
Сегодня компания Google анонсировала черновик RFC стандарта Robots Exclusion Protocol (REP), попутно сделав доступным свой парсер файла robots.txt под лицензией Apache License 2.0. До сегодняшнего дня какого-либо официального стандарта для Robots Exclusion Protocol (REP) и robots.txt не существовало (ближайшим к нему было вот это), что позволяло разработчикам и пользователям интерпретировать его по-своему. Инициатива компании направлена на то, чтобы уменьшить различия между реализациями.
Черновик нового стандарта можно просмотреть на сайте IETF, а репозиторий доступен на Github по ссылке https://github.com/google/robotstxt.
Парсер представляет собой исходный код, который Google используют в составе своих продакшн-систем (за исключением мелких правок — вроде убранных заголовочных файлов, используемых только внутри компании) — парсинг файлов robots.txt осуществляется именно так, как это делает Googlebot (в том числе то, как он обращается с Юникод-символами в паттернах). Парсер написан на С++ и по сути состоит из двух файлов — вам потребуется компилятор, совместимый с C++11, хотя код библиотеки восходит к 90-ым, и вы встретите в ней «сырые» указатели и strbrk. Для того, чтобы его собрать, рекомендуется использовать Bazel (поддержка CMake планируется в ближайшем будущем).
Сама идея robots.txt и стандарта принадлежит Мартейну Костеру, который создал его в 1994 году — по легенде, причиной тому стал поисковый паук Чарльза Стросса, который «уронил» сервер Костера при помощи DoS-атаки. Его идея была подхвачена другими и быстро стала стандартом де-факто для тех, кто занимался разработкой поисковых систем. Тем же, кто хотел заниматься его парсингом, иногда приходилось заниматься реверс-инженирингом работы Googlebot — в их числе компания Blekko, написавшая для своей поисковой системы собственный парсер на Perl.
В парсере не обошлось и без забавных моментов: взгляните к примеру на то, сколько труда пошло на обработку «disallow».
Комментарии (44)


xPomaHx
02.07.2019 01:50+2А почему проблемы индейцев волнуют шерифа? ведь гугл мог бы улучить поиск если бы парсил вообще всё. Они протсо пытаются казаться добыми или там есть какие то юридические тонкости, и еще есть ли поисковики игнорирующие робот.тхт?

tendium
02.07.2019 08:32+1Я не знаю, как сейчас, но в былые времена даже при наличии запрета в robots.txt, если есть большое количество ссылок на ресурс, он таки показывался в выдаче (хотя в description было написано что-то вроде «description is not available»).

xpert13
02.07.2019 09:26+3robots.txt запрещает индексировать страницу, но не запрещает помещать эту страницу в выдачу. Сам недавно только узнал об этом, когда часть запрещенных страниц попала в выдачу.
ua30
02.07.2019 09:27+2Вы так говорите об этом, будто это что то секретное.
support.google.com/webmasters/answer/7440203#indexed_though_blocked_by_robots_txt
support.google.com/webmasters/answer/6062608tendium
02.07.2019 09:46Из какой части моего предложения вы сделали вывод, что я это воспринимаю, как секретное? За ссылки спасибо.

gasizdat
02.07.2019 08:50+1Скорее это защита самих краулеров от спама. Бывают ведь страницы с бесконечным содержимым, типа календариков на все года.

