
Мне показалась интересной данная публикация: Получаем абсолютные курсы из парных кросс-курсов валют и я захотел проверить возможность найти этот аааабсолютный курс валюты через численное моделирование, вообще отказавшись от линейной алгебры.
Результаты получились интересными.
Эксперимент будет небольшим: 4 валюты, 6 валютных пар. Для каждой пары одно измерение курса.
Итак, начнем
Гипотеза в том, что стоимость любой валюты можно выразить неким значением, которое будет учитывать стоимости других валют, в которых она котируется, при том, что другие валюты сами будут выражены в стоимости всех других валют. Это интересная рекурсивная задача.
Имеется 4 валюты:
- usd
- eur
- chf
- gbp
Для них был набраны валютные пары:
- eurusd
- gbpusd
- eurchf
- eurgbp
- gbpchf
- usdchf
Обратите внимание, что если число валют n = 4, то число пар k = (n ^2 — n) / 2 = 6. Нет смысла искать usdeur, если котируется eurusd…
В момент времени t был замерен курс валютных пар у одного из провайдеров:
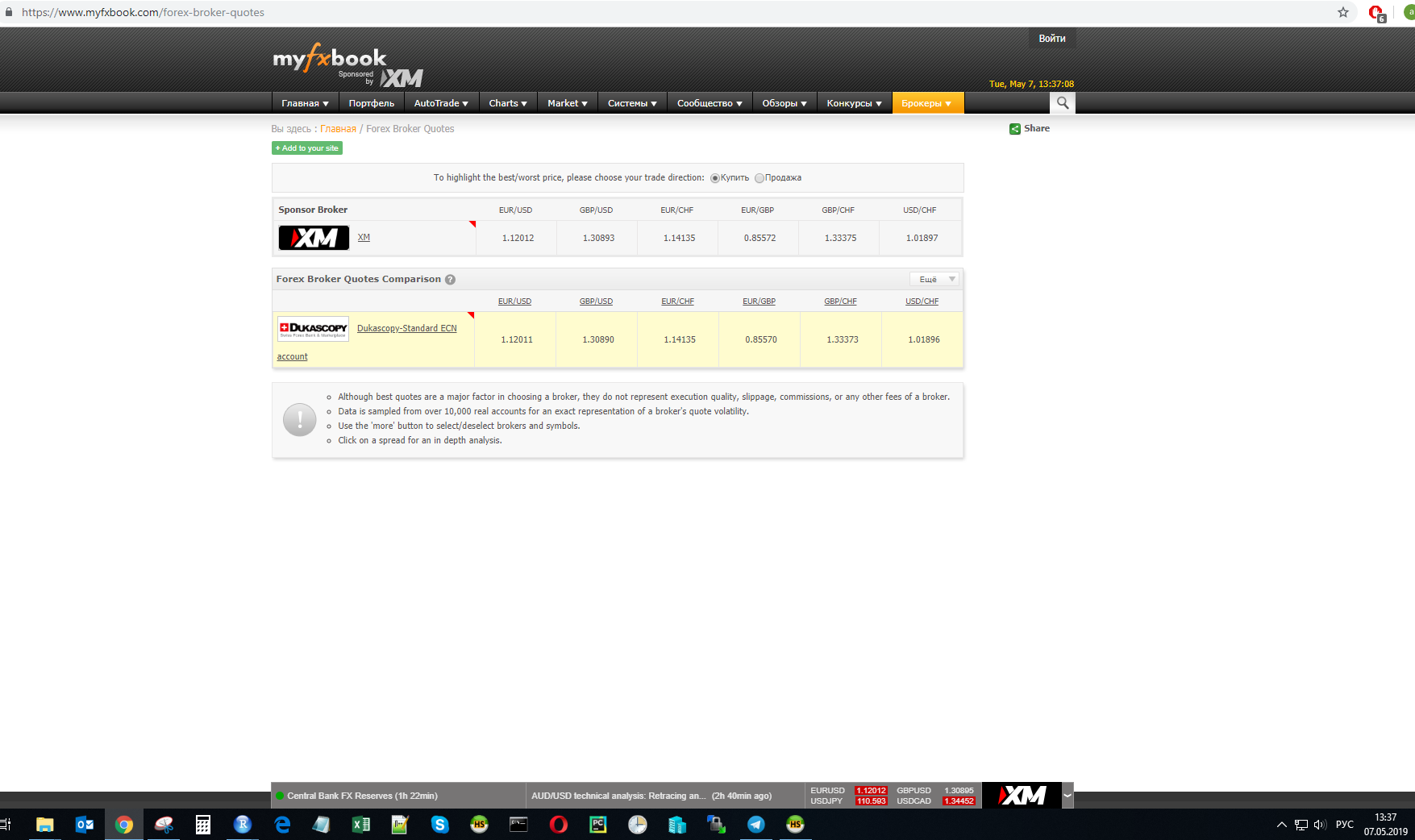
Расчеты будут проводиться для этих значений.
