
Если мы исследуем коинтеграцию чисто теоретически, то легко доказать, что если ряд коинтегрирован с , то и ряд коинтегрирован с . Однако если мы начнём исследовать коинтеграцию эмпирически, окажется, что теоретические выкладки подтверждаются не всегда. Почему так происходит?
Симметричность
Отношение называется симметричным, если , где — обратное отношение, определяемое условием: равносильно . Иначе говоря, если выполнено соотношение , то выполнено и соотношение .
Рассмотрим два ряда и , . Коинтеграция симметрична, если влечёт , то есть если наличие прямой регрессии ведёт к наличию обратной.
Рассмотрим уравнение , . Поменяем левую и правую часть местами и вычтем из обоих частей: . Так как по определению, разделим обе части на :
Заменим на , а на , получим . Следовательно, отношение коинтеграции является симметричным.
Отсюда следует, что если переменная коинтегрирована с переменной , то переменная должна быть коинтегрирована с переменной . Однако тест Энгла-Грэнджера для коинтеграции не всегда подтверждает это свойство симметричности, поскольку иногда переменная не коинтегрирована с переменной в соответствии с этим тестом.
Я тестировала свойство симметричности на данных 2017 года Московской и Нью-Йоркской бирж с помощью теста Энгла-Грэнждера. На Московской бирже было 7975 коинтегрированных пар акций. Для 7731 (97%) коинтегрированных пар свойство симметричности подтвердилось, для 244 (3%) коинтегрированных пар свойство симметричности не подтвердилось.
На Нью-Йоркской бирже было 140903 коинтегрированные пары акций. Для 136586 (97%) коинтегрированных пар свойство симметричности подтвердилось, для 4317 (3%) коинтегрированных пар свойство симметричности не подтвердилось.
Интерпретация
Данный результат можно интерпретировать низкой мощностью и высокой вероятностью ошибки второго рода теста Дики-Фуллера, на котором основан тест Энгла-Грэнджера. Вероятность ошибки второго рода можно обозначить через , тогда величину называют мощностью теста. К сожалению, тест Дики-Фуллера не способен различить нестационарные и около-нестационарные временные ряды.
Что такое около-нестационарный временной ряд? Рассмотрим временной ряд . Стационарным временным рядом называется такой ряд, в котором . Нестационарным временным рядом называется такой ряд, в котором . Около-нестационарным временным рядом называется такой ряд, в котором значение близко к единице.
В случае около-нестационарных временных рядов мы часто не способны отклонить нулевую гипотезу нестационарности. Это означает, что у теста Дики-Фуллера высокий риск ошибки второго рода, то есть вероятность не отклонить ложную нулевую гипотезу.
Тест KPSS
Возможным ответом на слабость теста Дики-Фуллера является тест KPSS, который обязан своим названием инициалам учёных Квятковского, Филлипса, Шмидта и Шина. Хотя методический подход этого теста полностью отличается от подхода Дики-Фуллера, главное различие следует понимать в перестановке нулевой и альтернативной гипотез.
В тесте KPSS нулевая гипотеза утверждает, что временной ряд является стационарным, против альтернативной о наличии нестационарности. Около-нестационарные временные ряды, которые с помощью теста Дики-Фуллера часто выявлялись как нестационарные, с помощью теста KPSS могут быть корректно выявлены как стационарные.
Однако мы должны сознавать, что любые результаты статистического тестирования являются всего лишь теоретико-вероятностными, и их не следует путать с неким истинным суждением. Всегда существует ненулевая вероятность, что мы ошибаемся. По этой причине в качестве идеального тестирования на нестационарность предлагается объединение результатов тестов Дики-Фуллера и KPSS.
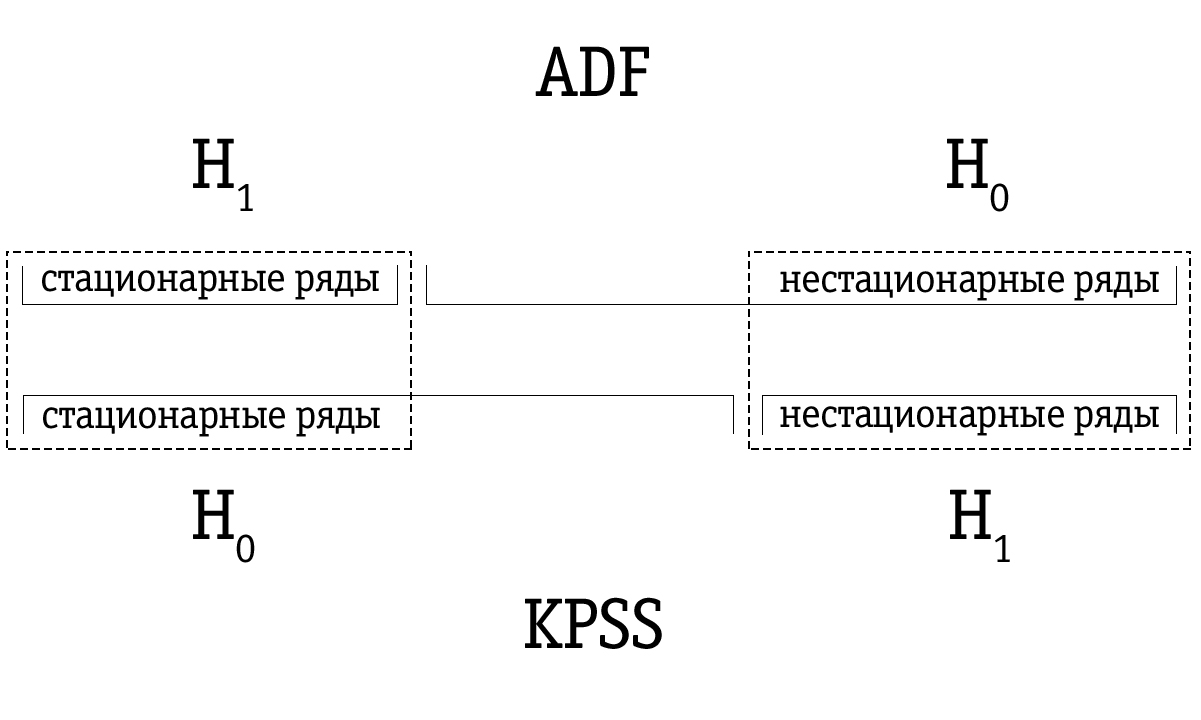
Из-за низкой мощности тест Дики-Фуллера часто ошибочно выявляет ряд как нестационарный, поэтому результирующее множество временных рядов, выявленных тестом Дики-Фуллера как нестационарные, оказывается больше по сравнению с множеством временных рядов, выявленных как нестационарные с помощью теста KPSS. Следовательно, порядок тестирования важен.
Если временной ряд выявлен как стационарный с помощью теста Дики-Фуллера, то он, скорее всего, будет также выявлен как стационарный и с помощью теста KPSS; в таком случае мы можем предполагать, что ряд и в самом деле стационарный.
Если временной ряд был выявлен как нестационарный с помощью теста KPSS, то он, скорее всего, будет также выявлен как нестационарный и с помощью теста Дики-Фуллера; в таком случае мы можем предполагать, что ряд и в самом деле нестационарный.
Однако часто случается, что временной ряд, который был выявлен как нестационарный с помощью теста Дики-Фуллера, будет отмечен как стационарный с помощью теста KPSS. В таком случае мы должны быть очень осторожны с нашим окончательным заключением. Мы можем проверить, насколько сильно основание для стационарности в случае теста KPSS и для нестационарности в случае теста Дики-Фуллера и принять соответствующее решение. Конечно, мы также можем оставить вопрос о стационарности такого временного ряда нерешённым.
Подход теста KPSS предполагает, что временной ряд , тестируемый на стационарность относительно тренда, может быть разложен на сумму детерминированного тренда , случайного блуждания и стационарной ошибки :
где — нормальный i.i.d. процесс с нулевым средним и дисперсией (). Начальное значение трактуется как фиксированное и играет роль свободного члена. Стационарная ошибка может быть сгенерирована любым общим ARMA процессом, то есть, может иметь сильную автокорреляцию.
Аналогично тесту Дики-Фуллера возможность учитывать произвольную структуру автокорреляции очень важна, потому что большинство экономических временных рядов сильно зависят от времени и, следовательно, имеют сильную автокорреляцию. Если мы хотим проверить стационарность относительно горизонтальной оси, то член просто исключается из уравнения выше.
Из уравнения выше следует, что нулевая гипотеза о стационарности эквивалентна гипотезе , из которой следует, что для всех ( — константа). Аналогично, альтернативная гипотеза о нестационарности эквивалентна гипотезе .
