

Привет, коллеги! Как из 20 000 новостей за 30 секунд выделить главные темы? Обзор тематического моделирования, которое мы делаем в ТАСС, с матешей и кодом.
Начну с того, что представленная в данной заметке информация является частью прототипа, который развивается в Цифровой лаборатории ИТАР-ТАСС, для поддержания «цифровизации» бизнеса. Решения постоянно улучшаются, я опишу текущий срез, он, очевидно, не будет венцом творения, а скорее опорой для дальнейших разработок.
Большая задумка
Помимо новостной повестки, над которой ежедневно работают редакции ТАСС, хорошо понимать, какие темы больше всего создают новостной фон в российских интернет-СМИ. С этой целью мы собираем свежие новости с 300 самых популярных сайтов каждые несколько минут, 24/7; затем наступает самое интересное — выбор методов моделирования и эксперименты.
Когда сеанс магии завершится, мои коллеги, редакторы и менеджеры начнут пользоваться отчетом с новостными темами. Я полагаю, что для людей вне ареала разработки ПО и data science автоматическая обработка, анализ и визуализация текстовых данных выглядит слегка волшебно. Из-за отчужденности человека от высоких технологий, различные несовершенства их работы могут приводить к непониманию того, что внутри и разочарованию. Чтобы негативной реакции было меньше, я стараюсь сделать продукт более простым и надежным. А понимание сути тематического моделирования можно свести к тому, что к одной теме принадлежат новости, похожие между собой и отличные от новостей в любой другой теме.
Я ставлю эксперименты по тематическому моделированию уже около года. К сожалению, большинство подходов, которые я опробовал, давали мне весьма сомнительное качество наполнения новостных тем. При этом я совершал действия согласно логике подбора параметров в методах из популярных библиотек кластеризации. Но у меня нет размеченного набора данных. Поэтому каждый раз я отсматриваю выборку текстов, попавших в ту или иную тему. Дело довольно муторное и не благодарное.
Особая пикантность этой задачи в том, что несколько специалистов, посмотрев на вошедшие в отобранную тему новости, найдут их в той или иной степени несоответствующими. Например, новость с заявлением Эрдогана о начале операции в Сирии и новость с первыми сводками после начала операции в Сирии можно понять либо как одну, либо как несколько тем. Соответственно, СМИ, цитируя ТАСС или иное информагентство, напишут ряд текстов и про то, и про это. А результат работы моего алгоритма будет склоняться к их объединению или разделению на основании… косинуса угла между векторами частоты слов, количества принятых априори тем, или радиуса в методе нахождения ближайших соседей.
В общем, вся эта большая задумка настолько же хрупка, насколько и красива.
Почему факторный анализ?
При ближайшем рассмотрении методов кластеризации текстов видно, что каждый из них базируется ряде предположений. Если предположения не соответствуют изучаемой проблеме, то и результат может сильно вести в сторону. Предположения факторного анализа кажутся мне — и многим другим исследователям — близкими к задаче моделирования тем.
Созданный в начале XX века, данный подход основывался на идее, что помимо переменных, характеризующих наблюдения выборки, есть скрытые факторы, которые, говоря немного неформально, коррелируют с некоторыми наблюдаемыми переменными. К примеру, ответы на вопрос «верите ли вы в бога» и «ходите ли вы в церковь» будут скорее совпадать, чем различаться. Можно сделать предположение, что есть «фактор религиозности», который проявляет себя в наборе взаимосвязанных переменных. При этом, есть также возможность померить, насколько сильно переменные связаны с их скрытым фактором.
Для текстов постановка задачи становится следующей. В новостях, которые описывают одну тему, будут встречаться одни и те же слова. Например, слова «Сирия», «Эрдоган», «Операция», «США», «Осуждение» будут встречаться вместе чаще в тех новостях, которые посвящены теме развертывания Турцией военного вмешательства в Сирию, и сопутствующей реакции на это дело со стороны США (как геополитического игрока на той же территории).
Остается выудить все важные факторы новостной повестки за какой-то период. Это и будут новостные темы. Но это еще не все…
Немного математики
Для людей, искушенных в методах тематического моделирования, я могу сделать такое заявление. Тот вариант факторного анализа, который я распробовал — это сильно упрощенная версия ARTM методологии.
Но я решил поэкспериментировать с методами, где поменьше степеней свободы, что лучше усвоилось то, что происходит внутри.
(Big)ARTM выросла из pLSA, вероятностного латентного семантического анализа, который, в свою, очередь, был альтернативой LSA, основанного на сингулярном разложении матрицы — SVD.
Разведывательный факторный анализ идет дальше SVD в том, что он дает «простую структуру» связи между переменными и факторами, что может быть совсем не простым делом для SVD, но ограничен в том, что не предназначен для точного расчета факторных значений (scores), то есть, вектора значений фактора, которым можно заменить 2 и более наблюдаемых переменных.
Формально задача разведывательного факторного анализа ставится так:
Где наблюдаемые переменные
линейно связаны со скрытыми факторами
Нужно найти
Всё! Данные бэта-коэффициенты называются в мире факторного анализа нагрузками (loadings). Рассмотрим их важность немного позже.
Чтобы прийти к результату анализа можно двигаться различными путями. Один из них, который я использовал, заключается в нахождении главным компонент в классическом понимании, которые затем вращаются для выделения «простой структуры». Главные компоненты как раз тянутся из сингулярного разложения матрицы, либо через разложение вариационно-ковариационной матрицы на собственные вектора и значения. Также задача решается через максимизацию функции правдоподобия. В целом, факторный анализ — это большой «зоопарк» методов, не менее 10, которые дают разные результаты, и рекомендуется выбирать тот метод, который лучше всего подходит под задачу.
Вращение матрицы нагрузок можно совершать также разными способами, я попробовал varimax — ортогональное вращение.
Почему же все так сложно-то?
Дело в том, что в среде статистиков и прикладников не прекращается дискуссия о различии и схожести метода главных компонент, факторного анализа и их комбинации. Методология пополняется новыми знаниями даже спустя более 100 лет с момента открытия. Один уважаемый статистик привел мне следующую картинку для облегчения понимания со словами: «Всё, разбирайся».
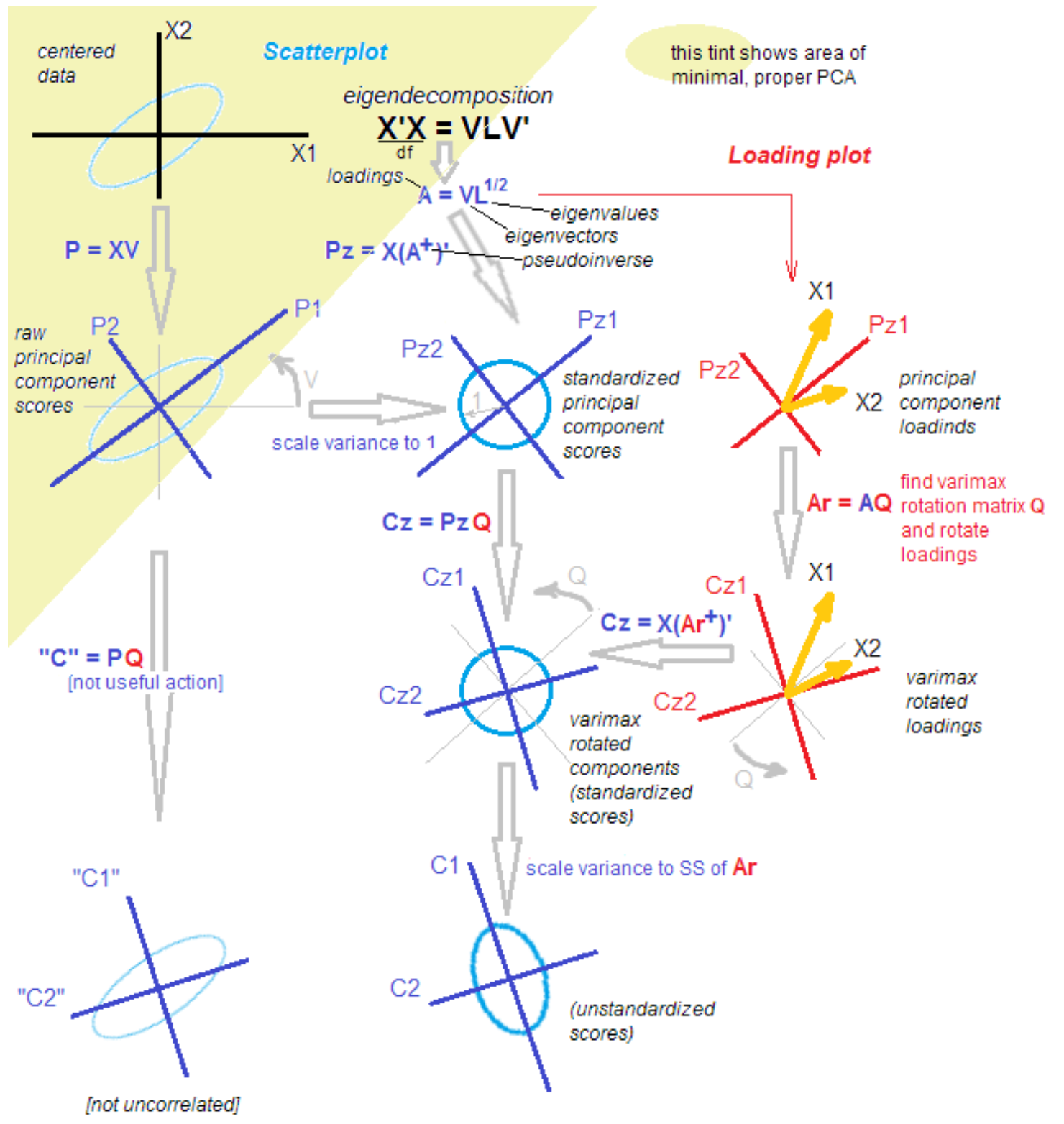
источник.
Всё, разбирайтесь!
Шучу ). Для понимания дальнейших шагов достаточно того, что после выделения главных компонент, мы их повращаем, перейдя от объяснения дисперсии внутри переменных к объяснению ковариации переменных и факторов.
Далее я делаю все это, используя атомарные функции, а не просто нажимая одну «большую красную кнопку». Такой подход позволяет понять трансформации в данных на промежуточных этапах.
Куда дели LDA?
Update
Я решил добавить мои соображения относительно латентных размещений Дирихле. Я пробовал этот популярнейший метод, но не смог за короткое время получить чистый результат. Простецкие примеры по его использованию, а ля «Давайте разделим новости на политику, экономику и культуру» действительно работают, но… В моем случае я должен разделять, скажем, политику, на 50 дневных тем, где будет и Россия, и Путин, и Иран, и такие узкие темы, как «освобождение Кокорина и Мамаева». Все это, по сути, 1-2 новости информационного агентства, процитированные несколько десятков раз в СМИ.
Более того, предположение о природе данных, свойственные гипотезе о том, что каждый текст это распределение вероятностей по темам, — кажется мне немного искусственным в контексте моей работы. Никакой редактор не согласится с тем, что новость о «прекращении дела в отношении Голунова» это микс тем. Для нас это 1 тема. Возможно, подбирая гиперпараметры можно добиться такой дробности и от LDA, оставлю этот вопрос на будущее.
Код
Я снова балуюсь с языком R, поэтому этот небольшой эксперимент будет арийским.
Мы работает с 3 парами скоррелированных случайных значений. В этом наборе заложено 3 скрытых фактора — просто для наглядности.
set.seed(1)
x1 = rnorm(1000)
x2 = x1 + rnorm(1000, 0, 0.2)
x3 = rnorm(1000)
x4 = x3 + rnorm(1000, 0, 0.2)
x5 = rnorm(1000)
x6 = x5 + rnorm(1000, 0, 0.2)
dt <- data.frame(cbind(x1,x2,x3,x4,x5,x6))
M <- as.matrix(dt)
sing <- svd(M, nv = 3)
loadings <- sing$v
rot <- varimax(loadings, normalize = TRUE, eps = 1e-5)
r <- rot$loadings
loading_1 <- r[,1]
loading_2 <- r[,2]
loading_3 <- r[,3]
plot(loading_1, type = 'l', ylim = c(-1,1), ylab = 'loadings', xlab = 'variables');
lines(loading_2, col = 'red');
lines(loading_3, col = 'blue');
axis(1, at = 1:6, labels = rep('', 6));
axis(1, at = 1:6, labels = paste0('x', 1:6))
Мы получаем такую матрицу нагрузок:
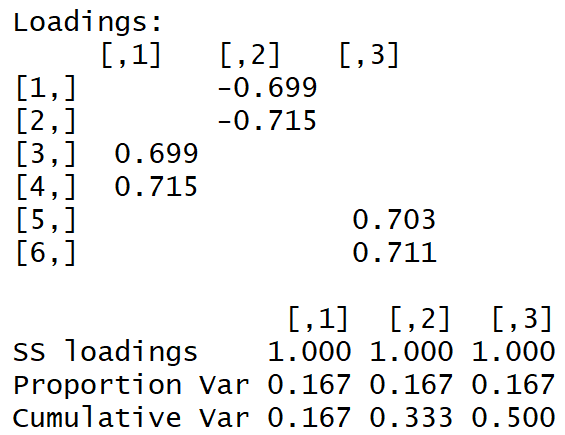
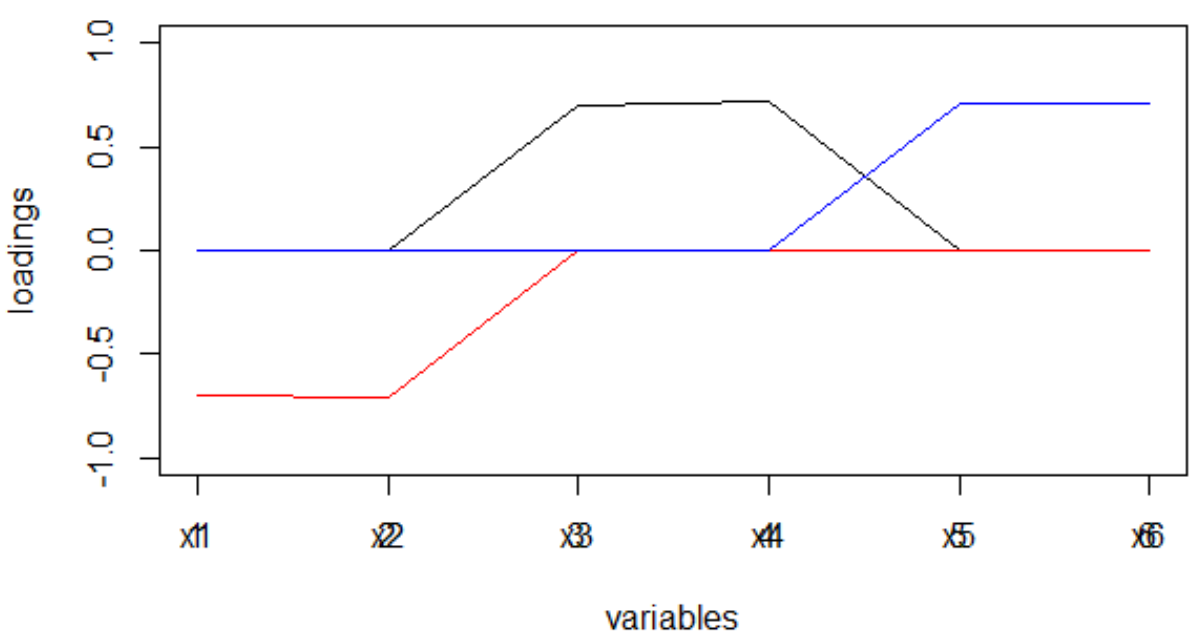
Видно невооруженным глазом «простую структуру».
А вот как выглядели нагрузки сразу после выполнения МГК:
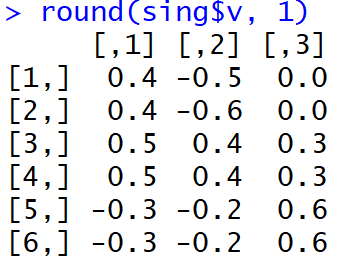
Не очень просто людям понять, какие факторы ассоциированы с какими переменными. Более того, такие веса, взятые по модулю, и в трактовке машины приведут к весьма странному распределению слов по темам.
Но, бо!, доля объясненной дисперсии у настоящих первых трех главных компонент (до вращения) дошла до 99%.

Что же с новостями?
Для новостей наши переменные x1, x2… xm становятся частотой (или tf-idf) встречаемости токена в текста. Слов много! Например, 50 000 уникальных слова за неделю это нормально. Би-грамм будет еще больше, понятно. Сложность сингулярного разложения такова в среднем:
То есть, она огромна. Разложение матрицы 20 000 * 50 000 значений в один поток занимает несколько часов…
Чтобы была возможность считать темы в реальном времени и выводить на дашбоард Shiny, я пришел к следующим болезненным обрезаниям:
- top-10% самых часто встречаемых слов
- случайная выборка текстов по самодурной формуле:
где n — все тексты.
В результате я обрабатываю недельные данные за 30 секунд, один день за 5 секунд. Неплохо! Но, надо понимать, что и новостные тренды захватываются только самые упитанные.
Получив нагрузки, которые, я замечу, являются оценкой ковариации наблюдаемых переменных к факторам, я освобождаю их от знака (через модуль, не через степень), который имеет свойство меняться в зависимости от применяемого метода вращения.
Вспомним, как отличалась матрица нагрузок после проведения МГК и после вращения варимаксом. Разреженность нагрузок, а также тот факт, что их дисперсия для каждого фактора максимизировалась: есть очень большие и очень маленькие, — приведут к тому, что слова будут распределяться между фактора довольно чисто, что, в свою очередь, приведет в дальнейшем к тому, что и распределение факторов на новостной текст будет иметь явно выраженный пик.
Примеры максимально нагруженных слов в различных найденных темах (выбраны случайно):
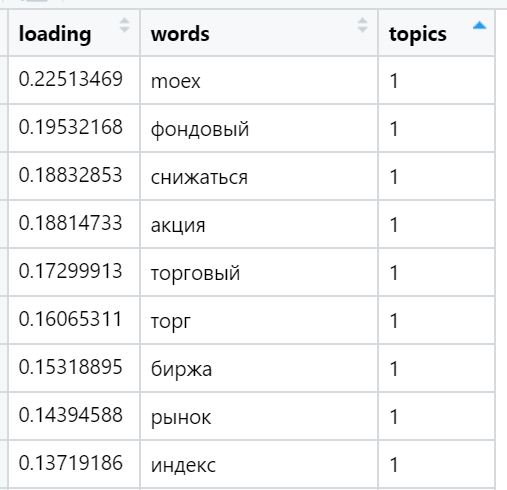
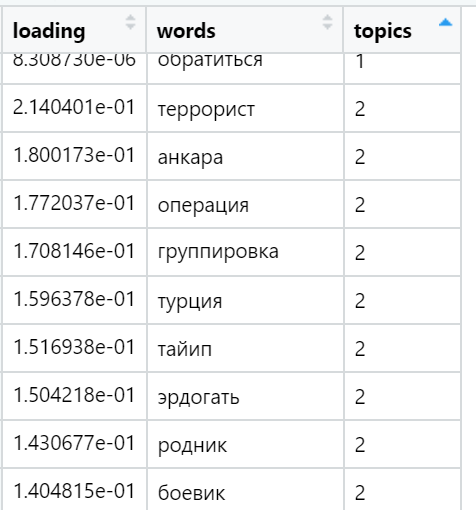

И, наконец, я считаю сумму нагрузок в текстах по отношению к каждому фактору. Побеждает сильнейший: для каждого текста выбирается фактор, сумма нагрузок которого максимизировалась — с учетом количества слов, входящих в документ, которые — как мы обеспечили в ходе вращения — имеют очень неравномерное распределение между факторами по нагрузкам. В этой итерации участвуют уже все тексты (n), то есть, полная выборка.
Примеры топовых по сумме нагрузок тем в конкретных новостных текстах (выбраны случайно):
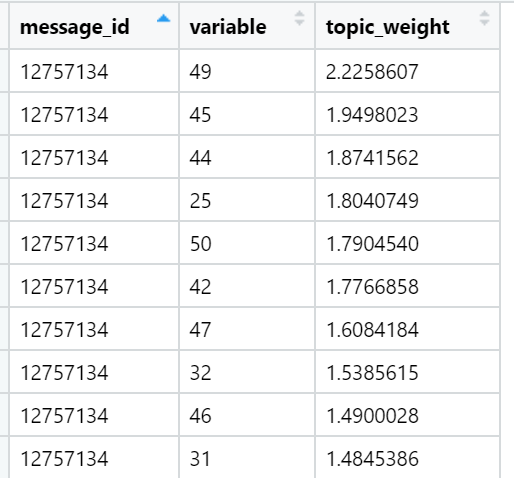
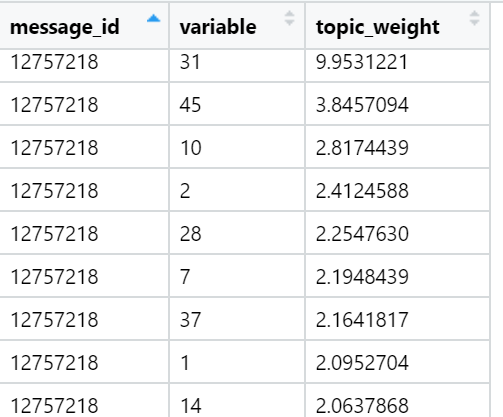
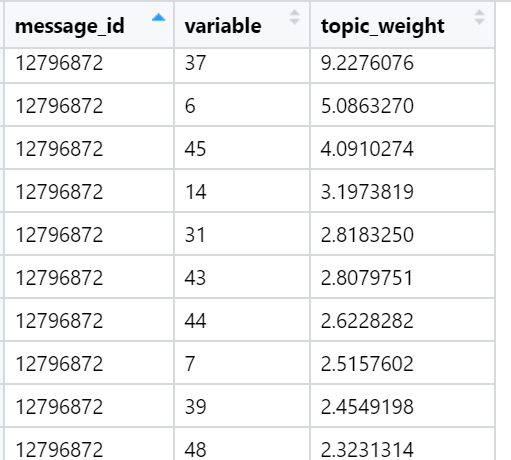
Результат за сегодня.

Дополнительная информация.
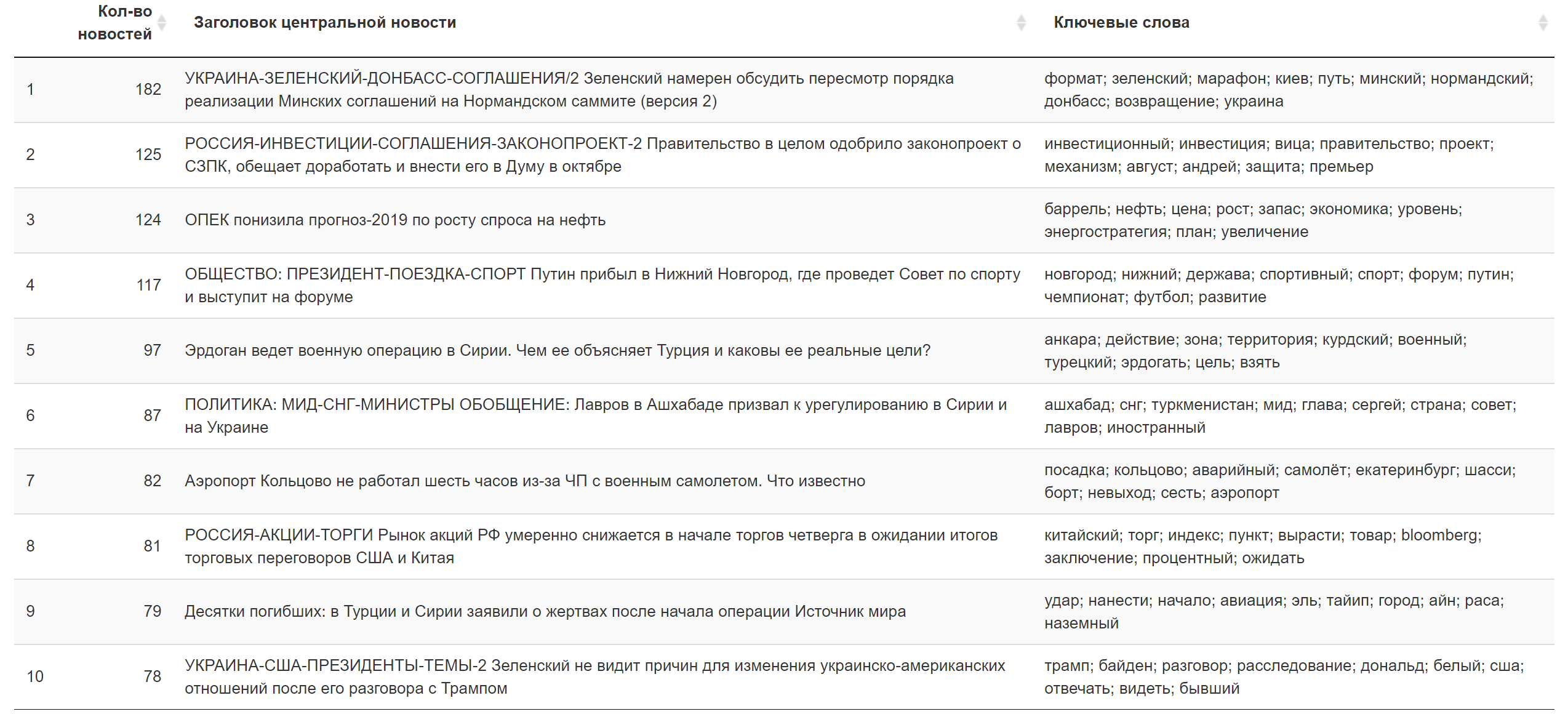
Что делать?
Вот, первое, что я сделаю, когда… В общем, когда придет вдохновение, это попытаюсь настроить джобу для ежечасного обучения нейронной сети с узким горлом, которая будет мне выдавать как раз нелинейную аппроксимацию факторов — искаженных главных компонент — в виде нейронов скрытого слоя. В теории — обучение можно провести быстро, используя повышенную скорость обучения. После этого веса скрытого слоя (как-то еще отнормированные) будут играть роль нагрузок на токены. Их уже можно быстро подгрузить в среду финальной обработки с приемлемой скоростью. Пожалуй, такой трюк может привести к тому, что неделя будет обрабатываться по всем текстам за 10 секунд: нормальное время для такого тяжелого случая.
В целом, это все, что я хотел осветить. Надеюсь, этот небольшой экскурс в метод тематического моделирования позволит вам лучше понимать, что делается под «большой красной кнопкой», уменьшит отчужденность от технологии и принесет удовлетворение. Если вы это уже знали, буду рад выслушать мнения технического или продуктового толка. Наш эксперимент развивается и все время меняется!
george3
Анализ текста без учета семантики слов — малополезная трата времени.