
Прим. перев.: этот материал от образовательного проекта learnk8s — ответ на популярный вопрос при проектировании инфраструктуры на базе Kubernetes. Надеемся, что достаточно развёрнутые описания плюсов и минусов каждого из вариантов помогут сделать оптимальный выбор и для вашего проекта.

TL;DR: один и тот же набор рабочих нагрузок можно запустить на нескольких крупных кластерах (на каждый кластер будет приходиться большое число workload'ов) или на множестве мелких (с малым числом нагрузок в каждом кластере).
Ниже приведена таблица, в которой оцениваются плюсы и минусы каждого подхода:

При использовании Kubernetes в качестве платформы для эксплуатации приложений часто возникают несколько фундаментальных вопросов о тонкостях настройки кластеров:
В этой статье я попытаюсь ответить на все эти вопросы, проанализировав плюсы и минусы каждого подхода.
Как создатель ПО, вы скорее всего параллельно разрабатываете и эксплуатируете множество приложений.
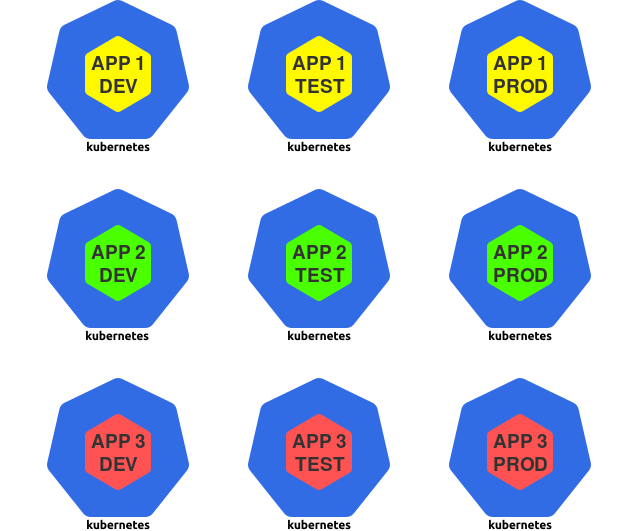
Кроме того, множество экземпляров этих приложений наверняка запускаются в различных окружениях — к примеру, это могут быть dev, test и prod.
В результате получается целая матрица из приложений и окружений:

Приложения и окружения
В приведенном выше примере представлены 3 приложения и 3 окружения, что в итоге дает 9 возможных вариантов.
Каждый экземпляр приложения представляет собой самодостаточную deployment-единицу, с которой можно работать независимо от других.
Обратите внимание, что экземпляр приложения может состоять из множества компонентов, таких как фронтенд, бэкенд, база данных и т.д. В случае микросервисного приложения экземпляр будет включать в себя все микросервисы.
В результате у пользователей Kubernetes возникают несколько вопросов:
Все эти варианты вполне жизнеспособны, поскольку Kubernetes — это гибкая система, которая не ограничивает пользователя в возможностях.
Вот некоторые из возможных путей:
Как показано ниже, первые два подхода находятся на противоположных концах шкалы вариантов:
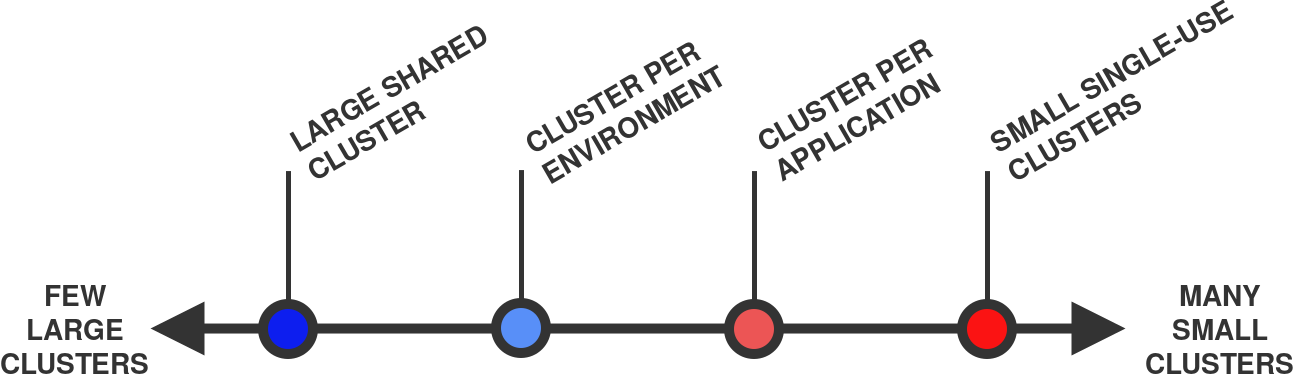
От нескольких больших кластеров (слева) до множества маленьких (справа)
В общем случае считается, что один кластер «больше» другого если у него больше сумма узлов и pod'ов. Например, кластер с 10-ю узлами и 100 pod'ами больше кластера с 1-м узлом и 10-ю pod'ами.