Чтобы протестировать гипотезу : (стационарный временной ряд) против альтернативной : (нестационарный временной ряд) авторы теста KPSS получают одностороннюю статистику теста множителей Лагранжа. Они также вычисляют его асимптотическое распределение и моделируют асимптотические критические значения. Теоретические детали мы здесь не рассматриваем, а только кратко изложим алгоритм выполнения теста.
При выполнении теста KPSS для временного ряда , используется метод наименьших квадратов (МНК), чтобы оценить одно из следующих уравнений:
Если мы хотим проверить стационарность относительно горизонтальной оси, мы оцениваем первое уравнение. Если мы планируем проверить стационарность относительно тренда, мы выбираем второе уравнение.
Остатки из оценённого уравнения используются для вычисления статистики теста множителей Лагранжа. Тест множителей Лагранжа основан на идее, что при выполнении нулевой гипотезы все множители Лагранжа должны быть равны нулю.
Тест множителей Лагранжа
Тест множителей Лагранжа связан с более общим подходом к оценке параметров методом максимального правдоподобия (ML). Согласно этому подходу данные рассматриваются как свидетельство, относящееся к параметрам распределения. Свидетельство выражается как функция неизвестных параметров – функция правдоподобия:
где — наблюдаемые значения, а — параметры, которые мы хотим оценить.
Функция максимального правдоподобия представляет собой совместную вероятность наблюдений выборки
Цель метода максимального правдоподобия состоит в максимизации функции правдоподобия. Это достигается дифференцированием функции максимальной вероятности по каждому из оцениваемых параметров и приравниванием частных производных к нулю. Значения параметров, при которых значение функции максимально, и является искомой оценкой.
Обычно для упрощения последующей работы сначала берётся логарифм функции правдоподобия.
Рассмотрим обобщённую линейную модель , где предполагается, что нормально распределены , то есть .
Мы хотим проверить гипотезу о том, что выполнена система () независимых линейных ограничений . Здесь — известная матрица ранга , а – известный вектор.
Для каждой пары наблюдаемых значений и будет существовать при условии нормальности функция плотности вероятностей следующего вида:
При условии совместных наблюдений и общая вероятность наблюдений всех значений в выборке равна произведению индивидуальных значений функции плотности вероятности. Таким образом, функция правдоподобия задаётся следующим образом:
Поскольку легче дифференцировать сумму, чем произведение, то обычно берётся логарифм функции правдоподобия, таким образом:
Это полезное преобразование не влияет на конечный результат, потому что — это возрастающая функция . Таким образом, то значение , которое максимизирует , также будет максимизировать .
ML-оценка для в регрессии с ограничением () получается максимизацией функции при условии . Чтобы найти эту оценку, запишем функцию Лагранжа:
где через обозначен вектор множителей Лагранжа.
Статистика теста множителей Лагранжа, обозначаемая через в случае стационарности относительно горизонтальной оси и через в случае стационарности относительно тренда, определяется выражением
где
и
где
В приведённых выше уравнениях — процесс частичной суммы остатков от оценённого уравнения; — оценка долгосрочной дисперсии остатков ; а — так называемое спектральное окно Бартлетта, где — параметр усечения лага.
В данном приложении спектральное окно используется для оценки спектральной плотности ошибок для определённого интервала (окна), который перемещается по всему диапазону ряда. Данные за пределами интервала игнорируются, так как оконная функция является функцией, равной нулю вне некоторого выбранного интервала (окна).
Оценка дисперсии зависит от параметра , а так как увеличивается и больше 0, оценка начинает учитывать возможную автокорреляцию в остатках .
Наконец, статистика теста множителей Лагранжа или сравнивается с критическими значениями. Если статистика теста множителей Лагранжа превышает соответствующее критическое значение, то нулевая гипотеза (стационарный временной ряд) отклоняется в пользу альтернативной гипотезы (нестационарный временной ряд). В противном случае мы не можем отвергнуть нулевую гипотезу о стационарности временного ряда.
Критические значения являются асимптотическими и, следовательно, наиболее подходят для выборки большого размера. Тем не менее, на практике они также используются и для небольшой выборки. Более того, критические значения не зависят от параметра . Однако статистика теста множителей Лагранжа будет зависеть от параметра . Авторы теста KPSS не предлагают какой-либо общий алгоритм для выбора соответствующего параметра . Обычно тест выполняется для в диапазоне от 0 до 8.
