

Представьте себе, что вы поспорили с друганом, что было раньше —
Краткая справка
Machine Learning for Social Good (ML4SG) — это инициатива внутри сообщества ODS, нацеленная на создание условий для проектов, как следует из названия, которые применяют машинное обучения для принесения какой-то пользы обществу. Под созданием условий здесь подразумеваются в основном организационные ресурсы. Выглядит это примерно так: кто-то формулирует идею проекта и призывает добровольцев, а кто-то просто присоединяется к проекту, ради идеи, опыта или ещё каких-то интересов. Всё держится на энтузиазме, чаще всего в свободное от основной работы время. Радар новостей рунета, или как мы его коротко зовём в команде “ньюзвиз”, один из проектов в рамках ML4SG.
Дисклеймер
В некоторых иллюстрациях в этой статье будут упоминаться какие-то политические события или персоны. Давайте оставим мнения о них при себе. Хабр не для политики.
Что мы делаем
В двух словах о мотивации
Сейчас проект позиционируется как инструмент для анализа СМИ в целом. Если есть какая-то гипотеза о том, как развивалось внимание в новостях к разным темам, событиям, персонам и так далее, то можно говорить опираясь на конкретные числа, а не на домыслы.
Изначальный замысел был такой: берём все новостные данные, какие найдём, применяем тематическое моделирование, раскладываем результаты по времени и рисуем результат.
Тематическая модель (topic model) — модель коллекции текстовых документов, которая определяет, к каким темам относится каждый документ коллекции. Алгоритм построения тематической модели получает на входе коллекцию текстовых документов. На выходе для каждого документа выдаётся числовой вектор, составленный из оценок степени принадлежности данного документа каждой из тем. Размерность этого вектора, равная числу тем, может либо задаваться на входе, либо определяться моделью автоматически.
Подробнее здесь.
Понятно, что для этого нужны сами новости, и мы их качаем. И раз у нас будут большие корпуса новостей, то можно сделать ещё много всего интересного, не ограничиваясь тематизацией. Но учитывая реальные условия, о которых мы ещё поговорим, а именно, что реализовывать проект будет толпа добровольцев, а не хорошо сработавшаяся команда оплачиваемых специалистов, сначала мы всё-таки решаем задачу почти без изменений.

Сейчас мы пришли к такому формату визуализации, он называется ridgeline plot. На слайде, кстати, настоящие темы, — это скрин из старого внутреннего демо. То есть здесь у нас по оси абсцисс время, толщина полоски пропорциональна тому, насколько тема в этот момент представлена среди других новостей. В данном случае агрегация по месяцам.
В базовом плане у нас есть выбор источника новостей и выбор способа, как показывать график. Также можно выбрать дополнительные данные не из новостей, например, как в это время вела себя цена на нефть или любой другой показатель на том же временном промежутке. Выбор рубрики и набора тем в ней. В дополнение к этому ещё много идей, но об этом позже.
Похожие проекты
Есть много разных других проектов, связанных с визуализацией новостей. Мне нравятся вот эти два. Первый сравнивает, как подаются одни и те же новости в разных источниках, и при этом очень хорошая форма изложения и интерактив. Второй просто имеет очень хорошее отношение информативности к простоте. Там сравнивается, как много говорится о разных причинах смерти в новостях, как часто какие причины смерти упоминаются в поисковых запросах, и как оно по статистике. Ну и в выводах о том, как катастрофически переоценивается терроризм и как недооцениваются сердечные заболевания и рак.
Как мы это делаем
Проект довольно прямолинейный. Сначала качаем данные, потом обрабатываем, делаем всякий машинлёрнинг, ну и рисуем графики. Потом делаем сайт, и все смотрят. Всё понятно (ну да, конечно).

Сбор данных
Для старта у нас был датасет ленты ру за 20 лет. В основном все эксперименты мы делали на нём. Сейчас мы собрали ещё несколько источников и продолжаем собирать всё, до чего дотянемся. О скрапинге и пауках есть достаточно много подробных материалов, поэтому мы не будем здесь подробно останавливаться на этой теме.
NLP
Я больше всего переживал за NLP часть, потому что тяжело формализовать требования к результату тематизации. К тому же, достаточно много побочных подзадач. Сейчас мы проделали довольно много экспериментов с разными инструментами для тематического моделирования, перед этим разделались с препроцессингом, наделали много бенчмарков и сравнений. На данный момент бесспорным лидером по тематизации с точки зрения ресурсов и качества оказался bigARTM. Теперь это наш рабочий вариант, пока кто-нибудь не покажет что-то лучше.
