

Во времена, когда Kubernetes был ещё v1.0.0, существовали плагины для томов (volume plugins). Нужны они были для подключения к Kubernetes систем для хранения персистентных (постоянных) данных контейнеров. Количество их было невелико, а в числе первых — такие провайдеры хранилищ, как GCE PD, Ceph, AWS EBS и другие.
Поставлялись плагины вместе с Kubernetes, за что и получили своё название — in-tree. Однако многим существующего набора таких плагинов оказалось недостаточным. Умельцы добавляли простенькие плагины в ядро Kubernetes при помощи патчей, после чего собирали свой собственный Kubernetes и ставили его на свои серверы. Но со временем разработчики Kubernetes поняли, что рыбой проблему не решить. Людям нужна удочка. И в релизе Kubernetes v1.2.0 она появилась…
Плагин Flexvolume: удочка на минималках
Разработчиками Kubernetes был создан плагин FlexVolume, который являлся логической обвязкой из переменных и методов для работы с реализуемыми сторонними разработчиками Flexvolume-драйверами.
Остановимся и подробнее рассмотрим, что представляет собой драйвер FlexVolume. Это некий исполняемый файл (бинарный файл, Python-скрипт, Bash-скрипт и т.п.), который при выполнении принимает на вход аргументы командной строки и возвращает сообщение с заранее известными полями в JSON-формате. Первым аргументом командной строки по соглашению всегда является метод, а остальные аргументы — его параметры.
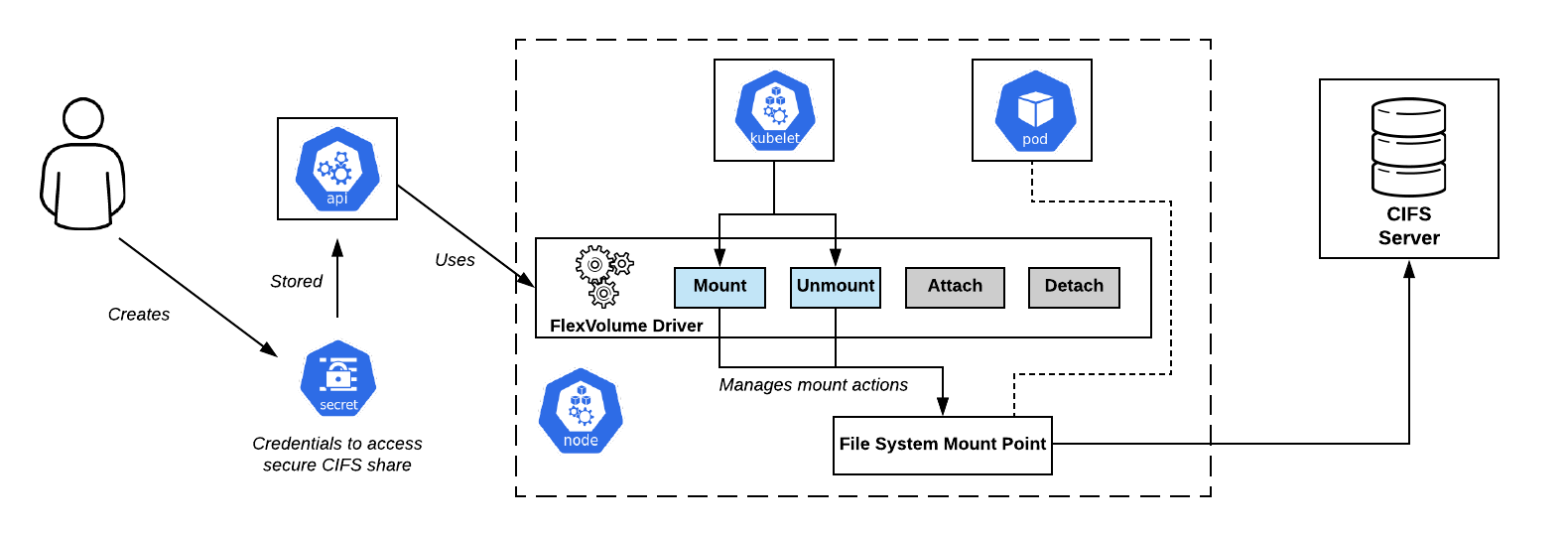
Схема подключения CIFS Shares в OpenShift. Драйвер Flexvolume — прямо по центру
Минимальный набор методов выглядит так:
flexvolume_driver mount # отвечает за присоединение тома к pod'у
# Формат возвращаемого сообщения:
{
"status": "Success"/"Failure"/"Not supported",
"message": "По какой причине был возвращен именно такой статус",
}
flexvolume_driver unmount # отвечает за отсоединение тома от pod'а
# Формат возвращаемого сообщения:
{
"status": "Success"/"Failure"/"Not supported",
"message": "По какой причине был возвращен именно такой статус",
}
flexvolume_driver init # отвечает за инициализацию плагина
# Формат возвращаемого сообщения:
{
"status": "Success"/"Failure"/"Not supported",
"message": "По какой причине был возвращен именно такой статус",
// Определяет, использует ли драйвер методы attach/deatach
"capabilities":{"attach": True/False}
}Использование методов
attach и detach определит сценарий, по которому в будущем kubelet будет действовать при вызове драйвера. Также существуют специальные методы expandvolume и expandfs, которые отвечают за динамическое изменение размера тома. В качестве примера изменений, которые добавляет метод
expandvolume, а вместе с ним — и возможность выполнять изменение размера томов в реальном времени, можно ознакомиться с нашим pull request'ом в Rook Ceph Operator.А вот пример реализации Flexvolume-драйвера для работы с NFS:
usage() {
err "Invalid usage. Usage: "
err "\t$0 init"
err "\t$0 mount <mount dir> <json params>"
err "\t$0 unmount <mount dir>"
exit 1
}
err() {
echo -ne $* 1>&2
}
log() {
echo -ne $* >&1
}
ismounted() {
MOUNT=`findmnt -n ${MNTPATH} 2>/dev/null | cut -d' ' -f1`
if [ "${MOUNT}" == "${MNTPATH}" ]; then
echo "1"
else
echo "0"
fi
}
domount() {
MNTPATH=$1
NFS_SERVER=$(echo $2 | jq -r '.server')
SHARE=$(echo $2 | jq -r '.share')
if [ $(ismounted) -eq 1 ] ; then
log '{"status": "Success"}'
exit 0
fi
mkdir -p ${MNTPATH} &> /dev/null
mount -t nfs ${NFS_SERVER}:/${SHARE} ${MNTPATH} &> /dev/null
if [ $? -ne 0 ]; then
err "{ \"status\": \"Failure\", \"message\": \"Failed to mount ${NFS_SERVER}:${SHARE} at ${MNTPATH}\"}"
exit 1
fi
log '{"status": "Success"}'
exit 0
}
unmount() {
MNTPATH=$1
if [ $(ismounted) -eq 0 ] ; then
log '{"status": "Success"}'
exit 0
fi
umount ${MNTPATH} &> /dev/null
if [ $? -ne 0 ]; then
err "{ \"status\": \"Failed\", \"message\": \"Failed to unmount volume at ${MNTPATH}\"}"
exit 1
fi
log '{"status": "Success"}'
exit 0
}
op=$1
if [ "$op" = "init" ]; then
log '{"status": "Success", "capabilities": {"attach": false}}'
exit 0
fi
if [ $# -lt 2 ]; then
usage
fi
shift
case "$op" in
mount)
domount $*
;;
unmount)
unmount $*
;;
*)
log '{"status": "Not supported"}'
exit 0
esac
exit 1Итак, после подготовки собственно исполняемого файла необходимо выложить драйвер в Kubernetes-кластер. Драйвер должен находиться на каждом узле кластера согласно заранее оговоренному пути. По умолчанию был выбран:
/usr/libexec/kubernetes/kubelet-plugins/volume/exec/имя_поставщика_хранилища~имя_драйвера/… но при использовании различных дистрибутивов Kubernetes (OpenShift, Rancher…) путь может быть другим.
Проблемы Flexvolume: как правильно закидывать удочку?
Выкладывать Flexvolume-драйвер на узлы кластера оказалось нетривиальной задачей. Проделав операцию однажды вручную, легко столкнуться с ситуацией, когда в кластере появятся новые узлы: из-за добавления нового узла, автоматического горизонтального масштабирования или — что страшнее — замены узла из-за неисправности. В этом случае работу с хранилищем на данных узлах производить невозможно, пока вы всё так же в ручном режиме не добавите на них Flexvolume-драйвер.
Решением данной проблемы послужил один из примитивов Kubernetes —
DaemonSet. При появлении нового узла в кластере на нем автоматически оказывается pod из нашего DaemonSet'a, к которому присоединяется локальный том по пути для нахождения Flexvolume-драйверов. При успешном создании pod копирует необходимые файлы для работы драйвера на диск.Вот пример такого DaemonSet'а для выкладывания Flexvolume-плагина:
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: flex-set
spec:
template:
metadata:
name: flex-deploy
labels:
app: flex-deploy
spec:
containers:
- image: <deployment_image>
name: flex-deploy
securityContext:
privileged: true
volumeMounts:
- mountPath: /flexmnt
name: flexvolume-mount
volumes:
- name: flexvolume-mount
hostPath:
path: <host_driver_directory>… и пример Bash-скрипта для выкладывания Flexvolume-драйвера:
#!/bin/sh
set -o errexit
set -o pipefail
VENDOR=k8s.io
DRIVER=nfs
driver_dir=$VENDOR${VENDOR:+"~"}${DRIVER}
if [ ! -d "/flexmnt/$driver_dir" ]; then
mkdir "/flexmnt/$driver_dir"
fi
cp "/$DRIVER" "/flexmnt/$driver_dir/.$DRIVER"
mv -f "/flexmnt/$driver_dir/.$DRIVER" "/flexmnt/$driver_dir/$DRIVER"
while : ; do
sleep 3600
doneВажно не забыть, что операция копирования не является атомарной. Велика вероятность, что kubelet начнет использовать драйвер до того, как процесс его подготовки будет завершен, что вызовет ошибку в работе системы. Правильным подходом будет сначала скопировать файлы драйвера под другим именем, после чего использовать атомарную операцию переименования.
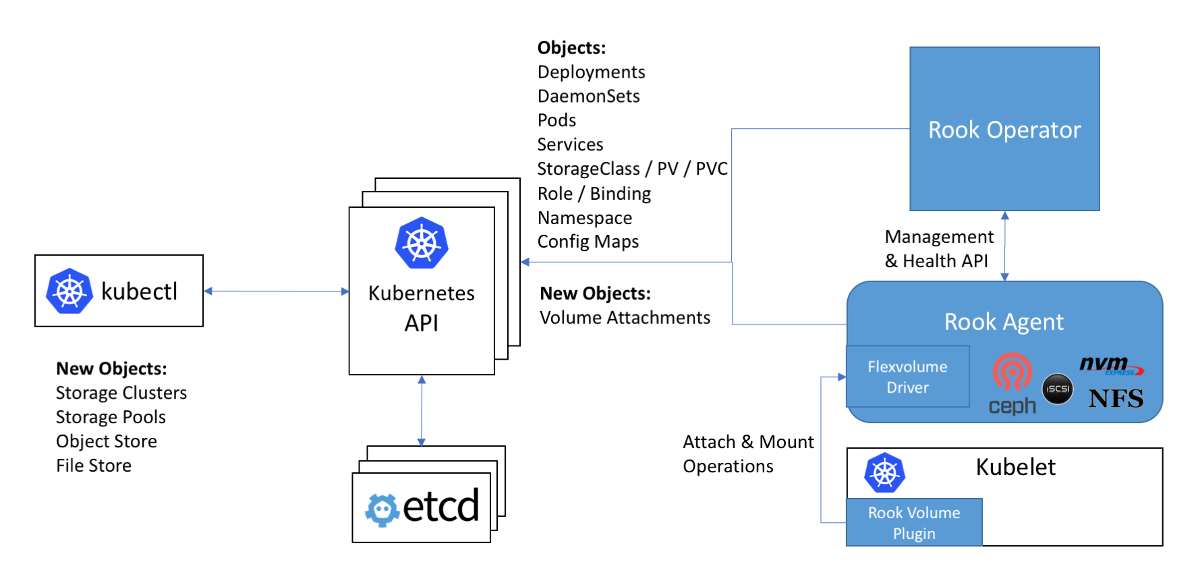
Схема работы с Ceph в операторе Rook: драйвер Flexvolume на схеме находится внутри агента Rook
Следующей проблемой при использовании Flexvolume-драйверов является то, что для большинства хранилищ на узле кластера должен быть установлен необходимый для этого софт (например, пакет ceph-common для Ceph). Изначально плагин Flexvolume не был задуман для реализации настолько сложных систем.
Оригинальное решение для этой проблемы можно увидеть в реализации Flexvolume-драйвера оператора Rook:
Сам драйвер выполнен в виде RPC-клиента. IPC-сокет для общения лежит в том же каталоге, что и сам драйвер. Мы с вами помним, что для копирования файлов драйвера хорошо бы использовать DaemonSet, который в качестве тома подключает себе директорию с драйвером. После копирования необходимых файлов драйвера rook этот pod не умирает, а подключается к IPC-сокету через присоединенный том как полноценный RPC-сервер. Пакет ceph-common уже установлен внутри контейнера pod’а. IPC-сокет дает уверенность, что kubelet будет общаться именно с тем pod'ом, который находится с ним на одном узле. Всё гениальное просто!..
До свидания, наши ласковые… плагины in-tree!
Разработчики Kubernetes обнаружили, что количество плагинов для хранилищ внутри ядра равняется двадцати. И изменение в каждом из них так или иначе проходит через полный релизный цикл Kubernetes.
Оказывается, чтобы использовать новую версию плагина для хранилища, нужно обновить весь кластер. В дополнение к этому вы можете удивиться, что новая версия Kubernetes вдруг станет несовместимой с используемым ядром Linux… А посему вы вытираете слезы и скрипя зубами согласовываете с начальством и пользователями время обновления ядра Linux и кластера Kubernetes. С возможным простоем в предоставлении услуг.
Ситуация более чем комичная, не находите? Всему сообществу стало ясно, что подход не работает. Волевым решением разработчики Kubernetes объявляют, что новые плагины для работы с хранилищами более не будут приниматься в ядро. Ко всему прочему, как мы уже знаем, в реализации Flexvolume-плагином был выявлен ряд недоработок…
Раз и навсегда закрыть вопрос с персистентными хранилищами данных был призван последний добавленный плагин для томов в Kubernetes — CSI. Его альфа-версию, более полно называемую как Out-of-Tree CSI Volume Plugins, анонсировали в релизе Kubernetes 1.9.
Container Storage Interface, или спиннинг CSI 3000!
Первым делом хотелось бы отметить, что CSI — это не просто volume plugin, а самый настоящий стандарт по созданию пользовательских компонентов для работы с хранилищами данных. Предполагалось, что системы оркестрации контейнерами, такие как Kubernetes и Mesos, должны «научиться» работе с компонентами, реализованными по этому стандарту. И вот Kubernetes уже научился.
Каково же устройство CSI-плагина в Kubernetes? CSI-плагин работает со специальными драйверами (CSI-драйверами), написанными сторонними разработчиками. CSI-драйвер в Kubernetes минимально должен состоять из двух компонентов (pod’ов):
- Controller — управляет внешними персистентными хранилищами. Релизуется в виде gRPC-сервера, для которого используется примитив
StatefulSet. - Node — отвечает за монтирования персистентных хранилищ к узлам кластера. Тоже реализуется в виде gRPC-сервера, но для него используется примитив
DaemonSet.
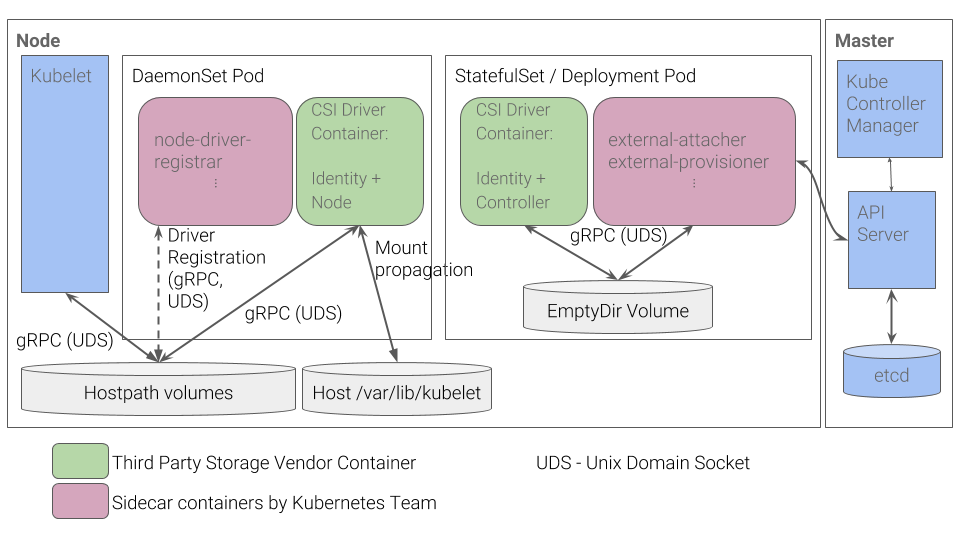
Схема работы CSI-плагина в Kubernetes
О некоторых других подробностях работы CSI вы можете узнать, например, из статьи «Understanding the CSI», перевод которой мы публиковали год назад.
Плюсы такой реализации
- Для базовых вещей — например, для регистрации драйвера для узла — разработчики Kubernetes реализовали набор контейнеров. Больше не нужно самим формировать JSON-ответ с capabilities, как это делалось для плагина Flexvolume.
- Вместо «подсовывания» на узлы исполняемых файлов мы теперь выкладываем в кластер pod’ы. Этого мы изначально и ждем от Kubernetes: все процессы происходят внутри контейнеров, развернутых при помощи примитивов Kubernetes.
- Для реализации сложных драйверов больше не нужно разрабатывать RPC-сервер и RPC-клиент. Клиент за нас реализовали разработчики Kubernetes.
- Передача аргументов для работы по протоколу gRPC гораздо удобнее, гибче и надежнее, чем их передача через аргументы командной строки. Для понимания, как добавить в CSI поддержку метрик по использованию тома при помощи добавления стандартизированного gRPC-метода, можно ознакомиться с нашим pull request'ом для драйвера vsphere-csi.
- Общение происходит через IPC-сокеты, чтобы не путаться, тому ли pod'у kubelet отправил запрос.
Этот список вам ничего не напоминает? Преимущества CSI — это решение тех самых проблем, что не были учтены при разработке плагина Flexvolume.
Выводы
CSI как стандарт реализации пользовательских плагинов для взаимодействия с хранилищами данных был принят сообществом очень тепло. Более того, благодаря своим преимуществам и универсальности, CSI-драйверы создаются даже для таких хранилищ, как Ceph или AWS EBS, плагины для работы с которыми были добавлены ещё в самой первой версии Kubernetes.
В начале 2019 года плагины in-tree были объявлены устаревшими. Планируется продолжать поддержку плагина Flexvolume, но разработки новых функциональных возможностей для него не будет.
Сами мы уже имеем опыт использования ceph-csi, vsphere-csi и готовы пополнять этот список! Пока что CSI с возложенными на него задачами справляется на ура, а там поживем-увидим.
Не забывайте, что всё новое — это хорошо переосмысленное старое!
P.S.
Читайте также в нашем блоге: