
Знаковая научная работа от 2012 года преобразовала область программного распознавания изображений

Сегодня я могу, допустим, открыть Google Photos, написать «пляж», и увидеть кучу своих фотографий с различных пляжей, которые я посетил за последнее десятилетие. И я никогда не подписывал свои фотографии – Google распознаёт на них пляжи на основе их содержания. Эта, казалось бы, скучная особенность основывается на технологии под названием «глубокая свёрточная нейросеть», позволяющая программам понимать изображения при помощи сложного способа, недоступного технологиям предыдущих поколений.
В последние годы исследователи обнаружили, что точность ПО становится лучше по мере того, как они создают всё более глубокие нейросети (НС) и обучают их на всё более крупных наборах данных. Это создало ненасытную потребность в вычислительных мощностях, и обогатило производителей GPU, таких, как Nvidia и AMD. В Google несколько лет назад разработали собственные специальные чипы для НС, а другие компании пытаются угнаться за ней.
В Tesla, к примеру, Андрея Карпати, эксперта по глубокому обучению, назначили главой проекта Autopilot. Теперь автопроизводитель разрабатывает собственный чип для ускорения работы НС в будущих версиях автопилота. Или взять Apple: в чипах A11 и A12, центральных для последних iPhone, есть "нейронный процессор" Neural Engine, ускоряющий работу НС и позволяющий приложениям для распознавания изображений и голоса работать лучше.
Эксперты, опрошенные мною для этой статьи, отслеживают начало бума глубинного обучения до определённой работы: AlexNet, названной так в честь главного автора, Алекса Крижевского. «Я считаю, что 2012-й стал знаковым годом, когда вышла работа AlexNet», — сказал Шон Герриш, эксперт по МО и автор книги "Как умные машины думают".
До 2012 года глубокие нейросети (ГНС) были чем-то вроде захолустья в мире МО. Но потом Крижевский и его коллеги из университета Торонто подали заявку на престижное соревнование по распознаванию изображений, и она кардинально превосходило по точности всё, что было разработано до неё. Почти мгновенно ГНС стали лидирующей технологией в распознавании изображений. Другие исследователи, использовавшие эту технологию, вскоре продемонстрировали дальнейшие улучшения точности распознавания.
В данной статье мы углубимся в глубокое обучение. Я объясню, что такое НС, как их обучают, и почему они требуют таких вычислительных ресурсов. А потом я объясню, почему определённый вид НС – глубокие свёрточные сети – так хорошо понимают изображения. Не беспокойтесь, картинок будет много.
Простой пример с одним нейроном
Понятие «нейросеть» может казаться вам туманным, поэтому начнём с простого примера. Допустим, вы хотите, чтобы НС решила, надо ли машине ехать, на основе зелёного, жёлтого и красного сигналов светофора. НС может решить эту задачу при помощи одного нейрона.