В общем-то весь машинлёрнинг сосредоточен по большей части именно в этой секции. Кроме изначально поставленной основной задачи тематизации есть ещё много других, которые тоже принесут интересные выводы. Например, NER. Мы уже вытащили все имена из тех данных, что у нас есть, составили словари, посчитали, кого сколько раз упоминают. Вышло, например, что про Порошенко в Ленте.ру за всё время писали в четыре раза больше, чем про Путина. Мне интересно стало, что Ассанж идёт синхронно с Магнитским, и всё это ровно после ухода Буша. А Бэтмен популярнее, чем Медведев.
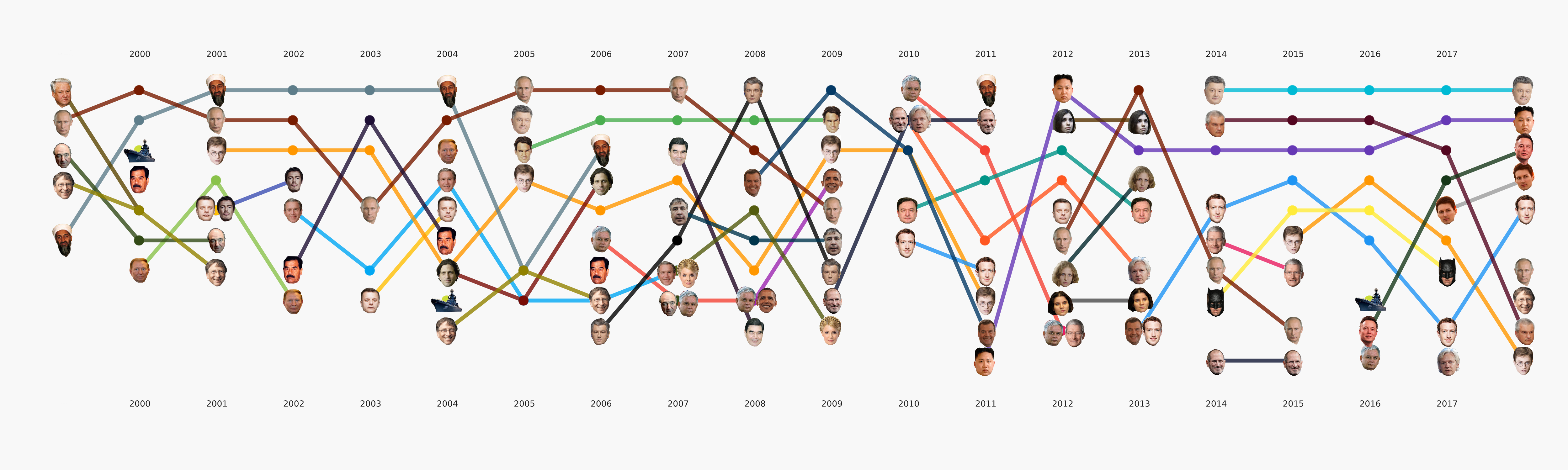

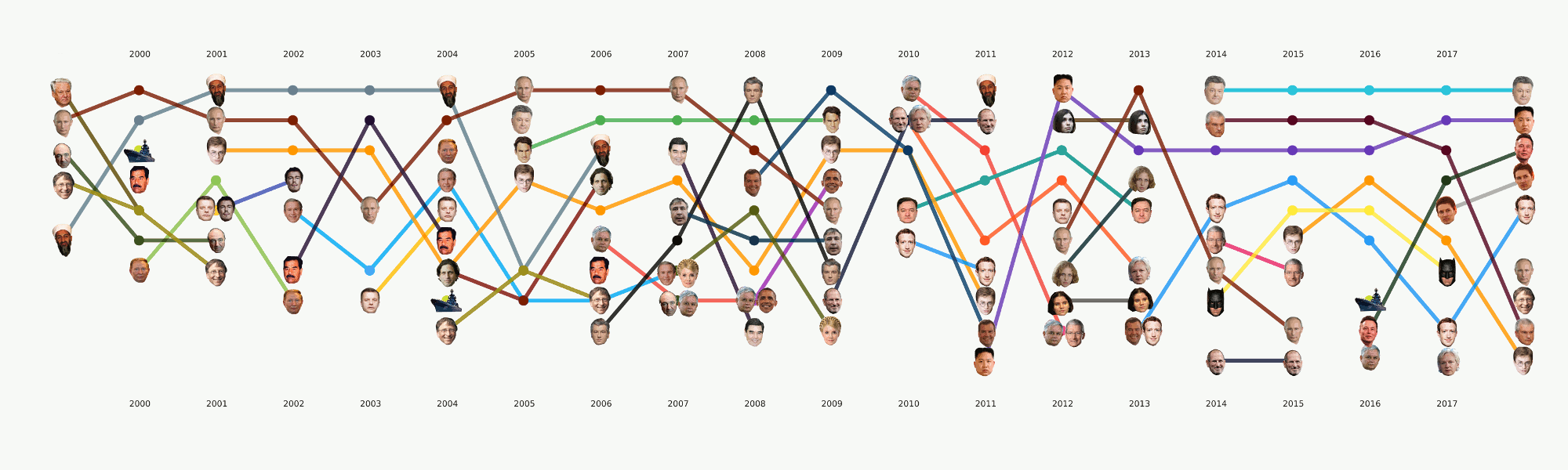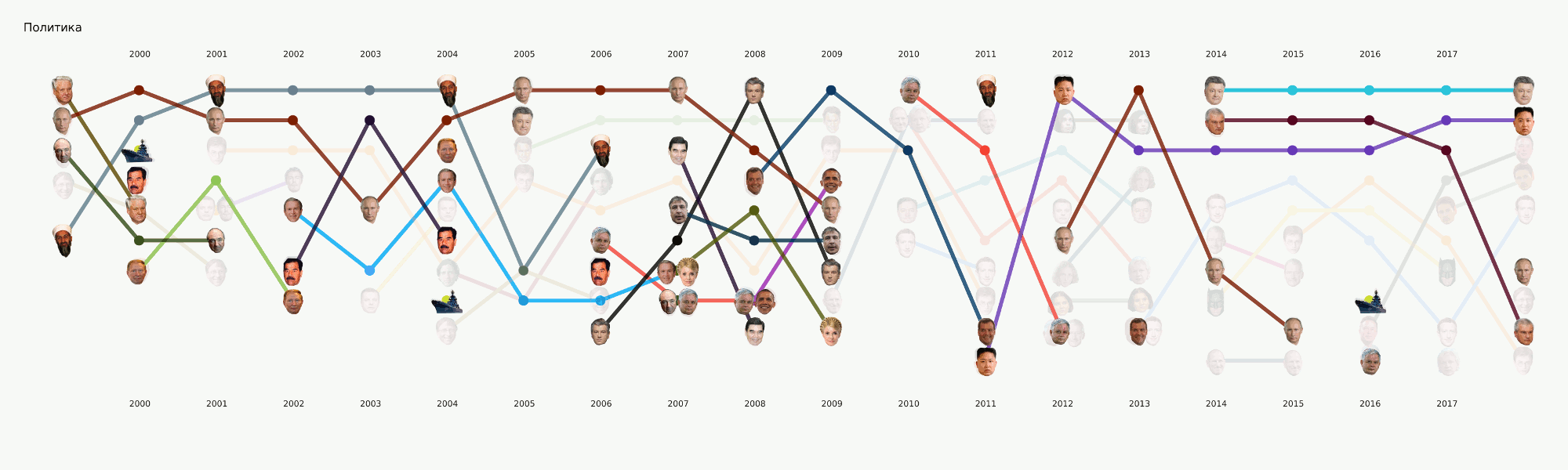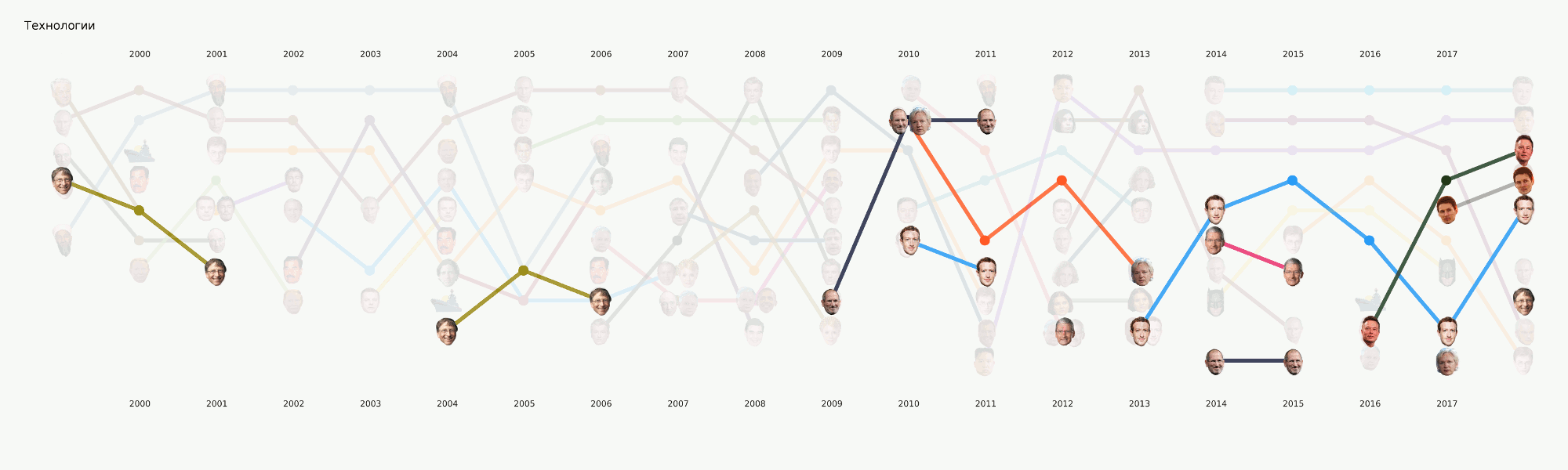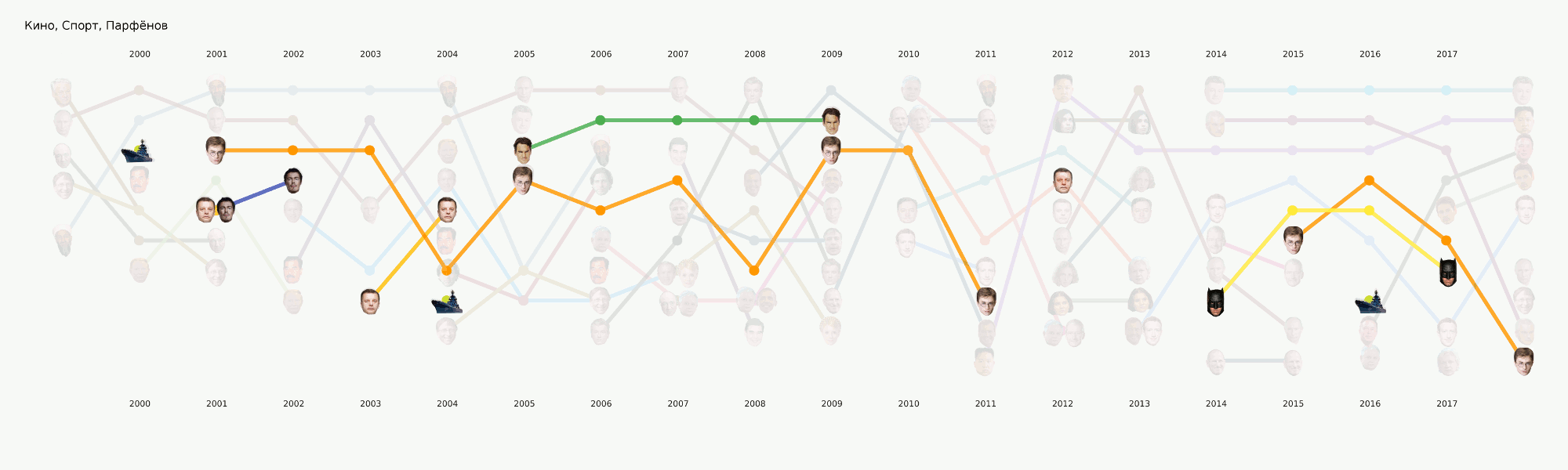
Хотя этот этап всё ещё в процессе, мы сделали большое количество экспериментов и сравнили много инструментов и подходов. В процессе большой туториал по разным задачам NLP с примерами кода и бенчмарками самых популярных и некоторых необычных инструментов.
Визуализация
Этот этап не казался слишком сложным, однако почему-то почти никто не готов им заниматься. Требования к визуализациям идут чуть дальше, чем привычный подход к EDA в датасаенсе. Нарисовать график для себя или другого датасентиста — это гораздо проще, чем нарисовать график для широкой публики. Мы очень долго возились с форматами и инструментами и сейчас пришли к некоторым подходам, которые кажутся наиболее разумными, но впереди ещё много работы, так как готовых инструментов для наших задач практически нет. Например, график с лицами выше делался в два этапа — основные элементы сгенерированы в коде, а затем следовал длинный этап ручной перерисовки, чтобы хоть что-то читалось. В плане подробный разбор этой визуализации в отдельной статье — она отражает в какой-то мере историю России за последние 20 лет.
Команда
Условно можно на две группы разделить участников: новички и профи. У новичков мотивация простая — положить в копилку какой-то проект, чтобы показывать работодателям, или просто приобрести опыт, чему-то научиться. И мне уже сообщали, что разные вещи, которые мы делали в рамках проекта, пригодились в работе участников, начальство оценило. Профи приходят либо из-за самой цели проекта, потому что им интересно присоединиться к идее, либо потому что хотят попробовать что-то из своих идей на новостных данных.
На самом деле есть ещё одна группа участников — это вот такие неуловимые ниндзя, которые вписались и ничего не делают либо только стартуют, а потом исчезают. Но как я уже пояснял, никто не работает в проекте за деньги, поэтому неорганизованность человеческих ресурсов неизбежна. Наблюдать со стороны из любопытства тоже можно.

Сейчас формально числится около 80 человек, из них около 10-20 бывают активны и 2-4 человека из них активны почти постоянно. В таком формате можно компенсировать отсутствие опыта временем. Многие пишут, что нет знаний, как делать, есть страх подвести из-за неумелости, но по факту важно только делать, а не ждать момент. Потому что ml4sg это очень крутая активность. Можно принести пользу и одновременно получить профит в виде опыта и портфолио, при этом из рисков только время, для менеджера ещё и репутация, конечно, но основной ресурс здесь это время, которое в итоге окупается.
Дальнейшие планы
Сейчас я это пытаюсь позиционировать как инструмент для исследований. Мы планируем добавить “разведочный” поиск, который может оценивать тему запроса и давать статистики по новостям этой темы, графики разных неновостных данных, но релевантных теме проекта. Тогда можно будет проверять всякие гипотезы о том, как ведут себя СМИ, как связаны события и другие произвольные показатели, социальные или экономические. Такой инструмент, чтобы исследовать СМИ в целом.
Кто нужен проекту
- У нас очень мало кто занимается визуализацией. Мы выходим за рамки привычных датасаентисту инструментов вроде matplotlib или plotly, поэтому нужны люди, которые действительно любят визуализацию данных и хотят глубоко в ней прокачаться.
- Нужны люди, которые что-то понимают в веб-разработке.
- Нужны люди, которые подскажут нам, что искать. По сути это должны быть наши заказчики, которым интересно провести исследование и докопаться до каких-то вещей о том, как менялись русскоязычные СМИ в последнее время.
- Нам всегда нужны спецы в NLP, я думаю, тут пояснять не надо. Причём найдётся чем заняться и тем, кто хочет поучиться, и опытным ребятам, так как есть много таких интересных проблем в этой области.
- Ну и конечно нам надо собирать приличный проект, чтобы всё работало не на изоленте, поэтому если вы шарите в архитектуре проектов, умеете пересобирать кучу экспериментов в один пайплайн и готовы поделиться опытом, то велком. Если хотите научиться на ходу, то тоже добро пожаловать.
Комментарии (25)

3aiats
01.08.2019 17:25а вы тащите в том числе количество просмотров новости? если да — можно попробовать посчитать влияние новостей о кассовых сборах фильмов в зависимости от освещения в прессе рекордов в первый — второй — третий викенд. Если проклюнется что нибудь интересное, можно попробовать монетизировать

iggisv9t Автор
01.08.2019 17:26Я думаю, что этим и без нас занимаются, конечно. Сейчас мы просмотры не парсим. Когда-нибудь обязательно будем.
Deerenaros
02.08.2019 15:01+1Без просмотров, особенно персонализированных, боюсь, это слишком не интересно для монетизации. Разве что спекулятивной)
Есть вообще какие-либо перспективы изучения этих графиков окромя удовлетворения собственного любопытства?
iggisv9t Автор
02.08.2019 16:17+1Мы же не задачу рекомендаций решаем. То есть вопрос стоит «что пишут», а не «что читают». И тем более не «что предложить почитать». Если брать именно этот проект в чистом виде — то это скорее археология. Но я уже говорил в другом комментарии, что есть бизнес-задачи, где то же самое монетизируется. Только на других данных. Например то же самое «что пишут» в соцсетях простые пользователи даёт ответ на вопрос «что читают» и «что интересно», соответственно и «что предложить почитать». Странно говорить о возможностях инструмента не глядя на сам инструмент, а только на то, к чему его сейчас применили.
Если пытаться охарактеризовать проект с точки зрения того, чем он не является, то разумеется выглядеть будет абсурдно. В данном случае проект не является ни в каком качестве бизнесом. Ни стартапом, ни POC для какого-то стартапа, ни чем похожим. Поэтому вопросы о монетизации надо было бы задавать начиная с вопроса «а нужна ли монетизация?». Ответ — вообще не обязательно. С деньгами и работниками конечно будет эффективнее, но задачи тогда тоже будут другие.
Я говорил, что в проекте предполагаются не только эти графики, поэтому не будем перспективы проекта сжимать в рамки того, что уже нарисовали. Я немного ответил на этот вопрос здесь habr.com/ru/company/ods/blog/460287/#comment_20466025
Дополню, что дата-журналистика находит свою нишу и пользуется спросом. Сам факт того, что люди читают новости, показывает то, что людям интересно, что происходит. То есть если вы переживаете по поводу аудитории — не переживайте.
По поводу просмотров всё таки отвечу. Во-первых мы их всё равно рано или поздно скачаем. Во-вторых пока больше других фундаментальных задач, без которых просмотры бесполезны. В третьих — сначала мы собрали разные индексы о просмотрах самих СМИ, не конкретных статей, отранжировали и начали качать с самых популярных. Лента_ру везде в примерах только потому что она была уже скачана до нас.
rPman
01.08.2019 22:07+3Я извиняюсь за нескромный вопрос, 80 человек! достаточно сомнительный по монетизации проект, как вы собираетесь собственно поддерживать работу такого количества человек над таким относительно бесполезным проектом как анализ 'новостей' рунета?
dmitry_sh
02.08.2019 11:08не согласен, что проект бесполезный. Новостной поток — это своеобразный «пульс» общества. Клубок новостей — это как некий общественный «мозг», который совокупно реагирует на происходящее. Его анализ — потенциальный ключ к прогнозированию и принятию решений. Решения могут быть разные — общественные, планы развития, и даже ставки на биржах. имхо
iggisv9t Автор
02.08.2019 12:56+180 человек, из которых 2-4 бывают активны постоянно, около 20 вносили какой-то вклад в проект. У нас за ЗП никто не работает, в том числе и я. И никто и не надеялся на какие-то вознаграждения. Монетизация не была целью никогда. Я пытался пояснить мотивацию участников в разделе «команда» и формат таких проектов в разделе «краткая справка». В общем, нет необходимости поддерживать 80 человек, их которых 60 ограничились только тем, что заполнили заявку на участие.
Тем не менее на нас выходят организации, которым интересно применять подобные подходы к своим данным и задачам. Так что потенциал для монетизации есть, но немного в других рамках, уже вне всего этого движа.

AirLight
02.08.2019 04:04+1Как это применять? Примеры можно? Действительно ли он вообще позволяет что-то выуживать?
iggisv9t Автор
02.08.2019 13:28+1Изначальная идея применений примерно как то, что описано до ката. То есть чисто проверка гипотез о том, что происходит и как об этом пишут. Готовят ли почву для каких-то действий или событий, пытаются ли отвлечь внимание. С несколькими источниками можно будет сравнивать перекос в направленности или находить заимствования. Ещё интересные обзоры истории можно делать, как в том примере с лицами. Там видно, например, как на политическую арену выходили персоны из ИТ, а до этого там был только Гейтс, хотя в тот момент всех интересовало только его богатство. Для рекламщиков и пиарщиков здесь тоже есть интерес. Я сам, к сожалению, не очень понимаю их мир, но отслеживать влияние медиа — это очень важная для них задача.
S_A
02.08.2019 05:03Проект отличный, жаль что я попадаю в категорию нинзь за фатальным недостатком свободного времени по семейным обстоятельствам.
В плане веб-разработки там поляна широкая для творчества! А объем по моему мнению не запредельный. Идеально для желающих научиться делать современно и красиво.
iggisv9t Автор
02.08.2019 12:57+1Сделать что-то один раз, или посоветовать подход — тоже хороший вариант участия.

Arson
02.08.2019 08:58Мне кажется было бы интересно искать корреляции графиков, например человек интересуется новостями про победы в спорте, по идее система должна ему показать все новости с такими-же графиками и с зависимыми. Такие-же это, понятно, новости с пиками в тех же местах где пики того что я ищу, а зависимые — это, например, новости о фанатах/беспорядках, пик которых обычно следует (но не совпадает) за пиком спортивных новостей. Или наоборот, пик каких-то новостей всегда будет предшествовать тому что я ищу.
iggisv9t Автор
02.08.2019 13:01+1У нас есть в планах воспроизвести одну работу на эту тему. В ней ищут совпадение по пикам разных устойчивых фраз во временных рядах. Там это применяли к предвыборным кампаниям США на базе твитов и политических блогов, и обнаруживали кто за кем повторяет. Возможности применения такого подхода, конечно гораздо шире. Алгоритм называется K-Spectral Centroid Clustering, а проект memetracker. Meme здесь в том смысле, в каком его Докинз вводил.

nikolay_karelin
02.08.2019 11:17По поводу визуализации, есть хороший обзор здесь: http://jmlda.org/papers/doc/2015/no11/Aysina2015Survey.pdf
К сожалению, там нету ссылок на активные и открытые проекты. Нашел только вот эти две статьи с описанием исследовательских проектов:
iggisv9t Автор
02.08.2019 13:08+1Спасибо, почитаю. Пока только картинки посмотрел. Мы тоже пробовали steamgraph, stacked area и прочее из предложенного. Из-за огромного количества тем графики в таком виде получаются сильно перегружены. Пришли к тому, что хорошо сделанный bump chart и ridgeline plot пока лучший вариант. Но в любом случае выводить вообще всё не получится. Мы хотим давать пользователю выбор, как отображать. Пока только выбор из двух форматов.
Tollanin
02.08.2019 13:08+1Планируете ли Вы использовать вручную предопределённые сложносоставные темы (в виде графа с векторами оценки взаимосвязей). Корректно составленный граф позволяет оценивать валидность источников СМИ (по аналогии с группами вопросов для проверки валидности (лживости) в психологических тестах).
iggisv9t Автор
02.08.2019 13:12+1Честно говоря, я не понял о чём вы. То есть по отдельности понимаю куски идей, а как это всё вместе связано не понял. Мы очень надеемся на иерархические модели — наверное это можно назвать сложносоставными темами, и они строят дерево тем, да, то есть граф. Мысль про валидность, психологические тесты и вопросы не понял совсем.
Tollanin
02.08.2019 14:41+1Подразумевал: полезные для жизни результаты обычно учитывают валидность источников. Для какой-то изучаемой темы мы вручную строим шаблон из нескольких элементов со взаимосвязями. Например «сын моего отца мне не брат» — правильный ответ «Я». Если в результате анализа конкретного СМИ этот паттерн не проходит (например, утверждается, что ответ «сестра»), то у такого источника занижается оценка валидности (компетентности) по данной теме.
v_m_smith
03.08.2019 14:25а в открытом доступе для всех вы планируете результаты вашей обработки показывать?
В идеале хорошо бы вам превратиться не только в визуализатор, но и в экструдер новостей, чтобы новости превращались в краткую лаконичную саммари, содержащую лишь значимый факт из новости, без всей этой кликбейтной шелухи.
А то тошнит уже от нынешних «новостей»
и круто было бы конечно семантически связывать новости. чтобы от каждой можно было проследить цепочку в исторической перспективе, с цифрами динамики, графиками и т.п.iggisv9t Автор
05.08.2019 13:23Да, в открытом доступе будет, как только до приличного вида доведём.
Суммаризация текстов — довольно сложная задача, но в принципе всё для этого есть. Можно будет этим заняться, когда с текущим пулом задач разберёмся.
Связывать новости друг с другом семантически — это уже похоже на предмет для серьёзной научной работы, то есть это не просто техническая проблема. Мы такое любим, но тут понятно, что это надолго и результаты могут быть разные.
Спасибо за идеи.
Artgor
Активно участвую в работе над этим проектом и мне он очень нравится. Приглашаю интересующихся тоже поучаствовать в нём :)