
А еще о нем говорят, что он где-то посередине между градиентным спуском и методом Ньютона, что бы это ни значило. Ну, с методом Ньютона и его связью с градиентным спуском вроде как разобрались. Но что имеют в виду когда произносят эту глубокомысленную фразу? Попробуем слегка подразобраться.
В своих статьях товарищ Левенберг [Levenberg, K. A Method for the Solution of Certain Problems in Last Squares. Quart. Appl. Math. 1944. Vol. 2. P. 164—168.], а после него гражданин Марквардт [Marquardt, Donald (1963). «An Algorithm for Least-Squares Estimation of Nonlinear Parameters». SIAM Journal on Applied Mathematics. 11 (2): 431–441.] рассмотрели задачу наименьших квадратов, которая выглядит так:
-d_{i}\right)^{2}\rightarrow\min\"") ,
, которую можно записать проще в векторной форме
-d\parallel_{2}^{2}\rightarrow\min\"") .
. А можно еще проще, полностью забив на наименьшие квадраты. Это никак не повлияет на повествование.
Итак, рассматривается задача
\parallel_{2}^{2}=\dfrac{1}{2}f^{T}(x)f(x)\rightarrow\min\"") .
.Такая задача возникает настолько часто, что важность нахождения эффективного метода ее решения сложно переоценить. Но мы начнем с другого. В предыдущей статье было показано, что широко известный метод градиентного спуска, и не только он, может быть получен из следующих соображений. Допустим, что мы пришли в некоторую точку
 , в которой минимизируемая функция имеет значение
, в которой минимизируемая функция имеет значение \"") . Определим в этой точке вспомогательную функцию
. Определим в этой точке вспомогательную функцию =f(x+p)\"") , а также некоторую ее модель
, а также некоторую ее модель \approx g(p)\"") . Для данной модели мы ставим вспомогательную задачу
. Для данной модели мы ставим вспомогательную задачу \rightarrow\min \p\in\Omega
\"")
где
 – некоторое наперед заданное множество допустимых значений, выбираемое так, чтобы задача имела простое решение и при этом функция
– некоторое наперед заданное множество допустимых значений, выбираемое так, чтобы задача имела простое решение и при этом функция  достаточно точно аппроксимировала
достаточно точно аппроксимировала  на . Такую схему называют методом доверительного региона, а множество , на котором минимизируется значение модельной функции — доверительным регионом этой функции. Для градиентного спуска мы брали
на . Такую схему называют методом доверительного региона, а множество , на котором минимизируется значение модельной функции — доверительным регионом этой функции. Для градиентного спуска мы брали  , для метода Ньютона
, для метода Ньютона }=\Delta\right\}\"") , а в качестве модели для выступала линейная часть разложения в ряд Тейлора
, а в качестве модели для выступала линейная часть разложения в ряд Тейлора +\bigtriangledown f^{T}(x)p\"") .
. Посмотрим, что будет, если усложнить модель, взяв
=f(x)+\bigtriangledown f^{T}(x)p+\dfrac{1}{2}p^{T}H(x)p\"") .
.Минимизируем эту модельную функцию на эллиптическом доверительном регионе
 (множитель добавлен для удобства вычислений). Применив метод множителей Лагранжа, получим задачу
(множитель добавлен для удобства вычислений). Применив метод множителей Лагранжа, получим задачуp+\dfrac{1}{2}p^{T}H(x)p+\dfrac{\lambda}{2}p^{T}Bp-\lambda\Delta\rightarrow\min\"") ,
,решение которой удовлетворяет равенству
p+\lambda Bp+\bigtriangledown f(x)=0\"")
или
+\lambda B\right)p=-\bigtriangledown f(x)\"")
Здесь, в отличие от того, что мы видели раньше при использовании линейной модели, направление p оказывается зависимым не только от метрики
 , но и от выбора размера доверительного региона
, но и от выбора размера доверительного региона  , а значит методика линейного поиска неприменима (по крайней мере обоснованно). Также оказывается проблемным определить в явном виде величину
, а значит методика линейного поиска неприменима (по крайней мере обоснованно). Также оказывается проблемным определить в явном виде величину  , соответствующую величине . Однако вполне очевидно, что при увеличении длина
, соответствующую величине . Однако вполне очевидно, что при увеличении длина  будет уменьшаться. Если при этом мы еще наложим условие
будет уменьшаться. Если при этом мы еще наложим условие  , то длина шага будет не больше, чем та, которую дал бы метод Ньютона (всамделешный, без модификаций и условий).
, то длина шага будет не больше, чем та, которую дал бы метод Ньютона (всамделешный, без модификаций и условий). Таким образом, мы можем вместо того, чтобы для заданного
искать подходящее значение , поступить с точностью до наоборот: найти такое , при котором выполняется условие  < g(0)\"") . Это своего рода замена почившему в данном случае линейному поиску. Марквардт предложил следующую простую процедуру:
. Это своего рода замена почившему в данном случае линейному поиску. Марквардт предложил следующую простую процедуру: - если для некотрого значения условие
) < g(0)\"") выполнено, то повторять
выполнено, то повторять  до тех пор, пока
до тех пор, пока  < g(p(\lambda))"")
- если же
)\geq g(0)\"") , то принять
, то принять  и повторить.
