
Прим. перев.: Ведущий инженер из компании Zalando — Henning Jacobs — не раз замечал у пользователей Kubernetes проблемы в понимании предназначения liveness (и readiness) probes и их корректного применения. Посему он собрал свои мысли в эту ёмкую заметку, которая со временем станет частью документации K8s.

Проверки состояния, известные в Kubernetes как liveness probes (т.е., дословно, «тесты на жизнеспособность» — прим. перев.), могут быть весьма опасными. Рекомендую по возможности избегать их: исключениями являются только случаи, когда они действительно необходимы и вы полностью осознаете специфику и последствия их использования. В этой публикации речь пойдет о liveness- и readiness-проверках, а также будет рассказано, в каких случаях стоит и не стоит их применять.
Мой коллега Sandor недавно поделился в Twitter'е самыми частыми ошибками, которые ему встречаются, в том числе связанными с использованием readiness/liveness probes:
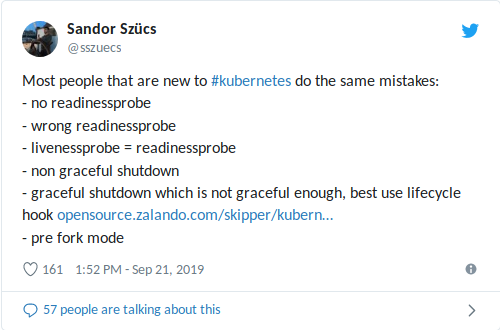
Неправильно настроенная
Общий посыл «Не используйте liveness probes» в данном случае помогает мало, поэтому рассмотрим, для чего предназначены readiness- и liveness-проверки.
Примечание: б?льшая часть приведенного ниже теста изначально была включена во внутреннюю документацию для разработчиков Zalando.
Kubernetes предоставляет два важных механизма, называемых liveness probes и readiness probes. Они периодически выполняют некоторое действие — например, посылают HTTP-запрос, открывают TCP-соединение или выполняют команду в контейнере, — чтобы подтвердить, что приложение работает должным образом.
Kubernetes использует readiness probes, чтобы понять, когда контейнер готов принимать трафик. Pod считается готовым к работе, если все его контейнеры готовы. Одно из применений этого механизма состоит в том, чтобы контролировать, какие pod'ы используются в качестве бэкендов для сервисов Kubernetes (и особенно Ingress'а).
Liveness probes помогают Kubernetes понять, когда пришло время перезапустить контейнер. Например, подобная проверка позволяет перехватить deadlock, когда приложение «застревает» на одном месте. Перезапуск контейнера в таком состоянии помогает сдвинуть приложение с мертвой точки, несмотря на ошибки, при этом он же может привести к каскадным сбоям (см. ниже).
Если вы попытаетесь развернуть обновление приложения, которое проваливает проверки liveness/readiness, его выкатывание застопорится, поскольку Kubernetes будет ждать статуса
Вот пример readiness probe, проверяющей путь

Об init-контейнерах для миграции БД: добавлена сноска.
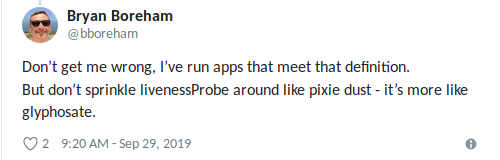
EJ напомнил мне о PDB: одна из бед liveness-проверок — отсутствие координации между pod'ами. В Kubernetes есть Pod Disruption Budgets (PDB) для ограничения числа параллельных сбоев, которое может испытывать приложение, однако проверки не учитывают PDB. В идеале мы можем приказать K8s: «Перезапусти один pod, если его проверка окажется неудачной, но не перезапускай их все, чтобы не сделать еще хуже».
Bryan отлично сформулировал: «Используйте liveness-зондирование, когда точно знаете, что лучшее, что можно сделать, — это «убить» приложение» (опять же, увлекаться не стоит).
Касаемо чтения документации перед использованием: я создал соответствующий запрос (feature request) на дополнение документации о liveness probes.
Читайте также в нашем блоге:
Проверки состояния, известные в Kubernetes как liveness probes (т.е., дословно, «тесты на жизнеспособность» — прим. перев.), могут быть весьма опасными. Рекомендую по возможности избегать их: исключениями являются только случаи, когда они действительно необходимы и вы полностью осознаете специфику и последствия их использования. В этой публикации речь пойдет о liveness- и readiness-проверках, а также будет рассказано, в каких случаях стоит и не стоит их применять.
