
Прим. перев.: Рады поделиться переводом замечательного материала от старшего технологического евангелиста из AWS — Adrian Hornsby. В простых словах он объясняет важность экспериментов, призванных смягчить последствия сбоев в ИТ-системах. Вы, наверное, уже слышали про Chaos Monkey (или даже применяли подобные решения)? На сегодняшний день подходы к созданию подобных инструментов и их реализация в более широком контексте осуществляются в рамках деятельности, которую называют chaos engineering. Подробнее о ней читайте в этой статье.

Пожарные. Эти высококвалифицированные специалисты каждый день рискуют жизнью, борясь с огнем. Знаете ли вы, что перед тем, как стать пожарным, необходимо провести в тренировках минимум 600 часов? И это только начало. Согласно отчетам, пожарные тренируются до 80% своего рабочего времени.
Когда пожарный борется с реальным огнем, ему необходима соответствующая интуиция. Для того, чтобы ее выработать, приходится тренироваться час за часом, день за днем. Как говорится, практика творит чудеса.
Прим. перев.: Phillip Calvin «Phil» McGraw — американский психолог, писатель, ведущий популярной телевизионной программы «Доктор Фил», в которой ведущий предлагает своим участникам решения их проблем.
В начале 2000-х Jesse Robbins, занимавший в Amazon должность с официальным названием Master of Disaster, создал и возглавил программу GameDay. Она была основана на его опыте пожарного. GameDay предназначалась для тестирования, обучения и подготовки различных систем Amazon, программного обеспечения и людей к воздействию потенциальных кризисных ситуаций.
Подобно тому, как пожарные вырабатывают интуицию для борьбы с пожарами, Джесси собирался помочь своей команде выработать интуицию для противодействия крупномасштабным катастрофическим событиям.
«GameDay: Creating Resiliency Through Destruction» — Jesse Robbins
GameDay была призвана повысить устойчивость retail-сайта Amazon путем умышленного внедрения ошибок в критически важные системы.
GameDay начиналась с ряда объявлений на всю компанию о том, что планируется учебная тревога — иногда весьма масштабная, например, отключение целого ЦОД. Детали о планируемом отключении предоставлялись минимальные, а команде давалось несколько месяцев на подготовку. Главная цель упражнения состояла в том, чтобы проверить, сможет ли персонал справиться с локальным кризисом и оперативно устранить его последствия.
Во время этих упражнений применялись специальные инструменты и процессы, такие как мониторинг, алерты и срочные вызовы, для анализа и выявления ошибок в процедурах реагирования на инциденты. Как оказалось, GameDay прекрасно выявляет классические архитектурные проблемы. Иногда также удавалось обнаружить так называемые «скрытые дефекты» — проблемы, проявляющиеся из-за специфики инцидента. Например, системы управления инцидентами, критически важные для процесса восстановления, отказывали из-за неожиданных побочных последствий, вызванных рукотворной проблемой.
По мере роста компании расширялся теоретический радиус поражения от GameDay. В конечном итоге эти упражнения прекратились: слишком большим стал потенциальный ущерб для компании в случае, если что-то пошло бы не по плану. С тех пор программа выродилась в серию разрозненных, не оказывающих влияния на бизнес, экспериментов для обучения персонала действиям в кризисных ситуациях. Не буду углубляться в подробности экспериментов в этой статье, но сделаю это в будущем. На сей же раз хочу обсудить важную идею, лежащую в основе GameDay: инжиниринг надежности (resiliency engineering), также известный как хаос-инжиниринг (chaos engineering).
Вы, вероятно, слышали о Netflix — онлайн-поставщике видеоконтента. Netflix начал переезжать из собственного ЦОД в AWS Cloud в августе 2008-го. Этот шаг был вызван серьезным повреждением базы данных, из-за которого поставка DVD задержалась на трое суток (да, Netflix начинал с пересылки фильмов по обычной почте). Миграция в облако была связана с необходимостью выдерживать гораздо более высокие стриминговые нагрузки, а также желанием отказаться от монолитной архитектуры и перейти к микросервисам, которые легко масштабировать в зависимости от числа пользователей и размера команды инженеров. Пользовательская часть стримингового сервиса переехала на AWS первой, в период между 2010 и 2011 годами, за ним последовали корпоративные ИТ и все остальные структуры. Собственный ЦОД Netflix закрылся в 2016 году. Компания измеряет доступность как отношение числа успешных попыток запустить фильм к общему числу, а не как простое сравнение uptime и downtime, и старается достичь показателя в 0,9999 в каждом регионе на ежеквартальной основе (часто ей это удается). Глобальная архитектура Netflix охватывает три региона AWS. Таким образом, в случае возникновения проблем в одном из регионов компания имеет возможность перенаправлять пользователей на другие.
Повторю одну из моих любимых цитат:
В самом деле, сбои в распределенных системах, особенно масштабных, неизбежны даже в облаке. Однако облако AWS и его примитивы избыточности — в частности, принцип зон с множественной доступностью, на котором оно построено, — позволяет любому желающему проектировать высоконадежные сервисы.
Используя принципы избыточности (redundancy) и постепенного снижения функциональности (graceful degradation), Netflix сумел пережить сбои, не затронув конечных пользователей.
С самого начала Netflix придерживался самых жестких архитектурных принципов. Одним из первых приложений, что они развернули в AWS, стал их Chaos Monkey — для поддержки автомасштабируемых stateless-микросервисов. Другими словами, любой инстанс может быть остановлен и автоматически заменен без какой-либо потери состояния. Chaos Monkey следит за тем, чтобы никто не нарушал этот принцип.
Прим. перев.: Кстати, для Kubernetes есть аналог под названием kube-monkey, развитие которого, похоже, прекратилось в марте этого года.
У Netflix есть еще одно правило, предусматривающее распределение каждого сервиса по трем зонам доступности. Он должен продолжать работать, если доступны всего две из них. Чтобы убедиться в выполнении этого правила, Chaos Gorilla отключает зоны доступности. В более глобальном масштабе Chaos Kong способен отключить целый регион AWS, чтобы подтвердить, что все пользователи Netflix могут обслуживаться из любого из трех регионов. И они проводят эти масштабные тесты каждые несколько недель в production, чтобы убедиться, что ничто не ускользнуло от внимания.
Наконец, Netflix также разработал более узконаправленные инструменты Chaos Testing для помощи в обнаружении проблем с микросервисами и архитектурой хранения данных. Подробнее об этих техниках можно узнать из книги Chaos Engineering, которую я рекомендую всем интересующимся данной темой.
На сегодняшний день принципы хаос-инжиниринга формализованы; им дано следующее определение:
Однако в своем выступлении на AWS re:Invent-2018, посвященном хаос-инжинирингу, Adrian Cockcroft, бывший создатель облачной архитектуры Netflix, который помог компании перейти целиком на облачную инфраструктуру, представил альтернативное определение хаос-инжиниринга. На мой взгляд, оно более точное и устоявшееся:
В самом деле, мы знаем, что сбои происходят постоянно. При правильной ответной реакции они не должны влиять на конечных пользователей. Главная цель хаос-инжиниринга — обнаруживать проблемы, которые не устраняются должным образом.
Прежде чем приступить к хаос-инжинирингу, убедитесь, что проделали всю необходимую работу по обеспечению устойчивости на всех уровнях организации. Создание отказоустойчивых систем связано не только с программным обеспечением. Оно начинается на уровне инфраструктуры, распространяется на сеть и данные, влияет на структуру приложений, а в конечном итоге охватывает людей и культуру. В прошлом я много писал о моделях устойчивости и сбоях (здесь, здесь, здесь и здесь) и не буду сейчас заострять на этом внимание, однако не могу обойтись без небольшого напоминания.
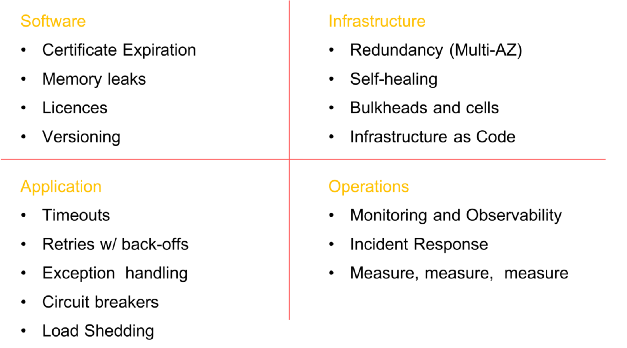
Некоторые обязательные элементы перед внедрением хаоса в систему (список не исчерпывающий)
Важно понимать, что суть хаос-инжиниринга НЕ в том, чтобы выпустить обезьян на волю и позволить им крушить все подряд, без всякой цели. Смысл этой дисциплины в том, чтобы разрушать некоторые элементы системы в контролируемой среде путем хорошо спланированных экспериментов, чтобы проверить, сможет ли ваше приложение выдержать турбулентные условия.
Для этого вы должны следовать четко определенному, формализованному процессу, приведенному на рисунке ниже. С его помощью можно перейти от понимания устойчивого состояния вашей системы к формулированию гипотезы, ее проверке и, наконец, к анализу опыта, полученного в ходе эксперимента, и повышению устойчивости самой системы.
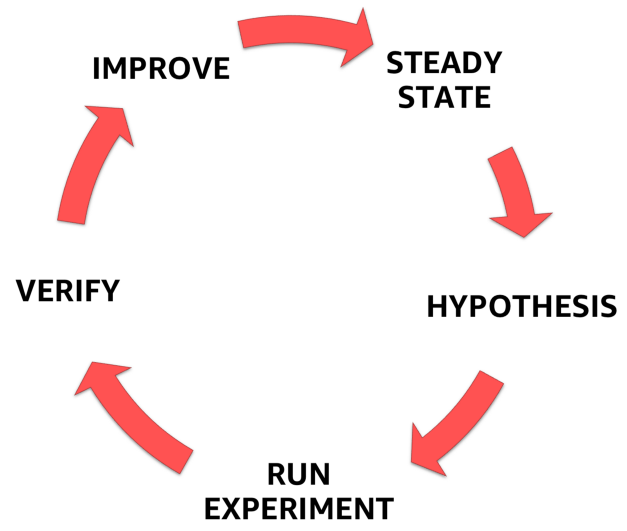
Этапы хаос-инжиниринга
Одним из наиболее важных элементов хаос-инжиниринга является понимание поведения системы в нормальных условиях.
Почему? Все просто: после внедрения искусственного сбоя вы должны убедиться, что система вернулась в хорошо изученное стабильное состояние и эксперимент больше не мешает ее нормальному поведению.
Ключевой момент здесь в том, что нужно концентрироваться не на внутренних атрибутах системы (процессоре, памяти и т. д.), а следить за измеримыми выходными сигналами, связывающими рабочие показатели с пользовательским опытом. Чтобы эти выходные сигналы находились в стабильном состоянии, наблюдаемое поведение системы должно иметь предсказуемый паттерн, но значительно меняться при возникновении сбоя в системе.
Держа в уме определение хаос-инжиниринга, предложенное выше Adrian'ом Cockcroft'ом, это стабильное состояние меняется, когда вышедший из-под контроля сбой вызывает неожиданную проблему и сигнализирует о том, что хаос-эксперимент следует прервать.
