 'areaPitch1' с входными данными, которые разделены пробелами. Другие поля заполнятся в ходе работы с различными настройками Musicalgorithms. В приведённых выше данных (например, 24 72 12 84 и т. д.) значения представляют собой исходные подсчёты количества надписей в британских городах вдоль римской дороги (позже попрактикуемся и с другими данными).

После загрузки данных в верхней строке меню можно выбрать различные операции. На скриншоте наведение курсора мыши на информацию выводит объяснение, что происходит при выборе операции деления для масштабирования данных до выбранного диапазона нот
Теперь при просмотре различных вкладок в интерфейсе (длительность, трансляция высоты, трансляция длительности, параметры масштаба) доступны различные преобразования. В «отображении высоты» (pitch mapping) есть ряд математических опций для трансляции данных на полную 88-клавишную клавиатуру фортепиано (в линейной трансляции среднее значение транслируется на среднюю C, то есть 40). Можно также выбрать вид шкалы: минор или мажор и так далее. На этом этапе после выбора различных преобразований необходимо сохранить текстовый файл. На вкладке File > Play можно загрузить файл midi. Ваша аудиопрограмма по умолчанию должна уметь воспроизводить midi (часто по умолчанию используются ноты фортепиано). Более сложные инструменты midi назначаются в программах-микшерах, таких как GarageBand (Mac) или LMMS (Windows, Mac, Linux). Впрочем, использование GarageBand и LMMS выходит за рамки данного руководства: видеоучебник по LMMS доступен здесь, а учебников по GarageBand полно в интернете. Например, отличное руководство на Lynda.com.
Бывает, что для одних и тех же точек имеется несколько столбцов данных. Скажем, в нашем примере из Британии мы хотим озвучить также подсчёт по типам керамики для тех же городов. Тогда вы можете перезагрузить следующий ряд данных, произвести преобразования и сопоставления — и создать другой файл MIDI. Поскольку GarageBand и LMMS позволяют накладывать голоса, то доступно создание сложных музыкальных последовательностей.
Скриншот GarageBand, где midi-файлы представляеют собой озвученные темы из дневника Джона Адамса. В интерфейсе GarageBand (и LMMS) каждый midi-файл перетаскивается мышкой на соответствующее место. Инструментарий каждого midi-файла (то есть дорожки) выбирается в меню GarageBand. Метки треков изменены, чтобы отразить ключевые слова в каждой теме. Зелёная область справа представляет собой визуализацию нот на каждой дорожке. Можете посмотреть этот интерфейс в действии и послушать музыку здесь
Какие преобразования использовать? Если у вас два столбца данных, то это два голоса. Возможно, в наших гипотетических данных имеет смысл воспроизвести первый голос громко, как главный: в конце концов, надписи в некотором роде «говорят» с нами (римские надписи буквально обращаются к прохожим: «О ты, проходящий мимо...»). А керамика, пожалуй, более скромный артефакт, который можно сопоставить с нижним концом шкалы или увеличить длительность нот, отражая её вездесущность среди представителей разных классов в этом регионе.
Не существует единственного «правильного» способа транслировать данные в звук, по крайней мере, пока нет. Но даже в этом простом примере мы видим, как в данных и их восприятии появляются оттенки смысла и интерпретации.
А как же время? Исторические данные часто имеют определённую привязку к дате. Таким образом, необходимо учитывать промежуток времени между двумя точками данных. Именно здесь становится полезным наш следующий инструмент, если точки данных соотносятся друг с другом в пространстве времени. Мы начинаем переходить от озвучивания (точки данных) к музыке (отношения между точками).
В первой колонке набора данных — количество римских монет и количество других материалов из тех же городов. Информация взята из Portable Antiquities Scheme Британского музея. Обработка этих данных может выявить некие аспекты экономической ситуации вдоль Уотлинг-стрит — главного маршрута через Римскую Британию. Точки данных расположены географически с северо-запада на юго-восток; таким образом, по мере воспроизведения звука мы слышим движение в пространстве. Каждая нота представляет собой каждую остановку на пути.
Итак, мы озвучили один столбец данных! Нажмите 'Save', затем 'Save CSV'.
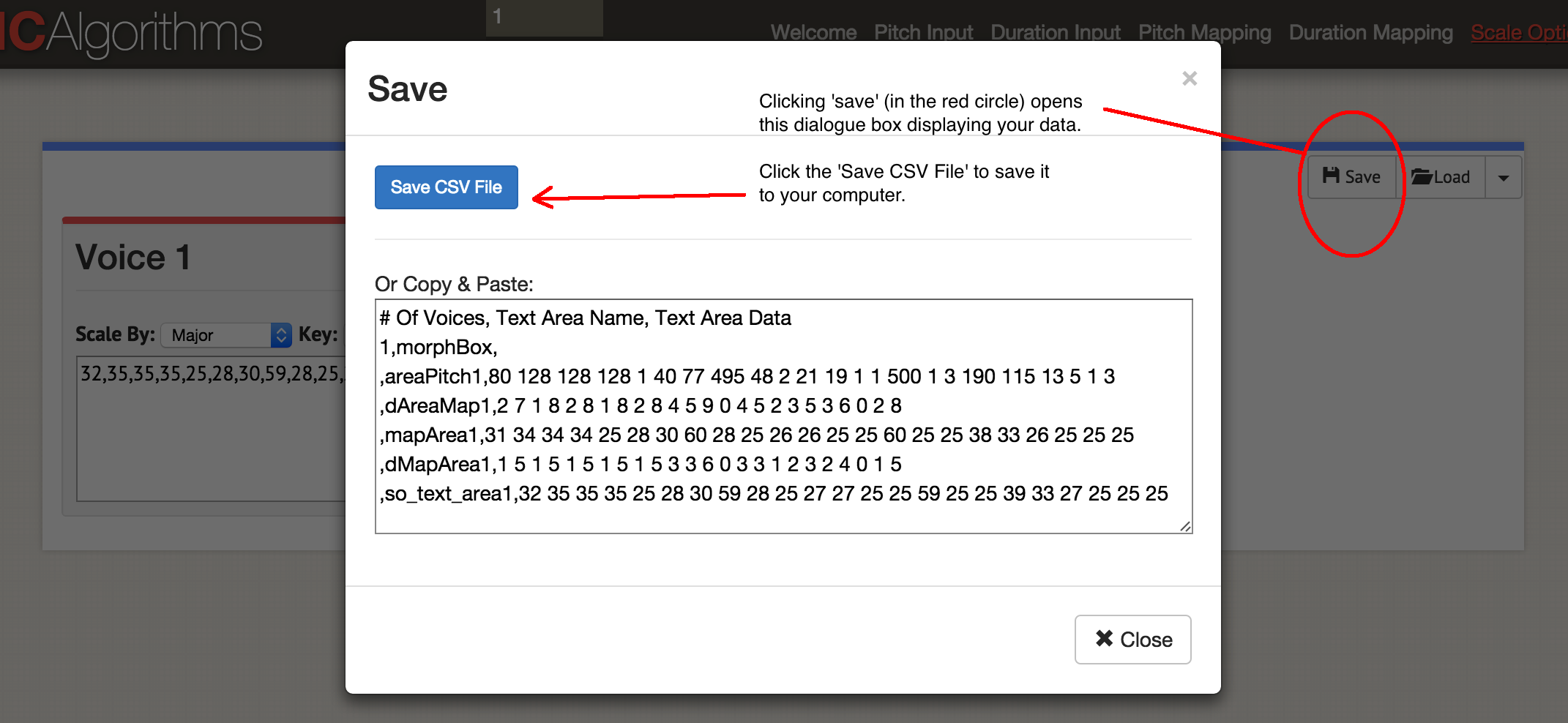
Диалоговое окно 'Save'
У вас получится примерно такой файл:
Исходные данные остались в поле 'areaPitch1', а дальше идут созданные сопоставления. Сайт позволяет генерировать в одном MIDI-файле до четырёх голосов одновременно. В зависимости от того, какие инструменты вы желаете использовать впоследствии, вы можете выбрать генерацию по одному MIDI-файлу за раз. Давайте запустим музыку: нажмите 'Play'. Здесь вы выбираете темп и инструмент. Свои данные можно прослушать в браузере или сохранить как MIDI-файл синей кнопкой ‘Save MIDI file’.
Вернёмся к началу и загрузим в этот шаблон оба столбца данных:
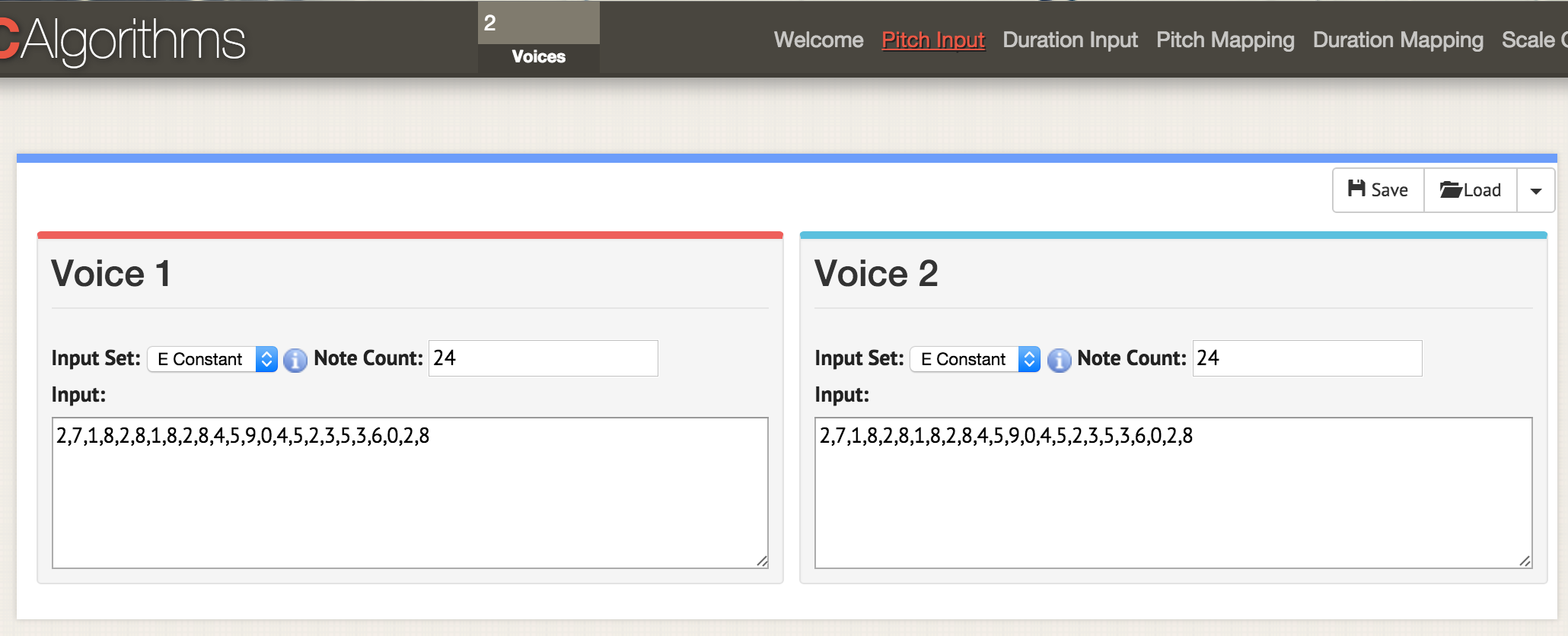
Тут мы находимся на странице с параметрами 'pitch input'. Вверху окна укажите два голоса, теперь на любой странице с параметрами открываются два окна для двух голосов. Как и раньше, загружаем данные в формате CSV, но файл нужно отформатировать, чтобы там были указаны значения 'areaPitch1' и 'areaPitch2'. Данные для первого голоса появятся слева, а второго — справа
Если у нас несколько голосов, что вынести на первый план? Обратите внимание, что при таком подходе в нашей озвучке не учитывается расстояние между точками в реальном мире. Если учитывать, то оно сильно повлияет на результат. Конечно, расстояние не обязательно привязывать к географии — его можно привязать ко времени. Следующий инструмент позволит явно указать этот фактор при озвучивании.
Для данного раздела руководства потребуется Python. Если вы ещё не экспериментировали с этим языком, придётся потратить некоторое время на знакомство с командной строкой. См. также краткое руководство по установке модулей.
На маках Python уже установлен. Можете проверить: нажмите COMMAND и пробел, в окне поиска введите
Пользователям Windows нужно установить Python самостоятельно: начните с этой страницы, хотя всё немного сложнее, чем там написано. Во-первых, надо скачать файл
Если по нажатию Enter ничего не произойдёт, значит, команда сработала. Для проверки откройте командную строку (вот 10 способов сделать это) и введите
Последняя часть головоломки — программа под названием
Когда у вас есть питоновский код, который вы хотите запустить, вставьте его в текстовый редактор и сохраните файл с расширением
MIDITime — питоновский пакет, разработанный Reveal News (раньше организация называлась Центр журналистских расследований). Репозиторий на Github. Программа MIDITime разработана специально для обработки временных рядов (то есть последовательности наблюдений, собранных с течением времени).
В то время как у Musicalgorithms более или менее интуитивно понятный интерфейс, здесь преимуществом является открытый исходный код. Что ещё более важно, предыдущий инструмент не умеет учитывать данные с учётом исторического времени. MIDITime позволяет кластеризовать информацию по этому фактору.
Предположим, у нас есть исторический дневник, к которому применили тематическую модель. Результирующие выходные данные могут содержать записи дневника в виде строк, а в колонках будет процентный вклад каждой темы. В этом случае прослушивание значений поможет понять такие паттерны мышления из дневника, какие невозможно передать в виде графика. На слух сразу заметны выбросы или повторяющиеся музыкальные паттерны, которые не видны на графике.
Установка одной командой pip:
для маков;
под Linux;
под Windows (если инструкция не работает, можете попробовать эту вспомогательную программу для установки Pip).
Рассмотрим пример скрипта. Откройте текстовый редактор, скопируйте и вставьте этот код:
Сохраните скрипт как
В каталоге будет создан новый файл
Поиграйте со скриптом, добавьте больше нот. Вот ноты для песенки 'Baa Baa Black Sheep':
Можете написать инструкции, чтобы компьютер сыграл мелодию (вот диаграмма в помощь)?
Кстати. Существует специальный формат текстового файла для описания музыки под названием ABC Notation. Он выходит за рамки этой статьи, но скрипт для озвучивания можно написать, скажем, в электронных таблицах, сопоставляя значения нот в АВС-нотации (если вы когда-нибудь использовали конструкцию IF — THEN в Excel, то имеете представление, как это делается), а затем через сайты вроде этого АВС-нотация преобразуется в файл .mid.
Этот файл содержит выборку из тематической модели дневников Джона Адамса для сайта Macroscope. Тут оставили только самые сильные сигналы, округлив значений в столбцах до двух десятичных знаков. Чтобы вставить эти данные в питоновский скрипт, нужно их особым образом отформатировать. Сложнее всего с полем даты.
Для этого урока оставим имена переменных и остальное без изменений из скрипта с примером. Пример разработан для обработки данных землетрясений; поэтому здесь «магнитуду» можно представить как наш «вклад темы».
Для форматирования данных можно использовать регулярные выражения, а ещё проще — электронные таблицы. Скопируйте элемент со значением вклада темы на новый лист и оставьте столбцы слева и справа. В приведённом ниже примере я поместил его в столбец D, а затем заполнил остальные:
Затем скопируйте и вставьте неизменяемые элементы, заполнив весь столбец. Элемент с датой должен быть в формате (год, месяц, день). После заполнения таблицы её можно скопировать и вставить в текстовый редактор, сделав частью массива
Обратите внимание, что в конце последней строки нет запятой.
Окончательный скрипт будет выглядеть примерно так, если использовать пример со страницы самого Miditime (фрагменты кода ниже прерываются комментариями, но в текстовый редактор их следует вставить вместе как один файл):
Значения после MIDITime устанавливаются как
Теперь передаём данные в скрипт, загрузив их в массив
… здесь вставляем все данные и не забываем удалить запятую в конце последней строчки
затем вставляем тайминг:
Этот код устанавливает тайминг между различными записями дневника; если записи дневники близко друг к другу во времени, то соответствующие ноты тоже будут ближе. Наконец, мы определяем, как данные сопоставляются с высотой. Исходные значения указаны в процентах в диапазоне от 0,01 (т. е. 1%) до 0,99 (99%), так что
и последний фрагмент, чтобы сохранить данные в файл:
Сохраните этот файл с новым именем и расширением
Для каждого столбца в исходных данных делаем уникальный скрипт и не забываем изменить название выходного файла! Затем можете загрузить отдельные midi-файлы в GarageBand или LMMS для инструментирования. Вот полный дневник Джона Адамса.
Обработка уникальных midi в GarageBand или другом музыкальном редакторе означает переход от простого озвучивания к музыкальному искусству. Этот заключительный раздел статьи — не полное руководство по использованию Sonic Pi, а скорее знакомство со средой, которая позволяет в реальном времени кодировать и воспроизводить данные в виде музыки (пример кодирования с воспроизведением в реальном времени см. на видео). Встроенные в программу учебники покажут, как использовать компьютер в качестве музыкального инструмента (вы вводите код Ruby во встроенный редактор, а интерпретатор сразу проигрывает результат).
Зачем это нужно? Как можно понять из этого руководства, по мере озвучивания данных вы начинаете принимать решения, каким образом транслировать данные в звук. Эти решения отражают неявные или явные решения о том, какие данные имеют значение. Существует континуум «объективности», если хотите. С одной стороны озвученные исторические данные, с другой — представление о прошлом, такое же захватывающее и личное, как любая хорошо сделанная публичная лекция. Озвучивание позволяет реально услышать данные, которые хранятся в документах: это своего рода публичная история. Музыкальное исполнение наших данных… только представьте себе!
Здесь я предлагаю фрагмент кода для импорта данных, представляющих собой просто список значений, сохранённых как csv. Выражаю благодарность библиотекарю Университета Джорджа Вашингтона Лауре Врубель, которая выложила на gist.github.com свои эксперименты по озвучиванию библиотечных операций.
В этом образце (тематическая модель, сгенерированная из «Реляции иезуитов») есть две темы. В первой строке заголовки 'topic1' и 'topic2'.
Следуйте встроенным руководствам Sonic Pi, пока не позникомитесь с интерфейсом и возможностями (все эти учебники собраны здесь; вы также можете послушать интервью с Сэмом Аароном, создателем Sonic Pi). Затем в новый буфер (окно редактора) скопируйте следующий код (опять же, разрозненные фрагменты следует собрать в один скрипт):
Помните, что
Теперь загрузим эти данные в музыкальную композицию:
Первые несколько строк загружают столбцы данных; затем мы указываем, какой образец звука хотим использовать (фортепиано), а затем указываем играть первую тему (topic1) в соответствии с указанными критериями: для силы воспроизведения ноты (attack) выбирается случайное значение менее 0,5; для затухания (decay) — случайное значение менее 1; для амплитуды — случайное значение менее 0,25.
Видите строку с умножением на сто (
И последнее, что нужно здесь отметить: значение 'rand' (random) позволяет в музыку добавить немного «человечности» с точки зрения динамики. То же самое делаем для 'topic2'.
Ещё можно указать ритм (ударов в минуту), циклы, сэмплы и другие эффекты, которые поддерживает Sonic Pi. Место размещения кода влияет на воспроизведение: например, если поместить перед вышеприведённым блоком данных, то он сыграет первым. Например, если после строки
…то получится небольшое музыкальное вступление. Программа ждёт 2 секунды, воспроизводит сэмпл 'ambi_choir', затем ждёт ещё 6 секунд перед началом проигрывания наших данных. Если хотите добавить немного зловещего барабана на протяжении всей мелодии, поставьте следующим этот бит (перед вашими собственными данными):
Код довольно понятен: зацикленный сэмпл 'bd_boom' со звуковым эффектом реверберации на определённой скорости. Пауза между циклами 2 секунды.
Что касается «кодирования в реальном времени», это значит, что вы можете вносить изменения в код с одновременным воспроизведением этих изменений. Не нравится то, что вы слышите? Сразу изменяете код!
Изучение Sonic Pi можно начать с этого семинара. См. также доклад Лауры Врубель о посещении семинара, где также рассказывается о её работе в этой области и работах коллег.
И опять повторю: не нужно думать, что мы со своим алгоритмическим подходом находимся на переднем крае науки. В 1978 году была опубликована научная статья о «музыкальных играх в кости» 18 века, где броски костей определяли рекомбинацию предварительно написанных фрагментов музыки. Робин Ньюман изучил и закодировал для Sonic Pi некоторые из этих игр. Для музыкальной нотации Ньюман использует инструмент, который можно описать как Markdown+Pandoc, а для преобразования в ноты — Lilypond. Так что у всех тем в нашем блоге The Programming Historian давняя предыстория!
При озвучивании мы видим, что наши данные часто отражают не столько историю, сколько её интерпретацию в нашем исполнении. Отчасти так происходит из-за новизны и художественного характера, необходимого для трансляции данных в звук. Но это и сильно отличает звуковую интерпретацию от традиционной визуализации. Может, сгенерированные звуки никогда не поднимутся до уровня «музыки»; но если они помогают изменить наше понимание прошлого и воздействовать на других, то усилия того стоят. Как сказал бы Тревор Оуэнс, «Озвучивание — это открытие нового, а не обоснование известного».
Богатая литература по археоакустике и звуковым ландшафтам помогает воссоздать звук места, каким он был (например, см. Виртуальный Собор Святого Павла или работу Джеффа Вейча по древней Остии). Но мне интересно «озвучить» сами данные. Я хочу определить синтаксис для представления данных в виде звука, чтобы эти алгоритмы можно было использовать в исторической науке. Друкер сказал знаменитую фразу, что «данные» — это на самом деле не то, что дано, а скорее то, что захвачено, трансформировано, то есть 'capta'. При озвучивании данных я буквально воспроизвожу прошлое в настоящем. Поэтому на передний план выходят допущения и преобразования этих данных. Полученные звуки являются «деформированным исполнением», которое заставляет по-новому услышать современные пласты истории.
