
Привет.
Создать такую нейронную сеть — просто.
Этот высокоуровневый урок рассчитан на новичков в машинном обучении и искусственном интеллекте. Для того, чтобы успешно создать нейронную сеть, необходимо:
Мы пропустим много деталей работы нейронной сети, не будем углубляться в теоретическую часть, а сфокусируемся на предсказании рака за 5 минут.

Для построения предсказаний будем использовать имплементацию нейронной сети из библиотеки
Если у вас не установлена библиотека
Откройте среду разработки и создайте новый файл под названием, например,
Ссылки на документации используемых методов и датасетов
Прежде чем приступить к обучению нейронной сети на датасете, необходимо обработать данные. Для начала загрузим данные и выделим в
Теперь мы разделяем данные на тренировочные (для обучения нейронной сети) и тестовые (для проверки корректности ее работы). Тренировочный набор данных состоит из
Теперь, когда наши данные разделены на обучающий и тестовый сеты, мы можем обучить нашу нейронную сеть! Для начала нужно создать нейронную сеть с многослойным перцептроном. Затем обучаем её на наших данных при помощи функции
Попробуйте запустить нейронную сеть через терминал командой
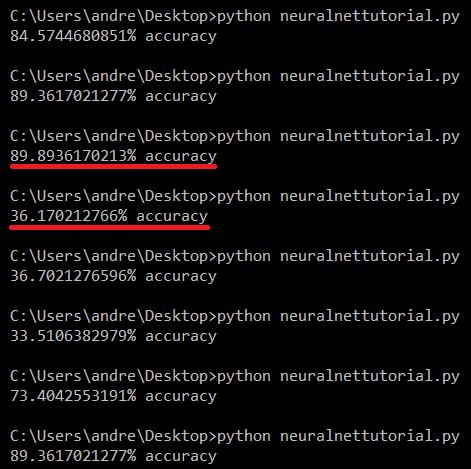
Результаты работы классификатора
Есть вероятность, что разница в измерениях точности нейронной сети будет большой. Когда мы разделяли данные на обучающий и тестовый сеты, данные были перемешаны случайно, что и объясняет изменения результатов. В нашем датасете всего лишь 569 объектов, и модель обучается на 379 его объектах-представителях, что приводит к переобучению, так как данных слишком мало.
К тому же мы создавали нейронную сеть при помощи конструктора
Мы можем исправить ситуацию либо обучая сеть на большем наборе данных, либо настраивая параметры датасета.
Я выбрал второй вариант и переключил solver с
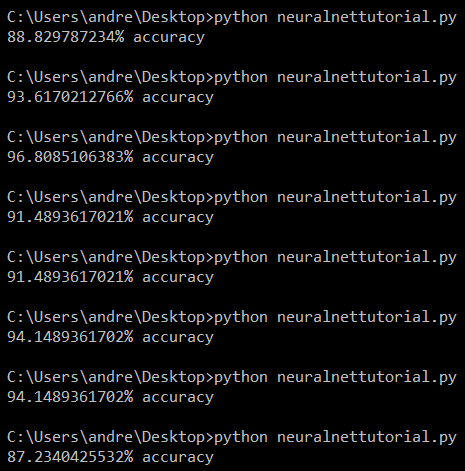
Результаты работы оптимизированного классификатора
Теперь это выглядит гораздо лучше! Точность до сих пор не так высока, как хотелось бы, однако разница между показателями значительно уменьшилась. И это не все изменения, которые можно было бы сделать. Вы можете разобраться в документации и продолжить процесс оптимизации.
То, чему мы научились, применимо к любому датасету и к любому алгоритму машинного обучения, реализованному в
Если вы заинтересовались машинным обучением, то в интернете имеется множество курсов на эту тему, например, на Coursera, которые помогут разобраться в работе алгоритмов.
Успехов! Всем знаний!
Создать такую нейронную сеть — просто.
Минута первая: введение
Этот высокоуровневый урок рассчитан на новичков в машинном обучении и искусственном интеллекте. Для того, чтобы успешно создать нейронную сеть, необходимо:
- Установленный Python;
- Как минимум начальный уровень программирования;
- Пять минут свободного времени.
Мы пропустим много деталей работы нейронной сети, не будем углубляться в теоретическую часть, а сфокусируемся на предсказании рака за 5 минут.