и повторить.
Здесь
 и
и  – константы, являющиеся параметрами метода. Умножение на
– константы, являющиеся параметрами метода. Умножение на  соответствует расширению доверительного региона, а умножение на
соответствует расширению доверительного региона, а умножение на  – его сужению.
– его сужению. Указанная методика может быть применена к любой целевой функции. Заметьте, здесь уже не требуется положительная определенность гессиана в отличие от рассмотренного ранее случая, когда метод Ньютона представлялся частным случаем метода последовательного спуска. Не требуется даже его невырожденность, что в ряде случаев очень важно. Однако в этом случае увеличивается цена поиска направления, поскольку каждое изменение
приводит к необходимости решать линейную систему для определения .Посмотрим что будет, если применить данный подход к задаче о наименьших квадратах.
Градиент функции
=J^{T}f\"") , ее гессиан
, ее гессиан  , где
, где  . Подставляем и получаем следующую систему, определяющую направление поиска
. Подставляем и получаем следующую систему, определяющую направление поискаp=-J^{T}f\"") .
.Вполне приемлемо, но вычислять вторые производные вектор-функции может быть довольно накладно. Марквардт для обхода этой проблемы предложил использовать не саму функцию
 , а ее линейную аппросимацию
, а ее линейную аппросимацию =f(x_{0})+J(x_{0})(x-x_{0})\"") , при которой матрица
, при которой матрица  обращается в ноль. Если теперь в качестве взять единичную матрицу
обращается в ноль. Если теперь в качестве взять единичную матрицу  , то получим стандартную форму метода Левенберга-Марквардта для решения задачи наименьших квадратов:
, то получим стандартную форму метода Левенберга-Марквардта для решения задачи наименьших квадратов:p=-J^{T}f\"") .
.Для данного способа определения направления спуска Марквардтом же была доказана теорема о том, что при устремлении
к бесконечности направление стремится к антиградиенту. Строгое доказательство заинтересованный читатель сможет найти в базовой статье, но надеюсь, что само это утверждение стало достаточно очевидным из логики построения метода. Оно в определенной мере оправдывает вездесущую отсылку к тому, что при увеличении лямбды (которую по непонятной мне причине часто называют параметром регуляризации) мы получаем градиентный спуск. На самом деле ничего подобного — мы получили бы его только в пределе, в том самом, где длина шага стремится к нулю. Намного важнее то, что при достаточно большом значении лямбды направление, которое мы получаем, будет являться направлением спуска, а значит мы получаем глобальную сходимость метода. А вот вторая часть утверждения, что при устремлении лямбды к нулю мы получаем метод Ньютона, со всей очевидностью верна, но только если принять вместо ее линейную аппроксимацию  .
.Казалось бы, всё. Минимизируем норму вектор-функции в эллиптической метрике – используем Левенберга-Марквардта. Имеем дело с функцией общего вида и имеем возможность вычислить матрицу вторых производных – велкам использовать метод доверительного региона общего вида. Но есть же извращенцы…
Иногда методом Левенберга-Марквардта для минимизации функции
называют выражение вот такого вида:p=-H^{T}\bigtriangledown f\"") .
. Вроде все то же самое, но здесь
 – матрица вторых! производных функции . Формально это имеет право на существование, но является извращением. И вот почему. Тот же Марквардт в своей статье предложил метод решения системы уравнений
– матрица вторых! производных функции . Формально это имеет право на существование, но является извращением. И вот почему. Тот же Марквардт в своей статье предложил метод решения системы уравнений =0\"") путем минимизации функции
путем минимизации функции \parallel_{2}^{2}\"") описанным методом. Если в качестве
описанным методом. Если в качестве \"") взять градиент целевой функции, то действительно получим приведенное выражение. А извращение это потому, что
взять градиент целевой функции, то действительно получим приведенное выражение. А извращение это потому, что решается задача минимизации, порождаемая системой нелинейных уравнений, порождаемых задачей минимизации.
Даблстрайк. Такое выражение, как минимум, не лучше первого уравнения сферического доверительного региона, а вообще намного хуже как с точки зрения производительности (лишние операции по умножению, а в нормальных реализациях — факторизации), так и с точки зрения устойчивости метода (умножение матрицы на себя ухудшает ее обусловленность). Здесь иногда возражают, что
 гарантированно положительно определена, но в данном случае это не имеет никакого значения. Давайте посмотрим на метод Левенберга-Марквардта с позиций метода последовательного спуска. В этом случае мы, получается, хотим в качестве метрики использовать матрицу
гарантированно положительно определена, но в данном случае это не имеет никакого значения. Давайте посмотрим на метод Левенберга-Марквардта с позиций метода последовательного спуска. В этом случае мы, получается, хотим в качестве метрики использовать матрицу +\lambda B\"") , и чтобы она могла выступать в этом качестве, значение должно обеспечивать ее положительную определенность. Учитывая, что положительно определена, нужное значение всегда может быть найдено — а значит никакой необходимости требовать от положительной определенности не наблюдается.
, и чтобы она могла выступать в этом качестве, значение должно обеспечивать ее положительную определенность. Учитывая, что положительно определена, нужное значение всегда может быть найдено — а значит никакой необходимости требовать от положительной определенности не наблюдается. В качестве матрицы
не обязательно брать единичную, но для квадратичной модели целевой функции указать адекватный доверительный регион уже не так просто, как для линейной модели. Если брать эллиптический регион, индуцированный гессианом, то метод вырождается в метод Ньютона (ну, почти)p=\left(1+\lambda\right)J^{T}Jp=-J^{T}f\approx\left(1+\lambda\right)Hp=-\bigtriangledown\left(\dfrac{1}{2}f^{T}f\right).\"")
Если, конечно, матрица Гессе положительно определена. Если нет — то как и раньше можно в качестве метрики использовать исправленный гессиан, либо некоторую матрицу, к нему в каком-либо смысле близкую. Встречается также рекомендация использовать в качестве метрики матрицу
\"") , которая по построению гарантированно является положительно определенной. К сожалению, мне не известно хоть сколь-нибудь строгого обоснования данного выбора, но в качестве эмпирической рекомендации он упоминается довольно часто.
, которая по построению гарантированно является положительно определенной. К сожалению, мне не известно хоть сколь-нибудь строгого обоснования данного выбора, но в качестве эмпирической рекомендации он упоминается довольно часто.В качестве иллюстрации давайте посмотрим, как ведет себя метод на все той же функции Розенброка, причем мы будем рассматривать ее в двух ипостасях — как простую функцию, записанную в форме
=(1-x)^{2}+100(y-x^{2})^{2}\rightarrow\min\"") ,
, и как задачу наименьших квадратов
=\left\Vert \begin{array}{c}
1-x\100(y-x^{2})
\end{array}\right\Vert _{2}^{2}\rightarrow\min
\"")

Так ведет себя метод со сферическим доверительным регионом.