В качестве примера стабильных состояний приведем опыт Amazon. Компания использует количество заказов как одну из метрик стабильного состояния, и по веской причине. В 2007 году Грег Линден (Greg Linden), ранее работавший в Amazon, рассказал о том, как в рамках эксперимента с применением метода A/B-тестирования попробовал замедлять время загрузки страниц сайта с шагом в 100 мс и обнаружил, что даже незначительные задержки приводят к серьезному падению выручки. С увеличением времени загрузки на 100 мс количество заказов (а значит и продажи) снижалось на 1%. Именно поэтому число заказов является отличным кандидатом в метрики стабильного состояния.
Netflix же использует метрику на стороне сервера, связанную с началом воспроизведения, — число нажатий на кнопку «play». Они заметили закономерность в поведении показателя SPS (starts-per-second) и его значительные колебания при возникновении сбоев в системе. Метрика получила название «Пульс Netflix'а» (Pulse of Netflix).
Число заказов в случае Amazon и Пульс Netflix'а — отличные барометры стабильного состояния, поскольку они совмещают пользовательский опыт и операционные метрики в единый, измеримый и высоко предсказуемый показатель.
Само собой разумеется, если вы не в состоянии должным образом фиксировать показатели системы, то вы не сможете следить и за переменами в стабильном состоянии (или даже обнаруживать их). Уделите особое внимание снятию всех параметров/показателей, начиная от сетевых, аппаратных и заканчивая приложением и людьми. Нарисуйте графики этих измерений, даже если они не меняются во времени. Вы с удивлением откроете для себя корреляции, о которых не подозревали.
Разобравшись со стабильным состоянием, можно переходить к формулированию гипотезы.

Конечно, следует выбрать только одну гипотезу и не нужно усложнять ее без необходимости. Начинайте с малого. Я люблю начинать с гипотезы персонала. Слышали ли вы о факторе автобуса (bus factor)? Фактор автобуса — это мера риска, связанная с тем, что знания неравномерно распределены между членами команды. Он позволяет подсчитать минимальное количество ее участников, после внезапной потери которых проект остановится из-за недостатка знаний или опыта.
Во многих компаниях есть технические эксперты, внезапное исчезновение которых («попадание под автобус») окажет разрушительное воздействие как на проект, так и на команду. Определите этих людей и проведите хаос-эксперименты с их участием: например, заберите у них компьютеры и отправьте домой на день, а затем понаблюдайте за (часто хаотическими) результатами.
Привлеките всю команду к разработке гипотезы. Пусть в мозговом штурме участвуют все: владелец продукта, технический менеджер, backend- и frontend-разработчики, дизайнеры, архитекторы и т.д. Каждый, кто тем или иным образом связан с продуктом.
Прежде всего попросите всех самостоятельно написать ответ на вопрос «Что, если… ?» на листке бумаги. Вы увидите, что в большинстве случаев у каждого будет свой ответ, и поймете, что некоторая часть команды до сих пор вообще не задумывалась о подобной проблеме.
Остановитесь на этом моменте и обсудите, почему члены команды по-разному представляют себе поведение продукта в случае «Что, если...?». Вернитесь к его спецификациям и убедитесь, что все правильно представляют себе возможное развитие событий.
Возьмем, к примеру, упомянутый retail-сайт Amazon. Что, если сервис «Shop by Category» перестанет загружаться на главной странице?

Стоит ли возвращать ошибку 404? Стоит ли грузить страницу, оставляя пустое пространство как на скрине внизу?

Стоит ли пожертвовать частью функциональности и, например, позволить странице развернуться и скрыть ошибку?
И это только на стороне пользовательского интерфейса. Что должно произойти в backend'е? Должны ли быть посланы оповещения? Должен ли сбойный сервис продолжать получать запросы каждый раз, когда пользователь загружает домашнюю страницу, или backend должен отрезать его полностью?
И последнее. Пожалуйста, не формулируйте гипотезу, о которой заранее известно, что она наломает дров! Экспериментируйте с частями системы, которые, по вашему мнению, устойчивы — в конечном итоге, в этом и заключается весь смысл эксперимента.
Сегодня многие люди, а также сайт principlesofchaos, продвигают идею хаос-инжиниринга в production. Хотя это и должно быть конечной целью, большинство организаций этот подход пугает, поэтому не стоит начинать именно с него.
Для меня хаос-инжиниринг — это не только разрушение различных элементов production-систем. Это путешествие. Путешествие в мир познания, неразрывно связанный с таким занятием, как разрушение систем в контролируемой среде — любой среде, будь то локальное dev-окружение, beta, staging или prod. Разрушение путем хорошо спланированных экспериментов ради укрепления уверенности в способности вашего приложения перенести турбулентные условия. «Укрепление уверенности» — ключевой момент в данном случае, поскольку он является предшественником культурных изменений, необходимых для успешного внедрения хаос-инжиниринга и практики повышения надежности в вашей компании.
Честно говоря, большинство команд очень многое узнают, «ломая» вещи даже в не-production-среде. Просто попытайтесь сделать
Остановка базы данных — пример
Начинайте с малого и постепенно взращивайте уверенность внутри вашей команды и организации. Вам будут говорить, что «реальный production-трафик — это единственный способ надежно захватить поведение системы». Слушайте, улыбайтесь и продолжайте не спеша делать то, что делаете. Худшее, что можно сделать — применить хаос-инжиниринг к production и с треском провалиться. После этого вам никто не будет доверять, и вы будете вынуждены навсегда забыть об «обезьянках хаоса».
Сначала заслужите доверие. Покажите организации и коллегам, что знаете, что делаете. Станьте пожарным и узнайте об пламени как можно больше, прежде чем переходить к тренировкам с живым огнем. Заработайте себе авторитет. Помните историю о черепахе и зайце? Гонку всегда выигрывает медленный и терпеливый.
