

Почему мне (и, надеюсь, вам) интересно распознавание речи? Во-первых, это направление является одним из самых популярных по сравнению с другими задачами компьютерной лингвистики, поскольку технология распознавания речи сейчас используется почти повсеместно – от распознавания простого «да/нет» в автоматическом колл-центре банка до способности поддерживать «светскую беседу» в «умной колонке» типа «Алисы». Во-вторых, чтобы система распознавания речи была качественным, необходимо найти самые эффективные средства для создания и настройки такой системы (одному из подобных средств и посвящена эта статья). Наконец, несомненным «плюсом» выбора специализации в области распознавания речи лично для меня является то, что для исследований в этой области необходимо владеть как программистскими, так и лингвистическими навыками. Это весьма стимулирует, заставляя приобретать знания в разных дисциплинах.
Почему именно Kaldi, ведь есть же и другие фреймворки для распознавания речи?
Для ответа на этот вопрос стоит рассмотреть существующие аналоги и используемые ими алгоритмы и технологии (алгоритмы, используемые в Kaldi, описаны далее в статье):
- CMU Sphinx
CMU Sphinx (не путать с поисковым движком Sphinx!) – это система распознавания речи, созданная разработчиками из университета Карнеги-Меллон и состоящая из различных модулей для извлечения речевых признаков, распознавания речи (в том числе и на мобильных устройствах) и обучения такому распознаванию. CMU Sphinx использует скрытые марковские модели на акустико-фонетическом уровне распознавания и статистические N-граммные модели на лингвистическом уровне распознавания. Также в системе присутствуют ряд интересных возможностей: распознавание продолжительной речи (например, стенограмм или звукозаписей интервью), возможность подключения большого словаря в сотни тысяч словоформ, и т. п. Важно отметить, что система постоянно развивается, с каждой версией улучшаются качество распознавания и производительность. Также присутствуют кроссплатформенность и удобная документация. Из минусов использования данной системы можно выделить невозможность запустить CMU Sphinx «из коробки», т.к. даже для решения простых задач требуются знания по адаптации акустической модели, в сфере языкового моделирования и т.д. - Julius
Julius разрабатывалась японскими разработчиками с 1997 года, и сейчас проект поддерживается Advanced Science, Technology & Management Research Institute of Kyoto. Работа модели основана на N-граммах и контекстозависимых скрытых марковских моделях, система способна распознавать речь в реальном времени. В качестве недостатков можно назвать распространение только для модели японского языка (хотя существует проект VoxForge, который создает акустические модели и для других языков, в частности для английского языка) и отсутствие стабильных обновлений. - RWTH ASR
Модель развивается специалистами из Рейнско-Вестфальского технического университета с 2001 года, состоит из нескольких библиотек и инструментов, написанных на языке C++. В проект также входят документация по установке, различные обучающие системы, шаблоны, акустические модели, языковые модели, поддержка нейронных сетей и т. д. При этом RWTH ASR практически не обладает кроссплатформенностью и имеет низкую скорость работы. - HTK
HTK (Hidden Markov Model Toolkit) – это набор инструментов для распознавания речи, который был создан в Кембриджском университете в 1989 году. Инструментарий, основанный на скрытых марковских моделях, используется чаще всего как дополнительное средство для создания систем распознавания речи (например, этот фреймворк используют разработчики Julius). Несмотря на то, что исходный код является общедоступным, использование HTK для создания систем для конечных пользователей запрещено лицензией, из-за чего инструментарий сейчас не является популярным. Также система имеет относительно невысокие скорость и точность работы.
В статье “Сравнительный анализ систем распознавания речи с открытым кодом” (https://research-journal.org/technical/sravnitelnyj-analiz-sistem-raspoznavaniya-rechi-s-otkrytym-kodom/) было проведено исследование, в ходе которого все системы были обучены на корпусе английского языка (160 часов) и применены на небольшом 10-часовом тестовом корпусе. В итоге выяснилось, что Kaldi имеет самую высокую точность распознавания, по скорости работы незначительно проигрывая конкурентам. Также система Kaldi способна предоставить пользователю наиболее богатый выбор алгоритмов для разных задач и очень удобна в использовании. При этом делается акцент на том, что неопытному пользователю может доставить неудобство работа с документацией, т.к. она рассчитана на специалистов по распознаванию речи. Но в целом, Kaldi подходит для научных исследований больше, чем её аналоги.