Математика
Я решаю задачку, аналитически беря градиент функции потерь, которая по сути есть система уравнений.
Код эксперимента будет на языке R:
#set.seed(111)
usd <- runif(1)
eur <- runif(1)
chf <- runif(1)
gbp <- runif(1)
# snapshot of values at time t
eurusd <- 1.12012
gbpusd <- 1.30890
eurchf <- 1.14135
eurgbp <- 0.85570
gbpchf <- 1.33373
usdchf <- 1.01896
## symbolic task ------------
express <- expression(
(eurusd - eur / usd) ^ 2 +
(gbpusd - gbp / usd) ^ 2 +
(eurchf - eur / chf) ^ 2 +
(eurgbp - eur / gbp) ^ 2 +
(gbpchf - gbp / chf) ^ 2 +
(usdchf - usd / chf) ^ 2
)
eval(express)
x = 'usd'
D(express, x)
eval(D(express, x))
R позволяет с помощью ф-ии stats::D брать производную функции. Например, если мы хотим продифференцировать по валюте USD, получаем такое выражение:
2 * (eur/usd^2 * (eurusd — eur/usd)) + 2 * (gbp/usd^2 * (gbpusd —Чтобы уменьшить значение функции express, мы будем выполнять градиентный спуск и сразу понятно (видим квадратные разницы), что минимальное значение будет равно нулю, что нам и нужно.
gbp/usd)) — 2 * (1/chf * (usdchf — usd/chf))
-deriv_vals * lr
