
В статье я расскажу о том, как аналитика может помочь в принятии таких решений. Как собрать информацию о населении, ценах на недвижимость и сделать интерактивные визуализации. Зависит ли кол-во клиентов от расстояния до филиала, года постройки дома, стоимости недвижимости.
Население города с точностью до дома

#Тепловая карта для СПб
import pandas as pd
from folium.plugins import HeatMap
import folium
#Загрузка данных
df = pd.read_csv('people_spb.csv')
filial = pd.read_csv('filial.csv')
competitor = pd.read_csv('competitors.csv')
#Создание карты
hmap = folium.Map(location=[59.95, 30.15], zoom_start=11)
#Слой для населения Спб
people = folium.FeatureGroup(name = 'Население СПб')
hm = HeatMap( list(zip(df.lat.values, df.lng.values, df['People'])),
min_opacity = .1,
max_val = df['People'].max(),
radius = 15,
blur = 25,
max_zoom = 1
)
people.add_child(hm)
#Маркеры с адресами филиалов
filial_markers = folium.FeatureGroup(name = 'Адреса филиалов')
for index, row in filial.iterrows():
folium.Marker(
location = [row['lat'], row['lng']],
popup = row['Name'],
icon = folium.Icon(color='blue', icon='cloud')
).add_to(filial_markers)
#Маркеры с адресами конкурентов
competitor_markers = folium.FeatureGroup(name = 'Адреса конкурентов')
for index, row in competitor.iterrows():
folium.Marker(
location = [row['lat'], row['lng']],
popup = row['Name'],
icon = folium.Icon(color='red')
).add_to(competitor_markers)
#Добавляем слои на карту
hmap.add_child(people)
hmap.add_child(filial_markers)
hmap.add_child(competitor_markers)
#Добавляем контроль слоев
folium.LayerControl(collapsed=False).add_to(hmap)
#Сохраняем полученную карту в html файл
hmap.save('people_spb.html')
Для оценки населения дома мы использовали данные реформы ЖКХ. На этом портале можно получить информацию по каждому дому: год постройки, жилая площадь, кол-во жилых помещений. Оценка населения каждого дома базировалась на кол-ве квартир и общей жилой площади: в среднем около 3-х человек на квартиру с небольшими отличиями для некоторых домов и муниципальных округов.
Выше представлена тепловая карта с плотностью населения по СПб. Наша карта для внутреннего пользования содержит еще отдельный слой с плотностью проживания клиентов. Так удобнее искать белые пятна — места с низким покрытием.
Адреса клиентов
Благодаря специфики бизнеса у нас в базе данных были адреса почти по всем клиентам. Нужно было только найти географические координаты для каждого адреса: геокодирование или геокодинг. Для получения координат я использовал пакет geocoder для python. В процессе геокодирования возникли следующие проблемы:
- Некоторые адреса указаны неверно, например, перепутан корпус или литера. В этой ситуации геокодинг может “поселить” клиента в детский сад или административное здание. Для таких случаев пришлось написать процесс, который менял координаты на ближайший жилой дом в пределах 200 м.
- Точки с аномально высоким кол-вом клиентов: центр города, середина большой улицы, середина района. Такие координаты получались при некорректно заполненном адресе и могли исказить общую картину, поэтому перед моделированием удалялись
В итоге, мы получили точные координаты дома для 93% клиентов. Теперь можно построить такую карту:
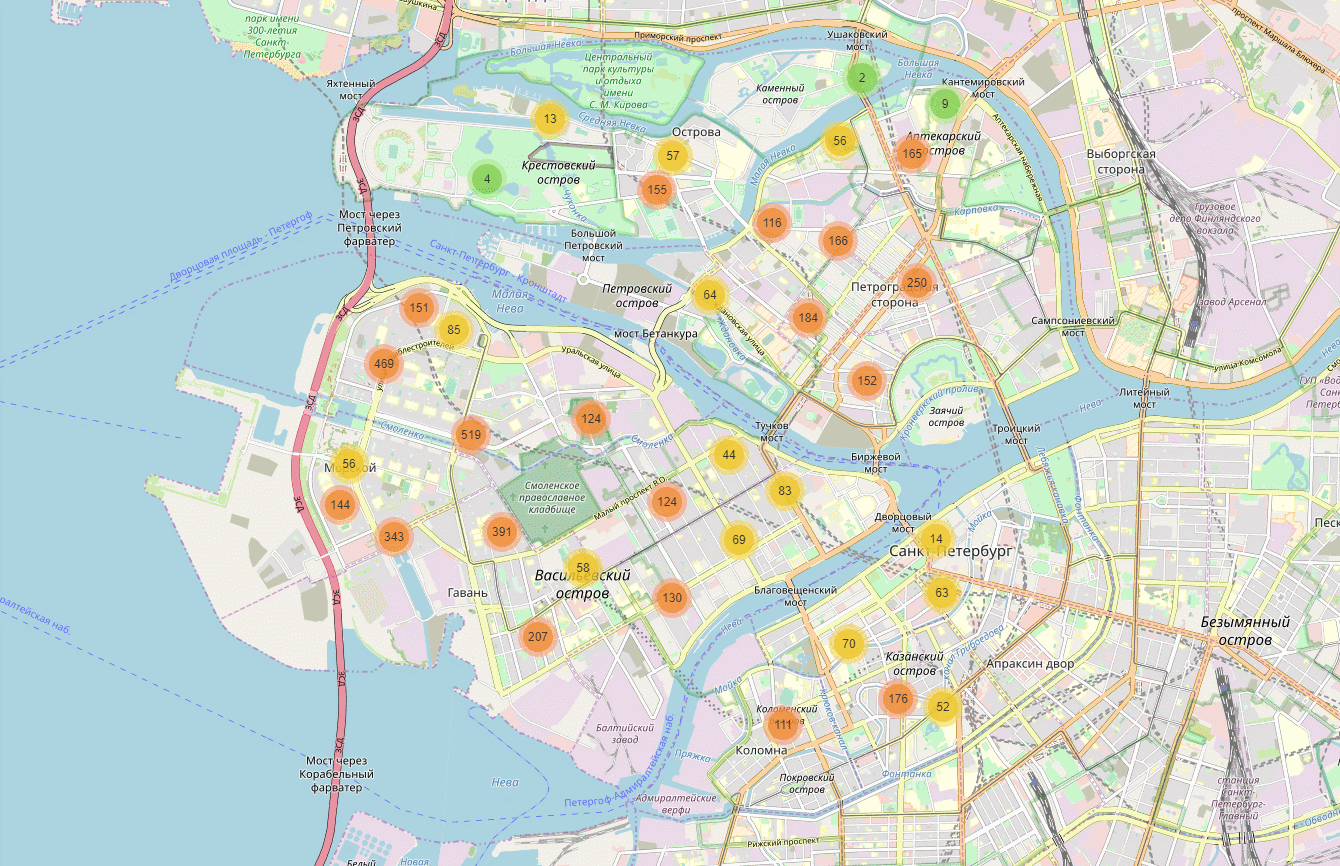