Как установить Kaldi
- Скачиваем архив с репозитория на https://github.com/kaldi-asr/kaldi:
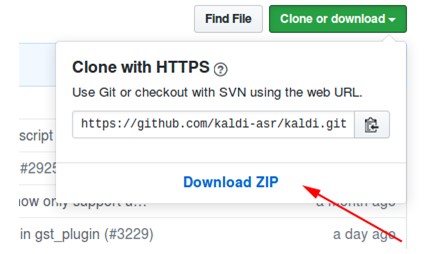
- Распаковываем архив, заходим в kaldi-master/tools/extras.
- Выполняем ./check_dependencies.sh:

Если после этого вы увидите не «all ok», то откройте файл kaldi-master/tools/INSTALL и выполните находящиеся там инструкции. - Выполняем make(находясь в kaldi-master/tools, не в kaldi-master/tools/extras):

- Заходим в kaldi-master/src.
- Выполняем ./configure --shared, при этом можно настроить установку с технологией CUDA или без нее, указав путь к установленной CUDA (./configure --cudatk-dir=/usr/local/cuda-8.0) или поменять изначальное значение «yes» на «no»(./configure —use-cuda=no) соответственно.
Если при этом вы увидите:

то либо вы не выполнили пункт 4, либо нужно самостоятельно скачать и установить OpenFst: http://www.openfst.org/twiki/bin/view/FST/FstDownload. - Выполняем make depend.
- Выполняем make -j. Здесь рекомендуется ввести правильное число ядер процессора, которые вы будете использовать при сборке, например make -j 2 .
- В результате получаем:

Пример использования модели с установленным Kaldi
В качестве примера я использовал модель kaldi-ru версии 0.6, cкачать её можно по этой ссылке:
- После скачивания заходим в файл kaldi-ru-0.6/decode.sh и указываем путь к установленной Kaldi, у меня это выглядит вот так:

- Запускаем модель, указывая файл, речь в котором нужно распознать. Можно использовать файл decoder-test.wav, это специальный файл для теста, он уже есть в этой папке:

- И вот что распознала модель:

Какие алгоритмы используются, что лежит в основе работы?
Полная информация о проекте находится по адресу http://kaldi-asr.org/doc/, здесь же я выделю несколько главных моментов:
- Для извлечения акустических признаков из входного сигнала используются либо широко известные MFCC (Mel-Frequency Cepstral Coefficients), либо чуть менее популярные PLP (Perceptual Linear prediction – см. H. Hermansky, “Perceptual linear predictive (PLP) analysis of speech”). В первом методе спектр исходного сигнала преобразуется из шкалы Герц в мел-шкалу, а затем с помощью обратного косинусного преобразования вычисляются кепстральные коэффициенты (https://habr.com/ru/post/140828/). Второй метод основан на регрессионном представлении речи: строится модель сигнала, которая описывает предсказание текущего отсчета сигнала линейной комбинацией – произведением известных отсчетов входных и выходных сигналов на коэффициенты линейного предсказания. Задача вычисления признаков речи сводится к нахождению этих коэффициентов при некоторых условиях.
- Модуль акустического моделирования включает в себя скрытые марковские модели (HMM), модель смеси гауссовских распределений (GMM), глубокие нейронные сети, а именно Time-Delay Neural Networks (TDNN).
- Языковое моделирование осуществляется с помощью конечного автомата-преобразователя, или FST (finite-state transducer). FST кодирует отображение из входной последовательности символов в выходную последовательность символов, при этом для перехода существуют веса, которые определяют вероятность вычисления входного символа в выходной.
- Декодирование происходит при помощи алгоритма прямого-обратного хода.
О создании модели kaldi-ru-0.6
Для русского языка существует предобученная модель распознавания, созданная Николаем Шмырёвым, также известным на многих сайтах и форумах как nsh.
- Для извлечения признаков использовался метод MFCC, а сама акустико-фонетическая модель основана на нейронных сетях типа TDNN.
- В качестве обучающей выборки послужили звуковые дорожки видеозаписей на русском языке, выкачанные с YouTube.
- Для создания языковой модели использовались словарь CMUdict и именно та лексика, которая была в обучающей выборке. Из-за того, что словарь содержал похожие произношения разных слов, было решено присвоить каждому слову значение “вероятности” и их нормализовать.
- Для обучения языковой модели использовался фреймворк RNNLM (recurrent neural network language models), основанный, как можно увидеть из названия, на рекуррентных нейронных сетях (вместо старых добрых N-грамм).
Сравнение с Google Speech API и Yandex Speech Kit
Наверняка у кого-то из читателей при чтении предыдущих пунктов возник вопрос: окей, то что Kaldi превосходит своих прямых аналогов мы разобрались, но что насчет систем распознавания от Google и Яндекс? Может быть, актуальность описанных ранее фреймворков сомнительна, если есть инструменты от этих двух гигантов? Вопрос действительно хорош, поэтому давайте потестируем, а в качестве датасета возьмем записи и соответствующие текстовые расшифровки с небезызвестного VoxForge.