Что ж, давайте начнем!
Первый вариант — разместить все рабочие нагрузки в одном кластере:

Один большой кластер
В рамках этого подхода кластер используется как универсальная инфраструктурная платформа — все необходимое вы просто разворачиваете в существующем кластере Kubernetes.
Namespace'ы Kubernetes позволяют логически отделить части кластера друг от друга, так что для каждого экземпляра приложения можно использовать свое пространство имен.
Давайте рассмотрим плюсы и минусы этого подхода.
В случае единственного кластера потребуется лишь одна копия всех ресурсов, необходимых для запуска кластера Kubernetes и управления им.
Например, это справедливо для мастер-узлов. Обычно на каждый кластер Kubernetes приходится по 3 мастер-узла, поэтому для одного единственного кластера их число таким и останется (для сравнения, 10 кластерам понадобятся 30 мастер-узлов).
Вышеуказанная тонкость относится и другим сервисам, функционирующим в масштабах всего кластера, таким как балансировщики нагрузки, контроллеры Ingress, системы аутентификации, логирования и мониторинга.
В едином кластере все эти сервисы можно использовать сразу для всех рабочих нагрузок (не нужно создавать их копии, как в случае нескольких кластеров).
Как следствие вышеизложенного, меньшее число кластеров обычно обходится дешевле, поскольку отсутствуют расходы на избыточные ресурсы.
Это особенно справедливо для мастер-узлов, которые могут стоить значительных денег независимо от способа размещения (on-premises или в облаке).
Некоторые управляемые (managed) сервисы Kubernetes, такие как Google Kubernetes Engine (GKE) или Azure Kubernetes Service (AKS), предоставляют управляющий слой бесплатно. В данном случае вопрос затрат стоит менее остро.
Также существуют managed-сервисы, взимающие фиксированную плату за работу каждого кластера Kubernetes (например, Amazon Elastic Kubernetes Service, EKS).
Управлять одним кластером проще, чем несколькими.
Администрирование может включать в себя следующие задачи:
и многие другие…
В случае одного кластера заниматься всем этим придется только один раз.
Для множества кластеров операции придется повторять многократно, что, вероятно, потребует некой автоматизации процессов и инструментов, чтобы обеспечить систематичность и единообразие процесса.
А теперь несколько слов о минусах.
В случае отказа единственного кластера перестанут работать сразу все рабочие нагрузки!
Существует масса вариантов, когда что-то может пойти не так:
Один такой инцидент может нанести серьезный урон всем рабочим нагрузкам, размещенным в общем кластере.
Работа в общем кластере означает, что приложения совместно используют аппаратное обеспечение, сетевые возможности и операционную систему на узлах кластера.
В определенном смысле два контейнера с двумя различными приложениями, работающие на одном и том же узле, подобны двум процессам, работающим на одной и той же машине под управлением одного и того же ядра ОС.
Контейнеры Linux обеспечивают некоторую форму изоляции, но она далеко не так сильна, как та, которую обеспечивают, скажем, виртуальные машины. В сущности, процесс в контейнере — это тот же процесс, запущенный в операционной системе хоста.
Это может стать проблемой с точки зрения безопасности: подобная организация теоретически позволяет несвязанным приложениям взаимодействовать друг с другом (намеренно или случайно).
Кроме того, все рабочие нагрузки в кластере Kubernetes совместно используют некоторые общекластерные сервисы, такие как DNS — это позволяет приложениям находить Service'ы других приложений в кластере.
Все вышеперечисленные пункты могут иметь разное значение в зависимости от требований, предъявляемых к безопасности приложений.