Один из самых важных моментов во время эксперимента — это понимание потенциального радиуса поражения от вводимого вами сбоя и его минимизация. Задайте себе следующие вопросы:
Подумайте о «кнопке аварийной остановки» или способе незамедлительно прервать эксперимент и вернуться в стабильное состояние как можно скорее. Я люблю проводить эксперименты с помощью т. н. «канареечных» выкатов. Эта техника позволяет снизить риск неудачи при запуске новых версий приложения в production путем постепенного выкатывания изменений на небольшое подмножество пользователей и затем их медленного распространения на всю инфраструктуру и всех пользователей. Я обожаю канареечные выкаты просто потому, что они удовлетворяют принципу неизменной инфраструктуры, да и сам эксперимент остановить довольно просто.

Пример основанного на DNS канареечного выката для хаос-экспериментов
Будьте осторожны с экспериментами, меняющими состояние приложения (кэша или базы данных) или с теми, которые невозможно откатить (легко или в принципе).
Любопытно, что Adrian Cockcroft сказал мне, что одной из причин, по которой Netflix начал использовать базы NoSQL, являлось отсутствие в них схемы для изменений или откатов, поэтому там намного проще постепенно обновлять или исправлять отдельные записи с данными (т. е. они более дружественны к хаос-инжинирингу).
Чтобы узнавать что-то новое и следить за ходом эксперимента, необходимо иметь возможность отслеживать показатели системы. Как говорилось ранее, уделите максимальное внимание всевозможным метрикам и параметрам! Затем количественно оцените результаты и всегда — всегда! — засекайте время до появления первых признаков проблемы. За мою историю неоднократно случалось так, что системы оповещения отказывали и первыми о проблеме сообщали клиенты в Twitter… поверьте мне, вы не захотите оказаться в такой ситуации, так что используйте хаос-эксперименты и для проверки ваших систем мониторинга и оповещения.
Помните, что не существует единственной изолированной причины сбоя. Крупные аварии всегда являются результатов нескольких небольших сбоев, которые накапливаются и приводят к масштабному кризису.
Проводите подробный анализ (postmortem) по итогам каждого эксперимента!
В AWS мы огромное внимание уделяем анализу обнаруженных сбоев и пониманию причин, их вызвавших, чтобы предотвратить аналогичные проблемы в будущем. Все выводы и результаты эксперимента сводятся в документ под названием Correction-of-Errors (COE). COE позволяет нам учиться на своих ошибках, будь то изъяны в технологии, процессе или даже в организации. Мы используем этот механизм для устранения глубинных причин поломок и постоянного развития.
Ключом к успеху в этом процессе являются открытость и прозрачность в отношении того, что пошло не так. Один из наиважнейших принципов при написании хорошего COE — быть беспристрастным и избегать упоминания конкретных людей. Это часто непросто в среде, которая не поощряет подобное поведение и не допускает возможности провала. Amazon использует коллекцию «принципов лидерства» (Leadership Principles) для поощрения такого поведения — например, самокритичность, аналитический подход, приверженность высочайшим стандартам и ответственность являются ключевыми компонентами процесса COE и операционного совершенства в целом.
В отчете COE имеется пять основных разделов:
На эти вопросы ответить труднее, чем представляется на первый взгляд, поскольку нужно удостовериться, что каждый непонятный/неизвестный момент тщательно изучен.
Чтобы превратить механизм COE в полноценный процесс, мы постоянно проводим проверки в форме еженедельных встреч с обязательным анализом операционных метрик. Кроме того, ведущие технические специалисты еженедельно проводят обзоры метрик с участием всего персонала AWS.
Главный урок здесь — в первую очередь устранять проблемы, выявленные в ходе хаос-экспериментов, присваивая им более высокий приоритет, чем разработке новых функций. Привлеките высшее руководство к этому процессу и внедрите ему в голову идею о том, что устранение текущих проблем гораздо важнее разработки новой функциональности.
Однажды с помощью хаос-эксперимента я помог клиенту выявить критические проблемы с устойчивостью, но из-за давления со стороны отдела продаж приоритет исправления был понижен, и все силы направлены на внедрение новой штуки, «крайне важной» для клиентов. Две недели спустя 16-часовой простой вынудил компанию заняться решением тех же самых проблем, которые мы выявили в ходе хаос-эксперимента. Только потери оказались куда выше.
Преимуществ много. Я выделю два, на мой взгляд, наиболее важных:
Во-первых, хаос-инжиниринг помогает вскрыть неизвестные проблемы в системе и исправить их до того, как они приведут к сбою production, скажем, в 3 часа ночи в воскресенье. То есть он повышает устойчивость к сбоям и, собственно, качество сна.
Во-вторых, эффективно проведенные хаос-эксперименты всегда вызывают более обширные перемены (преимущественно культурные), чем предполагалось. Пожалуй, самая важная из них — это естественная эволюция к «безвинной» (non-blaming) культуре, когда вопрос «Зачем ты это сделал?» превращается в «Как мы можем избежать этого в будущем?». В результате команда становится счастливее, эффективнее, заинтересованнее и успешнее. И это прекрасно!
На этом первая часть подходит к концу. Надеюсь, она вам понравилась. Пожалуйста, пишите отзывы, делитесь мнениями или просто хлопайте в ладоши в Medium. В следующей части я рассмотрю инструменты и методы по внедрению сбоев в системы. До тех пор — пока!
Тем, кому не терпится ознакомиться со второй частью, предлагаю свое выступление по теме хаос-инжиниринга на NDC в Осло. В нем я рассказываю о многих из любимых инструментов:
Вторая часть статьи в на английском языке уже появилась и мы её тоже переведём, если увидим достаточный интерес читателей хабра к этому материалу — соответствующие комментарии к статье приветствуются!
