
В статье рассматриваются подходы по построению персонализированных товарных и контентных рекомендаций, и возможные кейсы использования.
Персонализированные товарные и контентные рекомендации используются для повышения конверсии, среднего чека и улучшения опыта пользователей.

Пример использования подхода — компании Amazon и Netflix. Amazon начал использовать подход на основе коллаборативной фильтрации в первые годы существования и добился повышения выручки только за счет алгоритма на 10%. Netflix увеличивает количество просматриваемого контента за счет подхода на основе алгоритма рекомендательной системы на 40%. Сейчас, проще назвать компанию, которая не использует подобный подход, чем перечислять всех использующих.
С Netflix связана увлекательная история связанная с этой технологией. В 2006-2009 году (еще до того, как стала популярна площадка для ML состязаний Kaggle), Netflix объявил открытый конкурс на улучшение алгоритма с призовым фондом в 1 000 000 $. Конкурс длился 2 года и в нем участвовало несколько тысяч разработчиков и ученых. Если бы Netflix нанимал их в штат, расходы были бы многократно больше обещанных призовых. В результате, одна из команд выиграла отправив решение с требуемым качеством на 2 часа раньше другой команды, повторивший результат победителя. В итоге, деньги достались расторопной команде. Конкурс стал катализатором качественных изменений в области персонализированных рекомендаций.
Основной подход решения задачи построения рекомендательных систем — коллаборативная фильтрация.
Идея коллаборативной фильтрации проста – если пользователь совершал покупки товара или просмотры контента, найдем пользователей с похожими вкусами, и порекомендовать нашему клиенту то, что похожие на него люди потребляли, а клиент еще нет. Это User-Based подход.
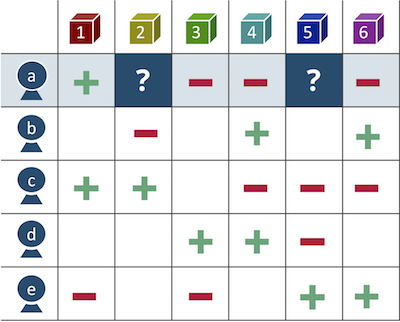
Рисунок 1 — Матрица товарных предпочтений
Аналогичным образом можно посмотреть на задачу с точки зрения товара, и подобрать комплиментарные товары к корзине клиента, повысив средний чек, или заменив отсутствующих на складе товар на аналог. Это Item-Based подход.
В самом простом случае, используется алгоритм поиска ближайших соседей.
Пример: Если Марии нравится фильм «Титаник» и «Звездные войны», ближайший по вкусам пользователь к ней будет Аня, которая смотрела в дополнении к этим фильмам еще и «Хатико». Давайте порекомендуем Марии фильм «Хатико». Стоит уточнить, что обычно используют не одного ближайшего соседа, а несколько, с усреднением результатов.
Рис.2 Принцип работы алгоритма ближайших соседей
Кажется, все просто, но качество рекомендаций с использованием подобного подхода невелико.
Рассмотрим сложные алгоритмы рекомендательных систем базирующиеся на свойстве матриц, а вернее на разложении матриц.
Классический алгоритм — SVD (сингулярное разложении матриц).
Смысл алгоритма в том, что матрица товарных предпочтений (матрица, где строки это пользователи, а столбцы это продукты, с которыми пользователи взаимодействовали) представляется произведением трех матриц.
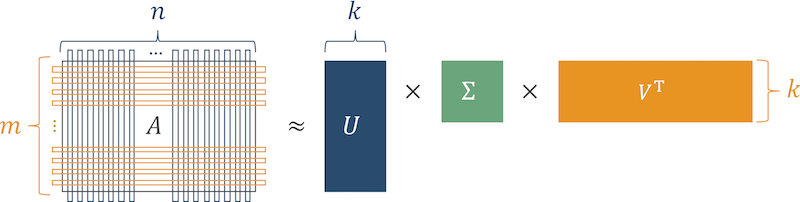
Рис.3 Алгоритм SVD
После восстановления исходной матрицы, клетки, где у пользователя были нули, а появились «большие» числа, показывают степень латентного интереса к товару. Упорядочим эти цифры, и получим список товаров, релевантных для пользователя.