saboteur_kiev
02.07.2019 16:08robots.txt это не про безопасность, это про оптимизацию и релевантность.
Правила всегда могут измениться в одностороннем порядке.
demimurych
07.07.2019 03:09Расскажите мне пожалуйста,
про какую релевантность идет речь в robotx.txt
а на закуску мне объясните про оптимизацию.
Забегая вперед, я Вам расскажу, что Google клал с большим прибором на все правила в robots.txt и индексирует ВСЕ страницы которые может скачать.
Показывает не все. А индексирует все.
khim
02.07.2019 17:32Они протсо пытаются казаться добыми или там есть какие то юридические тонкости, и еще есть ли поисковики игнорирующие робот.тхт?
Юридическая тонкость в том, что только наличие robots.txt позволяет поисковикам заявлять, что они вообще что-то там могут скачивать и парсить. Юридически это называется Implied license.
vedenin1980
02.07.2019 18:46Если бы это было так, то поисковики не индексировали бы сайты без robots.txt, а они действуют ровно наоборот (отстутствие robots.txt не подразумевает, что я разрешаю делать, что угодно с моим контентом).
Дайте ссылку на подтверждения вашего утверждения с реальными судебными решениями в отношении поисковиков (или хотя бы утверждениями представителей поисковиков про юридическое значение robots.txt или что хоть один суд учитывает наличие/отсутствие этого файла).
Насколько я знаю, поисковики в основном упирают на пункты о возможности ограниченного цитирования объектов авторского права.khim
02.07.2019 19:49отстутствие robots.txt не подразумевает, что я разрешаю делать, что угодно с моим контентом
Подразумевает. Для ограничений доступа во всех протоколах есть встроенные средства (вот в HTTP, например). Если вы ими не пользуетесь и не ограничиваете доступ с помощью robots.txt — то подразумевается, что вы выложили информацию на всеобщее обозрение.
Дайте ссылку на подтверждения вашего утверждения с реальными судебными решениями в отношении поисковиков (или хотя бы утверждениями представителей поисковиков про юридическое значение robots.txt или что хоть один суд учитывает наличие/отсутствие этого файла).
А искать не пробовали? Field v. Google Inc., Parker v. YAHOO!, Inc. и другие.
Это всё лет 10 назад отшумело, когда на поисковики реально люди пытались «наехать» не очень понимая, что без них — от их сайтах тупо никто не узнал бы.
Насколько я знаю, поисковики в основном упирают на пункты о возможности ограниченного цитирования объектов авторского права.
Поисковики (а вернее их юристы), обычно презентуют сразу 100500 вариантов. Но обычно всё сводится к вопросам:
1. Знал ли владелец авторских прав о том что и как делают поисковики.
2. Были ли у него средства ограничить их деятельность.
Вторая часть очень важна (вот как раз совсем недавно обсуждалась похожая вещь), правда в отношении другого закона. «Выбор без выбора» суды очень не любят — и вот именно robots.txt предназначен для того, чтобы дать возможность кому-то ограничить доступ для роботов (сохранив свободный доступ для людей).vedenin1980
03.07.2019 10:09-1и вот именно robots.txt предназначен для того, чтобы дать возможность кому-то ограничить доступ для роботов (сохранив свободный доступ для людей).
Там могут быть любые средства блокирования поисковика — метатеги, запрет на индексацию в самом поисковике, возможность удаления своего сайта из индекса через вебинтерфейс. Там главное, чтобы такая возможность была, она работала и о ней было широко известно.
не очень понимая, что без них — от их сайтах тупо никто не узнал бы.
Понимая, там скорее жулики вида «добавить по тихому недосайт в гугл, а потом вдруг прокатит срубить денег».
Если вы ими не пользуетесь и не ограничиваете доступ с помощью robots.txt — то подразумевается, что вы выложили информацию на всеобщее обозрение.
На обозревание, но не копирование. Поисковики — исключение, только потому что они не используют сам контент для других целей кроме поиска.khim
03.07.2019 10:30-1На обозревание, но не копирование.
А это уж как вы в robots.txt напишите.
Поисковики — исключение, только потому что они не используют сам контент для других целей кроме поиска.
Не совсем.
Понимая, там скорее жулики вида «добавить по тихому недосайт в гугл, а потом вдруг прокатит срубить денег».
Они со сниппетами боролись. И с кешом. То есть как раз с «с использованием для других целей, кроме поиска». Суд постановил, что раз есть возможность поисковики ограничить — то это уже ваша забота решать: хотите вы давать доступ или нет. А требовать, чтобы контент использовался «только для поиска» — вы не можете.
Archive.org и archive.is под то же исключение попадают — а там поиска в принципе нету.vedenin1980
03.07.2019 10:56Они со сниппетами боролись. И с кешом. То есть как раз с «с использованием для других целей, кроме поиска». Суд постановил, что раз есть возможность поисковики ограничить — то это уже ваша забота решать: хотите вы давать доступ или нет.
Да, но там речь не шла о robots.txt, а о мета кейбордах позволяющих удалить данные из кеша поисковиков и возможность удалить данные кеша через вебинтерфейс.
Archive.org и archive.is под то же исключение попадают — а там поиска в принципе нету.
Насколько помню они недавно решили забить на robots.txt и их до сих пор не засудили. Исключение связано с так называемым «добросовестном использованием» — пока суд считает, что вы не наживаетесь на чужом авторском праве вы в рамках закона.
А это уж как вы в robots.txt напишите.
Лицензию на распорстраненние и копирование нельзя поместить в него. Гугл недавно пресовали за то, что он полностью копировал новости, так что пропадала необходимость заходить на сайт новостных агенств и это вроде было признано не «добросовестным использованием», несмотря на открытые robots.txt. Был так же запрет показ картинок в поиске гугла в полном качестве, в результате сейчас это обходит хитрыми фокусами «открыть на новой странице».
ИМХО, дело не в robots.txt, а том посчитают ваше использование «добросовестным» или нет.khim
03.07.2019 20:15+1Насколько помню они недавно решили забить на robots.txt и их до сих пор не засудили.
Ссылку можно? Я пока встречал только случаи ретроактивного применения robots.txt, а не его игнорирование…
Исключение связано с так называемым «добросовестном использованием» — пока суд считает, что вы не наживаетесь на чужом авторском праве вы в рамках закона.
К наживе это вообще не имеет отношение. Ваше нарушение авторского права должно способствовать прогрессу науки и полезных искусств — что достаточно очевидно в случае с поисковиками, но куда как менее очевидно в случае с теми же сниппетами, например.
Гугл недавно пресовали за то, что он полностью копировал новости, так что пропадала необходимость заходить на сайт новостных агенств и это вроде было признано не «добросовестным использованием», несмотря на открытые robots.txt.
Ни разу ни так. Поскольку суды категорически отказывались признавать подобные вещи незаконными,
то Германия и Испания попытались «выжать денег» через изменение законов. Получили тупо закрытие Google News в Испании, в Германии пришлось договариваться.
ИМХО, дело не в robots.txt, а том посчитают ваше использование «добросовестным» или нет.
Если бы дело было так, как вы описываете (а оно примерно так обстоит в Америке) — то не потребовалось бы специальные законы «против Гугла» принимать.



VokaMut
02.07.2019 08:41+4В парсере не обошлось и без забавных моментов: взгляните к примеру на то, сколько труда пошло на обработку «disallow».
Первый PR как раз по расширению списка disallow опечаток. Плюс туча с исправлениями опечаток в комментариях. Всем хочется внести свой вклад в OpenSource.

github.com/google/robotstxt/pull/1/filesVSOP_juDGe
02.07.2019 09:24+19и потом небрежно: я тут в гугл коммитил

DmitryOlkhovoi
02.07.2019 15:09Вы еще не видели коммиты в сорцы Апполо. Спустя день там небыло опечаток в коментариях
Gordon01
02.07.2019 16:10Почему у вас шрифты так плохо выглядят или это картинка плохо отмасштабировалась?

sumanai
02.07.2019 17:39Просто шрифт говно на гитхабе. В идеале должно выглядеть так:
Заголовок спойлера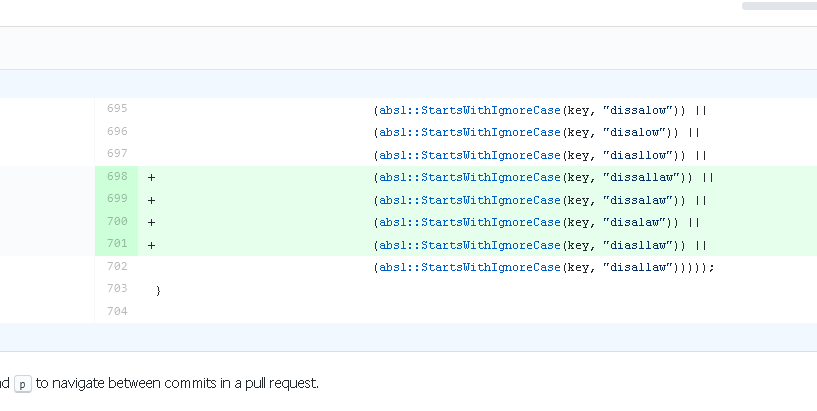
knotri
02.07.2019 18:06+1Я конечно понимаю что про вкус фломастеров не спорят, но называть отсутствие сглаженности идеальным...
sumanai
02.07.2019 18:26Это идеальный хинтинг. Абсолютно чёткие шрифты. Ни капли мыла. Жаль, что всё больше программ в Windows не подчиняются системным настройкам сглаживания и шрифтов.
khim
02.07.2019 19:51+1Вы можете сколько угодно рассказывать сказки о том, что это — идеал… но дизайнеры — так не считают.
А поскольку они, последние лет 10, рулят Web'ом — то имеем то, что имеем.
Gordon01
02.07.2019 21:28+1Да потому что появился пласт "дизайнеров" выращенных на макосевом freetype со сглаживанием без хинтинга и с читающих что так — хорошо
psycho-coder
02.07.2019 19:59Шрифт для кода с засечками? У вас глаза не устают вчитываться?
sumanai
03.07.2019 01:48Я даже не знаю какой это шрифт, дефолтный на monospase, я на гитхабе код не читаю в больших объёмах.
Сейчас посмотрел, это старый добрый Courier New, как ни странно. Сколько читал, ещё ничего не сломал.psycho-coder
03.07.2019 10:48Действительно, он. Видимо я уже отвык от него и читать такой мне не очень удобно. Тогда мой вопрос не уместен.

KodyWiremane
02.07.2019 19:57+2Первый PR должен был быть про сокращение этого списка до одной строки — той, что с
disallow. По крайней мере, пока остальные варианты не попадут в стандарт. Устроили тут…
psycho-coder
02.07.2019 20:05Быть может я чего-то не понимаю, но ведь есть расстояние Левенштейна, которого должно хватить.
Как пример:
$d = [ 'dissallow', 'dissalow', 'disalow', 'diasllow', 'disallaw',]; foreach ($d as $item) echo levenshtein('disallow', $item), PHP_EOL;so1ov
02.07.2019 23:32Правильно, парсер на сишке недостаточно хорош, надо портировать туда расстояние Левенштейна из бортовых возможностей всяких там интерпретируемых языков, этого точно хватит всем.
khim
03.07.2019 00:07+1Проблема не в том, что levenshtein невозможно написать на C, проблема в том, что какое-нибудь «isallow» — точно не «disallow»… а по Левенштейну оно ближе, чем «dissalow».
Человеческий взгляд цепляется за первые и последние буквы, но склонно упускать то, что там творится в середине слова — а Левенштейн этого не учитывает…psycho-coder
03.07.2019 10:58+1Этот момент я не учел, так как в исходниках такой ситуации тоже нету. С другой стороны, «isallow» это также точно не «allow» поэтому путаницы быть не должно, но это в теории.
А вообще, я согласен с KodyWiremane, чтобы указать жестко «disallow» и пусть перепроверяют что они там написали.
tangro
04.07.2019 23:23Представьте сколько миллиардов раз этот код запускается каждый день на серваках гугла. И Вы предлагаете его замедлить расчётами расстояния Левенштейна. У меня в голове первое предложение пул-реквеста выглядело так:
return ( absl::StartsWithIgnoreCase(key, "disallow") || (kAllowFrequentTypos && absl::StartsWithIgnoreCase(key, "dis") && ((absl::StartsWithIgnoreCase(key, "dissallow")) || (absl::StartsWithIgnoreCase(key, "dissalow")) || (absl::StartsWithIgnoreCase(key, "disalow")) || (absl::StartsWithIgnoreCase(key, "diasllow")) || (absl::StartsWithIgnoreCase(key, "disallaw")))));
Тогда можно будет сразу за одно сравнение отбросить все слова, не начинающиеся с «dis», а не делать 5 сравнений каждый раз.

Andrey2008
11.07.2019 19:42?PVS-Studio хотел, но не смог найти баги в robots.txt — habr.com/ru/company/pvs-studio/blog/459662

VolCh
Был уверен, что RFC или иной стандарт есть, просто на глаза не попадался :)