Читайте также в нашем блоге:
«Но за всей этой красотой скрывается хаос и безумие». — Tanner Walling
Пожарные. Эти высококвалифицированные специалисты каждый день рискуют жизнью, борясь с огнем. Знаете ли вы, что перед тем, как стать пожарным, необходимо провести в тренировках минимум 600 часов? И это только начало. Согласно отчетам, пожарные тренируются до 80% своего рабочего времени.
Почему?
Когда пожарный борется с реальным огнем, ему необходима соответствующая интуиция. Для того, чтобы ее выработать, приходится тренироваться час за часом, день за днем. Как говорится, практика творит чудеса.
«Кажется, будто они проникают в саму суть огня; этакие аналоги доктора Фила для пламени». — Fighting Wildfires With Computers and Intuition
Прим. перев.: Phillip Calvin «Phil» McGraw — американский психолог, писатель, ведущий популярной телевизионной программы «Доктор Фил», в которой ведущий предлагает своим участникам решения их проблем.
Однажды в Сиэтле
В начале 2000-х Jesse Robbins, занимавший в Amazon должность с официальным названием Master of Disaster, создал и возглавил программу GameDay. Она была основана на его опыте пожарного. GameDay предназначалась для тестирования, обучения и подготовки различных систем Amazon, программного обеспечения и людей к воздействию потенциальных кризисных ситуаций.
Подобно тому, как пожарные вырабатывают интуицию для борьбы с пожарами, Джесси собирался помочь своей команде выработать интуицию для противодействия крупномасштабным катастрофическим событиям.
«GameDay: Creating Resiliency Through Destruction» — Jesse Robbins
GameDay была призвана повысить устойчивость retail-сайта Amazon путем умышленного внедрения ошибок в критически важные системы.
GameDay начиналась с ряда объявлений на всю компанию о том, что планируется учебная тревога — иногда весьма масштабная, например, отключение целого ЦОД. Детали о планируемом отключении предоставлялись минимальные, а команде давалось несколько месяцев на подготовку. Главная цель упражнения состояла в том, чтобы проверить, сможет ли персонал справиться с локальным кризисом и оперативно устранить его последствия.
Во время этих упражнений применялись специальные инструменты и процессы, такие как мониторинг, алерты и срочные вызовы, для анализа и выявления ошибок в процедурах реагирования на инциденты. Как оказалось, GameDay прекрасно выявляет классические архитектурные проблемы. Иногда также удавалось обнаружить так называемые «скрытые дефекты» — проблемы, проявляющиеся из-за специфики инцидента. Например, системы управления инцидентами, критически важные для процесса восстановления, отказывали из-за неожиданных побочных последствий, вызванных рукотворной проблемой.
По мере роста компании расширялся теоретический радиус поражения от GameDay. В конечном итоге эти упражнения прекратились: слишком большим стал потенциальный ущерб для компании в случае, если что-то пошло бы не по плану. С тех пор программа выродилась в серию разрозненных, не оказывающих влияния на бизнес, экспериментов для обучения персонала действиям в кризисных ситуациях. Не буду углубляться в подробности экспериментов в этой статье, но сделаю это в будущем. На сей же раз хочу обсудить важную идею, лежащую в основе GameDay: инжиниринг надежности (resiliency engineering), также известный как хаос-инжиниринг (chaos engineering).
Восстание обезьян
Вы, вероятно, слышали о Netflix — онлайн-поставщике видеоконтента. Netflix начал переезжать из собственного ЦОД в AWS Cloud в августе 2008-го. Этот шаг был вызван серьезным повреждением базы данных, из-за которого поставка DVD задержалась на трое суток (да, Netflix начинал с пересылки фильмов по обычной почте). Миграция в облако была связана с необходимостью выдерживать гораздо более высокие стриминговые нагрузки, а также желанием отказаться от монолитной архитектуры и перейти к микросервисам, которые легко масштабировать в зависимости от числа пользователей и размера команды инженеров. Пользовательская часть стримингового сервиса переехала на AWS первой, в период между 2010 и 2011 годами, за ним последовали корпоративные ИТ и все остальные структуры. Собственный ЦОД Netflix закрылся в 2016 году. Компания измеряет доступность как отношение числа успешных попыток запустить фильм к общему числу, а не как простое сравнение uptime и downtime, и старается достичь показателя в 0,9999 в каждом регионе на ежеквартальной основе (часто ей это удается). Глобальная архитектура Netflix охватывает три региона AWS. Таким образом, в случае возникновения проблем в одном из регионов компания имеет возможность перенаправлять пользователей на другие.
Повторю одну из моих любимых цитат:
«Сбои — это неизбежность; в конечном итоге любая система со временем рухнет». — Werner Vogels
В самом деле, сбои в распределенных системах, особенно масштабных, неизбежны даже в облаке. Однако облако AWS и его примитивы избыточности — в частности, принцип зон с множественной доступностью, на котором оно построено, — позволяет любому желающему проектировать высоконадежные сервисы.
Используя принципы избыточности (redundancy) и постепенного снижения функциональности (graceful degradation), Netflix сумел пережить сбои, не затронув конечных пользователей.
С самого начала Netflix придерживался самых жестких архитектурных принципов. Одним из первых приложений, что они развернули в AWS, стал их Chaos Monkey — для поддержки автомасштабируемых stateless-микросервисов. Другими словами, любой инстанс может быть остановлен и автоматически заменен без какой-либо потери состояния. Chaos Monkey следит за тем, чтобы никто не нарушал этот принцип.
Прим. перев.: Кстати, для Kubernetes есть аналог под названием kube-monkey, развитие которого, похоже, прекратилось в марте этого года.