При этой операции у пользователя и товара появляются «латентные» признаки. Это признаки, показывающие «скрытое» состояние пользователя и товара.
Но известно, что и пользователя и у товара помимо «латентных», есть еще и явные признаки. Это пол, возраст, средний чек покупки, регион и т.д.
Давайте попробуем обогатить этими данными нашу модель.
Для этого используем алгоритм «факторизационные машины».
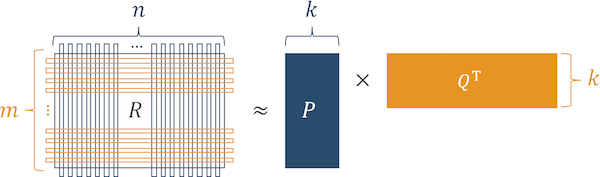
Рис.4 Алгоритм работы факторизационных машин
Из нашего опыта, в компании Data4, решения кейсов в области построения рекомендательных систем для интернет магазинов, именно факторизационные машины дают наилучший результат. Так, факторизационные машины мы использовали для построения рекомендационной системы для нашего клиента, компании KupiVip. Прирост по метрике RMSE составил 6-7%.
Но у подходов на основе разложения матриц существуют свои недостатки. Число обобщаемых паттернов взаимной комбинации товаров не велико. Для решения этой задачи целесообразно использовать нейронные сети. Но для нейронной сети требуется объемы данных, которые есть только у крупных компаний.
Из нашего опыта, в компании Data4, только у одного клиента нейронную сеть для персонализированных товарных рекомендаций дала лучший результат. Зато, при успехе, можно получить до 10% к метрике RMSE. Нейронные сети используются в YouTube и ряде крупнейших контентных площадок.
В статье мы обсудили основы устройства рекомендательных систем и кейсы использования. Узнали, что основной принцип заключается в рекомендации товаров, понравившихся людям с похожим вкусом, и применение алгоритма коллаборативной фильтрации.
В следующей статье, будут рассмотрены лайфхаки рекомендательных систем, на основе реальных бизнес кейсов. Покажем, какие метрики лучше использовать, и какой коэффициент близости выбрать для предсказания.
Персонализированные товарные и контентные рекомендации используются для повышения конверсии, среднего чека и улучшения опыта пользователей.
Пример использования подхода — компании Amazon и Netflix. Amazon начал использовать подход на основе коллаборативной фильтрации в первые годы существования и добился повышения выручки только за счет алгоритма на 10%. Netflix увеличивает количество просматриваемого контента за счет подхода на основе алгоритма рекомендательной системы на 40%. Сейчас, проще назвать компанию, которая не использует подобный подход, чем перечислять всех использующих.
С Netflix связана увлекательная история связанная с этой технологией. В 2006-2009 году (еще до того, как стала популярна площадка для ML состязаний Kaggle), Netflix объявил открытый конкурс на улучшение алгоритма с призовым фондом в 1 000 000 $. Конкурс длился 2 года и в нем участвовало несколько тысяч разработчиков и ученых. Если бы Netflix нанимал их в штат, расходы были бы многократно больше обещанных призовых. В результате, одна из команд выиграла отправив решение с требуемым качеством на 2 часа раньше другой команды, повторивший результат победителя. В итоге, деньги достались расторопной команде. Конкурс стал катализатором качественных изменений в области персонализированных рекомендаций.
Основной подход решения задачи построения рекомендательных систем — коллаборативная фильтрация.
Идея коллаборативной фильтрации проста – если пользователь совершал покупки товара или просмотры контента, найдем пользователей с похожими вкусами, и порекомендовать нашему клиенту то, что похожие на него люди потребляли, а клиент еще нет. Это User-Based подход.
Рисунок 1 — Матрица товарных предпочтений
Аналогичным образом можно посмотреть на задачу с точки зрения товара, и подобрать комплиментарные товары к корзине клиента, повысив средний чек, или заменив отсутствующих на складе товар на аналог. Это Item-Based подход.
В самом простом случае, используется алгоритм поиска ближайших соседей.