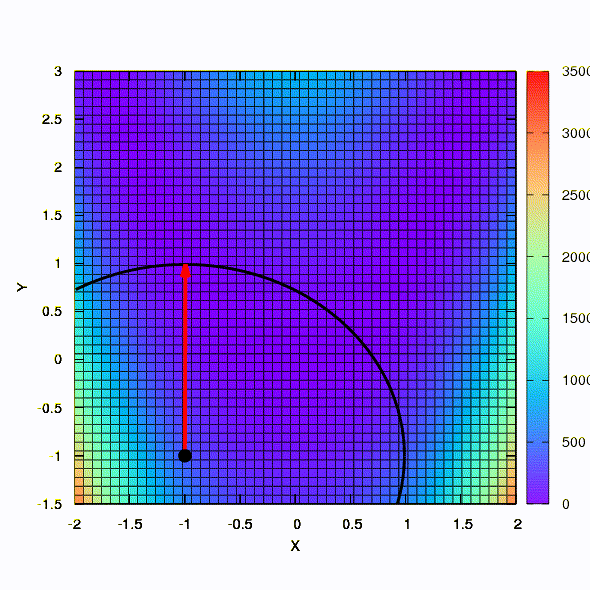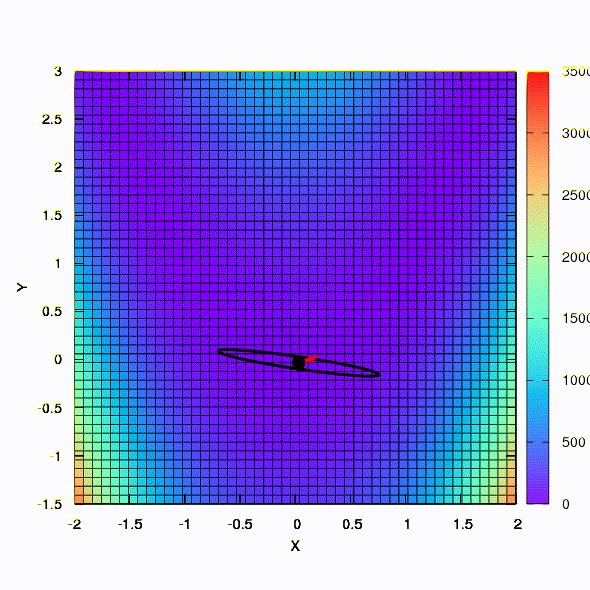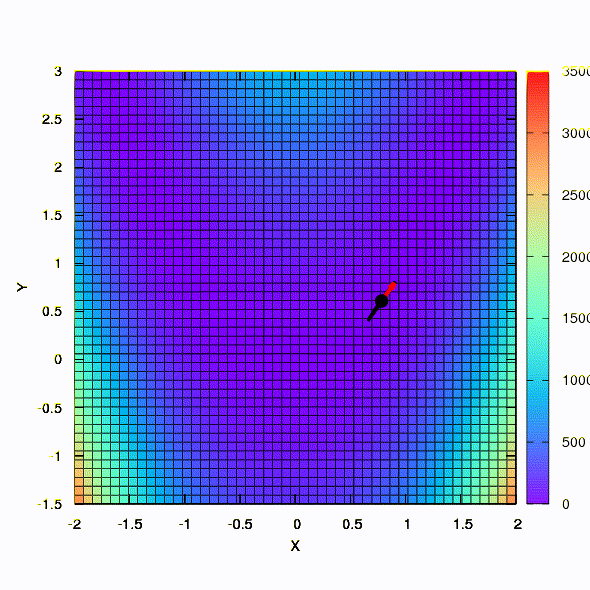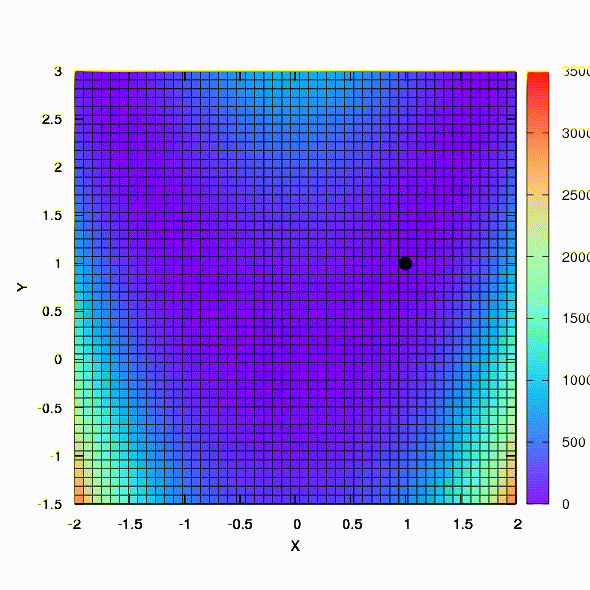
Так тот же метод ведет себя в том случае, если форма доверительного региона задается матрицей, построенной по правилу Давидона-Флетчера-Пауэла. Влияние на сходимость имеется, но куда скромнее, чем в аналогичном случае при использовании линейной модели целевой функции.
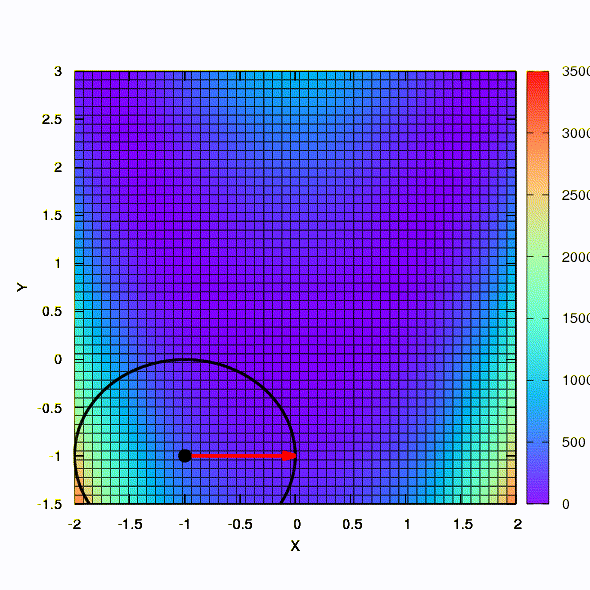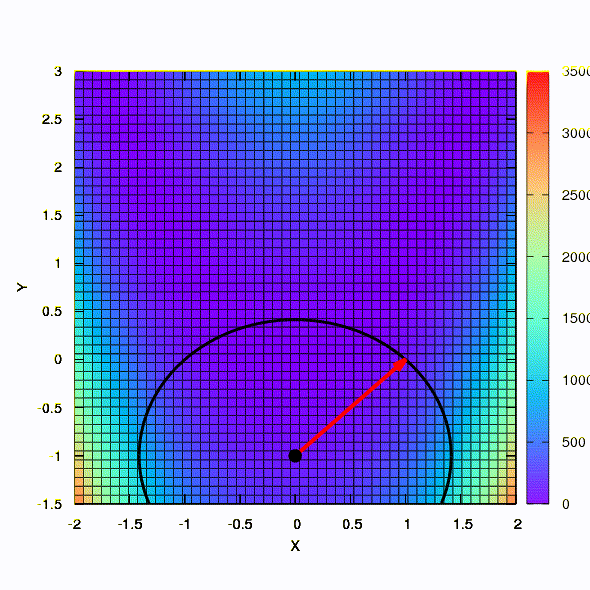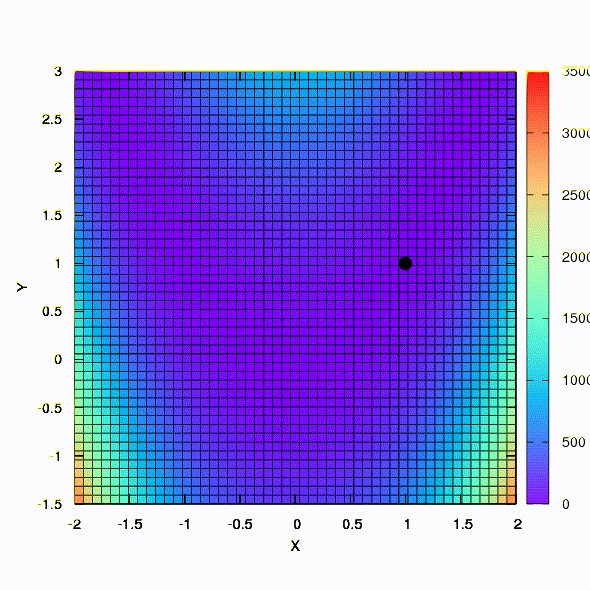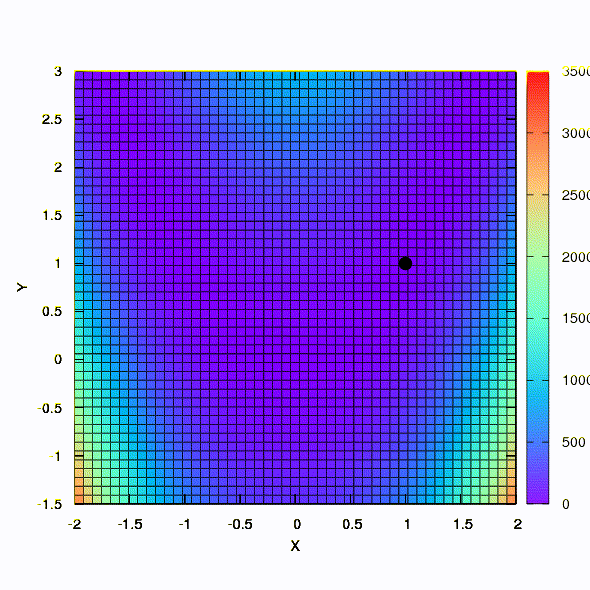
А это уже поведение метода, примененного к задаче наименьших квадратов. Сходится за 5 итераций. Только пожалуйста, не делайте из этого вывода, что вторая формулировка для функций такого вида всегда лучше первой. Это не так, просто в этом конкретном случае случае так вышло.
Заключение
Метод Левенберга-Марквардта является, на сколько мне известно, первым методом, основанным на идее доверительного региона. Он весьма неплохо показал себя на практике при решении задачи наименьших квадратов. Сходится метод в большинстве случаев (виденных мной) довольно быстро (о том, хорошо это или плохо я говорил в предыдущей статье). Однако при минимизации функций общего вида выбирать сферу в качестве доверительного региона — вряд ли наилучший из возможных вариантов. Кроме того, существенным недостатком метода (в его базовой формулировке, которая здесь и была описана) является то, что размер доверительного региона задается неявно. Недостаток проявляется в том, что зная значение
мы, конечно, можем в текущей точке посчитать просто вычислив длину шага . Однако когда мы перейдем в новую точку, этому же значению будет уже соответствовать совсем другая величина доверительного региона. Таким образом, мы лишаемся возможности определения “характерной для задачи” величины доверительного региона и вынуждены в каждой новой точке определять его размер по-новому. Это может быть существенным, когда для сходимости требуется достаточно большое количество итераций, а вычисление значения функции обходится недешево. Подобные проблемы решаются в более продвинутых методах, основанных на идее доверительного региона.Но это уже совсем другая история.
Дополнение
Благодаря ценным комментариям Dark_Daiver я решил, что следует дополнить вышеизложенное следующим замечанием. Разумеется, к методу Левенберга-Марквардта можно прийти иным, чисто эмпирическим путем. А именно, вернемся к описанной в предыдущей статье схеме метода последовательного спуска и снова зададимся вопросом построения адекватной метрики для линейной модели целевой функции.
Допустим, что матрица Гессе в текущей точке поискового пространства не является положительно определенной и не может служить метрикой (причем проверить, так ли это мы не имеем ни возможности, ни желания). Обозначим за
 ее наименьшее собственное значение. Тогда мы можем скорректировать гессиан, просто сместив все его собственные значения на величину
ее наименьшее собственное значение. Тогда мы можем скорректировать гессиан, просто сместив все его собственные значения на величину  . Для этого достаточно прибавить к гессиану матрицу
. Для этого достаточно прибавить к гессиану матрицу  . Тогда уравнение, определяющее направление спуска, примет вид
. Тогда уравнение, определяющее направление спуска, примет вид + \lambda I)p = -\bigtriangledown f(x) \\ \lambda > -\lambda_{\min}")
Если у нас есть хорошая оценка снизу для
, то дальше мы можем делать все то, что делалось в методах последовательного спуска. Однако если мы такой оценки не имеем, то приняв во внимание, что при увеличении длина p будет уменьшаться, можно уверенно говорить о том, что найдется такое достаточно большое , что одновременно  + \lambda I") положительно определена и .
положительно определена и .Почему такой вывод метода я считаю не слишком удачным. Во-первых, совершенно не очевидно, что построенная таким образом метрика является годной для практического применения. В ней, конечно, используется информация о вторых производных, но совершенно ни от куда не следует, что смещение собственных значений на заданную величину не сделают ее негодной. Как было отмечено коллегой в комментариях, представляется очевидным, что добавление масштабированной единичной матрицы к матрице Гессе приводит к тому, что эллиптический доверительный регион будет стремиться к сферическому и тут снова (как кажется) должны выползти проблемы застревания в каньоне и прочие прелести градиентного спуска и близких к нему методов. Но на практике такого не происходит. Мне, во всяком случае, примеров, иллюстрирующих подобное поведение наблюдать не доводилось. В таком случае возникает вопрос: а, собственно, почему?
Но такого вопроса не возникает, если смотреть на данный метод не как на частный случай методов спуска, а как на метод доверительного региона с квадратичной моделью целевой функции, поскольку ответ очевиден: при увеличении лямбды мы всего лишь сжимаем сферу — доверительный регион для нашей модели. Информация о кривизне никуда не уходит и ничем не размывается — мы всего лишь должны подобрать размер региона, в котором квадратичная модель адекватно описывает целевую функцию. Отсюда же следует, что вряд ли стоит ожидать существенного эффекта от изменения метрики, то есть формы доверительного региона, поскольку вся имеющаяся у нас информация о целевой функции и так учтена в ее модели.
Ну и во-вторых, важно при рассмотрении метода понять основную идею, приведшую Марквардта к данному методу, а именно — идею доверительного региона. Ведь в конечном счете только понимание подноготной численного метода позволит понять почему он работает и, что важнее, почему он может не работать.
Комментарии (28)

grewishka
05.10.2019 07:20+1Интересно, может ли что-то сойтись быстрее чем в градиентном спуске, ведь мы идем всегда в направлении максимального спуска. А если не может, зачем все остальное может быть нужно.

Dark_Daiver
05.10.2019 09:06Почти любой метод второго порядка быстрее чем градиентный спуск, причем намного (как минимум для большинства практических задач).
grewishka
05.10.2019 10:58Из чего это следует? Как происходят сами итерации, по какой схеме мы от Xi идем к Xi+1?
Dark_Daiver
05.10.2019 11:15Локально аппроксимируем нашу функцию ошибки в точке при помощи квадратичной функции, после чего делаем шаг в точку минимума нашей аппроксимации. Повторить до сходимости.
Можете представить себе участок функции ошибки, который выглядит как "узкий желоб" с небольшим наклоном (например что-то похожее на https://www.wolframalpha.com/input/?i=f%28x%2C+y%29+%3D+100*x%5E2+%2B+0.1*y%5E2+-+x*y). Предположим, что мы стоим на стенке. Метод наискорейшего спуска укажет в сторону противоположной стенки. Дальше, если у нас есть эффективный line search, то градиентному спуску надо сделать сначала шаг в пространство между стенками, а потом шаг в направлении наклона желоба. Если у нас нет эффективного line search, то градиентный спуск будет осцилировать между стенками, медленно смещаясь в сторону глобального минимума.
Метод Ньютона сразу будет делать эффективный шаг в минимум, т.к. помимо направления наискорейшего спуска им известна локальная форма функции.
В теории, методы третьего порядка должны давать еще более эффективные шаги, но на практике такую аппроксимацию очень сложно и дорого использовать.
grewishka
05.10.2019 11:49Я просто вижу из алгоритма, что нам придется каждую итерацию перемножать матрицу якобиана с транспонированой. Он может хоть за пять итераций сойтись, но если каждая итерация будет стоить как 10 в градиентном спуске, зачем это надо.

Pand5461
05.10.2019 12:27Сложность сильно зависит от деталей.
Для каких-нибудь блочно-диагональных или ленточных якобианов это перемножение будет очень дёшево.
А число итераций может снижаться на порядки. Или робастность метода радикально улучшаться при добавлении второго порядка.
Хотя, конечно, есть случаи, когда овчинка не стоит выделки. В этом засада вообще всех численных методов — "лучше в теории" совсем не означает "лучше на практике в 100% случаев". Почти всегда метод надо подстраивать под задачу.
alexkolzov Автор
05.10.2019 19:29Вы правы, вычислительная сложность методов, в которых направление спуска сильно отличается от антиградиента обычно недешевы. Их применение не всегда оправдано. Но, например, для функции Розенброка, которая в примере, градиентному спуску потребуется несколько десятков тысяч итераций чтобы прийти к минимуму. Ньютону и Левенбергу-Марквардту — пять. Обычно практически оправдано сначала приводить итерации дешевых методов, а когда и если появится затык — переходить к более затратным, но не подверженным всяким неприятностям.
alexkolzov Автор
05.10.2019 19:17Прочитайте предыдущую статью, ссылка в начале. Там рассказано почему что-то сходится быстрее градиентного спуска.
