
Причём, регистрация прошла аж в 2017 году. (ссылка для интересующихся) и с тех пор на хабре ни строчки об этом.
Итак, встречайте — Arenadata Hadoop (ADH)!
Первые впечатления:
Перешёл на сайт и… Последний раз такую комбинацию озадаченности и недоумения испытал в 2014, когда встретил в магазине белорусских устриц.
Судите сами:
вот сайт Arenadata
вот сайт Hortonworks

Основные цвета — зелёный и серый.
Оба дистрибутива используют Ambari для управления кластером, только у ADP есть надпись Arenadata, а у Horton — нет:
После этого перешёл в раздел Roadmap, посмотреть версии компонентов и первая реакция была «зачем нужно было транспонировать таблицу?»:
Вариант от Horton:
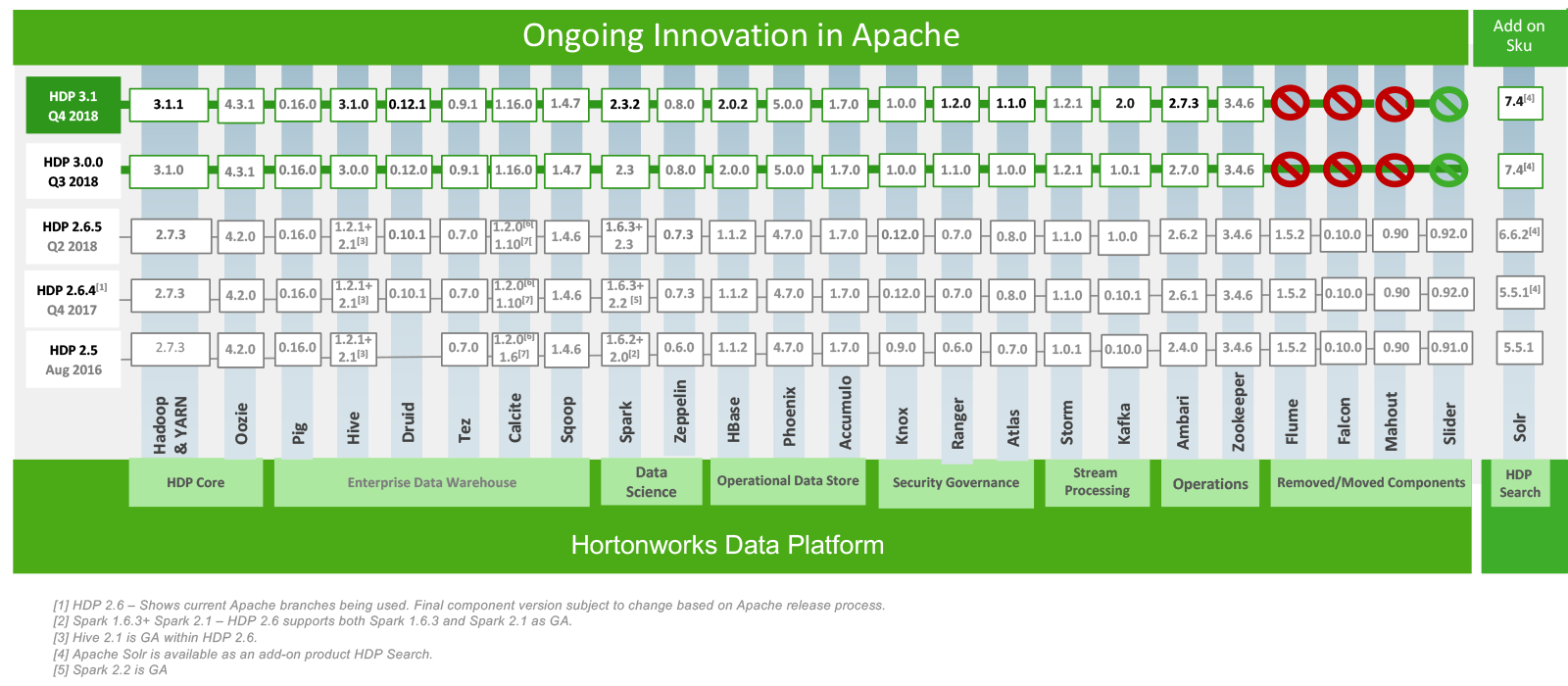
И версия Arenadata:
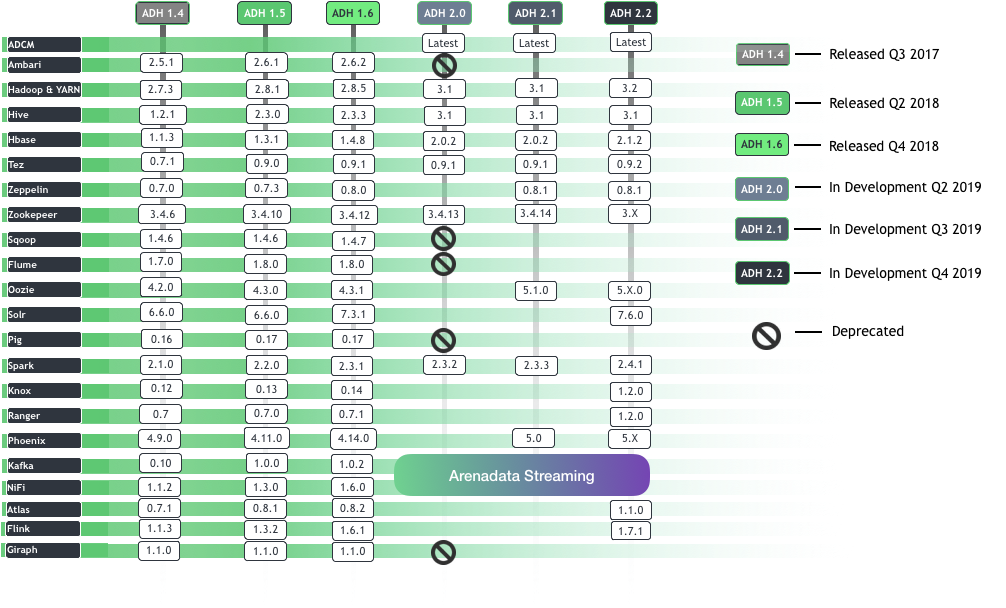
После этого стало немного грустно и решил было, что «импортозамещение» закончилось переклееной этикеткой, особенно заметив Greenplum в качестве Arenadata DB и Arenadata Grid в списке продуктов, но потом внимательно вгляделся в версии пакетов и понял, что основа взята у Hortonworks, а наполнение своё, и это радует.
Небольшое лирическое отступление: да, я знаю, что Hortonworks и Cloudera слились, но компания ещё 3 года будут выпускать дистрибутивы под прежними торговыми марками, поэтому я не называю Hortonworks Clouder'ой, хотя мог бы.
Из плюсов — есть русскоязычная документация и поддержка ( новички и те, кто работал с поддержкой в виде индусов в Америке — должен оценить), правда, поддержка по подписке, а форума, где можно бесплатно задать вопросы о наболевшем как у Cloudera/Horton я не нашёл.
А теперь немного странностей: на сайте прописаны 2 версии: Enterprise и Platform, причем Enterprise изрядно непонятный — без Spark, Zeppelin и Ranger, а для скачки доступна только одна версия и та без права выбора.
Впрочем, судя по наличию Ranger, доступна наиболее полная сборка Arenadata Hadoop Platform.
Но это так, мелочи.
Интересны лишь 2 вещи: когда выйдет в релиз ADP 2.0 с Hadoop 3 под капотом — даёшь Yarn-on-GPU, способный конкурировать с релизами от Cloudera и качество поддержки — способна ли она раскопать и решить низкоуровневый баг или будет заведен тикет в Apache Foundation и нужно будет ждать ответ.
PS: не стал скачивать и локально ставить дистрибутив по одной простой причине: привык работать с многонодовыми кластерами, а после локальной установки (читаем — никаких тысяч ядер и терабайтов RAM) впечатление было бы изрядно испорчено.