Kubernetes предоставляет различные инструменты для предотвращения проблем в системе безопасности, такие как PodSecurityPolicies и NetworkPolicies. Однако для их правильной настройки требуется определенный опытж кроме того, они не в состоянии закрыть абсолютно все дыры в безопасности.
Важно всегда помнить, что Kubernetes изначально разработан для совместного использования, а не для изоляции и безопасности.
Учитывая обилие общих ресурсов в кластере Kubernetes, существует множество способов, которыми различные приложения могут «наступать друг другу на пятки».
Например, приложение может монополизировать некий общий ресурс (вроде процессора или памяти) и лишить другие приложения, работающие на том же узле, доступа к нему.
Kubernetes обеспечивает различные механизмы контроля за подобным поведением, такие как запросы ресурсов и лимиты (см. также статью « CPU-лимиты и агрессивный троттлинг в Kubernetes » — прим. перев.), ResourceQuotas и LimitRanges. Однако, как и в случае безопасности, их настройка достаточно нетривиальна и они не способны предотвратить абсолютно все непредвиденные побочные эффекты.
В случае единственного кластера приходится открывать доступ к нему множеству людей. И чем значительнее их число, тем выше риск того, что они что-нибудь «сломают».
Внутри кластера можно контролировать, кто и что может делать с помощью управления доступом на основе ролей (RBAC) (см. статью « Пользователи и авторизация RBAC в Kubernetes » — прим. перев.). Впрочем, оно не помешает пользователям «сломать» что-то в границах своей зоны ответственности.
Кластер, который используется для всех рабочих нагрузок, будет, вероятно, весьма большим (по числу узлов и pod'ов).
Но тут возникает другая проблема: кластеры в Kubernetes не могут расти до бесконечности.
Существует теоретический предел на размер кластера. В Kubernetes он составляет примерно 5000 узлов, 150 тыс. pod'ов и 300 тыс. контейнеров.
Однако в реальной жизни проблемы могут начаться гораздо раньше — например, всего при 500 узлах.
Дело в том, что крупные кластеры оказывают высокую нагрузку на управляющий слой Kubernetes. Другими словами, чтобы поддерживать кластер в рабочем состоянии и эффективно использовать ресурсы, требуется тщательная настройка.
Эта проблема изучается в соответствующей статье в оригинальном блоге под названием «Architecting Kubernetes clusters — choosing a worker node size».
Но давайте рассмотрим противоположный подход: множество мелких кластеров.
При данном подходе вы используете отдельный кластер для каждого развертываемого элемента:
Множество мелких кластеров
Для целей этой статьи под развертываемым элементом понимается экземпляр приложения — например, dev-версия отдельного приложения.
В данной стратегии Kubernetes используется как специализированная среда выполнения для отдельных экземпляров приложения.
Давайте рассмотрим плюсы и минусы этого подхода.
При «поломке» кластера негативные последствия ограничиваются лишь теми рабочими нагрузками, которые были развернуты в этом кластере. Все другие workload'ы остаются нетронутыми.
Рабочие нагрузки, размещенные в индивидуальных кластерах, не имеют общих ресурсов, таких как процессор, память, операционная система, сеть или другие сервисы.
В результате мы получаем жесткую изоляцию между несвязанными приложениями, что может благоприятно сказаться на их безопасности.
Учитывая, что в каждом кластере содержится лишь ограниченный набор рабочих нагрузок, сокращается число пользователей с доступом к нему.
Чем меньше людей имеют доступ к кластеру, тем ниже риск того, что что-то «сломается».
Давайте посмотрим на минусы.
Как упоминалось ранее, каждому кластеру Kubernetes требуется определенный набор управляющих ресурсов: мастер-узлы, компоненты контрольного слоя, решения для мониторинга и ведения логов.
В случае большого числа малых кластеров приходится выделять бoльшую долю ресурсов на управление.
Неэффективное использование ресурсов автоматически влечет за собой высокие затраты.
Например, содержание 30 мастер-узлов вместо трех при той же вычислительной мощности обязательно отразится на расходах.
Администрировать множество кластеров Kubernetes гораздо сложнее, чем работать с одним.
Например, придется настраивать аутентификацию и авторизацию для каждого кластера. Обновление версии Kubernetes также придется проводить по несколько раз.
Скорее всего, придется применить автоматизацию, чтобы повысить эффективность всех этих задач.
Теперь рассмотрим менее экстремальные сценарии.
