
Расскажу о проблемах и способах их решения при разработке скоринговых моделей. Эти примеры могут быть интересны специалистам, работающим в сфере кредитования и просто читателям хабра, интересующимся особенностями разработки в проектах машинного обучения/кредитного скоринга.

Рассмотрим два сценария:
- У вас уже есть модель скоринга и вы хотите ее сломать.
- Вы знаете, что скоро компания захочет разработать свою скоринговую модель и ни в коем случае нельзя этого допустить.
Итак, вот несколько способов сломать скоринговую модель.
Сценарий 1
Способ №1 — внести изменения на сайт
- Изменить дизайн страницы выбора суммы и срока кредита
- Изменить дефолтное значение сумма/срок кредита при заходе на сайт
Способ №2 — создать отдел маркетинга
Необходимо, чтобы в МФО был создан отдел маркетинга. При очень частом появлении новых кредитных продуктов, изменении процентных ставок, маркетинговых акций «первый займ бесплатно», скоринговые модели не смогут адекватно работать длительный период.

Сценарий 2
Способ №3 — уничтожить данные (желательно платные)
- Перезатереть данные кредитной истории клиента от предыдущих обращений
- Перезатереть данные анкеты клиента от предыдущих обращений
Способ №4 — сделать отличающийся интерфейс ввода данных в разных каналах подачи заявки и устройствах (онлайн, оффлайн, Android, Iphone)
Способ №5 — добавить сценарий заполнения поля базы данных и не задокументировать это
В базе данных необходимо создать поле FIRSTLOAN с комментарием «запрошенная сумма кредита». При одобрении кредита перезаписывать значение этого поля на сумму, которая была в конечном итоге одобрена.
Способ №6 — нанять data science специалиста
Он всех убедит, что скоринговый бал бюро — это отстой. Стэкинг в проде — это хорошо. Подбор гиперпараметров и крутые модели — это то, на что нужно тратить большую часть времени. А если найти золотой сид, то можно получить небольшой прирост в качестве.
Разберем более подробно каждый способ.
Дизайн страницы выбора суммы и срока кредита
Вот так выглядит главная страница сайта, где клиент выбирает сумму и срок кредита. Обратите внимание на количество вкладок и диапазон сумм на каждой вкладке.