Pand5461
05.10.2019 11:40Хитрость в длине шага.
Если шаг длинный — то в конечной точке он далёк от настоящего градиента, и там будет резкий поворот. Если шаг короткий — надо много итераций.
Классическая картинка:

Методы второго порядка умеют "осреднять" градиент и делать шаги "прямо к минимуму".alexkolzov Автор
05.10.2019 19:22Простите за грубость, но это полная ерунда. Методы второго порядка не усредняют градиент, что бы Вы в эту фразу не вкладывали. Длина шага вообще не при чем, ее определение является отдельной задачей линейного поиска, присущей любому методу спуска. Причину появления вашей классической картинки я рассматривал статьей раньше, прочитайте.
Pand5461
05.10.2019 20:15Ну поправьте, как верно.
Я, может быть, плохо сформулировал (и невольно поспособствовал росту каких-то заблуждений, да).
У меня лично такая цепочка. Реальное время сходимости метода определяется именно количеством шагов. А меньше шагов можно сделать, только если шаг будет длинным. А у чисто градиентного метода, если не учитывать историю (а если учитывать — это будет уже другой метод с другой сходимостью), вообще нет информации, как выбрать длину шага. Поэтому линейный поиск, зигзаги в одном случае и избыточное количество шагов в другом и т.д. А у квадратичного метода есть матрица, которая говорит и куда двигаться, и насколько — и для квадратичной формы гарантированно приводит в стационарную точку с первой же итерации.alexkolzov Автор
05.10.2019 20:32Вы все-таки решили не читать статью. Хорошо, я повторюсь.
Меньше шагов можно сделать, только если шаг будет длинным
Нет, меньше шагов можно сделать если правильно выбрано направление шага.
У чисто градиентного метода вообще нет информации как выбрать длину шага
Ни у какого метода нет такой информации. У вас есть только гарантия, что если выбранное направление является направлением спуска, то существует такой шаг в этом направлении, что значение целевой функции уменьшится.
У квадратичного метода есть матрица, которая говорит и куда двигаться, и насколько
Не для «квадратичного метода», а для метода Ньютона при решении уравнения, которому удовлетворяет стационарная точка. Вы имеете ввиду именно его — будьте точны в терминах. Его сходимость — локальна. Глобально сходящаяся версия метода требует, во-первых, положительную определенность гессиана в каждой проходимой точке, и во-вторых — также линейного поиска. То есть куда двигаться — да, насколько — нет.
А зигзаги возникают не от недостатка информации о длине шага, а от недостатка информации о разности масштаба (грубо) переменных, который может быть учтён посредством изменения формы доверительного региона. Что и приводит к методу Ньютона, квазиньютонам и т.д.Pand5461
05.10.2019 22:02Абсолютно верные замечания.
Но что-то это уходит от исходного вопроса, который был "Интересно, может ли что-то сойтись быстрее чем в градиентном спуске, ведь мы идем всегда в направлении максимального спуска".
Я всего лишь написал, что градиентный спуск, если делать не бесконечно короткие, а длинные шаги, не тождественен максимальному спуску, что поправки следующего порядка и призваны исправить.
И то, что серебряной пули в численных методах нет, — это тоже в другом комментарии написал.alexkolzov Автор
05.10.2019 22:49Значит Вы крайне неудачно выразились. Понятно, что задававший вопрос просто не владеет минимальной теорией, а прочитав про градиент уцепился за термин «максимальный спуск», но зачем его в ещё больший блуд загонять?
Dark_Daiver
05.10.2019 09:27+1alexkolzov а нет желания подробно разобрать BFGS? Что метод Ньютона, что Гаусса-Ньютона довольно хорошо разобраны в разных источниках, а для BFGS все обычно ограничиваются общей формулировкой (накапливаем значение матрицы обратной матрице Гессе), и выражением для шага. А метод ведь очень красивый, и использует только градиент ф-ии + line search
А еще лучше K-FAC (https://arxiv.org/abs/1503.05671). Там вообще все хорошо — идеи из метода Гаусса-Ньютона адаптируются для эффективного обучения нейронок. Правда его все еще никто особо не использует на практике :)
Pand5461
05.10.2019 11:27Плюсую за BFGS.
Попробовал недавно — просто, красиво, эффективно.
А ещё там можно обновлять не матрицу, а сразу разложение Холецкого, и будет численно устойчиво.
А ещё есть трюки, чтобы сразу взять "хорошее" приближение для матрицы, и тогда линейный поиск оказывается почти не нужен.Dark_Daiver
05.10.2019 11:31А ещё там можно обновлять не матрицу, а сразу разложение Холецкого
Про такое не слышал, а можно подробней?
А ещё есть трюки, чтобы сразу взять "хорошее" приближение для матрицы
А не поделитесь тем, что зашло?)
