
(достаточно вольный перевод огромной эмоциональной статьи, которая на практике наводит мосты между возможностями Си и Rust в плане решения бизнес-задач и разрешение багов, связанных с ручным управлением памятью. Также должно быть полезно и людям с опытом сборки мусора — отличий в плане семантики намного меньше, чем может показаться — прим.пер.)
С момента, когда я заинтересовался Rust, прошла будто целая вечность. Тем не менее я отчетливо помню знакомство с анализатором заимствований (borrow checker, далее — БЧ — прим.пер.), сопровождаемое головной болью и отчаянием. Разумеется я не один такой страдающий — статей в интернете на тему общения с БЧ предостаточно. Однако я хотел бы выделиться и осветить в данной статье БЧ с точки зрения практической пользы, а не только лишь генератора головной боли.
Периодически мной встречаются мнения, что в Rust — ручное управление памятью (вероятно, раз не автоматическое с GC, тогда какое же еще? — прим.пер.), однако я совершенно не разделяю данную точку зрения. Способ, примененный в Rust, я называю термином "декларативное управление памятью". Почему так — сейчас покажу.
Правила оформления
Вместо того, чтобы теоретизировать, давайте напишем что-то полезное.
Встречайте Овербук — издательство художественной литературы!
Как у любого издательства, в Овербуке есть правила оформления. Точнее, правило всего одно, простое как двери — никаких запятых. Овербук искренне считает, что запятые суть последствие авторской лени и — цитата — "должны быть истреблены как явление". К примеру, фраза "Она прочла и рассмеялась" — хорошая, годная. "Она прочла, после чего рассмеялась" — требует коррекции.
Проще некуда, казалось бы, однако в Овербуке регулярно ловят авторов на патологическом несоблюдении данного правила! Как будто такого правила вообще не существует, возмутительно! Приходится все перепроверять. Вручную. Более того, если по черновику издательством запрашивается правка, автор может прислать версию, исправленную в одном, но испорченную в другом месте, и поэтому все приходится перепроверять с самого начала. Бизнес такого халатного отношения к рабочему времени не терпит, и сама собой возникла необходимость процесс отлова "авторской лени" автоматизировать. Например, компьютерной программой. Можно же, да?
Робин спешит на выручку
Робин — один из сотрудников издательства, который вызвался помочь с написанием программы, так как знал программирование — вот это удача! Правда, в универе все, включая Робина, учили Си и Java, а Java VM в издательстве устанавливать беспричинно запретили — вот так поворот! Ну пусть будет Си, на Си много чего написано, язык уверен и проверен. Все пойдет как надо, инфа 100%.
#include <stdio.h>
int main() {
printf("Зашибца.");
return 0;
}Успех почти в кармане. Но Робин опытный и ожидает в будущем трудности, и запиливает Makefile:
.PHONY: all
all:
gcc -Wall -O0 -g main.c -o main
./mainНичего военного:
- Варнинги включены
- Не оптимизировать
- Дебажное инфо
- Запустить после компиляции
Пока что все зашибца:
$ make
gcc -Wall -O0 -g main.c -o main
./main
Зашибца.Робин осмелел. "Нам нужные еще некоторые функции и типы данных!"
// пропустим: #include directives
struct Mistake {
// человеко-читаемое описание ошибки:
char *message;
};
struct CheckResult {
// имя проверяемого файла
char *path;
// NULL если проблем в файле нет
// иначе мы здесь опишем проблему
struct Mistake *mistake;
};
struct CheckResult check(char *path, char *buf) {
struct CheckResult result;
result.path = path;
result.mistake = NULL;
// TODO(Robin): прочесть файл
// TODO(Robin): проверить ошибки
return result;
}
// пропустим: main()"Нам нужен буфер" — продолжал Робин — "Мы в основном работаем с повестями, нам 256КБ должно хватить".
#define BUF_SIZE 256 * 1024
int main() {
char buf[BUF_SIZE];
struct CheckResult result = check("sample.txt", buf);
if (result.mistake != NULL) {
printf("У нас проблемы!");
return 1;
}
return 0;
}Робин регулярно читает мой блог, и потому, несмотря на отсутствие постоянной практики программирования, смог безошибочно с первого раза написать функцию чтения файлов:
struct CheckResult check(char *path, char *buf) {
struct CheckResult result;
result.path = path;
result.mistake = NULL;
FILE *f = fopen(path, "r");
size_t len = fread(buf, 1, BUF_SIZE - 1, f);
fclose(f);
// не забыть про нулл-терминаторы в строках, это же Си, блин.
buf[len] = '\0';
// TODO(Robin): поискать ошибки
return result;
}В Овербук принимаются только тексты на литературном английском языке, потому формат принимаемых файлов исключительно *.txt, и переживать по поводу всяких глупых кодировок не стоит. Один раз кто-то пытался протащить в тексте эмодзи, но больше ни этого автора, ни эмодзи в тексте никто никогда не видел...
Энивей, в коде остался всего один TODO — это ли не признак скорого успеха? Робин был горд как никогда. Однако впереди еще была задача выделения памяти:
// надо для malloc
#include <stdlib.h>
// пропустим: structs, etc.
struct CheckResult check(char *path, char *buf) {
struct CheckResult result;
result.path = path;
result.mistake = NULL;
FILE *f = fopen("sample.txt", "r");
size_t len = fread(buf, 1, BUF_SIZE - 1, f);
fclose(f);
buf[len] = '\0';
// Робин в теме C99, и не портит вид функции непонятными
// определениями переменных, определяя то, что нужно для цикла,
// только в цикле.
for (size_t i = 0; i < len; i++) {
if (buf[i] == ',') {
struct Mistake *m = malloc(sizeof(Mistake));
m->message = "запятые нельзя!";
result.mistake = m;
break;
}
}
return result;
}Для проверки написанного Робин сделал выжимку из нетленной классики Льюиса Кэррола "Бармаглот" (в русском переводе Дины Орловской — прим.пер.) в файле sample.txt:
'О, бойся Бармаглота, сын!Натравил его на программу:
$ make
gcc -Wall -O0 -g main.c -o main
./main
У нас проблемы!В файле sample2.txt запятых уже не было — для беспроблемного примера:
Он стал под дерево и ждёт.И действительно:
$ make
gcc -Wall -O0 -g main.c -o main
./mainПроблем не было! Окрыленный успехом Робин отдал программу в релиз и быстро и решительно сбежал на недельку в Европу отдыхать от проделанной работы.
А через неделю...
А через неделю размякшего после отпуска Робина ожидало в корпоративной почте письмо примерно следующего содержания:
Программа работает безукоризненно, определяя, есть ли в тексте ошибка. Однако нам поступило множество запросов от редакторов ее улучшить, возможностью показать, где же именно в тексте произошла ошибка.
Да, мы совершенно уверены, что редакторы в основной своей массе редкостные лентяи и при возможности спихнут с себя любой труд. Однако не мог бы ты все же уделить этой проблеме время?
Робин открыл уже немного подзабытый проект. "Агамсь. Я могу добавить в Mistake указатель на, собственно, ошибку.". Сказано — сделано:
struct Mistake {
char *message;
// указывает на ошибку
char *location;
}
// ...
struct CheckResult check(char *path, char *buf) {
// пропустим: определение 'result'
// пропустим: чтение файла
for (size_t i = 0; i < len; i++) {
if (buf[i] == ',') {
struct Mistake *m = malloc(sizeof(struct Mistake));
// НОВИНКА: локация проблемы
m->location = &buf[i];
m->message = "запятые нельзя!";
result.mistake = m;
break;
}
}
return result;
}Надо еще эту инфу напечатать:
void report(struct CheckResult result) {
printf("\n");
printf("~ %s ~\n", result.path);
if (result.mistake == NULL) {
printf("Ошибок нет!!\n");
} else {
// внимание: "%s" печатает вообще все.
// а нам надо контекст и первых 12 символов текста, или меньше,
printf(
"проблема: %s: '%.12s'\n",
result.mistake->message,
result.mistake->location
);
}
}
int main() {
char buf[BUF_SIZE];
{
struct CheckResult result = check("sample.txt", buf);
report(result);
}
{
struct CheckResult result = check("sample2.txt", buf);
report(result);
}
}«Нормас», — решил Робин. Проверим:
$ make
gcc -Wall -O0 -g main.c -o main
./main
~ sample.txt ~
проблема: запятые нельзя!: ', бойся Барм'
~ sample2.txt ~
Ошибок нет!!Хорошо. А что, если еще более упростить редакторам задачу и проверять все тексты сразу, а в конце выдавать все ошибки?
#define MAX_RESULTS 128
// пропустим: все, что точно работает
int main() {
char buf[BUF_SIZE];
struct CheckResult bad_results[MAX_RESULTS];
int num_results = 0;
char *paths[] = { "sample2.txt", "sample.txt", NULL };
for (int i = 0; paths[i] != NULL; i++) {
char *path = paths[i];
struct CheckResult result = check(path, buf);
bad_results[num_results++] = result;
}
for (int i = 0; i < num_results; i++) {
report(bad_results[i]);
}
}Робин выдохнул. Не то чтобы программисты не любили программирование — просто никогда нельзя знать наверняка, правильно ли работает программа. Но именно здесь вроде все прекрасно.
$ make
gcc -Wall -O0 -g main.c -o main
./main
~ sample2.txt ~
Ошибок нет!!
~ sample.txt ~
проблема: запятые нельзя!: ', бойся Барм'Приключения продолжаются
На следующий день Робин находит письмо:
Приветы, Робин,
Очень классная получилась программа, с помощью нее мы сэкономили уйму времени, особенно с новой фичей, когда можно скормить ей все тексты сразу! Только с отображением места ошибки какая-то шляпа — оно показывает неверный кусок. Глянешь?
"Даблин!" — воскликнул Робин — "У меня же все работало!"
Некоторое время ушло на воспроизведение бага. В конце концов, переставив входные файлы местами, Робин получил ошибку:
int main() {
// пропустим: неважный кусок
// тут было "sample2.txt", "sample.txt"
char *paths[] = { "sample.txt", "sample2.txt", NULL };
for (int i = 0; paths[i] != NULL; i++) {
// пропустим проверку
}
for (int i = 0; i < num_results; i++) {
report(results[i]);
}
}
```bash
$ make
gcc -Wall -O0 -g main.c -o main
./main
~ sample.txt ~
проблема: запятые нельзя!: 'н стал под д'
~ sample2.txt ~
Ошибок нет!!Еще какое-то время ушло на вдумчивый осмотр кода. Наконец, отойдя к кофемашине, Робин внезапно понял:
— Итить вы бестолочь, сударь. У меня же общий буфер на все файлы! Я перезаписал его содержимое беспроблемным текстом, а указатель-то с проблемного файла — остался!
Находкой срочно надо было с кем-то поделиться, но ёлки, тут же издательство, а не аутсорс, Робина никто с его проблемами не понимал до конца, хотя его находку все подтверждали:
— Да, точно. Все ошибки были с текстом из самого последнего файла. Зуб даю.
Теперь это бы починить. Выделение отдельного буфера каждому файлу вообще не выход — никакой оперативки не хватит. Отдавать ошибку сразу после отлова — значит отменить последнюю полюбившуюся фичу и кормить прогу по одному файлу по старинке.
"Может тупо копировать только кусок с ошибкой куда-то?" — подумал Робин.
// еще инклуд, для memcpy
#include <string.h>
struct CheckResult check(char *path, char *buf) {
// пропустим: то, что работает
for (size_t i = 0; i < len; i++) {
if (buf[i] == ',') {
struct Mistake *m = malloc(sizeof(struct Mistake));
// копируем максимум 12 символов в "m->location"
size_t location_len = len - i;
if (location_len > 12) {
location_len = 12;
}
m->location = malloc(location_len + 1);
memcpy(m->location, &buf[i], location_len);
m->location[location_len] = '\0';
m->message = "запятые нельзя!";
result.mistake = m;
break;
}
}
return result;
}Для того, чтоб проблема никогда больше не повторилась, был добавлен новый тестовый файл, sample3.txt:
Но взял он меч, и взял он щитОпля, работает!