У Netflix есть еще одно правило, предусматривающее распределение каждого сервиса по трем зонам доступности. Он должен продолжать работать, если доступны всего две из них. Чтобы убедиться в выполнении этого правила, Chaos Gorilla отключает зоны доступности. В более глобальном масштабе Chaos Kong способен отключить целый регион AWS, чтобы подтвердить, что все пользователи Netflix могут обслуживаться из любого из трех регионов. И они проводят эти масштабные тесты каждые несколько недель в production, чтобы убедиться, что ничто не ускользнуло от внимания.
Наконец, Netflix также разработал более узконаправленные инструменты Chaos Testing для помощи в обнаружении проблем с микросервисами и архитектурой хранения данных. Подробнее об этих техниках можно узнать из книги Chaos Engineering, которую я рекомендую всем интересующимся данной темой.
«Проводя эксперименты на регулярной основе, имитирующие региональные отключения, мы смогли на раннем этапе выявить различные системные недостатки и устранить их». — блог Netflix
На сегодняшний день принципы хаос-инжиниринга формализованы; им дано следующее определение:
«Хаос-инжиниринг — это подход, предусматривающий проведение экспериментов над production-системой, чтобы убедиться в ее способности выдерживать различные помехи, возникающие во время работы». — principlesofchaos.org
Однако в своем выступлении на AWS re:Invent-2018, посвященном хаос-инжинирингу, Adrian Cockcroft, бывший создатель облачной архитектуры Netflix, который помог компании перейти целиком на облачную инфраструктуру, представил альтернативное определение хаос-инжиниринга. На мой взгляд, оно более точное и устоявшееся:
«Хаос-инжиниринг — это эксперимент, призванный смягчить последствия сбоев».
В самом деле, мы знаем, что сбои происходят постоянно. При правильной ответной реакции они не должны влиять на конечных пользователей. Главная цель хаос-инжиниринга — обнаруживать проблемы, которые не устраняются должным образом.
Необходимые условия для создания хаоса
Прежде чем приступить к хаос-инжинирингу, убедитесь, что проделали всю необходимую работу по обеспечению устойчивости на всех уровнях организации. Создание отказоустойчивых систем связано не только с программным обеспечением. Оно начинается на уровне инфраструктуры, распространяется на сеть и данные, влияет на структуру приложений, а в конечном итоге охватывает людей и культуру. В прошлом я много писал о моделях устойчивости и сбоях (здесь, здесь, здесь и здесь) и не буду сейчас заострять на этом внимание, однако не могу обойтись без небольшого напоминания.
Некоторые обязательные элементы перед внедрением хаоса в систему (список не исчерпывающий)
Этапы хаос-инжиниринга
Важно понимать, что суть хаос-инжиниринга НЕ в том, чтобы выпустить обезьян на волю и позволить им крушить все подряд, без всякой цели. Смысл этой дисциплины в том, чтобы разрушать некоторые элементы системы в контролируемой среде путем хорошо спланированных экспериментов, чтобы проверить, сможет ли ваше приложение выдержать турбулентные условия.
Для этого вы должны следовать четко определенному, формализованному процессу, приведенному на рисунке ниже. С его помощью можно перейти от понимания устойчивого состояния вашей системы к формулированию гипотезы, ее проверке и, наконец, к анализу опыта, полученного в ходе эксперимента, и повышению устойчивости самой системы.
Этапы хаос-инжиниринга
1. Стабильное состояние
Одним из наиболее важных элементов хаос-инжиниринга является понимание поведения системы в нормальных условиях.
Почему? Все просто: после внедрения искусственного сбоя вы должны убедиться, что система вернулась в хорошо изученное стабильное состояние и эксперимент больше не мешает ее нормальному поведению.
Ключевой момент здесь в том, что нужно концентрироваться не на внутренних атрибутах системы (процессоре, памяти и т. д.), а следить за измеримыми выходными сигналами, связывающими рабочие показатели с пользовательским опытом. Чтобы эти выходные сигналы находились в стабильном состоянии, наблюдаемое поведение системы должно иметь предсказуемый паттерн, но значительно меняться при возникновении сбоя в системе.
Держа в уме определение хаос-инжиниринга, предложенное выше Adrian'ом Cockcroft'ом, это стабильное состояние меняется, когда вышедший из-под контроля сбой вызывает неожиданную проблему и сигнализирует о том, что хаос-эксперимент следует прервать.
В качестве примера стабильных состояний приведем опыт Amazon. Компания использует количество заказов как одну из метрик стабильного состояния, и по веской причине. В 2007 году Грег Линден (Greg Linden), ранее работавший в Amazon, рассказал о том, как в рамках эксперимента с применением метода A/B-тестирования попробовал замедлять время загрузки страниц сайта с шагом в 100 мс и обнаружил, что даже незначительные задержки приводят к серьезному падению выручки. С увеличением времени загрузки на 100 мс количество заказов (а значит и продажи) снижалось на 1%. Именно поэтому число заказов является отличным кандидатом в метрики стабильного состояния.
Netflix же использует метрику на стороне сервера, связанную с началом воспроизведения, — число нажатий на кнопку «play». Они заметили закономерность в поведении показателя SPS (starts-per-second) и его значительные колебания при возникновении сбоев в системе. Метрика получила название «Пульс Netflix'а» (Pulse of Netflix).
Число заказов в случае Amazon и Пульс Netflix'а — отличные барометры стабильного состояния, поскольку они совмещают пользовательский опыт и операционные метрики в единый, измеримый и высоко предсказуемый показатель.
Измеряйте, измеряйте и еще раз измеряйте
Само собой разумеется, если вы не в состоянии должным образом фиксировать показатели системы, то вы не сможете следить и за переменами в стабильном состоянии (или даже обнаруживать их). Уделите особое внимание снятию всех параметров/показателей, начиная от сетевых, аппаратных и заканчивая приложением и людьми. Нарисуйте графики этих измерений, даже если они не меняются во времени. Вы с удивлением откроете для себя корреляции, о которых не подозревали.