В результате, после распознавания каждой системой 3677 звуковых файлов я получил такие значения WER(Word Error Rate):

Подводя итоги, можно сказать, что все системы справились с задачей примерно на одном уровне, и Kaldi не слишком уступила Yandex Speech Kit и Google Speech API. Но при этом Yandex Speech Kit и Google Speech API – это «чёрные ящики», которые работают где-то далеко-далеко на чужих серверах и недоступны для тюнинга, а вот Kaldi можно своими руками адаптировать под особенности решаемой задачи – характерную лексику (профессионализмы, жаргон, разговорный слэнг), особенности произношения и т.п. И всё это бесплатно и без СМС! Система является своеобразным конструктором, который мы все можем использовать для создания чего-то необычного и интересного.
Я работаю в лаборатории ЛАПДиМО НГУ:
Сайт: https://bigdata.nsu.ru/
Группа VK: https://vk.com/lapdimo
Комментарии (34)

endymion
09.10.2019 20:26Я честно говоря в теме как свинья в апельсинах поэтому дисклэймер — могу спросить глупость.
Вопрос раз — можно ли этот фреймворк сравнить с wav2letter? Он вроде совсем не упоминается здесь.
Вопрос два — по поводу тестирования фреймворков. Мой небольшой опыт показывает, что распознование сильно зависит от конкретной модели. Т.е. кастомная модель натасканная на определенный словарь может показать лучший результат, чем модель широкого профиля. Это как-то учитывалось при тестировании?
Wicron
09.10.2019 20:38Очевидно, что нет. У Шнырева использовался тот же воксфордж плюс ещё столько же. Это маленькая модель. Сам тест бы поставлен неверно, для этой модели он был проведён на обучающих данных. У гугла модель русского языка на почти 1 млн. часов. И она даёт результат лучше, чем маленькая модель на собственных данных. С яндексом схожая история

bond005
09.10.2019 10:12Мне вот просто интересно, откуда вы взяли, что модель Николая Шмырёва обучена на Voxforge? По моим данным, там использовались только звукозаписи с Ютуба.
И ещё момент: утверждение, что модель гугла или яндекса лучше — это очень сильное утверждение. Оно требует доказательства. Модели что Яндекса, что Гугла имеют «под капотом» математику, во многом аналогичную той, что внутри Kaldi. Нигде нет никакого «секретного ингредиента». Более того, Гугл вообще публикует результаты своих исследований в открытом доступе ai.google/research/pubs/?team=perception А датасет в «миллион часов» — это даже не фантастика, это художественное фэнтези.Wicron
09.10.2019 11:36Работаете в Google? Общаетесь с людьми типа Дена Пуви (kaldi)? Начитаны, но не посчитали сумму обучающих сетов из публикаций Google?
— Оценка снизу — 100 000 часов
— Сверху — 1 млн. часов.
Диапазон большой. Коэффициент увеличения искусственными аугментированными сетами — около 10-12.
Общались с руководителями направлений из Яндекс? Как давно?
Калди уже давно не в проде в Я.
Google распознавание — E2E
Утверждение об аналогичности — это также смешно, как и печально.bond005
09.10.2019 12:01Т.е. ваше утверждение про «миллион часов» было не художественной гиперболой, а вы всерьёз это тут пишите? У меня просто нет слов. И путать объём исходного датасета и процедуру аугментации этого датасета — просто прекрасно. Фейспалм.
Wicron
09.10.2019 13:07-2У вас вообще нет цифр. Вы так и не ответили, связались ли с автором и спросили ли про VoxForge? Мои цифры реальные. Исходный датасет и обучающий датасет не одно и то же и я ничего не путал. Нижняя граница обучающего датасета — это объем исходного. Верхняя граница — это исходный + синтетически аугментированный. Все цифры верны. Если вы решили посчитать WER как параметр качества, то учтите, что в открытых источниках качество распознавания оценивается примерно по 15 и более известным метрикам (лично мне). Ваша попытка делать вывод о качестве на основании одной метрики — это реально смешно. Что касается тусовок, то да, кажется вас там не было видно. Однако сути вещей не меняет. Какую цель вы ставите этой публикацией? Таблица сравнения — не очень адекватная, цифры не сходятся с тестами на больших тестовых сетах. Объем тестовой выборки позволяет вам утверждать о точности определения WER только с учетом диапазона. Подскажите, вы оценили точность определения WER? Судя по объему сета и цифрам в таблице точность оценки WER тут вряд ли превышает +-5%. Вы понимаете, что максимальная ошибка ваших выводов эквивалента нескольким годам работы крупных компаний по изменению этих показателей в лучшую сторону? Статья как по мне — пример как забить гвозди микроскопом.
bond005
09.10.2019 13:38+2С Николаем и я, и мои студенты связывались.
