
Предлагаю ознакомиться с расшифровкой доклада Дениса Яковлева "Автоматизация инфраструктуры. Зачем мы это делаем?"
Сам доклад 2016 года. Доклад специально расшифровал для тех, которые создают виртуальные машины руками.
Доклад о том, как мы в компании 2ГИС автоматизировали работу с инфраструктурой.
«Нужно бежать со всех ног, чтобы только оставаться на месте, а чтобы куда-то попасть, надо бежать как минимум вдвое быстрее» (Алиса в стране чудес).
Что эта фраза означает для нас? В условиях жесткой конкуренции, компании должны стремиться доставлять свои продукты до пользователей максимально быстро. Уменьшение параметра time to market — задача многоуровневая. Чтобы ее решить надо менять как процессы разработки, так и инструменты. Важной основой всего процесса разработки является инфраструктура. Чем больше инфраструктура, тем больше с ней проблем, use case'ов и т.д. Если все операции с ней не автоматизированы, то число проблем увеличивается. Одной из них является время, которое разработчик тратит на инфраструктурные вопросы вместо того, чтобы писать бизнес логику.
Поговорим о том:
- Какие проблемы с инфраструктурой стояли перед командами;
- Как от этого страдали процессы разработки и тестирования;
- Как мы внедрили OpenStack;
- Какие у нас есть сценарии использования OpenStack;
- Как автоматизация получила дополнительный толчок в развитии и начали появляться новые внутренние продукты;
- Какие аспекты у нас остались не автоматизированы.
О себе. Компания 2ГИС. В компании работаю два года.

Команда Infrastructure and Operations. Мы в основном занимаемся поддержкой внутренней инфраструктуры Web отдела. Недавно к нам еще присоединились другие команды внутренних продуктов. Мы также отвечаем за эксплуатацию web продуктов компании в продакшене. И мы также занимаемся исследованием и разработкой новых инструментов для облегчения своей жизни и для улучшения жизни наших любимых разработчиков. Нас всего 9 человек.

Сначала поймем инфраструктуру. Почему мы о ней говорим? Что это такое? Когда мы начинаем о ней говорить?

C первых моментов работы над продуктом и каким-то проектом у нас возникает вопрос — куда мы будем деплоить? где проверить результаты? где тестировать и так далее.

Сразу же первый ответ — это локально. Локально потому что очень просто. Разработал на своем ноутбуке, запустил, проверил — все хорошо. Сидишь думаешь — зачем проверять кроме своего ноутбука? У меня все работает.

А если у нас на ноутбуке одна операционная система, а в продакшене крутится другая? Или у нас продукт должен поддерживать несколько операционных систем?

Кейс не покрывается. То есть разные операционные системы.

Если мы имеем возможность и мы принимаем волевое решение — у нас везде Linux. К примеру Ubuntu какая-нибудь. Остальное всё от лукавого. Нам кажется, что мы решили все свои проблемы.

Но простого совпадения операционной системы недостаточно. Нам нужны пакеты определенной версии.

мы думаем как решать эту проблему. И вспоминаем — у нас же изоляция есть. Очень кайфовая штука. Слава богу на рынке есть очень много продуктов. Мы берем virtualbox. Создаем виртуальную машину. Накатываем свой продукт. Делаем снапшоты. Мы получили окружение.

Мы развиваемся. Наш продукт становится сложнее. Это уже не просто php приложение с базой. Приложение переросло в распределенную систему. У нас появляются другие продукты.

Компания развивается. И у нас появляются новые кейсы использования. Все эти продукты хотят интегрироваться, уметь работать вместе. У нас фичи проходят через несколько продуктов. Нас постоянно просят покажите что вы разработали. Дайте нам где-нибудь это посмотреть. У нас перестает хватать ресурсов на ручное тестирование. Мы вспоминаем что есть Сontinuous integration, автотесты. Для этого всего нужен дополнительный софт. Нам локального окружения, даже со всей изоляцией, перестает хватать. Здесь появляется инфраструктура. Нам необходимо место, куда мы можем задеплоить свои продукты и показать кому-нибудь результаты. Мы должны всем этим как-то управлять и это должно быть удобно.

