
Легко посчитать, сколько трафика пришло с ютуб-канала. К примеру, зайти в счетчик Яндекс Метрики или Google Analytics. А вы попробуйте узнать, что происходило с вашим видео на канале. Кто его посмотрел, кто добавил в фавориты, а кто дислайкнул. Вот для выгрузки таких данных и потребуется скрипт на Python.
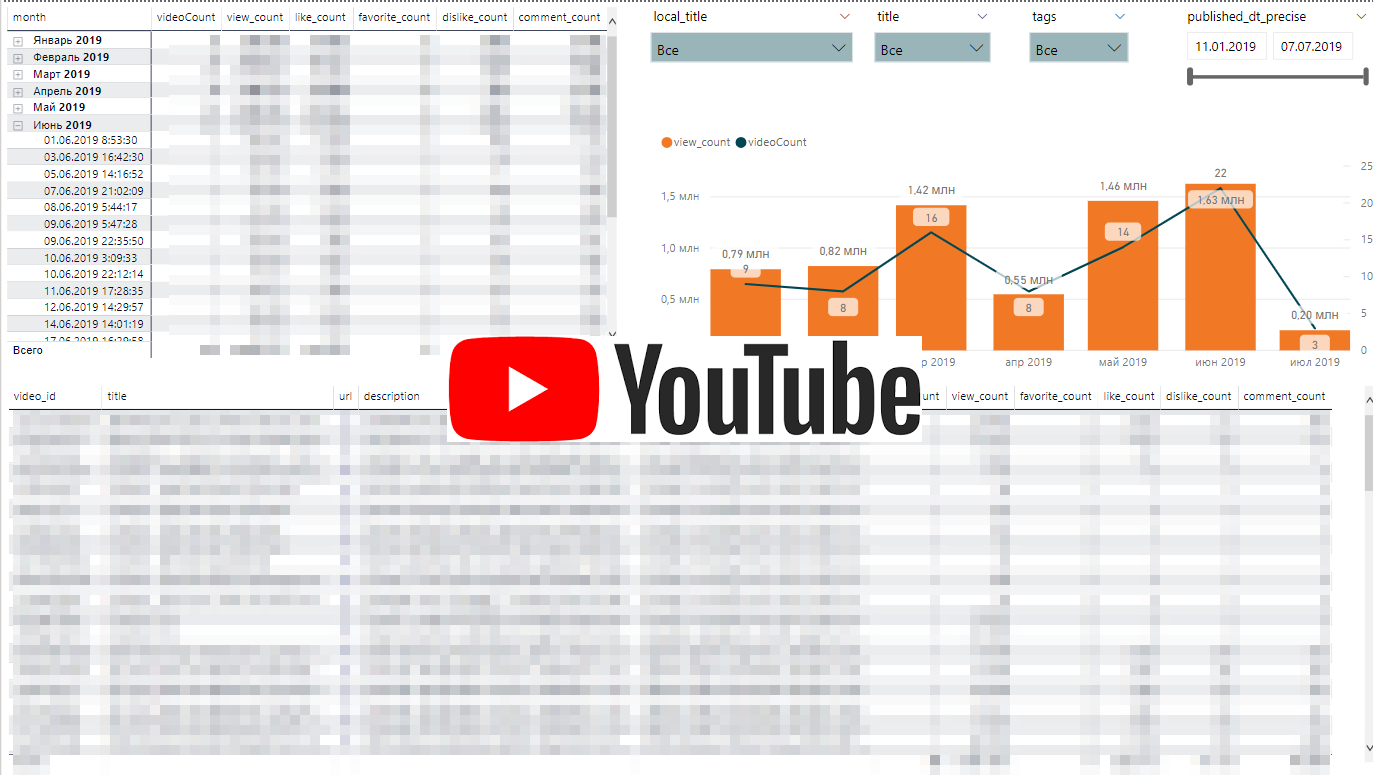
Динамика Youtube-активностей
API Youtube достаточно прост. Мы будем выгружать список плейлистов и по каждому плейлисту выгружать статистику по видео.
Идентификатор канала можно найти в коде страницы. О получении ключа доступа можно прочитать здесь. Создадим класс report_client и определим в нем процедуры.
Далее для получения выгрузки нам потребуется инициализировать класс и запустить выгрузку.
Статьи из цикла:
Динамика Youtube-активностей
API Youtube достаточно прост. Мы будем выгружать список плейлистов и по каждому плейлисту выгружать статистику по видео.
YOUTUBE_API_URL = 'https://www.googleapis.com/youtube/v3'
YOUTUBE_API_KEY = '...'
YOUTUBE_CHANNEL_ID = '...'
Идентификатор канала можно найти в коде страницы. О получении ключа доступа можно прочитать здесь. Создадим класс report_client и определим в нем процедуры.
class report_client:
def __init__(self, api_url, api_key, proxies):
self._url = api_url
self._key = api_key
self._proxies = proxies
def req_video(self, channel_id = YOUTUBE_CHANNEL_ID):
url = ('{0}/activities?channelId={1}&key={2}&part=snippet%2CcontentDetails&maxResults=50')
r = requests.get(url.format(self._url, channel_id,self._key)
, proxies = self._proxies)
parsed = json.loads(r.text)
res_df = pd.DataFrame(columns=['video_id'])
for i in parsed['items']:
temp = {}
if 'upload' in i['contentDetails']:
temp['video_id'] = i['contentDetails']['upload']['videoId']
res_df = res_df.append(temp, ignore_index=True)
return res_df
def req_playlist(self, channel_id = YOUTUBE_CHANNEL_ID):
url = ('{0}/playlists?channelId={1}&key={2}&part=snippet%2CcontentDetails&maxResults=50')
r = requests.get(url.format(self._url, channel_id, self._key)
, proxies = self._proxies)
parsed = json.loads(r.text)
res_df = pd.DataFrame(columns=['playlist_id', 'playlist_name'])
for i in parsed['items']:
temp = {}
temp['playlist_id'] = i['id']
temp['playlist_name'] = i['snippet']['title']
res_df = res_df.append(temp, ignore_index=True)
return res_df
def req_playlist_stat(self, playlist_id, channel_id = YOUTUBE_CHANNEL_ID):
res_df = pd.DataFrame(columns=['video_id', 'playlist_id', 'playlist_name'])
for i,k in playlist_id.iterrows():
url = ('{0}/playlistItems?playlistId={1}&key={2}&part=snippet&maxResults=50')
r = requests.get(url.format(self._url, k['playlist_id'],self._key)
, proxies = self._proxies)
parsed = json.loads(r.text)
for j in parsed['items']:
temp = {}
temp['video_id'] = j['snippet']['resourceId']['videoId']
temp['playlist_id'] = k['playlist_id']
temp['playlist_name'] = k['playlist_name']
res_df = res_df.append(temp, ignore_index=True)
stop = 0
while 'nextPageToken' in parsed:
url = ('{0}/playlistItems?playlistId={1}&key={2}&part=snippet&maxResults=50&pageToken={3}')
r = requests.get(url.format(self._url, k['playlist_id'],self._key,parsed['nextPageToken'])
, proxies = self._proxies)
parsed = json.loads(r.text)
for j in parsed['items']:
temp = {}
temp['video_id'] = j['snippet']['resourceId']['videoId']
temp['playlist_id'] = k['playlist_id']
temp['playlist_name'] = k['playlist_name']
res_df = res_df.append(temp, ignore_index=True)
stop = stop + 1
if stop == 1:
break
return res_df
def req_stat(self, video_id):
res_df = pd.DataFrame(columns=['video_id','publishedAt','title','description', 'tags','local_title','viewCount','likeCount', 'dislikeCount','favoriteCount','commentCount' , 'playlist_id', 'playlist_name'])
for i,k in video_id.iterrows():
url = ('{0}/videos?id={1}&key={2}&part=snippet,contentDetails,statistics,status&maxResults=50')
r = requests.get(url.format(self._url, k['video_id'], self._key)
, proxies = self._proxies)
parsed = json.loads(r.text)
if 'error' in parsed.keys():
break
temp = {}
if 'items' in parsed:
if parsed['items']:
temp['video_id'] = parsed['items'][0]['id']
temp['publishedAt'] = parsed['items'][0]['snippet']['publishedAt']
temp['title'] = parsed['items'][0]['snippet']['title']
temp['description'] = parsed['items'][0]['snippet']['description']
temp['playlist_id'] = k['playlist_id']
temp['playlist_name'] = k['playlist_name']
if 'tags' in parsed['items'][0]['snippet']:
temp['tags'] = parsed['items'][0]['snippet']['tags']
if 'title' in parsed['items'][0]['snippet']['localized']:
temp['local_title'] = parsed['items'][0]['snippet']['localized']['title']
if 'viewCount' in parsed['items'][0]['statistics']:
temp['viewCount'] = parsed['items'][0]['statistics']['viewCount']
if 'likeCount' in parsed['items'][0]['statistics']:
temp['likeCount'] = parsed['items'][0]['statistics']['likeCount']
if 'dislikeCount' in parsed['items'][0]['statistics']:
temp['dislikeCount'] = parsed['items'][0]['statistics']['dislikeCount']
if 'favoriteCount' in parsed['items'][0]['statistics']:
temp['favoriteCount'] = parsed['items'][0]['statistics']['favoriteCount']
if 'commentCount' in parsed['items'][0]['statistics']:
temp['commentCount'] = parsed['items'][0]['statistics']['commentCount']
res_df = res_df.append(temp, ignore_index=True)
return res_df
Далее для получения выгрузки нам потребуется инициализировать класс и запустить выгрузку.
def youtube_reports():
a = report_client(YOUTUBE_API_URL,YOUTUBE_API_KEY,{})
method_rep = getattr(a, "req_playlist")
playlist_id = method_rep()
method_rep = getattr(a, "req_playlist_stat")
video_id = method_rep(playlist_id)
report_list = ["req_stat"]
for rep in report_list:
result_local_file_name = 'df_{0}.csv'.format(rep)
method_rep = getattr(a, rep)
df = method_rep(video_id)
df.to_csv(r'C:\\Users\\User\\Desktop\\youtube.csv',
index=False,
header=True,
sep='\t',
quoting = csv.QUOTE_ALL,
encoding="utf-8")
to_sql_server(df, 'youtube_{0}'.format(rep))
youtube_reports()
Статьи из цикла:
- Проектирование дашбордов для веб-аналитики e-commerce сайта. Часть 1: Удобный интерфейс
- Проектирование дашбордов для веб-аналитики e-commerce сайта. Часть 2: Email-рассылки. Стратегический дашборд
- Проектирование дашбордов для веб-аналитики e-commerce сайта. Часть 2: Email-рассылки. Операционный дашборд
- Проектирование дашбордов для веб-аналитики e-commerce сайта. Часть 3: SEO-канал
Maslukhin
Простите, но у вашего хорошего в задумке поста есть три недостатка.
tytanya Автор
Спасибо за обратную связь! Дробление на каналы выглядит более понятным вариантом для меня, чем объединение одного канала с другим. Он решает основную задачу — собрать, выгрузить данные для Ютуб-канала. Про непосредственную аналитику я планировала дописать позже. Пожалуй, стоило оставить пост в черновиках и выложить только после окончания написания