При увеличении мы с меньшей вероятностью отвергаем нулевую гипотезу о стационарности, что частично приводит к снижению мощности теста и может дать неоднозначные результаты. Однако, в целом, можно сказать, что если нулевая гипотеза о стационарности временного ряда не отвергается даже при малых значениях (0, 1 или 2), мы заключаем, что проверенные временные ряды являются стационарными.
Сравнение результатов тестов
Для оценки вероятности симметричности была разработана следующая методология.
- Все временные ряды проверяются на интегрируемость 1-го порядка с помощью теста Дики-Фуллера на уровне значимости 0,05. Далее рассматриваются только интегрируемые ряды 1-го порядка.
- Из интегрируемых рядов 1-го порядка, полученных в п. 1, составляются пары путём сочетания без повторений.
- Пары акций, составленные в п. 2, тестируются на коинтеграцию с помощью теста Энгла-Грэнджера. В результате выявляются коинтегрированные пары.
- Остатки от регрессии, полученные в результате тестирования в п. 3, тестируются на стационарность с помощью теста KPSS. Таким образом, результаты двух тестов объединяются.
- Временные ряды в коинтегрированных парах из п. 2 переставляются местами и снова проверяются на коинтеграцию с помощью теста Энгла-Грэнджера, то есть мы исследуем, является ли отношение между временными рядами симметричным.
- Временные ряды в коинтегрированных парах из п. 4 переставляются местами и остатки от регрессии снова проверяются на стационарность с помощью теста KPSS, то есть мы исследуем, является ли отношение между временными рядами симметричным.
Все вычисления выполняются с использованием пакета MATLAB. Результаты представлены в таблице ниже. Для каждого теста у нас есть количество отношений, которые являются симметричными по результатам теста (отмечены ); у нас есть количество отношений, которые не являются симметричными по результатам теста (отмечены ); и у нас есть эмпирическая вероятность того, что отношение является симметричным по результатам теста ().
На Московской бирже:
| Тест | ADF | ADF + KPSS |
|---|---|---|
| 7731 | 16 | |
| 244 | 1 | |
| 97% | 94% |
На Нью-Йоркской бирже:
| Тест | ADF | ADF + KPSS |
|---|---|---|
| 136586 | 182 | |
| 4317 | 7 | |
| 97% | 96% |
Сравнение результатов бэктестов
Давайте сравним результаты торговой стратегии на исторических данных для коинтегрированных пар, отобранных с помощью теста Энгла-Грэнджера, и для коинтегрированных пар, отобранных с помощью теста KPSS.
| Критерии | ADF | ADF + KPSS |
|---|---|---|
| Количество симметричных пар | 6417 | 205 |
| Максимальная прибыль | 340,31% | 287,35% |
| Максимальный убыток | -53,28% | -46,35% |
| Пар торговалось в плюс | 2904 | 113 |
| Пар торговалось в ноль | 293 | 3 |
| Пар торговалось в минус | 3220 | 89 |
| Среднегодовая доходность | 13,51% | 22,72% |
Как можно видеть из таблицы, благодаря более точной идентификации коинтегрированных пар акций, удалось увеличить среднегодовую доходность при торговле отдельной коинтегрированной парой на 9,21%. Таким образом, предложенная методология может увеличить прибыльность алгоритмической торговли при использовании рыночно-нейтральных стратегий.
Альтернативная интерпретация
Как мы видели выше, результаты теста Энгла-Грэнджера — это лотерея. Кому-то мои мысли покажутся излишне категоричными, но я считаю, что есть большой смысл не принимать на веру нулевую гипотезу, подтверждённую статистическим анализом.
Консерватизм научного метода проверки гипотез заключается в том, что при анализе данных мы можем сделать лишь одно правомочное заключение: нулевая гипотеза отклоняется на выбранном уровне значимости. Это не означает, что верна альтернатива — просто мы получили косвенное свидетельство её правдоподобия на основании типичного «доказательства от противного». В случае, когда верна , исследователю также предписывается сделать лишь осторожное заключение: на основе данных, полученных в условиях эксперимента, не удалось обнаружить достаточно доказательств, чтобы отклонить нулевую гипотезу.
В унисон моим мыслям в сентябре 2018-го года вышла статья, написанная влиятельными людьми и призывающая отказаться от понятия «статистическая значимость» и парадигмы тестирования нулевой гипотезы.
Самое главное: «Такие предложения, как изменение уровня порогового -значения по умолчанию, использование доверительных интервалов с акцентом на том, содержат они ноль или нет, или использование коэффициента Байеса наряду с повсеместно принятыми классификациями для оценки силы доказательств, которые исходят от всё тех же или подобных проблем, что и текущее использование -значений с уровнем 0,05… представляют собой форму статистической алхимии, которая делает ложное обещание преобразовать случайность в достоверность, так называемое „отмывание неопределенности“ (Gelman, 2016), которое начинается с данных и заканчивается дихотомическими выводами об истинности или ложности — бинарными утверждениями о том, что „есть эффект“ или „нет эффекта“ — на основе достижения некоторого -значения или другого порогового значения.
Критическим шагом вперёд станет принятие неопределенности и вариативности эффектов (Carlin, 2016; Gelman, 2016), признание того, что мы можем узнать больше (намного больше) о мире, отказавшись от ложного обещания определенности, предлагаемой такой дихотомизацией.»
Выводы
Мы увидели, что хотя свойство симметричности отношения коинтеграции, теоретически, должно выполняться, экспериментальные данные расходятся с теоретическими выкладками. Один из вариантов интерпретации данного парадокса — низкая мощность теста Дики-Фуллера.
В качестве новой методологии выявления коинтегрированных пар активов было предложено тестировать остатки от регрессии, полученные с помощью теста Энгла-Грэнджера, на стационарность с помощью теста KPSS и объединять результаты данных тестов; а также объединять результаты теста Энгла-Грэнджера и теста KPSS как для прямой, так и для обратной регрессии.
Были проведены бэктесты на данных Московской биржи за 2017 год. По результатам бэктестов, среднегодовая доходность при использовании предложенной выше методологии идентификации коинтегрированных пар акций составила 22,72%. Таким образом, по сравнению с идентификацией коинтегрированных пар акций с помощью теста Энгла-Грэнджера, удалось увеличить среднегодовую доходность на 9,21%.
Альтернативный вариант интерпретации парадокса — не принимать на веру нулевую гипотезу, подтверждённую статистическим анализом. Парадигма тестирования нулевой гипотезы и дихотомия, предлагаемая такой парадигмой, даёт нам ложное ощущение знания рынка.
Когда я только начинала свои исследования, мне казалось, что можно взять рынок, засунуть его в «мясорубку» статистических тестов и на выходе получить отфильтрованные вкусные ряды. К сожалению, сейчас я вижу, что эта концепция статистического брутфорса не сработает.
Есть ли на рынке коинтеграция или нет — для меня этот вопрос остаётся открытым. Большие вопросы у меня остаются и к родоначальникам этой теории. Раньше у меня был какой-то трепет перез Западом и теми учёными, которые развивали финансовую математику в то время, когда в Советском Союзе эконометрика считалась продажной девкой буржуазии. Мне казалось, что мы очень сильно отстали, и где-то там в Европе и Америке сидят боги финансов, которые познали священный грааль истины.
Сейчас я понимаю, что европейские и американские учёные мало чем отличаются от наших, разница только в масштабе шарлатанства. Наши учёные сидят в замке из слоновой кости, пишут какую-то ахинею и получают за это гранты размером 500 тысяч рублей. На Западе сидят примерно такие же учёные в примерно таком же замке из слоновой кости, пишут примерно такую же ахинею и получают за это «нобелевки» и гранты размером 500 тысяч долларов. Вот и вся разница.
На данный момент у меня нет однозначного взгляда на предмет моего исследования. Апеллировать к тому, что «все хедж-фонды используют торговлю парами» я считаю неправильным, потому что большинство хедж-фондов точно так же прекрасно банкротится.
К сожалению, думать и принимать решения всегда приходится своей головой, особенно когда мы рискуем деньгами.
Комментарии (9)

hannimed
01.07.2019 16:42Очень интересный вывод. По-этому, принято считать рынок марковским процессом. Это приводит нас к тому, что исторические данные не особо нужны, т.к. мы их можем генерировать, используя логнормальное распределение.
AdrenaLeen Автор
01.07.2019 20:35Это очень спорно. Во-первых, случайное блуждание, которое красной нитью проходит через всё моё исследование — это и есть, по сути, марковский процесс. Во-вторых, нет какой-то единой принятой модели рынка, и нельзя считать, что рынок — это марковский процесс. Это всего лишь гипотеза.
В-третьих, исторические данные нужны, потому что рынок не всегда ведёт себя логнормально, и, занимаясь лишь имитационным моделированием и используя лишь сгенерированные данные, мы, к сожалению, очень сильно отходим от реальности.