Нейрон получает входные данные (1 – горит, 0 – не горит), умножает на соответствующий вес, и складывает все значения весов. Потом нейрон добавляет смещение, определяющее пороговое значение для «активации» нейрона. В данном случае, если выход положителен, мы считаем, что нейрон активировался – и наоборот. Нейрон эквивалентен неравенству «зелёный – красный – 0,5 > 0». Если оно оказывается истинным – то есть, зелёный горит, а красный не горит – тогда машина должна ехать.
В реальных НС искусственные нейроны делают ещё один шаг. Просуммировав взвешенный ввод и добавив смещение, нейрон применяет нелинейную функцию активации. Часто используется сигмоида, S-образная функция, всегда выдающая значение от 0 до 1.
Использование функции активации не изменит результат нашей простой модели светофора (просто нам нужно будет использовать пороговое значение 0,5, а не 0). Но нелинейность функций активации необходима для того, чтобы НС могли моделировать более сложные функции. Без функции активации каждая сколь угодно сложная НС сводится к линейной комбинации входных данных. А линейная функция не может моделировать сложные явления реального мира. Нелинейная функция активации позволяет НС аппроксимировать любую математическую функцию.
Пример сети
Конечно, существует множество способов аппроксимации функции. НС выделяются тем, что мы знаем, как «обучать» их, используя немного алгебры, кучу данных и море вычислительных мощностей. Вместо того, чтобы программисту напрямую разрабатывать НС для определённой задачи, мы можем создать ПО, начинающее с достаточно общей НС, изучающее кучу размеченных примеров, а потом изменяющее НС так, что она выдаст правильную метку для как можно большего количества примеров. Расчёт на то, что итоговая НС обобщит данные и будет выдавать правильные метки для примеров, которых раньше не было в базе.
Процесс, ведущий к этой цели, начался задолго до AlexNet. В 1986 году трио исследователей опубликовало знаковую работу по обратному распространению – технологии, помогшей сделать реальностью математическое обучение сложных НС.
Чтобы представить, как работает обратное распространение, посмотрим на простую НС, описанную Майклом Нильсеном в его прекрасном онлайн-учебнике по ГО. Цель сети – обработать изображение написанной от руки цифры в разрешении 28х28 пикселей и правильно определить, написана ли цифра 0, 1, 2, и т.д.
Каждое изображение – это 28 * 28 = 784 входных величины, каждая из которых представляет собой вещественное число от 0 до 1, обозначающее, насколько пиксель светлый или тёмный. Нильсен создал НС такого вида:
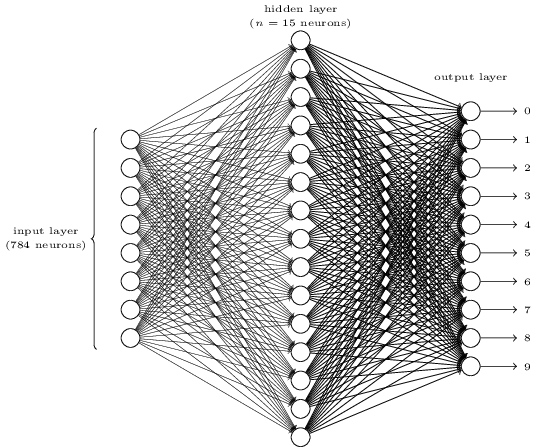
Каждый кружок в центре и в правой колонке – это нейрон, похожий на тот, что мы рассматривали в предыдущем разделе. Каждый нейрон принимает взвешенное среднее из входных данных, добавляет смещение и применяет функцию активации. Кружочки слева – это не нейроны, они обозначают входные данные сети. И хотя на картинке показано только 8 входных кружков, на самом деле их 784 – по одному на каждый пиксель.
Каждый из 10 нейронов справа должен «срабатывать» на свою цифру: верхний должен включаться, когда на вход подаётся рукописный 0 (и только в этом случае), второй – когда сеть видит рукописную 1 (и только её), и так далее.
Каждый нейрон воспринимает входные данные от каждого нейрона предыдущего слоя. Так что каждому из 15 нейронов в середине поступает 784 входных значения. У каждого из этих 15 нейронов есть параметр веса для каждого из 784 входных значений. Это значит, что только у этого слоя есть 15*784=11 760 весовых параметров. Сходным образом выходной слой содержит 10 нейронов, каждый из которых принимает входные данные от всех 15 нейронов среднего слоя, что добавляет ещё 15*10=150 весовых параметров. Кроме этого, у сети есть 25 переменных смещения – по одной у каждого из 25 нейронов.
Обучение нейросети
Цель тренировки – подстроить эти 11 935 параметров для максимизации вероятности того, что нужный выходной нейрон – и только он – активируется, когда сети дадут изображение рукописной цифры. Мы можем сделать это при помощи известного набора изображений MNIST, где есть 60 000 размеченных изображений разрешения 28х28 пикселей.

160 из 60 000 изображений из набора MNIST
Нильсен демонстрирует, как обучить сеть, используя 74 строчки обычного кода на python – без всяких библиотек для МО. Обучение начинается с выбора случайных значений для каждого из этих 11 935 параметров, весов и смещений. Затем программа перебирает примеры изображений, проходя два этапа с каждым из них:
- Шаг прямого распространения вычисляет выходные данные сети на основе входного изображения и текущих параметров.
- Шаг обратного распространения вычисляет отклонение результата от правильных выходных данных и изменяет параметры сети так, чтобы немного улучшить её эффективность на данном изображении.
Пример. Допустим, сеть получила следующую картинку:
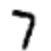
Если она хорошо откалибрована, тогда вывод «7» должен стремиться к 1, а другие девять выводов должны стремиться к 0. Но, допустим, что вместо этого сеть на выходе «0» даёт величину 0,8. Это слишком много! Обучающий алгоритм изменяет входные веса нейрона, отвечающего за «0», чтобы он стал ближе к 0 в следующий раз при обработке этого изображения.
Для этого алгоритм обратного распространения вычисляет градиент ошибки для каждого входного веса. Это мера того, как изменится выходная ошибка для заданного изменения входного веса. Потом алгоритм использует градиент, чтобы решить, насколько менять каждый входной вес – чем больше градиент, тем сильнее изменение.
Иначе говоря, обучающий процесс «обучает» нейроны выходного слоя обращать меньше внимания на те входы (нейроны в среднем слое), которые подталкивают их к неправильному ответу, и больше – на те входы, которые подталкивают в нужном направлении.
Алгоритм повторяет этот шаг для всех остальных выходных нейронов. Он уменьшает веса входных данных для нейронов «1», «2», «3», «4», «5», «6», «8» и «9» (но не «7»), чтобы понизить значение этих выходных нейронов. Чем выше выходное значение, тем больше градиент выходной ошибки по отношению к входному весу – и тем сильнее уменьшится его вес.
И наоборот, алгоритм увеличивает веса входных данных для выхода «7», что заставить нейрон выдавать более высокое значение в следующий раз, когда ему дадут это изображение. Опять-таки, входы с более крупными значениями сильнее увеличат веса, что заставит выходной нейрон «7» уделять больше внимания этим входам в следующие разы.
Затем алгоритм должен выполнить те же расчёты для среднего слоя: изменить каждый входной вес в том направлении, которое уменьшит ошибки сети – опять-таки, приближая выход «7» ближе к 1, а остальные – к 0. Но У каждого среднего нейрона есть связь со всеми 10 выходными, что осложняет дело в двух аспектах.
Во-первых, градиент ошибки для каждого среднего нейрона зависит не только от входного значения, но и от градиентов ошибки в следующем слое. Алгоритм называется обратным распространением потому, что градиенты ошибок более поздних слоёв сети распространяются в обратном направлении и используются для расчёта градиентов в более ранних слоях.
Также каждый средний нейрон является входом для всех десяти выходных. Поэтому обучающему алгоритму приходится подсчитывать градиент ошибки, отражающий то, как изменение определённого входного веса влияет на среднюю ошибку по всем выходам.
Обратное распространение – это алгоритм карабканья на холм: каждый его проход приближает выходные значения к правильным для заданного изображения, но лишь на немного. Чем больше примеров просматривает алгоритм, тем выше на холм взбирается он, по направлению к оптимальному набору параметров, правильно классифицирующих максимальное количество тренировочных примеров. Для достижения высокой точности требуются тысячи примеров, и алгоритму может понадобиться пройти циклом по каждому изображению в этом наборе десятки раз до того, как его эффективность перестанет расти.
Нильсен показывает, как реализовать эти 74 строчки на python. Удивительно, что натренированная при помощи такой простой программы сеть способна распознать более 95% рукописных чисел из базы MNIST. С дополнительными улучшениями простая двухслойная сеть способна распознать более 98% цифр.
Прорыв AlexNet
Вы могли подумать, что развитие темы обратного распространения должно было пройти в 1980-х, и породить быстрый прогресс в МО на основе НС – но этого не произошло. В 1990-х и начале 2000-х кое-кто работал над этой технологией, но интерес к НС не набирал оборотов до начала 2010-х.
Это можно отследить по результатам соревнования ImageNet – ежегодному конкурсу по МО, организованному специалистом по информатике из Стэнфорда Фей-Фей Ли. Каждый год соперникам выдают одинаковый набор из более миллиона изображений для обучения, каждое из которых вручную размечено по категориям числом более 1000 – от «пожарная машна» и «гриб» до «гепард». ПО участников судят по возможности классификации других изображений, отсутствовавших в наборе. Программа может выдавать несколько догадок, и её работа считается успешной, если хотя бы одна из пяти первых догадок совпадает с меткой, проставленной человеком.
Соревнование началось в 2010-м, и глубокие НС не играли в нём большой роли в первые два года. Лучшие команды использовали иные различные техники МО, и достигали довольно средних результатов. В 2010-м году победила команда с процентом ошибок, равным 28. В 2011 – с ошибкой в 25%.
А потом наступил 2012-й. Команда из университета Торонто сделала заявку – которую позже окрестили AlexNet в честь ведущего автора работы, Алекса Крижевского – и оставила соперников далеко позади. Используя глубокую НС, команда достигла 16% показателя ошибок. У ближайшего конкурента этот показатель равнялся 26.
У описанной в статье НС для распознавания почерка есть два слоя, 25 нейронов и почти 12 000 параметров. AlexNet была гораздо крупнее и сложнее: восемь обучаемых слоёв, 650 000 нейронов и 60 млн параметров.
Для обучения НС такого размера требуются огромные вычислительные мощности, и AlexNet была спроектирована так, чтобы использовать преимущества массивной параллелизации, доступной современным GPU. Исследователи додумались, как можно разделить работу по обучению сети на два GPU, что в два раза увеличило мощность. И всё равно, несмотря на жёсткую оптимизацию, тренировка сети занимала 5-6 дней на том железе, которое было доступно в 2012-м (на паре Nvidia GTX 580 с 3 Gb памяти).
Полезно изучить примеры результатов работы AlexNet, чтобы понять, насколько серьёзным был этот прорыв. Вот картинка из научной работы, где показаны примеры изображений и пять первых догадок сети по их классификации:

AlexNet смогла распознать на первой картинке клеща, хотя от него там есть лишь небольшая форма в самом углу. ПО не только правильно определило леопарда, но и дало другие близкие варианты – ягуар, гепард, снежный барс, египетский мау. AlexNet пометила фото грабов как «пластинчатый гриб». Просто «гриб» был вторым вариантом сети.
«Ошибки» AlexNet тоже впечатляют. Она отметила фото с далматинцем, стоящим за кучкой вишен, как «далматинец», хотя официальной меткой была «вишня». AlexNet распознала, что на фото есть какая-то ягода – среди первых пяти вариантов были «виноград» и «бузина» – просто не распознала именно вишню. К фото мадагаскарского лемура, сидящего на дереве, AlexNet привела список небольших млекопитающих, живущих на деревьях. Думаю, что многие люди (включая и меня) поставили бы тут неправильную подпись.
Качество работы было впечатляющим, и демонстрировало, что ПО способно распознавать обычные объекты в широком спектре их ориентаций и окружения. ГНС быстро стали самой популярной техникой для распознавания изображений, и с тех пор мир МО не отказывался от неё.
«На волне успеха в 2012 году метода, основанного на ГО, большая часть участников соревнования 2013 года перешла на глубокие свёрточные нейросети», — писали спонсоры ImageNet. В следующие годы эта тенденция сохранялась, и впоследствии победители работали на основе базовых технологий, впервые применённых командой AlexNet. К 2017 году соперники, используя более глубокие НС, серьёзно снизили процент ошибок до показателя менее трёх. Учитывая сложность задачи, компьютеры в какой-то мере научились решать её лучше многих людей.
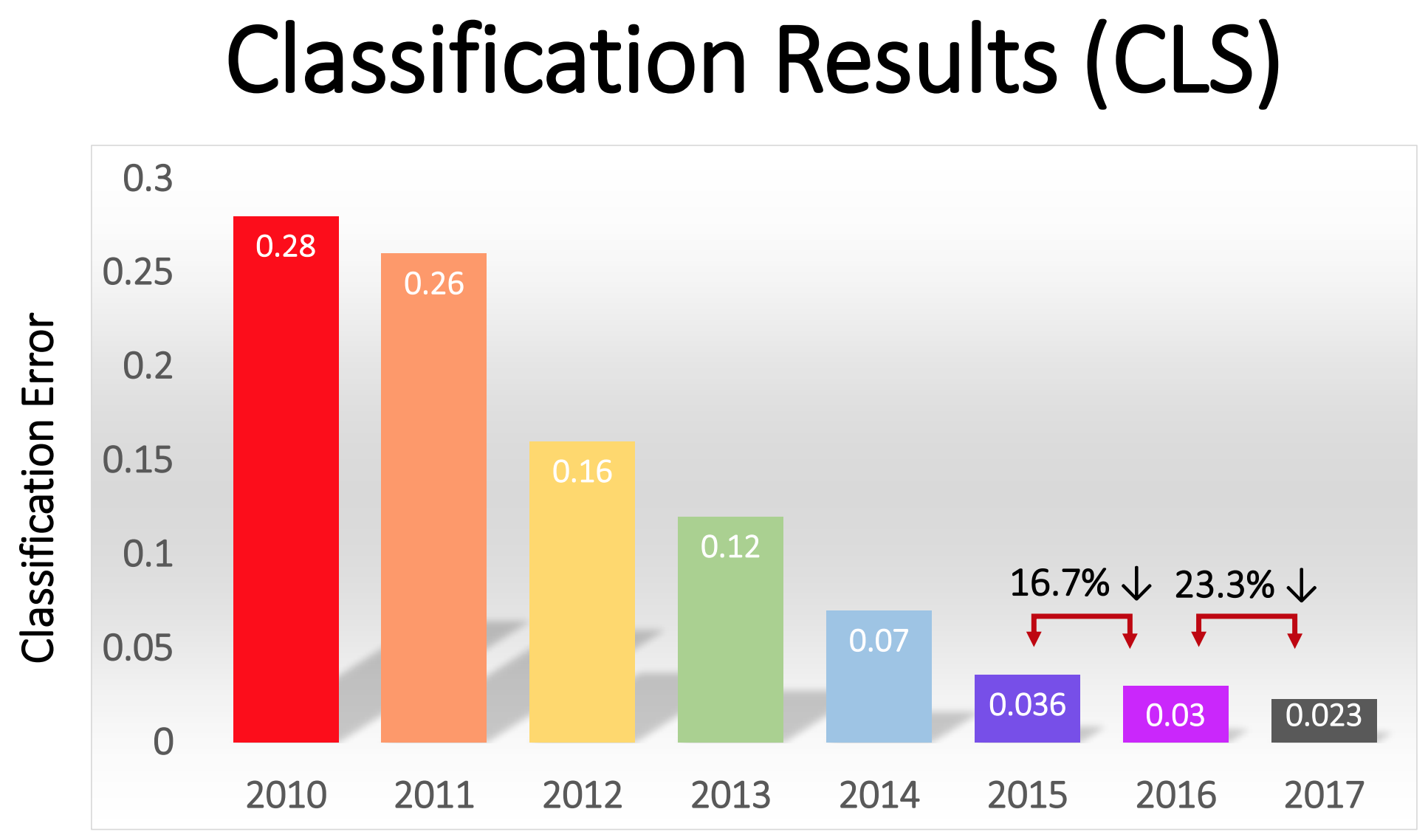
Процент ошибок в классификации изображений в разные годы
Свёрточные сети: концепция
Технически, AlexNet была свёрточной НС. В данном разделе я объясню, что делает свёрточная нейросеть (СНС), и почему эта технология стала критически важной для современных алгоритмов распознавания образов.
Рассмотренная ранее простая сеть для распознавания рукописного ввода была полностью связанной: каждый нейрон первого слоя был входным для каждого нейрона второго слоя. Такая структура достаточно хорошо работает на простых задачах с распознаванием цифр на изображениях 28х28 пикселей. Но плохо масштабируется.
В базе данных рукописных цифр MNIST все символы отцентрированы. Это серьёзно упрощает обучение, поскольку, допустим, у семёрки всегда будут несколько тёмных пикселей вверху и справа, а левый нижний угол всегда белый. У нуля почти всегда будет белое пятно в середине и тёмные пиксели по краям. Простая и полностью связная сеть может распознавать подобные закономерности достаточно легко.
Но, допустим, вам захотелось создать НС, способную распознавать числа, которые могут располагаться где угодно на более крупном изображении. Полностью связная сеть не будет так же хорошо работать с такой задачей, поскольку у неё нет эффективного способа распознавать сходные черты у форм, расположенных в различных частях изображения. Если в вашем тренировочном наборе данных большинство семёрок расположено в левом верхнем углу, тогда ваша сеть будет лучше распознавать семёрки в левом верхнем углу, чем в любой другой части изображения.
Теоретически, эту проблему можно решить, гарантировав, что в вашем наборе есть много примеров каждой цифры в каждой из возможных позиций. Но на практике это будет огромной тратой ресурсов. С увеличением размера изображений и глубины сети количество связей – и количество весовых параметров – будет расти взрывообразно. Вам понадобится гораздо больше тренировочных изображений (и вычислительных мощностей) для достижения адекватной точности.
Когда нейросеть учится распознавать форму, расположенную на одном месте изображения, она должна уметь применить это знание для распознавания той же формы в других частях изображения. СНС дают элегантное решение этой задачи.
«Это похоже на то, как если бы вы взяли трафарет и приложили его ко всем местам изображения, — сказал исследователь ИИ Джай Тэн. – У вас есть трафарет с изображением собаки, и вы сначала прикладываете его к верхнему правому углу изображения, чтобы посмотреть – есть ли там собака? Если нет, вы немного сдвигаете трафарет. И так для всего изображения. Неважно, где там будет картинка собаки. Трафарет совпадёт с ней. Вам не нужно, чтобы каждая часть сети обучалась своей собственной классификации собак».
Представьте, что мы взяли большое изображение, и разбили на квадраты 28х28 пикселей. Тогда мы сможем скормить каждый квадратик полностью связанной сети, распознающей рукописный ввод, которую мы изучили до этого. Если хотя бы в одном из квадратов сработает выход «7», это будет признаком того, что в целом на изображении есть семёрка. Примерно это и делают свёрточные сети.
Как свёрточные сети работали в AlexNet
В свёрточных сетях такие «трафареты» известны, как детекторы признаков, а изучаемая ими область – рецептивным полем. Реальные детекторы признаков работают с гораздо меньшими полями, чем квадрат со стороной в 28 пикселей. В AlexNet детекторы признаков в первом свёрточном слое работали с рецептивным полем размером 11х11 пикселей. В последующих слоях рецептивные поля были шириной в 3-5 единиц.
В процессе обхода детектор признаков входного изображения выдаёт карту признаков: двумерную решётку, на которой отмечается, как сильно активировался детектор в различных частях изображения. У свёрточных слоёв обычно бывает больше одного детектора, и каждый из них сканирует изображение в поиске разных шаблонов. У AlexNet на первом слое было 96 детекторов признаков, выдававших 96 карт признаков.

Чтобы лучше это понять, рассмотрим визуальную репрезентацию закономерностей, изученных каждым из 96 детекторов первого слоя AlexNet после обучения сети. Там есть детекторы, ищущие горизонтальные или вертикальные линии, переходы от светлого к тёмному, шахматные узоры и многие другие формы.
Цветное изображение обычно представляется в виде пиксельной карты с тремя числами для каждого пикселя: значение красного, зелёного и синего. Первый слой AlexNet берёт это представление и превращает его в представление, использующее 96 чисел. Каждый «пиксель» в этом изображении имеет 96 значений, по одному на каждый детектор признаков.
В этом примере первое из 96 значений отмечает, совпадает ли какая-то точка изображения с таким узором:

Второе значение отмечает, совпадает ли какая-то точка изображения с таким узором:

Третье значение отмечает, совпадает ли какая-то точка изображения с таким узором:

И так далее ещё для 93 детекторов признаков в первом слое AlexNet. Первый слой выдаёт новое представление изображения, где каждый пиксель – это вектор в 96 измерениях (позже я объясню, что это представление уменьшается в 4 раза).
Таков первый слой AlexNet. Затем идут ещё четыре свёрточных слоя, каждый из которых принимает на вход выход предыдущего.
Как мы увидели, первый слой обнаруживает базовые закономерности, типа горизонтальных и вертикальных линий, переходов от светлого к тёмному и кривых. Второй уровень использует их как строительный блок распознавания чуть более сложных форм. К примеру, у второго слоя мог бы быть детектор признаков, находящий кружочки при помощи комбинации выходов детекторов признаков первого слоя, находящих кривые. Третий слой находит ещё более сложные формы, комбинируя признаки со второго слоя. Четвёртый и пятый находят ещё более сложные закономерности.
Исследователи Мэтью Зейлер и Роб Фергус опубликовали в 2014 году прекрасную работу, где приводятся весьма полезные способы визуализации закономерностей, распознаваемых пятислойной нейросетью, похожей на ImageNet.
В следующем слайдшоу, взятом из их работы, у каждой картинки, кроме первой, есть две половины. Справа вы увидите примеры миниатюр, сильно активировавших определённый детектор признаков. Они собраны по девять – и каждая группа соответствует своему детектору. Слева – карта, где показано какие именно пиксели в этой миниатюре наиболее ответственны за совпадение. Особенно хорошо это видно на пятом слое, поскольку там есть детекторы признаков, сильно реагирующие на собак, логотипы, колёса и так далее.

Первый слой – простые закономерности и формы

Второй слой – начинают проявляться мелкие структуры

Детекторы признаков на третьем слое могут распознавать более сложные фигуры, типа колёс автомобилей, сот и даже силуэты людей

Четвёртый слой способен различать сложные формы, типа морд собак или ног птиц

Пятый слой может распознавать очень сложные формы
Просматривая изображения, вы можете видеть, как каждый последующий слой способен распознавать всё более сложные закономерности. Первый слой распознаёт простые узоры, не похожие ни на что. Второй распознаёт текстуры и простые формы. К третьему слою становятся видны узнаваемые формы типа колёс и красно-оранжевых сфер (помидоры, божьи коровки, что-то ещё).
У первого слоя сторона рецептивного поля равна 11, а у более поздних – от трёх до пяти. Но помните, более поздние слои распознают карты признаков, сгенерированные более ранними слоями, поэтому каждый их «пиксель» обозначает несколько пикселей оригинальной картинки. Поэтому рецептивное поле каждого слоя включает в себя более крупную часть первого изображения, чем предыдущие слои. Это часть причин того, что миниатюры в более поздних слоях выглядят сложнее, чем в ранних.
Пятый, последний слой сети способен распознавать впечатляюще большой спектр элементов. К примеру, посмотрите на это изображение, выбранное мною из правого верхнего угла изображения, соответствующего пятому слою:

Девять картинок справа могут не быть похожими друг на друга. Но если взглянуть на девять тепловых карт слева, вы увидите, что этот детектор признаков не концентрируется на объекты на переднем плане фоток. Вместо этого он концентрируется на траве на фоне каждой из них!
Очевидно, детектор травы полезен, если одной из категорий, которую вы пытаетесь определить, будет «трава», однако это может быть полезным и для многих других категорий. После пяти свёрточных слоёв у AlexNet есть три слоя, связанных полностью, как у нашей сети для распознавания рукописного текста. Эти слои рассматривают каждую из карт признаков, выдаваемых пятью свёрточными слоями, пытаясь отнести изображение к одной из 1000 возможных категорий.
Так что если на фоне есть трава, то с большой вероятностью на изображении будет дикое животное. С другой стороны, если на фоне есть трава, это с меньшей вероятностью будет изображение мебели в доме. Эти и другие детекторы признаков пятого слоя дают кучу информации о вероятном содержании фото. Последние слои сети синтезируют эту информацию для выдачи подкреплённой фактами догадки о том, что в целом изображено на картинке.
Что отличает свёрточные слои: общие входные веса
Мы видели, что детекторы признаков у свёрточных слоёв демонстрируют впечатляющее распознавание образов, однако пока что я не объяснял, как реально работают свёрточные сети.
Свёрточный слой (СС) состоит из нейронов. Они, как и любые нейроны, принимают взвешенное среднее на вход и применяют функцию активации. Параметры обучаются с использованием техник обратного распространения.
Но, в отличие от предыдущих НС, СС связан не полностью. Каждый нейрон принимает входные данные у небольшой доли нейронов из предыдущего слоя. И, что важно, у нейронов свёрточных сетей общие входные веса.
Давайте рассмотрим первый нейрон первого СС AlexNet подробнее. Рецептивное поле этого слоя имеет размер 11х11 пикселей, поэтому первый нейрон изучает квадрат 11х11 пикселей в одном углу изображения. Этот нейрон получает входные данные из этого 121 пикселя, а у каждого пикселя есть три значения – красное, зелёное и синее. Поэтому в целом у нейрона 363 входных параметра. Как любой нейрон, этот берёт взвешенное среднее 363 параметров, и применяет к ним функцию активации. И, поскольку входных параметров 363, весовых параметров тоже нужно 363.
Второй нейрон первого слоя похож на первый. Он тоже изучает квадраты 11х11 пикселей, однако его рецептивное поле сдвинуто на четыре пикселя относительно первого. У двух полей возникает нахлёст в 7 пикселей, благодаря чему сеть не упускает из виду интересные закономерности, попавшие на стык двух квадратов. Второй нейрон тоже принимает 363 параметра, описывающие квадрат 11х11, умножает каждое из них на вес, складывает и применяет функцию активации.
Но вместо того, чтобы пользоваться отдельным набором из 363 весов, второй нейрон используют те же самые веса, что и первый. Верхний левый пиксель первого нейрона использует те же веса, что верхний левый пиксель второго. Поэтому оба нейрона ищут одну и ту же закономерность; просто их рецептивные поля сдвинуты на 4 пикселя относительно друг друга.
Естественно, нейронов там больше двух: в решётке 55х55 находится 3025 нейронов. Каждый из них использует один и тот же набор из 363 весов, что и первые два. Совместно все нейроны формируют детектор признаков, «сканирующий» картинку на предмет нужной закономерности, которая может располагаться в любом месте.
Помните, что у первого слоя AlexNet есть 96 детекторов признаков. Только что упомянутые мною 3025 нейронов составляют один из этих 96 детекторов. Каждый из остальных 95-и – это отдельная группа из 3025 нейронов. Каждая группа из 3025 нейронов использует общий набор из 363 весов – однако, для каждой из 95 групп он свой.
СН обучаются при помощи того же обратного распространения, что используется для полностью связанных сетей, однако свёрточная структура делает процесс обучения более эффективным и результативным.
«Использование свёрток реально помогает – параметры можно использовать повторно», — сказал нам эксперт по МО и автор Шон Герриш. Это радикально уменьшает количество входных весов, которые приходится учить сети, что позволяет ей выдавать лучшие результаты на меньшем количестве обучающих примеров.
Обучение на одной части изображения выливается в улучшение распознавания той же закономерности в других частях изображения. Это позволяет сети достигать высокой эффективности на гораздо меньшем количестве обучающих примеров.
Люди быстро поняли всю мощь глубоких свёрточных сетей
Работа AlexNet стала сенсацией в академическом сообществе МО, однако её важность быстро поняли и в IT-индустрии. Особенно сильно ею заинтересовалась Google.
В 2013 Google приобрела стартап, основанный авторами AlexNet. Компания использовала эту технологию, чтобы добавить новую возможность поиска по фотографиям в Google Photos. «Мы взяли передовое исследование и запустили его в работу чуть больше, чем через шесть месяцев», — писал Чак Розенберг из Google.
Тем временем, в работе 2013 года было описано, как Google использует ГСС для распознавания адресов с фотографий сервиса Google Street View. «Наша система помогла нам извлечь почти 100 млн физических адресов с этих изображений», — писали авторы.
Исследователи обнаружили, что эффективность НС растёт с увеличением глубины. «Мы обнаружили, что эффективность этого подхода растёт с увеличением глубины СНС, и наилучшие результаты показывают самые глубокие из обученных нами архитектур, — писала команда Google Street View. – Наши эксперименты говорят о том, что более глубокие архитектуры могут выдавать большую точность, но с замедлением роста эффективности».
Так что после AlexNet сети начали становиться всё глубже. Команда Google выступила с выигрывшей на конкурсе заявкой в 2014 году – всего через два года после того, как AlexNet выиграла в 2012. Она тоже была основана на глубокой СНС, однако в Goolge использовали гораздо более глубокую сеть из 22 слоёв, чтобы достичь показателя ошибки в 6,7% — это было серьёзное улучшение по сравнению с 16% у AlexNet.
Но при этом более глубокие сети работали лучше только с более крупными наборами обучающих данных. Поэтому Герриш говорит, что набор данных ImageNet и соревнования сыграли основную роль в успехе СНС. Вспомните, что на соревновании ImageNet участникам дают по миллиону изображений и просят рассортировать их по 1000 категорий.
«Если у вас есть миллион изображений для обучения, значит, в каждый класс входит по 1000 изображений», — сказал Герриш. Без такого крупного набора данных, по его словам, «у вас было бы слишком много параметров для обучения сети».
В последние годы специалисты всё больше концентрируются на сборе огромного объёма данных для обучения более глубоких и точных сетей. Именно поэтому компании, разрабатывающие робомобили, концентрируются на пробеге по общественным дорогам – изображения и видео этих поездок отправляются в штаб-квартиру и используются для обучения корпоративных НС.
Вычислительный бум глубокого обучения
Открытие того факта, что более глубокие сети и более объёмные наборы данных могут улучшать производительность НС создало ненасытную жажду всё больших вычислительных мощностей. Одной из основных составляющих успеха AlexNet была идея о том, что в обучении НС используются матричные операции, которые можно эффективно выполнять на хорошо параллелизуемых графических процессорах.
«НС хорошо параллелизуются», — сказал исследователь в области МО Джай Тен. Графические карты – обеспечивающие огромную параллельную вычислительную мощность для видеоигр – оказались полезными и для НС.
«Центральная часть работы GPU, очень быстрое матричное умножение, оказалось центральной частью для работы НС», — сказал Тен.
Всё это стало удачным для лидирующих производителей GPU, Nvidia и AMD. Обе компании разработали новые чипы, специально подогнанные под нужды МО-применения, и теперь приложения ИИ отвечают за значительную часть продаж GPU этих компаний.
В 2016 году Google объявила о создании специального чипа, Tensor Processing Unit (TPU), предназначенного для работы НС. «Хотя Google рассматривала возможность создания интегральных схем специального назначения (ASIC) ещё в 2006 году, срочной эта ситуация стала в 2013-м, — писал в прошлом году представитель компании. – Именно тогда мы поняли, что быстро растущие требования НС к вычислительным мощностям могут потребовать от нас удвоения количества имеющихся у нас дата-центров».
Сначала к TPU имели доступ только собственные сервисы Google, но позже компания разрешила пользоваться этой технологией всем, посредством облачной вычислительной платформы.
Конечно, Google – не единственная компания, работающая над ИИ-чипами. Лишь несколько примеров: в последних версиях чипов для iPhone имеется «нейронное ядро», оптимизированное для операций с НС. Intel разрабатывает собственную линейку чипов, оптимизированных для ГО. Tesla недавно объявила об отказе чипов от Nvidia в пользу собственных НС-чипов. Amazon, по слухам, также работает над своими ИИ-чипами.
Почему глубокие нейросети сложно понять
Я объяснил, как работают нейросети, но не объяснил, почему они работают так хорошо. Довольно непонятно, как именно необъятное количество матричных вычислений позволяет компьютерной системе отличать ягуара от гепарда, а бузину от смородины.
Возможно, наиболее примечательным качеством НС служит то, что они не делают. Свёртки позволяют НС понимать переносы – они могут сказать, похожа ли картинка из правого верхнего угла изображения на картинку в левом верхнем углу другого изображения.
Но при этом у СНС нет никакого представления о геометрии. Они не могут распознать похожесть двух картинок, если они будут повёрнуты на 45 градусов или увеличены в два раза. СНС не пытаются понять трёхмерные структуры объектов, и не могут учитывать разные условия освещения.
Но при этом НС могут распознавать фото собак, сделанные как спереди, так и сбоку, и неважно, занимает ли собака небольшую часть изображения, или большую. Как они это делают? Оказывается, что при наличии достаточного количества данных, статистический подход с прямым перебором может справляться с задачей. СНС не разработана так, чтобы она могла «представить», как определённое изображение смотрелось бы с другого угла или в других условиях, но с достаточным количеством размеченных примеров она может выучить все возможные варианты изображения простым повторением.
Есть свидетельства того, что зрительная система людей работает схожим образом. Посмотрите на пару фоток – сначала внимательно изучите первую, а потом откройте вторую.