Давайте вернемся посмотрим на нашу компанию 2ГИС.

Это справочник и карты. Можно посмотреть на карте город, поискать организации.

У нас: web продукты, mobile, десктопное приложение. Разных команд порядка тридцати пяти, разных размеров.

Какие проблемы у нас были с инфраструктурой? На конец 2013 года у нас использовался proxmox. Это система управления виртуализацией. С её помощью можно создавать либо KVM виртуальные машины, либо OpenVZ контейнеры. Но это все делается руками через интерфейсы. Для полноценного функционирования еще нужно зайти в виртуальную машину и сконфигурировать сеть, dns.

Поэтому какое-то время flow нашей разработки выглядел следующим образом. Я как разработчик завожу ticket админам. Админы, когда у них будет время, создают виртуалку. Выдают IP-адрес, логин, пароль. Но если мне нужно переразвернуть эту виртуалку, то я опять иду к админам, которые на меня уже смотрят подозрительно. Говорят — парень сколько можно?

Не было разделения по проектам. Был набор виртуалок на нескольких серверах, где админы всё руками создавали. Была большая вероятность человеческой ошибки. Можно было перепутать IP-адрес или удалить не ту виртуальную машину. Очень-очень много таких кейсов. И непонятна ответственность за виртуальную машину. Разработчики ответственность не несут, админы тоже не парятся. Непонятно виртуалка ещё кому-то нужна или про нее все уже давно забыли и не знают о ней.

Плюс там слабый API. Плагины либо платные либо на перле.

Но помимо проблем у нас было еще кое-что полезное. У нас было свое железо, на котором все это крутилось. У нас системные администраторы большие молодцы, умеют это железо готовить, за ним ухаживать, его правильно закупать. И у них был какой-то опыт работы с виртуализацией.

Мы начали думать: какое бы решение нас устроило? Как должна выглядеть наша инфраструктура, чтобы не мешать процессу разработки, а наоборот помогать?
У нас получился следующий список требований в результате исследования:
Эффективная утилизация железо. Мы не хотим иметь бесхозные виртуальные машины. Мы не хотим просто греть воздух в дата-центре.
Мы хотим иметь командные ресурсы чтобы команда взяла на себя ответственность за те ресурсы, которые она использует. И внимательно к ним относилась.
Мы хотим, чтобы решение было модульным, набрать только необходимые нам сервисы. И в случае нужды, при дальнейшем развитии, иметь возможность расширения.
Решение должно быть легко дорабатываем. Если появляются новые требования, мы могли доработать решение под наши специфичные нужды.
Нам нужен не только пользовательский интерфейс, нам нужен API чтобы писать свои обвязки и управлять инфраструктурой.
Мы хотим изолировать команды и особенно команду нагрузочного тестирования. Хотелось, чтобы она вообще не мешала остальным.

Какие у нас были варианты?
Мы посмотрели на публичное облако: AWS и прочее. Вариант привлекательный тем, что они берут на себя практически все вопросы, связанные с инфраструктурой. Можно было взять и заплатить много денег этим известным компаниям, но но нас сдерживала отвратительная ситуация с долларом (или санкциями). Не очень хотелось какой-нибудь vendor-lock получить. Третий вариант, на которой мы посмотрели, что у нас есть на рынке open source? Какие решения у нас предлагаются? Железо у нас свое, остаётся выбрать что-нибудь из этого множества open source приложений.

Вот так в итоге наши исследования и эксперименты привели нас к софтинке называемый OpenStack. Софтинке конечно это слишком грубо звучит.

OpenStack это полноценное программное обеспечение по сути это набор сервисов для построения публичного или приватного облака. OpenStack это open source решение. Все сервисы написаны на питоне. Каждый сервис отвечает за свою задачу, имеет свой API.
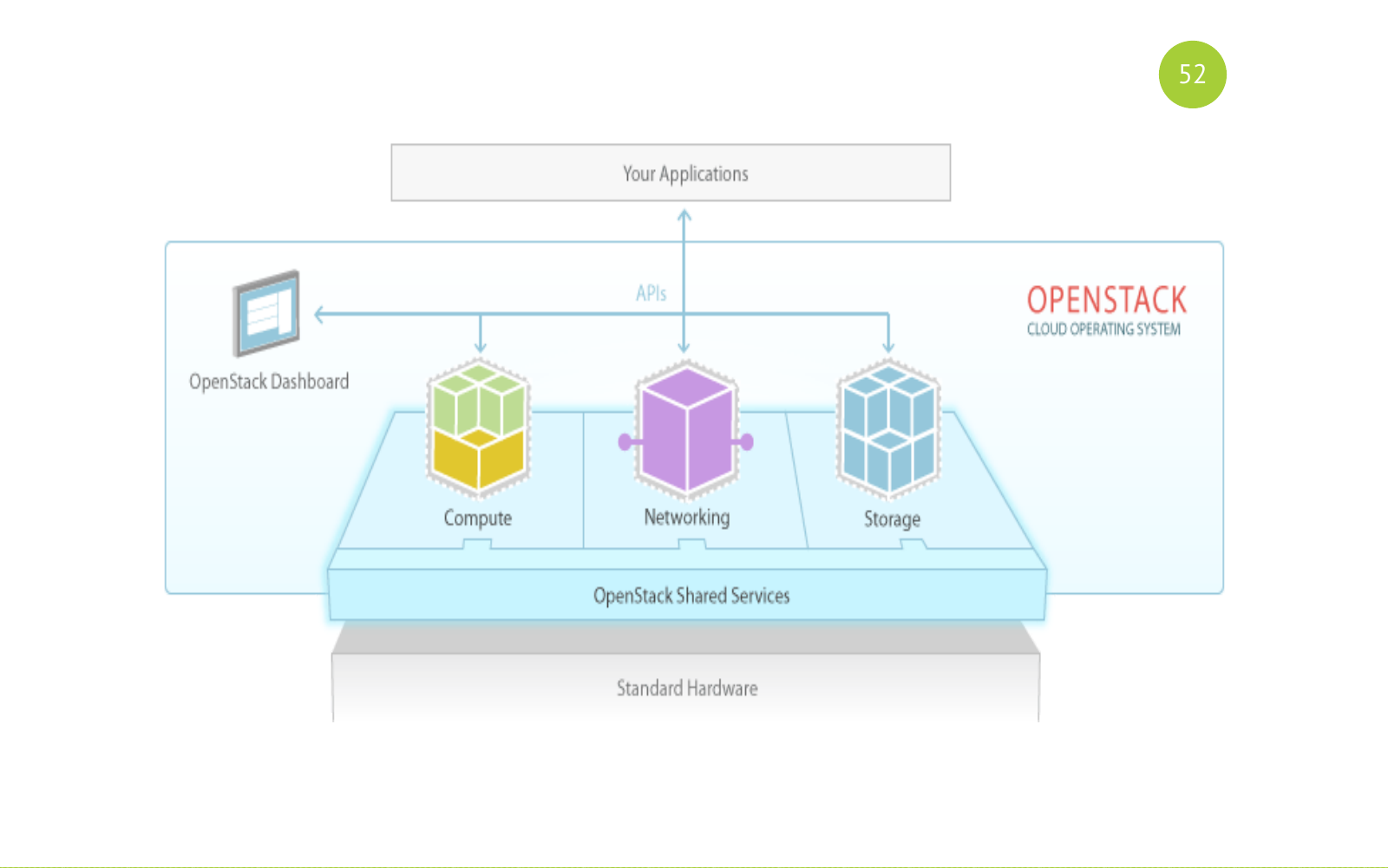
И выглядит это вот так вот. Запомните эту картинку. Дальше потом к ней вернемся. Есть шаренные (общие) сервисы. Есть сервисы по назначению: Compute, Networking, Storage. И наш application или юзер работает с этими сервисами.