Пример: Если Марии нравится фильм «Титаник» и «Звездные войны», ближайший по вкусам пользователь к ней будет Аня, которая смотрела в дополнении к этим фильмам еще и «Хатико». Давайте порекомендуем Марии фильм «Хатико». Стоит уточнить, что обычно используют не одного ближайшего соседа, а несколько, с усреднением результатов.
Рис.2 Принцип работы алгоритма ближайших соседей
Кажется, все просто, но качество рекомендаций с использованием подобного подхода невелико.
Рассмотрим сложные алгоритмы рекомендательных систем базирующиеся на свойстве матриц, а вернее на разложении матриц.
Классический алгоритм — SVD (сингулярное разложении матриц).
Смысл алгоритма в том, что матрица товарных предпочтений (матрица, где строки это пользователи, а столбцы это продукты, с которыми пользователи взаимодействовали) представляется произведением трех матриц.
Рис.3 Алгоритм SVD
После восстановления исходной матрицы, клетки, где у пользователя были нули, а появились «большие» числа, показывают степень латентного интереса к товару. Упорядочим эти цифры, и получим список товаров, релевантных для пользователя.
При этой операции у пользователя и товара появляются «латентные» признаки. Это признаки, показывающие «скрытое» состояние пользователя и товара.
Но известно, что и пользователя и у товара помимо «латентных», есть еще и явные признаки. Это пол, возраст, средний чек покупки, регион и т.д.
Давайте попробуем обогатить этими данными нашу модель.
Для этого используем алгоритм «факторизационные машины».
Рис.4 Алгоритм работы факторизационных машин
Из нашего опыта, в компании Data4, решения кейсов в области построения рекомендательных систем для интернет магазинов, именно факторизационные машины дают наилучший результат. Так, факторизационные машины мы использовали для построения рекомендационной системы для нашего клиента, компании KupiVip. Прирост по метрике RMSE составил 6-7%.
Но у подходов на основе разложения матриц существуют свои недостатки. Число обобщаемых паттернов взаимной комбинации товаров не велико. Для решения этой задачи целесообразно использовать нейронные сети. Но для нейронной сети требуется объемы данных, которые есть только у крупных компаний.
Из нашего опыта, в компании Data4, только у одного клиента нейронную сеть для персонализированных товарных рекомендаций дала лучший результат. Зато, при успехе, можно получить до 10% к метрике RMSE. Нейронные сети используются в YouTube и ряде крупнейших контентных площадок.
Кейсы использования
Для интернет магазинов
- Рекомендовать релевантные пользователю товары на страницах интернет магазина
- В карточке товара использовать блок «вам может понравиться»
- В корзине порекомендовать комплементарные товары (пульт к телевизору)
- Если товара нет на складе, порекомендовать аналог
- Делать персонализированные рассылки
Для контента
- Увеличить вовлеченность, рекомендуя релевантные статьи, фильмы, книги, видео
Другое
- Рекомендовать людей в приложениях знакомств
- Рекомендовать блюда в ресторане
В статье мы обсудили основы устройства рекомендательных систем и кейсы использования. Узнали, что основной принцип заключается в рекомендации товаров, понравившихся людям с похожим вкусом, и применение алгоритма коллаборативной фильтрации.
В следующей статье, будут рассмотрены лайфхаки рекомендательных систем, на основе реальных бизнес кейсов. Покажем, какие метрики лучше использовать, и какой коэффициент близости выбрать для предсказания.
roofcat
Интересно, что, по идее, Нетфликсу хорошие рекомендации должны быть интересны только с т.з. улучшения пользовательского опыта — подписная можель, нерекламная монетизация и затягивать подписчика на доп просмотр не очень-то и выгодно — только полосу потратит.
kirillkosolapov Автор
Думаю, сейчас так и есть. Но когда был конкурс (более 10 лет назад), у них могла быть другая бизнес модель, они вообще начинали с проката фильмов на дисках по почте.
Don_Eric
по идее, это неверно. если пользователю будет неинтересно, то он просто уйдет и никому больше не порекомендует этот сервис. А стоимость пользователя гораздо выше чем полоса