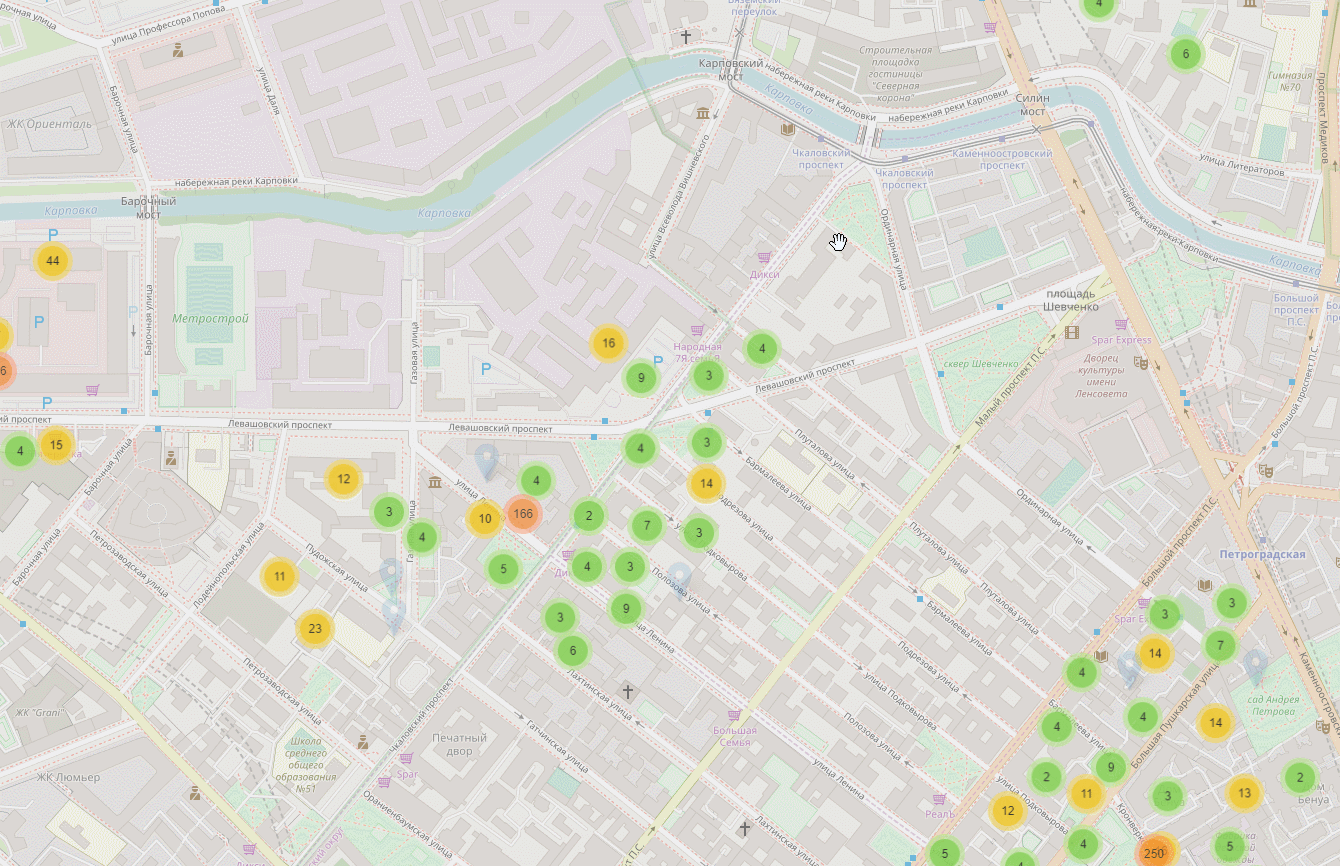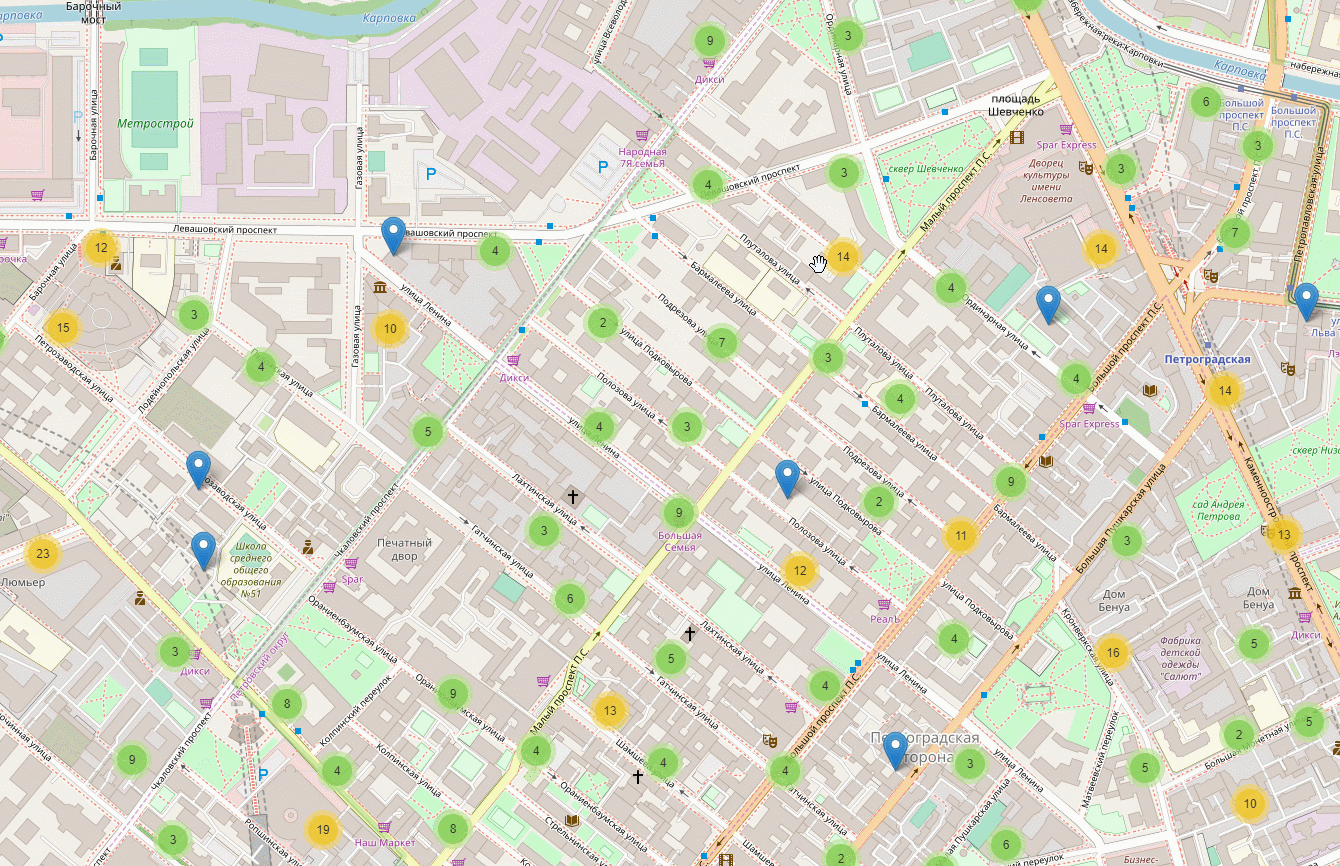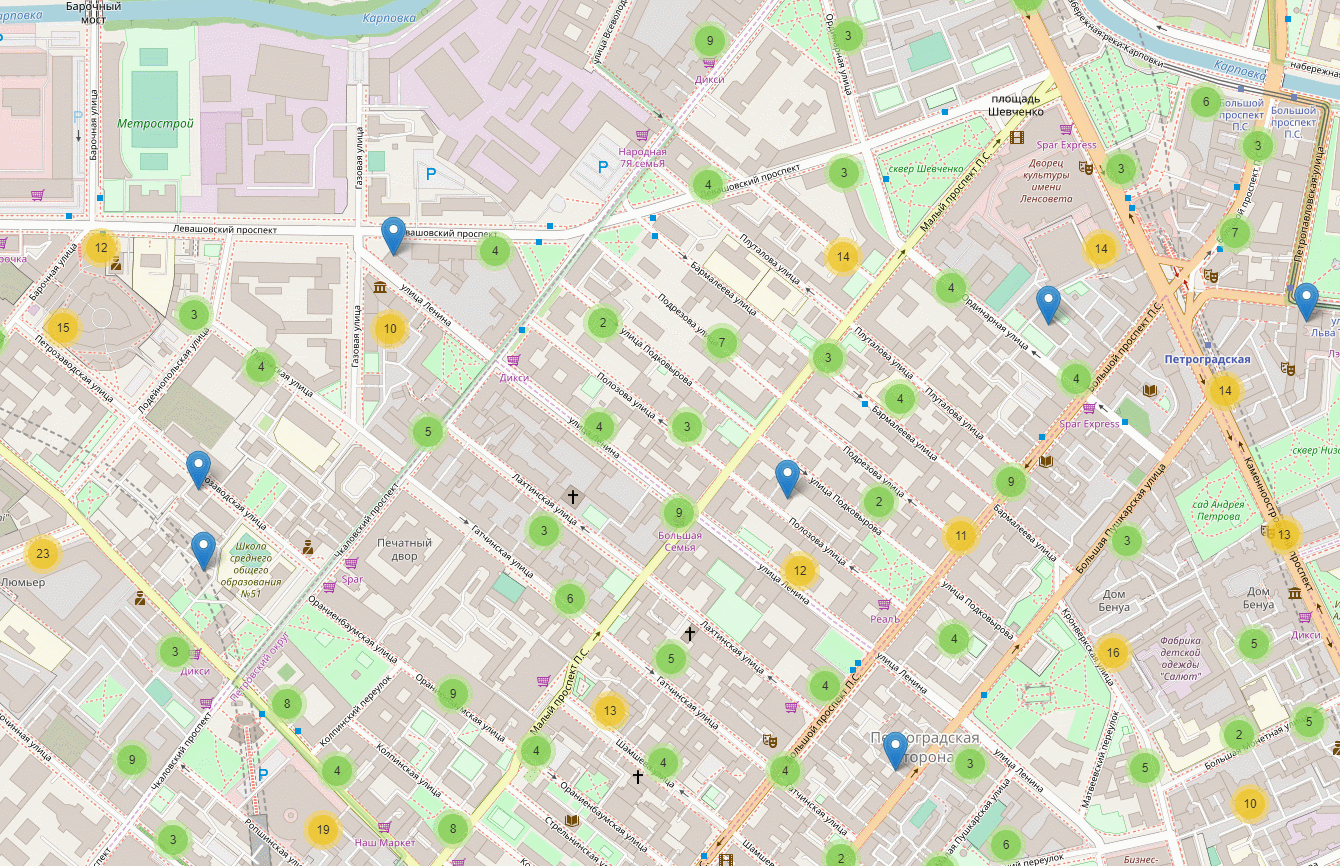
На карту для части Санкт-Петербурга нанесены случайные данные.
import pandas as pd
import folium
from folium.plugins import MarkerCluster
#Загружаем данные
df = pd.read_csv('data.csv')
cmap = folium.Map(location=[59.95525, 30.2923], zoom_start=13)
mс = MarkerCluster()
for i, row in df.iterrows():
mc.add_child(folium.Marker(location=[row.lat,row.lng]))
cmap.add_child(mc)
cmap.save(folder+"marker_map.html")
Такая карта оказалась удобным инструментом для проверки гипотез. Например, у бизнеса была гипотеза о том, что в некоторых типах домов (советская массовая застройка: корабли, 504 серия, хрущевки и т.д.) не будет наших клиентов. Оказалось, это не совсем так. Да, доля клиентов от населения в таких домах низкая. Но их нужно учитывать так как в городе таких домов очень много и в итоге они обеспечивают до 20% клиентского потока.
Границы муниципальных округов
Можно перегруппировать данные о населении и клиентах из предыдущего раздела по муниципальным округам и нанести на карту. Если добавить инфоокна и кастомизированную окраску, получается очень информативно. На хабре уже есть отличная статья, где по шагам показано, как строить такие карты.
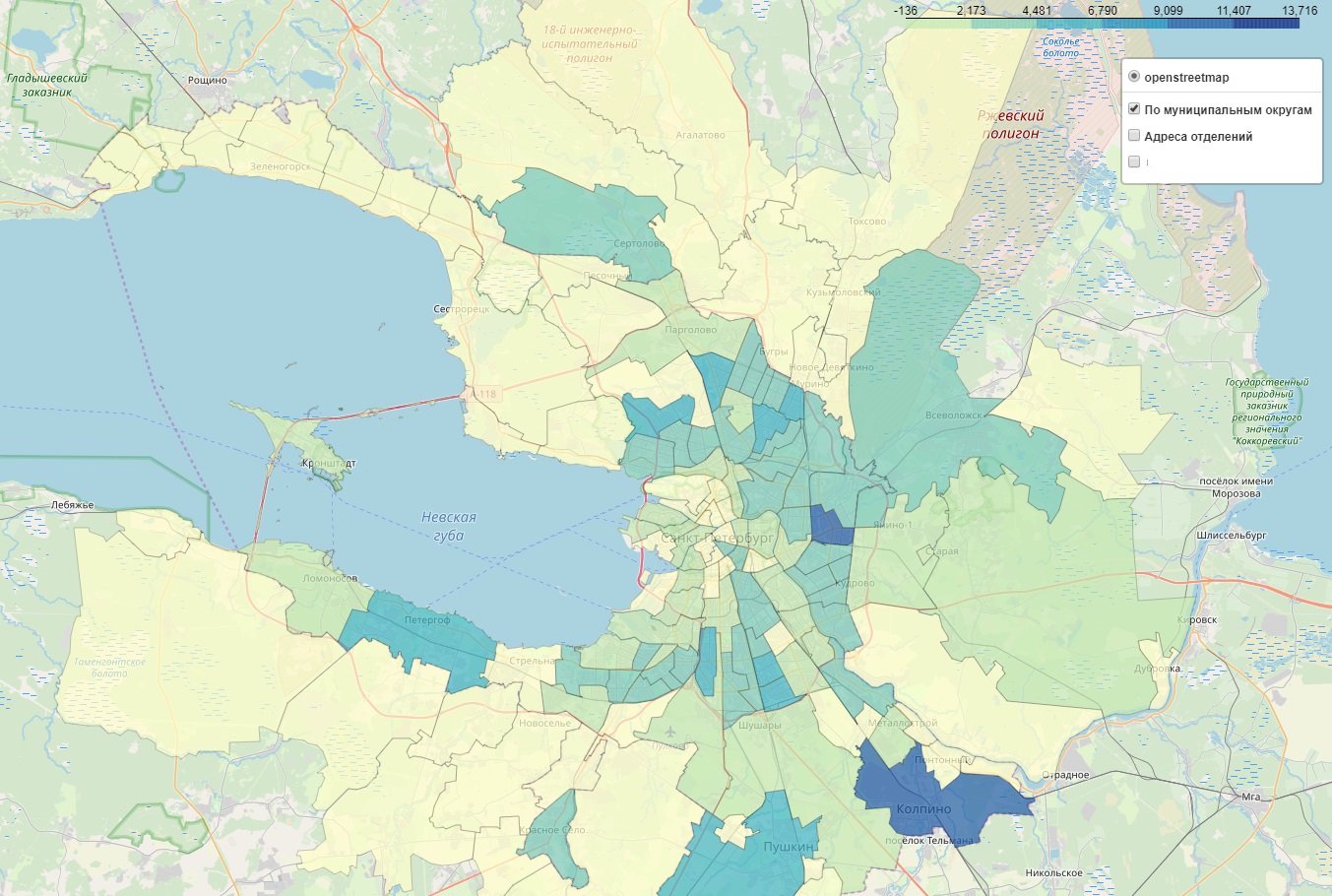

Стоимость недвижимости
Определение цен на недвижимость оказалось непростой задачей. На первом этапе удалось получить все объявления о продаже недвижимости с начала 2018 года — это около 700 тыс. записей.