Насчёт того, что ваши цифры реальные, я глубоко сомневаюсь. Сам Гугл, например, в статье «Bytes are all you need» пишет, что у них речевой корпус достигал объёма меньше 100 тысяч часов (76 тысяч часов — это меньше 100 тысяч часов, и я надеюсь, что вы это понимаете) и при этом данный речевой корпус был мультиязычным, а не моноязычным. Объём корпуса речевых данных для экспериментов, проводившихся другим «гигантом», Байду, с его end-to-end-моделью достигал тоже порядка десяти тысяч часов. Так что про миллион часов «поздравляю вас соврамши». Такое впечатление, что вы не понимаете ни то, что пишете, ни то, что читаете.
Про 15 и более метрик — нигде, ни в одной научной работе нет оценки по 15 метрикам. Если вы приведёте мне публикацию в рецензируемом издании или на arxiv, где авторы оценивают алгоритм распознавания по 15 мерам качества, то и я, и другие люди, возможно, читающие нашу переписку, будут весьма признательны. А пока что это опять художественное фэнтези от сетевого анонимуса.
Ну и в завершение по поводу «ваших тусовок», на которых нас не видно. Я более или менее знаком с теми коллективами в России, которые занимаются исследованиями по распознаванию речи (но не со всеми людьми в них, разумеется). Возможно, где-то там тусуется некий неизвестный мне Wicron. Но, судя по вашему стилю общения, «ваша тусовка» — это «Серый, Зубастый и Дима Большой»
Учительница спрашивает Вовочку, знает ли он Циолковского, Кулибина, Попова.
– А вы знаете Серого, Зубастого и Диму Большого?
– Не знаю, – отвечает ошарашенная учительница.
– Ну так нечего меня своей бандой пугать.Wicron
09.10.2019 16:16CER, CHER, CXER, DEL, GER, HES, IMER, IMERA, INFLER, INFLERA, INS, IWER, IWERA, LMER, MER, MSTAT, NCR, OCWR, PHER, RER, SF, SUB, WER, WLMER, WMER…
Продолжать?
Вы еще студентов учите? Не позавидую результатам.
Для подтверждения информации об объемах датасетов вам нужно изучать публикации Google и Amazon.
А еще вам стоит иметь связи с людьми, которые там делают в прод. Стоит организовать переписку с Деном Пуви (facebook)
Иначе вы будете учить тому, подтверждения чего не имеет сами, это неэффективно.
buriy
09.10.2019 16:39Daniel Povey же сказал, что не будет с Facebook работать :) И он вообще-то учёный, научные работы пишет, а не в прод модельки выкатывает.
Если критикуете, делайте это более корректно и обоснованно, пожалуйста.Wicron
09.10.2019 17:59Метрики качества устроили? С Деном Пуви уже пообщались? Он кстати быстро отвечает, особенно тем, кто «из тусовки». Наиболее впечатляющими цифрами по объему исходного сета как ни странно упоминается в контексте Amazon, затем идет Google. Эталоном объема являются цифры от 100 000 часов (Google), для Amazon цифра может быть большей, я не исключу, что Amazon имеет порядка 170 000 часов для каждого из языков (кажется 7 языков). Baidu и Facebook тоже оперируют цифрами от 100 000 часов на языки, поддерживаемые сервисами. Полагаю, что освоение новых групп языков идет по мере накопления размеченных данных. На этапе, когда данных мало для e2e распознавания работают kaldi-based решения, в момент достижения объема подключаются группы разработчиков e2e решения и заменяют прежние. Конечное решение о релизе применяются на основе метрик, обозначенных ранее с добавлением «экономических» метрик.
bond005
09.10.2019 18:18+1Вы читать умеете? Я не просил вас нагуглить мне меры качества. Я просил показать статьи, где используется одновременно 15 мер качества, а не стандартные WER и CER (ну или ещё PER, если эксперименты проводятся на чём-то типа TIMIT).
bond005
09.10.2019 18:22И ещё жду извинений за ваше враньё про VoxForge и миллион часов (извинения за стиль общения даже не жду, вам это даже непонятно, видимо)

dangrebenkin Автор
09.10.2019 06:051. С wav2letter и другими end2end системами распознавания речи планирую сравнение в будущем.
dangrebenkin Автор
09.10.2019 06:122. Вы правы, но модель Николая Шмырева была обучена на аудиозаписях с YouTube-роликов и мне было интересно, как она себя покажет в качестве модели широкого профиля в сравнении со средствами Google и Yandex. Однако, как я уже упоминал в конце статьи, Kaldi это конструктор, можно обучить и свою модель, настроить ее на определённый словарь и получить другие результаты.