Мой коллега Sandor недавно поделился в Twitter'е самыми частыми ошибками, которые ему встречаются, в том числе связанными с использованием readiness/liveness probes:
Неправильно настроенная
livenessProbe может усугубить ситуации с высокой нагрузкой (лавинообразное отключение + потенциально долгий запуск контейнера/приложения) и привести к другим негативным последствиям вроде падения зависимостей (см. также мою недавнюю статью об ограничении числа запросов в связке K3s+ACME). Еще хуже, когда liveness probe сочетается с проверкой здоровья зависимости (health check'ом), в роли которой выступает внешняя база данных: единственный сбой БД перезапустит все ваши контейнеры!Общий посыл «Не используйте liveness probes» в данном случае помогает мало, поэтому рассмотрим, для чего предназначены readiness- и liveness-проверки.
Примечание: б?льшая часть приведенного ниже теста изначально была включена во внутреннюю документацию для разработчиков Zalando.
Проверки Readiness и Liveness
Kubernetes предоставляет два важных механизма, называемых liveness probes и readiness probes. Они периодически выполняют некоторое действие — например, посылают HTTP-запрос, открывают TCP-соединение или выполняют команду в контейнере, — чтобы подтвердить, что приложение работает должным образом.
Kubernetes использует readiness probes, чтобы понять, когда контейнер готов принимать трафик. Pod считается готовым к работе, если все его контейнеры готовы. Одно из применений этого механизма состоит в том, чтобы контролировать, какие pod'ы используются в качестве бэкендов для сервисов Kubernetes (и особенно Ingress'а).
Liveness probes помогают Kubernetes понять, когда пришло время перезапустить контейнер. Например, подобная проверка позволяет перехватить deadlock, когда приложение «застревает» на одном месте. Перезапуск контейнера в таком состоянии помогает сдвинуть приложение с мертвой точки, несмотря на ошибки, при этом он же может привести к каскадным сбоям (см. ниже).
Если вы попытаетесь развернуть обновление приложения, которое проваливает проверки liveness/readiness, его выкатывание застопорится, поскольку Kubernetes будет ждать статуса
Ready от всех pod'ов.Пример
Вот пример readiness probe, проверяющей путь
/health через HTTP с настройками по умолчанию (interval: 10 секунд, timeout: 1 секунда, success threshold: 1, failure threshold: 3):# часть общего описания deployment'а/стека
podTemplate:
spec:
containers:
- name: my-container
# ...
readinessProbe:
httpGet:
path: /health
port: 8080Рекомендации
- Для микросервисов с HTTP endpoint'ом (REST и т.п.) всегда определяйте readiness probe, которая проверяет, готово ли приложение (pod) принимать трафик.
- Убедитесь, что readiness probe покрывает готовность фактического порта веб-сервера:
- используя порты для административных нужд, называемых «admin» или «management» (например, 9090), для
readinessProbe, убедитесь, что endpoint возвращает ОК только в том случае, если основной HTTP-порт (вроде 8080) готов принимать трафик*;
* Мне известно по крайне мере об одном случае в Zalando, когда этого не произошло, то естьreadinessProbeпроверила порт «management», но сам сервер так и не начал работать из-за проблем с загрузкой кэша. - навешивание readiness probe на отдельный порт может привести к тому, что перегрузка на основном порте не будет отражаться в health check'е (то есть пул потоков на сервере заполнен, однако health check по-прежнему показывает, что все ОК).
- используя порты для административных нужд, называемых «admin» или «management» (например, 9090), для
- Убедитесь, что readiness probe включает инициализацию/миграцию базы данных;
- самый простой способ добиться этого — обращаться к HTTP-серверу только после окончания инициализации (например, миграции БД с Flyway и т.п.); то есть вместо того, чтобы менять статус health check'а, просто не запускайте веб-сервер до завершения миграции БД*.
* Также можно запускать миграции БД из init-контейнеров снаружи pod'а. Я по-прежнему являюсь поклонником самостоятельных (self-contained) приложений, то есть таких, в которых контейнер приложения без внешней координации знает, как привести БД в нужное состояние.
- самый простой способ добиться этого — обращаться к HTTP-серверу только после окончания инициализации (например, миграции БД с Flyway и т.п.); то есть вместо того, чтобы менять статус health check'а, просто не запускайте веб-сервер до завершения миграции БД*.
- Используйте
httpGetдля readiness-проверок через типичные endpoint'ы health check'ов (например,/health). - Разберитесь в параметрах проверок, заданных по умолчанию (
interval: 10s,timeout: 1s,successThreshold: 1,failureThreshold: 3):- параметры по умолчанию означают, что pod станет not-ready примерно через 30 секунд (3 неудачных проверок работоспособности).
- Используйте отдельный порт для «admin» или «management», если технологический стек (к примеру, Java/Spring) позволяет это, чтобы отделить управление «здоровьем» и метриками от обычного трафика:
- но не забывайте о пункте 2.