Первое фото
Второе фото
Создатель изображения взял чью-то фотографию и перевернул глаза и рот вверх ногами. Картинка кажется относительно нормальной, когда вы смотрите на неё в перевёрнутом виде, поскольку человеческая зрительная система привыкла видеть глаза и рты в таком положении. Но если посмотреть на картинку в правильной ориентации, сразу видно, что лицо странно искажено.
Это говорит о том, что человеческая зрительная система основывается на таких же грубых техниках распознавания закономерностей, что и НС. Если мы смотрим на что-то, что почти всегда видно в одной ориентации – глаза человека – мы гораздо лучше можем распознавать это в его нормальной ориентации.
НС хорошо распознают изображения, используя весь имеющийся на них контекст. К примеру, машины обычно ездят по дорогам. Платья обычно надеты на тело женщины или висят в шкафу. Самолёты обычно сняты на фоне неба или рулят по взлётной полосе. Никто специально не обучает НС этим корреляциям, но при достаточном количестве размеченных примеров сеть может сама их выучивать.
В 2015 году исследователи из Google попытались лучше понять НС, «запуская их задом наперёд». Вместо того, чтобы использовать картинки для обучения НС, они использовали обученные НС для изменения картинок. К примеру, они начинали с изображения, содержащего случайный шум, а потом постепенно изменяли его, чтобы оно сильно активировало один из выходных нейронов НС – по сути, просили НС «нарисовать» одну из категорий, которую её учили распознавать. В одном интересном случае они заставили НС сгенерировать картинки, активирующие НС, обученную распознавать гантели.

«Тут, конечно, присутствуют гантели, но ни одно изображение гантелей не кажется полной без наличия на ней мускулистого качка, поднимающего их», — писали исследователи из Google.
На первый взгляд это выглядит странно, но на деле не так уж сильно отличается от того, что делают люди. Если мы видим на картинке небольшой или размытый объект, мы ищем подсказку в его окружении, чтобы понять, что там может происходить. Люди, очевидно, рассуждают о картинках по-другому, пользуясь сложным концептуальным пониманием окружающего мира. Но в итоге ГНС хорошо распознают картинки, потому что пользуются всеми преимуществами всего изображённого на них контекста, и это не сильно отличается от того, как это делают люди.
Комментарии (3)

MooNDeaR
11.06.2019 13:16Картинка кажется относительно нормальной, когда вы смотрите на неё в перевёрнутом виде, поскольку человеческая зрительная система привыкла видеть глаза и рты в таком положении
Признаться жутко мне стало от этого фото в первую долю секунды в любом виде)
kuzevan
Я не понял, откуда берутся детекторы признаков.
Первый слой еще понятен, это простые геометрические примитивы, их ограниченное число (96?) и их можно создать искусственно.
Второй слой — комбинации всех 96 первичных признаков в матрице 11х11=121. Итого 96 в 121 степени уникальных возможных сочетаний?
Видимо, все таки, эти детекторы должны как-то генерироваться в процессе обучения?
И еще. Похоже, такая сеть учится распознавать изображения определенного размера, не вижу механизма масштабирования. Собачка в углу кадра и собака крупно?
Akon32
Так и есть. Никто не прописывает веса вручную, все веса вычисляются на основе примеров алгоритмами, подобными градиентному спуску.
Некоторые сети — да. Но распознавание разных масштабов можно добавить предобработкой или чем-то вроде inception-слоёв.