Wicron
09.10.2019 11:30В нашей тусовке на воскфордже не обучал только конченый…
Вы общались с Шмыревым и уверены в том, что его модель НЕ обучалась на voxforge?
Даже если так, что ждем теста на 10-12 видов аугментации от бытовых шумов до эффектов скорости чтения и посмотрим на показатели.bond005
09.10.2019 12:05Т.е. про Voxforge вы банально соврали.
А «ваша тусовка» — это кто, осмелюсь спросить?
dangrebenkin Автор
09.10.2019 12:32На Ваш вопрос ответил не только я, но и мой коллега.
Я думал у нас с Вами конструктивный диалог, но Вы перешли на оскорбления и ложь.
Если в Вашей «тусовке» принято в таком стиле вести диалог, то я очень рад. Рад что не состою в этой «тусовке».Wicron
09.10.2019 13:15-3Ваша статья с самого начала серьезно похожа на оскорбление и ложь, породили ваши доводы, ноль пруфоф, отсутствует позиция автора модели, серьезная путанница в терминах, очень поверхностный подход к оценке качества, нет учета точности измерений. Нет сравнения ваших цифр и цифр из других публикаций. Отсутствуют тесты на аугментированных тестовых данных. Нет методики оценки общего показателя качества на основании нескольких метрик одновременно. Если бы она была, google и яндекс были бы для вас заоблачны и вывод был бы другим (особенно google)
arheops
09.10.2019 21:24Только вот гугловский API распознает фразы, причем делает это даже в зашумленном случае.
Тоесть у него с увеличением размера сампла РАСТЕТ точность, а у kaldi — падает.dangrebenkin Автор
09.10.2019 05:53arheops, а Вы можете, пожалуйста, скинуть ссылку на исследование качества распознавания Google API и Kaldi на зашумленных записях?

yar3333
09.10.2019 11:26Есть опыт использования CMU Sphinx. На вроде бы простых практических задачах вида «распознать одну команду из 10 возможных» я был разочарован качеством. Не исключаю, конечно, что я что-то делал не так. Но факт в том, что всё не так просто, как и было, в общем-то, указано в статье.
bond005
09.10.2019 12:32CMU Sphinx довольно-таки плохо распознаёт зашумленную речь, поскольку его матаппарат (гауссовы смеси + скрытые марковские модели) нельзя назвать робастным. Всё-таки старые добрые скрытые марковские модели имеют свой предел. Но на относительно «чистых» звукозаписях да с хорошей языковой моделью (например, на основе НКРЯ) CMU Sphinx ещё что-то может! На упомянутом здесь VoxforgeRu нам удалось получить WER примерно 20% на 10-фолдовой кросс-валидации (с отклонением в 5%).
А вот Kaldi существенно более крут, чем CMU Sphinx, по ряду параметров и — по акустико-фонетической модели, и по реализации языковой модели тоже. Собственно, я немного удивился, почему у автора получился WER для всех сравниваемых систем хуже, чем у нас на CMU Sphinx, хотя, по идее, у нас на CMU Sphinx должно быть хуже всех. Возможно, что у нас была не совсем корректная постановка этого эксперимента. Например, языковую модель мы настраивали на базе N-грамм из НКРЯ, а тексты VoxforgeRu основаны, если я не ошибаюсь, на «Аэлите» Толстого, которая входит в НКРЯ. Ну и разбиение мы старались делать так, чтобы одни и те же дикторы не попали в несколько фолдов, но всё же могли где-то накосячить (там много анонимусов участвовало в записях, и корректно разнести их по фолдам — целая проблема).
А вообще, люди вот сделали большой открытый датасет русской речи, на порядки превышающий VoxforgeRu по размеру, и на нём будет интересно провести эксперименты: habr.com/ru/post/450760
DollaR84
09.10.2019 16:08А как именно вы это делали на cmuSphinx? Просто я когда с ним игрался, то такие ограниченные условия, как вы описали, неплохо работали на грамматических правилах JSGF, ну и с ограниченным словарем под эти правила конечно
bond005
09.10.2019 17:08+2Да, с JSGF-грамматикой на ограниченном домене (например, при распознавании речевых геозапросов в не слишком шумных условиях) CMU Sphinx работает вообще неплохо.