- При необходимости readiness probe можно использовать для разогрева/загрузки кэша и возвращать код состояния 503, пока контейнер не «разогреется»:
- также рекомендую ознакомиться с новой проверкой
startupProbe, появившейся в версии 1.16 (мы писали о ней на русском здесь — прим. перев.).
- также рекомендую ознакомиться с новой проверкой
Предостережения
- Не полагайтесь на внешние зависимости (такие как хранилища данных) при проведении тестов на readiness/liveness — это может привести к каскадным сбоям:
- в качестве примера возьмем stateful-сервис REST с 10-ю pod'ами, зависящими от одной базы данных Postgres: когда проверка зависит от работающего подключения к БД, все 10 pod'ов могут упасть, если возникнет задержка в сети/на стороне БД — обычно все это заканчивается хуже, чем могло бы;
- обратите внимание, что Spring Data по умолчанию проверяет соединение с БД*;
* Таково поведение по умолчанию Spring Data Redis (по крайней мере, оно было таким, когда я проверял в прошлый раз), что привело к «катастрофическому» сбою: когда на короткое время Redis оказался недоступен, все pod'ы «упали». - «внешний» в данном смысле также может означать другие pod'ы того же приложения, то есть в идеале проверка не должна зависеть от состояния других pod'ов того же кластера для предотвращения каскадных падений:
- результаты могут варьироваться для приложений с распределенным состоянием (например, in-memory-кэширование в pod'ах).
- Не используйте liveness probe для pod'ов (исключениями являются случаи, когда они действительно необходимы и вы полностью осознаете специфику и последствия их применения):
- liveness probe может способствовать восстановлению «зависших» контейнеров, но, поскольку вы имеете полный контроль над своим приложением, таких вещей, как «зависшие» процессы и deadlock'и, в идеале не должно случаться: лучшей альтернативой является намеренное падение приложения и его возвращение к предыдущему устойчивому состоянию;
- неудавшаяся liveness probe приведет к перезапуску контейнера, тем самым потенциально усугубляя последствия ошибок, связанных с загрузкой: перезапуск контейнера приведет к простою (по крайней мере, на время запуска приложения, скажем, на 30 с лишним секунд), вызывая новые ошибки, увеличивая нагрузку на другие контейнеры и повышая вероятность их сбоя, и т.д.;
- liveness-проверки в сочетании с внешней зависимостью — худшая из возможных комбинаций, грозящая каскадными отказами: незначительная задержка на стороне БД приведет к перезапуску всех ваших контейнеров!
- Параметры liveness- и readiness-проверок должны быть разными:
- можно использовать liveness probe с тем же health check'ом, но более высоким порогом срабатывания (
failureThreshold), например, присваивать статус not-ready после 3 попыток и считать, что liveness probe провалился после 10 попыток;
- можно использовать liveness probe с тем же health check'ом, но более высоким порогом срабатывания (
- Не используйте exec-проверки, поскольку с ними связаны известные проблемы, приводящие к появлению зомби-процессов:
- подробности: см. выступление специалистов компании Datadog.
Резюме
- Используйте readiness probes, чтобы определить, когда pod готов принимать трафик.
- Используйте liveness probes только тогда, когда они действительно необходимы.
- Неверное использование readiness/liveness probes может привести к снижению доступности и каскадным сбоям.
Дополнительные материалы по теме
- Kubernetes docs: Configure Liveness and Readiness Probes;
- Kubernetes Liveness and Readiness Probes Revisited: How to Avoid Shooting Yourself in the Other Foot;
- NRE Labs Outage Post-Mortem (рассказывает и про livenessProbe).
Обновление №1 от 2019-09-29
Об init-контейнерах для миграции БД: добавлена сноска.
EJ напомнил мне о PDB: одна из бед liveness-проверок — отсутствие координации между pod'ами. В Kubernetes есть Pod Disruption Budgets (PDB) для ограничения числа параллельных сбоев, которое может испытывать приложение, однако проверки не учитывают PDB. В идеале мы можем приказать K8s: «Перезапусти один pod, если его проверка окажется неудачной, но не перезапускай их все, чтобы не сделать еще хуже».
Bryan отлично сформулировал: «Используйте liveness-зондирование, когда точно знаете, что лучшее, что можно сделать, — это «убить» приложение» (опять же, увлекаться не стоит).
Обновление №2 от 2019-09-29
Касаемо чтения документации перед использованием: я создал соответствующий запрос (feature request) на дополнение документации о liveness probes.
P.S. от переводчика
Читайте также в нашем блоге:
celebrate
А вот в 1.16 еще startupProbe появилась.
shurup
Про неё ведь автор оригинала написал, а мы даже ссылку на свою статью про релиз добавили… :-) «Рекомендации» > №7.