В рамках этого подхода вы создаете отдельный кластер для всех экземпляров конкретного приложения:
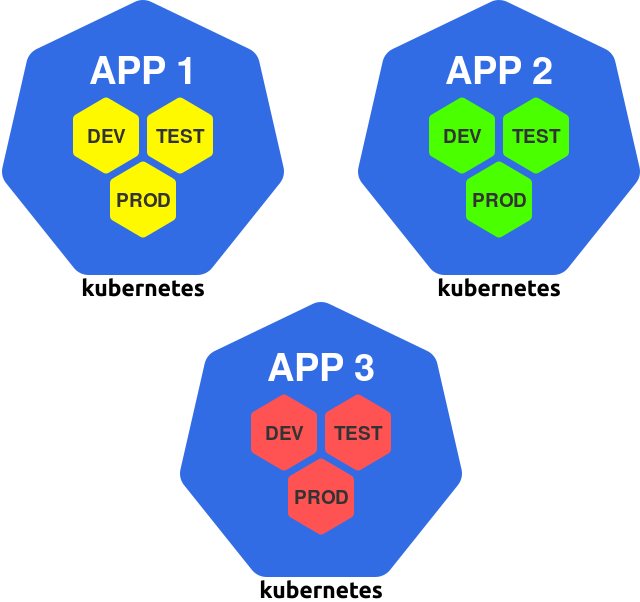
Кластер на приложение
Такой путь можно рассматривать как обобщение принципа «отдельный кластер на команду», поскольку обычно команда инженеров занимается разработкой одного или нескольких приложений.
Давайте рассмотрим плюсы и минусы этого подхода.
Если у приложения имеются особые потребности, их можно реализовать в кластере, не затрагивая другие кластеры.
Такие потребности могут включать worker'ы с GPU, определенные плагины CNI, service mesh или какой-нибудь другой сервис.
Каждый кластер можно подстроить под работающее в нем приложение, чтобы он содержал только то, что необходимо.
Недостатком этого подхода является то, что экземпляры приложений из разных окружений сосуществуют в одном кластере.
Например, prod-версия приложения работает в том же кластере, что и dev-версия. Это также означает, что разработчики ведут свою деятельность в том же кластере, в котором эксплуатируется production-версия приложения.
Если из-за действий разработчиков или глюков dev-версии в кластере произойдет сбой, то потенциально может пострадать и prod-версия — огромный недостаток такого подхода.
Ну и, наконец, последний сценарий в нашем списке.
Данный сценарий предусматривает выделение отдельного кластера на каждое окружение:

Один кластер на окружение
К примеру, у вас могут быть кластеры dev, test и prod, в которых вы будете запускать все экземпляры приложения, предназначенные для определенной среды.
Вот плюсы и минусы такого подхода.
В рамках этого подхода все окружения оказываются изолированными друг от друга. Однако на практике это особенно важно для prod-среды.
Production-версии приложения теперь не зависят от происходящего в других кластерах и средах.
Таким образом, если в dev-кластере внезапно возникнет проблема, prod-версии приложений продолжат работать как будто ничего не случилось.
Каждый кластер можно подстроить под его окружение. Например, можно:
Это позволяет повысить эффективность как разработки, так и эксплуатации приложений.
Необходимость работать с prod-кластером напрямую возникает нечасто, так что можно значительно ограничить круг лиц, имеющих к нему доступ.
Можно пойти еще дальше и вообще лишить людей доступа к этому кластеру, а все развертывания выполнять с помощью автоматизированного инструмента CI/CD. Подобный подход позволит максимально снизить риск человеческих ошибок именно там, где это наиболее актуально.
А теперь несколько слов о минусах.
Основной недостаток подхода — отсутствие аппаратной и ресурсной изоляции между приложениями.
Несвязанные приложения совместно используют ресурсы кластера: системное ядро, процессор, память и некоторые другие службы.
Как уже упоминалось, это может быть потенциально опасным.
Если у приложения имеются особые требования, то их приходится удовлетворять во всех кластерах.
Например, если приложению необходим GPU, то каждый кластер должен содержать по крайней мере один worker с GPU (даже если он используется только этим приложением).
В результате мы рискуем получить более высокие издержки и неэффективное использование ресурсов.
При наличии определенного набора приложений их можно разместить в нескольких больших кластерах или во множестве малых.
В статье рассмотрены плюсы и минусы различных подходов, начиная от одного глобального кластера и заканчивая несколькими небольшими и узкоспециализированными:
Итак, какой же подход выбрать?
Как обычно, ответ зависит от сценария использования: необходимо взвесить плюсы и минусы разных подходов и выбрать наиболее оптимальный вариант.
Однако выбор не ограничивается приведенными выше примерами — можно задействовать любое их сочетание!
Например, можно организовать по паре кластеров на каждую команду: кластер для разработки (в котором будут окружения dev и test) и кластер для production (где будет находиться production-среда).
Опираясь на информацию из этой статьи, вы сможете соответствующим образом оптимизировать плюсы и минусы под конкретный сценарий. Удачи!
Читайте также в нашем блоге:
TL;DR: один и тот же набор рабочих нагрузок можно запустить на нескольких крупных кластерах (на каждый кластер будет приходиться большое число workload'ов) или на множестве мелких (с малым числом нагрузок в каждом кластере).
Ниже приведена таблица, в которой оцениваются плюсы и минусы каждого подхода:
При использовании Kubernetes в качестве платформы для эксплуатации приложений часто возникают несколько фундаментальных вопросов о тонкостях настройки кластеров:
- Какое число кластеров использовать?
- Насколько крупными их делать?
- Что должен включать каждый кластер?
В этой статье я попытаюсь ответить на все эти вопросы, проанализировав плюсы и минусы каждого подхода.
Постановка вопроса
Как создатель ПО, вы скорее всего параллельно разрабатываете и эксплуатируете множество приложений.
Кроме того, множество экземпляров этих приложений наверняка запускаются в различных окружениях — к примеру, это могут быть dev, test и prod.
В результате получается целая матрица из приложений и окружений:
Приложения и окружения
В приведенном выше примере представлены 3 приложения и 3 окружения, что в итоге дает 9 возможных вариантов.
Каждый экземпляр приложения представляет собой самодостаточную deployment-единицу, с которой можно работать независимо от других.
Обратите внимание, что экземпляр приложения может состоять из множества компонентов, таких как фронтенд, бэкенд, база данных и т.д. В случае микросервисного приложения экземпляр будет включать в себя все микросервисы.
В результате у пользователей Kubernetes возникают несколько вопросов:
- Стоит ли размещать все экземпляры приложения в одном кластере?
- Стоит ли заводить отдельный кластер под каждый экземпляр приложения?
- Или, возможно, следует воспользоваться комбинацией вышеперечисленных подходов?
Все эти варианты вполне жизнеспособны, поскольку Kubernetes — это гибкая система, которая не ограничивает пользователя в возможностях.
Вот некоторые из возможных путей:
- один большой общий кластер;
- множество небольших узкоспециализированных кластеров;
- один кластер на каждое приложение;
- один кластер на каждое окружение.
Как показано ниже, первые два подхода находятся на противоположных концах шкалы вариантов:
От нескольких больших кластеров (слева) до множества маленьких (справа)
В общем случае считается, что один кластер «больше» другого если у него больше сумма узлов и pod'ов. Например, кластер с 10-ю узлами и 100 pod'ами больше кластера с 1-м узлом и 10-ю pod'ами.
Что ж, давайте начнем!
1. Один большой общий кластер
Первый вариант — разместить все рабочие нагрузки в одном кластере:
Один большой кластер
В рамках этого подхода кластер используется как универсальная инфраструктурная платформа — все необходимое вы просто разворачиваете в существующем кластере Kubernetes.
Namespace'ы Kubernetes позволяют логически отделить части кластера друг от друга, так что для каждого экземпляра приложения можно использовать свое пространство имен.
Давайте рассмотрим плюсы и минусы этого подхода.
+ Эффективное использование ресурсов
В случае единственного кластера потребуется лишь одна копия всех ресурсов, необходимых для запуска кластера Kubernetes и управления им.
Например, это справедливо для мастер-узлов. Обычно на каждый кластер Kubernetes приходится по 3 мастер-узла, поэтому для одного единственного кластера их число таким и останется (для сравнения, 10 кластерам понадобятся 30 мастер-узлов).
Вышеуказанная тонкость относится и другим сервисам, функционирующим в масштабах всего кластера, таким как балансировщики нагрузки, контроллеры Ingress, системы аутентификации, логирования и мониторинга.
В едином кластере все эти сервисы можно использовать сразу для всех рабочих нагрузок (не нужно создавать их копии, как в случае нескольких кластеров).
+ Дешевизна
Как следствие вышеизложенного, меньшее число кластеров обычно обходится дешевле, поскольку отсутствуют расходы на избыточные ресурсы.
Это особенно справедливо для мастер-узлов, которые могут стоить значительных денег независимо от способа размещения (on-premises или в облаке).
Некоторые управляемые (managed) сервисы Kubernetes, такие как Google Kubernetes Engine (GKE) или Azure Kubernetes Service (AKS), предоставляют управляющий слой бесплатно. В данном случае вопрос затрат стоит менее остро.
Также существуют managed-сервисы, взимающие фиксированную плату за работу каждого кластера Kubernetes (например, Amazon Elastic Kubernetes Service, EKS).
+ Эффективное администрирование
Управлять одним кластером проще, чем несколькими.
Администрирование может включать в себя следующие задачи:
- обновление версии Kubernetes;
- настройка конвейера CI/CD;
- установка плагина CNI;
- настройка системы аутентификации пользователей;
- установка контроллера допуска;
и многие другие…
В случае одного кластера заниматься всем этим придется только один раз.
Для множества кластеров операции придется повторять многократно, что, вероятно, потребует некой автоматизации процессов и инструментов, чтобы обеспечить систематичность и единообразие процесса.
А теперь несколько слов о минусах.
? Единая точка отказа
В случае отказа единственного кластера перестанут работать сразу все рабочие нагрузки!
Существует масса вариантов, когда что-то может пойти не так:
- обновление Kubernetes приводит к неожиданным побочным эффектам;
- общекластерный компонент (например, плагин CNI) начинает работать не так, как ожидалось;
- один из компонентов кластера настроен неправильно;
- сбой в нижележащей инфраструктуре.
Один такой инцидент может нанести серьезный урон всем рабочим нагрузкам, размещенным в общем кластере.
? Отсутствие жесткой изоляции
Работа в общем кластере означает, что приложения совместно используют аппаратное обеспечение, сетевые возможности и операционную систему на узлах кластера.
В определенном смысле два контейнера с двумя различными приложениями, работающие на одном и том же узле, подобны двум процессам, работающим на одной и той же машине под управлением одного и того же ядра ОС.
Контейнеры Linux обеспечивают некоторую форму изоляции, но она далеко не так сильна, как та, которую обеспечивают, скажем, виртуальные машины. В сущности, процесс в контейнере — это тот же процесс, запущенный в операционной системе хоста.
Это может стать проблемой с точки зрения безопасности: подобная организация теоретически позволяет несвязанным приложениям взаимодействовать друг с другом (намеренно или случайно).
Кроме того, все рабочие нагрузки в кластере Kubernetes совместно используют некоторые общекластерные сервисы, такие как DNS — это позволяет приложениям находить Service'ы других приложений в кластере.
Все вышеперечисленные пункты могут иметь разное значение в зависимости от требований, предъявляемых к безопасности приложений.
Kubernetes предоставляет различные инструменты для предотвращения проблем в системе безопасности, такие как PodSecurityPolicies и NetworkPolicies. Однако для их правильной настройки требуется определенный опытж кроме того, они не в состоянии закрыть абсолютно все дыры в безопасности.
Важно всегда помнить, что Kubernetes изначально разработан для совместного использования, а не для изоляции и безопасности.
? Отсутствие жесткой multi-tenancy
Учитывая обилие общих ресурсов в кластере Kubernetes, существует множество способов, которыми различные приложения могут «наступать друг другу на пятки».
Например, приложение может монополизировать некий общий ресурс (вроде процессора или памяти) и лишить другие приложения, работающие на том же узле, доступа к нему.
Kubernetes обеспечивает различные механизмы контроля за подобным поведением, такие как запросы ресурсов и лимиты (см. также статью « CPU-лимиты и агрессивный троттлинг в Kubernetes » — прим. перев.), ResourceQuotas и LimitRanges. Однако, как и в случае безопасности, их настройка достаточно нетривиальна и они не способны предотвратить абсолютно все непредвиденные побочные эффекты.
? Большое число пользователей
В случае единственного кластера приходится открывать доступ к нему множеству людей. И чем значительнее их число, тем выше риск того, что они что-нибудь «сломают».
Внутри кластера можно контролировать, кто и что может делать с помощью управления доступом на основе ролей (RBAC) (см. статью « Пользователи и авторизация RBAC в Kubernetes » — прим. перев.). Впрочем, оно не помешает пользователям «сломать» что-то в границах своей зоны ответственности.
? Кластеры не могут расти до бесконечности
Кластер, который используется для всех рабочих нагрузок, будет, вероятно, весьма большим (по числу узлов и pod'ов).
Но тут возникает другая проблема: кластеры в Kubernetes не могут расти до бесконечности.
Существует теоретический предел на размер кластера. В Kubernetes он составляет примерно 5000 узлов, 150 тыс. pod'ов и 300 тыс. контейнеров.
Однако в реальной жизни проблемы могут начаться гораздо раньше — например, всего при 500 узлах.
Дело в том, что крупные кластеры оказывают высокую нагрузку на управляющий слой Kubernetes. Другими словами, чтобы поддерживать кластер в рабочем состоянии и эффективно использовать ресурсы, требуется тщательная настройка.
Эта проблема изучается в соответствующей статье в оригинальном блоге под названием «Architecting Kubernetes clusters — choosing a worker node size».
Но давайте рассмотрим противоположный подход: множество мелких кластеров.
2. Множество небольших, специализированных кластеров
При данном подходе вы используете отдельный кластер для каждого развертываемого элемента:
Множество мелких кластеров
Для целей этой статьи под развертываемым элементом понимается экземпляр приложения — например, dev-версия отдельного приложения.
В данной стратегии Kubernetes используется как специализированная среда выполнения для отдельных экземпляров приложения.
Давайте рассмотрим плюсы и минусы этого подхода.
+ Ограниченный «радиус взрыва»
При «поломке» кластера негативные последствия ограничиваются лишь теми рабочими нагрузками, которые были развернуты в этом кластере. Все другие workload'ы остаются нетронутыми.
+ Изоляция
Рабочие нагрузки, размещенные в индивидуальных кластерах, не имеют общих ресурсов, таких как процессор, память, операционная система, сеть или другие сервисы.
В результате мы получаем жесткую изоляцию между несвязанными приложениями, что может благоприятно сказаться на их безопасности.
+ Малое число пользователей
Учитывая, что в каждом кластере содержится лишь ограниченный набор рабочих нагрузок, сокращается число пользователей с доступом к нему.
Чем меньше людей имеют доступ к кластеру, тем ниже риск того, что что-то «сломается».
Давайте посмотрим на минусы.
? Неэффективное использование ресурсов
Как упоминалось ранее, каждому кластеру Kubernetes требуется определенный набор управляющих ресурсов: мастер-узлы, компоненты контрольного слоя, решения для мониторинга и ведения логов.
В случае большого числа малых кластеров приходится выделять бoльшую долю ресурсов на управление.
? Дороговизна
Неэффективное использование ресурсов автоматически влечет за собой высокие затраты.
Например, содержание 30 мастер-узлов вместо трех при той же вычислительной мощности обязательно отразится на расходах.
? Сложности администрирования
Администрировать множество кластеров Kubernetes гораздо сложнее, чем работать с одним.
Например, придется настраивать аутентификацию и авторизацию для каждого кластера. Обновление версии Kubernetes также придется проводить по несколько раз.
Скорее всего, придется применить автоматизацию, чтобы повысить эффективность всех этих задач.
Теперь рассмотрим менее экстремальные сценарии.
3. Один кластер на каждое приложение
В рамках этого подхода вы создаете отдельный кластер для всех экземпляров конкретного приложения:
Кластер на приложение
Такой путь можно рассматривать как обобщение принципа «отдельный кластер на команду», поскольку обычно команда инженеров занимается разработкой одного или нескольких приложений.
Давайте рассмотрим плюсы и минусы этого подхода.
+ Кластер можно подстроить под приложение
Если у приложения имеются особые потребности, их можно реализовать в кластере, не затрагивая другие кластеры.
Такие потребности могут включать worker'ы с GPU, определенные плагины CNI, service mesh или какой-нибудь другой сервис.
Каждый кластер можно подстроить под работающее в нем приложение, чтобы он содержал только то, что необходимо.
? Разные среды в одном кластере
Недостатком этого подхода является то, что экземпляры приложений из разных окружений сосуществуют в одном кластере.
Например, prod-версия приложения работает в том же кластере, что и dev-версия. Это также означает, что разработчики ведут свою деятельность в том же кластере, в котором эксплуатируется production-версия приложения.
Если из-за действий разработчиков или глюков dev-версии в кластере произойдет сбой, то потенциально может пострадать и prod-версия — огромный недостаток такого подхода.
Ну и, наконец, последний сценарий в нашем списке.
4. Один кластер на каждое окружение
Данный сценарий предусматривает выделение отдельного кластера на каждое окружение:
Один кластер на окружение
К примеру, у вас могут быть кластеры dev, test и prod, в которых вы будете запускать все экземпляры приложения, предназначенные для определенной среды.
Вот плюсы и минусы такого подхода.
+ Изоляция prod-среды
В рамках этого подхода все окружения оказываются изолированными друг от друга. Однако на практике это особенно важно для prod-среды.
Production-версии приложения теперь не зависят от происходящего в других кластерах и средах.
Таким образом, если в dev-кластере внезапно возникнет проблема, prod-версии приложений продолжат работать как будто ничего не случилось.
+ Кластер можно подстроить под среду
Каждый кластер можно подстроить под его окружение. Например, можно:
- установить в dev-кластере инструменты для разработки и отладки;
- установить тестовые фреймворки и инструменты в кластере test;
- использовать более мощное оборудование и сетевые каналы в кластере prod.
Это позволяет повысить эффективность как разработки, так и эксплуатации приложений.
+ Ограничение доступа к production-кластеру
Необходимость работать с prod-кластером напрямую возникает нечасто, так что можно значительно ограничить круг лиц, имеющих к нему доступ.
Можно пойти еще дальше и вообще лишить людей доступа к этому кластеру, а все развертывания выполнять с помощью автоматизированного инструмента CI/CD. Подобный подход позволит максимально снизить риск человеческих ошибок именно там, где это наиболее актуально.
А теперь несколько слов о минусах.
? Отсутствие изоляции между приложениями
Основной недостаток подхода — отсутствие аппаратной и ресурсной изоляции между приложениями.
Несвязанные приложения совместно используют ресурсы кластера: системное ядро, процессор, память и некоторые другие службы.
Как уже упоминалось, это может быть потенциально опасным.
? Невозможность локализовать зависимости приложений
Если у приложения имеются особые требования, то их приходится удовлетворять во всех кластерах.
Например, если приложению необходим GPU, то каждый кластер должен содержать по крайней мере один worker с GPU (даже если он используется только этим приложением).
В результате мы рискуем получить более высокие издержки и неэффективное использование ресурсов.
Заключение
При наличии определенного набора приложений их можно разместить в нескольких больших кластерах или во множестве малых.
В статье рассмотрены плюсы и минусы различных подходов, начиная от одного глобального кластера и заканчивая несколькими небольшими и узкоспециализированными:
- один крупный общий кластер;
- множество небольших узкоспециализированных кластеров;
- один кластер на каждое приложение;
- один кластер на каждое окружение.
Итак, какой же подход выбрать?
Как обычно, ответ зависит от сценария использования: необходимо взвесить плюсы и минусы разных подходов и выбрать наиболее оптимальный вариант.
Однако выбор не ограничивается приведенными выше примерами — можно задействовать любое их сочетание!
Например, можно организовать по паре кластеров на каждую команду: кластер для разработки (в котором будут окружения dev и test) и кластер для production (где будет находиться production-среда).
Опираясь на информацию из этой статьи, вы сможете соответствующим образом оптимизировать плюсы и минусы под конкретный сценарий. Удачи!
P.S.
Читайте также в нашем блоге:
BadMan02
А к какому подходу склоняется Флант?
Wimbo Автор
Добрый день.
На самом деле мы практикуем любые схемы в зависимости от финаносв и специфики клиентов.
Однако более удобен для нас вариант с большим количеством меньших кластеров. Для нас управление большим количеством кластеров не является проблемой, так как у нас есть свой инструмент, который позволяет автоматически устанавливать, настраивать и обновлять все компоненты кластера с помощью конфигов, версий и CustomResource. При этом сохраняет единообразие всего ПО в кластере, будь то кластер в AWS, Azure, OpenStack или bare metal.
Совсем скоро мы планируем выпустить данный инструмент в Open Source.
leventov
Не увеличивает ли ваш инструмент «радиус взрыва»?
alexkuzko
Если придерживаться правила что все развертывания идут через CI/CD, то можно минимизировать этим риски до незначительных.