

Сегодня расскажу о том, как появилась и реализовалась идея создания новой внутренней сети для нашей компании. Позиция руководства — для себя нужно сделать такой же полноценный проект, как для клиента. Если сделаем хорошо для себя — сможем пригласить заказчика и показать, насколько хорошо устроено и работает то, что мы ему предлагаем. Поэтому к проработке концепта новой сети для московского офиса мы подошли весьма основательно, использовав полный производственный цикл: анализ потребностей отделов > выбор технического решения > проектирование > реализация > тестирование. Итак, начинаем.
Выбор технического решения: заповедник мутантов
Порядок работы над сложной автоматизированной системой пока лучше всего описан в ГОСТ 34.601-90 «Автоматизированные системы. Стадии создания», поэтому мы работали по нему. И уже на стадиях формирования требований и разработки концепции мы столкнулись с первыми трудностями. Организациям разного профиля — банкам, страховым компаниям, разработчикам софта и т. п. — под их задачи и стандарты нужны определённые типы сетей, специфика которых понятна и стандартизирована. Однако с нами такое не прокатит.
Почему?
«Инфосистемы Джет» — крупная многопрофильная ИТ-компания. При этом отдел внутренней поддержки у нас небольшой (но гордый), он обеспечивает работоспособность базовых сервисов и систем. Компания содержит в себе множество подразделений, выполняющих разные функции: это и несколько мощнейших аутсорс-команд, и собственные разработчики бизнес-систем, и информбезопасность, и архитекторы вычислительных комплексов, — в общем, кто только не. Соответственно, задачи, системы и политики безопасности у них тоже разные. Что ожидаемо создало сложности в процессе анализа потребностей и их стандартизации.
Вот, например, отдел разработки: его сотрудники пишут и тестируют код для большого количества заказчиков. Часто возникает необходимость оперативно организовать тестовые среды, и скажем откровенно, не всегда для каждого проекта удается сформировать требования, запросить ресурсы и построить отдельную тестовую среду в соответствии со всеми внутренними регламентами. Это порождает курьезные ситуации: однажды ваш покорный слуга заглянул в комнату разработчиков и обнаружил под столом исправно работающий Hadoop-кластер из 20 десктопов, который непонятным образом был подключен к общей сети. Думаю, не стоит уточнять, что ИТ-отдел компании не знал о его существовании. Это обстоятельсто, как и многие другие, стали виновниками того, что в ходе разработки проекта у нас родился термин «заповедник мутантов», описывающий состояние многострадальной инфраструктуры офиса.
Или вот еще пример. Периодически внутри какого-либо подразделения заводится тестовый стенд. Так было с Jira и Confluence, которые ограниченно использовались Центром программной разработки в некоторых проектах. Через некоторое время об этих полезных ресурсах узнали в других подразделениях, оценили, и в конце 2018 года Jira и Confluence перешли из статуса «локальная игрушка программистов» в статус «ресурсы компании». Теперь за этими системами должен быть закреплен владелец, должны быть определены SLA, политики доступа/ИБ, политика резервного копирования, мониторинга, правила маршрутизации заявок на устранение проблем, — в общем, должны присутствовать все атрибуты полноценной информационной системы.
Каждое наше подразделение — это еще и инкубатор, выращивающий собственные продукты. Некоторые из них погибают на стадии разработки, какие-то мы используем в период работы над проектами, другие же приживаются и становятся тиражируемыми решениями, которые мы начинаем применять сами и продавать клиентам. Для каждой подобной системы желательно иметь собственную сетевую среду, где она будет развиваться, не мешая другим системам, и в какой-то момент сможет быть интегрирована в инфраструктуру компании.
Помимо разработки, у нас есть очень большой Сервисный центр с более чем 500 сотрудниками, сформированными в команды под каждого заказчика. Они занимаются обслуживанием сетей и других систем, удаленным мониторингом, урегулированием заявок, и так далее. То есть инфраструктура СЦ — это, по сути, инфраструктура того заказчика, с которым они сейчас работают. Особенность работы с этим участком сети заключается в том, что их рабочие станции для нашей компании являются частично внешними, а частично — внутренними. Поэтому для СЦ мы реализовали следующий подход — компания предоставляет соответствующему подразделению сетевые и другие ресурсы, рассматривая рабочие станции этих подразделений как внешние подключения (по аналогии с филиалами и удаленными пользователями).
Проектирование магистрали: мы — оператор (сюрприз)
После оценки всех подводных камней мы поняли, что у нас получается сеть телекоммуникационного оператора в рамках одного офиса, и стали действовать соответствующим образом.