Решение open source. Релиз проходит раз полгода. В релиз включаются базовые компоненты. Каждый релиз включаются новые компоненты, которые изначально появляются от в этом инкубаторе. Они там какое-то время проводят, там фиксят баги, стабилизирует и прочее. И в какой-то момент сообщество принимает решение что этот компонент включить в состав базовых компонентов со следующего релиза. Также много различных рассылок, встреч, конференций. Самая большая конференция это OpenStack Summit. Проводится каждый год. И на последнем OpenStack саммите было порядка четырех или пяти тысяч участников. Очень большой такой ивент. Много докладов.

Контрибьютят в это решение очень много народа. Здесь я привел только список из таких топов. Этот список достаточен чтобы понять насколько проект серьезен и какие компании и сколько ресурсов в него вкладывают.

Как мы решили наши проблемы с инфраструктурой.
- Один из компонентов OpenStack это scheduler, который выбирает хост на котором будет создан виртуальная машина.
- Теперь у команды есть свои собственные ресурсы. Это количество CPU, памяти и прочее. Мы избавились от этого сценария создания виртуалки по tiket (заявки).
- OpenStack это набор сервисов то есть. Мы взяли только базовый набор, который обеспечивал наши нужды.
- Так как OpenStack это open-source, то есть возможность его дорабатывать.
- У каждого сервиса есть API. Есть питоновские билдинги. То есть достаточно просто с каждым сервисом взаимодействовать и писать свои какие-то обвязки.
- Изоляция. Мы можем изолировать команд нам по проектам, по aggragation зонам, по сетям и прочее.

Разработчики команд получили инфраструктуру по требованию (infrastructure as service). Как это выглядит.

Есть два понятия Stack и шаблон. Stack это набор облачных ресурсов: виртуальные машины, сеть, dns записи и прочее. Шаблон это описание этого Stack. В случае OpenStack это обычная YAML файл. Здесь часть файла. Тут написано что есть такая сущность как сервер с внутренним типом OS Nova сервер. Для его нормальной работы нужен IP адрес и dns запись. Здесь на вход принимаются параметры имя, flavor — это описание ресурсов, которые нужно этому серверу. Image операционная система. key_name — какой публичный ключ положить при развертывании сервера. У нас все эти шаблоны лежат в репозитории каждой имеют в git. Каждый имеет доступ. Каждый может прислать pull request.

И создание Stack выглядит следующим образом. Heat эта компонента OpenStack, отвечающая за оркестрацию. Мы говорим это в данном контексте. Это отличная утилита, которую мы установили себе. Мы говорим дорогой heat, создай нам Stack с таким именем, вот описание ресурсов, которые нам нужны для создания этого Stack. И вот входные данные, которые требует наш шаблон, который описывает наш стек. Мы это в heat загружаем. Он там шуршит какое-то время, создает нам все необходимые ресурсы у себя внутри. И также мы в этом шаблоне вот здесь вот мы можем указать output. Когда heat создал Stack, он может вывести информацию: ip-адрес, доступ и остальное что мы попросим. Дальше уже можем применять эту информацию для дальнейшей автоматизации.

Для того для того чтобы вы не подумали что OpenStack это просто и дешево, я расскажу на каком железе у на работает OpenStack. Контрольная панель крутится на 3 инфра-нодах. Это железные сервера вот с такими от ресурсами. Это рекомендованная конфигурация для отказоустойчивых.

Также у нас есть две KVM network-ноды, которые обслуживают нашу сеть.

Командные ресурсы у нас крутятся на 8 compute-нодах. Они у нас поделены на 3 агрегационные зоны. Одна compute-нода выделена на зону для нагрузочного тестирования. Там создаются сервера только от команды нагрузочного тестирования. Чтобы не мешать остальным. У нас есть агрегационная зона для нашего внутреннего проекта автоматизации тестирования GUI. У него определенные требования. Он расположен в отдельной агрегационной зоне. Все остальные наши девелоперские окружения, сервера, тестовые окружения крутятся в третьем большом агрегационной зоне. На нее у нас уходит 6 compute-нод.

Мы крутим порядка 350 виртуалок на все команды.

Что мы поняли когда мы уже прошли какой-то путь. Для деплоя и для сопровождения вот этого программного обеспечения нужна команда. Команда в зависимости от ваших ресурсов.