Комментарии (22)

sshikov
02.06.2019 22:07>Из плюсов — есть русскоязычная документация и поддержка ( новички и те, кто работал с поддержкой в виде индусов в Америке — должен оценить),
В смысле, кому и кто должен? Не, я понимаю что русскоязычная поддержка желательна, но в реальности определяющим все-таки является ее качество, а какое оно будет — еще неизвестно.
Впрочем, вы кажется двумя абзацами ниже практически тоже самое пишете.
>изрядно непонятный — без Spark, Zeppelin и Ranger,
Насколько я понимаю, Ranger это аналог Sentry (ну или наоборот)? Да, это странно для энтерпрайза, как и отсутствие спарка.
Ну а так Zeppelin скажем у нас тоже нет — и ничего, как-то никто не страдает, это все-таки не критичная часть дистрибутива, вполне можно и отдельно доставить.
Ну и в целом удивляетесь вы зря, мне кажется. Есть проект bigtop, на основе которого вполне можно собрать свою сборку. Это не будет совсем легко, конечно же, но и не запредельно сложно.DrunkBear Автор
01.06.2019 22:46Можно и руками собрать из пакетов, но удовольствия при этом не получаешь, зато багов…
Кстати, новичкам Data Engeneer'ам советовал бы попробовать этот путь, скакать по граблям очень познавательно.
PS Ходят слухи с той стороны океана, что от Sentry откажутся в дистрибутивах Cloudera CDH в пользу Ranger.
loltrol
02.06.2019 22:10Взяли за основу древнюю версию. Код полностью скопирован с hdp и hdf с минимальными допилами. Аж прослезился, давно уже не видел этот древний код.
DrunkBear Автор
02.06.2019 00:23Искренне надеюсь, что выйдет новая версия.
Импортозамещение же!
Поэтому пойдёт в госорганы, значит, любой поддержке придётся копаться и настраивать не самый свежий релиз.

kxl
02.06.2019 11:55Используем в проде, 2 года версию 1.4 на кластере побольше (2448 VCores), и недавно начали использовать 1.6 на кластере поменьше…
Полет нормальный.
Без поддержжки иногда бывает непросто — не все ответы находятся в Интернете.
И, может не нужно ругать Аренадату за использование не самых свежих релизов. Да, как разработчику — хочется новое, фичастое… Но, потеря важных данных на непроверенных версиях может выйти боком…DrunkBear Автор
02.06.2019 12:07Стоял HDP 2.6 с llap, который админы никак не хотели включать — мол, Tez проверенный движок, а это какие-то новомодные заморочки.
После того, как на удалось на админов надавить и включили — запросы ускорились раз в 20, а примитивные запросы типа «select * from… limit 10» начали вместо 2 минут исполняться 0.9 секунд.
Пришли ошаращенные Data Scientists и задали два вопроса: — Что это такое вы сделали и почему этого раньше не сделали?!
Мораль истории проста: не всё, что проверено временем, полезно.
А новые версии можно ( и нужно) на небольшом тестовом кластере обкатывать.
PS В Arenadata добавлен LLAP в качестве движка для Hive?
kapustor
02.06.2019 13:00Да, LLAP есть, но, со слов нашей поддержки, вам очень повезло что он работает хорошо. У нас были кейсы с ним, используем очень осторожно.
kapustor
02.06.2019 12:58Всем привет.
Я отвечаю за продуктовое наполнение платформы в Arenadata. Попробую ответить на вопросы в статье и в комментариях. В нашей платформе я технически больше погружен в Greenplum и Clickhouse, чем в Hadoop, но постараюсь использовать экспертизу коллег. Боюсь, правда, получится очень много букв :)
Для начала, кто мы такие. Команда Arenadata (AD) формировалась в 2014-2017 году. Все мы (на тот момент около 5 человек, сейчас уже больше 40) до AD многие годы занимались корпоративными хранилищами данных (КХД) — кто-то разрабатывал Hadoop и Greenplum (CEO и CTO пришли из Pivotal), кто-то внедрял в интеграторах (Glowbyte), кто-то поддерживал на местах (я занимался эксплуатацией Greenplum и Hadoop в Tinkoff). В какой-то момент мы поняли, что объединившись мы сможем улучшить те open-source проекты, с которыми до этого работали, объединив их в единую платформу и наделив её enterprise-фичами — глубоким саппортом, единым мониторингом и управлением, обучающими программами для спецов заказчика и возможностью менять код под заказчиков.
При этом мы не просто собираем open-source на коленке и продаём:
1) Большинство наших разработок мы отдаём в open-source (комитим в проекты, больше всего в Greenplum, в Hadoop поменьше)
2) Мы разрабатываем собственную систему управления кластерами (вот тут и тут можно посмотреть как это выглядит), и она доступна абсолютно бесплатно на нашем сайте. Код также скоро будет открыт. Мы берём деньги лишь за техподдержку.
Да вы же просто слизали всё у Хортона! DrunkBear
И да, и нет. Мы никогда не ставили себе целью сильно отличаться от Hortonworks (точнее, от Bigtop) — это банально вопрос совместимости, заказчики не хотят vendor lock-in. Более того, специально для того, чтобы не отличаться от Хортон и Клаудеры, в 2015-м году мы прошли сертификацию нашего дистрибутива в ODPi — часть Linux Foundation (и каждый год проходим её снова) — это гарантия того, что мы не делаем наколеночного, закрытого и несовместимого ни с чем решения.
Также, мы никогда не будем сильно отличаться от Bigtop ещё и потому, что более-менее серьёзные изменения в коде мы комитим в сам Bigtop и другие репы. Кстати, один из наших PR принял лично Alan Gates.
С другой стороны, мы видим слабые стороны у дистрибутивов Хортона и Кладудеры (хотя теперь уже не разберёшь кто есть кто), которые мы смогли сделать своими преимуществами:
1) Сильное отставание версий компонентов от upstream
2) Невозможность обновлять компоненты по отдельности (по краней мере без танцев с бубном, но мы же говорим об Enterprise, верно?)
Поэтому версии компонентов у нас всегда немного впереди (про 3.0 чуть дальше), а благодаря нашему Cluster Manager заказчики могут обновлять компоненты по отдельности.
Когда наконец будет 3.х? DrunkBear
Ох, тоже самое спрашивают наши заказчики) С 3.х есть два нюанса:
1) Недавно было объявлено, что Ambari — deprecated и скоро умрет, поэтому мы решили полностью отказаться от Ambari в нашем 3.х и перевести всё управление в Arenadata Cluster Manager, чем сейчас и занимаемся. Это займёт ещё несколько месяцев, дальше будет проще.
2) По мнению наших спецов, 3.х ещё всё-таки не настолько стабилен, чтобы брать его на саппорт.
Что с саппортом? Можете ли вы соответствовать уровню хортона? DrunkBear
Да, можем, а за счёт 3-го пункта мы даже немного лучше:
1) У нас саппорт 24х7, за счёт того что наши специалисты находятся в разных часовых поясах в России
2) За этот год мы очень сильно нарастили ресурсы на саппорт — сейчас это самый многочисленный отдел в AD (9 человек + подключаем разработчиков на сложные кейсы)
3) В отличии от Хортона и Клаудеры, мы готовы адаптировать дистрибутив под адекватные хотелки заказчиков — в том числе вносить (комитить) изменения в основные OS-репы. Мы здесь, в России, с нами можно и нужно встречаться, договариваться и развивать продукты вместе.
Ваше импортозамещение — это переклеенная этикетка DrunkBear
Вот тут будет сложно, но я попробую.
1) В первую очередь, в нашу платформу входят дистрибутивы продуктов (Hadoop, Greenplum, Clickhouse), а не их аналоги или свои разработки с нуля. Мы нигде и никогда не скрывали, что используем OS-проекты. Разрабатывать с нуля свой аналог дистрибутива Hadoop в 2019-м году — безумие.
2) Работать с open-source можно и нужно только одним способом — делиться ресурсами, отдавая свои наработки в open-source. Это не просто (куча бюрократии, согласований, общения с сообществом и тд), но мы это знаем и умеем. Это значит, что у нас (надеюсь) никогда и не будет своего отдельного форка Hadoop или Greenplum. При этом, мы делаем много дополнительного функционала (коннеткоры, управлялки и тд).
3) Рискую отхватить за политику, но я попробую.
Откуда растут ноги у импортозамещения? Всё просто: большие государственные (иногда и частные) предприятия опасаются, что в какой-то момент они не смогут использовать зарубежное ПО из-за:
— санкций с нашей стороны
— санкций с той стороны
— валютных изменений
— ухода экспертизы по этому ПО с нашего рынка
Мы закрываем эти риски. Более того, в случае глобального экстерминатуса (т-т-т), мы сможем поддерживать и развивать эти OS-проекты независимо (повторюсь, это не является целью).
4) Импортозамещение — не основной драйвер нашего бизнеса, так как большинство наших заказчиков — частные компании, которые в первую очередь ценят экспертизу (Х5 Retail Group, IQ Option, Touch Bank и другие). Потребность в импортозамещении у госов — приятный бонус, не более.
А Pivotal и Hortonworks вообще знают, чем вы тут занимаетесь?
Не просто знают, а ещё и помогают нам. Вот тут к нам на митап приехал Pivotal Director of Data Engineering, а вот тут я выступал на Greenplum Day в Нью-Йорке вместе с CIO Morgan Stanley — крупнейшим пользователем Greenplum в мире. Так работает open-source — рынок захватывает технлология, а уже потом его делят вендоры.
Где Ranger и Zeppelin? sshikov
Ranger есть в платформе, на сайте, увы, сильно устаревшая информация. Мы использовали его в двух проектах, всё ок. Sentry действительно похоже умирает.
А вот от Hue мы отказались в пользу Zeppelin (он у нас выделен в отдельный продукт, как и Kafka) — кстати, рекомендую, новый Zeppelin 0.8 стал очень крутым.
Код полностью скопирован с hdp и hdf с минимальными допилами loltrol
Выше я ответил, почему это так и почему это правильно.
Взяли за основу древнюю версию. loltrol
Вот тут не очень понял — можете указать на версии компонентов, которые по вашему мнению устарели? Уточню у наших ребят.
Сайт у вас отстой.
Мы знаем :( Этот сайт создавался когда нас было 5 человек, мы вообще плохо умеем в дизайн и сайты. Этим летом хотим переделать, если у вас есть контакты студии, которая сможет сделать сайт не хуже pivotal.io — поделитесь в ЛС плз.
Почему у вас нет блога на хабре? Почему так мало информации?
Блога нет, потому что дорого :)
Информации о нас в открытом доступе мало, потому что рынок очень узкий, и мы своих потенциальных заказчиков знаем и так.
Ну и плюс мы активно участвуем в конференциях, организуем митапы и т.д.
А ещё...
А ещё мы:
1) Раз в квартал проводим митапы по распределённым системам — присоединяйтесь, следующий будет в сентябре, сможете спросить и высказать нам всё лично :)
2) Ведём чат в ТГ по Greenplum, там есть почти все наши заказчики — можете спросить их о качестве нашего сервиса
3) Сейчас совместно с Яндекс запускаем продукт на базе Clickhouse — детали сможем опубликовать чуть позже, но получается круто!
Мне кажется, получилось очень много информации для комментария. Есть ли смысл оформить отдельную статью, где рассказать о нас подробней?sshikov
02.06.2019 13:30>Где Ranger и Zeppelin? sshikov
>Ranger есть в платформе, на сайте, увы, сильно устаревшая информация. Мы использовали его в двух проектах, всё ок. Sentry действительно похоже умирает.
Ну я на самом деле несколько не так спрашивал :) Но не важно. Мы реально нахлебались с Sentry, и не то чтобы хотели заменить на что-то (вряд ли имея не один большой 24/7 кластер это возможно сделать просто), но по крайней мере попробовать альтернативы было бы неплохо.
kxl
02.06.2019 15:39Hue как средство выполнения запросов, действительно — отстой, но Zeppelin не будет полноценной заменой — это разные продукты.
DrunkBear Автор
02.06.2019 21:22+1Спасибо за большой ответ, здесь именно те пункты, которых не хватало.
И да, я не писал про «просто переклеили этикетку», я честно добавил, что в релизах другие версии пакетов — а это автоматом значит совсем другой набор багов и фич.acmnu
03.06.2019 08:40в релизах другие версии пакетов
Это вообще огромная проблема дитрибутивов на базе Ambari. Что Bigtop, что Horton, что Arenadata 1.x, страдали от глубокой взаимосвязанности продуктов. Если мне память не изменяет, то в ADH 1.5 было 26 сервисов и все они как-то взаимодействовали друг с другом. Проблема была на столько сложна, что, например, Hive все поставляют в неком гибридном виде 1.x + 2.x и внутри это устроено весьма люто.
DrunkBear Автор
03.06.2019 10:52Подобрать стабильный набор пакетов, работающих и самим, и друг с другом — задача нетривиальная.
А под высокой нагрузкой становится ещё веселее: посмотрел, на стабильном кластере около 20кб правок добавлено в разные Advanced Configuration Snippet for *-site.xml
PS судя по тем же слухам, место Ambari займёт Cloudera Manageracmnu
03.06.2019 13:59Это уже не слухи, а реальность. Не очень понятно что будет с теми компонентами, для которых у Cloudera есть собственные реализации.
DrunkBear Автор
03.06.2019 15:07Какие-то будут заменять аналогами Horton'a, что-то оставят своё.
Или добавлять к существующим — Tez в качестве движка для hive запросов замечен в CDH 6.
Кстати, спор «как лучше хранить файлы — в orc или parquet» скоро тоже будет устаревшим — оставят parquet.kapustor
03.06.2019 19:19Не поделитесь инфой про ORC? Очень интересно.
DrunkBear Автор
03.06.2019 20:10Я скажу только одно слово и это слово будет — Impala.
Она изначально заточена под паркет и остаётся в будущих релизах, поэтому паркет остаётся основным форматом CDH.
Если нужно — могу поискать пруфы, суть передал своими словами.
Только учитите, что ещё 3 года с марта 2019 ( когда завершилось объединение), релизы будут выпускаться под своими брендами, поэтому вотпрямщас Ambari и ORC не выпилят.kxl
04.06.2019 00:36Hive проиграл Impala?
Orc — был разработан для ускорения работы Apache Hive и увеличения эффективности хранения в Apache Hadoop. И, в принципе Hive с ним неплохо работает… Spark вот тоже в последних версиях использует vectorized-engine для работы с орками… странно, что всё под хвост…acmnu
04.06.2019 10:38Так это все ожидаемо. Заопарк надо уменьшать. После выхода в GPDB в opensource все sql движки сильно просели в популярности и искуственно держать два продукта Хортондере невыгодно. А если Hive исчезнет из портфеля ведущего производеля, то судьба его очевидна.
DrunkBear Автор
04.06.2019 11:25Не знаю, кто кому проиграл, но захватывающие тесты, где сначала Impala в разы быстрее Hive с тюнингом Horton, потом Hive + LLAP в те же разы быстрее Impala, все машут флажками и скандируют что-то про subsecond queries, смотрел с большим интересом.
Возможно, будут менять parquet и внедрят в него фичи ORC — тогда и маркетинг будет цел, и пользователи довольны.
IMHO, основная проблема в том, что Impala не полностью поддерживает orc.
Hive остаётся, в том числе с движками Tez и Hive-on-spark2 ( уже выкатили в Cloudera CDH 6.x.x)
Векторизация parquet тоже

mickvav
Хабр вроде не жалобная книга…