Создали опорную сеть, при помощи которой любому внутреннему, а в перспективе и внешнему потребителю предоставляется требуемый сервис: L2 VPN, L3 VPN или обычная маршрутизация L3. Одним подразделениям нужен безопасный доступ в интернет, другим — чистый доступ без межсетевых экранов, но при этом с защитой наших корпоративных ресурсов и опорной сети от их трафика.
С каждым подразделением мы неформально «заключили SLA». В соответствии с ним все возникающие инциденты должны устраняться за определенный, заранее согласованный промежуток времени. Требования к своей сети у компании оказались жёсткими. Максимальное время реагирования на инцидент при сбоях телефонной связи и электронной почты составило 5 минут. Время восстановления работоспособности сети при типовых отказах — не больше минуты.
Поскольку у нас сеть операторского класса, к ней можно подключаться только в строгом соответствии с правилами. Обслуживающие подразделения устанавливают политики и предоставляют сервисы. Им даже не нужна информация о подключениях конкретных серверов, виртуальных машин и рабочих станций. Но при этом нужны механизмы защиты, потому что ни одно подключение не должно выводить сеть из строя. При случайном создании петли другие пользователи не должны этого замечать, то есть необходима адекватная реакция сети. Любой оператор связи постоянно решает подобные, казалось бы, сложные, задачи внутри своей опорной сети. Он предоставляет сервис множеству клиентов с различными потребностями и трафиком. При этом разные абоненты не должны испытывать неудобства от трафика других.
У себя мы решили эту задачу следующим образом: построили опорную L3-сеть с полным резервированием, с использованием протокола IS-IS. Поверх опорной построили наложенную сеть на основе технологии EVPN/VXLAN, с использованием протокола маршрутизации MP-BGP. Для ускорения сходимости протоколов маршрутизации применили технологию BFD.
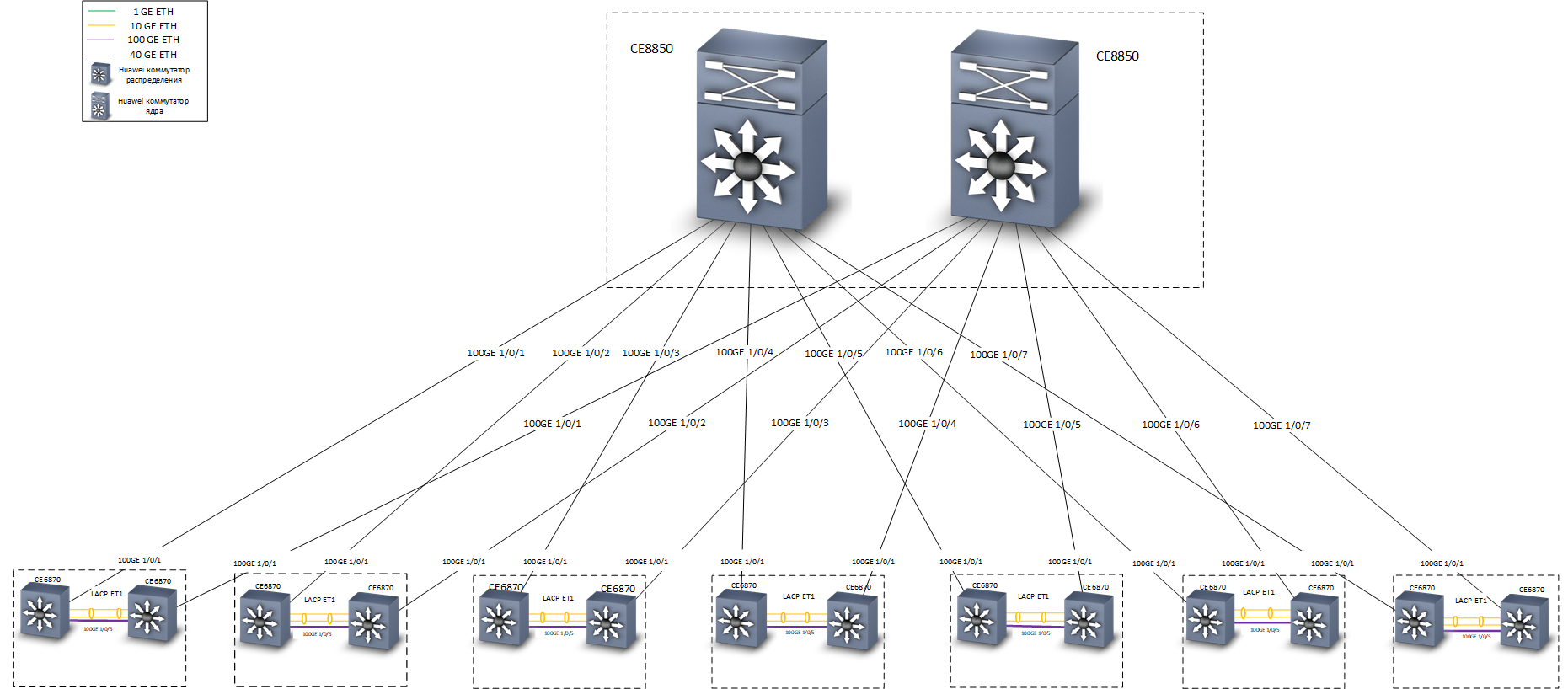
Структура сети
На испытаниях такая схема показала себя отлично — при отключении любого канала или коммутатора время сходимости не более 0.1-0.2 с, теряется минимум пакетов (часто — ни одного), TCP-сессии не рвутся, телефонные разговоры не прерываются.
