
 СУБД InterSystems IRIS поддерживает любопытные структуры для хранения данных — глобалы. По сути это многоуровневые ключи с различными дополнительными плюшками в виде транзакций, быстрых функций для обхода деревьев данных, блокировок и своего языка ObjectScript.
СУБД InterSystems IRIS поддерживает любопытные структуры для хранения данных — глобалы. По сути это многоуровневые ключи с различными дополнительными плюшками в виде транзакций, быстрых функций для обхода деревьев данных, блокировок и своего языка ObjectScript.Подробнее о глобалах в цикле статей «Глобалы — мечи-кладенцы для хранения данных»:
Деревья. Часть 1
Деревья. Часть 2
Разреженные массивы. Часть 3
Мне стало интересно как реализованы транзакции в глобалах, какие там есть особенности. Ведь это совершенно иная структура для хранения данных, чем всем привычные таблицы. Намного более низкоуровневая.
Как известно из теории реляционных баз данных хорошая реализация транзакций должна удовлетворять требованиям ACID:
A — Atomic (атомарность). Записываются все изменения сделанные в транзакции или вообще никаких.
С — Consistency (согласованность). После завершения транзакции логическое состояние БД должно быть внутренне непротиворечивым. Во многом это требование касается программиста, но в случае SQL-баз данных оно касается также внешних ключей.
I — Isolate (изолированность). Параллельно выполняющиеся транзакции не должны оказывать влияние друг на друга.
D — Durable (долговечность). После успешного завершения транзакции проблемы на нижних уровнях (сбой по питанию, например) не должны оказывать влияние на данные изменённые транзакцией.
Глобалы — это нереляционные структуры данных. Они создавались для сверхбыстрой работы на очень ограниченном железе. Давайте разберёмся в реализации транзакций в глобалах с помощью официального docker-образа IRIS.
Для поддержки транзакций в IRIS используются команды: TSTART, TCOMMIT, TROLLBACK.
1. Атомарность
Легче всего проверить атомарность. Проверяем из консоли базы данных.
Kill ^a
TSTART
Set ^a(1) = 1
Set ^a(2) = 2
Set ^a(3) = 3
TCOMMITПотом делаем вывод:
Write ^a(1), “ ”, ^a(2), “ ”, ^a(3)Получим:
1 2 3Всё в порядке. Атомарность соблюдена: все изменения записались.
Усложним задачу, введём ошибку и посмотрим как сохранится транзакция, частично или вообще никак.
Ещё раз проверим атомарность:
Kill ^A
TSTART
Set ^a(1) = 1
Set ^a(2) = 2
Set ^a(3) = 3После чего принудительно остановим контейнер, запустим и посмотрим.
docker kill my-irisЭта команда практически эквивалентна насильственному выключению питания, так как отправляет сигнал немедленной остановки процесса SIGKILL.
Может быть транзакция сохранилась частично?
WRITE ^a(1), ^a(2), ^a(3)
^
<UNDEFINED> ^a(1)— Нет, не сохранилась.
Испытаем команду отката:
Kill ^A
TSTART
Set ^a(1) = 1
Set ^a(2) = 2
Set ^a(3) = 3
TROLLBACK
WRITE ^a(1), ^a(2), ^a(3)
^
<UNDEFINED> ^a(1)Тоже ничего не сохранилось.
2. Согласованность
Поскольку в базах на глобалах ключи делаются также на глобалах (напомню, что глобал — это более низкоуровневая структура для хранения данных, чем реляционная таблица), для выполнения требования согласованности нужно изменение ключа включать в ту же транзакцию, что и изменение глобала.
Например у нас есть глобал ^person, в котором мы храним персоналии и в качестве ключа мы используем ИНН.
^person(1234567, ‘firstname’) = ‘Sergey’
^person(1234567, ‘lastname’) = ‘Kamenev’
^person(1234567, ‘phone’) = ‘+74995555555
...Для того, чтобы иметь быстрый поиск по фамилии и имени мы сделали ключ ^index.