Я хочу услышать смысл прошлого, но знаю, что это невозможно. Тем не менее, когда я слышу инструмент, то могу физически представить музыканта; по отзвукам и резонансам могу различить физическое пространство. Я чувствую бас, могу двигаться в ритме. Музыка охватывает моё тело, всё воображение. Ассоциации со слышанными ранее звуками, музыкой и тонами создают глубокий темпоральный опыт, систему воплощённых взаимоотношений между мной и прошлым. Визуальность? У нас так давно существуют визуальные представления о прошлом, что эти грамматики почти потеряли художественную выразительность и перформативный аспект.
В этом уроке вы научитесь создавать некий шум из исторических данных. Значение этого шума, ну… зависит от вас. Частично смысл в том, чтобы снова сделать ваши данные незнакомыми. Транслируя, перекодируя, восстанавливая их, мы начинаем видеть элементы данных, которые оставались незаметными при визуальном рассмотрении. Эта деформация согласуется с аргументами, сделанными, например, Марком Сэмплом о деформации общества или Бетани Ноувиски о «сопротивлении материалов». Озвучивание ведёт нас от данных к «капте», от социальных наук к искусству, от глюка к эстетике. Давайте посмотрим, на что это похоже.
Содержание
- Цели и задачи
- Небольшое введение в озвучивание
- Musicalgorithms
- Кратко о настройке Python
- MIDITime
- Sonic Pi
- Nihil novi sub sole
- Заключение
Цели и задачи
В этом уроке я рассажу о трёх способах генерации звука или музыки из ваших данных.
Сначала будем использовать свободную и открытую систему Musicalgorithms, разработанную Джонатаном Миддлтоном. В ней познакомимся с ключевыми проблемами и терминами. Затем возьмём небольшую библиотеку Python для «трансляции» данных на 88-клавишную клавиатуру и привнесём в работу некое творчество. Наконец, загрузим данные в программу обработки звука и музыки в реальном времени Sonic Pi, для которой опубликовано множество учебных пособий и справочных ресурсов.
Вы увидите, как работа со звуками перемещает нас из простой визуализации в реально эффективное окружение.
Инструменты
- Musicalgorithms
- MIDITime (я сделал форк)
- Sonic Pi
Образцы данных
- Артефакты Римской империи
- Отрывок из тематической модели дневника президента Джона Адамса
- Отрывок из тематической модели «Реляции иезуитов»
Небольшое введение в озвучивание
Озвучивание (sonification) — это метод трансляции некоторых аспектов данных в звуковые сигналы. В общем, метод можно назвать «озвучиванием», если он удовлетворяет определённым условиям. К ним относятся воспроизводимость (другие исследователи могут обработать те же данные теми же способами и получить такие же результаты) и то, что можно назвать «внятность» или «разборчивость», то есть когда значимые элементы исходных данных систематически отражаются в результирующем звуке (см. Херманн, 2008). В работе Марка Ласта и Анны Усыскиной (2015) описана серия экспериментов для определения, какие аналитические задачи можно выполнить при озвучивании данных. Их экспериментальные результаты показали, что даже неподготовленные слушатели (без формального обучения музыке) могут различать данные на слух и делать полезные выводы. Они обнаружили, что слушатели способны выполнять на слух общие задачи дата-майнинга, такие как классификация и кластеризация (в своих экспериментах они транслировали базовые научные данные в масштабе западной музыки).
Ласт и Усыскина сосредоточились на временных рядах. Согласно их выводам, данные временных рядов особенно хорошо подходят для озвучивания, поскольку здесь естественные параллели. Музыка последовательна, у неё есть длительность, и она развивается со временем; так же и с данными временных рядов (Ласт, Усыскина 2015: стр. 424). Остаётся сопоставить данные с соответствующими звуковыми выходами. Для объединения аспектов данных по различным слуховым измерениям, таким как высота, вариационная форма и интервал (onset), во многих приложениях используется метод «трансляция параметров» (parameter mapping). Проблема с этим подходом в том, что если между исходными точками данных нет временной связи (или, скорее, нелинейной связи), результирующий звук может получиться «запутанным» (2015: 422).
Заполняя пробелы
Слушая звук, человек заполняет моменты тишины своими ожиданиями. Рассмотрим видео, где mp3 преобразован в MIDI и обратно в mp3; музыка «сплющена», так что вся звуковая информация воспроизводится одним инструментом (эффект похож на сохранение веб-страницы как .txt, открытии её в Word, а затем повторном сохранении в формате .html). Все звуки (включая вокал) переводятся в соответствующие значения нот, а затем снова в mp3.
Это шум, но смысл можно уловить:
Что здесь происходит? Если эта песня была вам известна, вероятно, вы поняли настоящие «слова». Но в песне нет слов! Если вы её раньше не слышали, то она звучит как бессмысленная какофония (больше примеров на сайте Энди Байо). Этот эффект иногда называют «звуковыми галлюцинациями» (auditory hallucination). Пример показывает, как в любом представлении данных мы можем слышать/видеть то, чего, строго говоря, нет. Мы заполняем пустоты собственными ожиданиями.
Что это значит для истории? Если мы озвучиваем наши данные и начинаем слышать паттерны в звуке или странные выбросы, то наши культурные ожидания о музыке (воспоминания о похожих фрагментах музыки, услышанных в определённых контекстах), окрасят нашу интерпретацию. Я бы сказал, что это верно для всех представлений о прошлом, но озвучивание достаточно сильно отличается от стандартных методов, поэтому такое самосознание помогает идентифицировать или выразить некие критические паттерны в (данных о) прошлом.
Рассмотрим три инструмента для озвучивания данных и отметим, как выбор инструмента влияет на результат, и как решить эту проблему путём переосмысления данных в другом инструменте. В конечном счёте, озвучивание не объективнее визуализации, поэтому исследователь должен быть готов оправдать свой выбор и сделать этот выбор прозрачным и воспроизводимым. (Чтобы никто не думал, что озвучивание и алгоритмически генерируемая музыка — это нечто новое, направляю заинтересованного читателя к Хеджесу, 1978).
Каждый раздел содержит концептуальное введение, а затем пошаговое руководство с использованием образцов археологических или исторических данных.
Musicalgorithms
Существует широкий спектр инструментов для озвучивания данных. Например, пакеты для популярной статистической среды R, такие как playitbyR и AudiolyzR. Но первый не поддерживается в текущей версией R (последнее обновление было несколько лет назад), а чтобы заставить второй работать должным образом, требуется серьёзная конфигурация дополнительного программного обеспечения.
В отличие от них, сайт Musicalgorithms довольно прост в использовании, он работает уже более десяти лет. Хотя исходный код не опубликован, это долгосрочный исследовательский проект по вычислительной музыке от Джонатана Миддлтона. В настоящее время он в третьей крупной версии (прежние итерации доступны в интернете). Начнём с Musicalalgorithms, потому что это позволяет быстро загрузить и настроить наши данные для выпуска представления в виде MIDI-файлов. Перед началом работы обязательно выберите третью версию.
Сайт Musicalgorithms по состоянию на 2 февраля 2016 года
Musicalgorithms производит ряд преобразований с данными. В приведённом ниже примере (по умолчанию на сайте) только одна строка данных, хотя она выглядит как несколько строк. Этот образец состоят из полей, разделённых запятыми, которые внутри разделены пробелами.
# Of Voices, Text Area Name, Text Area Data 1,morphBox, ,areaPitch1,2 7 1 8 2 8 1 8 2 8 4 5 9 0 4 5 2 3 5 3 6 0 2 8 ,dAreaMap1,2 7 1 8 2 8 1 8 2 8 4 5 9 0 4 5 2 3 5 3 6 0 2 8 ,mapArea1,20 69 11 78 20 78 11 78 20 78 40 49 88 1 40 49 20 30 49 30 59 1 20 78 ,dMapArea1,1 5 1 5 1 5 1 5 1 5 3 3 6 0 3 3 1 2 3 2 4 0 1 5 ,so_text_area1,20 69 11 78 20 78 11 78 20 78 40 49 88 1 40 49 20 30 49 30 59 1 20 78
Эти цифры представляют исходные данные и их преобразования. Совместный доступ к файлу позволяет другому исследователю повторить работу или продолжить обработку другими инструментами. Если начинать с самого начала, то нужны только исходные данные ниже (список точек данных):
# Of Voices, Text Area Name, Text Area Data 1,morphBox, ,areaPitch1,24 72 12 84 21 81 14 81 24 81 44 51 94 01 44 51 24 31 5 43 61 04 21 81
Для нас ключевым является поле 'areaPitch1' с входными данными, которые разделены пробелами. Другие поля заполнятся в ходе работы с различными настройками Musicalgorithms. В приведённых выше данных (например, 24 72 12 84 и т. д.) значения представляют собой исходные подсчёты количества надписей в британских городах вдоль римской дороги (позже попрактикуемся и с другими данными).
После загрузки данных в верхней строке меню можно выбрать различные операции. На скриншоте наведение курсора мыши на информацию выводит объяснение, что происходит при выборе операции деления для масштабирования данных до выбранного диапазона нот
Теперь при просмотре различных вкладок в интерфейсе (длительность, трансляция высоты, трансляция длительности, параметры масштаба) доступны различные преобразования. В «отображении высоты» (pitch mapping) есть ряд математических опций для трансляции данных на полную 88-клавишную клавиатуру фортепиано (в линейной трансляции среднее значение транслируется на среднюю C, то есть 40). Можно также выбрать вид шкалы: минор или мажор и так далее. На этом этапе после выбора различных преобразований необходимо сохранить текстовый файл. На вкладке File > Play можно загрузить файл midi. Ваша аудиопрограмма по умолчанию должна уметь воспроизводить midi (часто по умолчанию используются ноты фортепиано). Более сложные инструменты midi назначаются в программах-микшерах, таких как GarageBand (Mac) или LMMS (Windows, Mac, Linux). Впрочем, использование GarageBand и LMMS выходит за рамки данного руководства: видеоучебник по LMMS доступен здесь, а учебников по GarageBand полно в интернете. Например, отличное руководство на Lynda.com.
Бывает, что для одних и тех же точек имеется несколько столбцов данных. Скажем, в нашем примере из Британии мы хотим озвучить также подсчёт по типам керамики для тех же городов. Тогда вы можете перезагрузить следующий ряд данных, произвести преобразования и сопоставления — и создать другой файл MIDI. Поскольку GarageBand и LMMS позволяют накладывать голоса, то доступно создание сложных музыкальных последовательностей.
Скриншот GarageBand, где midi-файлы представляеют собой озвученные темы из дневника Джона Адамса. В интерфейсе GarageBand (и LMMS) каждый midi-файл перетаскивается мышкой на соответствующее место. Инструментарий каждого midi-файла (то есть дорожки) выбирается в меню GarageBand. Метки треков изменены, чтобы отразить ключевые слова в каждой теме. Зелёная область справа представляет собой визуализацию нот на каждой дорожке. Можете посмотреть этот интерфейс в действии и послушать музыку здесь
Какие преобразования использовать? Если у вас два столбца данных, то это два голоса. Возможно, в наших гипотетических данных имеет смысл воспроизвести первый голос громко, как главный: в конце концов, надписи в некотором роде «говорят» с нами (римские надписи буквально обращаются к прохожим: «О ты, проходящий мимо...»). А керамика, пожалуй, более скромный артефакт, который можно сопоставить с нижним концом шкалы или увеличить длительность нот, отражая её вездесущность среди представителей разных классов в этом регионе.
Не существует единственного «правильного» способа транслировать данные в звук, по крайней мере, пока нет. Но даже в этом простом примере мы видим, как в данных и их восприятии появляются оттенки смысла и интерпретации.
А как же время? Исторические данные часто имеют определённую привязку к дате. Таким образом, необходимо учитывать промежуток времени между двумя точками данных. Именно здесь становится полезным наш следующий инструмент, если точки данных соотносятся друг с другом в пространстве времени. Мы начинаем переходить от озвучивания (точки данных) к музыке (отношения между точками).
Практика
В первой колонке набора данных — количество римских монет и количество других материалов из тех же городов. Информация взята из Portable Antiquities Scheme Британского музея. Обработка этих данных может выявить некие аспекты экономической ситуации вдоль Уотлинг-стрит — главного маршрута через Римскую Британию. Точки данных расположены географически с северо-запада на юго-восток; таким образом, по мере воспроизведения звука мы слышим движение в пространстве. Каждая нота представляет собой каждую остановку на пути.
- Откройте thesonification-roman-data.csv в электронной таблице. Скопируйте первый столбец в текстовый редактор. Удалите окончания строк, чтобы все данные находились в одной строке.
- Добавьте следующую информацию:
# Of Voices, Text Area Name, Text Area Data 1,morphBox, ,areaPitch1,
…так что ваши данные следуют сразу после последней запятой (как pltcm). Сохраните файл с осмысленным названием, например,coinsounds1.csv.
- Перейдите на сайт Musicalgorithms (третья версия) и нажмите кнопку 'Load'. Во всплывающем окне нажмите синюю кнопку 'Load' и выберите файл, сохранённый на предыдущем шаге. Сайт загрузит ваши материалы и в случае успеха покажет зелёную галочку. Если это не так, убедитесь, что значения разделены пробелами и немедленно следуют за последней запятой в блоке кода. Можете попробовать загрузить демо-файл из этого руководства.

После нажатия 'Load' на главном экране появляется это диалоговое окно. Тут нажмите 'Load CSV File'. Выберите свой файл, он появится в поле. Затем нажмите кнопку 'Load' внизу
- Нажмите на 'Pitch Input', и увидите значения ваших данных. На данный момент не выбирайте на этой странице дополнительные параметры (таким образом, применяются значения по умолчанию).
- Нажмите на ‘Duration Input’. Не выбирайте пока здесь никаких опций. Данные опции произведут различные трансформации ваших данных с изменением длительности каждой ноты. Пока не беспокойтесь об этих параметрах, двигайтесь дальше.
- Нажмите ‘Pitch Mapping’. Это самый важный выбор, так как он транслирует (то есть масштабирует) ваши необработанные данные на клавиши клавиатуры. Оставьте
mappingв значении 'division' (другие параметры — трансляция по модулю или логарифмическая). ПараметрRangeот 1 до 88 использует всю длину клавиатуры из 88 клавиш; таким образом, самое низкое значение будет соответствовать самой глубокой ноте на фортепиано, а самое большое значение — самой высокой ноте. Вместо этого можно ограничить музыку диапазоном вокруг среднего C, тогда введите диапазон 25 до 60. Выдача изменится следующим образом:31,34,34,34,25,28,30,60,28,25,26,26,25,25,60,25,25,38,33,26,25,25,25. Это уже не ваши цифры, а ноты на клавиатуре.