А эксперименты по распознаванию произвольной речи с большим словарём (выше 800 тысяч словоформ) мы делали вот так (смотрите именно веточку ruscorpora-ngrams). Скрипт, который запускает эксперименты с вышеупомянутой 10-фолдовой кросс-валидацией, можно посмотреть вот тут
Если же вам не интересны эксперименты, а хочется потестить уже готовую модель, то можно использовать вот этот наш репозиторий. Но каких-то крутых результатов не ждите, это же CMU Sphinx и HMM :-)
Вкратце методика экспериментов была такая. Мы использовали наш словарь произношений voxforge_ru.dic, полученный на основе слов из НКРЯ, преобразовывали N-граммы оттуда же в ARPA-формат с помощью библиотеки SRILM и конвертировали в бинарный формат с помощью sphinx_lm_convert (так, как описано в этом туториале, потому что языковая модель в бинарном формате быстрее загружается и работает). Транскрипции для словаря произношений мы генерировали с помощью нашего russian_g2p
Сам VoxforgeRu мы били на десять фолдов так, чтобы звукозаписи одного и того же диктора не попадали в разные фолды. Дикторов мы различали по их именам (никам), при этом отдельная проблема заключалась в том, как разбить анонимных дикторов, которых была примерно треть корпуса. В итоге мы решили различать анонимусов по датам (если анонимус сделал два сеанса записей, отстоящие друг от друга на неделю, то это не один, а два разных анонимуса). Ну и получилось то, что получилось. К сожалению, VoxforgeRu до недавнего времени был единственным открытым корпусом русской речи. Очень здорово, что наши коллеги недавно сделали ещё один habr.com/ru/post/450760, и сейчас, конечно же, стоит экспериментировать на нём.
buriy
09.10.2019 16:31+1(напишу один комментарий всем сразу, надеюсь, вы не против?)
1) Да, у нас в датасете open_stt есть три открытых сабсета для валидации (и ещё штук 5 приватных), у меня есть по ним результаты, скоро оформлю их и поделюсь. Непонятно, почему вы не использовали эти открытые сабсеты, а выбрали именно voxforge.
Wicron идейно прав, хоть и плохо знает детали про kaldi и про русский язык. Но в любом случае, статистика по одному неаугментированному датасету даёт очень сильно искажённые результаты во время практического использования. И тут совершенно неважно, делали ли вы cross-fold валидацию, потому что у вас датасет однородный: нет фоновой музыки/белого/уличного шума, лишь одна группа интонаций, соответствующая чтению фраз из текста, и невысокая скорость чтения этого самого текста. Языковая модель у kaldi не очень большая и тоже, судя по всему, натренирована преимущественно на литературных текстах, это очень неприятный вид переобучения, который искажает статистику.
Вот посмотрите на github.com/syhw/wer_are_we: на английском языке типично WER на сабсете с шумам (test-other) отличается от чистого сабсета (test-clean) более чем в два раза!
Так что лучше уберите вообще статистику из поста, нежели публиковать такую.
И будет хороший пост просто про описание kaldi и его компиляцию.
2) Не забывайте, что VoxforgeRu имеет некоммерческую лицензию (GPL), это ещё одна причина сомневаться в том, что коммерческая модель kaldi-ru-0.6 by alphacephei дополнительно тренировалась на нём.
И, кстати, мои данные как раз показывают, что kaldi лучше всего работает на youtube (понятно, что под «лучше» имеется в виду датасет с наименьшим отрывом по WER).
3) В разделе «Почему именно Kaldi, ведь есть же и другие фреймворки для распознавания речи?» нет никаких End2End подходов, нет даже улучшенных фонемно-нейросетевых подходов. Как будто их не существует! Это тоже может ввести людей в заблуждение, не надо так делать.
4) В целом пост про kaldi получился хороший (у меня пара знакомых не смогла самостоятельно установить kaldi, потому что у них мало опыта возни с C и с Make, им точно пригодится), но если вы ориентируетесь на начинающих, мне кажется важным правильно расставлять акценты и не допускать существенного искажения информации.bond005
09.10.2019 18:03+1Спасибо за замечания!
Хоть я и не автор, но позволю себе, во-первых, согласиться с ними, но, во-вторых, при этом некоторые из замечаний прокомментировать.
1. Эксперименты на валидационных сабсетах из open_stt автору следует провести и дополнить статью их результатами, это да.
2. Также имеет смысл аугментировать тестовые записи фоновым шумом, например, из датасета Freesound Audio Tagging, и посмотреть, какая система чего стоит на зашумлённых данных.
3. По поводу end2end — по идее, про это должен быть отдельный пост. Но лично я сейчас выскажу одну субъективную вещь. End2End — это, конечно, хорошая штука, но не всегда. В любом случае, end2end системы типа DeepSpeech, wav2letter и т.п. демонстрируют качество распознавания хуже человека. Для компонентных систем типа Kaldi, состоящих из акустико-фонетического блока и языковой модели, это тоже справедливо, но есть нюанс. Такие вот компонентные системы гораздо легче «тюнятся» под конкретную задачу, чем end2end — достаточно просто модифицировать языковую модель, для чего не нужны речевые корпуса, а хватит только текстовых. Соответственно, именно поэтому я считаю, что в практическом плане Kaldi выглядит не менее интересно, чем любая существующая end2end-система.
4. По поводу улучшенных фонемно-нейросетевых подходов — если я правильно понимаю, в Kaldi используется нейросеть типа TDNN — что-то в духе одномерных свёрточных сетей. Т.е. речь не идёт про GMM+HMM, пусть даже обученные дискриминативно, а именно про нейросети. В принципе, Kaldi поддерживает (или в Kaldi можно встроить) разные типы сетей — например, VAE для предобучения без учителя. Можно использовать LSTM или SRU. Но насколько оправдано это в одной небольшой научно-популярной публикации, для которой, к тому же, планируется продолжение? Цель конкретно этой публикации — показать, что Kaldi тоже можно использовать, и что для этого не обязательно брать какой-то «черный ящик» от корпораций. Качество при этом будет отличаться, но не в разы, а поскольку Kaldi позволяет «малой кровью» дотюнивать модель «под себя» без перестройки акустико-фонетического модуля, то эту разницу можно нивелировать и даже улучшить результаты для конкретного домена.buriy
09.10.2019 19:27Не, дело не в том, что подход end2end не рассмотрен подробно. Дело в том, что он не упомянут, как будто его вообще не существует, и современные модели Яндекса и Гугла не на нём построены. При этом, какая цель вообще упоминать Julius, NTK и что там древнее ещё было? Зачем эта битва инвалидов? Чтобы kaldi на их фоне выглядел хорошим?
И, кстати, разве для них тоже есть русские модели, которые участвовали в сравнении качества? Или просто эта секция в статье была целиком позаимствована из какой-то статьи 2014 года? Существуют такие же открытые пакеты DeepSpeech2, ESPNet, NeMo для end2end подхода.
>Качество при этом будет отличаться, но не в разы
1) Для такого вывода в статье недостаточно данных :) У меня на одном шумном тексте 57% WER у Kaldi, и 31-35% у всех остальных. Это как раз в разы.
Вот из него фрагмент. Сравни и попробуй угадать, где тут Kaldi, а где другая система:
«а вон тем атрейо нравственностью и доктора никого делали заказывала шансон тебя»
«здравствуйте марио здравствуйте я завтра никого делали заказы на нашем сайте»
а вот правильный ответ:
«здравствуйте мария алло здравствуйте меня зовут вероника вы делали заказ на нашем сайте»
Вот такие финты он любит делать, когда слова в LM не попадают и два диктора разговаривают на одном канале, перекрывая друг друга. Кстати, как видно, другие системы тоже этим страдают, но в меньшей степени.
2) На глаз, 30% WER от 40% WER и 50% WER очень сильно отличается. И практическая польза от этого сильно разная. (Также, хотелось бы видеть CER, а не только WER, именно из-за того, что есть виды оверфита, которые меняют CER, не просаживая WER, и наоборот).
Например, из-за своего скудного словаря и маленькой LM, Kaldi склонен к тому, чтобы заменять не очень понятные слова другими почти случайными словами. Из WER это не очень видно — ведь половина слов же у него правильная, а вот на CER гораздо виднее, кто оверфитится на LM.
3) Сравнение с уровнем человека — тонкая штука.
>Такие вот компонентные системы гораздо легче «тюнятся» под конкретную задачу, чем end2end — достаточно просто модифицировать языковую модель, для чего не нужны речевые корпуса, а хватит только текстовых
Языковую модель можно и у нейросетевых систем затюнить ровно таким же образом, поэтому не понимаю, чем здесь Kaldi лучше (в облаках, конечно, фиксированная LM, но там она намного более хорошая в любом случае, и рескоринг есть, и исправление опечаток). End2end обычно делают только AM, а LM является отдельным модулем.bond005
09.10.2019 20:10Для CMU Sphinx точно есть русская модель, и не одна. Для HTK (и, соответственно, для Julius) не помню уже (украинская вот есть, это я могу сказать). Для end2end-систем с русскоязычными предобученными моделями, по-моему, совсем беда. В частности, для той же DeepSpeech2 пока что нет русской модели (или я не нашёл). А проводить эксперименты по обучению собственных моделей не планировалось в объёме данной статьи — по сути дела, первой для автора. На это предполагается отдельная статья.
Насчёт примера с Kaldi и другой системой — могу предположить, что тут Kaldi сгенерировала первый вариант, а другая система — второй, раз у Kaldi оказался WER в два раза хуже на этом датасете :) Но, например, в моей практике были и обратные примеры, когда и Kaldi, и другая система показывали сопоставимые (при этом достаточно приемлемые) результаты на сложных предметно-ориентированных звукозаписях из области нефтехимии, со всякими там «полипропиленами» и т.п.
Опять-таки, у опенсорсной компонентной системы типа Kaldi больше «степеней свободы» в плане тюнинга, даже если сравнивать с опенсорсной end2end-системой, не говоря уже о коммерческом «чёрном ящике» в облаке. Мы же можем взять и перенастроить не только языковую модель, но и словарь Kaldi под новую предметную область, если у нас есть модуль автоматического транскрибирования. Т.е. мы не отдаём всё на откуп машинному обучению («вот тебе, алгоритм, звукозаписи, а вот их аннотации, и научись превращать звуки в буквы»), а вносим априорную информацию в модель, что, по идее, должно повышать робастность всей системы распознавания в целом. Я понимаю, что у Kaldi могут быть проблемы со скоростью (тот же wav2letter существенно круче в этом плане, достаточно вспомнить статью с его описанием), но с качеством в зависимости от датасета (решаемой задачи) и модели бывает по-разному — и хуже, и лучше. Мне, например, непонятно, почему авторы статьи про wav2letter опубликовали сравнение с Kaldi только по быстродействию, а не по качеству распознавания.buriy
09.10.2019 20:43> и другая система показывали сопоставимые (при этом достаточно приемлемые) результаты на сложных предметно-ориентированных звукозаписях из области нефтехимии, со всякими там «полипропиленами» и т.п.
Это при низких шумах, и при наличии длинных терминов в словаре. Чем длиннее слово, тем проще его правильно написать для FST, так что проблемы Kaldi наоборот нужно искать на коротких словах и разговорной лексике.
bond005
09.10.2019 20:16А насчёт CER — да, надо и этот показатель привести, согласен на 100%.
Но, опять-таки, скудный словарь и маленькая LM в исходной модели KaldiRu — это штуки, которые легко фиксятся без дообучения на акустических данных, и это плюс, с моей точки зрения.buriy
09.10.2019 20:40Если у Kaldi сделать большой словарь, то скорость ещё сильнее упадёт. Rescoring гипотез никак не сделать, исправление ошибок никак не сделать, т.к. слов не из словаря не бывает. Да, казалось бы, чуть большая модульность (и намного большой порог вхождения), но даже после больших трудозатрат, качество и скорость до приемлемых значений всё равно не поднять. Вот в чём проблема Kaldi. Многие с него начинают, пытаются допиливать некоторое время под себя, а потом плюют и уходят на системы получше. Именно поэтому я рекомендовал бы при возможности с ним вообще не связываться, как раз для экономии времени и сил для получения более хороших результатов.
dangrebenkin Автор
09.10.2019 18:29+1Юрий, спасибо за отзыв)
1. Мне нравится идея взять три открытых датасета из open_stt и вычислить WER на них, это будет хорошим дополнением для последнего раздела. Также мне нравится идея @bond_005 об аугментации первоначальной выборки с VoxForge шумом, попробую реализовать и эту идею.
2. End2End подходы я планировал сравнить в будущем, в этой же статье я хотел понять, насколько Kaldi лучше/хуже справляется со своими задачами чем наиболее известные системы, такие как CMU Sphinx и т.д. Возможно стоило рассмотреть и другие подходы, я не ожидал, что к этому будет такой интерес. Постараюсь, по возможности, дополнить и эту тему.
Wicron
Автор, ты канонический. Взял воксфордж в качестве тестовых данных и модель шнырев. Подскажи, ты в курсе что есть почти 100% вероятность, что Шнырев использовал воксфордж в качестве обучающей выборки? Таким образом ты вычислил WER не на тестовых данных, а на обучающих
dangrebenkin Автор
Насколько я знаю, Николай Шнырев использовал в качестве обучающей выборки аудиозаписи с YouTube-роликов, а не VoxForge.