^index(‘Kamenev’, ‘Sergey’, 1234567) = 1Для того, чтобы база была согласована мы должны добавлять персоналию так:
TSTART
^person(1234567, ‘firstname’) = ‘Sergey’
^person(1234567, ‘lastname’) = ‘Kamenev’
^person(1234567, ‘phone’) = ‘+74995555555
^index(‘Kamenev’, ‘Sergey’, 1234567) = 1
TCOMMITСоответственно, при удалении мы также должны использовать транзакцию:
TSTART
Kill ^person(1234567)
ZKill ^index(‘Kamenev’, ‘Sergey’, 1234567)
TCOMMITИными словами выполнение требования согласованности лежит полностью на плечах программиста. Но когда речь идёт о глобалах — это нормально, в силу их низкоуровневой природы.
3. Изолированность
Вот тут начинаются дебри. Много пользователей одновременно работают над одной и той же базой, изменяют одни и те же данные.
Ситуация сравнима с тем, когда много пользователей одновременно работают с одним и тем же репозиторием с кодом и пытаются одновременно в него коммитить изменения во многих файлах сразу.
База данных должна это всё разруливать в реальном времени. Учитывая, что в серьёзных компаниях есть даже специальный человек, который отвечает за контроль версий (за слияние веток, разрешение конфликтов и т.п), а БД всё это должна делать в реальном времени, то становится очевидной сложность задачи и правильность проектирования базы данных и кода, который её обслуживает.
База данных не может понять смысл действий выполняемых пользователями, чтобы не допустить конфликтов, если они работают над одними и теми же данными. Она может только отменить одну транзакцию противоречащую другой или выполнить их последовательно.
Ещё одна проблема, что во время выполнения транзакции (до коммита), состояние базы может быть несогласованным, поэтому желательно, чтобы у других транзакций не было доступа к несогласованному состоянию базы данных, что достигается в реляционных БД многими способами: создание снепшотов, многоверсионностью строк и т.п.
При параллельном исполнении транзакций нам важно, чтобы они не мешали друг другу. Это и есть свойство изолированности.
SQL определяет 4 уровня изолированности:
- READ UNCOMMITTED
- READ COMMITTED
- REPEATABLE READ
- SERIALIZABLE
Рассмотрим каждый уровень в отдельности. Затраты на реализацию каждого уровня растут чуть-ли не экспоненциально.
READ UNCOMMITTED — это самый низкий уровень изолированности, но при этом самый скоростной. Транзакции могут читать изменения внесённые друг другом.
READ COMMITTED — это следующий уровень изоляции, который является компромиссом. Транзакции не могут читать изменения внесённые друг другом до коммита, но могут читать любые изменения внесённые после коммита.
Если у нас есть долгая транзакция Т1, в течении которой прошли коммиты в транзакциях Т2, Т3 … Тn, которые работали с теми же данными что и Т1, то при запросе данных в Т1 мы будем каждый раз получать разный результат. Этот феномен называется неповторяемое чтение.
REPEATABLE READ — в этом уровне изоляции у нас нет феномена неповторяемого чтения, за счёт того, что для каждого запроса на чтение данных создаётся снимок данных результата и при повторном использовании в этой же транзакции используется данные из снимка. Однако в этом уровне изоляции возможно чтение фантомных данных. Имеются ввиду чтение новых строк, которые были добавлены параллельными зафиксированными транзакциями.
SERIALIZABLE — самый высокий уровень изоляции. Он характеризуется тем, что данные каким-либо образом используемые в транзакции (чтение или изменение) становятся доступными другим транзакциям только после завершения первой транзакции.
Для начала разберёмся есть ли изоляция операций в транзакции от основного потока. Откроем 2 окна терминала.
|
|
Изоляции нет. Один поток видит, что делает второй открывший транзакцию.
Посмотрим видят ли транзакции разных потоков то, что происходит внутри них.
Откроем 2 окна терминала и откроем 2 транзакции параллельно.
|
|
Параллельные транзакции видят данные друг друга. Итак, мы получили самый простой, но и самый быстрый уровень изоляции READ UNCOMMITED.
В принципе это можно было ожидать для глобалов, для которых быстродействие всегда ставилось во главу угла.
Как же быть, если нам понадобится более высокий уровень изоляции в операциях на глобалах?
Здесь нужно задуматься зачем вообще нужны уровни изоляции и как они работают.
Самый высокий уровень изоляции SERIALIZE означает, что результат параллельно исполняемых транзакций эквивалентен их последовательному исполнению, что гарантирует отсутствие коллизий.
Такое мы можем сделать с помощью грамотных блокировок в ObjectScript, которые имеют массу разнообразных способов применения: можно делать обычную, инкрементную, множественную блокировку командой LOCK.
Более низкие уровни изоляции — это компромиссы призванные увеличить скорость работы базы данных.
Посмотрим как мы можем добиться разных уровней изоляции с помощью блокировок.
Этот оператор позволяет брать не только эксклюзивные блокировки, нужные для изменения данных, но так называемые shared, которые могут брать параллельно сразу несколько потоков, когда им нужно читать данные, которые не должны быть изменены другими процессами в процессе чтения.
Подробнее о двухфазном методе блокировок на русском и английском языках:
> Двухфазная блокировка
> Two-phase locking
Сложность состоит в том, что во время транзакции состояние базы может быть несогласованным, однако эти несогласованные данные видны другим процессам. Как этого избежать?
Мы сделаем с помощью блокировок такие окна видимости, в которых состояние базы будет согласовано. И все обращения к таким окнам видимости согласованного состояния будет контролироваться блокировками.
Shared-блокировки одних и тех же данных многоразовые — их могут взять несколько процессов. Это блокировки запрещают другим процессам изменять данные, т.е. они используются для формирования окон согласованного состояния БД.
Эксклюзивные блокировки используются для изменений данных — такую блокировку может взять только один процесс. Эксклюзивную блокировку может взять:
- Любой процесс, если данные свободны
- Только тот процесс, который имеет на эти данные shared-блокировку и первый запросил эксклюзивную блокировку.
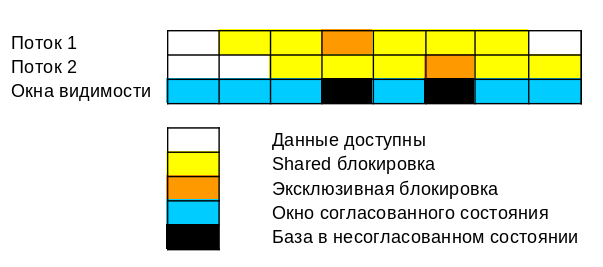
Чем уже окно видимости, тем дольше его приходится ждать другим процессам, но тем согласованнее может быть состояние БД в нём.
READ_COMMITED — суть этого уровня, что мы видим только закоммиченные данные из других потоков. Если данные в другой транзакции ещё не закоммичены, то мы видим их старую версию.
Это позволяет нам распараллелить работу вместо ожидания освобождения блокировки.
Без специальных ухищрений мы не сможем видеть старую версию данных в IRIS, поэтому нам придётся обойтись блокировками.
Соответственно нам придётся с помощью shared блокировок разрешить чтение данных только в моменты согласованности.
Допустим у нас есть база пользователей ^person, которые переводят друг другу деньги.
Момент перевода от персоны 123 к персоне 242:
LOCK +^person(123), +^person(242)
Set ^person(123, amount) = ^person(123, amount) - amount
Set ^person(242, amount) = ^person(242, amount) + amount
LOCK -^person(123), -^person(242)Момент запроса количества денег у персоны 123 перед списанием должен сопровождаться эксклюзивной блокировкой (по умолчанию):
LOCK +^person(123)
Write ^person(123)А если нужно показать состояние счёта в личном кабинете, то можно использовать shared блокировку или вообще её не использовать:
LOCK +^person(123)#”S”
Write ^person(123)Однако, если допустить, что операции работы с БД выполняются практически мгновенно (напомню, что глобалы — это намного более низкоуровневая структура, чем реляционная таблица), то необходимость этого уровня падает.
REPEATABLE READ — в этом уровне изоляции допускается, что могут быть несколько чтений данных, которые могут быть изменены параллельными транзакциями.
Соответственно нам придётся ставить shared блокировку на чтение данных, которые мы меняем и эксклюзивные блокировки на данные которые мы меняем.
Благо оператор LOCK позволяет в одном операторе детально перечислить все необходимые блокировки, которых может быть очень много.
LOCK +^person(123, amount)#”S”
чтение ^person(123, amount)другие операции (в это время параллельные потоки пытаются изменить ^person(123, amount), но не могут)
LOCK +^person(123, amount)
изменение ^person(123, amount)
LOCK -^person(123, amount)
чтение ^person(123, amount)
LOCK -^person(123, amount)#”S”При перечислении блокировок через запятую они берутся последовательно, а если сделать так:
LOCK +(^person(123),^person(242))то они берутся атомарно все сразу.
SERIALIZE — нам придётся выставить блокировки так, чтобы в конечном итоге все транзакции, которые имеют общие данные выполнялись последовательно. Для этого подхода большинство блокировок должны быть эксклюзивными и браться на самые маленькие области глобала для производительности.
Если же говорить о списаниях средств в глобале ^person, то для него приемлем только уровень изоляции SERIALIZE, так как деньги должны тратиться строго последовательно, иначе возможно потратить одну и ту же сумму несколько раз.
4. Долговременность
Я проводил тесты с жёстким вырубанием контейнера посредством
docker kill my-irisБаза их переносила хорошо. Проблем не было выявлено.
Заключение
Для глобалов в InterSystems IRIS есть поддержка транзакций. Они действительно атомарные, надёжные. Для обеспечения же согласованности БД на глобалах необходимы усилия программиста и использование транзакций, так как в ней нет сложных встроенных конструкций типа внешних ключей.
Уровень изоляции у глобалов без использования блокировок — это READ UNCOMMITED, а при использовании блокировок можно его обеспечить вплоть до уровня SERIALIZE.
Корректность и скорость работы транзакций на глобалах очень сильно зависит от мастерства программиста: чем более широко используются shared-блокировки при чтении, тем выше уровень изоляции, а чем более узко берутся эксклюзивные блокировки, тем больше быстродействие.
Комментарии (7)

epishman
30.07.2019 11:56Насколько я понял, языка запросов как такового тут нет, и основной метод обработки данных это map/reduce?

inetstar Автор
30.07.2019 15:42+1Языка запросов (типа SQL) для глобалов нет. Хотя SQL может быть применён, если на глобалах эмулируются таблицы.
Изначально глобалы проектировались под свой язык (ныне ObjectScript). В этом языке с ними работают также как с обычными переменными этого языка. Только крышечка перед именем переменной (^) говорит о том, что эта переменная хранится на диске (т.е. постоянно, персистентно), а не в RAM.
Coriolis
Странно, я давным-давно читал что в Cache транзакции работают как раз магическим образом: если база обнаружила конфликт в двух транзакциях то она в одной из транзакций производит отмотку точки исполнения кода вместе с состоянием всех локальных переменных задания к месту вызова команды tstart, таким образом если процесс ничего не читал и не писал во вне он даже и не замечал что его откатили к старту транзакции. Получается такая прозрачная конкуренция, прикладник даже не задумывается о таких штуках а в итоге конфликты все разруливаются на низком уровне. Или это в GT.M только сделали, как-нибудь погуглю, интересно стало.
inetstar Автор
Да, реализация транзакций в разных БД на глобалах сильно отличается. Может быть позже напишу про GT.M.
Coriolis
Ну значит так и есть. Ну дак эта вот реализация, где происходит откат — это настоящая, крутая техномагия. В этом огромная сила технологии MUMPS. Вы специально такое на конец оставили?
inetstar Автор
У меня есть свой план и порядок написания статей. Я не хотел бы забегать вперёд и спойлерить, но у каждого решения есть свои плюсы и минусы. Мне ещё нужно время, чтобы понять какие.
В этой статье я не исследовал аспекты отката ошибочных транзакций, только уровень изолированности.
Лично для меня двухуровневая блокировка — тоже техномагия.
Более того в IRIS есть такие хитрые типы блокировок, которые как обезьянки умеют подниматься по деревьям данных — escalating. С ними ещё не разобрался.