Для каждого дома стоимость квадратного метра рассчитывалась как медиана по объявлениям. Для 20% домов без объявлений мы оценили стоимость кв. м. с помощью модели. Основной фактор – это цена за кв. м 15 ближайших домов. При этом больший вес получили дома со схожими характеристиками: год постройки, кол-во жильцов, тип проекта. Средняя ошибка модели на тестовом наборе составила 9,5%, что вполне приемлемо для нашего исследования. Особенно, если учесть, что даже в одном доме стоимость кв. м. может сильно разниться: этаж, ремонт, площадь и др. факторы.
Расстояние от дома до филиала
На графике для 4-х отделений видна зависимость доли клиентов в доме от расстояния до отделения. По некоторым филиалам есть сильные скачки, что наталкивает на мысль о влиянии других факторов (возраст дома, цена недвижимости).

Возраст дома
Интересной является зависимость между годом постройки дома и долей клиентов.

Для дальнейшего моделирования возраст дома был разбит на 5 осмысленных категорий:
| Период | Описание |
|---|---|
| 1700-1960 | Старый фонд и сталинки |
| 1960-1990 | Период массовой советской застройки |
| 1990-2000 | Точечная застройка в старых кварталах, много кирпичных домов |
| 2000-2010 | Период экономического подъема. Строится много жилья в хороших локациях |
| 2010-2018 | массовая застройка в менее удачно расположенных и отдаленных районах |
Цена за кв. м.
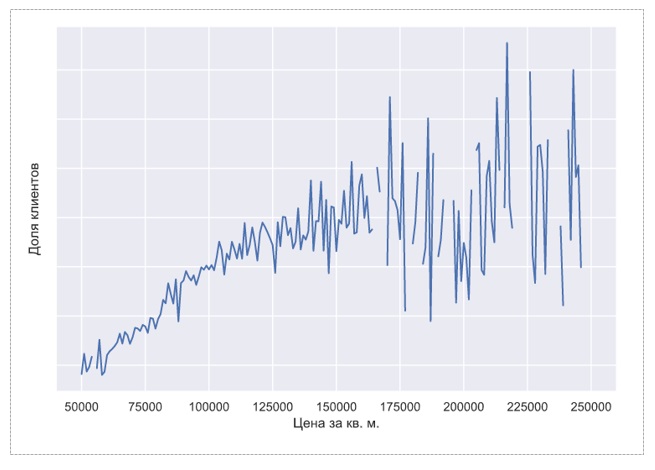
Цена коррелирует с долей клиентов. Но зависимость слабее, чем между долей клиентов и возрастом дома. Возможно, причина в том, что возраст дома коррелирует с возрастом жильцов. А возраст человека сильно влияет на частоту обращений за медицинскими услугами.
Описание модели
В дальнейшем этот анализ развился в полноценную модель, где на входе подаются координаты, а на выходе получается кол-во визитов от новых клиентов. Статья получилась объемная, поэтому расскажу про модель кратко.
Для простоты интерпретации результатов в качестве модели выбрана линейная регрессия. Целевая переменная — доля клиентов в доме, факторы: логарифм расстояния до ближайшего отделения, стоимость жилья, год постройки дома. Все три фактора оказались значимыми и вошли в модель.
Подставляя в такую модель новые координаты (то есть меняя фактор расстояние до ближайшего отделения), на выходе мы получаем новое кол-во клиентов для всей сети. Если вычесть из этого числа кол-во клиентов, которое было до этого, мы получим чистый эффект.
Такая постановка задачи удобна тем, что новые локации выбираются с учетом расположения текущих филиалов. То есть не нужно дополнительно учитывать фактор “каннибализации” между разными отделениями.
Поиск оптимальных точек для всего города производился простым перебором координат через каждые 500 м. Для расчета эффекта от открытия нескольких отделений, точки выставлялись последовательно.
Результаты
Нам удалось заменить настенную карту, на которой вручную рисовали границы округов и что-то считали на удобные интерактивные карты. Избавить сотрудников от ручного исправления и сопоставления с муниципальными округами тысяч адресов. Обогатить данные и перейти с уровня муниципального округа до каждого дома.
Получилось выявить несколько очень перспективных и неочевидных локаций для размещения. Построить модель, которая автоматически и беспристрастно сравнивает различные точки.
Интересные результаты получились при разделении направлений бизнеса на “геозависимые” и “геонезависимые”. Первые должны входить в состав новых филиалов, вторые можно развивать в рамках текущих локаций. (в статье не представлено).
Комментарии (18)

mdyakovaml
20.06.2019 13:42Добрый день! А где вы брали информацию о адресах клиентов? Или ваша модель работает только для текущих и не учитывает потенциальных?

egorborisov Автор
20.06.2019 13:44Добрый день! Клиенты сами называют свои адреса при оформлении. Модель опирается на данные о существующих клиентах и зависимостях которые есть и на этой основе делает прогноз для потенциальных клиентов.
mdyakovaml
20.06.2019 13:52То есть при расчете предсказания для нового места продаж вы учитываете текущих клиентов в этом районе?
egorborisov Автор
20.06.2019 13:55При расчете нового места мы считаем только дополнительный эффект для всей сети. Он не включает в себя текущих клиентов, только новых.
mdyakovaml
20.06.2019 14:04Тогда как вы получаете данные адресов потенциальных клиентов?
egorborisov Автор
20.06.2019 14:10У нас их нет. Но мы знаем для каждого дома численность жителей и долю текущих клиентов. Выставляя новую точку мы пересчитываем долю клиентов для части домов по модели. После этого пересчитываем кол-во клиентов.

gofat
20.06.2019 13:44Какое качество модели получено?
egorborisov Автор
20.06.2019 13:48Сразу, поясню что в этом конкретном случае мы больше ориентировались не на показатели качества, а на субъективное восприятие правильности результата. Но для порядка все считали: R^2 был около 0,8. Дополнительно контроль качества делали так: подставляли координаты текущих филиалов и сравнивали предсказание модели с фактическими данными. Расхождение ±10%, что вполне нас устроило.
sshikov
20.06.2019 20:25А расскажите, как вы координаты получили? У нас была и есть очень похожая задача, и по нашему опыту, если не предпринять специальных больших усилий, типовой процесс геокодирования дает точность в лучшем случае около 75%.
Правда, я вижу некоторые очевидные отличия (поправьте, если ошибаюсь):
— у вас только один город, в нашем случае это была вся Россия, включая мелкие населенные пункты
— 700 тыс это совсем немного. Самая большая наша база была на пару порядков больше.sagaan
20.06.2019 21:41У Вас была база на 70 млн чел? Это же все экономически активное население России.
sshikov
20.06.2019 21:44Где я сказал, что это люди? Это объявления по недвижимости. То есть, это помещения. И там дубли, т.е. объявления — они повторяются время от времени. Уникальных адресов там наверное порядка 15 миллионов, не более.
egorborisov Автор
21.06.2019 09:49+1700 тыс. — это объявления о продаже квартир. Мы получили их уже с координатами. Геокодирование требовалось только для клиентов, там меньше записей. Стандартных средств, таких как API Яндекс карт на такой объем достаточно. Даже с ограничением на 25 000 запросов в сутки. А по поводу точности, видимо сказалось что это Санкт-Петербург и адреса заполнены корректно.
sshikov
21.06.2019 20:18Да, я понял. Была у нас часть таких объявлений тоже. Меньшая, увы.
Насчет Санкт-Петербурга — да, скорее всего, по нашему опыту чем дальше от столичных городов — тем хуже качество геокодирования. Хотя как раз на Санкт-Петербурге у меня тоже сломалось пара инструментов, когда я пытался целиком ФИАС геокодировать — в нем адреса (улицы) были записаны вместе с районом (городом). Ну т.е. такой-то проспект (Петергоф), например. Это напрочь ломает например наш ArcGis с его настройками.
Kbazil
21.06.2019 09:491) Учитывалась только гипотеза, что клиенты ходят из дома? Не проверялась ли гипотеза визита пациентов после работы, соответственно применить модель к районам с офисами и предприятиями? Хотя, полагаю, проблема в доступности информации о месте работы от текущих клиентов.
2) Также учитывается ли фактор конкурентов? То есть у района большой потенциал (дорогие новые дома), но там уже много клиник.
Либо же цель анализа — открыть более удобные филиалы для уже имеющихся клиентов?egorborisov Автор
21.06.2019 09:58+11) Да, вы правы. Есть много других факторов которые влияют на вероятность визита, в том числе место работы. В модели мы их не использовали, потому что таких данных нет. Но есть несколько соображений из которых можно опираться именно на место проживания, как на основной фактор. Пик посещений в течении дня почти во всех отделениях приходится на утро-день. Основная аудитория — это женщины, часто с детьми. То есть можно предположить, что существенная часть аудитории — это неработающие женщины, которым важно именно расстояние от дома.
2) Цель — это и привлечение новой аудитории и удобство для имеющихся клиентов. Но оценку мы делали только по привлеченной новой аудитории. Гипотеза по по поводу конкурентов была, но текущие отделения расположены очень близко с отделениями основных конкурентов. В итоге если добавить этот фактор в модель получается не совсем корректный результат: ближе к конкуренту — лучше. Я попробовал подавать этот фактор в модель в другом виде: как кол-во конкурентов в радиусе, что тоже не дало нужного результата. В итоге этот фактор мы не включали в модель. На картах я сделал отдельный слой с адресами конкурентов.
sagaan
1) Вы исходили из того, что наилучшим местом для открытия филиала будет точка, рядом с которой проживает наибольшее количество потенциальных клиентов. Это, несомненно, лучше, чем выбор места «экспертным методом», но есть одна потенциальная опасность такого подхода.
Ваша точка может оказаться местом, мимо которого никто не ходит. Да, люди могут жить рядом, но их маршруты будут пролегать в других местах.
Например, в районе максимальная плотность проживания потенциальных клиентов может оказаться в стороне от метро или торгового центра, в который эти люди ходят. Или у Вас может быть два компактных жилмассива, разделенных пустырем — не попадет ли модель как раз в этот пустырь?
2) Клиенты клиентам рознь. Пробовали в качестве целевой переменной устанавливать не количество визитов, а размер выручки?
egorborisov Автор
1) Да, конечно, модель и все картинки только дают ориентир. А конечное решение остается за менеджментом. Такие факторы как наличие подходящего помещения, транспортная доступность, парковка учитываются, но на другом этапе.
2) Выручка для на складывается из кол-ва визитов и среднего чека на визит. Мы проанализировали оба показателя в разрезах: цена недвижимости, расстояние до отделения, год постройки. Оказалось что все эти факторы почти не влияют на средний чек и среднее кол-во визитов, поэтому мы отталкивались только от кол-ва клиентов.