Для построения предсказаний будем использовать имплементацию нейронной сети из библиотеки
scikit-learn. Сами же предсказания будут основаны на данных из датасета Калифорнийского университета в Ирвайн “Breast Cancer Wisconsin” (рак груди, Висконсин). На вход нейронной сети подаются свойства клеточных ядер новообразования (например, строение), а на выходе мы получаем предсказание: злокачественное или доброкачественное новообразование.Минута вторая: начало работы
Если у вас не установлена библиотека
scikit-learn, то запустите команду pip install scikit-learn в терминале, которая установит библиотеку и все её зависимости.Откройте среду разработки и создайте новый файл под названием, например,
neuralnet.py. Теперь мы загрузим имплементацию нейронной сети, обучающие данные и функцию для разделения наших данных на тренировочный и тестовый наборы для нейронной сети.# Имплементация нейронной сети
from sklearn.neural_network import MLPClassifier
# Функция для загрузки датасета
from sklearn.datasets import load_breast_cancer
# Функция для разделения датасета
from sklearn.model_selection import train_test_split
Ссылки на документации используемых методов и датасетов
scikit-learn:- Документация датасета с данными о раке груди (
load_breast_cancer) - Документация для функции предобработки данных (
train_test_split) - Документация для имплементации нейронной сети (
MLPClassifier)
Минута третья: предварительная обработка
Прежде чем приступить к обучению нейронной сети на датасете, необходимо обработать данные. Для начала загрузим данные и выделим в
attributes свойства новообразований (двумерный список, содержащий численные значения), а в labels?—?целевые переменные, метки злокачественности или доброкачественности новообразования (список из нулей и единиц). Содержимое каждого из списков соответствует содержимому другого списка под тем же индексом, то есть, к примеру, labels[0] определяет значение целевой переменной для признаков, хранящихся в attributes[0].data = load_breast_cancer() # Загружаем и сохраняем датасет
attributes = data.data # Свойства клеточных ядер
labels = data.target # Метки злокачественности
Теперь мы разделяем данные на тренировочные (для обучения нейронной сети) и тестовые (для проверки корректности ее работы). Тренировочный набор данных состоит из
attributes_train и labels_train, тестовый?—?из attributes_test и labels_test. Треть наших данных будет составлять тестовый сет, оставшиеся две трети? —? обучающий.attributes_train, attributes_test, labels_train, labels_test = train_test_split(attributes, labels, test_size=0.33)
Минута четвёртая: нейронная сеть
Теперь, когда наши данные разделены на обучающий и тестовый сеты, мы можем обучить нашу нейронную сеть! Для начала нужно создать нейронную сеть с многослойным перцептроном. Затем обучаем её на наших данных при помощи функции
fit, измеряем её точность при помощи функции score и выводим эту точность.neuralnet = MLPClassifier() # Инициализация нейронной сети
neuralnet.fit(attributes_train, labels_train) # Обучение сети
accuracy = neuralnet.score(attributes_test, labels_test) # Измерение точности работы сети
print(str(accuracy * 100) + "% accuracy") # Вывод значения точности в процентах
Попробуйте запустить нейронную сеть через терминал командой
python neuralnet.py примерно десять раз (можете заменить neuralnet.py на название вашего скрипта) и сравните результаты.Минута пятая: оптимизация результата
Результаты работы классификатора
Есть вероятность, что разница в измерениях точности нейронной сети будет большой. Когда мы разделяли данные на обучающий и тестовый сеты, данные были перемешаны случайно, что и объясняет изменения результатов. В нашем датасете всего лишь 569 объектов, и модель обучается на 379 его объектах-представителях, что приводит к переобучению, так как данных слишком мало.
К тому же мы создавали нейронную сеть при помощи конструктора
neuralnet = MLPClassifier(), которому не передали ни одного аргумента. Это значит, что сеть была построена с использованием параметров по умолчанию, то есть, она не оптимизирована.Мы можем исправить ситуацию либо обучая сеть на большем наборе данных, либо настраивая параметры датасета.
Я выбрал второй вариант и переключил solver с
adam (по умолчанию) наlbfgs. В документации было сказано, что этот параметр позволяет оптимизировать сеть на маленьких наборах данных. Также я изменил активационную функцию с relu на logistic и экспериментальным путём установил, что значения alpha от 0.0001 до 10.0 предотвращают переобучение.# Замените предыдущую строку инициализации нейронной сети на эту
neuralnet = MLPClassifier(solver='lbfgs', activation='logistic', alpha=10.0)
Результаты работы оптимизированного классификатора
Теперь это выглядит гораздо лучше! Точность до сих пор не так высока, как хотелось бы, однако разница между показателями значительно уменьшилась. И это не все изменения, которые можно было бы сделать. Вы можете разобраться в документации и продолжить процесс оптимизации.
Заключение
То, чему мы научились, применимо к любому датасету и к любому алгоритму машинного обучения, реализованному в
scikit-learn. Я выбрал нейронную сеть для предсказания рака груди, потому что эти две темы сейчас являются одними из самых обсуждаемых в сфере точных наук.Если вы заинтересовались машинным обучением, то в интернете имеется множество курсов на эту тему, например, на Coursera, которые помогут разобраться в работе алгоритмов.
Успехов! Всем знаний!