Шаг градиентного спуска будет регулироваться параметром lr и все это взято с отрицательным знаком.
То есть, человеческими словами, подберем курсы 4-х валют так, чтобы все валютные пары в эксперименте получили значения равные исходным значениям этих пар. Ммм, решим задачку — в лоб!
Результаты
Чтобы не растягивать, сразу сообщу вам следующее: эксперимент в целом удался, код заработал, ошибка ушла близко-близко к нулю. Но тут я заметил, что результаты всегда получаются разными.
Вопрос знатокам: похоже, эта задача имеет неограниченное количество решений, но в этом я полный ноль, думаю, мне подскажут в комментариях.
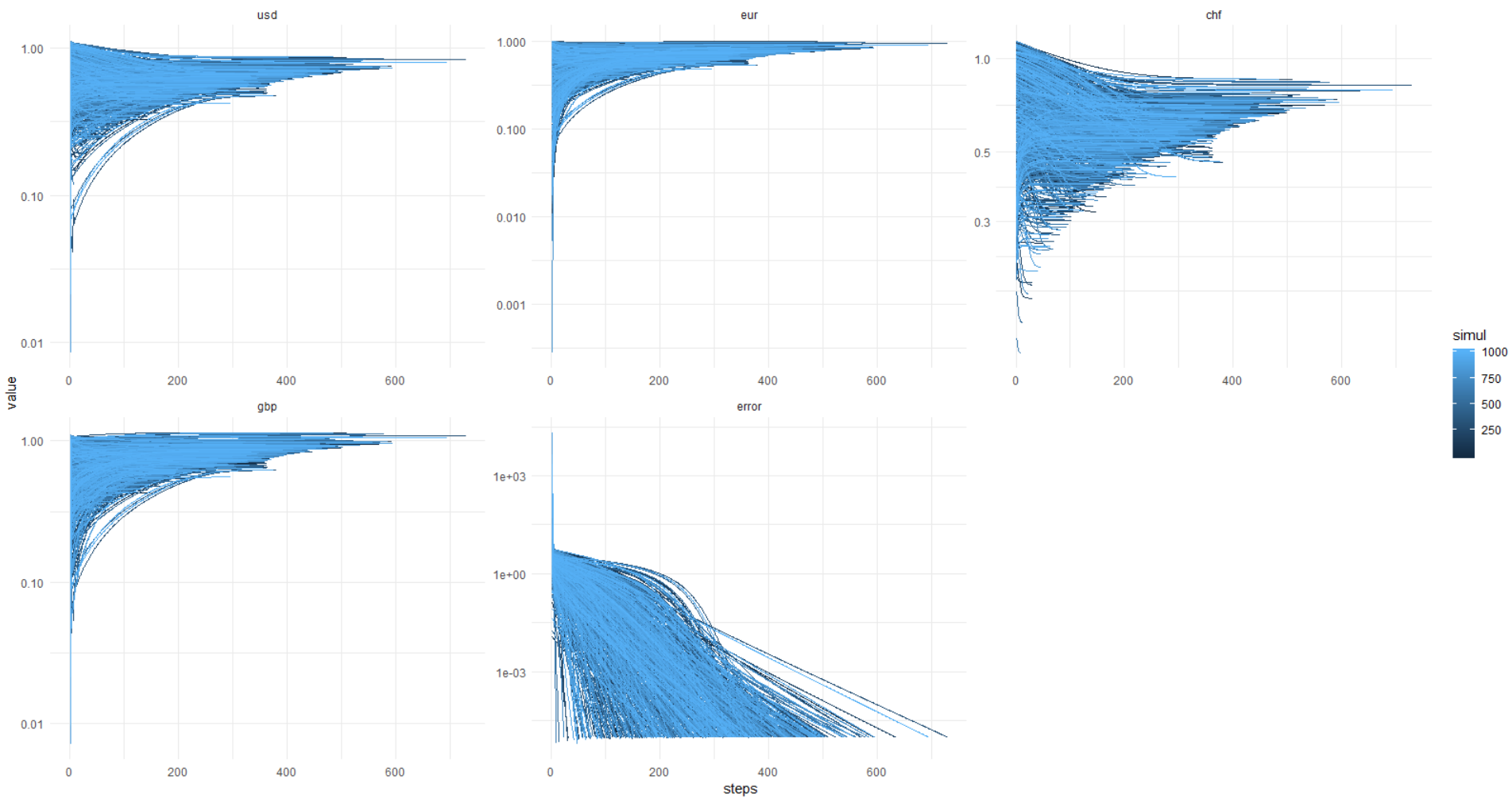
Чтобы убедиться в (не)стабильности решения, я провел симуляцию 1000 раз, не зафиксировав сид ГПСЧ для стартовых значений ценности валют.
А здесь идет картинка из ката: error достигает 0,00001 и меньше (так задана оптимизация) всегда, при этом значения валют уплывают черти-знает куда. Получается, всегда разное решение, господа!
Еще раз эта картинка, y-axis в оригинальных единицах (не лог.):
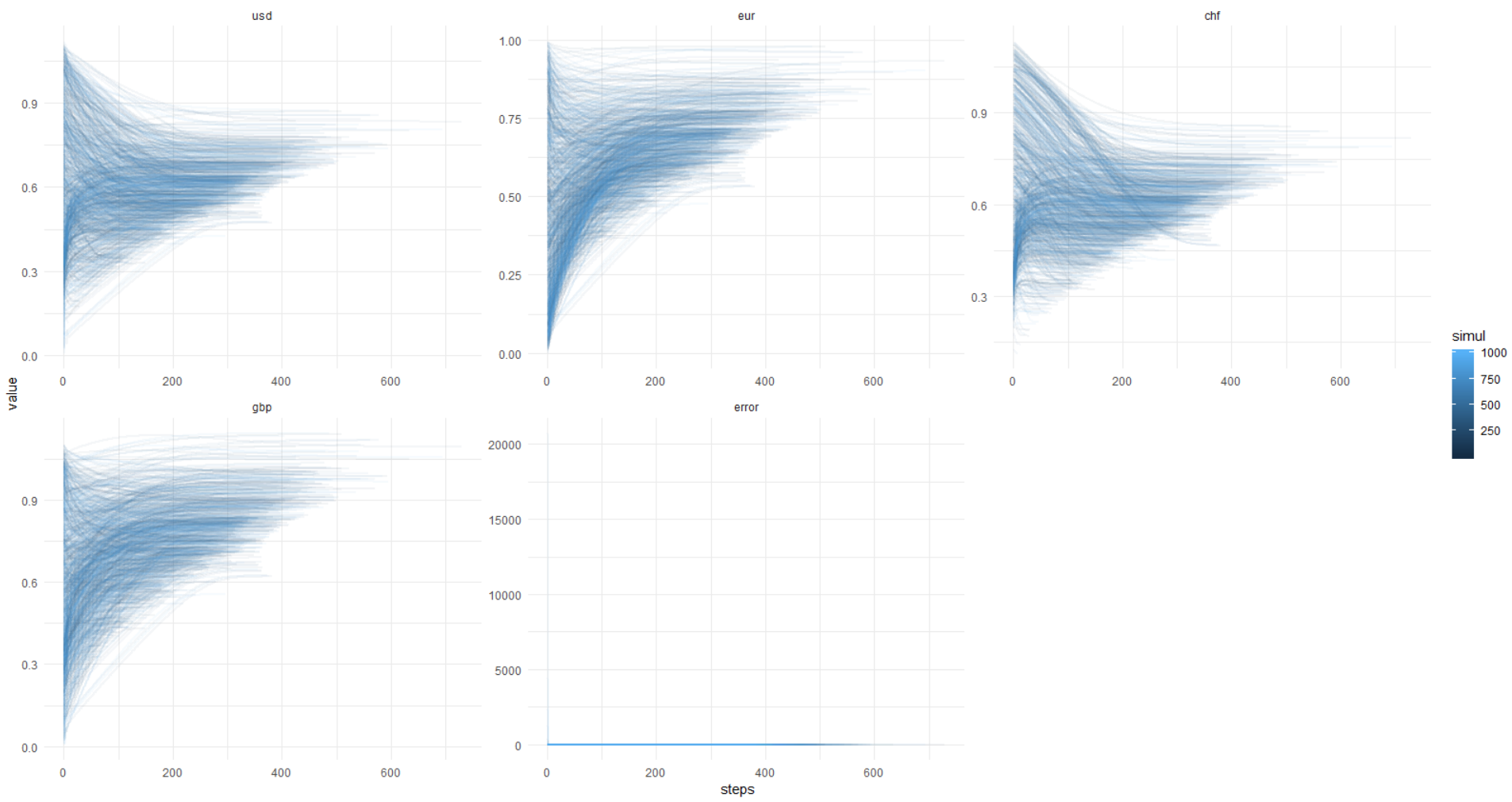
Чтобы вы могли повторить это, ниже я прикладываю полный код.