Линейный поиск стал для меня причиной отказа от BFGS в продакшене — слишком сложно тюнить для некоторых случаев. Гаусс-Ньютон не всегда хорош, но довольно робастен, на практике. К сожалению, расчет якобиана не очень хорошо ложится на автодифф, поэтому приходиться страдать.Pand5461
05.10.2019 12:04Можно посмотреть Gill, Murray and Wright, Practical Optimization.
Там почти в начале приводятся формулы для rank-one update разложения Холецкого.
Там же предлагается модифицированное разложение Холецкого — по сути, берём матрицу, пытаемся делать обычное разложение, если где-то вылез слишком маленький элемент на диагонали — заменяем его на положительный нужной величины. И такое разложение гессиана можно брать как начальное приближение для BFGS.
Реально такую вещь не пробовал, у меня системы довольно маленькие и простые, обхожусь линейным поиском. Вот тут пишут, что с мод. разложением для аналогичной моей задачи линейный поиск даже не понадобился.
Dark_Daiver
Не настоящий сварщик, но есть версия, что это для того, чтобы скомпенсировать разный масштаб переменных, который не учитывается в дефолтной регуляризации с единичной матрицей. В этом случае, как раз, доверительный регион будет "эллипсом", а не "сферой"
alexkolzov Автор
Это справедливо для линейной модели целевой функции. При использовании квадратичной модели разный масштаб переменных уже компенсируется использованием матрицы Гессе. И это не строгое обоснование, а умозрительное.
Dark_Daiver
Пока мы не регуляризируем — да, но добавление lambda*I начинает приводить нашу параболу к сферической форме.
По идее так же работает диагональный прекондишенер в методе сопряженных градиентов
alexkolzov Автор
Тогда уж приводить параболу к плоскости, форма региона не меняется. Этот аргумент справедлив если матрица Гессе близка к диагональной — тогда переменные правильно масштабируются, а направление оказывается очень близко к ньютоновскому. Тот же аргумент с большим правом может быть применен к исправленному гессиану или квазиньютоновской метрике.
Это экстраполяция геометрических представлений с плоского случая на многомерный. Идею прочувствовать помогает, но в общем и целом — эмпирика. По идее вы правы, но я говорил о том, что не знаю строгого обоснования.
Dark_Daiver
Не очень правильно выразился — парабола остается параболой, просто если оригинальная аппроксимация могла иметь довольно вытянутую форму (эллипс), то добавление регуляризации сделает ее менее вытянутой (сфера)
Так-то и метод Гаусса-Ньютона тоже во многом эмпиричен :) Если не ошибаюсь, то его сходимость не гарантируется, в отличие от метода Ньютона. Более того, что Левенберг-Марквардт, что Dog leg опираются на эвристики при подборе размера trust region.
alexkolzov Автор
Это смотря как смотреть. Если смотреть на матрицу Марквардта как на метрику — то да, при увеличении лямбды она будет стремиться к масштабированной евклидовой, а форма региона — к сфере. В статье на этот вопрос я смотрю по другому и метрика, а следом и форма региона от величины лямбды не зависит. Это исключает оговорки на положительную определенность гессиана и в целом мне кажется более логичным. Но тут можно говорить, что метрика Марквардта и так насколько это возможно учитывает рассогласование масштаба переменных, поскольку если уж форма региона сильно вырождается, то шаг настолько мал, что это перестаёт быть важным. Если уж заговорили об эмпирике, то по моему опыту применения дополнительного перемасштабирование переменных при использовании квадратичных моделей приводило к значимому ускорению сходимости разве что случайно.
В каком месте Гаусс-Ньютон эмпиричен? По поводу сходимости Ньютона я говорил в прошлом посте и вот он как раз может расходиться, а вот Гаусс-Ньютон сходится глобально. В приведённом изложении без явного использования размера региона Левенберг-Марквардт ни на какие эвристики не опирается, а трастрегионы общего вида опираются на них только плане угадывания размера региона. Ну ещё иногда при поиске квазиоптимального решения, но эти правила эвристичны в меньшей степени.
Dark_Daiver
Насчет сходимости Гаусса-Ньютона — https://en.wikipedia.org/wiki/Gauss%E2%80%93Newton_algorithm#Convergence_properties. Пишут что "However, convergence is not guaranteed, not even local convergence as in Newton's method, or convergence under the usual Wolfe conditions"
Вот их я и имел ввиду.
alexkolzov Автор
У меня есть мечта. Мечта, что однажды люди будут не просто выдирать фразы из Википедии, а будут читать источники, чтобы разобраться в вопросе.
Потому что Википедия брешет. Проблема не в том, что направление, которое метод даёт плохое, проблема в методах линейного поиска — Вульфа, Гольдштейна и их модификаций. Для выдаваемых ими последовательности шагов действительно возможно построить контрпримеры, при которых поиск не сходится даже к локальному минимуму. Это уже сделано для Ньютона, Гаусса-Ньютона, некоторых квазиньютоновских, возможно ещё для каких-то мне неизвестных. Но это никак не отменяет их теоретических свойств сходимости. Просто на практике предполагают без проверки наличие свойств, которые у задачи могут отсутствовать.