$ make
gcc -Wall -O0 -g main.c -o main
./main
~ sample.txt ~
проблема: запятые нельзя!: ', бойся Барм'
~ sample2.txt ~
Ошибок нет!!
~ sample3.txt ~
mistake: запятые нельзя: ', и взял он 'Кореш директора
Разумеется, долго праздник продолжаться не мог — новое письмо от СЕО на следующий день:
Привет, Робин. В чатике Тим,
Я тут показал нашу программку приятелю. Ему дико понравилось, но он заметил, что у нас течет память. Понимаю, что мы в первую очередь издательство, и утечки памяти нам вроде безразличны, но ты мог бы все же глянуть, в чем дело?
"Наша песня хороша", вздохнул Робин и полез открывать проект. Ага, ну да, мы память выделяем с malloc(), а возвращать ее системе с free() не возвращаем. Ну так она должна автоматически освобождаться при завершении программы, не так ли? Робин вроде похожее читал в блоге, но инфа не 100%, к тому же босс вряд ли бы напрягся только из-за того, что кто-то что-то там сказал или написал. В любом случае, надо исправить.
int main() {
char buf[BUF_SIZE];
struct CheckResult results[MAX_RESULTS];
int num_results = 0;
// пропустим: то, что работает
// вернем память системе!
for (int i = 0; i < num_results; i++) {
free(results[i].mistake);
}
}Теперь точно все. Остальное — buf и results определены на стеке и не нуждаются в ручном освобождении. Робин уже было расслабился, как вдруг за спиной появился незнакомец.
— Привет, ты Робин?
— Да, а ты кто?
— Я Джеф, друг Тима. У тебя очень крутая прога.
— Ой, привет, Джеф! Спасибо. Да, и спасибо за утечку. Я ее как раз только что поправил.
— Класс. А можно посмотреть?
Эээ. Ну ладно. Пренебрегая всеми правилами конфиденциальности компании, Робин пустил незнакомого человека за ноутбук. Кореш директора, в конце концов. Через минуту Джеф ответил:
— Почти получилось. Надо добавить еще один free(), и все, в программу можно будет никогда не лезть.
С одной стороны, Робина раздражало, что кто-то прерывает его работу без предупреждения, с другой стороны, он веселился, представив себе новый знак качества "Джеф одобряэ", на случай когда/если его программка снова сломается, и ее снова придется чинить.
int main() {
// ну вы поняли...
// Больше освобождения памяти богу освобождения памяти!
for (int i = 0; i < num_results; i++) {
free(results[i].mistake->location);
free(results[i].mistake);
}
} — Ты это, не переживай. Вызов free() не рекурсивный, освобождает только то, что ты в него передал, прозевать такое просто, как два байта переслать.
Вообще-то я не программист в компании, начнем с этого, подумал Робин. Все пишется на энтузиазме. Я не трогал Си уже черте-сколько, ну короче, Джеф, все ок, замяли. Джеф тем временем продолжал:
— Главное, не перепутай эти вызовы free(). Иначе будет сегфолт.
Робин был вот совсем не уверен, что тут будет именно сегфолт, и вообще, есть же системы, в которых мало того что сегфолтов в принципе не бывает, так и системы, которые не говорят про сегфолт пользователю. Даже Джефу. Пусть живет с этим. А то шибко собой доволен.
— Да-да, безусловно, конечно, спасибо, досвидания.
Спустя год
Робин уже было заскучал. Начальство довольно, программа работает, редакторы эффективны, утечек нет. Овербук усиленно готовился к крупному релизу, и Робин как раз обдумывал рекламную кампанию. Словом, все настолько спокойно, что не могло так долго продолжаться.
Действительно, Робина срочно вызывают на совещание.
— Робин, нам кранты. Ты знаешь, я не люблю такое.
Робин не совсем понимал, что именно не любит Тим. Точно не любит выражаться. Может что-то еще. Может, не любит Си?
— А в чем, собственно, дело?
— Ни черта не работает. Проверялка вчера работала, а сегодня нет.
За последний год поделие Робина стало играть ключевую роль в издательском бизнесе Овербука. Сейчас только после прогона через Проверялку (ей дали название!) издание допускалось к публикации. Это значит, что пока Проверялка не работала, Овербук терял деньги. Десятки долларов в минуту.
Робин немедленно сел за починку. Код выглядел до последнего символа тем же, каким он оставил его год назад. Функционал не изменился, соответственно. Ломаться было нечему.
— Секундочку, — мелькнуло у Робина в голове, — А сколько текстов одновременно загружается в проверялку?
— На этой неделе завал, не меньше 130 текстов в очереди.
А, ну да.
#define MAX_RESULTS 128
int main() {
char buf[BUF_SIZE];
struct CheckResult results[MAX_RESULTS];
// ...
}Казалось бы вот, проблема найдена, но Робин знал, что настоящая беда только чудом не вылезла до сих пор. За пределы results Проверялка вылезти не должна (это чревато переполнением стека, но операционка за этим бдит). Но лишь волей случая переменные были определены именно в этом порядке, не позволяя ссылкам на results выходить за пределы самого массива results. Будь buf определен позже, ссылки на results перетекали бы в него, указывая на чужие участки памяти, показывая пользователю произвольный текст из buf вместо ошибок, и вся репутация Овербука пошла бы по грибы. Так оставлять было нельзя. Робин в качестве быстрой заплатки поднял значение MAX_RESULTS до 256. На ближайшее время бизнес был спасен.
— Робин… Спасибо тебе. Ты спас нам всем задницы. Вот в такие моменты мне становится неловко, что мы платим тебе минималку. Не настолько неловко, чтобы почесаться и как-то это изменить, но достаточно, чтобы сожалеть. Ну ты понял. Это фрустрация.
Робину тем временем было не до этого. Амбиции компании легко могут преодолеть барьер в 256 текстов за раз, не сегодня, так через месяц. Проблема не решена. Программу нужно было полностью переписать.
"Да нахрен." — произнес про себя Робин, — "Переписываю на Rust."
Книгой спустя
(видимо, под книгой имеется в виду растбук — прим.пер.)
Робин ввел в консоль cargo new checker и открыл src/main.rs. Удобно. Теперь надо добавить чтение из файла:
use std::fs::read_to_string;
fn main() {
let s = read_to_string("sample.txt");
}"Лол, похоже на Ruby!" — за спиной явился Джеф, какого-то лешего тусящий в офисе издательства. Робин промолчал. Хрен тебе, Джеф, а не Ruby. Ты не в теме вообще.
"Так, что у нас тут с поиском запятых?"
fn main() {
let s = read_to_string("sample.txt");
s.find(",");
}Не взлетело, понял Робин по сообщению компилятора:
error[E0599]: no method named `find` found for type `std::result::Result<std::string::String, std::io::Error>` in the current scope
--> src\main.rs:5:7
|
5 | s.find(",");
| ^^^^Хм. Ошибку чтения файла проигнорировать не удалось — в типе Result<String, Error> метода find() нет, он есть только в String. Робин обязан обработать ошибку чтения.
fn main() -> Result<(), std::io::Error> {
let s = read_to_string("sample.txt")?;
s.find(",");
Ok(())
}Теперь мы показываем, что main() тоже может упасть, и ошибку из read_to_string() мы перенаправляем в main(), а та роняет всю программу. Это уже выглядело обнадеживающе, даже несмотря на то, что программа по сути ничем полезным не занималась. Можно пойти дальше и посмотреть, что возвращает find():
fn main() -> Result<(), std::io::Error> {
let s = read_to_string("sample.txt")?;
let result = s.find(",");
println!("Result: {:?}", result);
Ok(())
}$ cargo run --quiet
Result: Some(22)Ага. Если оно что-то найдет, вернет Option::Some(index), а если нет, то Option::None. Сюда можно применить сопоставление с образцом (паттерн матчинг, если понятным языком — прим.пер.):
fn main() -> Result<(), std::io::Error> {
let path = "sample.txt";
let s = read_to_string(path)?;
println!("~ {} ~", path);
match s.find(",") {
Some(index) => {
println!("проблема: запятые нельзя: символ №{}", index);
},
None => println!("Ошибок нет!!"),
}
Ok(())
}$ cargo run --quiet
~ sample.txt ~
проблема: запятые нельзя: символ №22Робин читал Песнь Льда и Пламени, потому понимал, что показывать порядковый номер символа в тексте размером с этот слегка бесполезно, даже если ты автор текста. Нужно вернуть отображение позиции с контекстом.
fn main() -> Result<(), std::io::Error> {
let path = "sample.txt";
let s = read_to_string(path)?;
println!("~ {} ~", path);
match s.find(",") {
Some(index) => {
// так, эта штука ест вообще всю строку,
// не только первые 12 символов,
// но проблем быть не должно
let slice = &s[index..];
println!("проблема: запятые нельзя: {:?}", slice);
}
None => println!("Ошибок нет!!"),
}
Ok(())
}$ cargo run --quiet
~ sample.txt ~
проблема: запятые нельзя: ', бойся Бармаглота, сын!'Робин готов был обрыдаться от счастья. Нет malloc()! Нет memcpy()! Модный и молодежный синтаксис для нарезания слайсов (ну в Go он тоже есть, например — прим.пер.)! Символьные слайсы можно форматировать с {:?}, и макрос знает, что внутри строка, и сам окружает кавычками. Озадачило, что free() тоже не было. В книге было написано, что память освобожается самостоятельно сразу же, как только переменная выходит за пределы области видимости — то есть s освобождается сразу после match. Слайс (&s[index..]) тоже не выделяет под себя память, но является просто частью изначального массива символов, вычитанного из файла. Вообще надо перечитать этот кусок про память, подумал Робин, а то уже все подзабылось.
Сокращаем разрыв
Смешение всего в main() и общая неструктурированность нового кода Робина раздражала, потому он взялся за рефактор, начав с выделения функции check():
fn main() -> Result<(), std::io::Error> {
check("sample.txt")?;
Ok(())
}
fn check(path: &str) -> Result<(), std::io::Error> {
let s = read_to_string(path)?;
println!("~ {} ~", path);
match s.find(",") {
Some(index) => {
let slice = &s[index..];
println!("проблема: запятые нельзя: {:?}", slice);
}
None => println!("Ошибок нет!!"),
}
Ok(())
}Что показательно, рефактор не привел к изменению результатов тестирования. Так и надо.
Также было замечено, что новая Проверялка на каждый новый файл выделяет отдельный буфер, то есть аллокаций памяти больше. Подгоним управление памятью под версию Си:
fn main() -> Result<(), std::io::Error> {
let mut s = String::with_capacity(256 * 1024);
check("sample.txt", &mut s)?;
Ok(())
}
fn check(path: &str, s: &mut String) -> Result<(), std::io::Error> {
use std::fs::File;
use std::io::Read;
s.clear();
File::open(path)?.read_to_string(s)?;
println!("~ {} ~", path);
match s.find(",") {
Some(index) => {
let slice = &s[index..];
println!("проблема: запятые нельзя: {:?}", slice);
}
None => println!("Ошибок нет!!"),
}
Ok(())
}В восторг Робина привели следующие вещи:
- несмотря на изначальный размер буфера
sв 256 КБ, при необходимости он может самостоятельно расширяться. - существенно более читаемый код чтения файла — сразу видно, где и какие ошибки могут выскочить: при открытии файла, и при непосредственном его чтении.
- Можно, в отличие от
#include, лепитьuseровно туда, где его содержимое использовалось: типажReadи его функцияread_to_stringиспользуется только внутриcheck().
Миграция, однако, еще не завершена. В версии Си check() возвращал CheckResult, в котором мог быть Mistake. В версии Rust Робину ничего не мешало убрать CheckResult вовсе, заменив его на Option<Mistake>. Впрочем, Mistake все равно нужен. Робин закатал рукава:
struct Mistake {
location: &str,
}Но нет. У компилятора были другие планы.
$ cargo run --quiet
error[E0106]: missing lifetime specifier
--> src\main.rs:10:15
|
10 | location: &str,
| ^ expected lifetime parameter"Хрень", подумал Робин, "об этом меня и предупреждали!", но общая элегантность уже написанного кода убедила его не бросить все на полпути, а вернуться к книге. Книга в этом вопросе оказалась на редкость неуклюжей в плане объяснения, и все, что Робин оттуда выудил — эта хрень зовется временем жизни (здесь и далее — ВЖ — прим.пер.). Пришлось покурить форумы, и вскоре Робин вернулся с решением:
struct Mistake<'a> {
location: &'a str,
}Факт того, что этот стремный код собрался, настолько впечатлила Робина, что он бросился дореализовывать остальные части из версии Си, хотя по хорошему стоило бы остановиться и почитать больше теории по этим самым ВЖ. Если ВЖ настолько важны, я на них еще наткнусь, решил он мимоходом.
В общем, сейчас check() возвращает Option<Mistake> вместо () (спецтип, который возвращается, если из функции ничего не возвращается — прим.пер.):
fn check(path: &str, s: &mut String) -> Result<Option<Mistake>, std::io::Error> {
use std::fs::File;
use std::io::Read;
s.clear();
File::open(path)?.read_to_string(s)?;
println!("~ {} ~", path);
Ok(match s.find(",") {
Some(index) => {
let location = &s[index..];
Some(Mistake { location })
}
None => None,
})
}Понимание ВЖ Робину пока не особо давалось, зато окружающие концепции он схватывал на лету. Вот например — если функция заканчивается выражением, значение выражения возвращается из функции. match — выражение, потому Ok(match ...) взлетает. Это было слишком круто, чтобы не попробовать его применить к main():
fn main() -> Result<(), std::io::Error> {
let mut s = String::with_capacity(256 * 1024);
let result = check("sample.txt", &mut s)?;
if let Some(mistake) = result {
println!("проблема: запятые нельзя: {:?}", mistake.location);
}
Ok(())
}"По большому счету, отдельный result мне тут тоже не нужен", защищал себя перед воображаемым ревьюером Робин, "но с ним все куда более читаемо". Еще как-то сразу зашел вот этот if let, вроде и мелочь, можно было оставить и match, но насколько аккуратней выглядит!
От винта!
$ cargo run --quiet
error[E0106]: missing lifetime specifier
--> src\main.rs:17:55
|
17 | fn check(path: &str, s: &mut String) -> Result<Option<Mistake>, std::io::Error> {
| ^^^^^^^ expected lifetime parameterНевыученные уроки всегда наносят ответный удар, и от этого удара Робин рисковал не оправиться. К счастью, вовремя была замечена рука поддержки от компилятора:
Хелп: Эта функция возвращает тип с заимствованным значением, но в сигнатуре не указывается, было оно заимствовано изpathили изs.
Заимствованное? Этосамое, в Mistake есть location: &'a str — заимствование. Оно пришло из s — одного из параметров. Теоретически их надо объединить одним и тем же ВЖ:
// все эти полные пути и имена типов писать утомительно:
use std::io::Error as E;
fn check(path: &str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> {
// ...
}Так, вроде правильно. Почему ВЖ названо именно 'a? А фиг знает. Может других имен не бывает вовсе? А почему перед именем ВЖ одинарная кавычка, одна? Так надо, что ли? Надо будет опять мануал покурить, потом.
error[E0261]: use of undeclared lifetime name `'a`
--> src\main.rs:19:26
|
19 | fn check(path: &str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> {
| ^^ undeclared lifetime
error[E0261]: use of undeclared lifetime name `'a`
--> src\main.rs:19:66
|
19 | fn check(path: &str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> {
| ^^ undeclared lifetimeКомпилер недоволен. Какое еще декларирование ВЖ? Робин пробежался по коду:
struct Mistake<'a> {
location: &'a str,
}Здесь, решил он, компилятор знает про 'a в location: &'a str потому что 'a определено в Mistake<'a>, что в свою очередь страшно напоминает декларацию дженериков из Java. Хохохо. А можно ли подход дженериков из Java в методах применить к ВЖ из Rust?
fn check<'a>(path: &str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> {
// ...
}Вот это дела, взлетело!
$ cargo run --quiet
~ sample.txt ~
проблема: запятые нельзя: ", бойся Бармаглота, сын!"Больше структур!
Передохнув минутку, Робин осмотрел код полностью:
fn main() -> Result<(), std::io::Error> {
let mut s = String::with_capacity(256 * 1024);
let path = "sample.txt";
let result = check(path, &mut s)?;
println!("~ {} ~", path);
if let Some(mistake) = result {
println!("проблема: запятые нельзя: {:?}", mistake.location);
}
Ok(())
}
struct Mistake<'a> {
location: &'a str,
}
use std::io::Error as E;
fn check<'a>(path: &str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> {
use std::fs::File;
use std::io::Read;
s.clear();
File::open(path)?.read_to_string(s)?;
Ok(match s.find(",") {
Some(index) => {
let location = &s[index..];
Some(Mistake { location })
}
None => None,
})
}Бесконечные 'a в сигнатурах его напрягали, и вообще не было до конца понятно, на кой пес они там нужны. Впрочем, работает и ладно. Запилим report():
fn main() -> Result<(), std::io::Error> {
let mut s = String::with_capacity(256 * 1024);
let path = "sample.txt";
let result = check(path, &mut s)?;
report(path, result);
Ok(())
}
fn report(path: &str, result: Option<Mistake>) {
println!("~ {} ~", path);
if let Some(mistake) = result {
println!("проблема: запятые нельзя: {:?}", mistake.location);
} else {
println!("Ошибок нет!!");
}
}Наверное, путь к файлу надо сделать частью Mistake, тогда я смогу напилить к нему типаж Display и красиво выводить инфо пользователю.
struct Mistake<'a> {
// пыщь!
path: &'static str,
location: &'a str,
}Вовремя Робин вычитал, что для значений, которые живут всю программу, можно и нужно использовать ВЖ 'static. Путь к файлу захардкожен в код, соответственно — жив всю программу от начала до конца. Заполним путь в check():
fn check<'a>(path: &str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> {
use std::fs::File;
use std::io::Read;
s.clear();
File::open(path)?.read_to_string(s)?;
Ok(match s.find(",") {
Some(index) => {
let location = &s[index..];
// пыщь!
Some(Mistake { path, location })
}
None => None,
})
}Попутно решим уже знакомую проблемку:
$ cargo run --quiet
error[E0621]: explicit lifetime required in the type of `path`
--> src\main.rs:37:28
|
27 | fn check<'a>(path: &str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> {
| ---- help: add explicit lifetime `'static` to the type of `path`: `&'static str`
...
37 | Some(Mistake { path, location })
| ^^^^ lifetime `'static` required// new: &'static
fn check<'a>(path: &'static str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> {
// ...
}Вклеим обещаный Display:
use std::fmt;
impl<'a> fmt::Display for Mistake<'a> {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(
f,
"{}: запятые нельзя: {:?}",
self.path, self.location
)
}
}И подгоним под это все report():
fn report(result: Option<Mistake>) {
if let Some(mistake) = result {
println!("{}", mistake);
}
}Хорошо, когда все работает :)
$ cargo run --quiet
sample.txt: запятые нельзя: ", бойся Бармаглота, сын!"50 строк кода, включая пустые строки для красоты, пот этом содержание каждой предельно понятно. Если это не счастье, тогда что же?
Сразу несколько текстов
Ай, забыли совсем. Самое главное!
fn main() -> Result<(), std::io::Error> {
let mut s = String::with_capacity(256 * 1024);
let paths = ["sample.txt", "sample2.txt", "sample3.txt"];
for path in &paths {
let result = check(path, &mut s)?;
report(result);
}
Ok(())
}$ cargo run --quiet
sample.txt: запятые нельзя: ", бойся Бармаглота, сын!"
sample3.txt: запятые нельзя: ", и взял он щит"Даже не пришлось напрягаться. Но потом Робин вспомнил, что в версии Си ошибки сначала собирались со всех файлов, а потом выдавались в самом конце. Плевое дело.
fn main() -> Result<(), std::io::Error> {
let mut s = String::with_capacity(256 * 1024);
let paths = ["sample.txt", "sample2.txt", "sample3.txt"];
// все собери
let mut results = vec![];
for path in &paths {
let result = check(path, &mut s)?;
results.push(result);
}
// потом отчитайся
for result in results {
report(result);
}
Ok(())
}Как тут вдруг откуда ни возмись...
$ cargo run --quiet
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src\main.rs:9:34
|
9 | let result = check(path, &mut s)?;
| ^^^^^^ mutable borrow starts here in previous iteration of loopПаааадажжи. Чего-чего? Нельзя заимствовать s для изменения более одного раза??
Это было что-то совсем уж новое. Заимствование, думал Робин, это ссылка на s, то есть &s. Заимствование для изменения — это, выходит, &mut s. А зачем его заимствовать для изменения несколько раз? Ааа, у нас s это буфер для чтения из файла:
fn check<'a>(path: &'static str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> {
// тут мы пишем в `s` - изменение
s.clear();
// и тут мы пишем в `s` - тоже изменение!
File::open(path)?.read_to_string(s)?;
// все такое.
}Да, и буфер у них один и тот же. Но это получается, что...
Компилятор Rust.
Не собирает программу.
С багом, который уже был в программе на Си!
Но Си его съел и выдавал в рантайме бред, а Rust считает ошибкой компиляции!!
Екарный бабай.
Хорошо. Вероятно, вопрос можно решить способом, аналогичным Си. Только без memcpy(), пожалуйста-пожалуйста.
В первую очередь надо было пересмотреть содержимое Mistake. location сейчас был ссылкой на общую строку, из которой росла по остальному коду зависимость от ВЖ строки. В то же время в Си Mistake владела собственной строкой, в которой хранилась часть оригинала. Как нам завладеть строкой в Rust?
Спустя минуту у Робина было и решение — отдельный тип String, который, в противовес ссылочному &str был владельцем содержимого строки. Изначально Робин ни фига не понимал, зачем нужно два отдельных типа для строки, и просто принимал это как должное. Сейчас было куда понятней.
struct Mistake<'a> {
// это все еще ссылка, хоть и вечноживущая
path: &'static str,
// а вот это всецело принадлежит Mistake
location: String,
}Компилятор, настроенный на активацию при каждом сохранении, встрепенулся:
error[E0392]: parameter `'a` is never used
--> src\main.rs:27:16
|
27 | struct Mistake<'a> {
| ^^ unused parameter
|
= help: consider removing `'a` or using a marker such as `std::marker::PhantomData`"Да-да, я в курсе", сказал вслух Робин, удаляя <'a> из структуры. Также оказались не нужны 'a в Display и check():
struct Mistake {
// это все еще ссылка, хоть и вечноживущая
path: &'static str,
// а вот это всецело принадлежит Mistake
location: String,
}
// ...
impl fmt::Display for Mistake {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(
f,
"{}: запятые нельзя: {:?}",
self.path, self.location
)
}
}
// ...
fn check(path: &'static str, s: &mut String) -> Result<Option<Mistake>, E> {
s.clear();
File::open(path)?.read_to_string(s)?;
Ok(match s.find(",") {
Some(index) => {
let location = &s[index..];
Some(Mistake { path, location })
}
None => None,
})
}Компилятор, однако, был неумолим:
error[E0308]: mismatched types
--> src\main.rs:43:34
|
43 | Some(Mistake { path, location })
| ^^^^^^^^
| |
| expected struct `std::string::String`, found &str
| help: try using a conversion method: `location: location.to_string()`
|
= note: expected type `std::string::String`
found type `&str`Окай. location и был изначально ссылкой на s. А нам надо, чтобы это была отдельная строка с собственным содержимым. Робин рисовал пальцем на стене на воображаемой доске воображаемое расположение разных строк в воображаемой оперативной памяти, отчего коллеги по комнате периодически на него оглядывались. Впрочем, с тех пор, как от Робина стали слышаться слова "Rust" и "переписать", коллеги просто молча понимающе переглядывались и уходили назад в свою работу. Робин тем временем дорисовал воображаемые строки и вернулся к реальной проблеме — как получить строку во владение?
"У меня нет нигде malloc(). Я вообще не видел, чтобы где-то выделял память! Что вообще происходит?" Уже привычным движением Робин переключился на браузер, где его ждала документация. Спустя минуту была найдена страница с интересным содержимым:

"Вроде как я могу использовать оба варианта. Типаж ToString реализует преобразование именно в строку, а ToOwned — для всех остальных типов из ссылки в отдельный экземпляр, которым можно завладеть. Робин поспешил применить свежее знание:
fn check(path: &'static str, s: &mut String) -> Result<Option<Mistake>, E> {
s.clear();
File::open(path)?.read_to_string(s)?;
Ok(match s.find(",") {
Some(index) => {
let location = s[index..].to_string();
Some(Mistake { path, location })
}
None => None,
})
}```bash
$ cargo run --quiet
sample.txt: запятые нельзя: ", бойся Бармаглота, сын!"
sample3.txt: запятые нельзя: ", и взял он щит"На этом задача считалась законченой. Робин отправил новую Проверялку в прод, а старую, написанную на Си, спрятал поглубже в дебри компа, чтоб никто случайно не нашел.
Прошло пять лет
Пять долгих лет Rust-версия Проверялки трудилась на благо Овербука, не получив ни упрека в свой адрес. Для софта, тем более написанного за вечер на коленке, это значимое достижение. Тем не менее ни мир, ни Овербук не стояли на месте, и, как читатель уже мог догадаться, Робин снова был приглашен на совещание. На этот раз с амбициозной целью — создать на базе Проверялки Суперпроверялку!
Здравствуй Робин,
Проверялка работает безукоризненно. Однако сотрудники периодически жалуются, что она находит всего лишь одну ошибку, после чего надо отправлять текст автору, ждать исправления, и потом запускать Проверялку снова, чтобы она нашла новую ошибку, и так далее. В итоге мы поштормили немного и пришли к выводу, что было бы крайне желательно модифицировать Проверялку выдавать все ошибки сразу, а не по одной.
"Логично. Хорошо. Но это в самый последний раз я лезу в код."
Робин полез в подзабытый проект. Кажется, это уже происходило, кажется, даже совсем недавно...
"Мне определенно нужен массив..." Робин заимел привычку говорить вслух все, что касается работы. Во-первых, его сотрудники как-то отучились делать вид, будто их кто-то вообще слушает, взамен теперь произнося вслух любую мелочь, что взбредет в голову. Во вторых, дела у Овербука шли настолько хорошо, что всех расселили из опенспейса по отдельным кабинетам, и это до одури злило друзей Робина, которые все еще жили в опенспейсах в своих компаниях.
"Так. Ах да. Мне нужен массив."
struct Mistake {
path: &'static str,
locations: Vec<String>,
}Безусловно, Робин был в курсе связных списков (да все в курсе, этому всех учат!). Однако Овербук использовал железо с предсказателями ветвлений, бездонными кешами, короче, обычное современное железо, с которым данные, организованные в массив подряд идущих частей, создавали куда меньше проблем с производительностью, чем данные, рассыпанные по оперативке, за которыми надо постоянно прыгать туда-сюда. Но основной проблемой была не организация данных, а то, что старый добрый find() уже не подходил в принципе.
"Нет, я конечно могу бегать findом по строке, каждый раз подсовывая ему все меньший и меньший ее хвост. Но это как-то некузяво совсем. Неужели нет ничего удобней?"
Робин снова открыл доку к 'str и нашел следующее:
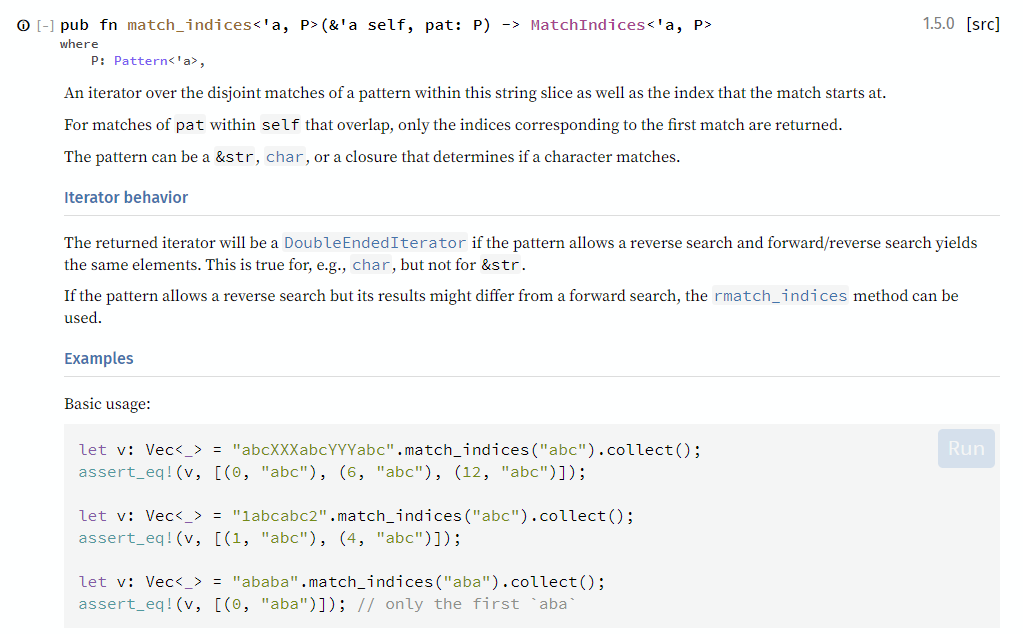
fn check(path: &'static str, s: &mut String) -> Result<Option<Mistake>, E> {
s.clear();
File::open(path)?.read_to_string(s)?;
let locations: Vec<_> = s
.match_indices(",")
.map(|(index, slice)| slice.to_string())
.collect();
Ok(if locations.is_empty() {
None
} else {
Some(Mistake { path, locations })
})
}"Ха, if это тоже выражение с возвратом результата!" Робин уже настолько к этому привык, что сначала писал код, а потом осмысливал написанное. Еще оказалось странным, но невероятно удобным отделить понимание хранения данных в массиве от перечисления этих данных, то есть разница между массивом и итератором. Отсюда вырос навык использования map() и collect().
Пришлось подпилить Display, и готово:
impl fmt::Display for Mistake {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
for location in &self.locations {
write!(f, "{}: запятые нельзя: {:?}\n", self.path, location)?;
}
Ok(())
}
}Для проверки пришлось создать новый sample.txt с более сложным куском Бармаглота:
О, бойся Бармаглота, сын!
Он так свирлеп и дик!
А в глу?ше ры?мит исполин —
Злопастный Брандашмыг!
Но взял он меч, и взял он щит
Высоких полон дум.
В глущобу путь его лежит
Под дерево Тумтум."Немного похоже на ситуацию, когда надо идти объяснять заказчику, почему упал прод", подумал Робин после прочтения стиха. Впрочем, мы отвлеклись.
$ cargo run --quiet
sample4.txt: запятые нельзя: ","
sample4.txt: запятые нельзя: ","
sample4.txt: запятые нельзя: ","Ну. Технически программа работает правильно. Корректно. Без ошибок. Только бесполезно. "Может подсунуть в location индексы найденных запятых, чтобы при выводе по ним искать в строке контекст?"
// check():
let locations: Vec<_> = s
.match_indices(",")
.map(|(index, _)| {
use std::cmp::{max, min};
let start = max(0, index - 12);
let end = min(index + 12, s.len());
s[start..end].to_string()
})
.collect();прим.автора: не пишите так адресацию в строках никогда. Ладно, если бы все происходило в восьмидесятые, когда стандартом был однобайтный ASCII, но в 21 веке с его UTF-кодировками у вас очень ненулевые шансы получить по пальцам линейкой.
(прим.пер: прочтите Спольски, там полезно.)
$ cargo run --quiet
sample4.txt: запятые нельзя: "О, бойся Барма"
sample4.txt: запятые нельзя: "я Бармаглота, сын!"
sample4.txt: запятые нельзя: " взял он меч, и взял он щ""Уже существенно лучше, но чего-то не хватает." Робин нахмурился. "Было бы очень неплохо показывать, во-первых, номер строки с запятой, во вторых, подсвечивать само место ошибки. А еще не нравятся эти манипуляции со строкой в check(), им самое место в report(). Попадется какой-то автор — фанат запятых, и отчет по его тексту будет занимать больше места, чем сам текст."
"И да, я вот это сделаю, и все, и больше никаких правок, хватит."
План
Значит так.
Номер раз. check() у нас отвечает только за проверку, а report() — только за вывод ошибок.
Номер два. Ошибки — это позиции в оригинальном тексте, а не копии текста.
Номер раз оказался несложным:
struct Mistake {
path: &'static str,
text: String,
locations: Vec<usize>,
}
fn check(path: &'static str) -> Result<Option<Mistake>, E> {
let text = std::fs::read_to_string(path)?;
let locations: Vec<_> = text.match_indices(",").map(|(index, _)| index).collect();
Ok(if locations.is_empty() {
None
} else {
Some(Mistake { path, text, locations })
})
}Робину было неспокойно хранить индексы вместо ссылок на символы в строке. Он на это согласился лишь потому, что соответствующая строка хранилась тут же рядом, а все это добро было запривачено внутри Mistake, чтобы никто нечаянно не влез (хотя кто влез бы?).
(вы же еще помните про Спольски и UTF-8? — прим.пер.)
Еще можно грохнуть глобальный буфер — все равно его копии хранились в Mistake.
$ cargo run --quiet
warning: field is never used: `text`
--> src\main.rs:28:5
|
28 | text: String,
| ^^^^^^^^^^^^
|
= note: #[warn(dead_code)] on by default
sample4.txt: запятые нельзя: 1
sample4.txt: запятые нельзя: 19
sample4.txt: запятые нельзя: 83Правильно, вывод-то еще не исправлен. Для начала надо найти индексы начала и конца соответствующей строки. Появляется соответствующий приватный метод:
impl Mistake {
fn line_bounds(&self, index: usize) -> (usize, usize) {
let len = self.text.len();
let before = &self.text[..index];
let start = before.rfind("\n").map(|x| x + 1).unwrap_or(0);
let after = &self.text[index + 1..];
let end = after.find("\n").map(|x| x + index + 1).unwrap_or(len);
(start, end)
}
}"Я использую реверсивный поиск rfind(). Также, если строка первая или последняя в тексте, начальный и конечный перевод строки я могу и не найти, потому для таких ситуаций мне нужен unwrap_or()."
Новый метод казался сложным, и требовал немедленного испытания:
impl fmt::Display for Mistake {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
for &location in &self.locations {
let (start, end) = self.line_bounds(location);
let line = &self.text[start..end];
write!(f, "{}: запятые нельзя:\n", self.path)?;
write!(f, "\n")?;
write!(f, " | {}", line)?;
write!(f, "\n\n")?;
}
Ok(())
}
}$ cargo run --quiet
sample4.txt: запятые нельзя:
| О, бойся Бармаглота, сын!
sample4.txt: запятые нельзя:
| О, бойся Бармаглота, сын!
sample4.txt: запятые нельзя:
| Но взял он меч, и взял он щитВопль победы вырвался из груди Робина. Почти оно!
Остались номера строк, и кое-что по мелочи:
impl fmt::Display for Mistake {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
for &location in &self.locations {
let (start, end) = self.line_bounds(location);
let line = &self.text[start..end];
let line_number = self.text[..start].matches("\n").count() + 1;
write!(f, "{}: запятые нельзя:\n", self.path)?;
write!(f, "\n")?;
write!(f, "{:>8} | {}", line_number, line)?;
write!(f, "\n\n")?;
}
Ok(())
}
}$ cargo run --quiet
sample4.txt: запятые нельзя:
1 | О, бойся Бармаглота, сын!
sample4.txt: запятые нельзя:
1 | О, бойся Бармаглота, сын!
sample4.txt: запятые нельзя:
6 | Но взял он меч, и взял он щит(вы же заметили, как наловчился Робин писать код на Rust без войны с компилятором?)
Последний рывок — показывать, где именно в выделенном тексте затесалась запятая. Робину очень понравилось, как на ошибки в коде указывает сам Rust, и он решил применить сюда тот же стиль с символом ^. Изменений на самом деле немного — подпилить Display, добавив строку с указателем, которая отсчитывалась от начала строки, которая, в свою очередь, отсчитывалась от начала текста. Ну еще 11 пробелов (для самого номера строки длиной в 8 цифр + разделитель |, еще 3 символа):
impl fmt::Display for Mistake {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
for &location in &self.locations {
let (start, end) = self.line_bounds(location);
let line = &self.text[start..end];
let line_number = self.text[..start].matches("\n").count() + 1;
let comma_index = location - start;
write!(f, "{}: запятые нельзя:\n\n", self.path)?;
// напечатать строку с номером
write!(f, "{:>8} | {}\n", line_number, line)?;
// показать запятую
write!(f, "{}^\n\n", " ".repeat(11 + comma_index))?;
}
Ok(())
}
}$ cargo run --quiet
sample4.txt: запятые нельзя:
1 | О, бойся Бармаглота, сын!
^
sample4.txt: запятые нельзя:
1 | О, бойся Бармаглота, сын!
^
sample4.txt: запятые нельзя:
6 | Но взял он меч, и взял он щит
^Всё.
Робин осмотрел полный текст программы. 85 строк.
fn main() -> Result<(), std::io::Error> {
let paths = ["sample4.txt"];
// все проверить
let mut results = vec![];
for path in &paths {
let result = check(path)?;
results.push(result);
}
// все доложить пользователю
for result in results {
report(result);
}
Ok(())
}
fn report(result: Option<Mistake>) {
if let Some(mistake) = result {
println!("{}", mistake);
}
}
struct Mistake {
path: &'static str,
text: String,
locations: Vec<usize>,
}
use std::io::Error as E;
fn check(path: &'static str) -> Result<Option<Mistake>, E> {
let text = std::fs::read_to_string(path)?;
let locations: Vec<_> = text.match_indices(",").map(|(index, _)| index).collect();
Ok(if locations.is_empty() {
None
} else {
Some(Mistake {
path,
text,
locations,
})
})
}
use std::fmt;
impl Mistake {
fn line_bounds(&self, index: usize) -> (usize, usize) {
let len = self.text.len();
let before = &self.text[..index];
let start = before.rfind("\n").map(|x| x + 1).unwrap_or(0);
let after = &self.text[index + 1..];
let end = after.find("\n").map(|x| x + index + 1).unwrap_or(len);
(start, end)
}
}
impl fmt::Display for Mistake {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
for &location in &self.locations {
let (start, end) = self.line_bounds(location);
let line = &self.text[start..end];
let line_number = self.text[..start].matches("\n").count() + 1;
let comma_index = location - start;
write!(f, "{}: запятые нельзя:\n\n", self.path)?;
// напечатать строку с номером
write!(f, "{:>8} | {}\n", line_number, line)?;
// показать запятую
write!(f, "{}^\n\n", " ".repeat(11 + comma_index))?;
}
Ok(())
}
}Заключение
Несмотря на оглушительный успех новой Проверялки, Робин не получил за нее ни гроша.
Совершенно логичным его шагом было уйти прочь из Овербука и основать собственную компанию. Книги там не проверяли, зато использовали Rust. Робин впоследствии натыкался на фразу "в Rust ручное управление памятью", но, как ему уже было известно, это было очень далеко от правды. Ни единого байта ему не пришлось выделять вручную, вместо этого он просто декларировал экземпляры типов, которые ему были нужны, договаривался с БЧ о временах жизни этих экземпляров и следил, чтобы при этом его задачи были решены.
(А еще ему повезло, что не пришлось работать с FFI.)
Комментарии (117)


gecube
04.10.2019 16:49+2TL;DR
Отличная статья, но очень длинная. Прочитал первые три абзаца с удовольствием. Остальное оставил на вечер, когда можно будет спокойно почитать
AndreySu
Казалось бы при чем тут С++ со смартпоинтерами.
PsyHaSTe
Уже не раз в комментариях обсуждалось, что смартпоинтеры помогают только если вы соблюдаете правила хорошего тона. Причем нарушить их можно и случайно.
Конечно, можно возразить популярным "Настоящий С++ программист так никогда не напишет!", но отчеты Microsoft/Google/Mozilla, да и хотя бы того же PVS считают иначе.
А еще они имеют рантайм оверхед. Поэтому полагаю, иногда приходится специально выпиливать их и заменять на сырые указатели, чтобы ускорить на 5% выполнение горячего участка. А менять безопасность на скорость всегда грустно. Можно было бы перефразировать Франклина на эту тему, но, пожалуй, не буду.
Antervis
да, я помню ваши «показательные» примеры:
ага
но выпиливание умных указателей из того же раста идет через unsafe…
а можно взглянуть на эти отчеты?
по моей памяти подавляющее большинство ошибок, находимых PVS'ом, в коде, который старше того же раста. Возьмем например их последнюю проверку TON, «код написан на языке C++14 и насчитывает 210 тысяч строк». Ни одной ошибки памяти PVS не нашел.
PsyHaSTe
Ну да, а что не так? "Так никогда никто не напишет"? Я даже в расте такое встречал, правда там не компилировалось, и люди приходили в чат с вопросом "как бы мне сделать чтобы собралось". В плюсах не придут — компилится же.
А зачем вам бокс опшне в расте? Надо тогда уж с Rc/Arc использовать, но тут фишка в том, что их вы будете юзать кое-где по необходимости, а большая часть кода будет верифицироваться бесплатными
&T\&mut T, а вот в плюсах такого разделения нет. Придется платить всегда.да, я потом могу грепнуть по ансейфу и найти потенциально проблемные места. Если бы в плюсах разработчики оставляли бы специальный
// UNSAFE BEGINS HERE/// UNSAFE ENDS HEREкомментарий, который бы еще и всегда поддерживался в актуальном состоянии, то получился бы паритет. Но, увы, они так не делают, и без помощи компилятора боюсь и не смогут. Не говоря о том, что семантика плюсов сама по себе часто небезопасная, а если ансейфа становится слишком много то и толку от демаркации не так много становится.Да хотя бы этот https://www.cso.com.au/article/664150/microsoft-eyes-mozilla-rust-obliterate-c-memory-security-flaws/. Я надеюсь вы не будете предполагать, что майкрософт пишет в 2019 году С++ код без умных указателей, и сравнивал со старыми плюсами новый раст.
Antervis
а можете найти такой мисюз в каком-нибудь открытом проекте?
Rc/Arc — от «reference counted», который мне здесь не нужен. А нужен мне был прямой аналог std::unique_ptr, коим именно оптобокс и должен являться, т.к. Box — не nullable. Я же правильно помню, что там даже есть хитрая оптимизация, что отсутствие значения в оптобоксе сделано через null pointer а не отдельный флаг?
так место падения в обоих случаях отлавливается по логам/дебаггером, а не чтением всей (и даже не только unsafe) кодобазы.
но это не отчет. Это статья какого-то журналиста, спекулирующего над формулировкой вакансии, которую выложили MS. У них всё-таки не было официального заявления «мы переходим на раст!».
PsyHaSTe
Нет, я же не пишу на С++. У меня знакомые периодически в приватном чатике ругаются, но там искать долго, да и ссылку на чатик я не дам. Может humbug поделиться ссылочкой.
Пожалуйста —
&mutДаже имея стектрейс и лог не всегда понятно где что упало. С ансейфом у вас останется скорее всего 1-2 места на 5-10 строчек где могло произойти что-то плохое. Неплохая экономия времени.
Ну про переход они писали немного здесь: https://msrc-blog.microsoft.com/2019/09/30/building-the-azure-iot-edge-security-daemon-in-rust/
А вообще спросите у автора
actix, он его ведь не для фана писал, а по работе. У него могут быть интересные инсайды по поводу всех этих процессов. Судя по тому, что я слышал, майкрософт очень активно адоптит раст, а в своих ресерчах на сишарпе повторяют схожие с растом концепции (независимо от раста).Antervis
но это совсем не прямой аналог, ведь ссылка:
а. не определяет лайфтайм, а зависит от него
б. память под объект необязательно выделена в куче
Там, где в расте можно обойтись ссылкой, в плюсах это точно так же можно. Да, надо проверять соблюдения лайфтаймов. Но и false positive нет.
но это тоже не отчет. Это "мы написали один safe-critical daemon для одного сервиса на расте". Ваша цитата: "но отчеты Microsoft/Google/Mozilla, да и хотя бы того же PVS считают иначе.", я прошу предоставить ссылки на упомянутые отчеты, а не на спекуляции журналистов. Отчет — это документ с цифрами, аля «N уязвимостей памяти на M строк кода»
«неплохая» это сколько? За последние пару лет я потратил на отладку ошибок памяти меньше времени, чем на вон те 10 строчек раста в годболте
PsyHaSTe
Она определяет лайфтайм. Он просто не должен быть меньше, чем у объекта. Если объект передан во владение то он у вас уже есть в уникальном виде и вам даже &mut не нужен.
А это даже хорошо.
Окей, держите именно в такой формулировке: https://www.zdnet.com/article/microsoft-70-percent-of-all-security-bugs-are-memory-safety-issues/
Ну значит вы гений и не совершаете ошибок с памятью, как и ваши коллеги. Могу только позавидовать.
Antervis
это называется «зависит от». Я не могу спокойно передать ссылку в другой поток, но могу передать смартпоинтер, т.к. ссылка не продлит время жизни объекта.
а если мне надо часто мувить большой объект, или на этот объект есть ссылки из других частей кода, то это нифига не хорошо. Мне может быть явно нужен именно объект в куче с управляемым лайфтаймом.
«70% of all security bugs», а не «70% of all bugs».
Гением себя не считаю, а лавры отдал бы старому доброму код ревью.
П.с. лесть вам не поможет
PsyHaSTe
Берете канал и передаете безо всяких смартпоинтеров.
Ну тогда придется расчехлять аналог unique_ptr, да. Только локально и в конкретных местах. По моему опыту приходится этим заниматься не чаще чем в нескольких процентах от всех ссылок, что используются в программе.
Ну, у макйрософта другой статистики не приведено. Мозилла рассказывала про опыт переписвания файрфокса, там емнип были цифры были что порядка 50% багов которые они зафиксили в файрфоксе на расте бы не скомпилировались. Я в комментах на хабре пару месяцев назад кидал ссылку, сейчас искать лень.
Antervis
так я же уже несколько причин привел почему я могу хотеть именно смартпоинтер. Вы объекты килобайт в 16 тоже будете гонять между потоками копиями?
мозилла начали разрабатывать раст в 2007 году из-за длинной истории уязвимостей. В 2007 даже с++11 не было. И даже сейчас вероятно у них большая часть кода — застарелый си с классами. Его и на новые плюсы переписать можно и быстрее, и надежнее
да это то понятно, но мне неинтересно сравнивать ссылки с ссылками ибо примерно то же самое
PsyHaSTe
Да пожалуйста, если хотите. Программист на фортране может писать на фортране на любом языке программирования. Только странно не использовать плюсы языка, которые он дает.
Объекта в килобайт у вас скорее всего и не будет. Большие объекты как правило состоят из строк и векторов, у которых на стеке только адрес и длина.
А с 2007 года они на С++ ничего не писали получается?
Не писать лишнего, но и не терять в безопасности, вот что интересно.
Antervis
Ну вот бывают (де-факто) объекты размером в несколько килобайт, которые не «состоят из строк и векторов». Я вам уже кучу аргументов привел почему я могу хотеть именно гребаный unique_ptr а не «Arc/Rc», не мув, не ссылку и не канал. Не надо мне приводить заведомо неподходящие альтернативы, не надо мне рассказывать как часто это нужно и не надо меня стебать всякими «когда в руках молоток всё кажется гвоздями» — я не первый день работаю и я знаю что может быть необходимо в конкретной ситуации. Почему так сложно дискутировать по существу? Неужели дизлайк — самое конструктивное что от вас можно добиться? Где уважение к собеседнику, с которым вы спорите?
Вы же архитектуру программы строите основываясь не на ошибках компиляции? «Ну пусть это будет ссылка, пока компилятор не ругнется, а потом если что пройдемся автозаменой на Rc, и всё будет зашибись до потребности в Arc.»?
Ryppka
А чем Вас Box не устраивает? При том, что unique_ptr может и обмануть с уникальностью после release, а Box не может?
Antervis
std::boxed::Box::into_raw()
PsyHaSTe
И? Разыменовать указатель без
unsafeвы все равно не сможете, а вunsafeвы сами должны продемонстрировать что не нарушаете инварианты.Antervis
а в коде на плюсах я гарантирую инварианты сам, да, не надо пожалуйста повторять про safe/unsafe миллионный раз, это утомляет. Box позволяет те же самые потенциально небезопасные операции что и unique_ptr, пусть и под unsafe. Кроме двух: nullable и кастомного деструктора. Второго нет и у оптобокса. Так во что на расте оборачивать половину сишных либ?
Мне нужен был прямой аналог std::unique_ptr для демонстрации оверхеда умных указателей. Вы предложили несколько вариантов как обойтись без умных указателей, вообще не адресовав сабж.
PsyHaSTe
Фишка в том, что проверять инварианты на паре сотне строк проекта в десятки тысяч строк намного проще, чем каждую из этих тыщ строк.
Обмазываться ансейфом и оборачивать. Что поделать, раст не настолько крут чтобы верифицировать код на других языках.
Ну окей, берите бокс, только зачем вам исскуственный оверхед-то? Я думал вы задачу решить хотите, а не просто побольше ресурсов на неё потратить. Чтобы передавать значение по уникальной ссылке умные указатели в расте зачастую не нужны, а в плюсах обязательны. Вот и все.
И кстати, если вы вдруг не знали. в расте я могу запретить на уровне приложения ансейф. Нельзя будет вот так взять и два раза из одного указателя сделать два бокса. Ошибка компиляции будет на ансейф. Как в плюсах такое запретить не представляю.
Antervis
сразу после того, как я написал:
вы ответили тремя абзацами про safe/unsafe и одним по существу. Умоляю, хватит.
я привел минимальный пример «проверить указатель и разыменовать его», и сделал эквивалентную реализацию на двух языках. Почему вы требуете чтобы она была не эквивалентной?
это не так, юзкейсы полностью эквивалентны. Если соберетесь опровергать это утверждение — умоляю, не надо в миллионный раз про safe/unsafe. Можете просто дать ссылку на функционально эквивалентный код, корреткный в расте и с UB в плюсах.
рекурсивно?
PsyHaSTe
В расте нет эквивалентной операции. Там есть 3 разных (move, &mut, Box) которые используются каждые в своей области. Вы выбрали только третью, просто потому что вам так захотелось.
Это примерно как доказывать, что плюсцы не быстрее джавы, потому что если написать свой наколеночный сборщик мусора, то он будет даже медленнее стандартного. Можно еще привести с годболта листинг сборщика джавы для приложения, своего наколенчного на плюсах и увидеть, как они 1:1 похожи.
Да че тут опровергать:
Никаких боксов нет. Покажите, как на плюсах безопасно без смартпоинтеров это написать.
На уровне своего приложения. Офк я доверяю стд. Но потребовать от зависимостей емнип тоже можно, хотя это менее полезно, почти всегда ошибка в конечном коде, а не библиотеке.
Antervis
да, и я выбрал её в обоих языках. Там, где в расте можно использовать мув, мув есть и в плюсах. Там, где в расте есть ссылки, их можно использовать и в плюсах.
так проблема не в том, что я не понимаю растовый unsafe, а в том, что вы не понимаете плюсовый UB. Вот этот код:
является полностью корректным и безопасным, ровно до тех пор, пока в него не будет передана мертвая ссылка. И прежде чем вы попытаетесь привести аргумент «но в него же может быть передана мертвая ссылка!» прошу ознакомиться с таким примером вызова вашей foo:
И меня не интересует чей код прав а чей виноват. Я попросил привести
Ну если доверять кому угодно кроме себя, то да, нужны презервативы
PsyHaSTe
Нет, конечно, потому что у них разные гарантии.
Но это не является кодом на Rust. Напомню, что код на Rust не может содержать UB, поэтому это код на каком-то растоподобном псевдоязыке. В расте такой проблемы нет.
Да пожалуйста
Я вот нахожу забавным скорее желание человека обвинить разработчиков компилятора, стд, библиотек, но считать свой код свободным от багов (ну или хотя бы того же качества). Очень самонадеянно, должен сказать.
KanuTaH
Вот кстати с signed overflow в расте сделали довольно забавно с моей точки зрения. В режиме отладки проверка действительно реализована, а в режиме релиза просто заявлено, что будет two’s complement wrap. Интересно, какая ламбада будет, когда rust понадобится портировать на архитектуру с представлением отрицательных чисел в one's complement (а такие вполне себе еще есть).
Antervis
в чем отличия их гарантий внутри unsafe?
этот код полностью эквивалентен.
п.с. а что, раст даже в перегрузку не умеет?
да никто никого не обвиняет. Просто я знаю, что разработчики библиотек, которые я использую, такие же люди как и я, и тоже могут ошибаться. Поэтому позицию «им я доверяю, а себе — нет» я не разделяю.
PsyHaSTe
В том, что unsafe не отключает гарантий раста.
Не даже, а вполне сознательно не умеет. Зато можно выводить тип по результату функции. В целом, удобный трейдоф.
Да какой эквивалентен, когда вы специально написали совсем иначе чтобы не стриггерить UB.
Зависит от библиотек. В моем случае я редко использую библиотеку меньше чем десятков миллионов скачиваний, и качество там соответствующее.
Antervis
то есть до тех пор пока я всё делаю верно, раст только вставляет мне палки в колеса своим примитивным borrow checker'ом?
написал-то иначе, а поведение 100%-но эквивалентно. Я даже могу написать на эту функцию compile-time тесты, не пройдя которые программа не скомпилится. А rust так умеет?
а что, скачивания увеличивают качество библиотеки? Я ловил баги в Qt'е из-за редкого юзкейса, а у rust-враппера для fftw3 (сишная либа, с которой я больше всего работал) всего 2700 скачиваний, то есть по вашей логике надежнее написать самому?
Всё у раста круто, пока в песочнице играешься. А за её пределами — одни надежды
KanuTaH
Отлично, отлично. Ламбада на 5+. По такой же логике, код на C++ не может содержать UB (иначе он будет incorrect), поэтому любой такой код — это код на каком-то C++-подобном псевдоязыке, а в C++ такой проблемы нет и быть не может. Защита Чубаки какая-то :)
P.S. Добавил ссылку на ваш чудесный комментарий в закладки.
PsyHaSTe
Совершенно верно.
Осталось только понять, можно ли за конечное число шагов установить, является ли код валидным на этом языке или нет. Учитывая, что даже парсинг в C++ это в общем случае неразрешимая задача, то вопрос весьма актуален для них.
KanuTaH
Для unsafe rust (без которого safe rust по большому счету бесполезен) задача в этом плане ничем не отличается. Иначе утилиты типа нижеупомянутой miri были бы не нужны.
PsyHaSTe
Отличается, конечно. unsafe-блок не должен нарушать гарантий раста. Если он не нарушает, то все ок. Вам не нужно знать что происходит в других функциях, достаточно посмотреть на 4 строчки в блоке.
KanuTaH
Нет, к сожалению, нужно. Я ниже приводил пример бага с hash_raw_entry из std. То есть мне очень даже надо знать не только что происходит в других моих функциях, но и что происходит в std, и что происходит в чужих библиотеках тоже. Там тоже может быть все что угодно.
PsyHaSTe
Ну тогда это не про вас.
У меня лично нет времени проводить аудит всех зависимостей и стд.
KanuTaH
Значит, ни вы, ни я не способны «за конечное количество шагов» убедиться, что данная программа не является на самом деле «программой на каком-то растоподобном псевдоязыке» :)
PsyHaSTe
Ваша программа — является. Зависимости — ну наверное может оказаться, что нет.
Мы же все это делаем для получения практических результатов, а не носиться с сейф\ансейф на руках.
Предлагаю переформулировать чтобы не возникало разночтений. С растом у вас в вашем коде не будет проблем с памятью. Если вы всегда пишете идеальный код, а проблемы с памятью всегда в библиотеках — то что поделать, компиляторы УБ не умеют ловить, на то они и уб, тогда раст не дает ничего по сравнению с плюсами.
С другой стороны если у вас зависимости тоже ансейф не используют, то и там проблем не будет. Так работает рекурсивная порука безопасности.
KanuTaH
Я уже отвечал тут humbug'у про это. Когда клиент ко мне обращается с претензией, что моя программа падает, я не могу сделать лицо кирпичом и сказать «правила локальности раста формально гарантируют, что моя программа локально корректна, так что проследуйте, пожалуйста, в жопу». Я должен буду это падение как-то исправлять, не ограничиваясь лишь собственным кодом. Поэтому «гарантии» растопесочницы для меня как бы не гарантии вообще.
Ага, и я о том же.
PsyHaSTe
Смотрите утрированный пример. Вы пишете программу, у которой зависимости от serde_json, hyper и ваша вспомогательная либа. Так вот, баг в serde вы вряд ли поймаете, в hyper тоже, в вашем коде тоже проблем с памятью нет. Итого — код сразу работает ожидаемым образом.
Теперь пишем на плюсах. Вы используете nlohmann-json, cURLpp и вашу вспомогательную либу. Баг в nlohmann-json вы вряд ли поймаете, в cURLpp тоже, а вот в вашем коде он спокойно может засесть. В итоге баг может быть, и если он есть, то почти точно он в вашем коде, а не в коде зависимостей.
KanuTaH
Вашими бы устами да мед пить.
P.S.
Не будет, пока я пишу тривиальщину, для которой достаточно убогой функциональности borrow checker'а. Как только нужно реализовать что-то нетривиальное и вступает в дело написание unsafe кода — так это утверждение ломается.
PsyHaSTe
И что? Ошибки есть везде, проблема в том, что вы скорее всего с ними не столкнетесь. Я вот за 6 лет ни разу не словил ошибки csharp compiler, а они там все это время что-то регулярно чинят. Да и из знакомых не слышал ни кого, кто хотя бы issue с проблемой с которой лично столкнулся открыл. Магия?
KanuTaH
Я и в собственном-то коде не припомню когда ловил SIGSEGV в последний раз. Но вы сейчас скажете, что «это ничего не доказывает». Верно, не доказывает. Как и то, что вы еще не столкнулись с багами в rustc, std или собственном unsafe коде, никоим образом не доказывает, что их там нет.
PsyHaSTe
Ну значит вы молодец. А я вот NullRefernce всякие регулярно ловлю, и прочие вещи, которые растовая ситсема типов отлавливает. Сегфолт тоже ловил когда с opencv работал. Видимо, поэтому мне он нравится.
humbug
Вообще нет. Я уже перечислил вам правила локальности, но вы их упорно игнорируете. Это в С++ необходимо доказывать безопасность приложения в целом, а в Расте достаточно локального анализа. https://doc.rust-lang.org/nomicon/working-with-unsafe.html
KanuTaH
Видите ли, когда мне нужно будет в отладчике ковыряться, почему у меня программа падает, я не смогу просто взять и сказать «это не у меня, у меня весь код safe». Мне нужно будет найти, почему она падает и где именно, и как максимум исправить это (и послать патч в upstream) а как минимум — хотя бы сделать workaround. Ваши бумажные правила локальности для меня абсолютно бесполезны.
humbug
Так это не бумажные правила, у это следствия формального доказательства корректности системы типов Rust. Если вы не верите в математику, у меня для вас плохие новости.
KanuTaH
По вашей же ссылке:
Так что давайте без громких слов.
technic93
открываем первый пример
unsafe ничего не знает про idx, он может прийти откуда угодно, значит надо проверять всю программу.
PsyHaSTe
Нет, не надо, нам же не важно, откуда оно пришло, нам важно, какое значение оно принимает.
Если
idx < arr.len()то документация разрешает нам использовать unsafe-метод.Если нет, то не разрешает, но тогда мы в if не попадем.
В итоге обе ветки выполнения флоу не нарушаются, вне зависимости "откуда" там что пришло.
technic93
Eсли бы я хотел иметь проверку
idx < arr.len()прямо перед обращением к индексу я бы сразу использовал safe метод!У вас
ifснаружиunsafeвнутриunsafeважно.PsyHaSTe
ну так а если вы вынесите проверку if из метода, то вы не можете вызывать этот ансейф-метод без UB, все верно.
Ну так unsafe принято оборачивать только то, где он нужен. Для вызова метода
len()ансейф не нужен.technic93
Очевидно что можно писать вокруг каждого unsafe if-ы и проверять инварианты.
Но во-первых даже если так делать (но вдруг забыть) фактически (т.е. место в коде в котором нужен патч) ошибка будет в if-ах а не в unsafe. Т.е. уже история с грепом по unsafe это некое преукрашательство.
А во-вторых unsafe затем и нужен что я могу отключить проверки для ускорения программы при реализации хитрого алгоритма, когда гарантии следуют из вышестоящей логики алгоритма, а не тупого ифа строчкой выше. Например я делаю тип ValidIndex который я могу отдавать наружу пользователю либы но через инкапсуляцию я как писатель либы знаю что в нём будет всегда хороший индекс, тода я могу в своей либе опустить проверки при использовании ValidIndex. Это пример надуманный.
Но например в std большое количество unsafe, и доказать что там работает всё коректно т.е. внешний апи safe было не быстрой задачей. Тут кидали ссылку где-то выше (может и вы сами) на статью.
Теперь мы приходим к моему тезису изначальному "значит надо проверять всю программу" — естественно не прямо всю целиком, а какой то модуль или класс, в простых случаях действительно только функцию или только 5ть строк, где происходит заворачивание ансейф в сейф.
PsyHaSTe
Смотрите, вы условно говоря должны сделать тип
И дальше если вы где-то накосячили с индексом то будет виновато то место, которое криво вызвало
new_unsafe. Опять же, грепаем по этому месту и ищем виновных.В итоге по построению у вас не будет с этим типом проблем, даже если вы его пользователю отдали.
В большинстве случаев как раз-таки и правда придется проверить пару строчек кода. В моей попытке написать телеграм-бота ансейфов нет вообще, например. При этом работает, и отлично.
technic93
вы упрощаете в своем примере, например тут описывается реализация arena https://exyr.org/2018/rust-arenas-vs-dropck/, и уже инварианты не такие тривиальные.
Я тоже написал на расте жсон/хмл/sql молотилку и тоже без ансейф и всё хорошо :)
humbug
Так не всю программу, а модуль.
PsyHaSTe
Вот это кстати забавное замечание. На гитхабе полно проектов, где нет ни одного unsafe, и следовательно там нет этих проблем. Говорить что "ну там где-то под ковром произойдет в стд вызов FFI и все превратиться в тыкву" это полная чушь.
KanuTaH
Это не чушь, а суровая реальность. И даже не ffi, а криво написанного метода из std.
PsyHaSTe
Ну тогда остается только взять и повеситься, потому что стд любого языка это базиси которому все доверяют. И в котором не сомневается, пока не начнется странная дичь.
Хочется вспомнить одну цитату
У вас есть язык, который дает некоторые гарантии. ОКей, он не приставит свою голову, и работает не в 100% случаев, а в 99,9999%. Ну и ладно, в оставшихся десятитысячных процентах можно и руками покопаться в дбг, чай не каждый раз придется этим заниматься.
Мы вот написали прототип на 20к строк и не получили ни одной ошибки в рантайме. В плюсах думаете, получилось бы (при том, что плюсы мы не знаем, и раст тоже изучали по мере написания)?
gecube
Криво написанные методы были и в c/c++ stdlib
И что это тогда меняет ?
technic93
Спасибо повеселили. Код с UB не является кодом на С++. Корректный код на С++ не может содержать UB. Я ведь тоже так могу перефразировать.
Кстати гарантии для вызова unsafe они не в unsafe блоке содержатся. Если вы хотите разименовать указатель внутри unsafe блока Вы должны гарантировать что он валидный, а создан он мог быть вообще в абсолютно другом месте программы. Поэтому не всё так радостно, но от части ошибок защищает и при правильном подходе позволяет делать cвои safe api на основе unsafe инструкций.
MikailBag
Кажется, такого очень мало. Мне сходу в голову только одно приходит:
https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=5cadcaefcd6a2ca8f6d631b1f3a4ada2
Antervis
а вот тут вам потребуется ссылка к (не существующему) стандарту раста, в котором прямым текстом сказано, что такая конверсия well-defined.
Однако с уверенностью можно сказать что конверсия через честное копирование байт будет корректна в обоих языках. Если, разумеется, не пытаться использовать float, полученный таким образом
MikailBag
Например тут и во многих других аналогичных местах делается что-то вроде transmute с помощью union.
Antervis
но это не стандарт языка rust, а reference manual к одному его компилятору. По аналогии, на любом компиляторе c++ который вы сможете найти, ваш пример будет работать аналогично.
MikailBag
Сейчас вы уводите разговор в совершенно иную плоскость: мы все-таки про UB говорим а не про стандартизацию.
И да, reference — это то, что (в идеале) должно дорасти до стандарта.
И где в документации clang, g++ и msvc написано, что они гарантируют, что чтение неактивного поля это не всегда UB?
Antervis
так мы говорим про формальное или фактическое наличие/отсутствие UB? Если формальное, то у раста нет стандарта (мало ли, вдруг этот пункт они заимствуют?), а фактически компилятор раста ведет себя так же, как и clang.
В доке gcc указано, что он предоставляет сишные гарантии в виде расширения. С доками clang/msvc сложнее. Сlang'овская страничка до безобразия аскетична, известно лишь, что он максимально эмулирует gcc. У msvc в принципе тяжело что-то искать, но сами они этот type punning via union используют.
Ryppka
В C type punning совершенно законен. Хотя он и может породить trapped representation.
Antervis
а хедер windows.h используется не только в сишном коде
1. вы и в расте передаете владение в сишные функции через Box::into_raw().
2. никакого «неявно при присвоении одного unique_ptr другому» нет попросту потому, что unique_ptr нельзя присваивать другому unique_ptr, только мувить.
Ryppka
Ну вот не лень Вам спорить ради спора? Вы не понимаете, что имеется в виду?
Antervis
я-то понимаю что имеется в виду, вам бы читать и внимать а не спорить.
Ryppka
В Rust принято все аспекты явно выделять — заверните box в option — и вуаля. В C и C++ традиционно любят «сворачивать» в один тип для краткости записи. Можно бессмысленно спорить, какой подход лучше, дело вкуса.
Ну, а «выдрав» указатель из Box'а Вы явно делаете что-то, нарушающие правила языка. Иногда приходится, да. Но такое не назовешь случайной ошибкой по невнимательности.
Antervis
собственно, unique_ptr::release() тоже нечасто встречается, и тоже провоцирует внимательное отношение. Как и unique_ptr(new T(...)) вместо make_unique(...), и прочие подобные конструкции.
Ryppka
Уверены? Он и явно встречается, например, при передаче владения в C-функции. А уж неявно при присвоении одного unique_ptr другому…
technic93
Точно так же передадите значение в си функцию из раста.
PsyHaSTe
Ну окей, берите для своего единственного (вероятно) во всей программе объекта в несколько килобайт бокс. Только это не значит что бокс это аналог unique_ptr.
Я вам ни одного дизлайка ни разу не поставил, я им вообще редко пользуюсь.
Нет, я пользуюсь принципом относительной достаточности. Если у меня есть локальная переменнация цикла, я не буду её инкрементить на случай "а вдруг к ней будет доступ из многих потоков". Когда будет — добавлю интерлокед. А пока это как трата лишних ресурсов, так и неоправданное усложнение кода. "Как программисты хлеб пекли" — хороший эталон как надо разрабатывать программу.
Antervis
ну назовите полнофункциональный аналог std::unique_ptr в расте, и в следующий раз в сравнении эквивалентного кода я использую его.
Да, код не обязан быть расширяемым и не должен быть переусложненным. Однако он обязан быть переиспользуемым, иначе малейшие изменения влекут рефакторинги, и я слишком много раз стукался об эту проблему. Тем более когда пишешь не пета, а что-то командное.
KanuTaH
Насчет «грепнуть по ансейфу» — вот статья о реальном процессе отладки сегфолта в приложении на rust:
jvns.ca/blog/2017/12/23/segfault-debugging
Все как положено — анализ стека (из которого понятно, что падение происходит вовсе не там, где на самом деле скрывается проблема, как это обычно и бывает), valgrind, постепенное выкидывание всего лишнего до MWE (ну в данном случае скорее MNWE, хехе), и, наконец, проблема найдена. Процесс, я бы сказал, стандартный, и весьма сильно отличающийся от благостной картины «грепану по ансейфу».
Amomum
По-моему, "грепнуть по ансейфу" — это, все же, чуть меньший миф, чем плюсовое "грепнуть по const_cast/reinterpret_cast".
KanuTaH
Ни разу не видел плюсовика, предлагающего для исправления бага "просто грепнуть по reinterpret_cast". А вот утверждения про "грепнуть по unsafe" вижу регулярно, да хотя бы в данном обсуждении.
Amomum
А разве само наличие разных способов каста не оправдывается в том числе возможностью грепнуть по ним?
KanuTaH
Оно оправдывается в первую очередь тем, что это РАЗНЫЕ касты, и работают по-разному. Лично я никогда не встречался с точкой зрения "они разные затем, чтобы по ним было удобно грепать". Это все равно, что сказать "const или virtual придуманы для того чтобы по ним грепать".
Amomum
Возможно, у меня ложная память, но мне опять-таки казалось, что они разные и работают по-разному как раз чтобы отделить "опасные" от "безопасных". И, типа, "если вы используете const_cast, то вы, скорее всего, не правы" — Core Guidelines примерно так гласят, вроде.
И назывались касты специально так, чтобы не выглядеть похоже на сишный каст, в т.ч. потому что по сишному касту неудобно грепать.
Я не спорю, что на практике никто по кастам не грепает.
KanuTaH
Ну да, у них разная степень "опасности", но насчёт "назывались касты так потому, чтобы по ним было удобнее грепать" — как-то я не уверен :) В C просто всего один вид каста, и с точки зрения C++ он "смешанный" — это фактически последовательная попытка static_cast, если не получилось, то тогда reinterpret_cast. А раз вид всего один, то и синтаксиса со скобочками достаточно (кстати, в C++ он никуда и не делся, он по-прежнему в стандарте). А когда у тебя много кастов, то их же надо как-то разделять между собой, вот ввели для них имена и разделили по именам.
Amomum
Да, про это я в курсе, спасибо :)
Возможно, что это что-то вроде городской легенды, так же как то, что reinterpret_cast специально назван так длинно, чтобы его было дольше печатать и из-за этого меньше хотелось бы юзать.
Мне еще очень интересно, что вот эта идея — с разделением кастов на типы — как-то не очень прижилась в других языках. Обычно просто оператор as и все.
KanuTaH
Вы имеете в виду managed языки? Ну там в «опасных» видах каста и нет необходимости в силу того, что там им не с чем было бы работать. Там, например, не нужно конвертировать pointer type в integral type и обратно, для чего частенько и применяется тот же reinterpret_cast. Но даже и там не всегда только один operator as, в том же C# есть и каст через (), он, в отличие от as, выбрасывает исключение при неудачном касте.
Amomum
Я имею в виду вообще все языки, которые появились после С++, в т.ч. Go, D и Rust.
Во всех троих есть сырые указатели, но каст вроде бы всего один.
Так что шарп — скорее исключение (к тому же, касты в нем отличаются по другому признаку, не как в плюсах).
KanuTaH
Ну ни Go, ни D и не работают во всех тех областях, в которых применяется C++, на них не пишут какие-то сильно системные вещи (не в последнюю очередь потому, что и там и там для управления памятью применяется GC). В rust для «особо опасных» случаев тоже есть фактически отдельный каст под названием transmute, но список «особо опасных» случаев там отличается от представлений C++.
Amomum
Окей, но, скажем, const_cast (который вообще непонятно зачем нужен) или dynamic_cast вполне мог бы быть и там.
KanuTaH
Ну в том же rust нет наследования в терминологии C++, а dynamic_cast применяется главным образом все-таки для «безопасных» путешествий по иерархии классов. Просто тот же static_cast специально сделан так, чтобы не вносить лишний runtime overhead при работе с RTTI, а если ты хочешь именно в рантайме там проверить, что вот этот объект, указатель на который там тебе передан в качестве аргумента, у тебя ТОЧНО именно вот этого класса, и, так сказать, ни классом выше, то вот сделали dynamic_cast. const_cast и в C++ действительно применяется довольно редко, я, наверное, по пальцам одной или максимум двух рук могу посчитать сколько раз я его видел в кодовой базе.
technic93
dynamic_cast в раст есть.
Amomum
О, а вот это интересно, спасибо.
KanuTaH
Ну не знаю, можно ли считать частный метод из некоей struct аналогом dynamic_cast, который в случае C++ вшит в язык, даже если эта struct входит в std.
P.S. Ну хотя transmute, строго говоря, тоже не конструкция языка, а интринсик из std. Так что да, наверное, можно.
Ryppka
Не читали Страуструпа?! Или он в Вашем понимании не плюсовик?..
KanuTaH
Что-то я не припомню у него предложений грепать по кастам в целях исправления проблем. Ну, может, давно читал :)
P.S. А, это вы, наверное, про фразу «приведение в стиле C гораздо более опасно, чем указанные [именованные] операторы преобразования, потому что обозначения труднее обнаружить в большой программе»? Ну ладно, считается :)
humbug
Это был мой показательный пример.
Вот вы в наших дискуссиях упорно путаете MRE (Minimal Reproducible Example) и баги в реальных проектах. Да, это круто, что вы понимаете, что держать один ресурс в двух умных указателях может быть больно. Но реальность делает еще больнее https://github.com/pybind/pybind11/pull/1139/files.
У проекта pybind11 (из названия сразу понятно, что проект нацелен на безопасный C++11) 5,956 звезд на гитхабе. Умеют эти люди в С++? Умеют. Допустили ошибку? Допустили. Помог бы им C++14? Нет. C++17? Нет. C++20? Нет. Rust? Да.
KanuTaH
Ключевое слово "бы". А может и Rust не помог бы. Как здесь например:
https://github.com/rust-lang/rust/issues/56158
И в остальных случаях с проблемными реализациями std. И это ещё без пользовательского unsafe кода, а он в более-менее нетривиальных вещах будет обязательно. Я помню, автор way cooler (тоже отнюдь не новичок в расте) жаловался, что для того, чтобы взаимодействовать с wayland через wlroots, ему пришлось написать 11 тысяч строк растокода, и практически весь этот растокод занимался только управлением памятью с unsafe если не прямо в каждой строчке, то через строчку уж точно. Сколько там в этих 11 тысячах строк было потенциальных проблем — бог ведает. Так что с вашим "да" я бы погодил, это зависит.
bohdan-shulha
> Ключевое слово «бы». А может и Rust не помог бы. Как здесь например:
Да, только вот по вашей ссылке первое же предложение это
> While trying out the experimental hashmap raw entry API
Что как бы подразумевает, что что-то может пойти не так. К тому же, этот API нужно ещё и активировать, указав
#![feature(hash_raw_entry)]
:)
KanuTaH
И что же, что experimental? Факт ошибки от этого никуда не делся. Была бы ошибка по какому-то менее используемому пути, так сказать — у неё были бы все шансы перейти из experimental в stable, а затем, может, и до CVE дорасти :) Да и issue вон открыт до сих пор.
gecube
И что Вы хотите этим сказать — что стандартная библиотека C++ или boost не имеют проблем с управлением памятью? Ну, это же не так. Но вот impact от того и другого — мне оценить сложно.
KanuTaH
Я хочу сказать, что ответ "да(жирным), раст бы помог" — это некоторое… хм… преувеличение. Он бы, безусловно, помог… но только при соблюдении определенных правил. Как и C++.
humbug
Только в С++ этих правил 200+, а в Rust — только 5.
Вы нашли интересный пример, но он абсолютно нерепрезентативен.
KanuTaH
Вы считаете, что ваш пример репрезентативен, а мой нет? Ну, хорошо, да будет так. CVE database для вас достаточно репрезентативна? Согласно ей, в rust-lang за последние 2 года было 5 CVE. Что у нас из аналогичных продуктов на C/C++ есть? Есть, например, clang, точно такой же фронтенд к llvm, кстати — в нем вообще ни одной CVE за последние 2 года, и всего одна за всю историю, в 2014 году (это, кстати, единственная CVE и в самом LLVM в целом, поскольку clang в CVE database выступает как часть LLVM). Возьмем GCC, в нем 8 CVE, но это за 20 лет (начиная с 2000 года), а за последние 2 года — всего 2 штуки. Я не вижу какого-то превосходства в плане безопасности продукта на rust перед аналогичными продуктами на C/C++, причем продуктами куда более сложными.
Проблема утверждений типа «а вот на rust такое написать было бы нельзя, компилятор бы не пропустил» в том, что на safe rust многое вообще в принципе написать нельзя в силу примитивности логики работы borrow checker'а. Как как-то говорил гражданин, которого тут все время банят (я не одобряю его манеру, но во многом из того, что он говорит, есть рациональное зерно) — «rust делится на safe rust, на котором вообще ничего написать нельзя, и unsafe rust, на котором что-то написать все-таки можно». Мысль утрированная, но по сути верная. Как только ты хочешь действительно написать что-то нетривиальное, ты просто вынужден тем или иным образом использовать unsafe, и у тебя полезут точно такие же баги, как и в C/C++. Ситуация усугубляется еще больше, если ты не имеешь опыта низкоуровневой работы с памятью, а многие питонщики/jsеры/goшники и так далее как раз сейчас и клюют на rust, как на инструмент, позволяющий им (в теории) получать что-то быстро работающее, но без «сложностей» C/C++ (как они думают). Страшно подумать, что будет, когда люди с подобным опытом (а точнее его отсутствием) возьмутся за написание unsafe кода (а они возьмутся рано или поздно).
humbug
И опять предположения исходят из неправильных предпосылок.
Из пунктов, указанных выше, следует, что в hash_raw_entry напортачили с unsafe и получили проблему. В С++ с этим проблем нет, потому что C++ не дает гарантий по API, ведь всегда можно обвинить конечного разработчика в неправильном использовании API. И таких багов, которые приводят к CVE, миллионы, их просто не репортят.
Страшно, да не очень. Так как баги, подобные тем, что вы указали выше, это действительно проблема, сообщество пилит фреймворк для верификации кода. На текущий момент верифицированы большинство std примитивов: Box, Arc, Rc, Mutex, RefCell, Thread, Atomic… https://github.com/rust-lang/miri#bugs-found-by-miri
Вот вы можете сказать, что вы можете использовать C++ std::mutex и API не даст вам возможность выстрелить по памяти? А Rust это гарантирует. То же самое можно сказать про Box vs unique_ptr.
Поэтому ваш пример является подтверждением моего утверждения: все ошибаются. Но никак не является подтверждением утверждения, что раст небезопасный.
Ага. А еще есть люди, которые критикуют, а есть люди, которые пишут. В https://github.com/tox-rs/tox в 30к строк нет ни одного unsafe. И наша нода полгода не падает, тогда как сишные версии постоянно валятся на каких-то багах раз в день.
KanuTaH
Это всего лишь старые добрые runtime тесты. Вы же не хотите сказать, что их раньше не было? Не потому ли их раньше не было, что «rust безопасен»? Щютка юмора, не обижайтесь.
Да, есть такие люди :)
humbug
Так код формально верифицировали: https://plv.mpi-sws.org/rustbelt/popl18/paper.pdf, а MIRI — следующий шаг от математиков. Сейчас из miri начинают переползать куски проверок, которые не дают компилировать код с явными багами внутри.
gecube
Я вообще фигею от этих вот сравнений по CVE. Ну, нашли уязвимость. Молодцы. Пофиксили. Молодцы. А сколько их еще не найденных и не подтвержденных в программах на С/С++? Я уж не говорю о том, что тогда стоит сравнивать какие-то похоже вещи — проекты примерно одинаковой сложности, выполняющие примерно одни задачи, написанные разработчиками примерно одинаковой квалификации. А то я так могут CVEшки и в программах на голанге наковырять, а потом ходить и трубить на каждом углу, что голанг — небезопасный язык.
P.S. ну, и давайте до кучи смотреть на https://www.cvedetails.com/product/3847/Microsoft-Visual-C-.html?vendor_id=26
Или думаете, что в MS тоже не профессионалы, а студенты пишут?
KanuTaH
А сколько еще не найденных и не подтвержденных в программах на rust? И, если вы заметили, я специально выбрал аналогичные по функциональности проекты, а в плане сложности даже дал расту фору. Про квалификацию разработчиков сказать ничего не могу, возможно, в clang/gcc она и повыше, чем в rust-lang.
KanuTaH
P.S. Ну давайте. 6 CVE за 16 лет (с 2004 года включительно), ноль не только за последние 2 года, но и за последние 9 лет.
Antervis
спорное утверждение:
так это же ошибка выведения типов
KanuTaH
Это уже новый код, специализированный для случая когда p передан через std::move() и при этом не copy constructible, который как раз и призван решить проблему. В случае get и release для unique_ptr тип действительно одинаковый. Почему автор патча в специализированной функции после стрелочки написал decltype(p.get()) — это вопрос, конечно. Вероятно, как говорил кот Матроскин, «чтобы не нарушать отчетность», т.е. чтобы сигнатура совпадала с неспециализированной версией.
technic93
Кстати интересный пример. Как оно в c++ работает? Почему компилятор выкинул delete, потому что я не вижу heap аллокации тут.
technic93
Отвечу сам себе. Создание и удаление временного объекта для
f(unique_ptr<T> p)лежит на стороне вызывающего. Поэтому в с++ реализация функцииfне вызывает конструктор и деструктор. В расте происходит по другому, приf(p: Box<T>)ответственность за удаление объекта лежит на самой функцииfпоэтому мы видимdeallocв асм выхлопе. Естественно на всю программу количество new/delete в случае с++ и раст не изменилось (при условии что с++ компилятор выкинетdelete nullptrдля moved-out объекта). Далее было бы интересно подумать какие это дает плюсы и минусы для оптимизации сложной программы где есть много подобных вызовов (так же в случаяхf(f(f(p)))). Хотя если всё заинлайнилось то по-идее разницы быть не должно.humbug
Ага, а потом начинаются всякие
std::string_view path, и падения в произвольных местах.Antervis
будьте добры, объясните пожалуйста, как вы в рамках своего мировоззрения можете объяснить существование софта на с++ который работает?
SirEdvin
Мне кажется, это очень странный вопрос. Абсолютно так же, как и рабочий софт на любом другом языке — тестирование софта творит чудеса обычно.
Но в том же время, я считаю довольно самонадеянным расчитывать на то, что вы то всегда правильно будете работать с памятью, хотя даже с языками у которых есть GC у очень немногих получается. Шутка про то, что в программе на C++ всегда есть как минимум два разных segfault появилась не просто так.
Antervis
так тестировать софт нужно даже если в нём заведомо нет ошибок памяти.
PsyHaSTe
Можно вспомнить знаменитую табличку про стоимость исправления ошибки на разных этапах. Это один из кейсов PVS кстати, они по-моему не раз рекламировали "почему нужно прогонять постоянно, а не разово удостовериться что всё ок"