

Общеизвестно, что семантика инициализации — одна из наиболее сложных частей C++. Существует множество видов инициализации, описываемых разным синтаксисом, и все они взаимодействуют сложным и вызывающим вопросы способом. C++11 принес концепцию «универсальной инициализации». К сожалению, она привнесла еще более сложные правила, и в свою очередь, их перекрыли в C++14, C++17 и снова поменяют в C++20.
Под катом — видео и перевод доклада Тимура Домлера (Timur Doumler) с конференции C++ Russia. Тимур вначале подводит исторические итоги эволюции инициализации в С++, дает системный обзор текущего варианта правила инициализации, типичных проблем и сюрпризов, объясняет, как использовать все эти правила эффективно, и, наконец, рассказывает о свежих предложениях в стандарт, которые могут сделать семантику инициализации C++20 немного более удобной. Далее повествование — от его лица.
Table of Contents
- Инициализация по умолчанию (С)
- Копирующая инициализация (С)
- Агрегатная инициализация (С)
- Статическая инициализация (С)
- Прямая инициализация (С++98)
- Инициализация значением (C++03)
- Универсальная инициализация (C++11)
- Улучшения в С++14
- Как правильно инициализировать в C++
- Назначенная инициализация (С++20)
- Исправления в C++20
- Прямая инициализация агрегатных типов (C++20)

Гифка, которую вы сейчас видите, отлично доносит основную мысль доклада. Я нашёл её на просторах интернета где-то полгода тому назад, и выложил у себя в твиттере. В комментариях к ней кто-то сказал, что не хватает ещё трёх типов инициализации. Началось обсуждение, в ходе которого мне предложили сделать об этом доклад. Так всё и началось.
Про инициализацию уже рассказывал Николай Йоссутис. В его докладе был слайд, на котором перечислялись 19 различных способов инициализировать int:
int i1; //undefined value
int i2 = 42; //note: inits with 42
int i3(42); //inits with 42
int i4 = int(); //inits with 42
int i5{42}; //inits with 42
int i6 = {42}; //inits with 42
int i7{}; //inits with 0
int i8 = {}; //inits with 0
auto i9 = 42; //inits with 42
auto i10{42}; //C++11: std::initializer_list<int>, C++14: int
auto i11 = {42}; //inits std::initializer_list<int> with 42
auto i12 = int{42}; //inits int with 42
int i13(); //declares a function
int i14(7, 9); //compile-time error
int i15 = (7, 9); //OK, inits int with 9 (comma operator)
int i16 = int(7, 9); //compile-time error
int i17(7, 9); //compile-time error
auto i18 = (7, 9); //OK, inits int with 9 (comma operator)
auto i19 = int(7, 9); //compile-time errorМне кажется, это уникальная ситуация для языка программирования. Инициализация переменной — одно из простейших действий, но в С++ сделать это совсем не просто. Вряд ли в этом языке есть какая-либо другая область, в которой за последние годы было бы столько же отчётов об отклонениях от стандарта, исправлений и изменений. Правила инициализации меняются от стандарта к стандарту, и в интернете есть бесчисленное количество постов о том, как запутана инициализация в C++. Поэтому сделать её систематический обзор — задача нетривиальная.
Я буду излагать материал в хронологическом порядке: вначале мы поговорим о том, что было унаследовано от С, потом о С++98, затем о С++03, С++11, С++14 и С++17. Мы обсудим распространённые ошибки, и я дам свои рекомендации относительно правильной инициализации. Также я расскажу о нововведениях в С++20. В самом конце доклада будет представлена обзорная таблица.
Инициализация по умолчанию (С)
В С++ очень многое унаследовано от С, поэтому с него мы и начнём. В С есть несколько способов инициализации переменных. Их можно вообще не инициализировать, и это называется инициализация по умолчанию. На мой взгляд, это неудачное название. Дело в том, что никакого значения по умолчанию переменной не присваивается, она просто не инициализируется. Если обратиться к неинициализированной переменной в C++ и в С, возникает неопределённое поведение:
int main() {
int i;
return i; // undefined behaviour
}То же касается пользовательских типов: если в некотором struct есть неинициализированные поля, то при обращении к ним также возникает неопределённое поведение:
struct Widget {
int i;
int j;
};
int main() {
Widget widget;
return widget.i; // неопределенное поведение
}В С++ было добавлено множество новых конструкций: классы, конструкторы, public, private, методы, но ничто из этого не влияет на только что описанное поведение. Если в классе некоторый элемент не инициализирован, то при обращении к нему возникает неопределённое поведение:
class Widget {
public:
Widget() {}
int get_i() const noexcept { return i; }
int get_j() const noexcept { return j; }
private:
int i;
int j;
};
int main() {
Widget widget;
return widget.get_i(); // Undefined behaviour!
}Никакого волшебного способа инициализировать по умолчанию элемент класса в С++ нет. Это интересный момент, и в течение первых нескольких лет моей карьеры с С++ я этого не знал. Ни компилятор, ни IDE, которой я тогда пользовался, об этом никак не напоминали. Мои коллеги не обращали внимания на эту особенность при проверке кода. Я почти уверен, что из-за неё в моём коде, написанном в эти годы, есть довольно странные баги. Мне казалось очевидным, что классы должны инициализировать свои переменные.
В C++98 можно инициализировать переменные при помощи member initializer list. Но такое решение проблемы не оптимальное, поскольку это необходимо делать в каждом конструкторе, и об этом легко забыть. Кроме того, инициализация идёт в порядке, в котором переменные объявлены, а не в порядке member initializer list:
// C++98: member initialiser list
class Widget {
public:
Widget() : i(0), j(0) {} // member initialiser list
int get_i() const noexcept { return i; }
int get_j() const noexcept { return j; }
private:
int i;
int j;
};
int main() {
Widget widget;
return widget.get_i();
}В C++11 были добавлены инициализаторы элементов по умолчанию (direct member initializers), которыми пользоваться значительно удобнее. Они позволяют инициализировать все переменные одновременно, и это даёт уверенность, что все элементы инициализированы:
// C++11: default member initialisers
class Widget {
public:
Widget() {}
int get_i() const noexcept { return i; }
int get_j() const noexcept { return j; }
private:
int i = 0; // default member initialisers
int j = 0;
};
int main() {
Widget widget;
return widget.get_i();
}Моя первая рекомендация: когда можете, всегда используйте DMI (direct member initializers). Их можно использовать как со встроенными типами (float и int), так и с объектами. Привычка инициализировать элементы заставляет подходить к этому вопросу более осознанно.
Копирующая инициализация (С)
Итак, первый унаследованный от С способ инициализации — инициализация по умолчанию, и ей пользоваться не следует. Второй способ — копирующая инициализация. В этом случае мы указываем переменную и через знак равенства — её значение:
// copy initialization
int main() {
int i = 2;
}Копирующая инициализация также используется, когда аргумент передаётся в функцию по значению, или когда происходит возврат объекта из функции по значению:
// copy initialization
int square(int i) {
return i * i;
}Знак равенства может создать впечатление, что происходит присвоение значения, но это не так. Копирующая инициализация — это не присвоение значения. В этом докладе вообще ничего не будет про присвоение.
Другое важное свойство копирующей инициализации: если типы значений не совпадают, то выполняется последовательность преобразования (conversion sequence). У последовательности преобразования есть определенные правила, например, она не вызывает explicit конструкторов, поскольку они не являются преобразующими конструкторами. Поэтому, если выполнить копирующую инициализацию для объекта, конструктор которого отмечен как explicit, происходит ошибка компиляции:
struct Widget {
explicit Widget(int) {}
};
Widget w1 = 1; // ERRORБолее того, если есть другой конструктор, который не является explicit, но при этом хуже подходит по типу, то копирующая инициализация вызовет его, проигнорировав explicit конструктор:
struct Widget {
explicit Widget(int) {}
Widget(double) {}
};
Widget w1 = 1; // вызывает Widget(double)Агрегатная инициализация (С)
Третий тип инициализации, о котором я хотел бы рассказать — агрегатная инициализация. Она выполняется, когда массив инициализируется рядом значений в фигурных скобках:
int i[4] = {0, 1, 2, 3};Если при этом не указать размер массива, то он выводится из количества значений, заключённых в скобки:
int j[] = {0, 1, 2, 3}; // array size deductionЭта же инициализация используется для агрегатных (aggregate) классов, то есть таких классов, которые являются просто набором публичных элементов (в определении агрегатных классов есть ещё несколько правил, но сейчас мы не будем на них останавливаться):
struct Widget {
int i;
float j;
};
Widget widget = {1, 3.14159};Этот синтаксис работал ещё в С и С++98, причём, начиная с С++11, в нём можно пропускать знак равенства:
Widget widget{1, 3.14159};Агрегатная инициализация на самом деле использует копирующую инициализацию для каждого элемента. Поэтому, если попытаться использовать агрегатную инициализацию (как со знаком равенства, так и без него) для нескольких объектов с explicit конструкторами, то для каждого объекта выполняется копирующая инициализация и происходит ошибка компиляции:
struct Widget {
explicit Widget(int) {}
};
struct Thingy {
Widget w1, w2;
};
int main() {
Thingy thingy = {3, 4}; // ERROR
Thingy thingy {3, 4}; // ERROR
}А если для этих объектов есть другой конструктор, не-explicit, то вызывается он, даже если он хуже подходит по типу:
struct Widget {
explicit Widget(int) {}
Widget(double) {}
};
struct Thingy {
Widget w1, w2;
};
int main() {
Thingy thingy = {3, 4}; // вызывает Widget(double)
Thingy thingy {3, 4}; // вызывает Widget(double)
}Рассмотрим ещё одно свойство агрегатной инициализации. Вопрос: какое значение возвращает эта программа?
struct Widget {
int i;
int j;
};
int main() {
Widget widget = {1};
return widget.j;
}Совершенно верно, нуль. Если при агрегатной инициализации пропустить некоторые элементы в массиве значений, то соответствующим переменным присваивается значение нуль. Это очень полезное свойство, потому что благодаря нему никогда не может быть неинициализированных элементов. Оно работает с агрегатными классами и с массивами:
// все элементы инициализируются нулями
int[100] = {};Другое важное свойство агрегатной инициализации — пропуск скобок (brace elision). Как вы думаете, какое значение возвращает эта программа? В ней есть Widget, который является агрегатом двух значений int, и Thingy, агрегат Widget и int. Что мы получим, если передадим ей два инициализирующих значения: {1, 2}?
struct Widget {
int i;
int j;
};
struct Thingy {
Widget w;
int k;
};
int main() {
Thingy t = {1, 2};
return t.k; // что мы получим?
}Ответ: нуль. Здесь мы имеем дело с подагрегатом (subaggregate), то есть с вложенным агрегатным классом. Такие классы можно инициализировать, используя вложенные скобки, но одну из этих пар скобок можно пропустить. В этом случае выполняется рекурсивный обход субагрегата, и {1, 2} оказывается эквивалентно {{1, 2}, 0}. Надо признать, это свойство не вполне очевидное.
Статическая инициализация (С)
Наконец, от С также унаследована статическая инициализация: статические переменные всегда инициализируются. Это может быть сделано несколькими способами. Статическую переменную можно инициализировать выражением-константой. В этом случае инициализация происходит во время компиляции. Если же переменной не присвоить никакого значения, то она инициализируется значением нуль:
static int i = 3; // инициализация константой
statit int j; // инициализация нулем
int main() {
return i + j;
}Эта программа возвращает 3, несмотря на то, что j не инициализировано. Если же переменная инициализируется не константой, а объектом, могут возникнуть проблемы.
Вот пример из реальной библиотеки, над которой я работал:
static Colour red = {255, 0, 0};В ней был класс Colour, и основные цвета (red, green, blue) были определены как статические объекты. Это допустимое действие, но как только появляется другой статический объект, в инициализаторе которого используется red, появляется неопределённость, поскольку нет жёсткого порядка, в котором инициализируются переменные. Ваше приложение может обратиться к неинициализированной переменной, и тогда оно упадёт. К счастью, в С++11 стало возможным использовать конструктор constexpr, и тогда мы имеем дело с инициализацией константой. В этом случае никаких проблем с порядком инициализации уже не возникает.
Итак, от языка C унаследованы четыре типа инициализации: инициализация по умолчанию, копирующая, агрегатная и статическая инициализации.
Прямая инициализация (С++98)
Перейдём теперь к С++98. Пожалуй, наиболее важная возможность, отличающая С++ от С — это конструкторы. Вот пример вызова конструктора:
Widget widget(1, 2);
int(3);При помощи этого же синтаксиса можно инициализировать встроенные типы вроде int и float. Этот синтаксис называется прямой инициализацией. Она выполняется всегда, когда у нас есть аргумент в круглых скобках.
Для встроенных типов (int, bool, float) никакого отличия от копирующей инициализации здесь нет. Если же речь идёт о пользовательских типах, то, в отличие от копирующей инициализации, при прямой инициализации можно передавать несколько аргументов. Собственно, ради этого прямую инициализацию и придумали.
Кроме того, при прямой инициализации не выполняется последовательность преобразования. Вместо этого происходит вызов конструктора при помощи разрешения перегрузки (overload resolution). У прямой инициализации тот же синтаксис, что и у вызова функции, и используется та же логика, что и в других функциях С++.
Поэтому в ситуации с explicit конструктором прямая инициализация работает нормально, хотя копирующая инициализация выдаёт ошибку:
struct Widget {
explicit Widget(int) {}
};
Widget w1 = 1; // ошибка
Widget w2(1); // а так можноВ ситуации же с двумя конструкторами, один из которых explicit, а второй хуже подходит по типу, при прямой инициализации вызывается первый, а при копирующей — второй. В такой ситуации изменение синтаксиса приведёт к вызову другого конструктора — об этом часто забывают:
struct Widget {
explicit Widget(int) {}
Widget(double) {}
};
Widget w1 = 1; // вызывает Widget(double)
Widget w2(1); // вызывает Widget(int)Прямая инициализация применяется всегда, когда используются круглые скобки, в том числе когда используется нотация вызова конструктора для инициализации временного объекта, а также в выражениях new с инициализатором в скобках и в выражениях cast:
useWidget(Widget(1, 2)); // вызов конструктора
auto* widget_ptr = new Widget(2, 3); // new-expression with (args)
static_cast<Widget>(thingy); // castЭтот синтаксис существует столько, сколько существует сам С++, и у него есть важный недостаток, который упомянул Николай в программном докладе: the most vexing parse. Это значит, что всё, что компилятор может прочитать как объявление (declaration), он читает именно как объявление.
Рассмотрим пример, в котором есть класс Widget и класс Thingy, и конструктор Thingy, который получает Widget:
struct Widget {};
struct Thingy {
Thingy(Widget) {}
};
int main () {
Thingy thingy(Widget());
}На первый взгляд кажется, что при инициализации Thingy ему передаётся созданный по умолчанию Widget, но на самом деле здесь происходит объявление функции. Этот код объявляет функцию, которая получает на вход другую функцию, которая ничего не получает на вход и возвращает Widget, а первая функция возвращает Thingy. Код скомпилируется без ошибок, но вряд ли мы добивались именно такого поведения.
Инициализация значением (C++03)
Перейдём к следующей версии — С++03. Принято считать, что существенных изменений в этой версии не произошло, но это не так. В С++03 появилась инициализация значением (value initialization), при которой пишутся пустые круглые скобки:
int main() {
return int(); // UB в C++98, 0 начиная с C++03
}В С++98 здесь возникает неопределенное поведение, потому что происходит инициализация по умолчанию, а начиная с С++03 эта программа возвращает нуль.
Правило такое: если существует определённый пользователем конструктор по умолчанию, инициализация значением вызывает этот конструктор, в противном случае возвращается нуль.
Рассмотрим подробнее ситуацию с пользовательским конструктором:
struct Widget {
int i;
};
Widget get_widget() {
return Widget(); // value initialization
}
int main() {
return get_widget().i;
}В этой программе функция инициализирует значение для нового Widget и возвращает его. Мы вызываем эту функцию и обращаемся к элементу i объекта Widget. Начиная с C++03 возвращаемое значение здесь нуль, поскольку нет пользовательского конструктора по умолчанию. А если такой конструктор существует, но не инициализирует i, то мы получим неопределённое поведение:
struct Widget {
Widget() {} // пользовательский конструктор
int i;
};
Widget get_widget() {
return Widget(); // value initialization
}
int main() {
return get_widget().i; // значение не инициализировано, происходит UB
}Стоит заметить, что «пользовательский» не значит «определённый пользователем». Это значит, что пользователь должен предоставить тело конструктора, т. е. фигурные скобки. Если же в примере выше заменить тело конструктора на = default (эта возможность была добавлена в С++11), смысл программы изменяется. Теперь мы имеем конструктор, определённый пользователем (user-defined), но не предоставленный пользователем (user-provided), поэтому программа возвращает нуль:
struct Widget {
Widget() = default; // user-defined, но не user-provided
int i;
};
Widget get_widget() {
return Widget(); // value initialization
}
int main() {
return get_widget().i; // возвращает 0
}Теперь попробуем вынести Widget() = default за рамки класса. Смысл программы снова изменился: Widget() = default считается предоставленным пользователем конструктором, если он находится вне класса. Программа снова возвращает неопределённое поведение.
struct Widget {
Widget();
int i;
};
Widget::Widget() = default; // вне класса, считается user-provided
Widget get_widget() {
return Widget(); // value initialization
}
int main() {
return get_widget().i; // снова значение не инициализировано, UB
}Тут есть определённая логика: конструктор, определённый вне класса, может быть внутри другой единицы трансляции. Компилятор может не увидеть этот конструктор, поскольку он может быть в другом файле .cpp. Поэтому делать какие-либо выводы о таком конструкторе компилятор не может, и он не может отличить конструктор с телом от конструктора с = default.
Универсальная инициализация (C++11)
В версии С++11 было много очень важных изменений. В частности, была введена универсальная (uniform) инициализация, которую я предпочитаю называть «unicorn initialization» («инициализация-единорог»), потому что она просто волшебная. Давайте разберёмся, зачем она появилась.
Как вы уже заметили, в С++ очень много различных синтаксисов инициализации с разным поведением. Множество неудобств вызывала проблема vexing parse с круглыми скобками. Ещё разработчикам не нравилось, что агрегатную инициализацию можно было использовать только с массивами, но не с контейнерами вроде std::vector. Вместо неё приходилось выполнять .reserve и .push_back, или пользоваться всякими жуткими библиотеками:
// вот так было нельзя, а хотелось:
std::vector<int> vec = {0, 1, 2, 3, 4};
// приходилось писать так:
std::vector<int> vec;
vec.reserve(5);
vec.push_back(0);
vec.push_back(1);
vec.push_back(2);
vec.push_back(3);
vec.push_back(4);Все эти проблемы создатели языка попытались решить, введя синтаксис с фигурными скобками но без знака равенства. Предполагалось, что это будет единый синтаксис для всех типов, в котором используются фигурные скобки и не возникает проблемы vexing parse. В большинстве случаев этот синтаксис выполняет свою задачу.
Эта новая инициализация называется инициализация списком, и она бывает двух типов: прямая и копирования. В первом случае используются просто фигурные скобки, во втором — фигурные скобки со знаком равенства:
// direct-list-initialization
Widget widget{1, 2};
// copy-list-initialization
Widget widget = {1, 2};Используемый для иницализации список называется braced-init-list. Важно, что этот список не является объектом, у него нет типа. Переход на С++11 с более ранних версий не создаёт никаких проблем с агрегатными типами, так что это изменение не является критическим. Но теперь у списка в фигурных скобках появились новые возможности. Хоть у него и нет типа, он может быть скрыто преобразован в std::initializer_list, это такой специальный новый тип. И если есть конструктор, принимающий на вход std::initializer_list, то вызывается именно этот конструктор:
template <typename T>
class vector {
//...
vector(std::initializer_list<T> init); // конструктор с initializer_list
};
std::vector<int> vec{0, 1, 2, 3, 4}; // вызывает этот^ конструкторМне кажется, что со стороны комитета С++ std::initializer_list был не самым удачным решением. От него больше вреда, чем пользы.
Начнём с того, что std::initializer_list — это вектор фиксированного размера с элементами const. То есть это тип, у него есть функции begin и end, которые возвращают итераторы, есть собственный тип итератора, и чтобы его использовать, нужно включать специальный заголовок. Поскольку элементы std::initializer_list являются const, его нельзя перемещать, поэтому, если T в коде выше является типом move-only, код не будет выполняться.
Далее, std::initializer_list является объектом. Используя его, мы, фактически, создаём и передаём объекты. Как правило, компилятор может это оптимизировать, но с точки зрения семантики мы всё равно имеем дело с лишними объектами.
Несколько месяцев назад в твиттере был опрос: если бы можно было отправиться в прошлое и убрать что-либо из C++, что бы вы убрали? Больше всего голосов получил именно initializer_list.
https://twitter.com/shafikyaghmour/status/1058031143935561728
Джейсон Тёрнер недавно выступал с полуторачасовым докладом о том, как можно исправить initializer_list. Если вы хотите более подробно познакомиться с этой темой, я очень рекомендую этот доклад.
Давайе разберёмся, как работает новый синтаксис. Он вызывает конструкторы, которые принимают на вход initializer_list, и эти вызовы создают много проблем по сравнению с прямой инициализацией в старом синтаксисе. Часто приводят следующий пример:
std::vector<int> v(3, 0); // вектор содержит 0, 0, 0
std::vector<int> v{3, 0}; // вектор содержит 3, 0Если вызвать vector с двумя аргументами int и использовать прямую инициализацию, то выполняется вызов конструктора, который первым аргументом принимает размер вектора, а вторым — значение элемента. На выходе получается вектор из трёх нулей. Если же вместо круглых скобок написать фигурные, то используется initializer_list и на выходе получается вектор из двух элементов, 3 и 0.
Есть примеры ещё более странного поведения этого синтаксиса:
std::string s(48, 'a'); // "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"
std::string s{48, 'a'}; // "0a"В первой строке создаётся строка из 48 символов «а», а во второй строка «0а». Это происходит потому, что конструктор string принимает на вход initializer_list из символов. 48 является целочисленным значением, поэтому оно преобразуется в символ. В ASCII число 48 — код символа «0». Это очень странно, потому что есть конструктор, принимающий именно такие аргументы, int и char. Но вместо вызова этого конструктора происходит совершенно неочевидное преобразование. В итоге получается код, который чаще всего ведёт себя не так, как мы ожидаем.
Ещё больше трудностей возникает при использовании шаблонов. Как вы думаете, что возвращает эта программа? Какой здесь размер вектора?
template <typename T, size_t N>
auto test() {
return std::vector<T>{N};
}
int main () {
return test<std::string, 3>().size();
}Мы получим вектор с тремя строками, то есть ответ — 3. Но если string заменить на int, ответ будет 1, потому что для std::vector<std::int> будет использован initializer_list. В зависимости от шаблонного параметра вызывается либо конструктор initializer_list, либо другой конструктор. А если вместо string или int использовать float, я и вовсе не знаю, что выйдет. Предсказать поведение такого кода очень сложно, и это создаёт множество неудобств. Например, мы не можем написать emplace функцию, которая работала бы для агрегатных типов с синтаксисом фигурных скобок. В общем, агрегатная инициализиация и синтаксис {} не работают с шаблонами.
Теперь давайте разберёмся, что именно делает инициализация списком.
Для агрегатных типов при такой инициализации выполняется агрегатная
инициализация.
Для встроенных типов — прямая инициализация ({a}) или
копирующая инициализация (= {a});
А для классов выполняется такая последовательность:
- Вначале «жадно» выполняется вызов конструктора, который принимает
std::initializer_list.
Если для этого вызова необходимо сделать неочевидные преобразования — они выполняются. - Если подходящего конструктора нет, выполняется обычный
вызов конструктора()при помощи разрешения перегрузки.
Для второго шага есть пара исключений.
Исключение 1: при использовании = {a}, когда в списке один элемент a,
может быть использована инициализация копированием.
Исключение 2: пустые фигурные скобки, {}.
Пусть у нас будет тип с конструктором по умолчанию и конструктором, который принимает initializer_list.
Что происходит при вызове Widget<int> widget{}\?
template Typename<T>
struct Widget {
Widget();
Widget(std::initializer_list<T>);
};
int main() {
Widget<int> widget{}; // какой конструктор будет вызван?
}Мы ожидаем, что произойдёт вызов конструктора, принимающего initializer_list, поскольку мы передали ему пустой initializer_list в фигурных скобках. На самом деле тут вызывается конструктор по умолчанию. И только когда такого конструктора нет, вызывается конструктор, принимающий initializer_list. Если и такого конструктора нет, выполняется инициализация значением. К сожалению, все эти правила необходимо помнить.
Разберём подробнее инициализацию значением при использовании {}. Здесь, опять-таки, нужно помнить, что при Widget() = default и Widget() {} наблюдается разное поведение — об этом мы уже говорили.
Widget() = default:
struct Widget {
Widget() = default;
int i;
};
int main() {
Widget widget{}; // инициализация значением (нулем), не происходит vexing parse
return widget.i; // возвращает 0
}Widget() {}:
struct Widget {
Widget() {}; // user-provided конструктор
int i;
};
int main() {
Widget widget{}; // инициализация значением, вызывается дефолтный конструктор
return widget.i; // не инициализирована, возникает UB
}У инициализации списком есть полезное свойство: не допускаются преобразования, сужающие диапазон значений (narrowing conversions). Если для инициализации int использовать double, это является сужающим преобразованием, и такой код не компилируется:
int main() {
int i{2.0}; // ошибка!
}То же самое происходит, если агрегатный объект инициализировать списком элементов double. Это нововведение C++11, и оно вызывает больше всего ошибок при обновлении кода, написанного на более старых версиях языка. Это создаёт много работы при поддержке больших объёмов унаследованного кода:
struct Widget {
int i;
int j;
};
int main() {
Widget widget = {1.0, 0.0}; // ошибка в С++11 в отличие от C++98/03
}Далее, при инициализации списком можно использовать вложенные фигурные скобки, но, в отличие от агрегатной инициализации, с ними не работает пропуск скобок (brace elision). С одной стороны, использовать вложенные фигурные скобки бывает очень полезно, они вносят ясность. Например, у нас есть map. Тогда внешние фигурные скобки инициализируют этот map, а внутренние фигурные скобки — его элементы:
std::map<std::string, std::int> my_map {{"abc", 0}, {"def", 1}};Но бывают случаи, когда от этой конструкции только вред. Давайте рассмотрим такой случай:
std::vector<std::string> v1 {"abc", "def"}; // OK
std::vector<std::string> v2 {{"abc", "def"}}; // ??Напомню, это не агрегатная инициализация, это инициализация списком с initializer_list. В первой строке мы используем initializer_list из двух строк, поэтому в результате, очевидно, получается вектор из двух строк. А если заключить эти скобки в ещё одну пару фигурных скобок, получается неопределённое поведение. Попробуем разобраться, почему.
Внешний initializer_list имеет только один элемент — внутренний initializer_list, так что мы получим вектор с одной строкой. Эта строка инициализируется внутренним списком, в котором два const char*. Оказывается, у string есть конструктор, принимающий на вход итераторы char для начала и конца. Так что эти две строки преобразуются в итераторы. Далее выполняется чтение с начала, оно доходит до неинициализированной памяти, и программа падает.
Мораль:
- читайте списки с фигурными скобками снаружи вовнутрь;
- без агрегатного типа пропуск скобок не работает.
Идём дальше. Передача и возврат braced-init-list также является инициализацией копированием списка. Это очень полезное свойство:
Widget<int> f1() {
return {3, 0}; // copy-list инициализация возвращаемого значения
}
void f2(Widget);
f2({3, 0}); // copy-list инициализация аргументаЕсли происходит возврат по значению, то используется инициализация копированием, поэтому при возврате braced-init-list используется инициализация копированием списка. А если передать braced-init-list функции, это также приведёт к инициализации копированием списка.
Конечно, это приводит к некоторым затруднениям в случае со вложенными скобками. На StackOverflow недавно был замечательный пост, в котором рассматривался один и тот же вызов функции с разными уровнями вложенности. Выяснилось, что результаты на всех уровнях разные. Я не буду вдаваться в подробности, потому что там всё очень сложно, но сам этот факт показателен:
#include <iostream>
struct A {
A() {}
A(const A&) {}
};
struct B {
B(const A&) {}
};
void f(const A&) { std::cout << "A" << std::endl; }
void f(const B&) { std::cout << "B" << std::endl; }
int main() {
A a;
f( {a} ); // A
f( {{a}} ); // ambiguous
f( {{{a}}} ); // B
f({{{{a}}}}); // no matching function
}Улучшения в С++14
Итак, мы прошли все версии до C++11 включительно. Мы обсудили все инициализации прошлых версий, плюс инициализацию списком, которая часто работает по совсем не очевидным правилам. Поговорим теперь о C++14. В нём были исправлены некоторые проблемы, доставшиеся от прошлых версий.
Например, в С++11 у агрегатных классов не могло быть direct member initializers, что вызывало совершенно ненужные затруднения. Выше я уже говорил о том, что direct member initializers очень полезны. Начиная с С++14, у агрегатных классов могут быть direct member initializers:
struct Widget {
int i = 0;
int j = 0;
};
Widget widget{1, 2}; // работает начиная с C++14Второе улучшение Николай уже упоминал в программном докладе, оно связано с auto. Если в С++11 после auto следовал braced-init-list, это всегда приводило к выведению типа std::initializer_list:
int i = 3; // int
int i(3); // int
int i{3}; // int
int i = {3}; // int
auto i = 3; // int
auto i(3); // int
auto i{3}; // В С++11 — std::initializer_list<int>
auto i = {3}; // В С++11 — std::initializer_list<int>Такое поведение нежелательно: когда пишут auto i{3}, чаще всего имеют ввиду int, а не std::initializer_list<int>. В С++14 это поведение изменили, и auto i{3} теперь читается как int. Если же в фигурных скобках в этом примере несколько значений, то такой код не компилируется. Впрочем, auto i = {3} всегда читается как std::initializer_list<int>. Как видим, здесь всё равно остаётся непоследовательность: при прямой инициализации списка получается int, а при копирующей инициализации — initializer_list.
auto i = 3; // int
auto i(3); // int
auto i{3}; // в С++14 — int, но работает только для списка из одного элемента
auto i = {3}; // так и осталось std::initializer_list<int>Наконец, в C++14 была решена проблема со статической инициализацией, но она была значительно менее важной, чем те, о которых я сейчас рассказал, и останавливаться на ней мы не будем. Если есть желание, об этом можно почитать самостоятельно.
Несмотря на все эти фиксы, в С++14 осталось много проблем с инициализацией списком:
Не сразу понятно, вызывается ли конструктор, принимающий
std::initializer_list.
Сам
std::initializer_listне работает с move-only типами.
Синтаксис практичеcки бесполезен для шаблонов, поэтому
emplaceилиmake_uniqueнельзя использовать для агрегатных типов.
Есть некоторые неочевидные правила, о которых мы уже говорили:
- пустые фигурные скобки ведут себя иначе, чем не-пустые;
- вложенные фигурные скобки ведут себя неочевидным образом;
- auto работает не всегда очевидным образом.
Наконец, я еще не рассказал, что инициализация списка совсем не работает с макросами.
Пример про макросы: assert(Widget(2,3)) выполняется, а assert(Widget{2,3}) ломает препроцессор. Дело в том, что у макросов есть специальное правило, которое правильно читает запятую внутри круглых скобок, но оно не было обновлено для фигурных скобок. Поэтому запятая в этом примере рассматривается как конец первого аргумента макроса, хотя скобки ещё не закрыты. Это приводит к сбою.
Как правильно инициализировать в C++
Я могу предложить несколько советов относительно того, как правильно инициализировать значения в С++.
Для простых типов вроде int используйте инициализацию копированием, т. е. знак равенства и значение — так делается в большинстве языков программирования, к этому все давно привыкли и это наиболее простой вариант.
Фигурные скобки хороши в других ситуациях: для агрегатной инициализации, для вызова конструкторов, принимающих std::initializer_list, и для direct member initializers. В последнем случае мы не можем использовать синтаксис прямой инициализации, поэтому там лучше всего подходят фигурные скобки.
Кроме того, фигурными скобками удобно пользоваться для передачи и возвращения врeменных объектов. При помощи двух пустых фигурных скобок можно быстро сделать инициализацию значения временного объекта.
struct Point {
int x = 0;
int y = 0;
};
setPosition(Point{2, 3});
takeWidget(Widget{});Можно даже пропустить имя типа и использовать braced-init-list — это работает только с фигурными скобками.
setPosition({2, 3});
takeWidget({});Но если необходимо просто вызвать конструктор, то лично я предпочитаю использовать прямую инициализацию, то есть классический синтаксис. Я прекрасно понимаю, что в этом со мной многие не согласятся — Николай говорил, что предпочитает для этого использовать фигурные скобки. Мне кажется, что круглые скобки более очевидны, поскольку тогда синтаксис такой же, как при вызове функции, и сразу ясно, что выполняется разрешение перегрузки. Все правила здесь очевидны, не надо думать, есть тут или нет initializer_list. Мне этот подход кажется более простым и ясным: когда смотришь на такой код, сразу ясно, что он делает.
Ещё раз списком:
= valueдля простых типов
= {args}и= {}:
- для агрегатной инициализации
- для конструкторов от
std::initializer_list - для direct member initialisation (с ними нельзя использовать
(args))
{args}и{}для передачи и возврата врeменных объектов
(args)для вызова конструкторов
Правда, при использовании (args) мы сталкиваемся с проблемой vexing parse. Но на этот счёт есть ещё один совет. Герб Саттер в 2013 году написал статью, в которой говорилось, что при инициализации нового объекта практически всегда следует использовать auto. Мне этот совет кажется правильным, потому в этом случае все переменные всегда инициализированы: нельзя написать auto i; — это вызовет ошибку компиляции. Если же нужно указать тип, это можно сделать в правой части выражения:
auto widget = Widget(2, 3);Смысл тот же, но так вы никогда не забудете инициализировать переменную. Больше того, если следовать этой рекомендации и писать тип в правой части выражения, то не возникает проблемы vexing parse:
auto thingy = Thingy();Изначально это правило формулировалось как «почти всегда auto» («almost always auto», AAA), поскольку в С++11 и С++14 при таком написании код не всегда компилировался, как, например, в случае с таким std::atomic<int>:
auto count = std::atomic<int>(0); // C++11/14: ошибка
// std::atomic is neither copyable nor movableДело в том, что atomic нельзя перемещать и копировать. Несмотря на то, что в нашем синтаксисе никакого копирования и перемещения не происходит, всё равно было требование, чтобы использовался соответствующий конструктор, хоть вызова к нему и не происходило. В С++17 эта проблема была решена, было добавлено новое свойство, которое называется гарантированный пропуск копирования (guaranteed copy elision):
auto count = std::atomic<int>(0); // C++17: OK, guaranteed copy elisionТак что сейчас я советую всегда использовать auto. Единственное исключение — это direct member initializers. Элементы класса с помощью auto объявлять нельзя.
В С++17 также была добавлена CTAD (class template argument deduction). Оказалось, что у этого свойства есть довольно странные и не всегда очевидные следствия для инициализации. Эту тему уже затрагивал Николай в программном докладе. Кроме того, в прошлом году я выступал с докладом на CppCon, целиком посвящённым CTAD, там обо всём этом рассказано значительно подробнее. По большому счёту, в С++17 ситуация та же, что и в С++11 и С++14, за исключением того, что были исправлены некоторые самые неудобные неисправности. Инициализация списком сейчас работает лучше, чем в прошлых версиях, но, на мой взгляд, в ней ещё многое можно улучшить.
Назначенная инициализация (С++20)
Теперь давайте поговорим о С++20, то есть о грядущих изменениях. И да, вы угадали, в этом новом стандарте появится ещё один способ инициализации объектов: назначенная инициализация (designated initialization):
struct Widget {
int a;
int b;
int c;
};
int main() {
Widget widget{.a = 3, .c = 7};
};В сущности, это агрегатная инициализация с другим синтаксисом. В агрегатной инициализации мы указываем элементы в начале множества, и если некоторые пропущены в конце, то для них используется нулевая инициализация. С назначенной инициализацией можно инициализировать любое подмножество элементов, а для всех остальных применяется нулевая инициализация. В приведённом выше примере инициализируются а и с, а b равен нулю.
Важное преимущество такого подхода в том, что здесь, как и при агрегатной инициализации, не может быть неинициализированных переменных. Работает такая инициализация только с агрегатными типами, то есть фактически это другой синтаксис для агрегатной инициализации.
Сделано это было для совместимости с С, и работает так же, как в С99, с некоторыми исключениями:
в С не нужно соблюдать порядок элементов, то есть в нашем примере можно сначала инициализировать с, а потом а. В С++ так делать нельзя, поскольку вещи конструируются в порядке, в котором они объявлены. :
Widget widget{.c = 7, .a = 3}; // ошибка
К сожалению, это ограничивает применимость этой конструкции.
в С++ нельзя эту конструкцию нельзя использовать рекурсивно, то есть нельзя написать
{.c.e = 7};, хотя можно написать{.c{.e = 7}}:
Widget widget{.c.e = 7}; // ошибка
в С++ нельзя одновременно использовать назначенную и обычную инициализацию, но лично мне сложно придумать ситуацию, в которой это следовало бы делать:
Widget widget{.a = 3, 7}; // ошибка
в С++ этот вид инициализации нельзя использовать с массивами. Но, опять-таки, я не думаю, что это вообще следует делать.
int arr[3]{.[1] = 7}; // ошибка
Исправления в C++20
Помимо нового вида инициализации в С++20 будут исправлены некоторые вещи из предыдущих версий, и некоторые из этих изменений были предложены мной. Обсудим одно из них (wg21.link/p1008).
Когда в С++17 удаляется конструктор по умолчанию, это скорее всего значит, что автор кода хочет запретить создание экземпляров объекта. В агрегатных типах с удалённым конструктором по умолчанию инициализация по умолчанию выдаёт ошибку, но агрегатная инициализация работает, и это позволяет обойти удаление конструктора, сделанное автором класса:
struct Widget {
Widget() = delete;
int i;
int j;
};
Widget widget1; // ошибка
Widget widget2{}; // работает в C++17, но станет ошибкой в C++20Это очень странное поведение, чаще всего люди о нём не знают, и это приводит к непредсказуемым последствиям. В С++20 правила будут изменены. При объявлении конструктора тип больше не является агрегатным, так что конструкторы и агрегатная инициализация больше не входят в конфликт друг с другом. Мне кажется, это правильное решение. Если в классе нет объявленного пользователем конструктора, то это агрегатный тип, а если такой конструктор есть, то не агрегатный.
Было также реализовано ещё одно предложенное мной изменение (wg21.link/p1009). Braced-init-list можно использовать в выражениях new, поэтому часто спрашивают: работают ли они в этих выражениях так же, как при обычной инициализации? Обычно — да, но есть неприятное исключение: braced-init-list не выводит размер в выражениях new:
double a[]{1, 2, 3}; // OK
double* p = new double[]{1, 2, 3}; // ошибка в C++17, заработает в C++20Об этом просто забыли, когда в С++11 создавали braced-init-list. В С++ это будет исправлено. Вряд ли много людей сталкивалось с этой проблемой, но исправить её полезно для согласованности языка.
Прямая инициализация агрегатных типов (C++20)
Наконец, в С++20 будет добавлен ещё один способ инициализации. Я уже говорил о неудобствах инициализации списком, из них в особенности неприятна невозможность использовать её с шаблонами и с макросами. В С++20 это исправят: можно будет использовать прямую инициализацию для агрегатных типов (wg21.link/p0960).
struct Widget {
int i;
int j;
};
Widget widget(1, 2); // заработает в C++20То есть можно будет писать круглые скобки вместо фигурных для агрегатной инициализации. А это значит, что для агрегатных типов можно будет использовать emplace и make_unique. Это очень важно при написании библиотек. Вновь напомню: всегда используйте auto, то есть предыдущий пример я рекомендовал бы написать следующим образом: 58.11.
struct Widget {
int i;
int j;
};
auto widget = Widget(1, 2);Кроме того, эта новая возможность будет работать с массивами:
int arr[3](0, 1, 2);На мой взгляд, это очень важно: назовём это uniform инициализацией 2.0. Вновь будет достигнута некоторая однородность. Если агрегатную инициализацию можно будет выполнять и с фигурными, и с круглыми скобками, то, в сущности, круглые и фигурные скобки будут делать почти одно и то же. Исключение — конструктор initializer_list: если необходимо его вызвать, надо использовать фигурные скобки, если нет — круглые. Это позволяет однозначно указать, что именно нам необходимо. Кроме того, фигурные скобки по-прежнему не будут выполнять сужающие преобразования, а круглые — будут. Это делается для однородности с вызовами конструктора.
Итак, вновь повторим мои рекомендации. Всегда используйте direct member initializers. Всегда пользуйтесь auto. Для вызова конструктора я предпочитаю direct member initializers — мне кажется, это делает код понятнее. Но я понимаю, что многие придерживаются другого мнения по этому вопросу. Так что в конечном итоге выбор за вами — главное, чтобы вы знали все правила.
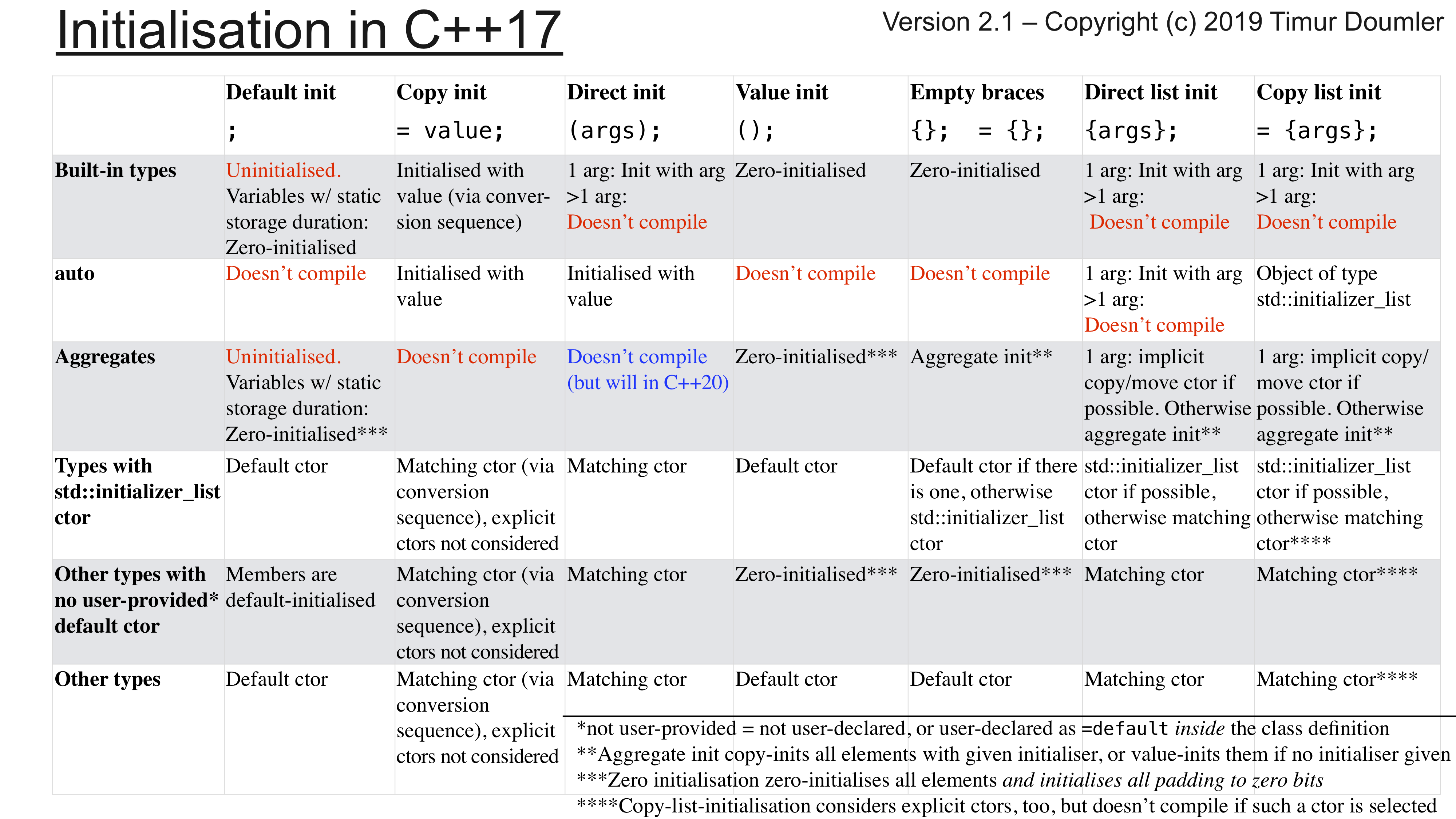
Я подвёл итог всему, что мы сегодня обсуждали, в таблице. Строки в этой таблице — различные типы, а столбцы — синтаксисы инициализации. На этом у меня всё, спасибо большое за внимание.
Уже совсем скоро, в конце октября, Тимур приедет на C++ Russia 2019 Piter и выступит с докладом «Type punning in modern C++». Тимур расскажет про новые техники, представленные в С++20, и покажет, как их безопасно использовать, а также разберёт «дыры» в С++ и объяснит, как их можно пофиксить.
technic93
Неудержался
KanuTaH
Баян.
0xd34df00d
А есть, кстати, соус этой картинки? Хочу сделать такое же, но про равенство в теориях типов.
technic93
У меня нету, картинка из интернетов)
ilammy
Это клип из «Форреста Гампа», там про креветки вместо C++.
excoder
Который день сижу и плАчу.
oktonion
Вот тоже не понимаю: что мешало? Ведь в конструкторах разрешили использовать любой порядок написания, что не влияет на порядок инициализации. А здесь вдруг порядок написания менять ни-ни.
excoder
Вот что говорят stackoverflow.com/questions/53250463/why-c20-doesnt-support-out-of-order-designated-initializer:
Конечно, понятно. По мне, это просто делает нововведение бесполезным. Так можно было бы эмулировать тэгированные параметры функций как в C# — завести параметры по умолчанию в середине, не запоминать порядок аргументов. А тут такая шляпа.
KanuTaH
Ну тут шляпа наполовину — пропускать элементы можно, но вот порядок сохранять придётся. У gcc и clang, кстати, различная реакция на изменение порядка следования именованных полей в списке инициализации — у gcc это ошибка, а у clang предупреждение о том, что поля будут инициализированы в порядке объявления, а не в порядке появления в списке.
khim
Предупреждение только в clang-10. И я рекомендую таки компилировать с -Werror=reorder-init-list, потому что альтернатива — это какой-то кошмар: объекты в этом случае инициализируются дважды, удаляются (sic!) во время генериации конструктора — и хотя оптимизатор обычно это безобразие изводит… лучше на это не полагаться. Потому что, когда, например, там ссылка, то… бывает всякое.
В общем хотя clang, вроде как, позволяет переставлять аргументы… лучше этого не делать.
khim
excoder
Согласен, что наполовину.
Мы не должны мириться с тем, что комитет загнал в угол сам себя.
По сути: кому помогал тот факт, что поля класса инициализируются в порядке их объявления в классе? Это массовый источник заблуждений. Все ожидают, что они инициализированы так, как ты записал в списке инициализации конструктора, и мне до сих пор приходится себя одергивать, когда я его пишу. То, что порядок инициализации не перегружен порядком, заданным мной к конструкторе, меня удивляет. Можно себя очень глубоко загнать — godbolt.org/z/NpFiI1:
Дальше, список инициализации в конструкторе не требует сохранять порядок как в классе, хотя оператор запятая у нас работает строго слева направо. Почему в списке инициализации можно, а в тэгированной инициализации нельзя? Может быть, комитету стоило поправить это место, и разрешить перегрузку порядка инцициализации с по-классовой к по-списочной?
khim
Не знаю кто такие «все»: я, как бы, всегда ожидал что конструкторы и деструкторы работают по принципу FIFO и меня всегда напрягало то, что компилятор вообще принимал другой порядок. Так как сбивает с толку. Слава богу сегодня это не проблема,
-Werror=reorderрулит.И вот именно это — и есть фундаментальная ошибка, которую когда-то сделал Страуструп.
Это тут вообще причём?
В тегированной переменной нельзя, так как ошибку, совершённую когда-то решили во второй раз не повторять.
По хорошему-то нужно сделать наоборот… и сделать
-Werror=reorderстандартом… но тут серьёзно пострадает обратная совместимость — так что вряд ли это когда-либо сделают.У C#/Java этой проблемы нет, так как деструкторов тоже нет, а для финализаторов ничего не гарантируется.
C, C++ и C# — это всё разные языки. С разными свойствами. Смиритесь.
excoder
Да, согласен. Без генерации компилятором отнаследованных классов с виртуальными деструкторами здесь не обойтись, никак не запомнить порядок инициализации полей для его раскрутки при разрушении объекта. Пойдём тогда ещё дальше — насколько действительно важно это «фундаментальное свойство» в прикладном коде на С++17? По мне так это скорее исключение, когда у вас эти поля ходят как-то друг к другу изнутри через ссылки или указатели друг на друга, и вам нужно отконтролить их жизненный цикл в совокупности — развязать направленный граф, так сказать. Часто ли?
khim
Если же рассматривать «идеоматичный C++17»… то это его основа. Поверх этого надстроены RAII, умные указатели и прочее, прочее, прочее. Так называемый «современный C++» чуть менее, чем полностью поверх этой концепции построен. Но да, это немного в расширительном смысле, с выходом за границы одного объекта.
А часто ли вас вообще волнует в какой последовательности подъобъекты конструируются? В моей практике ситуация такая:
1. В подавляющем большинстве случаев мне вообще пофигу в какой последовательности подобъекты конструируются и уничтожаются.
2. Зато уже если так случилось, что мне это не всё равно… то почти всегда мне при этом нужно и чтобы и удалялись они тоже в предсказуемой последовательности.
excoder
Совершенно согласен.
Я понимаю, что RAII, copy elision и пр. полагаются на фундаментальное свойство. Я не могу ответить, как. Я хотел бы иметь этот ответ, чтобы объяснить изучающим С++: «это так, ПОТОМУ ЧТО вот», а не просто «потому что». Пока не могу. Может быть, поможете :)
Конкретно, вот например RAII. Почему ИМЕННО ему важен детерминированный порядок инициализации и разрушения?
Хочется показать 2-3 примерами, что фундаментальное свойство — так его и назовём — не вещь в себе, а требование корневых механизмов С++.
KanuTaH
Самый элементарный пример — мутексы. Мутексы по-хорошему должны освобождаться строго в обратной последовательности по отношению в той, в которой они были захвачены, иначе могут быть всякие неприятные следствия в виде дедлоков. RAII в текущей реализации это обеспечивает автоматически. Далее, если есть ресурсы, зависимые друг от друга, например, файл и поток, то логично, что сначала должен открыться файл, потом на его основе быть создан поток, а при их разрушении наоборот — сначала должен закрыться поток, сбросить там кеши всякие и так далее, а потом уже должен закрыться файл, к которому он относится.
excoder
Спасибо. Это, правда, не «нутро» RAII, а всё же частный случай. Но будет ли в этом частном случае хорошим тоном полагаться на порядок, выбранный компилятором? Очень уж неявно — почва для ошибок. Human first, вы же понимаете. Разве не стоит сделать что-то типа:
Конечно, если я СЛУЧАЙНО поменяю порядок строк с r и m местами, будет беда. Захотеться случайно менять этот порядок, если я внесу его в конструктор, уже не должно. Попробуйте.
Мне кажется, очень уж самонадеянно и высоколобо было отдавать именно порядок инициализации и деинициализации на роль «RAII для класса как scope».
KanuTaH
Так все детерминировано же в подавляющем большинстве случаев (за исключением разве что глобальных объектов со static storage duration из разных модулей) — и в каком порядке вызываются конструкторы, и в каком деструкторы, причем все сделано, так сказать, естественным образом — конструкторы в порядке объявления соответствующих переменных, деструкторы в порядке, обратном вызову конструкторов. Не вижу тут проблемы, все сделано естественно и удобно.
excoder
Я вижу, и не я один. Случайно поменять порядок объявлений очень легко, особенно если работаешь не только с С++. Варнингов типа «warning: order of member declarations changed since last time» у нас нет и не будет. Потому — defensive programming, явно задаём порядок кодом, если он нужен, не полагаемся на сомнительную фичу. Она безусловно детерминирована, но настолько неявна, что лучше её полностью игнорировать.
Я совершенно понимаю, что они хотели ей сказать — что, мол, типа, раз в куске кода переменные у нас создаются на стеке в порядке их появления в коде, то пусть так будет и в scope класса, круто же, единообразно? Но, нет, не круто. Люди не смотрят на класс как на линейный код, потому что класс — не линейный код. Это НЕУПОРЯДОЧЕННЫЙ набор полей и методов.
KanuTaH
Хозяин — барин :) Никто не мешает использовать defensive programming. Но и в детерминированности относительно порядка инициализации и уничтожения в данном случае я ничего плохого тоже не вижу.
excoder
А потом начинается ещё… Поля в структурке перетасовать, чтобы утрясти размер, а тут порядок понимаешь ли, и т.д. и т.п. Знай сиди и рефактори до бесконечности свои назначенные инициализации :)
khim
Ну так вы уж определитесь — либо у вас класс это «НЕУПОРЯДОЧЕННЫЙ набор полей и методов», либо вы хотите «поля в структурке перетасовать».
Первое со вторым, как бы, не очень совместимо…
excoder
Дык я только и хочу их перетасовать, что у C++ такие правила выравнивания :) У нормальных людей класс — это логическая единица, неупорядоченный набор полей и методов. В С++ класс имеет мало общего с этим определением, т.к. он сразу тебя окунает в свою физику.
khim
Спорить об истинных шотладцах я не собираюсь, извините.
Есть и языки, где в класса во время работы программы могут появляться и исчезать поля во время работы программы (см. MOP) — и именно таким был ООП изначально.
Считать ли теперь C# и Java «ущербными» из-за того, что там это невозможно сделать? Вопрос, как обычно, философский.
Класс в C++ — это упорядоченная последовательность полей и методов. И их порядок — важен. Как бы вам ни хотелось чего-то иного.
khim
Нет, нет и нет. Почитайте правила, хотя бы:
You cannot…
For virtual member functions
change the order of virtual functions in the class declaration.
А уж про добавление/удаление полей я вообще молчу: поля (даже приватные) — это часть интерфейса класса. И, разумеется, их порядок важен.
Да, в C++ есть вот такие вот, несколько странные и неожиданные «правила игры» — но это плата за эффективность.
Какой смысл платить за них, но не использовать? Для этого другие языки есть…
excoder
Я как раз об этих правилах. Виртуальная функция — это типа указатель, со всеми вытекающими. Снова возвращаемся к фундаментальному правилу. Это мне и вам понятно. Понятно ли начинающим? Отнюдь. Все нормальные люди и начинающие считают класс НЕУПОРЯДОЧЕННЫМ множеством. ООП. В C++ же оно оказывается скорее упорядоченным, нежели нет. Скажем, частично и упорядоченным. Об этом кричат? Нигде не встречал. :) Хотя, о чём кричат на CppCon и иже с ним — о том, что «нам учить других этому языку, и с этим гигантская проблема».
excoder
khim
Я о том, что момент, когда будет освобожден объект, указатель на который хранится в unique_ptr определяется ровно-таки такими «нинужнами» правилами вызова деструкторов.
И да, можно объединить недостатки C++ и C явно вызывая эту операцию с помощью
.reset(nullptr)— вот только зачем в этом случае вообще нужны умные указатели — неясно совершенно.Вообще неясно зачем при использовать язык, основным и главным достоинством которого являются неявные операции (неявное преобразование типов, неявный вызов конструктора и деструктора и так далее) и носиться с лозунком «явное лучше неявного».
Хотите всего явного — есть же C, чёрт побери!
0xd34df00d
Теперь у вас одна и та же информация продублирована дважды — в объявлении класса и в объявлении его деструктора.
Так, конечно, лучше.
khim
Там ещё гораздо веселе получается (я ссылки на godbolt приводил): из-за этого дурацкого
resetа компьютеру приходится выполнять больше работы, что выливается в лишний код — и да, я могу привести весьма патологическую программу, которая будет от этого кода зависеть, так что это не «недоработка в компиляторе» — это сознательно написание плохого, плохо оптимизируемого, кода.excoder
khim
Ну вот простейший пример:
Вы хотите сказать, что не понимаете почему Foo более эффективен, чем Bar?
Или тут:
Тоже загадка?
Пруверы могут лишь что-то сказать про модель мира, которая у них есть. А у разработчиков C++ как раз проблемы с описанием этой модели, извините.
Такой пример:
Какой из классов быстрее? Неужели думате, что без разницы? Нет — разница таки есть… только вот в зависимости от программы быстрее может быть как Foo, так и Bar. И куда вы это в своём «прувере» засовывать собрались?
kdmitrii
Для меня загадка почему Foo более эффективен. Очень желателен бенчмарк собранным последними GCC/clang (со всеми оптимизациями, разумеется).
DistortNeo
Всё дело в выравнивании полей и особенностях невыровненного доступа на различных архитектурах.
khim
Нет, дело не в вырванивании, тут всё во всех структорах выравнено. Вопрос в кешировании и взаимодействии вот этого вот всего с кеш-линиями. Заметьте, кстати, что в последнем случае не будет никакой разницы, если вы положите эти структуры в массив, выигрыш будет если вы будете выделять память в стиле Java — отдельно для каждой структуры. Причём ведь ещё и окажется что от malloc'а это зависит!
В любом случае — это вещь, которую ни компилятор, ни формальный «прувер» не в состоянии правильно запроектировать. Потому что всё зависит от структуры вашей программы. Причём не локальной, а глобальной.
И никто, кроме вас не будет знать что для вас полезнее — увеличить размер структуры, но добиться того, чтобы данные лучше ложились в кеш-линии, либо уменьшить — и добиться, чтобы страктуры не вытесняли другие данные из L1.
DistortNeo
Дык, выравнивание по размеру кэш-линии.
Но мне кажется, что ситуаций, где это будет оказывать реальное влияние на производительность, будет очень и очень мало. Плюс будет жёсткая привязка к конкретному процессору.
Конкретно в моём случае возня с кэшем играла роль только при эффективной реализации математических алгоритмов.
0xd34df00d
А я что-то про false sharing подумал. Типа, разнести независимые вещи подальше друг от друга.
И вы, кстати, во всех этих случаях
alignas(64)забыли.sizeof(T) == 64не гарантирует помещения всего значения в одну кешлинию.khim
alignas(64)— большинство маллоков разместят эту структуру так, что, противоестественным образом, версия соstringвначале будет быстрее, если мы будем часто обращаться к координатам… и наоборот, она будет медленнее, если мы будем чаще отращаться к строкам.И да — всё это дико патологический случай. В большинстве случаев такая тонкая оптимизация никому особо не нужна — я просто хотел показать, что у компилятора нет никакой, ну вот совсем никакой возможности всё и всегда сделать «оптимально». Это от программы зависит.
Значит ли это, что нельзя сделать лучше, чем в C++? Нет, не значит, в Rust сделано лучше: обычно компилятор подбирает layout структур сам, «способом, приближенным к оптимальному», но если очень надо — layout можно задать самому, как в C/C++.
Нужно ли это фичу тащить в C++? Не уверен: практически в 99% случаев заметной разницы между «тупым» варинтов, когда вы размещаете поля так, как вам удобнее о них думать и «способом, приближенным к оптимальному», как в rust — не будет, а там где это окажется важно — компилятор, скорее всего, не очень-то и справится.
Но нужно больше наблюдений за практическими проектами на Rust.
khim
Вообще там три примера. И если вы не понимаете как состряпать бенчмарк, чтобы показать их эффективности-неэффективность, то дальше не очень понятно о чём вообще говорить.
Ну это всё равно как обсудлать с человеком, чинящим телевизоры путём сбрасывания их с обрыва (в надежде, что детали встанут на место и телевизор заработает) наилучший вид обрыва для этого: крутой там или не очень… вообще-то телевизоры не так чинятся… и программы не так оптимизируются.
kdmitrii
Нука нука, хочу узнать как там кто "правильно" оптимизирует. Начнём с простого. Об оптимизации чего вообще речь? Доступа к полям? Аллокации пустой структуры? Ее заполнения?(если это пункт, то как заполняется строка?)
khim
Ну в первом случае это очевидно: раз у нас два независимых мьютекса, то большой шанс, что они будут браться независимо. И, стало быть, нахождение их в одной кеш-линии — крайне нежелательно. Хотя можно себе представить и патологическую программу, где всё наоборот.
Тоже варинт. Странный, но возможный.
Это может быть как строка с сообщением об ошибке (в большинстве случае пустая), так и ключ поиска (к которому обращаются чаще всего).
Да, вы правы — без знания того, что, кто, когда и как делает с этой структурой не только бенчмарки бессмысленны, но и вообще — неясно под какой паттерн доступа к памяти мы всё это оптимизировать хотим.
И если бы были заданы эти вопросы — претензий бы не было. Но ведь от меня просят объяснить не это. А просто показать бенч. Ну состряпаю я его — дальше что? Что и кому это покажет?
excoder
Это физика. Меняю порядок полей для оптимизации — почему это должно сказываться на физике назначенной инициализации? Почему эта локальная оптимизация (делаю поля соответствующими схеме доступа к ним) должна меня заставлять перетасовывать прочие места кода? И вообще, по-хорошему, переупорядочить поля согласно паттерну доступа, кто там первый загрузится в кэши с кодом и т.д. — это задачка для PGO.
khim
Так-то рассказы на тему «а чёт-то мне звезду с неба не сняли и на блюдечке с голубой каёмочкой не поднесли» каждый может сочинять… вот только компиляторы от этого не образуются…
Это мы уже обсуждали, извините.
0xd34df00d
О пруверах я всегда рад поговорить, но у чуваков из комитета есть один очень сложный и всё ломающий констрейнт: совместимость с С.
Кстати, на заседание комитета вы можете приехать, предлагать там пропозалы, участвовать в обсуждениях и даже голосовать. Это абсолютно бесплатно (с точностью до оплаты билетов/гостиницы) и ничего от вас не требует.
Позволяет делать всякие трюки с памятью. Придумать достаточно замкнутый и самообоснованный пример, впрочем, сложно.
khim
resetы убрать — это уже даст 48 байт экономии в 10 инструкциях (да и быстрее будет).Вообще ваша проблема в том, что вы, с одной стороны, хотите использовать C++ потому что он быстрый и эффективный, а с другой — вы его ненавидите потому, что он неSOLIDен!
Но блин, неужели же вы не понимаете, что SOLID (при всех его положительных чертах в смысле удобства поддержкания кода и прочего) — страшно неэффективен? Идеоматичная программа на C#/Java в типичном случае медленее идеоматичной программы на C++ не потому, что C#/Java медленные JIT'ы имеют! Программа, написанная на C#/Java с учётом особенностей CPU может и быстрее программы на C++ быть!
Соответственно чтобы не обижаться на комитет по стандартизации C++ нужно просто выбрать: хотите вы быстрый язык… или SOLIDый! И всё, проблема решится.
excoder
Хорошо, фиг с ним, с этим поинтером. Согласен, поинтер перебор. Облегчим структуры. Что хотел показать тем примером: godbolt.org/z/OVirOQ (моё) / godbolt.org/z/LFds9y (ваше). Один-в-один. Собственно, я хотел явности в порядке, оно теперь у меня есть. Совсем по-хорошему нужен ещё свой std::reference_wrapper, который бы можно было инициализировать nullptr с дебаг-ассертами на обращение к нему пустому, чтобы не ничего не делать с сырым ptr. Да, здесь я, безусловно, борюсь с языком, лишь бы не полагаться на «фундаментальное правило», ожидая такой защитой, что кто-то о нём точно забудет. Что ж поделать, раз так задизайнили язык.
khim
release. Ну и? Чего вы этим, собственно, добиваетесь?А зачем?
Это вряд ли. То есть заставить кого-то выкинуть ваш код и написать нормальный, читабельный, наверное кого-то вы и сможете побудить (хотя зависит от того, насколько этот ужас его «достанет»). А вот забыть о том, что C++, всё-таки, должен выглядеть по другому… это вряд ли.
Выбрать другой язык? С тем же успехом можно сказать, что в английском и русском глагол «не там» стоит — и начать разговаривать в стиле Йоды. Ничего, кроме смеха вы, таким образом, не добъётесь.
excoder
Повторюсь — я отлично понимаю, чего добивались таким дизайном авторы языка. Решили не плодить сущности без необходимости, встроили порядок инициализации в порядок объявлений. Окей. Я считаю, это ошибка — вписывать низкоуровневый аспект физического дизайна в логическую структуру кода. Нужна была другая сущность. Это всё можно сделать zero-cost, конечно же.
Более того, я считаю, что именно этим правилом они и порочат zero-cost abstraction принцип. Цена этой абстракции — что с новыми фичами код теперь надо причёсывать на каждую перегруппировку переменных. Цена — производительность итоговой программы ценой этой вот возни, стоящей времени программистов, когда как ту же производительность можно было бы сохранить введением явного означения порядка как отдельной сущности. Да и даже улучшить — некоторые, например, просто не пожелают лишний раз перегруппировывать порядок определений, дабы не рефакторить массу кода.
excoder
Ну хотя бы:
И мне это даёт всё сразу. Компилер выведет порядок r->m, потому что я явно о нём пишу. Сейчас я могу переставить две эти строки и получится ерунда. Для o я ПОЧЕМУ-ТО хочу, чтобы o шло после r. Пожалуйста — задаю это. Всё явно, компактно, и нет прочих требований, связанных с тем, что этот порядок будет влиять на то, как вы выписываете код, использующий Owner. Я не понимаю, почему развязку и наполнение ациклических графов зависимостей нельзя возложить на компилятор, и я должен этим заниматься.
Естественно, когда задизайнили это нынешнее правило с порядком, не было аннотаций, как минимум. Но чем они думали (или может быть даже ОН? не упомню, писал ли он об этом конкретно аспекте в Design and Evolution of C++), когда видели, что даже когда r явно зависит от m, компилятору на это по боку, и язык ничего не требует. Бред же. Вы защищаете плохой дизайн, я считаю.
excoder
Тут ещё что страшно в языке:
Хоть у меня там всё НА ССЫЛКАХ, это таки скомпилируется. Даже ворнинга не приходит. И это страшно. Конечно, можно верить, что дураки не прикоснутся к вашему коду и т.д. Но жизнь расставляет всё по местам.
technic93
Согласен, имхо изначально была история запутанная: Типа давайте сделаем чтобы внешне было как на си только ооп, потом такие — блин у нас тут гораздо больше сущностей чем в си, ладно наделим каждую строчку дополнительным скрытым смыслом.
khim
Фичи в языке появляются не по желанию чьй-то левой пятки. Кто-то должен написать попозал, провести оценку полезности, убедить комитет в том, что решаемая проблема — таки реальна… продумать как всё это будет согласовываться с другими фичами языка… и да, вот после всего этого — можно и в стандарт включить…
Почему бред? Не вижу ничего странного в том, что метка текстового поля будет знать о своём текстовом поле. Просто она не должна будет, в этом случае, пытаться обращаться к нему в конструкторе и деструкторе — но само-по-себе знание вполне законно.
Я не «защищаю» «плохой» дизайн. Я объясняю почему он таков, каков он есть.
Хотите другого дизайна? Вперёд! Языков в мире — тысячи, если не миллионы. Можете и свой создать.
Но делать вид, что язык устроен не так, как он устроен и «бороться» с ним… ну что за детский сад, ей богу… назло бабушке отморожу уши…
excoder
Да уж и совсем в простом.
Это комитет расстреливает нам ноги.
KanuTaH
Это комитет за вас этот код пишет? :) И, кстати, ничего такого страшного в нем нет. d в Host будет проинициализирован ссылкой на d из Mixed, вот и все, все вполне валидно. До тех пор, пока вы в конструкторе Host по этой ссылке не полезете в еще не инициализированные внутренности этой d из Mixed, ничего страшного не случится.
excoder
Не за меня. Так я ж не все. Может я конечно упустил, где в C++ Guildelines этот момент ловится, или clang-tidy может словит? В любом случае — это намеренное проталкивание ногострелов, когда без них можно было обойтись без какой бы то ни было потери производительности кода.
KanuTaH
Что именно он должен словить? Еще раз — код, который вы привели выше, вполне валидный.
excoder
Так уж и не додумаете? :) Хорошо: godbolt.org/z/KuYMzu. Ронять не буду — но вы поняли. Меняю местами объявления — получаю 3 на выходе вместо 1.
KanuTaH
Там не тот код, что в вашем комментарии выше. Я же написал — «до тех пор, пока вы в конструкторе Host по этой ссылке не полезете в еще не инициализированные внутренности этой d из Mixed, ничего страшного не случится». А вы полезли.
P.S. Вы занимаетесь манипуляциями. Это все равно, что назвать «проблемным» код типа такого:
а когда вам справедливо укажут, что код корректный, прислать ссылку на годболт с «немного измененной» версией:
и вы такой: «ага-ага, видите-видите, упало!» :)
excoder
На ваш пример -Wreturn-local-addr -Wall же. А вот решить ошибки с порядком объявлений без санитайзеров уже никак.
khim
Вопрос не в том, кто чего ловит. Вопрос в том, что вы либо не разбираетесь в предмете, либо сознательно всех путаете.
В вашем примере выше никаких проблем не было. Ну вот совсем никаких. А вашем примере, который упал — были. При этом вы упорно делаете вид, что это — эквивалентные примеры.
Вывод: вы либо не знаете C++, либо троллите. Судя по остальным комментариям — я склоняюсь ко второму.
excoder
Я не могу принять вот эту запись беспроблемной:
Она компилируется, но может привести к неочевидным последствиям в будущем (при развитии кода классов). Это было показано в последующих примерах.
qw1
Справедливости ради, конструктор Host получает и сохраняет ссылку, которую можно будет потом (после завершения конструктора) использовать. В некоторых случаях, ничего криминального.
excoder
Да, см. godbolt.org/z/KuYMzu.
khim
Что я там должен был увидеть? Ваше незнание (или, возможно, сознательное игнорирование) спецификаций?
Язык вполне последовательно описывает когда и как к разным объектам можно достучаться.
Да, С++ не пытается диктовать вам условия. И ошибок типа «illegal forward reference» Java в нём нет — но, кстати, уже сами эти ошибки показывают нам, что класс — это, всё таки упорядоченный набор полей даже в Java. Кстати там тоже можно получить вариант, когда порядок объявления полей важен даже в программе, которая компилируется. Легко.
excoder
Что вы всё про меня-то. Я показываю гипотетическую ошибку. Не мою. Её непросто отловить из-за дизайна языка.
khim
Также, во многом из-за этого, в качестве альтернативы разработан Rust… который пока C++ не заменил, но имеет шансы (напомню, что C был разработан в 70е, но ещё в середине 80х куча коммерческого софта, включая аж целую известную операционку писалась на Pascal… замена языков — вообще небыстрое явление).
Вы же предлагаете вместо этого отказаться от всех преимуществ, которые даёт такой подход, одновременно продолжая платить за все его недостатки — и ради чего? Чего вы этим хотите добиться?
qw1
С другой стороны, а если кто-то гениальный много пользуется перекрёстными ссылками на ещё не сконструированные объекты, и у него всё корректно написано
excoder
Почему не скомпилируется? Здесь циклическая зависимость. Ворнинг было бы хорошо о циклической зависимости, раз. Дальше можно было бы выбрать порядок a1, b, root, a, исходя из числа входящих рёбер — сперва инициализируем менее зависимые. Перегрузить порядок — через аннотацию.
KanuTaH
Ну внесите proposal. Но, честно говоря, я что-то не припомню попыток вносить подобные proposal, что говорит о том, что детерминированный порядок инициализации полей класса в порядке их объявления особых возражений не встречает.
khim
Примеры вам привели. И да, пример, который вы придумали сами (когда объекты «живут» внутри другого объекта, при этом имеют так же ссылки и друг на друга) — тоже не редкость. Скажем метка и поле ввода, помеченное этой меткой. Не так важно — кто из них создаётся и удаляется первым… но после того, как вы об этом договоритесь (допустим первым удаляется поле ввода) то вам потребуется, чтобы это правило никогда не нарушалось (так как, напрмер, поле ввода будет «иметь право» обращаться к метке).
Пришельцам из C#/Java это тяжело понять, но код в конструкторе в C++ — отнюдь не является редкостью (в отличие от финалайзеров в C#/Java)… и это происходит именно потому, что язык даёт гарантии на тему того, когда они вызовутся.
excoder
Ну как. Я живу в C++ с 2001 года, а вот к .NET и Python лишь захаживаю. Привыкнуть за 18 лет к странному дизайну с порядком инициализации, заданном именно порядком декларациями полей, как-то не довелось и не желалось. Вернее, ни разу не доводилось на него полагаться — в случаях зависимостей и нужности порядка задавал его явно. Явное лучше неявного. Теперь же эта «фича» ещё и продолжает ограничивать развитие языка.
А вот наблюдать за адекватным развитием некоторых языков доводится с завистью. Хочется все 18 лет писать менее многословный прикладной код на С++ без птичьего щебета, запоминания порядка переменных в уме и мрака вроде www.boost.org/doc/libs/1_62_0/libs/parameter/doc/html/index.html. Экстраполировать отсутствие естественных фич в языке многоэтажным метапрограммированием — это как-то не очень.
khim
Ещё раз: не путайте python с C++! В C++ очень много чего происходит неявно, стараниями компилятора. Это — почти что строго противоположный подход.
А зачем его в уме-то запоминать? Компилятор ошибку выбросит, вы исправите… делов-то. IDE, опять-таки, подсказку может показать…
Не вижу ничего «естественного» в бардаке. Я даже в python стараюсь передавать параметры в том порядке, в котором они идут в описании функции. Хотя там их, как раз, можно их переставлять. То, что C++ этого требует (во всяком случае у нас, при использовании
-Werror=reorder) — мне скорее нравится. Больше порядка.excoder
Извините, я считаю, порядок ради порядка не имеет смысла. Компилятор за вас может упорядочить аргументы из неупорядоченного списка-множества. Зачем вручную делать работу компилятора? Это же противоречит идее С++ — вы сами выше говорите, «компилятор много чего делает за нас», так? Так.
Была бы моя воля — не юзал бы Питон вообще кроме как в билд-системе, и делал бы нейронные сети на C++. Но из-за ограничений языка всё это получается настолько многословным, что деревья теряются в лесу.
Ну я что могу сказать. Если бы я продавал часы — это мне всё на руку было бы. Как можно хорошо плюсануть к ивойсу это всё. Но так как я сам себе заказчик, а замены С++ по эффективности нет, вся эта мышиная возня мне сооовсем не на руку.
Я хочу элементарно писать код в pythonic-стиле, то бишь — прозрачно, компактно. Мы получаем плюшки в эту сторону, не скрою. Сколько мы их ждали, правда — другой вопрос. Поэтому, безусловно, в 2019 я могу себе позволить писать С++-код в куда более Pythonic-стиле, чем в 2011.
khim
Потому что на примере конструкторов уже убедились, что когда компилятор за человека делает эту работу — человек оказывается недоволен.
0xd34df00d
Это три объявления одной и той же функции. Компилятор должен учитывать все возможные имена их всех? Окей.
Какая перегрузка должна быть вызвана?
А если я теперь переименую аргумент в первой перегрузке с
argнаotherArg?Но это цветочки, ща ягодки будут.
Класс. Мы научились определять в компилтайме имя параметров метода и делать по ним перегрузку. Вы способны просчитать влияние этого на весь стандарт? Вы уверены, что теперь имена аргументов не протекут в ABI? Я — нет, на оба вопроса. Зато я точно знаю, что это просто машина для генерации ODR violations.
khim
Всё это, в принципе, разрешимо — но очень сильно меняет весь язык и совершенно неясно: насколько это реально облегчает жизнь.
В следующем смысле: да, я знаю что работать с API типа Win32 API, где у каждой функции по 10 аргументов, многие их которых — это структуры с кучей полей… неудобно и сложно… но может быть вместо кардинальных изменений языка лучше — не создавать таких API без крайней необходимости?
technic93
Кстати в расте так нельзя сделать совсем, и я думаю в том числе потому что нету этого провалила про порядок полей в структуре
excoder
Про move-семантику стоило бы упомянуть, ну и об этом вот: www.youtube.com/watch?v=PNRju6_yn3o.
MooNDeaR
В разделе про агрегатную инициализацию:
Есть один нюанс, касающийся subaggregates и о котором не было упомянуто. Возьмем вас же пример и слегка его модифицируем
Однако, GCC это всё же компилирует для С++11, но для С++98 отказывается.
UPD:
Как бы да, но только при наличии какого-то рантайма. На bare metal придется самому на этот счёт заморочиться.
Mingun
Кстати, если сравнить с примером повыше (где в
ThingyдваWidget-а), непонятно, почему не разобрана такая ситуация:KanuTaH
А в чем здесь неоднозначность? В упомянутой строчке производится aggregate initialization структуры из 2 элементов, первый элемент (Widget w) агрегатом не является (так как у Widget есть user-defined constructor), этот конструктор не explicit, соответственно он и будет вызван.
TheGodfather
Класс, прикольно осознавать, что был на докладе того же чувака на эту тему вживую на небольшом митапе в Мюнхене :)
andy_p
А где в Мюнхене такие митапы проходт?
TheGodfather
Ну конкретно этот в офисе Джетбрейнс был. А вообще — митап дот ком :)
MooNDeaR
В разделе про назначенную инициализацию (designated initialization):
В GCC есть расширение (а может это даже часть С11, я не проверял), которое позволяет писать на Си вот так:
Очень удобный синтаксис на мой взгляд и вполне мог бы пригодиться и в С++. Кстати, совсем не зависит от порядка элементов в квадратных скобочках.
khim
Это всего-навсего C99, даже не C11. И как, обычно, если его прикрутить к C++ и присывать ссылками… компилятор породит код, который завернёт вас всё программу в бараний рог.
По крайней мере clang.
assembled
Синтаксис удобный, но конкретно в этом примере структура наверное лучше подойдет.
Кстати интересно почему его не спешат в кресты добавлять, боятся усложнять парсер из-за неоднозначности с синтаксисом лямбд?
khim
Если запретить описывать значения строго по порядку, то он не особо и нужен, а если разрешить — то возникают противоречия в правилах.
И да, в большинстве практически важных случаев можно использовать структуры.
nikkolla
А разве не нулем?
slonopotamus
А еще вот это одно и то же:
Не говоря уже о том что мне вообще непонятно как можно некомпилирующийся код посчитать за «способ инициализации переменных».
barbos98
Если погромист ответственный пацан, то он пальчиками должен проинициализировать каждую переменную, обьект etc. Ибо при переходе на новую версию компилятора/компьютера/операционной системы возможно int i при первом обращении будет не нуль и даже не 255 в восьмибитных или 2^64 в соответствующих системах. И тогда шагай step-by-step ищи, где собака порылась. И не надеяться на порядочность компиляторописателей. Они тоже люди. Просто выносим инициализацию в include и все дела. Иначе старый добрый С++ превратится в Васик с непредсказуемыми результатами runtime. Я так думаю(с)(Фрунзик М.)
khim
Не надо так думать. Да, в компиляторах есть ошибки — но предоставьте уж их разработчикам компиляторов.
Попытка вот так вот «удушить всё» в краткосрочной перспективе ничего не улучшает, а в долгосрочной перспективе ухудшает: если таких умных, как вы, оказыватся много, то компилятор учат ваш код игнорировать, в этом игрировании обнаруживаются ошибки… ну и дальше — классика, гонка вооружений…
technic93
Но тем не менее, явное лучше не явного.
khim
Это вы С++ с python перепутали. И то — даже там есть
with.А C++ чуть менее, чем полностью, состоит из «неявного»: всякие RAII, хитрные вызове конструкторов и прочее.
Хотите, чтобы всё было явно — программируйте на C.
technic93
Да на самом деле бесит что примитивные типы ведут себя не так как нормальные классы. Почему конструктор по умолчанию не определен у int?
qw1
Чтобы не платить за то, что не используется.
technic93
а не лучше
? Передача выходных значений через аргументы это же ближе к си чем к наворотам современных плюсов. Даже иногда предлагают использовать анонимные лямбды для этого дела. И что то мне кажется что после компиляции код будет такой-же.
qw1
Я бы рад, но это функция Win32 API, и как-то повлиять на её сигнатуру уже невозможно.
bogolt
а об ошибке как тогда тогда узнать?
technic93
std::optional как вариант или std::tie. Я не знаю, сам писал (немного) раньше в си стиле. Интересно как принято сейчас делать в плюсах, разве не затем придумали исключения и все остальные штуки поновее?
qw1
Это всё хорошо для нового модного кода.
Но как вам ситуация, когда в C++22 ввели наконец принудительную инициализацию всех простых типов и после перекомпиляции во всех старых программах, написанных ещё в C99-стиле, просела производительность?
KanuTaH
Ну так потому и не вводят, что принудительная инициализация влияет на производительность. Новизна кода не имеет значения.
qw1
Если хорошо подумать, новый код можно писать так, чтобы лишней инициализации не было. Но об этом надо заранее заботится, и, возможно, некоторым API потребуется рефакторинг.
ilionsd
В обычном случае можно использовать то что нравится, но при использовании круглых скобок следует помнить, что порядок вычисления аргументов внутри не гарантирован.
Для фигурных же он определён слева направо.
Viceroyalty
То чувство когда решаешь свои задачи в том числе с помощью C++, а он развивается и уплывает от тебя куда-то далеко и, возможно, в будущем не сможешь не только читать современный C++, но и использовать C++ вообще
buldo
А есть что-то такое, но про указатели и выделение памяти? Много раз слышал, что использовать сырые указатели и new не стоит, но что сейчас правильно использовать?
bogolt
std::make_shared
std::make_unique
paluke
У нас есть 14 разных способов инициализации переменных. Надо разработать один универсальный.
…
Теперь у нас есть 15 способов инициализации.
UberSchlag
Спасибо за материал.
Тот самый случай, когда понимаешь, откуда есть пошли все мемные картинки про «изучить плюсы за 21 день»