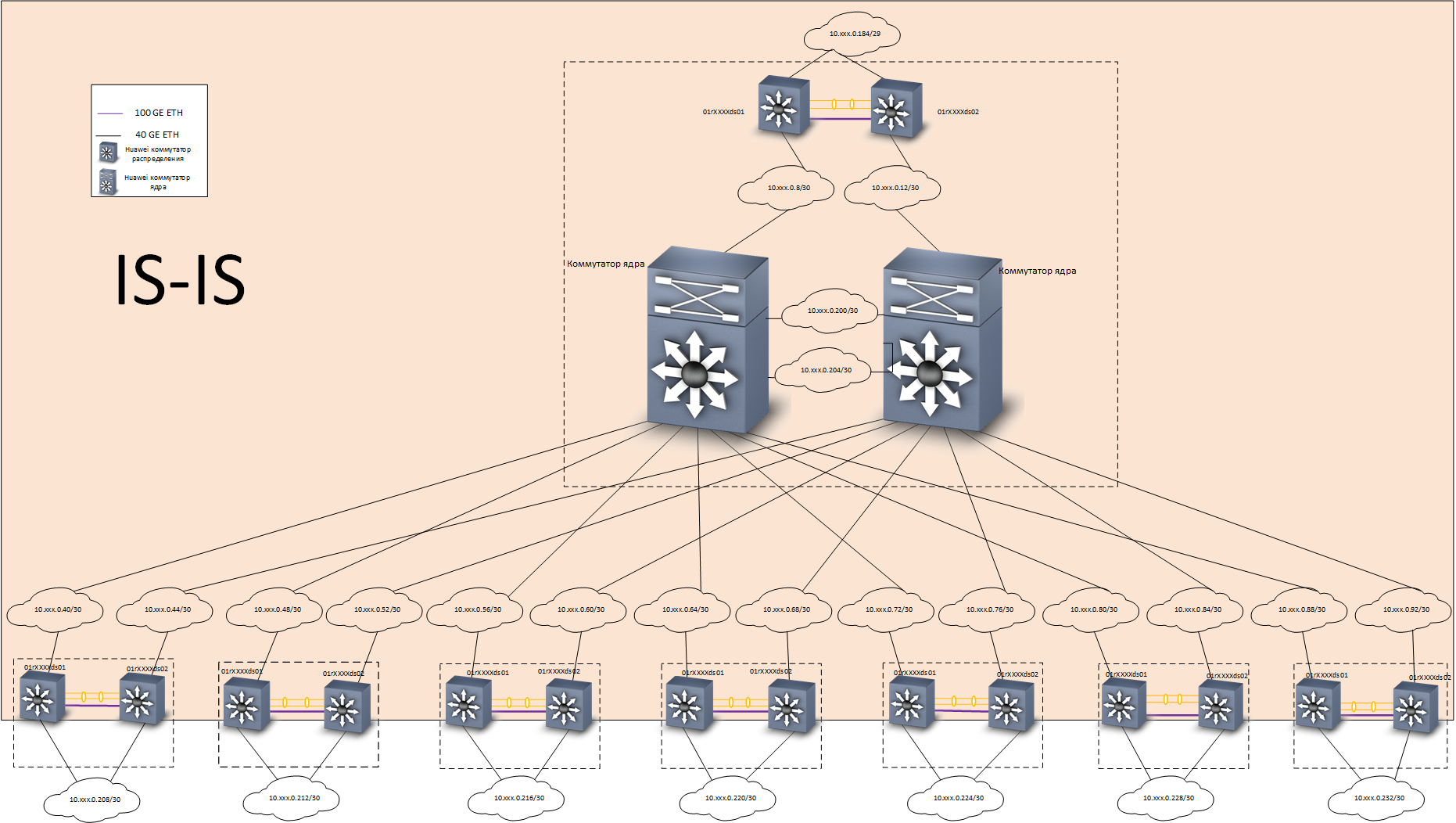
Уровень Underlay — маршрутизация
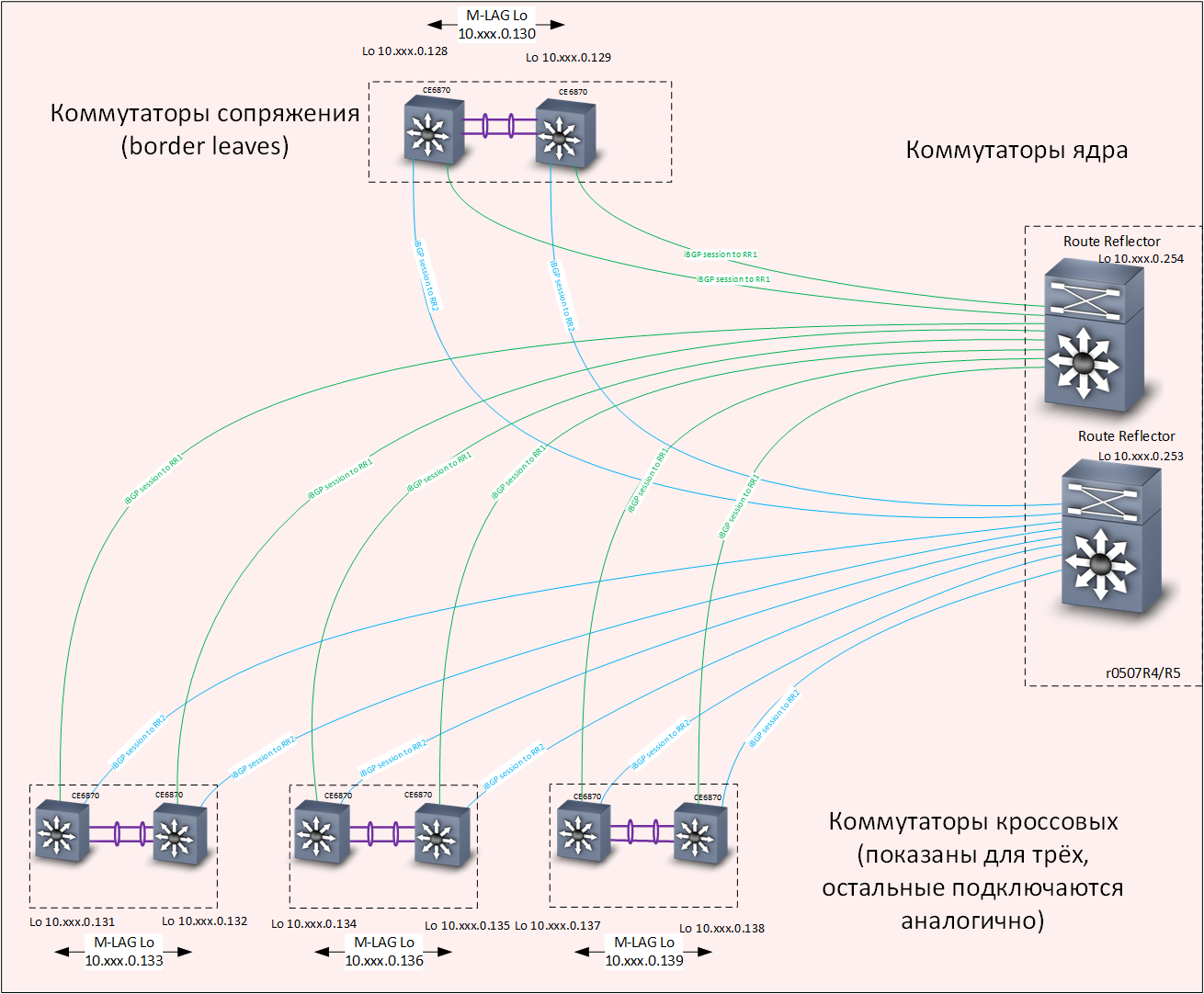
Уровень Overlay — маршрутизация
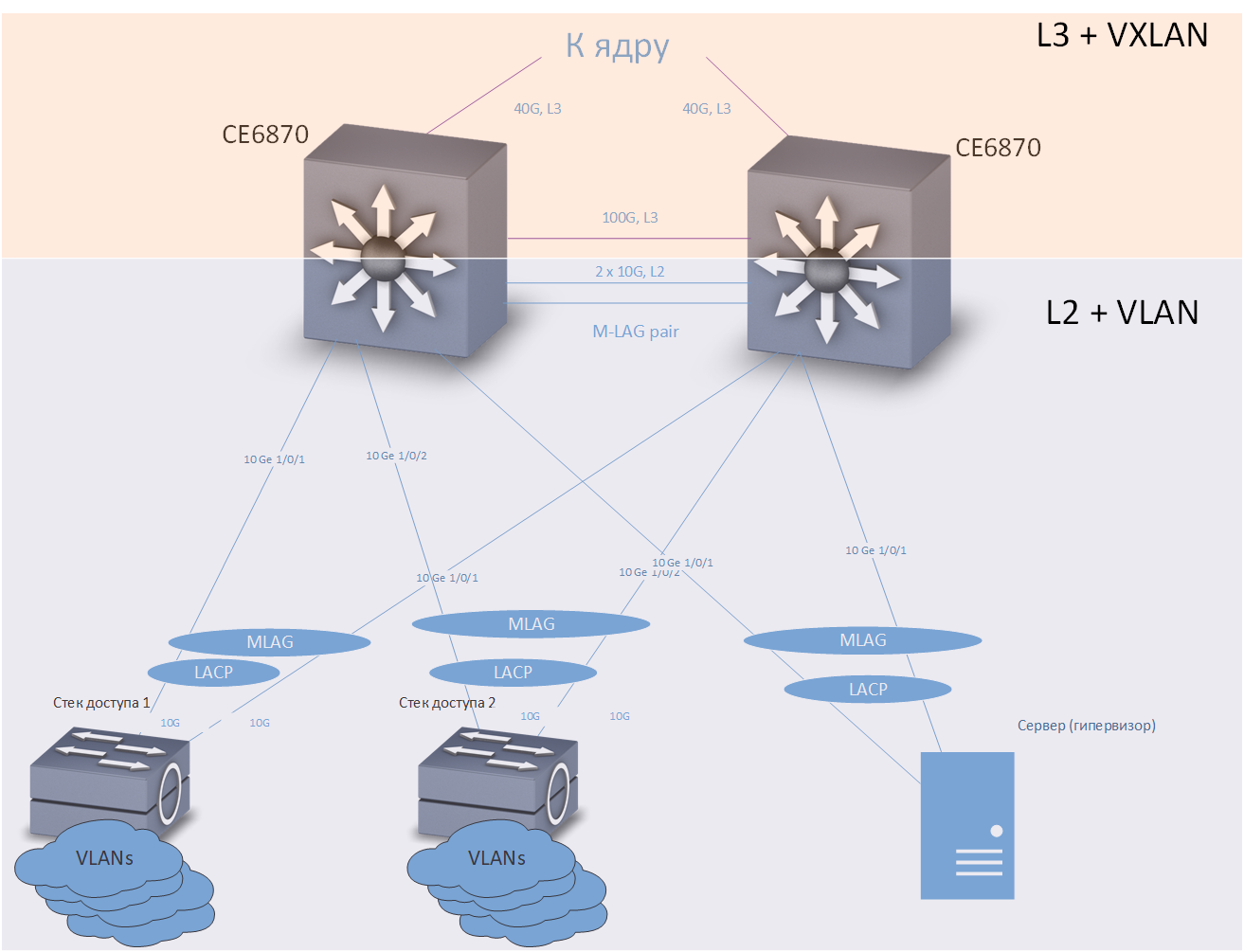
В качестве коммутаторов распределения использовались коммутаторы Huawei CE6870 с лицензиями VXLAN. Это устройство имеет оптимальное сочетание цена/качество, позволяет подключать абонентов на скорости 10 Гбит/с, и подключаться к магистрали на скоростях 40–100 Гбит/с, в зависимости от используемых трансиверов.

Коммутаторы Huawei CE6870
В качестве коммутаторов ядра использовались коммутаторы Huawei CE8850. Из задача — быстро и надежно передавать трафик. К ним не подключаются никакие устройства, кроме коммутаторов распределения, они ничего не знают про VXLAN, поэтому была выбрана модель с 32 портами 40/100 Гбит/с, с базовой лицензией, обеспечивающей L3-маршрутизацию и поддержку протоколов IS-IS и MP-BGP.

Самый нижний — коммутатор ядра Huawei CE8850
На этапе проектирования внутри команды разразилась дискуссия о технологиях, с помощью которых можно реализовать отказоустойчивое подключение к узлам опорной сети. Наш московский офис размещается в трёх зданиях, у нас 7 кроссовых помещений, в каждом из которых было установлено два коммутатора распределения Huawei CE6870 (ещё в нескольких кроссовых помещениях устанавливались только коммутаторы доступа). При разработке концепции сети было рассмотрено два варианта резервирования:
- Объединение коммутаторов распределения в отказоустойчивый стек в каждом кроссовом помещении. Плюсы: простота и удобство настройки. Минусы: выше вероятность выхода из строя всего стека при проявлении ошибок встроенного программного обеспечения сетевых устройств («утечки памяти» и подобные).
- Применить технологии M-LAG и Anycast gateway для подключения устройств к коммутаторам распределения.
В итоге остановились на втором варианте. Он несколько сложнее в настройке, но показал на практике свою работоспособность и высокую надежность.
Рассмотрим сначала подключение оконечных устройств к коммутаторам распределения:
Кроссовая
Коммутатор доступа, сервер или любое другое устройство, требующее отказоустойчивого подключения, включается в два коммутатора распределения. Технология M-LAG обеспечивает резервирование на канальном уровне. Предполагается, что два коммутатора распределения выглядят для подключаемого оборудования как одно устройство. Резервирование и балансировка нагрузки осуществляются по протоколу LACP.
Технология Anycast gateway обеспечивает резервирование на сетевом уровне. На каждом из коммутаторов распределения настроено достаточно большое количество VRF (каждый VRF предназначен для своих целей — отдельно для «обычных» пользователей, отдельно — для телефонии, отдельно — для различных тестовых сред и сред разработки, и т. п.), и в каждом VRF настроено несколько VLAN. В нашей сети коммутаторы распределения являются шлюзами по умолчанию для всех устройств, подключенных к ним. IP-адреса, соответствующие интерфейсам VLAN, одинаковые для обоих коммутаторов распределения. Маршрутизация трафика производится через ближайший коммутатор.
Теперь рассмотрим подключение коммутаторов распределения к ядру:
Отказоустойчивость обеспечивается на сетевом уровне, по протоколу IS-IS. Обратите внимание — между коммутаторами предусмотрена отдельная линия связи L3, на скорости 100G. Физически эта линия связи представляет собой кабель Direct Access, его можно увидеть справа на фотографии коммутаторов Huawei CE6870.
Альтернативой было бы организовать «честную» полносвязную топологию «двойная звезда», но, как было сказано выше, у нас 7 кроссовых помещений в трёх зданиях. Соответственно, если бы мы выбрали топологию «двойная звезда», то нам бы понадобилось ровно в два раза больше «дальнобойных» трансиверов 40G. Экономия здесь очень существенная.
Нужно сказать несколько слов о том, как совместно работают технологии VXLAN и Anycast gateway. VXLAN, если не вдаваться в детали — это туннель для транспортировки кадров Ethernet внутри пакетов UDP. В качестве целевого (destination) IP-адреса VXLAN-туннеля используются loopback-интерфейсы коммутаторов распределения. В каждой кроссовой установлены два коммутатора с одинаковыми адресами loopback-интерфейсов, соответственно пакет может прийти на любой из них, и из него может быть извлечен кадр Ethernet.
Если коммутатор знает о целевом MAC-адресе извлеченного кадра, кадр будет корректно доставлен по назначению. За то, чтобы оба коммутатора распределения, установленные в одной кроссовой, имели актуальную информацию обо всех MAC-адресах, «прилетающих» с коммутаторов доступа, отвечает механизм M-LAG, предусматривающий синхронизацию таблиц MAC-адресов (а также ARP-таблиц) на обоих коммутаторах M-LAG-пары.
Балансировка трафика достигается благодаря наличию в underlay-сети нескольких маршрутов на loopback-интерфейсы коммутаторов распределения.
Вместо заключения
Как уже было сказано выше, на испытаниях и в работе сеть показала высокую надежность (время восстановления при типовых отказах не более сотен миллисекунд) и хорошую производительность — каждая кроссовая связана с ядром двумя каналами по 40 Гбит/с. Коммутаторы доступа в нашей сети объединяются в стеки и подключаются к коммутаторам распределения по LACP/M-LAG двумя каналами по 10 Гбит/с. В стеке обычно 5 коммутаторов по 48 портов в каждом, к распределению в каждой кроссовой подключаются до 10 стеков доступа. Таким образом, магистраль обеспечивает около 30 Мбит/с на пользователя даже при максимальной теоретической загрузке, что на момент написания статьи достаточно для всех наших практических применений.
Сеть позволяет без проблем организовать сопряжение любых произвольных подключенных устройств как по L2, так и по L3, обеспечивая полную изоляцию трафика (что нравится службе информационной безопасности) и доменов отказов (что нравится службе эксплуатации).
В следующей части расскажем, как мы проводили миграцию на новую сеть. Stay tuned!
Максим Клочков
Старший консультант группы сетевого аудита и комплексных проектов
Центра сетевых решений
«Инфосистемы Джет»
Комментарии (30)

lebedinskiy
10.06.2019 15:38+1Вы конечно простите, но в свете последних событий, не рискованное ли вложение в оборудование Huawei?
Чего-то вспомнилось:
«Мыши плакали, кололись, но продолжали жрать кактус»…
Javian
10.06.2019 16:00+1Наоборот. Есть рекомендация в госконторах не использовать в новых проектах CISCO, ZTE, из-за риска санкций. Проекты выполняются на оборудовании Huawei. Возможно еще что-то.

MikhailShpak
10.06.2019 18:17+1не буду делать рекламу, но помимо Huawei — на наш рынок пришло еще много китайских производителей, к которым нет такой глобальной «аллергии». Живут и продают вполне неплохо

mklochkov Автор
10.06.2019 16:16Проект был инициирован около года назад, завершен в феврале. Тогда «последние события» даже на горизонте не просматривались. Подобные риски есть всегда, здесь мы «в одной лодке» с нашими заказчиками.

Dmitry88
10.06.2019 16:00+1Недавно посылали запрос по хуавею на сервера, там просто не смогли ответить по срокам поставки. У китайцев трудности.
MikhailShpak
10.06.2019 18:16+1так с серверами — это все-таки кросс-лицензированный x86, с которым пресловутый Entity List — позволяет поддерживать текущие контракты и обязательства. С точки зрения сетевых продуктов — влияние минимальное
gosha-z
10.06.2019 21:43У хуавей с поставками серверов/СХД/VDI традиционно трудности — не раз на эти грабли наступал с разными заказчиками. Трудности вплоть до невозможности цену посчитать.
vanyas
10.06.2019 16:49+1Почему IS-IS? Это довольно экзотический протокол для использовании в андерлее L3 фабрик, т.к. далеко не все ведоры его умеют в дата-центр коммуторах, ospf тут был бы всё же универсальнее. А вообще, имхо, bgp больше подходит в качестве протокола маршрутизации в L3 фабрике, т.к. куда лучше масштабируется, но в сети семью парами лифов, на масштабируемость конечно пофиг.
mklochkov Автор
10.06.2019 17:13Вы имеете в виду, организовать маршрутизацию по BGP не только на overlay, но и на underlay? Мы посчитали, что для сети из 7 пар лифов (на самом деле 8, т. к. присутствует ещё одна пара border leaves) это некоторый overkill.
Что до OSPF vs IS-IS — для сети такого размера это действительно значения не имеет, но у нас был не самый положительный опыт с OSPF в предыдущей нашей сети, и мы хотели попробовать что-то новое.
MikhailShpak
10.06.2019 18:22+1Так Huawei пришел из Телеком со стандартным де-факто IS-IS, его реализация в Underlay вполне обоснована, в тч из-за нативного dual-stack механизма.
vertex4
10.06.2019 20:47Внезапно, проприетарная L3 фабрика у juniper (virtual chassis fabric) — основана на IS-IS. А тут в целом что-то похожее…
vanyas
10.06.2019 20:51VCF — это L2 фабрика, а не L3 так-то. Благо для L3 фабрик сейчас ничего проприентарного не нужно, кроме разве что mlag у части вендор-лиз, джун благо умеет нативный EVPN multihoming
vanyas
10.06.2019 17:16Не увидел, как вы роутите vrf'ы, используете EVPN Type5 маршруты? Или тяние каждый влан vxlan'ом кудато на отдельную коробку, где уже роутите между собой?
mklochkov Автор
10.06.2019 17:43Мы используем оба варианта — для приложений/пользователей, которым достаточно обычной L3-связности, используем первый вариант, а если нужно организовать «растянутый» broadcast domain — то второй вариант. В следующей части статьи попробуем разрисовать подробнее.
alex005
10.06.2019 22:34Принципиально: использование большой трубы, которая вливается в более большую и т.д. и это все сводиться в сервер, который обрабатывает запросы, отбрасывая всю шелуху, которая инкапсулируется ниже целевого сервиса? Не кажется ли вам, что весь этот оверлейный подход давно уже пора выкинуть на помойку?
mklochkov Автор
10.06.2019 22:59До модернизации у нас так и было — ничего никуда не инкапсулировалось. Но в какой-то момент мы обнаружили, что между некоторыми кроссовыми и серверными есть кабели подразделения А, и кабели подразделения Б, и ещё кабели подразделения В, и хорошо бы ещё кабель протянуть, на 16 волокон, или даже на 32. Сетью с L2/L3 VPN рулить всё же проще, по крайней мере типовые задачи лучше поддаются автоматизации.
alex005
10.06.2019 23:53-1Вы не поняли! Вообще принципиально — это удар по всем капиталистическим ублюдкам, которые не дают жить природе, засрали этот мир пластиком и ещЁ тайными именами нефти! Но это мой офтоп-удар в жалких прохиндеев-владельцев вашей, погрязшей, в государственной коррупции компании — которые очень любят нюхать чистый колумбийский кокаин и пить односолодовый виски, как и их молодые распутные деревенские жЁны, желая прихвастнуть, как мы модернизировали свою сраную корпоративную, никому не нужную сеть.
Понятно, что это не в ближайшем будущем, но это не фантастика, а дело ближайших десятилетий (если не меньше), когда все нормализуется. Вся инфраструктура Интернет, как и корпоративных сетей страдает от ущербной клиент-серверной архитектуры, навязанной жаждой наживы — всечеловеческий обман о единственном пути. Который ведет к чрезмерной централизации как вычислений, так и хранения информации, всЁ увеличивающиеся потокам ничем не обоснованных никчемных данных. Потоки данных, которые отправляются в центры обработки и обратно, сгорая в /dev/null 2>&1 как в аду!
Вообще этот комментарий — удар по Хабру — это уже придаток корпоративного мира, желающего всего самого сладкого в жизни, фейковой корпоративной площадки, продажной и желающей наживы!MikhailShpak
11.06.2019 10:21+1текст самобытный и аутентичный, может в копирайтеры для диктаторов? Успех гарантирован!

abar
11.06.2019 09:42Хорошая статья, но обратил внимание на одну деталь:
Организациям разного профиля — банкам,… — под их задачи и стандарты нужны определённые типы сетей, специфика которых понятна и стандартизирована. Однако с нами такое не прокатит.
Не уверен, что мы говорим об одном и том же, но как работник банка хочу заметить, что проектирование сетей в банке может строиться по такому принципу: «Так, тут у нас будет техподдержка, тут — девочки с приемной сидеть, здесь — конференц-зал для стейкхолдеров, а сюда мы воткнем наш главный монолит! Никого не забыли? Тфу, да нет конечно же!».
После чего спустя какое-то время всем отделам разработки и QA приходится решать такие инересные задачи: «Как расширять внутреннюю инфраструктуру, когда некуда», «Как ввести новую методологию 'УЖЕ СЕЙЧАС ПРЯМО СРОЧНО', когда сервер под это дело получить можно будет в лучшем случае через пол года, если вообще дойдет очередь», или «Как провести нагрузочное тестирование сервиса и не уронить внутреннюю сеть».
Возможно, конечно, ошибаюсь и в России стандарты другие, чем «на западе».mklochkov Автор
11.06.2019 10:17Да, вы правы. Если в банке заводится собственная разработка/QA (а сейчас такие — все, или скоро будут), его ИТ-службам приходится решать проблемы, очень похожие на наши.
IgorKuznet
14.06.2019 10:46Улыбнуло «Порядок работы над сложной автоматизированной системой пока лучше всего описан в ГОСТ 34.601-90 «Автоматизированные системы. Стадии создания», поэтому мы работали по нему. И уже на стадиях формирования требований и разработки концепции мы столкнулись с первыми трудностями. » — что ж там в 34-м такого нашли? Или замполит эту фразу дописал? Джету — привет!
mklochkov Автор
14.06.2019 11:03Все 34-е госты изучать и использовать не обязательно, там много воды и мусора. Но упомянутый небольшой документ считаю одним из самых важных. Фактически, в нём описан правильный порядок работы над сложной системой, и не пропущена ни одна важная стадия (за исключением корректировки рабочей документации после опытнй эксплуатции).
furtaev
Шпионажа со стороны «товарищей» не опасаетесь совсем?
rader90
Стана происхождения думаю не будет важна. Основная часть оборудования за рубежом делается у всяких «товарищей». Гарантии все равно не будет на 100%.
mklochkov Автор
Опасаемся, конечно же. Но — оборудования, работающего автономно, без связки с вендором (через патчи, обновления, лицензии, или просто напрямую), в XXI веке уже и не найти.
pilot911
со стороны американцев не опасаются
MikhailShpak
а какого шпионажа вы ожидаете? у одного из ведущих интеграторов по ИБ? А также по искоренению непониманию в данной сфере — специально создан такой глобальный институт, как Huawei Cyber Security Transparency Centre.
www.huawei.com/en/press-events/news/2019/3/huawei-cyber-security-transparency-centre-brussels
Его задача, как раз и убирать такой Black PR, который все ещё PR )