Команды должны обладать определенной компетенцией.
В первую очередь это естественно Ansbile. Деплой OpenStack написан на Ansbile. Есть проект OpenStack-Ansible. Если вы захотите дописать OpenStack-Ansible под свои нужды, то нужно чтобы люди, которые будут этим заниматься, владели Ansbile.
Опыт виртуализации. Нужно уметь виртуализацию готовить, нужно тюнить. Понимать как она работает.
То же самое сетью.
То же самое с backend-сервисами, которые использует OpenStack для своей работы. Эта база MySQL Galera и RabbitMQ в качестве очереди.
Понимание как работает DNS. Как его настроить.
OpenStack написан на питоне. Нужно уметь читать код. В идеале нужно уметь патчить. Искать в комьюнити фиксы. Уметь дебажить код. Это все очень полезно. Если команда имеет такой подход, умеет пользовался подходом как Infrastructure as code, как например ansible все изменения хранят в коде, то у них не будет проблем, которые возникают при настройке руками.
Continues integrations. В набор сервисов OpenStack входит такой сервис как tempest. В нем все тесты написаны на все компоненты. Если мы меняем конфигурацию, запускаем отдельный диплой в All-In-One инсталяции и прогоняем tempest — смотрим не отвалилось ли что-нибудь у нас. Настроен CI и команда должна это понимать и должна уметь все это настроить.
Потому что выглядит все просто и привлекательно данного.

Но когда начинаешь больше вникать в нее, то понимаешь что на самом деле все выглядит вот так вот. Это для кого то может быть сюрпризом.

Внедрение OpenStack это не только техническое решение. Помимо этого нужно уметь продать, уметь объяснить командам новую парадигму того как они теперь работают, какие бенефиты это приносит. Как правильно с этим работать чтобы получить какой профит. Мы писали много документации. Документация вида quickstart (быстрый запуск), first steps(первые шаги). То есть что нужно сделать чтобы быстро облегчить себе жизнь и не за тратить на это много времени.
Мы проводили TechTalk, мы рассказывали, делали темы, показывали, говорили вот смотрите теперь ваш продукт вы можете получить следующим образом. буквально вот пишем шаблон, запускаем. Все достаточно просто. Не надо теперь ходить к админам и что-то у них там просить.
В особо таких сложных случаях когда проект сложный, у него куча кейсов, мы приходили в команды, работали непосредственно с командами. То есть как-то попытались им помочь в автоматизации процессов. Настраивали все командам. Заводили себе какие-то баги. Понимали что мы что-то там не неправильно настроили. В общем плотная работа с командами.

Мы получили быстрый деплой продуктов. Раньше чтобы получить продукты нужно было совершить много ручных действий, взаимодействовать с многими людьми. Сейчас мы получаем создание Envinronment (Окружение, сервера) по кнопке. А если у проекта написан и работает deploy, мы получаем deploy по кнопке или новые Envinronment (Окружение, сервера) с установленным продуктом.
Отсутствие нормальной инфраструктуры было блокером для некоторых команд в плане реализация процесса CI внутри команды. Мы проблемы с инфраструктуры решили, команды подняли по CI серверу, настроили pipeline, в pipeline создаются виртуальные машины. В общем дали толчок в развитии этих процессов.
Также помогли некоторым внутренним продуктам, которые используют инфраструктуру для автоматизации тестирования. VM Master — продукт, который тестирует наш онлайн. Ему нужно поднять много виртуальных машин чтобы с разных браузеров зайти на сайт, пройти какие-то шаги чтобы понимать что у нас онлайн работает во всех известных браузеров. То есть ему очень помогли.
Приятный бонус что разгрузили админов (сами себя). Потому что в какой-то момент деятельность по созданию виртуальной машины начала занимать космическое время. И все начали нервничать. Сейчас мы занимаемся интересными вещами, сложными продуктами. От рутинной задачи мы избавились.