Проблема реального рынка — это толстые хвосты, которых никогда не будет ни в нормальном, ни в логнормальном распределении: ситуация, когда очень редко, но метко цена делает резкий скачок вверх или вниз. К сожалению, такие вещи марковскими процессами никак не моделируются, а на графиках они видны очень и очень хорошо.
Более ушлые и модные кванты не используют для моделирования рынка нормальные и логнормальные распределения, они примешивают к марковским процессам модели типа диффузионных скачков и модели с распределением Лапласа.hannimed
01.07.2019 21:20Да, я согласен, что это гипотеза. Про диффузионные скачки и модели Лапласа, я пока не читал, спасибо за наводку! Надо обязательно ознакомиться.
И все же хотелось бы отметить, что генерация прибыли возможна, но на мой взгляд ни сколько из поиска корреляций, сколько из возможностей арбитража. Когда базовый актив и производные инструменты от него не правильно оценены.
fivehouse
01.07.2019 17:37Автор честен и последователен. Молодец. И подтверждает мою идею о том, что подобные статьи обычно появляются тогда, когда есть некоторые теоретические результаты, но нет практических.
Мы увидели, что хотя свойство симметричности отношения коинтеграции, теоретически, должно выполняться, экспериментальные данные расходятся с теоретическими выкладками.
К сожалению, думать и принимать решения всегда приходится своей головой, особенно когда мы рискуем деньгами.
abramov231
02.07.2019 00:16+1Когда я только начинала свои исследования, мне казалось, что можно взять рынок, засунуть его в «мясорубку» статистических тестов и на выходе получить отфильтрованные вкусные ряды. К сожалению, сейчас я вижу, что эта концепция статистического брутфорса не сработает.
Кажется Фейнман про это хорошо написал, что математика не даёт точных знаний как устроен мир, а только позволяет находить гипотезы. И гипотезой называется не то, что раз эти две акции 100 лет показывали корелляцию 0.99999, то и на 101-й будут (это не суть процесса), а, например, себестоимость продукции этой компании зависит от цен на литий, а такая то компания его производит и это составляет 70% её выручки, поэтому пока технологический процесс не изменился (привет черный лебедь) они будут кореллировать. А дальше в лучших традициях неопозитивизма пытаетесь поставить эксперимент, который эти гипотезы опровергает, на новых, а лучше будущих данных. Это если по научному, а то что фонды с цифрами делают это выдавание желаемого за действительное.
robomakerr
02.07.2019 13:38Есть ли на рынке коинтеграция или нет — для меня этот вопрос остаётся открытым.
Коинтеграция возможна (но не обязательна) там, где пара имеет общую физическую природу, например Сбер ао — Сбер ап, или акции производителей одного и того же товара.
Математика лишь инструмент.
malkovsky
Вы не первая и не последняя. «Тот, кто считает, что математика сложна, просто не осознает всю сложность жизни» (с).
Если вам интересно мнение человека, который немного в математике разбирается, то, как мне кажется, ваша проблема в том, что вы не осознаете, что статистические методы — это инструменты. Если вы пытаетесь съесть суп молотком — это не проблема молотка.
А вы знаете, что гражданин СССР тоже получил «нобелевку» по экономике? И его работы признают не только в экономике. В общем, такие заявления следует делать после того, как получите свою «нобелевку», а лучше никогда, ну или хотя бы не на хабре.
AdrenaLeen Автор
Замечу, что так называемая Нобелевская премия по экономике — это не Нобелевская премия, а премия Шведского национального банка по экономическим наукам памяти Альфреда Нобеля. Просто шведский банк решил давать призы за самодеятельность по экономике и распиарил это событие как нечто фантастически крутое.
Я тоже раньше попалась на эту удочку. Думала, что раз кому-то дали «нобелевку» по экономике, значит, это очень уважаемое и правдоподобное исследование, а автор, безусловно, заслуживает самого пристального внимания. На самом деле нет. Нобелевок всего пять: по физике, химии, медицине, литературе и содействию установления мира. Всё остальное — это профанация и пускание пыли в глаза.
Nashev
Ну, премии разные бывают… Не вижу причин, почему кому-то ещё невозможно вести себя столь же ответственно, как Нобелевскому комитету, и заработать обоснованную репутацию уважаемой премии. Примазываться шведскому банку к чужой славе могло бы быть стыдно, но это мало что говорит об уровне их скурпулёзности в оценке лауреатов. С другой стороны, собственно сама Нобелевская — тоже не с идеальной репутацией. Особенно, если смотреть про дело установления мира…