Нажмите в поле 'Range' и укажите 25. Значения внизу изменятся автоматически. В поле 'to' установите 60. Если перейти в другое поле, значения обновятся
- Нажмите 'Duration Mapping'. Как и при трансляции высоты, здесь программа берёт указанный диапазон времени и использует различные математические параметры для трансляции этого диапазона в ноты. Если навести курсор на
i, вы увидите, какие цифры соответствуют целым нотам, четвертям, восьмым и так далее. Пока оставьте значения по умолчанию.
- Нажмите ‘Scale Options’. Здесь мы начинаем работать с тем, что соответствует в некотором смысле «эмоциональному» аспекту. Обычно мажорная гамма воспринимается как «радостная», а минорная — как «грустная»; подробное обсуждение этой темы см. в здесь. Пока оставьте ‘scale by: major’. Оставьте 'scale' в значении
С.
Итак, мы озвучили один столбец данных! Нажмите 'Save', затем 'Save CSV'.
Диалоговое окно 'Save'
У вас получится примерно такой файл:
# Of Voices, Text Area Name, Text Area Data 1,morphBox, ,areaPitch1,80 128 128 128 1 40 77 495 48 2 21 19 1 1 500 1 3 190 115 13 5 1 3 ,dAreaMap1,2 7 1 8 2 8 1 8 2 8 4 5 9 0 4 5 2 3 5 3 6 0 2 ,mapArea1,31 34 34 34 25 28 30 60 28 25 26 26 25 25 60 25 25 38 33 26 25 25 25 ,dMapArea1,1 5 1 5 1 5 1 5 1 5 3 3 6 0 3 3 1 2 3 2 4 0 1 ,so_text_area1,32 35 35 35 25 28 30 59 28 25 27 27 25 25 59 25 25 39 33 27 25 25 25
Исходные данные остались в поле 'areaPitch1', а дальше идут созданные сопоставления. Сайт позволяет генерировать в одном MIDI-файле до четырёх голосов одновременно. В зависимости от того, какие инструменты вы желаете использовать впоследствии, вы можете выбрать генерацию по одному MIDI-файлу за раз. Давайте запустим музыку: нажмите 'Play'. Здесь вы выбираете темп и инструмент. Свои данные можно прослушать в браузере или сохранить как MIDI-файл синей кнопкой ‘Save MIDI file’.
Вернёмся к началу и загрузим в этот шаблон оба столбца данных:
# Of Voices, Text Area Name, Text Area Data 2,morphBox, ,areaPitch1, ,areaPitch2,
Тут мы находимся на странице с параметрами 'pitch input'. Вверху окна укажите два голоса, теперь на любой странице с параметрами открываются два окна для двух голосов. Как и раньше, загружаем данные в формате CSV, но файл нужно отформатировать, чтобы там были указаны значения 'areaPitch1' и 'areaPitch2'. Данные для первого голоса появятся слева, а второго — справа
Если у нас несколько голосов, что вынести на первый план? Обратите внимание, что при таком подходе в нашей озвучке не учитывается расстояние между точками в реальном мире. Если учитывать, то оно сильно повлияет на результат. Конечно, расстояние не обязательно привязывать к географии — его можно привязать ко времени. Следующий инструмент позволит явно указать этот фактор при озвучивании.
Кратко о настройке Python
Для данного раздела руководства потребуется Python. Если вы ещё не экспериментировали с этим языком, придётся потратить некоторое время на знакомство с командной строкой. См. также краткое руководство по установке модулей.
На маках Python уже установлен. Можете проверить: нажмите COMMAND и пробел, в окне поиска введите
terminal и нажмите на приложение терминала. Команда $ type python —version покажет, какая установлена версия Python у вас есть. В статье мы работаем с Python 2.7, код не проверялся в Python 3.Пользователям Windows нужно установить Python самостоятельно: начните с этой страницы, хотя всё немного сложнее, чем там написано. Во-первых, надо скачать файл
.msi (Python 2.7). Запустите инсталлятор, он установится в новый каталог, например, C:\Python27\. Затем нужно прописать этот каталог в путях, то есть сообщить Windows, где искать Python, когда вы запускаете питоновскую программу. Есть несколько способов сделать это. Возможно, проще всего найти на компьютере программу Powershell (введите 'powershell' в строке поиска Windows). Откройте Powershell и в командной строке вставьте это целиком:[Environment]::SetEnvironmentVariable("Path", "$env:Path;C:\Python27\;C:\Python27\Scripts\", "User")Если по нажатию Enter ничего не произойдёт, значит, команда сработала. Для проверки откройте командную строку (вот 10 способов сделать это) и введите
python --version. Должен отобразиться ответ с указанием Python 2.7.10 или похожей версии.Последняя часть головоломки — программа под названием
Pip. Пользователи Mac могут установить её командой в терминале sudo easy_install pip. Пользователям Windows придётся немного сложнее. Во-первых, щелкните правой кнопкой мыши и сохраните файл по этой ссылке (если просто нажать на ссылку, код get-pip.py откроется в браузере). Сохраните его где-нибудь под рукой. Откройте командную строку в каталоге, где вы сохранили get-pip.py. Затем введите в командной строке python get-pip.py.Когда у вас есть питоновский код, который вы хотите запустить, вставьте его в текстовый редактор и сохраните файл с расширением
.py. Это текстовый файл, но расширение файла говорит компьютеру использовать для интерпретации Python. Он запускается из командной строки, где сначала указывается название интерпретатора, а потом имя файла: python my-cool-script.py.MIDITime
MIDITime — питоновский пакет, разработанный Reveal News (раньше организация называлась Центр журналистских расследований). Репозиторий на Github. Программа MIDITime разработана специально для обработки временных рядов (то есть последовательности наблюдений, собранных с течением времени).
В то время как у Musicalgorithms более или менее интуитивно понятный интерфейс, здесь преимуществом является открытый исходный код. Что ещё более важно, предыдущий инструмент не умеет учитывать данные с учётом исторического времени. MIDITime позволяет кластеризовать информацию по этому фактору.
Предположим, у нас есть исторический дневник, к которому применили тематическую модель. Результирующие выходные данные могут содержать записи дневника в виде строк, а в колонках будет процентный вклад каждой темы. В этом случае прослушивание значений поможет понять такие паттерны мышления из дневника, какие невозможно передать в виде графика. На слух сразу заметны выбросы или повторяющиеся музыкальные паттерны, которые не видны на графике.
Установка MIDITime
Установка одной командой pip:
$ pip install miditimeдля маков;
$ sudo pip install miditimeпод Linux;
> python pip install miditimeпод Windows (если инструкция не работает, можете попробовать эту вспомогательную программу для установки Pip).
Практика
Рассмотрим пример скрипта. Откройте текстовый редактор, скопируйте и вставьте этот код:
#!/usr/bin/python
from miditime.miditime import MIDITime
# NOTE: this import works at least as of v1.1.3; for older versions or forks of miditime, you may need to use
# from miditime.MIDITime import MIDITime
# Instantiate the class with a tempo (120bpm is the default) and an output file destination.
mymidi = MIDITime(120, 'myfile.mid')
# Create a list of notes. Each note is a list: [time, pitch, attack, duration]
midinotes = [
[0, 60, 200, 3], #At 0 beats (the start), Middle C with attack 200, for 3 beats
[10, 61, 200, 4] #At 10 beats (12 seconds from start), C#5 with attack 200, for 4 beats
]
# Add a track with those notes
mymidi.add_track(midinotes)
# Output the .mid file
mymidi.save_midi()Сохраните скрипт как
music1.py. В терминале или командной строке запустите его:$ python music1.pyВ каталоге будет создан новый файл
myfile.mid. Его можно открыть для прослушивания с помощью Quicktime или Windows Media Player (и добавить туда инструменты в GarageBand или LMMS).Music1.py импортирует miditime (не забудьте установить его перед запуском скрипта: pip install miditime). Затем задаёт темп. Все ноты перечислены отдельно, где первое число — это время начала воспроизведения, высота (т. е. сама нота!), насколько сильно или ритмично играется нота (attack) и её длительность. Затем ноты записываются на дорожку, а сам трек записывается в файл myfile.mid.Поиграйте со скриптом, добавьте больше нот. Вот ноты для песенки 'Baa Baa Black Sheep':
D, D, A, A, B, B, B, B, A Baa, Baa, black, sheep, have, you, any, wool?
Можете написать инструкции, чтобы компьютер сыграл мелодию (вот диаграмма в помощь)?
Кстати. Существует специальный формат текстового файла для описания музыки под названием ABC Notation. Он выходит за рамки этой статьи, но скрипт для озвучивания можно написать, скажем, в электронных таблицах, сопоставляя значения нот в АВС-нотации (если вы когда-нибудь использовали конструкцию IF — THEN в Excel, то имеете представление, как это делается), а затем через сайты вроде этого АВС-нотация преобразуется в файл .mid.
Загрузка собственных данных
Этот файл содержит выборку из тематической модели дневников Джона Адамса для сайта Macroscope. Тут оставили только самые сильные сигналы, округлив значений в столбцах до двух десятичных знаков. Чтобы вставить эти данные в питоновский скрипт, нужно их особым образом отформатировать. Сложнее всего с полем даты.
Для этого урока оставим имена переменных и остальное без изменений из скрипта с примером. Пример разработан для обработки данных землетрясений; поэтому здесь «магнитуду» можно представить как наш «вклад темы».
my_data = [
{'event_date': <datetime object>, 'magnitude': 3.4},
{'event_date': <datetime object>, 'magnitude': 3.2},
{'event_date': <datetime object>, 'magnitude': 3.6},
{'event_date': <datetime object>, 'magnitude': 3.0},
{'event_date': <datetime object>, 'magnitude': 5.6},
{'event_date': <datetime object>, 'magnitude': 4.0}
]Для форматирования данных можно использовать регулярные выражения, а ещё проще — электронные таблицы. Скопируйте элемент со значением вклада темы на новый лист и оставьте столбцы слева и справа. В приведённом ниже примере я поместил его в столбец D, а затем заполнил остальные:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 1 | {‘event_date’: datetime | (1753,6,8) | , ‘magnitude’: | 0.0024499630 | }, |
| 2 | |||||
| 3 |
Затем скопируйте и вставьте неизменяемые элементы, заполнив весь столбец. Элемент с датой должен быть в формате (год, месяц, день). После заполнения таблицы её можно скопировать и вставить в текстовый редактор, сделав частью массива
my_data, например:my_data = [
{'event_date': datetime(1753,6,8), 'magnitude':0.0024499630},
{'event_date': datetime(1753,6,9), 'magnitude':0.0035766320},
{'event_date': datetime(1753,6,10), 'magnitude':0.0022171550},
{'event_date': datetime(1753,6,11), 'magnitude':0.0033220150},
{'event_date': datetime(1753,6,12), 'magnitude':0.0046445900},
{'event_date': datetime(1753,6,13), 'magnitude':0.0035766320},
{'event_date': datetime(1753,6,14), 'magnitude':0.0042241550}
]Обратите внимание, что в конце последней строки нет запятой.
Окончательный скрипт будет выглядеть примерно так, если использовать пример со страницы самого Miditime (фрагменты кода ниже прерываются комментариями, но в текстовый редактор их следует вставить вместе как один файл):
from miditime.MIDITime import MIDITime
from datetime import datetime
import random
mymidi = MIDITime(108, 'johnadams1.mid', 3, 4, 1)Значения после MIDITime устанавливаются как
MIDITime(108, 'johnadams1.mid', 3, 4, 1), здесь:- количество ударов в минуту (108),
- выходной файл (‘johnadams1.mid’),
- количество секунд в музыке для представления одного года в истории (3 секунды на календарный год, поэтому записи дневника за 50 лет масштабируются в мелодию длиной 50?3 секунд, то есть две с половиной минуты),
- базовая октава для музыки (средняя C обычно представлена как C5, поэтому здесь 4 соответствует октаве на одну ниже опорной),
- и количество октав для сопоставления высот.
Теперь передаём данные в скрипт, загрузив их в массив
my_data:my_data = [
{'event_date': datetime(1753,6,8), 'magnitude':0.0024499630},
{'event_date': datetime(1753,6,9), 'magnitude':0.0035766320},… здесь вставляем все данные и не забываем удалить запятую в конце последней строчки
event_date, а после данных поставить завершающую скобку на отдельной строке:{'event_date': datetime(1753,6,14), 'magnitude':0.0042241550}
]затем вставляем тайминг:
my_data_epoched = [{'days_since_epoch': mymidi.days_since_epoch(d['event_date']), 'magnitude': d['magnitude']} for d in my_data]
my_data_timed = [{'beat': mymidi.beat(d['days_since_epoch']), 'magnitude': d['magnitude']} for d in my_data_epoched]
start_time = my_data_timed[0]['beat']Этот код устанавливает тайминг между различными записями дневника; если записи дневники близко друг к другу во времени, то соответствующие ноты тоже будут ближе. Наконец, мы определяем, как данные сопоставляются с высотой. Исходные значения указаны в процентах в диапазоне от 0,01 (т. е. 1%) до 0,99 (99%), так что
scale_pct устанавливаем между 0 и 1. Если у нас не проценты, то используем самое низкое и самое высокое значения. Таким образом, вставляем следующий код:def mag_to_pitch_tuned(magnitude):
scale_pct = mymidi.linear_scale_pct(0, 1, magnitude)
# Pick a range of notes. This allows you to play in a key.
c_major = ['C', 'C#', 'D', 'D#', 'E', 'E#', 'F', 'F#', 'G', 'G#', 'A', 'A#', 'B', 'B#']
#Find the note that matches your data point
note = mymidi.scale_to_note(scale_pct, c_major)
#Translate that note to a MIDI pitch
midi_pitch = mymidi.note_to_midi_pitch(note)
return midi_pitch
note_list = []
for d in my_data_timed:
note_list.append([
d['beat'] - start_time,
mag_to_pitch_tuned(d['magnitude']),
random.randint(0,200), # attack
random.randint(1,4) # duration, in beats
])и последний фрагмент, чтобы сохранить данные в файл:
# Add a track with those notes
mymidi.add_track(midinotes)
# Output the .mid file
mymidi.save_midi()Сохраните этот файл с новым именем и расширением
.py.Для каждого столбца в исходных данных делаем уникальный скрипт и не забываем изменить название выходного файла! Затем можете загрузить отдельные midi-файлы в GarageBand или LMMS для инструментирования. Вот полный дневник Джона Адамса.
Sonic Pi
Обработка уникальных midi в GarageBand или другом музыкальном редакторе означает переход от простого озвучивания к музыкальному искусству. Этот заключительный раздел статьи — не полное руководство по использованию Sonic Pi, а скорее знакомство со средой, которая позволяет в реальном времени кодировать и воспроизводить данные в виде музыки (пример кодирования с воспроизведением в реальном времени см. на видео). Встроенные в программу учебники покажут, как использовать компьютер в качестве музыкального инструмента (вы вводите код Ruby во встроенный редактор, а интерпретатор сразу проигрывает результат).
Зачем это нужно? Как можно понять из этого руководства, по мере озвучивания данных вы начинаете принимать решения, каким образом транслировать данные в звук. Эти решения отражают неявные или явные решения о том, какие данные имеют значение. Существует континуум «объективности», если хотите. С одной стороны озвученные исторические данные, с другой — представление о прошлом, такое же захватывающее и личное, как любая хорошо сделанная публичная лекция. Озвучивание позволяет реально услышать данные, которые хранятся в документах: это своего рода публичная история. Музыкальное исполнение наших данных… только представьте себе!
Здесь я предлагаю фрагмент кода для импорта данных, представляющих собой просто список значений, сохранённых как csv. Выражаю благодарность библиотекарю Университета Джорджа Вашингтона Лауре Врубель, которая выложила на gist.github.com свои эксперименты по озвучиванию библиотечных операций.
В этом образце (тематическая модель, сгенерированная из «Реляции иезуитов») есть две темы. В первой строке заголовки 'topic1' и 'topic2'.
Практика
Следуйте встроенным руководствам Sonic Pi, пока не позникомитесь с интерфейсом и возможностями (все эти учебники собраны здесь; вы также можете послушать интервью с Сэмом Аароном, создателем Sonic Pi). Затем в новый буфер (окно редактора) скопируйте следующий код (опять же, разрозненные фрагменты следует собрать в один скрипт):
require 'csv'
data = CSV.parse(File.read("/path/to/your/directory/data.csv"), {:headers => true, :header_converters => :symbol})
use_bpm 100Помните, что
path/to/your/directory/ — это фактическое местоположение ваших данных на компьютере. Убедитесь, что файл действительно называется data.csv, или отредактируйте эту строчку в коде.Теперь загрузим эти данные в музыкальную композицию:
#this bit of code will run only once, unless you comment out the line with
#'live_loop', and also comment out the final 'end' at the bottom
# of this code block
#'commenting out' means removing the # sign.
# live_loop :jesuit do
data.each do |line|
topic1 = line[:topic1].to_f
topic2 = line[:topic2].to_f
use_synth :piano
play topic1*100, attack: rand(0.5), decay: rand(1), amp: rand(0.25)
use_synth :piano
play topic2*100, attack: rand(0.5), decay: rand(1), amp: rand(0.25)
sleep (0.5)
endПервые несколько строк загружают столбцы данных; затем мы указываем, какой образец звука хотим использовать (фортепиано), а затем указываем играть первую тему (topic1) в соответствии с указанными критериями: для силы воспроизведения ноты (attack) выбирается случайное значение менее 0,5; для затухания (decay) — случайное значение менее 1; для амплитуды — случайное значение менее 0,25.
Видите строку с умножением на сто (
*100)? Она берёт наше значение данных (десятичную дробь) и превращает его в целое число. В этом фрагменте число непосредственно приравнивается к ноте. Если самая низкая нота 88, а самая высокая 1, то этот подход немного проблематичен: мы на самом деле здесь не отображаем никакой высоты! В этом случае можете использовать Musicalgorithms для отображения высоты, а затем передать эти значения обратно в Sonic Pi. Кроме того, поскольку этот код более или менее стандартный Ruby, вы можете применить обычные способы нормализации данных, а затем сделать линейное сопоставление ваших значений с диапазоном 1?88. Для начала неплохо посмотреть на работу Стива Ллойда по озвучиванию погодных данных с Sonic Pi.И последнее, что нужно здесь отметить: значение 'rand' (random) позволяет в музыку добавить немного «человечности» с точки зрения динамики. То же самое делаем для 'topic2'.
Ещё можно указать ритм (ударов в минуту), циклы, сэмплы и другие эффекты, которые поддерживает Sonic Pi. Место размещения кода влияет на воспроизведение: например, если поместить перед вышеприведённым блоком данных, то он сыграет первым. Например, если после строки
use_bpm 100 вставить следующее:#intro bit
sleep 2
sample :ambi_choir, attack: 2, sustain: 4, rate: 0.25, release: 1
sleep 6…то получится небольшое музыкальное вступление. Программа ждёт 2 секунды, воспроизводит сэмпл 'ambi_choir', затем ждёт ещё 6 секунд перед началом проигрывания наших данных. Если хотите добавить немного зловещего барабана на протяжении всей мелодии, поставьте следующим этот бит (перед вашими собственными данными):
#bit that keeps going throughout the music
live_loop :boom do
with_fx :reverb, room: 0.5 do
sample :bd_boom, rate: 1, amp: 1
end
sleep 2
endКод довольно понятен: зацикленный сэмпл 'bd_boom' со звуковым эффектом реверберации на определённой скорости. Пауза между циклами 2 секунды.
Что касается «кодирования в реальном времени», это значит, что вы можете вносить изменения в код с одновременным воспроизведением этих изменений. Не нравится то, что вы слышите? Сразу изменяете код!
Изучение Sonic Pi можно начать с этого семинара. См. также доклад Лауры Врубель о посещении семинара, где также рассказывается о её работе в этой области и работах коллег.
Ничего нового под солнцем
И опять повторю: не нужно думать, что мы со своим алгоритмическим подходом находимся на переднем крае науки. В 1978 году была опубликована научная статья о «музыкальных играх в кости» 18 века, где броски костей определяли рекомбинацию предварительно написанных фрагментов музыки. Робин Ньюман изучил и закодировал для Sonic Pi некоторые из этих игр. Для музыкальной нотации Ньюман использует инструмент, который можно описать как Markdown+Pandoc, а для преобразования в ноты — Lilypond. Так что у всех тем в нашем блоге The Programming Historian давняя предыстория!
Заключение
При озвучивании мы видим, что наши данные часто отражают не столько историю, сколько её интерпретацию в нашем исполнении. Отчасти так происходит из-за новизны и художественного характера, необходимого для трансляции данных в звук. Но это и сильно отличает звуковую интерпретацию от традиционной визуализации. Может, сгенерированные звуки никогда не поднимутся до уровня «музыки»; но если они помогают изменить наше понимание прошлого и воздействовать на других, то усилия того стоят. Как сказал бы Тревор Оуэнс, «Озвучивание — это открытие нового, а не обоснование известного».
Термины
- MIDI: цифровой интерфейс музыкальных инструментов. Это описание высоты и длительности нот, а не их динамики способа воспроизведения (это важное различие). Это общий язык для компьютеров и музыкальных инструментов. К MIDI-файлу можно применить различные инструменты, словно изменить шрифт в тексте.
- MP3: формат сжатия звука с потерями в том смысле, что при сжатии часть данных удаляется.
- Высота: сама фактическая нота (средняя C и т. д.)
- Атака: как играется нота или удар
- Длительность: как долго длится нота (целые ноты, четверти, восьмые и т. д.)
- Трансляция высоты и длительности: масштабирование значений данных по диапазону нот или длительности ноты
- Амплитуда: грубо говоря, громкость ноты