Вопросы?
Вопрос: Сколько времени понадобилось чтобы внедрить OpenStack?
Ответ: Вопрос сложный потому что у нас был процесс, который может вместиться комедийный сериал. У него порог вхождения высокий. Осмысливали всю нашу инфраструктуру, искали решение — ушло три месяца. Потом мы за месяц где-то раскатали первую инсталляцию. Добавили туда парочку проектов. Они там пожили. Потом случился человеческий фактор — отстрелили голову этой инсталляции. Мы поняли что отсутствие отказоустойчивости плохо. Потом мы ждали железо.
Вопрос: пользуетесь ли платной поддержкой?
Ответ: нет, не пользуемся.
Вопрос: Какую версию OpenStack используете?
Ответ: Версия OpenStack называются словами. Сначала был Juno, потом мы обновили до Liberty.
Вопрос: Создаются ли виртуальные машины в pipeline Сontinuous integration?
Ответ: Сборка в Jenkins может вызвать Heat и создать виртуальную машину.
Вопрос: сталкивались ли вы с проблемами шаринга ресурсов? Грубо говоря 2 виртуалки находятся на одной физическом сервере. Одна из них начинает грузить диск, например база данных. Если сталкивались, то как решали?
Ответ: С проблемами шаринга ресурсов не сталкивались. Продукты друг друга особо не мешают. Мы разнесли по сценариям. Если нужно запустить тяжелый сценарий, прогнать нагрузочные тесты, То нужно идти к команде нагрузочного тестирования и они запускают нагрузочное тестирование.
Вопрос: нагрузочное тестирование сразу вынесли в отдельную агрегационную зону или натолкнулись на какие-то проблемы?
Ответ: Приходили сотрудники и говорили что OpenStack тормозит. Мы начинаем разбираться. Оказывается у нас появилась команда нагрузочного тестирования. И команду нагрузочного тестирования вынесли в отдельную агрегационную зону.
Вопрос: У нас большой поток тестов. И тесты находятся в очереди и ждут своих ресурсов. Поможет ли OpenStack в качестве менеджера ресурсов для автотестов?
Ответ: У нас такого кейса нет. В OpenStack есть планировщик. Он управляет ресурсами.
Вопрос: На сколько бы сложен переезд со старой инфраструктуры в OpenStack?
Ответ: Это был очень веселый процесс. Почистили ненужные виртуальные машины в proxmox. Перенесли виртуальные машины в OpenStack.
Вопрос: Что такое DevOps?
Ответ: DevOps это идеология, направленная на то чтобы как можно быстрее доставлять продукты кастомерам. Все процессы в компании, инструментарий, мышление и взаимодействие между командами должны быть выстроены вокруг этой цели.
P.S. В 2019 году для автоматического создания ресурсов в OpenStack вместо heat лучше использовать Terraform.
MMik
Расскажите, что изменилось с 2016 по 2019 год, кроме упомянутой замены Heat на Terraform. От OpenStack'а многие сейчас уже отказались, так как хватает контейнеров, развёртываемых и сворачиваемых в несколько раз быстрее в K8s/Nomad в разных namespace'ах/кластерах под разные среды. CI и сейчас на Jenkins?
gecube
Кубернетес не решает многие задачи, которые решает приватное облако.
Начать с того, что эти оба инструмента (k8s и облако) не заменяют, а прекрасно дополняют друг друга.
MMik
Всё верно, дополняют. Однако, есть множество приложений, для которых уже не нужны виртуалки с их плюсами и минусами, а достаточно только контейнеров.
gecube
Ага, давайте начнем засовывать БД в кубернетес, а потом выяснится, что преимуществ нет, а недостатков куча, учитывая, что этим еще и сложнее управлять....
MMik
Спорить ну буду. Разные приложения — разные требования.
chemtech Автор
Я не работаю в 2ГИС. Я расшифровал доклад Дениса, так как мне эта направление интересно.
Про Terraform добавил. А на чем у вас развернут K8S? Он же должен быть на чем то развернут.
MMik
Понял. Я подумал, что вы этот доклад и читали.
У нас Kubernetes развёрнут на bare metal.
gecube
У нас тоже. В этом решении есть свои плюсы и минусы.
Очень интересно сравнить — как у Вас реализован вопрос storage.
MMik
Локальные диски, контейнеризированный Ceph.
gecube
т.е. rook — https://habr.com/ru/post/452174/ ?
MMik
Нет, пока без Rook.