«Максимально упростите инженерам доступ к данным, которые они могут посчитать или перевести в графическую форму». — Ian Malpass
2. Гипотеза
Разобравшись со стабильным состоянием, можно переходить к формулированию гипотезы.
- Что, если остановится механизм рекомендаций?
- Что, если упадет балансировщик нагрузки?
- Что, если отвалится кэширование?
- Что, если задержка возрастет на 300 мс?
- Что, если упадет master-база?
Конечно, следует выбрать только одну гипотезу и не нужно усложнять ее без необходимости. Начинайте с малого. Я люблю начинать с гипотезы персонала. Слышали ли вы о факторе автобуса (bus factor)? Фактор автобуса — это мера риска, связанная с тем, что знания неравномерно распределены между членами команды. Он позволяет подсчитать минимальное количество ее участников, после внезапной потери которых проект остановится из-за недостатка знаний или опыта.
Во многих компаниях есть технические эксперты, внезапное исчезновение которых («попадание под автобус») окажет разрушительное воздействие как на проект, так и на команду. Определите этих людей и проведите хаос-эксперименты с их участием: например, заберите у них компьютеры и отправьте домой на день, а затем понаблюдайте за (часто хаотическими) результатами.
Сделайте проблему общей для всех!
Привлеките всю команду к разработке гипотезы. Пусть в мозговом штурме участвуют все: владелец продукта, технический менеджер, backend- и frontend-разработчики, дизайнеры, архитекторы и т.д. Каждый, кто тем или иным образом связан с продуктом.
Прежде всего попросите всех самостоятельно написать ответ на вопрос «Что, если… ?» на листке бумаги. Вы увидите, что в большинстве случаев у каждого будет свой ответ, и поймете, что некоторая часть команды до сих пор вообще не задумывалась о подобной проблеме.
Остановитесь на этом моменте и обсудите, почему члены команды по-разному представляют себе поведение продукта в случае «Что, если...?». Вернитесь к его спецификациям и убедитесь, что все правильно представляют себе возможное развитие событий.
Возьмем, к примеру, упомянутый retail-сайт Amazon. Что, если сервис «Shop by Category» перестанет загружаться на главной странице?
Стоит ли возвращать ошибку 404? Стоит ли грузить страницу, оставляя пустое пространство как на скрине внизу?
Стоит ли пожертвовать частью функциональности и, например, позволить странице развернуться и скрыть ошибку?
И это только на стороне пользовательского интерфейса. Что должно произойти в backend'е? Должны ли быть посланы оповещения? Должен ли сбойный сервис продолжать получать запросы каждый раз, когда пользователь загружает домашнюю страницу, или backend должен отрезать его полностью?
И последнее. Пожалуйста, не формулируйте гипотезу, о которой заранее известно, что она наломает дров! Экспериментируйте с частями системы, которые, по вашему мнению, устойчивы — в конечном итоге, в этом и заключается весь смысл эксперимента.
3. Разработайте и проведите эксперимент
- Выберите одну гипотезу;
- Определите рамки эксперимента;
- Определите связанные показатели, измерение которых будет проводиться;
- Известите организацию.
Сегодня многие люди, а также сайт principlesofchaos, продвигают идею хаос-инжиниринга в production. Хотя это и должно быть конечной целью, большинство организаций этот подход пугает, поэтому не стоит начинать именно с него.
Для меня хаос-инжиниринг — это не только разрушение различных элементов production-систем. Это путешествие. Путешествие в мир познания, неразрывно связанный с таким занятием, как разрушение систем в контролируемой среде — любой среде, будь то локальное dev-окружение, beta, staging или prod. Разрушение путем хорошо спланированных экспериментов ради укрепления уверенности в способности вашего приложения перенести турбулентные условия. «Укрепление уверенности» — ключевой момент в данном случае, поскольку он является предшественником культурных изменений, необходимых для успешного внедрения хаос-инжиниринга и практики повышения надежности в вашей компании.
Честно говоря, большинство команд очень многое узнают, «ломая» вещи даже в не-production-среде. Просто попытайтесь сделать
docker stop database в локальном окружении и посмотрите, сможете ли вы без последствий справиться с этой проблемой. Высока вероятность, что нет.Остановка базы данных — пример
Начинайте с малого и постепенно взращивайте уверенность внутри вашей команды и организации. Вам будут говорить, что «реальный production-трафик — это единственный способ надежно захватить поведение системы». Слушайте, улыбайтесь и продолжайте не спеша делать то, что делаете. Худшее, что можно сделать — применить хаос-инжиниринг к production и с треском провалиться. После этого вам никто не будет доверять, и вы будете вынуждены навсегда забыть об «обезьянках хаоса».
Сначала заслужите доверие. Покажите организации и коллегам, что знаете, что делаете. Станьте пожарным и узнайте об пламени как можно больше, прежде чем переходить к тренировкам с живым огнем. Заработайте себе авторитет. Помните историю о черепахе и зайце? Гонку всегда выигрывает медленный и терпеливый.
Один из самых важных моментов во время эксперимента — это понимание потенциального радиуса поражения от вводимого вами сбоя и его минимизация. Задайте себе следующие вопросы:
- Какое количество клиентов затронет эксперимент?
- Какая функциональность пострадает?
- Какие места будут затронуты?
Подумайте о «кнопке аварийной остановки» или способе незамедлительно прервать эксперимент и вернуться в стабильное состояние как можно скорее. Я люблю проводить эксперименты с помощью т. н. «канареечных» выкатов. Эта техника позволяет снизить риск неудачи при запуске новых версий приложения в production путем постепенного выкатывания изменений на небольшое подмножество пользователей и затем их медленного распространения на всю инфраструктуру и всех пользователей. Я обожаю канареечные выкаты просто потому, что они удовлетворяют принципу неизменной инфраструктуры, да и сам эксперимент остановить довольно просто.