| До изменений |
После изменений |
 |
 |
После того, как первую и вторую вкладку объединили в одну, часть заявок из диапазона 2-10к переместилось в диапазон 11-20к. Для бизнеса это хорошо с точки зрения среднего чека.
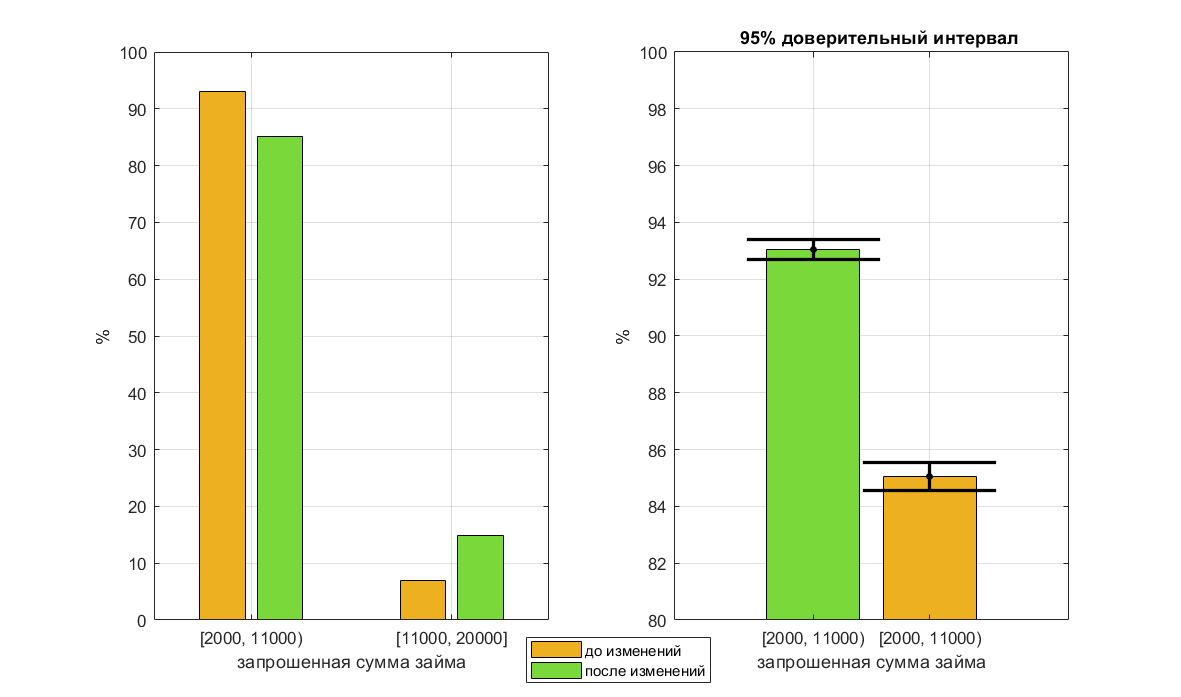
Распределение запрашиваемых сумм до и после изменений
Справа — крупный масштаб
По историческим данным, собранным во время работы старой версии сайта, в данных есть линейно отрицательная зависимость между запрашиваемой суммой займа и вероятностью невозврата. По клиентам, запросившим суммы 11-20к, вероятность невозврата меньше. Даже при ручном андеррайтинге наблюдается более высокий уровень одобрения. Это подтверждает гипотезу о том, что заемщики, подававшие заявку со второй вкладки, в среднем лучше. Для обученной модели это означает, что запрос суммы 11-20к характеризует заемщика как хорошего. Однако, после объединения вкладок уровень одобрения при ручном рассмотрении у таких заявок снизился, а вероятность невозврата возросла. Модель же продолжила считать таких заемщиков как хороших, что привело к снижению качества скоринга в этом диапазоне. Решением проблемы было перестроение модели на тех же данных, но без признака «сумма».
По займам, которые успели выдать старой моделью на новой версии сайта, проводился разбор ошибок модели. Большая часть из них была связана с тем, что заемщик с очень плохой кредитной историей должен был получить отказ, но указав сумму 20000 получал «накрутку» к своему скору и получал одобрение на минимальную сумму 2-3к.
Наличие связи между большой запрошенной суммой и низкой вероятностью невозврата странно. Есть предположение, что бОльшие суммы запрашивают люди с более высоким уровнем дохода. А на отдельную вкладку 11-20к (возможно) переходили люди, которым действительно нужна была именно такая сумма и они знали, что смогут ее погасить.
Дефолтное значение сумма/срок кредита при заходе на сайт
Давайте рассмотрим как влияет значение бегунка «сумма» на распределение запрашиваемых сумм. При заходе на сайт, значение слайдера выбора суммы установлено на 7000 р. — картинка слева, 8000 р. — картинка справа.
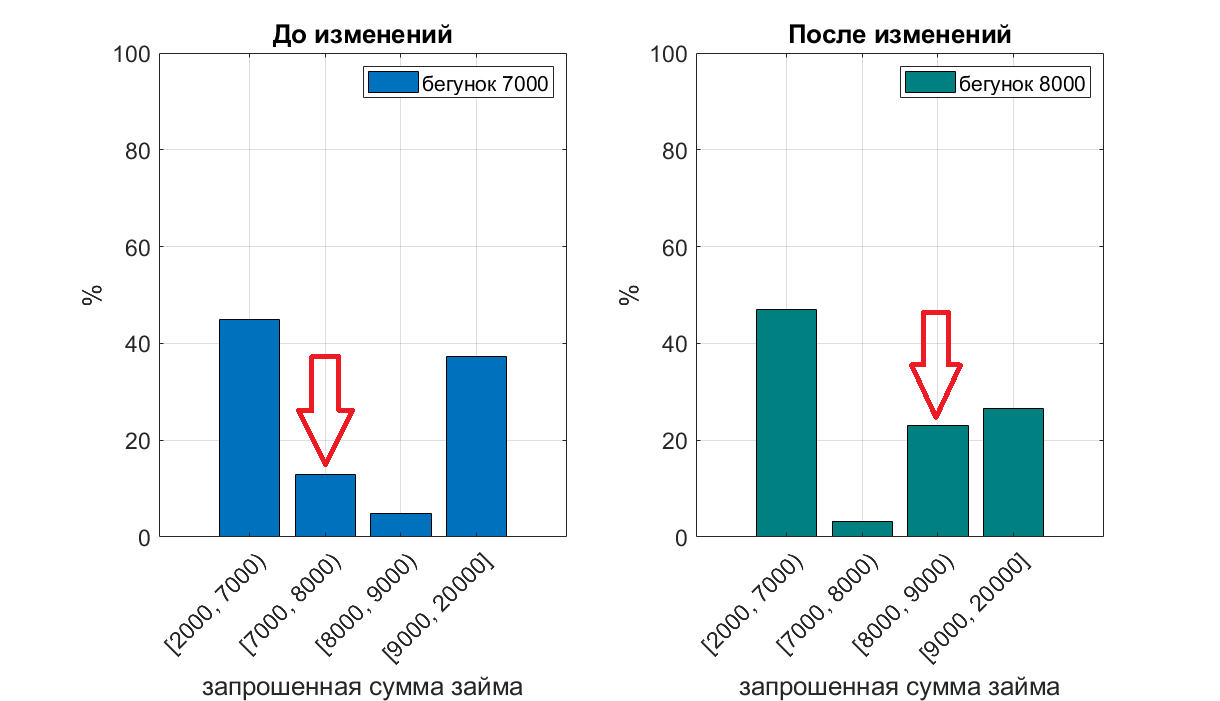
Видно, что количество запросов на кредит какой-то определенной суммы (7к или 8к) сильно возрастает, если установить бегунок по умолчанию на это значение.
При наличии зависимости между сдвигом бегунка (осознанного выбора нужной заемщику суммы) и риском невозврата, модель, основанная на деревьях, найдет эту зависимость в данных в признаке сумма займа. Даже без создания специального признака «совпадает ли выбранная сумма со значением бегунка по умолчанию». Алгоритм создает правило «если сумма больше 6к, но меньше 8к — заемщик плохой». В случае изменения дефолтного значения бегунка на сайте, это правило будет работать некорректно. Решением проблемы является отказ от использования этого признака, либо создание дополнительного признака — «совпадает ли выбранная сумма со значением бегунка по умолчанию».
При анализе новой модели, которая не использует признак «сумма займа», мы построили зависимость среднего скора от суммы займа.
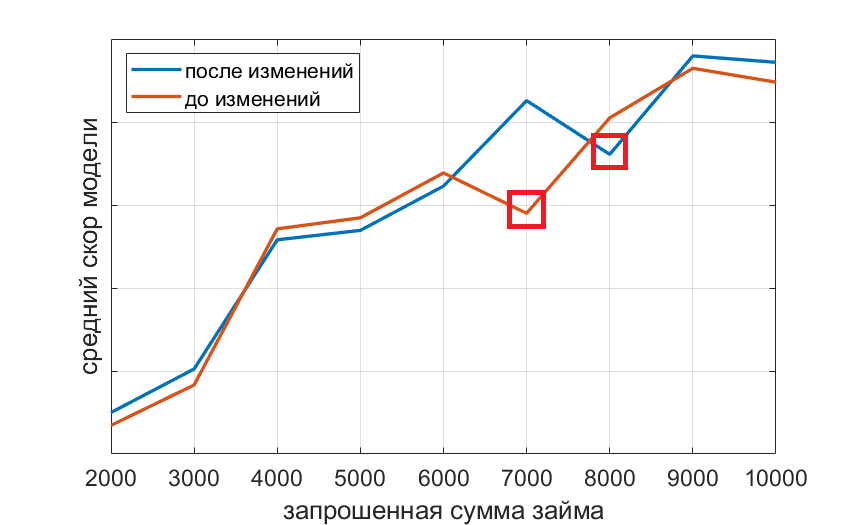
Модель, не зная какое на сайте установлено дефолтное значение бегунка, и не используя признак запрошенная сумма займа, все равно присваивает заемщикам, не сдвинувшим бегунок, меньший скор, опираясь на другие признаки. Эта интересная находка позволяет нам утверждать, что выбор суммы и срока займа по умолчанию является признаком плохого заемщика.
Перезатереть данные кредитной истории клиента
При подаче заявки на кредит в бюро кредитных историй направляется платный запрос. В ответе содержится подробная информация о том, как клиент выплачивал другие кредиты, допускал ли просрочки, размер, тип кредитов и т.д. Довольно часто клиенты берут займ в МФО больше, чем один раз. При повторном обращении в бюро также направляется запрос, т.к. финансовое положение заемщика могло измениться. Архитектор баз данных, андеррайтеры и другие лица, которые каким-либо образом работают с кредитной историей, решают, что хранить кредитную историю о предыдущих обращениях не имеет смысла, т.к. она занимает место на жёстком диске, а смотреть ее никто не будет. Создают две таблицы ORDERS и CLIENTS. В ORDERS записываются данные о заявке, в CLIENTS — о клиенте. КИ помещается в таблицу CLIENTS. При каждом новом обращении КИ перезаписывается. Для датасаентиста это означает, что он получает смещенную выборку для обучения. В базе остаются КИ о клиентах, которые либо взяли займ один раз и не вернули. Либо взяли один раз и не стали постоянными клиентами. Информация о первой заявке самых ценных клиентов, которые стали постоянными, недоступна.
Аналогично обстоит ситуация с данными анкеты. В таблице CLIENTS хранится информация о доходе, семейном статусе, месте работы и др. Эти данные, также перезатираются. Однако доход человека и семейный статус, как известно, могут меняться со временем.
Интерфейс ввода данных в разных каналах подачи заявки
При подаче заявки на кредит клиент заполняет анкету, в которой указывает ежемесячный доход. Давайте посмотрим, как выглядит распределение значений дохода в зависимости от канала подачи заявки. По х — id заявки, по у — доход.
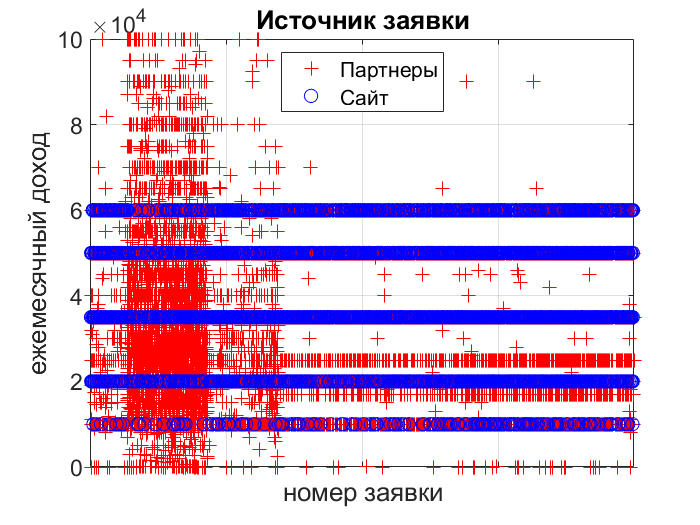
На сайте установлен выпадающий список. А когда заявка приходит из партнерской сети, поле может быть заполнено произвольным значением. Аналогичная ситуация происходит при заполнении заявки в оффлайн — офисе. Если не заметить этот факт при разработке скоринговой модели, то модель будет оценивать вероятность невозврата с использованием признака «доход» в зависимости от того, в каком соотношении были данные каналов партнеры/сайт/оффлайн в тренировочном наборе. Решение проблемы — не использовать признак «доход». Либо делать дискретизацию значения признака для канала «партнеры» и «оффлайн» в такие же интервалы, как указано на сайте (что не очень хорошо, т.к. способ ввода все-таки другой). Или же делать на сайте поле ввода и ждать, пока накопятся данные.
Отдел маркетинга
В компании несколько продуктов:
PDL займы — кредиты на сумму от 2 до 20к, которые нужно закрыть одним платежом.
Installment займы — займы на сумму от 21 до 100к. В момент, когда клиент подает заявку, в зависимости от того, новый это клиент или повторный, от региона и прочих факторов, маркетинг определяет, какой продукт ему можно и нужно дать. В параметры продукта входят минимальные/максимальные суммы и сроки займов. Изначально, определение продукта проводилось после скоринга. Т.е. в скоринговую модель подавались суммы и срок, указанные клиентом. В какой-то момент определение продукта начало происходить до скоринга. И указанные клиентом данные автоматически подменялись на «нужные» и подавались в скоринг. Это привело к ухудшению качества скоринга. Решение проблемы — возврат к прежней логике определения продукта.
Ошибки data science специалиста
Специалист по анализу данных хочет использовать в качестве признака текстовое поле «цель займа». Выгружает данные, группирует цели займа в категории. Проводит анализ процента плохих по каждой категории. Процент плохих, либо WOE — логарифм отношения количества хороших к плохим.

Анализ уровня просрочки (количество невозвращенных займов, поделенное на количество выданных) по каждой категории. Однако данные, по которым проводился анализ, включают в себя онлайн и оффлайн-заявки.
Процедура заполнения анкеты в оффлайне существенно отличается, т.к. анкету заполняет менеджер офиса со слов клиента, либо же клиент с подсказками менеджера.
Давайте посмотрим, как выглядит частотное распределение цели займа в срезах онлайн/оффлайн.

В онлайне клиенты не заполняют цель займа. С учетом того, что соотношение заявок в сторону онлайн постоянно растет, использовать признак возможно только после установки поля «цель займа» на обязательное и дополнительного цикла сбора данных.
Вернемся к признаку «сумма займа». Специалист по анализу данных решает использовать сумму займа из заявки на кредит. В качестве метода был выбран алгоритм, основанный на деревьях решений (случайный лес / градиентный бустинг). После первых экспериментов с моделями по графику feature importances выяснилось, что признак «сумма займа» самый сильный. Интуитивно более сильные признаки не вышли в топ. После анализа возможных причин, было установлено, что поле «сумма займа» перезаписывается после одобрения займа. Это происходит в случаях, когда кредитный специалист одобряет меньшую и «неровную» сумму займа. Таким образом в данные закрался data leak, который так часто встречается в соревнованиях по анализу данных. Решение проблемы — дополнительное поле в БД, в которое пишется изначально указанная сумма.
Но и это еще не все. Давайте посмотрим на частотность «неровных» сумм займа в зависимости от канала заявки.
| источник заявки |
доля заявок с неровной суммой |
| Android app |
0 |
| Iphone app |
0 |
| Оффлайн |
0 |
| Партнеры |
0.13 |
| Сайт |
0 |
Заявки, приходящие от партнеров, имеют неровные суммы. Что в нашем случае создает нелогичные связи в дереве и делает модель менее устойчивой к появлению новых каналов заявок. Проблема усугубляется тем, что в потоке заявок процент партнерских в некоторые периоды может достигать 80-90%. В данном случае проблема решается отказом от использования признака либо дискретизацией до 1000 р и более.
Просачивание данных из будущего
При заполнении анкеты клиент может не заполнить необязательные поля. Если андеррайтер видит, что кредитная история хорошая и можно одобрить займ, он может подстраховаться и дополнительно уточнить по телефону данные, которые клиент не заполнил. В результате датасаентист работает с тренировочным набором, в котором хорошие клиенты обычно имеют наиболее полную и заполненную анкету. В таком случае признаки типа «заполнено необязательное поле X» окажутся сильными и будут характеризовать заемщика как хорошего. Однако, в режиме работы автоматического скоринга у хороших клиентов эти поля будут незаполненными. В лучшем случае получится завышенная оценка качества модели при оффлайн валидации. В худшем — более низкое качество модели по сравнению с вариантом не использовать эти признаки. Решение проблемы — более плотная работа с отделом андеррайтинга. Контроль, анализ и улучшение процесса сбора данных.
Все перечисленные проблемы легли в основу системы мониторинга качества данных и устойчивости скоринговых моделей.
Заключение
В заключение хотелось бы дать несколько рекомендаций специалистам, которые отважатся строить скоринговые модели.
- Берите данные под полный контроль, старайтесь выстроить end-to-end систему. Чем короче путь от исходного источника данных до вашего сервиса со скоринговой моделью, тем лучше. Любая прослойка в виде дополнительных сервисов предобработки / хранения данных только навредит.
- Проводите анализ признаков во времени. Это можно сделать с помощью графика scatter plot, по оси х — id записи. А также путем анализа среднего значения признака во времени. Train и test лучше разделять и по времени, и по объектам (клиентам).
- Обращайте внимание на нелогично сильные признаки. Возможно, в них утечка.
- Проводите анализ линейной взаимосвязи признака и целевой переменной (даже при построении нелинейных моделей). Направление тренда должно быть логичным.
- Если хочется получить логичные взаимосвязи и устойчивую модель, дискретизируйте денежные переменные до целых значений. Бывает, что корреляция с другими признаками закрадывается в «неровность сумм» или в копейки.
- Проводите анализ данных и качества моделей в различных срезах. Диапазон сумм, сегмент клиентов, источник заявки — онлайн/оффлайн. Старайтесь добиться примерно одинакового качества модели в каждом срезе. В случае значительных изменений соотношений срезов в трафике, будет ухудшение показателей, т.к. качество модели было изначально оптимизировано под более крупные сегменты.
- Избегайте автообновления моделей при появлении новых данных. В этом случае будет легче проводить ретро анализ причин ошибок модели (в статье не раскрыто, возможно, в будущем).
- Использование данных анкеты дает не сильный прирост в качестве к варианту использования только данных бюро. Поэтому использовать этот источник лучше на последних этапах, когда выстроена внутренняя инфраструктура сбора и хранения данных.
- Налаживайте коммуникации с другими отделами. Каждый отдел (не только программистов-разработчиков) должен иметь журнал изменений, в котором отражены все изменения с кратким описанием и датой. Даже те, которые на первый взгляд кажутся абсолютно неважными для скоринга. Журнал изменений поможет выявить причинно-следственные связи.
Надеюсь, примеры, описанные в статье, окажутся полезными. Они основаны на боевом опыте и реальных выдачах кредитов в большом объеме на длительном периоде.
Дмитрий Горелов, Devim
Комментарии (11)

VolCh
11.06.2019 07:48А давно начали МЛ использовать в скоринге?
PS Непонятно за что минусуют, мы к подобным выводам приходили и без МЛ, на интуиции, как говорится.

mark-rtb
11.06.2019 10:29За МФО минусуют. Негативное отношение к МФО у многих. Хотя на мой взгляд, для применения машинного обучения это один из лучших сегментов. Займы короткие и их много, результат от внедрения новых решений видно практически сразу. Можно пробовать самые прогрессивные методы на небольшом сегменте трафика и при этом получать адекватные результаты тестирования, из за наличия большого количества заявок.
r3bus
11.06.2019 13:31Мне кажется, что уважающий себя специалист, который имеет совесть, не будет выполнять работу, которая необходима для МФО.
VolCh
11.06.2019 14:36Вы так говорите, как будто МФО — это что-то преступное или аморальное.
algotrader2013
12.06.2019 10:27+1Конечно, аморальное. В подавляющем большинстве случаев микрокредит — это способ оттянуть проблему ценой снежного кома проблем в будущем, не говоря уже о скрытых комиссиях и штрафах. По сути, подобный эффект можно получить, хорошо выпив, или приняв вещества — проблема тоже отступит мгновенно, и вернется, многократно выросши.
Но, с другой стороны, задачи там действительно хорошие и интересные для дата саенса. И люди, которые минусят не за техническую суть статьи, а за сферу деятельности, добиваются лишь того, что статьи на эту тему исчезнут с хабра, от чего пострадают не владельцы МФО, а читатели хабра. Да, понимаю, что можно возразить, мол, надо шеймить, да и вообще, меньше будет инфы о построении МФО в открытом доступе -> сложнее будет открыть и развить этот бизнес. Но они как раз инфу найдут, как и бандиты оружие. А вот люди из других сфер перенять опыт уже не смогут (к примеру, я не имею никакого отношения к МФО, но инсайты почерпнул, за что благодарен автору).
PS: не имеет отношения к статье, но видел, как в Киеве пришла одна Большая Начальница из этой сферы на конференцию по дата саенс, и в перерыве уговаривала докладчицу поработать на них, при чем, делая это предельно пренебрежительным тоном, демонстративно размахивая последним айфоном перед носом. Возможно, мое отношение сформировал и этот факт...VolCh
12.06.2019 17:21Аморально — это в Роскомнадзоре разрабатывать системы блокировки сайтов :) Клиенты МФО — взрослые дееспособные люди и должны быть способны оценить последствия своих действий. А скоринг как раз предназначен для отсеивания тех, кто не может или не хочет. Можно сказать защищает людей от снежного кома в будущем. Кстати, не замечал минусов в статьях об автоматизации учёта алкоголя.
P.S. Разные начальницы в этой сфере есть в Киеве. "Ваша", как минимум, умная.
algotrader2013
13.06.2019 13:12А скоринг как раз предназначен для отсеивания тех, кто не может или не хочет. Можно сказать защищает людей от снежного кома в будущем.
Не могу утверждать на 100%, но предполагаю, что как раз кейс «клиент взял микрокредит -> просрочил его -> начал потихоньку выплачивать -> выплатил штрафами десятикратный размер кредита, но все еще должен» с точки бизнеса ок, и даже более ок, чем кейс «взял микрокредит -> вернул досрочно и в полном объеме», и, соответственно, скоринг в идеале должен давать таким зеленый свет.
datasanta Автор
13.06.2019 13:54Сейчас максимальная переплата (влкючая штрафы) не может превышать 2.5 кратный размер кредита
а с 1 июля 2019 — 2-x кратный
(Федеральный закон от 27.12.2018 № 554-ФЗ «О внесении изменений в Федеральный закон „О потребительском кредите (займе)“ и Федеральный закон „О микрофинансовой деятельности и микрофинансовых организациях“)
Сопровождение долга на просрочке — это расходы, которые ни одна кредитная организация (в том числе и крупные банки) не способна поддерживать самостоятельно из-за нерентабельности. Просроченные кредиты продаются в коллекторское агенство
В связи с этим скоринг все-таки настраивают так, чтобы одобрять клиентам, которые не выйдут на просрочку.
Очень часто клиенты берут займ при задержке зарплаты, чтобы внести платеж по „правильным“ с точки зрения морали кредитам (по кредитной карте). Т.к. по ним могут быть штрафы 2к в день. В этом случае выгодней взять микрозайм. Наша модель это учитывает, используя признаки „количество дней до/после выплаты зарплаты“ и „цель займа“.
ZEvS_Poisk
На 3 минуты завис просматривая гифку КДПВ.