# clear environment
rm(list = ls()); gc()
## load libs
library(data.table)
library(ggplot2)
library(magrittr)
## set WD --------------------------------
# your dir here ...
## set vars -------------
currs <- c(
'usd',
'eur',
'chf',
'gbp'
)
############
## RUN SIMULATION LOOP -------------------------------
simuls <- 1000L
simul_dt <- data.table()
for(
s in seq_len(simuls)
)
{
#set.seed(111)
usd <- runif(1)
eur <- runif(1)
chf <- runif(1)
gbp <- runif(1)
# snapshot of values at time t
eurusd <- 1.12012
gbpusd <- 1.30890
eurchf <- 1.14135
eurgbp <- 0.85570
gbpchf <- 1.33373
usdchf <- 1.01896
## symbolic task ------------
express <- expression(
(eurusd - eur / usd) ^ 2 +
(gbpusd - gbp / usd) ^ 2 +
(eurchf - eur / chf) ^ 2 +
(eurgbp - eur / gbp) ^ 2 +
(gbpchf - gbp / chf) ^ 2 +
(usdchf - usd / chf) ^ 2
)
## define gradient and iterate to make descent to zero --------------
iter_max <- 1e+3
lr <- 1e-3
min_tolerance <- 0.00001
rm(grad_desc_func)
grad_desc_func <- function(
lr,
curr_list
)
{
derivs <- character(length(curr_list))
deriv_vals <- numeric(length(curr_list))
grads <- numeric(length(curr_list))
# symbolic derivatives
derivs <- sapply(
curr_list,
function(x){
D(express, x)
}
)
# derivative values
deriv_vals <- sapply(
derivs,
function(x){
eval(x)
}
)
# gradient change values
-deriv_vals * lr
}
## get gradient values ----------
progress_list <- list()
for(
i in seq_len(iter_max)
)
{
grad_deltas <- grad_desc_func(lr, curr_list = currs)
currency_vals <- sapply(
currs
, function(x)
{
# update currency values
current_val <- get(x, envir = .GlobalEnv)
new_delta <- grad_deltas[x]
if(new_delta > -1 & new_delta < 1)
{
new_delta = new_delta
} else {
new_delta = sign(new_delta)
}
new_val <- current_val + new_delta
if(new_val > 0 & new_val < 2)
{
new_val = new_val
} else {
new_val = current_val
}
names(new_val) <- NULL
# change values of currencies by gradient descent step in global env
assign(x, new_val , envir = .GlobalEnv)
# save history of values for later plotting
new_val
}
)
progress_list[[i]] <- c(
currency_vals,
eval(express)
)
if(
eval(express) < min_tolerance
)
{
break('solution was found')
}
}
## check results ----------
# print(
# paste0(
# 'Final error: '
# , round(eval(express), 5)
# )
# )
#
# print(
# round(unlist(mget(currs)), 5)
# )
progress_dt <- rbindlist(
lapply(
progress_list
, function(x)
{
as.data.frame(t(x))
}
)
)
colnames(progress_dt)[length(colnames(progress_dt))] <- 'error'
progress_dt[, steps := 1:nrow(progress_dt)]
progress_dt_melt <-
melt(
progress_dt
, id.vars = 'steps'
, measure.vars = colnames(progress_dt)[colnames(progress_dt) != 'steps']
)
progress_dt_melt[, simul := s]
simul_dt <- rbind(
simul_dt
, progress_dt_melt
)
}
ggplot(data = simul_dt) +
facet_wrap(~ variable, scales = 'free') +
geom_line(
aes(
x = steps
, y = value
, group = simul
, color = simul
)
) +
scale_y_log10() +
theme_minimal()
Код на 1000 симуляций работает около минуты.
Заключение
Вот что для меня осталось не понятно:
- можно ли хитрым математическим способом стабилизировать решение;
- будет ли схождение при большем количестве валют и валютных пар;
- если стабильности быть не может, то на каждый новый снэпшот данных наши валюты будут гулять как их вздумается, если не закрепить сид ГПСЧ, а это провал.
Вся затея представляется весьма туманной в отсутствии каких-либо внятных предпосылок и ограничений. Но это было интересно!
Ну, еще хотел сказать, что можно обойтись без МНК, когда данные хитрые, матрицы сингулярные, ну, или, когда теорию плохо знаешь (эхх...).
Спасибо eavprog за изначальный посыл.
Пока!
Комментарии (29)

vanxant
07.05.2019 17:25Кратко: без матана никак, реальность не описывается школьной математикой. Хороший пример для тех, кто кричит «нафиг нам это ваше университетское образование».
Чуть более подробно в следующем комменте.
Alexey_mosc Автор
07.05.2019 17:35Кратко: без матана никак
Еще бы вы сразу сказали, что именно никак, я не понял какой вопрос адресуется, спасибо.
vanxant
07.05.2019 17:38Теперь детали.
1. У вас тут метод наименьших квадратов, который предполагает нормальное (гауссово) распределение шумов (ошибок в начальных данных). Всем хорошо нормальное распределение, формулы короткие, считать и доказывать теоремки просто, за что его любят преподы математики и авторы учебников. Только вот с реальностью оно дружит в большинстве случаев примерно никак. Гауссово распределение в некотором смысле максимально компактное, у него самые тощие хвосты из всех возможных. Из-за этого любая ошибка во входных или промежуточных данных, которая не укладывается в рамки гауссова распределения (а большинство — не укладываются), вызывает «панику-панику» и сносит ваш алгоритм в неведомые дали. Что вы, собственно, и наблюдаете. Решение: разбираться с распределениями (строить гистограммы шумов, аппроксимировать их разными стат. моделями и считать критерий Колмогорова-Смирнова). А затем подбирать вид штрафной функции исходя из наиболее подходящего распределения.
2. Задача в вашей постановке существенно некорректно поставлена, в том смысле, что любое малое возмущение во входных данных может привести к сколько угодно большой ошибке на выходе. Наивными алгоритмами такое не решается от слова совсем, нужно как минимум гладить (т.е. на каждом шаге домножать вектор текущего решения на некую матрицу B слева и на TB справа). Определитель матрицы В должен быть равен строго 1, по диагонали должны стоять числа чуть меньше 1, а в остальных ячейках должны стоять некие малые числа. Какие конкретно это должны быть числа — нужно смотреть по результатам решения вопроса номер 1.Alexey_mosc Автор
07.05.2019 17:46У вас тут метод наименьших квадратов
Простите, но нет. Я же прямо написал, что линейную алгебру не использую.
У меня решение через аналитический градиент.
Всем хорошо нормальное распределение, формулы короткие, считать и доказывать теоремки просто, за что его любят преподы математики и авторы учебников.
Предположение о нормальности ошибок не используется совсем здесь — не нужно.
Задача в вашей постановке существенно некорректно поставлена, в том смысле, что любое малое возмущение во входных данных может привести к сколько угодно большой ошибке на выходе.
Я не знаю, что такое наивный алгоритм в вашем понимании. Но действительно симуляция показывает зависимость решения от начальных условий.vanxant
07.05.2019 17:48+1Простите, но нет. Я же прямо написал, что линейную алгебру не использую.
Простите, но да.
Вот это ваш код?
express <- expression(
(eurusd - eur / usd) ^ 2 +
(gbpusd - gbp / usd) ^ 2 +
(eurchf - eur / chf) ^ 2 +
(eurgbp - eur / gbp) ^ 2 +
(gbpchf - gbp / chf) ^ 2 +
(usdchf - usd / chf) ^ 2
)
Это МНК в незамутнённом первозданном виде.Alexey_mosc Автор
07.05.2019 17:56-1Мой код.
Тот факт, что я минимизирую сумму квадратов отклонений не делает метод МНК, я ее использую теорию матриц вообще, я делаю то, что делает нейронная сеть...
Попрошу вас немного прояснить ваш аргумент
vanxant
07.05.2019 18:22+2То, что вы отказываетесь узнавать МНК, не значит, что вы его не используете:)
Градиентный спуск просто добавляет в вашу систему уравнений дополнительные переменные — разностные производные — чтобы понизить степень уравнения.
Если вы принципиально не готовы курить матан, сделайте хотя бы следующее:
1. Добавьте коэффициенты перед квадратами, т.е. в сумме будет не просто (eurusd — eur/usd)?, а типа 1.05*(eurusd...)? + 0.89*(...)? Сами числа возьмите методом научного тыка из неких внешних данных, типа средних объёмов торгов или денежной массы М2. Арифметическое среднее ваших коэффициентов должно быть равно 1. Это сменит «вшитое» в МНК распределение с гауссова на хи-квадрат, которое всё же намного более гибкое в плане шумов.
2. Когда вы берёте начальные значения для тестов из ГСПЧ… Не знаю как сделан ГСПЧ в R, но думаю как везде — с равномерным распределением. Берите вместо просто random() арифметическое среднее от 6 идущих подряд вызовов random(). Эффект должен быть совершенно волшебным.
3. Не знаю, как у вас там дальше всё сделано, но данные всё же нужно гладить на каждом шаге. Это совершенно элементарно делается, только можно загладить насмерть: система будет устойчиво сходиться к единичному вектору, т.е. к состоянию «все валюты равны».Alexey_mosc Автор
07.05.2019 23:37Меня минусуют не оправдано. Это бред. МНК это устоявшийся термин для решения через b = (A * At)-1 * At * Y.
Это называется ordinary least squares, МНК. Если я решаю регрессионную задачу и использую квадраты невязок, через градиентный спуск, бред говорить об МНК, другие расчеты, другая сложность, другие результаты могут быть, в конце концов… Я мог выбрать фитнеса функцию как сумму модулей невязок, например… Понятно, я надеюсь…
1) производные не разностные, в тексте написано ясно (вы читали его?):
2 * (eur/usd^2 * (eurusd — eur/usd)) + 2 * (gbp/usd^2 * (gbpusd —
gbp/usd)) — 2 * (1/chf * (usdchf — usd/chf))
Это производная от дифференцмруемой ф-и. Дальше она умножается на скорость обучения, и все, классика жанра… Я ещё сделал gradient clipping [0;1].
Если вы принципиально не готовы курить матан, сделайте хотя бы следующее
Я решаю задачу БЕЗ линейной алгебры, то есть, без матана. Я исследую результат.
Это сменит «вшитое» в МНК распределение с гауссова на хи-квадрат, которое всё же намного более гибкое в плане шумов.
Это generalized linear model или что? Я вот не понял сейчас почему веса тут нужны, вот от слова совсем не понял…
Я вообще, мне не ясно как свести задачу к МНК, не ясен дизайн матрицы, я бы и по матану попробовал решить, и через GLM…
Alexey_mosc Автор
07.05.2019 23:57Гауссово распределение в некотором смысле максимально компактное, у него самые тощие хвосты из всех возможных. Из-за этого любая ошибка во входных или промежуточных данных, которая не укладывается в рамки гауссова распределения (а большинство — не укладываются), вызывает «панику-панику» и сносит ваш алгоритм в неведомые дали. Что вы, собственно, и наблюдаете. Решение: разбираться с распределениями (строить гистограммы шумов, аппроксимировать их разными стат. моделями и считать критерий Колмогорова-Смирнова). А затем подбирать вид штрафной функции исходя из наиболее подходящего распределения.</blockquot
У мня невязки уходят в ноль, задача решается на 100%, я не то делаю, что думаете вы. Тут нет выбросов, смещающих решение. Просто бесконечно много решений. В МНК это может быть возможно, если число независимых переменных намного больше числа наблюдений, не понимаю как у меня это получается.

Cekory
08.05.2019 19:27- Вы совершенно бескомпромиссно пишете чушь. Из того, что автор в качестве метрики выбрал квадрат евклидова расстояния, совершенно не следует никакого предположения о нормальности чего-либо. По факту, у него вообще статистики и распределений нет. Статистика и распределения появились бы, если бы автор начал оценивать погрешность своих результатов. Но этого нет, есть просто поиск оптимума некоторой непрерывной и дифференцируемой функции.
- Неустойчивость решения надо доказывать. Никаких предпосылок для "малое возмущение во входных данных может привести к сколько угодно большой ошибке на выходе" тут нет.
Как ниже верно замечено, достаточно очевидно, что решение здесь определено с точностью до множителя, поэтому оно не единственное. Надо накладывать еще какие-нибудь ограничения.
BadDevelop
07.05.2019 17:36+1Чтобы математически ограничить рост решения к минимизируемому функционалу добавляют норму вектора (или ее квадрат, так проще для подсчета производных) решения с каким-нибудь сравнимым с желаемой погрешностью весом (чем больше вес, тем строже будет соблюдаться условие минимизации вектора и тем больше отклонения будут влиять на итоговую погрешность). В вашем случае в expression добавится что-то такое:
… + (usd^2 + eur^2 + chf^2 + grb^2)*0.1
С порядком множителя (0.1) можно смело поигратьсяAlexey_mosc Автор
07.05.2019 17:36Регуляризация?
BadDevelop
08.05.2019 10:14+1Да, она самая. Для точности в пять знаков он будет где-то таким — 0.00001 / (4^2), я так понял это если хочется каждую из четырех валют в диапазоне (0..1) получить. То есть направляем «часть сходимости» системы на удержание размера вектора вместо погрешности. Ну и кстати — из вычисляемого выражения наверное все же лучше убрать деление (метод градиентного спуска очень любит сваливаться с гипербол в непонятно куда) — домножить все эти скобки на произведение квадратов валют, вроде как раз за счет отдельного слагаемого с регуляризацией получится эквивалентная постановка.
Alexey_mosc Автор
08.05.2019 10:59А как без деления?
BadDevelop
08.05.2019 11:08Домножить expression на (chf^2 * gpb^2 * usd^2)
Alexey_mosc Автор
08.05.2019 12:51Вот так, с регуляризацией и избавлением от деления? Спасибо.
alpha <- 1e-4 express <- expression( ( (eurusd - eur / usd) ^ 2 + (gbpusd - gbp / usd) ^ 2 + (eurchf - eur / chf) ^ 2 + (eurgbp - eur / gbp) ^ 2 + (gbpchf - gbp / chf) ^ 2 + (usdchf - usd / chf) ^ 2 + (usd^2 + eur^2 + chf^2 + gbp^2) * alpha ) * chf^2 * gbp^2 * usd^2 * eur^2 )
Результат:

Финальные решения похоже стали более равномерно распологаться в [0;1]. Ошибка опускается до 0,05 или выше.
apapacy
07.05.2019 18:41Математика математикой, а экономический смысл подобных изысканий как мне кажется нужно представлять более четко.
Я бы указал на три фактора из области экономики:
1. Объем обмена по каждой из валюты. То есть все эти же характеристики могли бы учитываться с некоторыми весами.
2. Конвертируемость. Есть валюты свободно конвертируемые или твердые. И для таких валют категория курс имеет смысл. И есть валюты не конвертируемые (с разной степенью не конвертируемости) — для них курс носит почти случайный, ситуационный характер.
3. Курс валюты (как одно число), который устанавливается государством по своим правилам является величиной которая используется для различных расчетов но с точки зрения экономики не является ни курсом покупки, ни курсом продажи (это два числа). Этот курс конечно соотносится как правило с курсом покупки/продажи и даже пытается оказывать на него регулирующее влияние. Но иногда расхождения могут быть существенные (напрмер во время кризисов)
Пытаясь выделить своеобразный «первичный» курс в котором можно выразить все другие валюты — система делает все валюты конвертируемыми а это не так. И также уходит разница между курсом покупки/продажи. А это как раз один из важных факторов которые нужно учитывать.Alexey_mosc Автор
07.05.2019 23:04Можно только работать с конвертируемыми валютами. В эксперименте все такие.
Веса это и есть курсы валют, если вы поняли метод, то восстанавливаются оригинальные котировки пар, то есть, валюты стоят ровно столько, чтобы выражение одной валюты через другую было почти 100% оригинальным.
AAbrosov
07.05.2019 21:42+2По результатам rbc.ru смог найти только следующие пары валют,
по которым есть хоть какой-то объём торгов (TOD тикер)
BYN_RUB
CHF_RUB
EUR_RUB
GBP_RUB
HKD_RUB
JPY_RUB
KZT_RUB
TRY_RUB
GBP_USD
KZT_USD
UAH_USD
USD_KZT
Есть мнение что по остальным парам вообще ничего не будет.
Вот и весь экономический смысл.Alexey_mosc Автор
07.05.2019 23:06Foreign Exchange включает намного больше, а на нашей бирже торгуется малая часть кроссов. В основном с рублем.

napa3um
08.05.2019 06:32Кажется, задачу можно свести к игре «камень-ножницы-бумага», решение которой сводится, по сути, к случайному блужданию от нуля.

slava_k
08.05.2019 10:20+1Спасибо за статью.
Если есть время и желание чуть дальше «покопать», то можно попробовать взять минутные данные за день, представить каждую минуту некоторым средним значением курса с учетом волатильности за выбранный период инструмента и сгенерировать gif/video по набору результатов, фрейм по каждой минуте. Будет ли заметно некоторое уменьшение всех вариантов решений? Может будет некоторый узкий диапазон решений, которые наиболее часто происходят (устойчивый узкий диапазон)? И что в моменты существования сужения диапазона будет происходить с ценовой волатильностью участвующих инструментов (снижается)? Может какой-то из инструментов будет чаще через волатильность кросса (объемы?) определять вектор движения «абсолютной» цены? И может тогда смотреть за динамикой ценовых волатильностей, есть ли где взаимосвязь (минутные задержки), а не пытаться найти «абсолютную» цену валют?
Если хочется хардкора с поиском внутри минут — можно взять не средние значения цены, а сразу тики. К примеру, здесь: www.truefx.com/?page=downloads. Ну или у иных агрегаторов/брокеров/бирж, в сети при желании это все можно найти.
В целом, я думаю что какого-то «среднего» в соотношении пар стабильно вряд ли возможно найти, так, чтобы на этом где-то получить хорошее матожидание. Слишком сложная система получается, со слабопрогнозируемым и неустойчивым во времени результатом. Возможно где-то внутри коротких промежутков времени (1… 5 минут) и получится что-то разглядеть, но такое больше удел HFTшников и там гораздо сложнее инструментарий.
Торговля/цены сильно завязаны на объем торгов набора инструментов по каждой валюте (кроссы/опционы/фьючерсы/CFD/etc), объемы в свою очередь завязаны на время торгов («сезонность» внутри дня, недели, месяца, внутри периодов действия деривативов, год к году и прочее), периоды торгов со временем также изменяются (летние/зимние времена, праздники и прочее).
При отсутствии данных по совокупным объемам торгов на биржах можно брать в расчет величину ценовой волатильности по инструментам, но такое допущение работает только на ликвидных мировых инструментах и только в некоторые пиковые по объемам часы (не более 1-2 часа в сутки) торгов, когда нет пересечения по кроссам с рынками других регионов (биржи азии/европы/сша) и нет новостного «шторма».
С большой долей вероятности все стандартные подходы наподобие методики из статьи либо уже не работают, либо очень редко работают в определенные моменты (в основном — при росте волатильности, пробой цены при сильном и стабильном росте объемов торгов).

echasnovski
08.05.2019 11:30+2Судя по всему, решений «много», потому что ваша целевая функция F(usd, eur, chf, gbp) инвариантна относительно умножения на скаляр: для любого a>0, F(a*usd, a*eur, a*chf, a*gbp) = F(usd, eur, chf, gbp). Это значит, что если какой-то набор (usd', eur', chf', gbp') минимизирует функцию, то то же можно сказать и про любой набор (a*usd', a*eur', a*chf', a*gbp').
Избежать этого можно положив, например, usd + eur + chf + gbp = 1, но тогда метод оптимизации должен быть другой.Alexey_mosc Автор
08.05.2019 13:16Спасибо, да, тоже заметил такую инвариантность. То есть, если стартовые значения сделать в районе 100, то решений тоже будет куча, но уже тоже в районе 100.
Избежать этого можно положив, например, usd + eur + chf + gbp = 1, но тогда метод оптимизации должен быть другой.
Можно оптимизировать через конечно-разностный метод с ограничениями или, например, вообще gradient-free.
Но вопрос вот в чем, является ли надежным предположением, что ценность валют вообще находится в рамках какой-то плотности вероятности, диапазона и т.д.
Интересно: если взять USD/JPY, курс будет уже на других порядках, так как йена миллионами исчисляется в быту. А если взять белорусский зайчик, там будут еще другие порядки. То есть, валюта зайчик вообще будет иметь ценность 0.000… от основных валют. А например Индекс доллара (взвешенный курс) гуляет около 100…
Cekory
08.05.2019 20:24Как выше заметили, в вашем подходе абсолютные валюта определена с точностью до множителя, поэтому получается много решений. Исходя из здравого смысла я наложил дополнительное условие, чтобы валюта была как можно ближе к доллару. Вместо аналитического градиента я использовал встроенную функцию
optim. Код и результат такие:
obs_rate = c( eurusd = 1.12012, gbpusd = 1.30890, eurchf = 1.14135, eurgbp = 0.85570, gbpchf = 1.33373, usdchf = 1.01896, usdusd = 1 ) loss = function(vec, rate){ sum((rate - c( vec["eur"]/ vec["usd"], vec["gbp"]/ vec["usd"], vec["eur"]/ vec["chf"], vec["eur"]/ vec["gbp"], vec["gbp"]/ vec["chf"], vec["usd"]/ vec["chf"], vec["usd"]) )^2) } initial = c(eur = 1, usd = 1, gbp = 1, chf = 1) set.seed(123) res = optim(initial, loss, rate = obs_rate) res$par # eur usd gbp chf # 1.1200905 0.9999775 1.3089043 0.9814043
Видно, что почти доллар и получается. Тут надо бы больше данных, чтобы было интереснее. Ну и дополнительные проверки на тестовой выборке с другими парами валют.
VaalKIA
Возможно, нужно дополнительное условие, того, что любая валюта представляет ценность, то есть, стремится к какому-нибудь среднему по больнице значению, а не нулю. И не знаю, какие там у вас типы, но была интересная статься про адаптивыне методы приближения, где показывалось, что разрядность всяких флоатов сильно маловата, но это можно исправить правильными алгоритмами.
Alexey_mosc Автор
У меня ошибка стремится к нулю, а ценность валюты инициализируется от 0 до 1 с равномерным распределением (в каждой итерации симуляции). А конечная стоимость валют тоже получается в этом же диапазоне, ну, может, с другой плотностью конечного решения, не равномерным…