Пример основанного на DNS канареечного выката для хаос-экспериментов
Будьте осторожны с экспериментами, меняющими состояние приложения (кэша или базы данных) или с теми, которые невозможно откатить (легко или в принципе).
Любопытно, что Adrian Cockcroft сказал мне, что одной из причин, по которой Netflix начал использовать базы NoSQL, являлось отсутствие в них схемы для изменений или откатов, поэтому там намного проще постепенно обновлять или исправлять отдельные записи с данными (т. е. они более дружественны к хаос-инжинирингу).
4. Наблюдайте и учитесь
Чтобы узнавать что-то новое и следить за ходом эксперимента, необходимо иметь возможность отслеживать показатели системы. Как говорилось ранее, уделите максимальное внимание всевозможным метрикам и параметрам! Затем количественно оцените результаты и всегда — всегда! — засекайте время до появления первых признаков проблемы. За мою историю неоднократно случалось так, что системы оповещения отказывали и первыми о проблеме сообщали клиенты в Twitter… поверьте мне, вы не захотите оказаться в такой ситуации, так что используйте хаос-эксперименты и для проверки ваших систем мониторинга и оповещения.
- Время до обнаружения?
- Время до оповещения и начала активных действий?
- Время до публичного уведомления?
- Время до частичной потери функционала?
- Длительность периода самовосстановления?
- Время до полного или частичного восстановления?
- Время до окончания кризиса и возврата в стабильное состояние?
Помните, что не существует единственной изолированной причины сбоя. Крупные аварии всегда являются результатов нескольких небольших сбоев, которые накапливаются и приводят к масштабному кризису.
Проводите подробный анализ (postmortem) по итогам каждого эксперимента!
В AWS мы огромное внимание уделяем анализу обнаруженных сбоев и пониманию причин, их вызвавших, чтобы предотвратить аналогичные проблемы в будущем. Все выводы и результаты эксперимента сводятся в документ под названием Correction-of-Errors (COE). COE позволяет нам учиться на своих ошибках, будь то изъяны в технологии, процессе или даже в организации. Мы используем этот механизм для устранения глубинных причин поломок и постоянного развития.
Ключом к успеху в этом процессе являются открытость и прозрачность в отношении того, что пошло не так. Один из наиважнейших принципов при написании хорошего COE — быть беспристрастным и избегать упоминания конкретных людей. Это часто непросто в среде, которая не поощряет подобное поведение и не допускает возможности провала. Amazon использует коллекцию «принципов лидерства» (Leadership Principles) для поощрения такого поведения — например, самокритичность, аналитический подход, приверженность высочайшим стандартам и ответственность являются ключевыми компонентами процесса COE и операционного совершенства в целом.
В отчете COE имеется пять основных разделов:
- Что произошло (хронологический порядок)?
- Каким было воздействие на клиентов?
- Почему произошла ошибка? (Пять «почему?»)
- Что мы узнали?
- Как предотвратить это в будущем?
На эти вопросы ответить труднее, чем представляется на первый взгляд, поскольку нужно удостовериться, что каждый непонятный/неизвестный момент тщательно изучен.
Чтобы превратить механизм COE в полноценный процесс, мы постоянно проводим проверки в форме еженедельных встреч с обязательным анализом операционных метрик. Кроме того, ведущие технические специалисты еженедельно проводят обзоры метрик с участием всего персонала AWS.
5. Исправляйте и улучшайте!
Главный урок здесь — в первую очередь устранять проблемы, выявленные в ходе хаос-экспериментов, присваивая им более высокий приоритет, чем разработке новых функций. Привлеките высшее руководство к этому процессу и внедрите ему в голову идею о том, что устранение текущих проблем гораздо важнее разработки новой функциональности.
Однажды с помощью хаос-эксперимента я помог клиенту выявить критические проблемы с устойчивостью, но из-за давления со стороны отдела продаж приоритет исправления был понижен, и все силы направлены на внедрение новой штуки, «крайне важной» для клиентов. Две недели спустя 16-часовой простой вынудил компанию заняться решением тех же самых проблем, которые мы выявили в ходе хаос-эксперимента. Только потери оказались куда выше.
Преимущества хаос-инжиниринга
Преимуществ много. Я выделю два, на мой взгляд, наиболее важных:
Во-первых, хаос-инжиниринг помогает вскрыть неизвестные проблемы в системе и исправить их до того, как они приведут к сбою production, скажем, в 3 часа ночи в воскресенье. То есть он повышает устойчивость к сбоям и, собственно, качество сна.
Во-вторых, эффективно проведенные хаос-эксперименты всегда вызывают более обширные перемены (преимущественно культурные), чем предполагалось. Пожалуй, самая важная из них — это естественная эволюция к «безвинной» (non-blaming) культуре, когда вопрос «Зачем ты это сделал?» превращается в «Как мы можем избежать этого в будущем?». В результате команда становится счастливее, эффективнее, заинтересованнее и успешнее. И это прекрасно!
На этом первая часть подходит к концу. Надеюсь, она вам понравилась. Пожалуйста, пишите отзывы, делитесь мнениями или просто хлопайте в ладоши в Medium. В следующей части я рассмотрю инструменты и методы по внедрению сбоев в системы. До тех пор — пока!
Тем, кому не терпится ознакомиться со второй частью, предлагаю свое выступление по теме хаос-инжиниринга на NDC в Осло. В нем я рассказываю о многих из любимых инструментов:
P.S. от переводчика
Вторая часть статьи в на английском языке уже появилась и мы её тоже переведём, если увидим достаточный интерес читателей хабра к этому материалу — соответствующие комментарии к статье приветствуются!
Читайте также в нашем блоге: