
Привет, меня зовут Евгений. Я работаю в инфраструктуре поиска Яндекс.Маркета. Хочу рассказать сообществу Хабра о внутренней кухне Маркета – а рассказать есть что. Прежде всего, как устроен поиск Маркета, процессы и архитектура. Как мы справляемся с внештатными ситуациями: что случится, если упадёт один сервер? А если таких серверов будет 100?
А ещё вы узнаете, как мы внедряем новую функциональность на куче серверов сразу. И как тестируем сложные сервисы прямо в production, не доставляя пользователям никаких неудобств. В общем, как устроен поиск Маркета, чтобы всем было хорошо.
Когда вы вводите текст, ищете товар по параметрам или сравниваете цены в разных магазинах, все запросы прилетают на сервис поиска. Поиск – это самый большой сервис в Маркете.
Мы обрабатываем все поисковые запросы: с сайтов market.yandex.ru, beru.ru, сервиса «Суперчек», Яндекс.Советника, мобильных приложений. К нам относятся и предложения товаров в поисковой выдаче на yandex.ru.
Под поисковым сервисом я имею в виду не только непосредственно поиск, но и базу данных со всеми предложениями на Маркете. Масштаб такой: в сутки обрабатывается более миллиарда поисковых запросов. И всё должно работать быстро, без перебоев и всегда выдавать нужный результат.
Кратко опишу текущую архитектуру Маркета. Условно можно описать её схемой ниже:
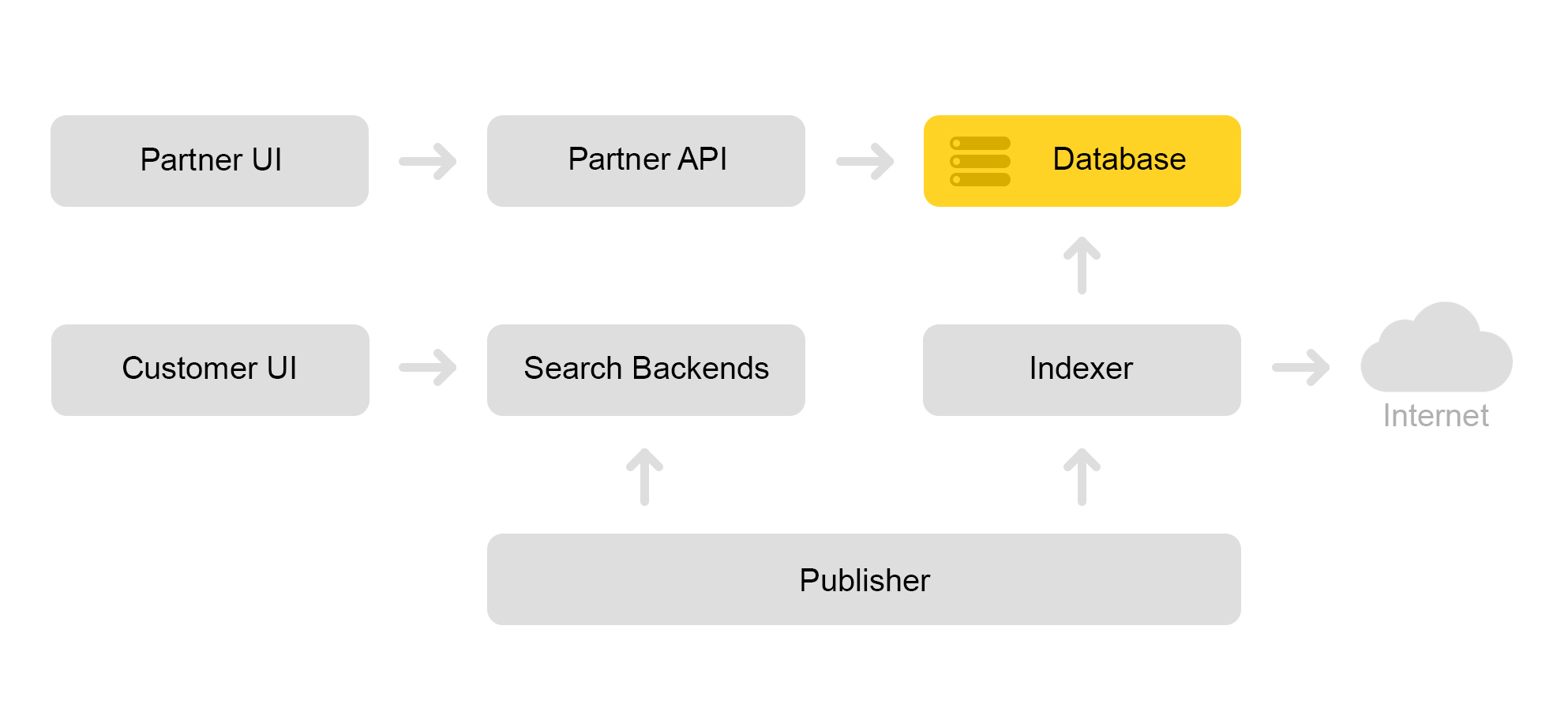
Допустим, к нам приходит магазин-партнёр. Говорит, хочу продать игрушку: вот этого злобного кота с пищалкой. И ещё злобного кота без пищалки. И просто кота. Тогда магазину нужно подготовить предложения, по которым Маркет осуществляет поиск. Магазин формирует специальный xml с предложениями и сообщает путь к этому xml через партнерский интерфейс. Затем индексатор периодически скачивает этот xml, проверяет на наличие ошибок и сохраняет всю информацию в огромную базу данных.
Таких сохранённых xml много. Из этой базы данных создается поисковый индекс. Индекс хранится во внутреннем формате. После создания индекса сервис Раскладки выкладывает его на поисковые серверы.
В итоге, в базе появляется злобный кот с пищалкой, а на сервере – индекс кота.
О том, как мы ищем кота, расскажу в части об архитектуре поиска.
Мы живем в мире микросервисов: каждый входящий запрос на market.yandex.ru вызывает очень много подзапросов, и в их обработке участвуют десятки сервисов. На схеме изображены только некоторые:
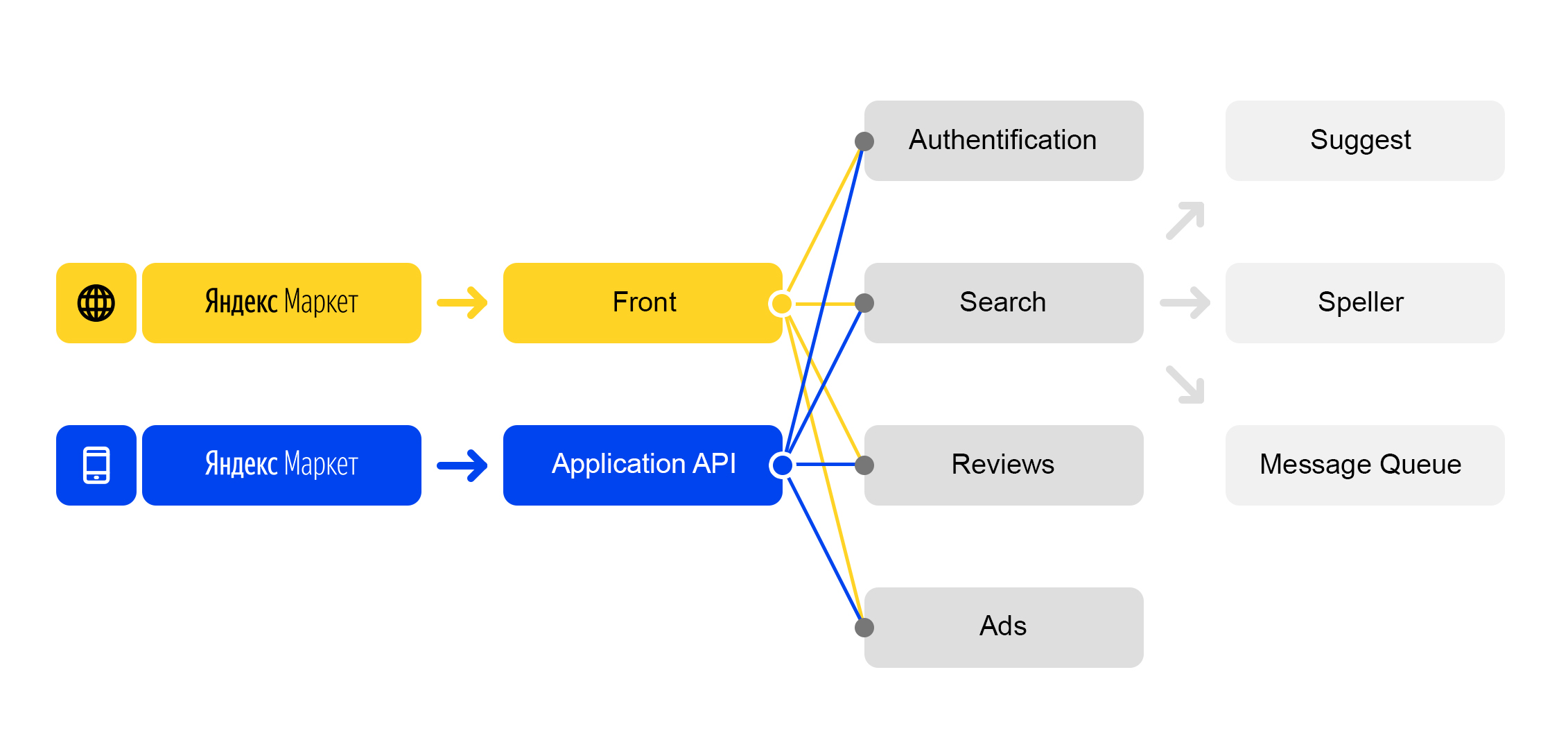
Упрощённая схема обработки запроса
У каждого сервиса есть замечательная штука – свой балансер с уникальным именем:
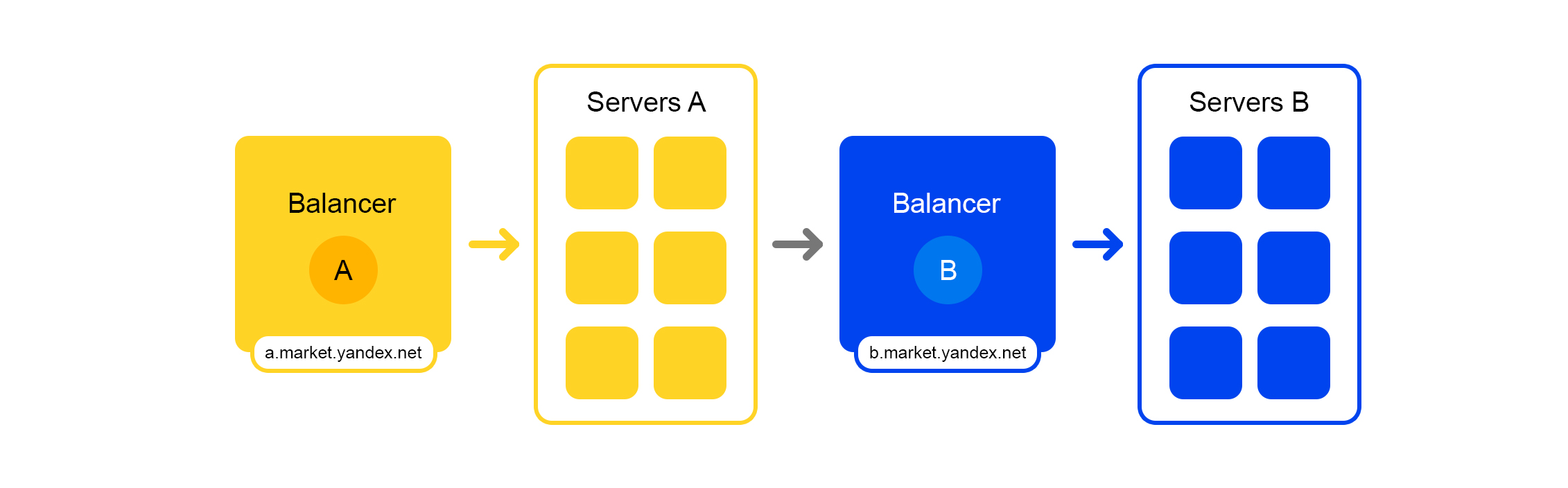
Балансер даёт нам большую гибкость в управлении сервисом: можно, например, выключать серверы, что часто требуется для обновлений. Балансер видит, что сервер недоступен и автоматически перенаправляет запросы на другие серверы или дата-центры. При добавлении или удалении сервера нагрузка автоматически перераспределяется между серверами.
Уникальное имя балансера не зависит от дата-центра. Когда сервис А делает запрос в B, то по умолчанию балансер B перенаправляет запрос в текущий дата-центр. Если же сервис недоступен или отсутствует в текущем дата-центре, то запрос перенаправляется в другие дата-центры.
Единый FQDN для всех дата-центров позволяет сервису А вообще абстрагироваться от локаций. Его запрос в сервис B всегда будет обработан. Исключение составляет случай, когда сервис лежит во всех дата-центрах.
Но не всё так радужно с этим балансером: у нас появляется дополнительная промежуточная компонента. Балансер может работать нестабильно, и эта проблема решается избыточными серверами. Также происходит дополнительная задержка между сервисами A и В. Но на практике она меньше 1 мс и для большинства сервисов это некритично.
Представьте, что случился коллапс: надо найти кота с пищалкой, но падает сервер. Или 100 серверов. Как выкрутиться? Неужели оставим пользователя без кота?
Ситуация страшная, но мы к ней готовы. Расскажу по порядку.
Поисковая инфраструктура находится в нескольких дата-центрах:
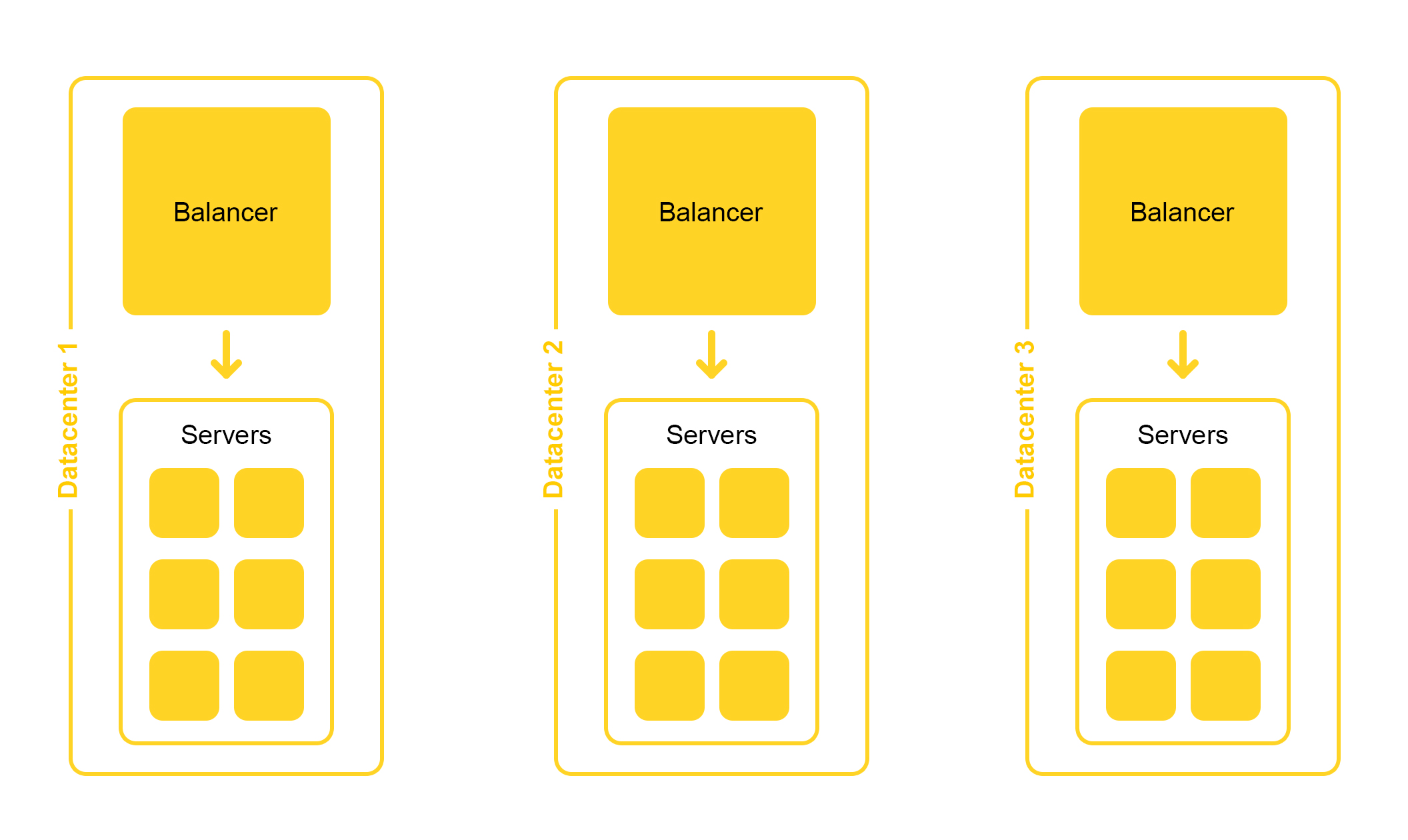
При проектировании мы закладываем возможность отключения одного дата-центра. Жизнь полна неожиданностей – например, экскаватор может перерубить подземный кабель (да, было и такое). Мощностей в оставшихся дата-центрах должно быть достаточно, чтобы выдержать пиковую нагрузку.
Рассмотрим отдельно взятый дата-центр. В каждом дата-центре одинаковая схема работы балансеров:
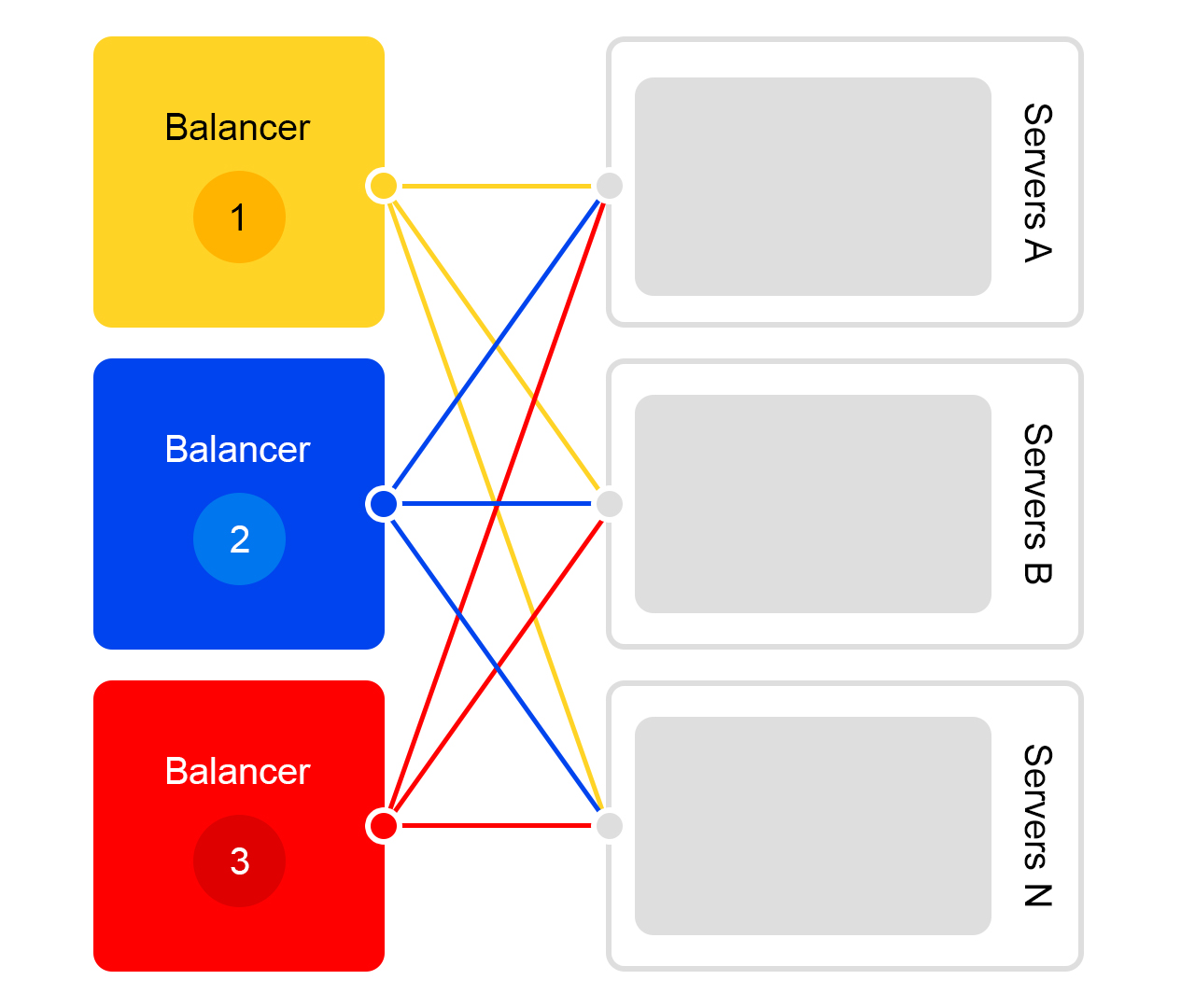
Один балансер – это как минимум три физических сервера. Такая избыточность сделана для надежности. Балансеры работают на HAProxу.
HAProxу мы выбрали из-за высокой производительности, небольших требований к ресурсам и широкой функциональности. Внутри каждого сервера работает наш поисковый софт.
Вероятность выхода из строя одного сервера невелика. Но если у вас много серверов, вероятность того, что упадёт хотя бы один, увеличивается.
Так и происходит в реальности: серверы падают. Поэтому надо постоянно отслеживать состояния всех серверов. Если сервер перестает отвечать, то его автоматически отключают от трафика. Для этого в HAProxy есть встроенный health check. Он раз в секунду ходит на все серверы с HTTP запросом «/ping».
Другая особенность HAProxy: agent-check позволяет равномерно загружать все сервера. Для этого HAProxy подключается ко всем серверам, а они возвращают свой вес в зависимости от текущей нагрузки от 1 до 100. Вес вычисляется на основании количества запросов в очереди на обработку и нагрузки на процессор.
Теперь о поиске кота. На поиск прилетают запросы вида /search?text=angry+cat. Чтобы поиск был быстрым, весь индекс кота должен помещаться в оперативную память. Даже чтение из SSD недостаточно быстрое.
Давным-давно база предложений была маленькая, и для неё хватало оперативной памяти одного сервера. По мере роста базы предложений, все перестало помещаться в эту оперативную память, и данные разделили на две части: shard 1 и shard 2.

Но так всегда бывает: любое решение, даже хорошее, порождает другие проблемы.
Балансер по-прежнему ходил на любой сервер. Но на той машине, куда пришел запрос, была только половина индекса. Остальная находилась на других серверах. Поэтому серверу надо было сходить на какую-то соседнюю машину. После получения данных от обоих серверов, результаты объединялись и переранжировались.
Поскольку балансер распределяет запросы равномерно, то все серверы занимались переранжированием, а не только отдавали данные.
Проблема возникала, если соседний сервер оказывался недоступен. Решением было указать в качестве «соседнего» сервера несколько серверов с разными приоритетами. Сперва запрос отправлялся на серверы в текущую стойку. Если не поступало ответа, запрос отправлялся на все серверы в этом дата-центре. И уже в последнюю очередь запрос шел в другие дата-центры.
По мере роста количества предложений данные разделили на четыре части. Но и это был не предел.
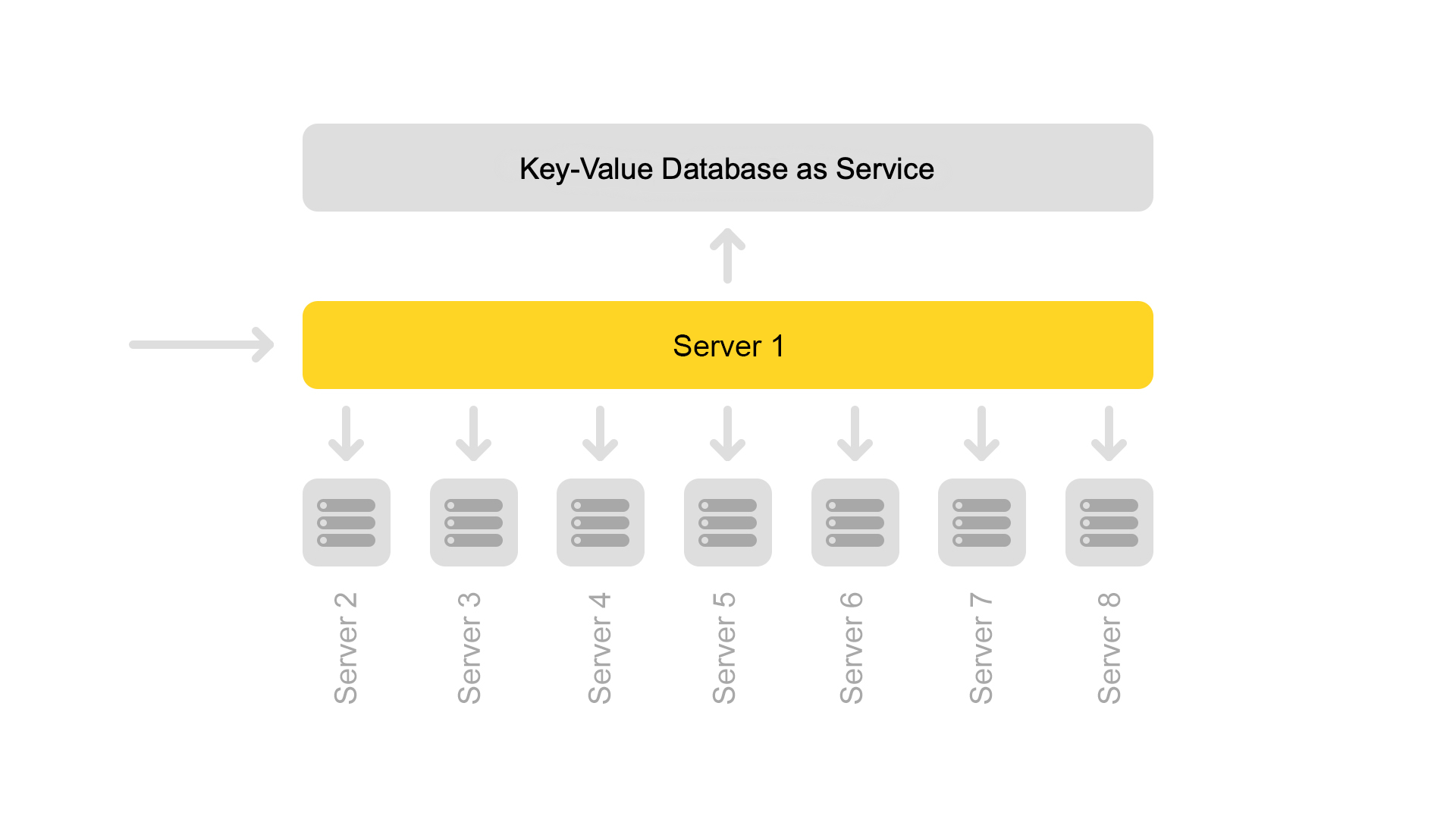
Сейчас используется конфигурация из восьми шардов. Кроме того, для ещё большей экономии памяти индекс разделили на поисковую часть (по которой происходит поиск) и на сниппетную часть (которая не участвует в поиске).
Один сервер содержит информацию только по одному шарду. Поэтому, чтобы совершить поиск по полному индексу, надо искать на восьми серверах, содержащих разные шарды.
Серверы сгруппированы в кластеры. Каждый кластер содержит восемь поисковых серверов и один сниппетный.
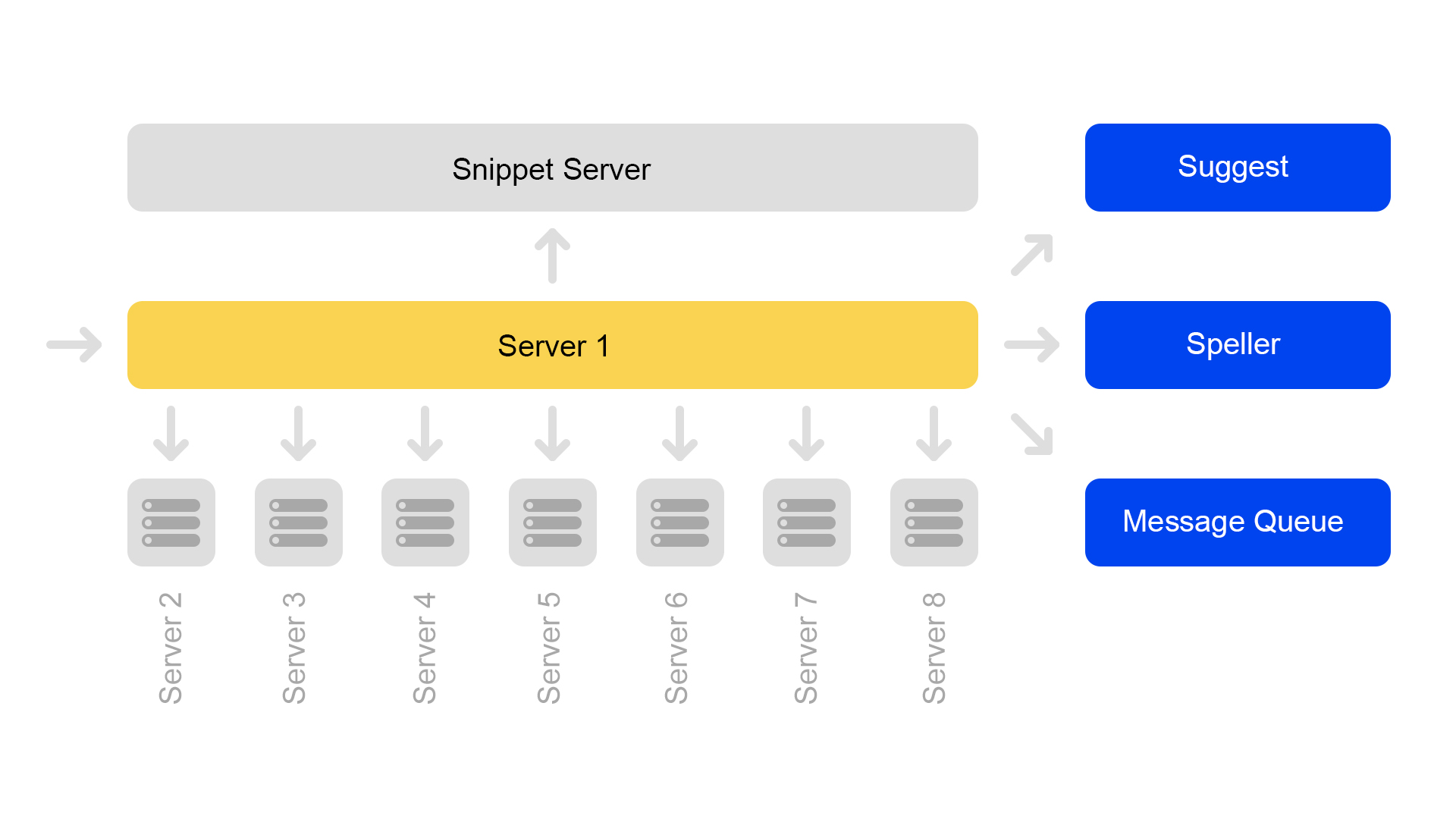
На сниппетном сервере работает key-value база данных со статическими данными. Они нужны для выдачи документов, например, описания кота с пищалкой. Данные специально вынесены на отдельный сервер, чтобы не загружать память поисковых серверов.
Поскольку ID документов уникальны только в рамках одного индекса, могла возникнуть ситуация, что в «сниппетах» отсутствуют документы. Ну или что по одному ID будет другой контент. Поэтому, чтобы поиск работал и происходила выдача, появилась необходимость в консистентности всего кластера. О том, как мы следим за консистентностью, расскажу чуть ниже.
Сам поиск устроен следующим образом: поисковый запрос может прийти на любой из восьми серверов. Допустим, он пришел на сервер 1. Этот сервер обрабатывает все аргументы и понимает, что и как надо искать. В зависимости от входящего запроса сервер может делать дополнительные запросы во внешние сервисы за нужной информацией. За одним запросом может последовать до десяти запросов во внешние сервисы.
После сбора нужной информации начинается поиск по базе предложений. Для этого делаются подзапросы на все восемь серверов в кластере.
После получения ответов результаты объединяются. В конце для формирования выдачи могут понадобиться еще несколько подзапросов на сниппетный сервер.
Поисковые запросы внутри кластера имеют вид: /shard1?text=angry+cat. Кроме того, между всеми серверами внутри кластера раз в секунду постоянно делаются подзапросы вида: /status.
Запрос /status обнаруживает ситуацию, когда сервер не доступен.
Также он контролирует, чтобы на всех серверах версия поисковика и версия индекса были одинаковы, иначе внутри кластера будут неконсистентные данные.
Несмотря на то, что один сниппетный сервер обрабатывает запросы от восьми поисковых, его процессор загружен совсем слабо. Поэтому сейчас мы переносим сниппетные данные в отдельный сервис.
Чтобы перенести данные, мы ввели универсальные ключи для документов. Теперь невозможна ситуация, когда по одному ключу возвращается контент от другого документа.
Но переход на другую архитектуру еще не завершён. Сейчас мы хотим избавиться от выделенного сниппетного сервера. А затем вообще отойти от кластерной структуры. Это позволит нам продолжать легко масштабироваться. Дополнительный бонус – значительная экономия железа.
А теперь к страшным историям со счастливым концом. Рассмотрим несколько случаев недоступности серверов.
Допустим, один сервер недоступен. Тогда остальные серверы в кластере могут продолжить отвечать, но поисковая выдача будет неполной.
Через проверку статуса /status соседние серверы понимают, что один недоступен. Поэтому, для сохранения полноты, все серверы в кластере на запрос /ping начинают отвечать балансеру, что они тоже недоступны. Получается, умерли все серверы в кластере (что не так). Это основной недостаток нашей схемы с кластерами – поэтому мы хотим от неё уйти.
Запросы, которые завершились с ошибкой, балансер переспрашивает на других серверах.
Также балансер перестает отправлять на мёртвые серверы пользовательский трафик, но продолжает проверять их статус.
Когда сервер становится доступен, он начинает отвечать на /ping. Как только начинают приходить нормальные ответы на пинги от мёртвых серверов, балансеры начинают отправлять туда пользовательский трафик. Работа кластера восстанавливается, ура.
Вырубается значительная часть серверов в дата-центре. Что делать, куда бежать? На помощь опять приходит балансер. Каждый балансер постоянно содержит в памяти текущее количество живых серверов. Он всё время считает максимальное количество трафика, которое может обработать текущий дата-центр.
Когда падает много серверов в дата-центре, балансер понимает, что этот дата-центр не может обработать весь трафик.
Тогда избыточный трафик начинает случайным образом распределятся в другие дата-центры. Всё работает, все счастливы.
Теперь о том, как мы публикуем внесённые в сервис изменения. Здесь мы пошли по пути упрощения процессов: выкатка нового релиза почти полностью автоматизирована.
Когда набирается определённое количество изменений в проекте, автоматически создается новый релиз и запускается его сборка.
Затем сервис выкатывается в testing, где проверяется стабильность работы.
Одновременно с этим запускается автоматическое тестирование производительности. Им занимается специальный сервис. Не буду о нём сейчас рассказывать – его описание достойно отдельной статьи.
Если публикация в testing прошла успешно, автоматически запускается публикация релиза в prestable. Prestable – это специальный кластер, куда направляется нормальный пользовательский трафик. Если он возвращает ошибку, балансер делает перезапрос в production.
В prestable замеряется время ответов и сравнивается с предыдущим релизом в production. Если всё нормально, то подключается человек: проверяет графики и результаты нагрузочного тестирования и затем запускает выкатку в production.
Не всегда очевидно, принесут ли изменения в сервисе реальную пользу. Чтобы измерять полезность изменений, люди придумали A/B-тестирование. Я немного расскажу, как это работает в поиске Яндекс.Маркета.
Все начинается с добавления нового CGI-параметра, который включает новую функциональность. Пусть нашим параметром будет: market_new_functionality=1. Затем в коде включаем эту функциональность при наличии флага:
Новая функциональность выкатывается в production.
Для автоматизации A/B-тестирования есть выделенный сервис, который подробно описан здесь. В сервисе создается экcперимент. Задается доля трафика, например, 15 %. Проценты задаются не для запросов, а для пользователей. Также указывается время эксперимента, например, неделя.
Одновременно может быть запущено несколько экспериментов. В настройках можно указать, возможно ли пересечение с другими экспериментами.
В результате сервис автоматически добавляет аргумент market_new_functionality=1 к 15 % пользователей. Также он автоматически считает выбранные метрики. После окончания эксперимента аналитики смотрят на результаты и делают выводы. На основании выводов принимается решение о выкатке в production или доработке.
Часто случается, что надо проверить работу новой функциональности в production, но при этом нет уверенности, как она себя поведет в «боевых» условиях под большой нагрузкой.
Есть решение: флаги в CGI параметрах можно использовать не только для A/B-тестирования, но и для проверки новой функциональности.
Мы сделали инструмент, который позволяет мгновенно изменять конфигурацию на тысячах серверов, не подвергая сервис рискам. Он называется «Стоп-кран». Первоначальная идея заключалась в возможности быстро отключать какую-то функциональность без раскладки. Затем инструмент расширился и усложнился.
Схема работы сервиса представлена ниже:
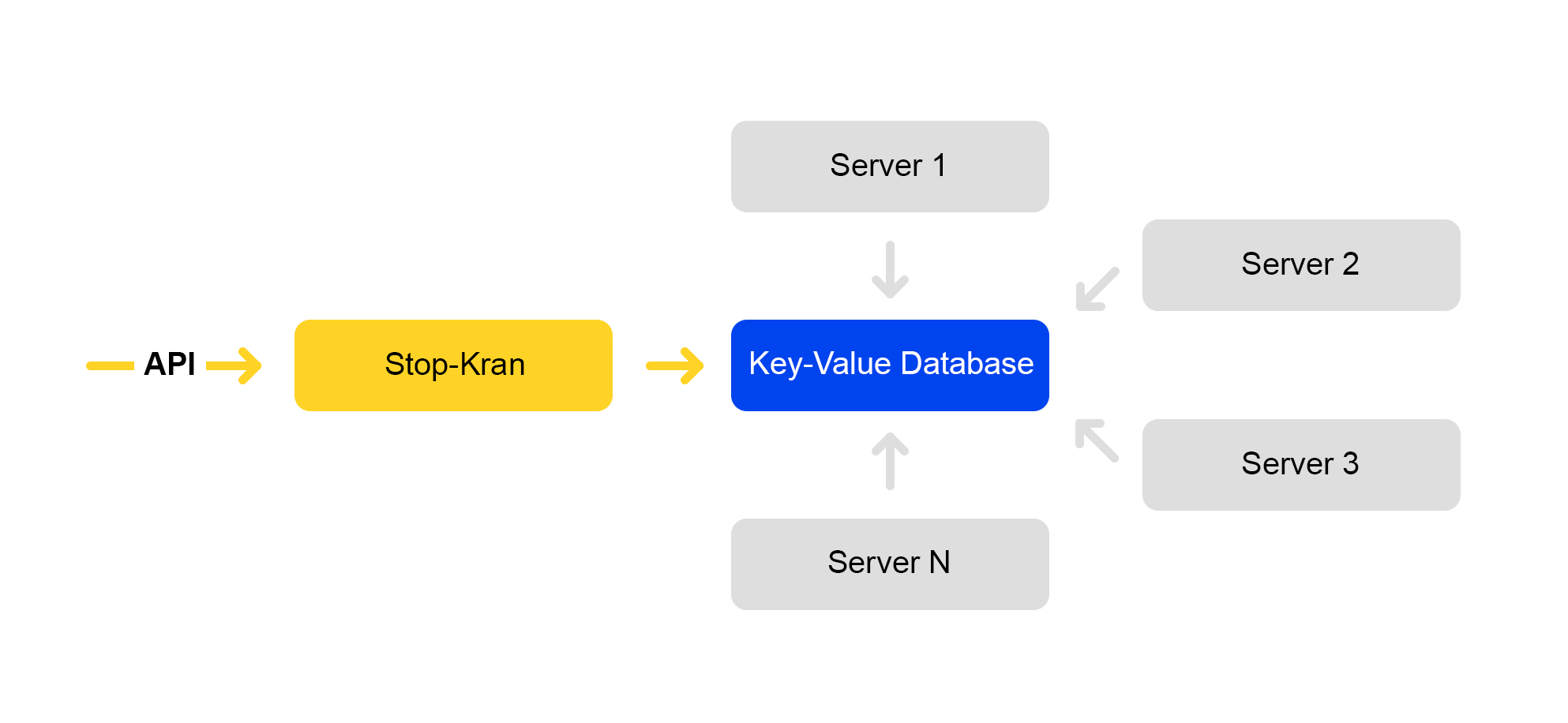
Через API задаются значения флагов. Сервис управления сохраняет эти значения базе данных. Все серверы ходят в базу раз в десять секунд, выкачивают значения флагов и применяют эти значения на каждый запрос.
В Стоп-кране можно выставлять два вида значений:
1) Условные выражения. Применяются, когда выполняется одно из значений. Например:
Значение «3» будет применяться, когда запрос будет обрабатываться в локации DC1. А значение «4», когда запрос обрабатывается на втором кластере для сайта beru.ru.
2) Безусловные значения. Применяются по умолчанию, если не выполнено ни одно из условий. Например:
value, value!
Если значение заканчивается на восклицательный знак, ему присваивается повышенный приоритет.
Парсер CGI-параметров разбирает URL. Затем применяет значения из Стоп-крана.
Применяются значения со следующими приоритетами:
Флагов, которые указываются в условных значениях, много – их хватает на все известные нам сценарии:
Этим инструментом можно включить новую функциональность на какой-то группе серверов (например, только в одном дата-центре) и проверить работу этой функциональности без особого риска для всего сервиса. Даже если вы где-то серьёзно ошиблись, всё начало падать и лег весь дата-центр, балансеры перенаправят запросы в другие дата-центр. Конечные пользователи ничего не заметят.
Если вы заметили проблему, можно сразу вернуть прежнее значение флага, и изменения откатятся назад.
У этого сервиса есть и минусы: разработчики его очень любят и часто пытаются все изменения запихнуть в Стоп-кран. Мы пытаемся бороться с неправильным использованием.
Подход со Стоп-краном хорошо работает, когда у вас уже есть стабильный код, готовый к выкатке в production. При этом у вас ещё остаются сомнения, и вы хотите проверить код в «боевых» условиях.
Однако Стоп-кран не подходит для тестирования в процессе разработки. Для разработчиков есть отдельный кластер, который называется «теневой кластер».
Запросы с одного из кластеров дублируются на теневой кластер. Но балансер полностью игнорирует ответы этого кластера. Схема его работы представлена ниже.
Мы получаем тестовый кластер, который находится в настоящих «боевых» условиях. Туда летит нормальный пользовательский трафик. Железо в обоих кластерах одинаковое, поэтому можно сравнивать производительность и ошибки.
А поскольку балансер полностью игнорирует ответы, то конечные пользователи ответов от теневого кластера не увидят. Поэтому не страшно совершить ошибку.
Итак, как же мы выстроили поиск Маркета?
Чтобы всё шло гладко, мы выделяем функциональности в отдельные сервисы. Так можно и масштабировать только те компоненты, которые нам нужны, и делать компоненты более простыми. Отдельный компонент легко отдать в другую команду и разделить обязанности по работе над ним. И значительная экономия железа при таком подходе – очевидный плюс.
Нам также помогает теневой кластер: можно разрабатывать сервисы, тестировать их в процессе и при этом не беспокоить пользователя.
Ну и проверка в production, конечно. Нужно изменить конфигурацию на тысяче серверов? Легко, используем Стоп-кран. Так можно сразу выкатить готовое сложное решение и сделать откат на стабильную версию, если возникнут проблемы.
Надеюсь, я сумел показать, как мы делаем Маркет быстрым и стабильным при постоянно растущей базе предложений. Как решаем серверные проблемы, разбираемся с огромным числом запросов, улучшаем гибкость сервиса и делаем это, не прерывая рабочих процессов.
А ещё вы узнаете, как мы внедряем новую функциональность на куче серверов сразу. И как тестируем сложные сервисы прямо в production, не доставляя пользователям никаких неудобств. В общем, как устроен поиск Маркета, чтобы всем было хорошо.
Немного о нас: какую задачу мы решаем
Когда вы вводите текст, ищете товар по параметрам или сравниваете цены в разных магазинах, все запросы прилетают на сервис поиска. Поиск – это самый большой сервис в Маркете.
Мы обрабатываем все поисковые запросы: с сайтов market.yandex.ru, beru.ru, сервиса «Суперчек», Яндекс.Советника, мобильных приложений. К нам относятся и предложения товаров в поисковой выдаче на yandex.ru.
Под поисковым сервисом я имею в виду не только непосредственно поиск, но и базу данных со всеми предложениями на Маркете. Масштаб такой: в сутки обрабатывается более миллиарда поисковых запросов. И всё должно работать быстро, без перебоев и всегда выдавать нужный результат.
Что есть что: архитектура Маркета
Кратко опишу текущую архитектуру Маркета. Условно можно описать её схемой ниже:
Допустим, к нам приходит магазин-партнёр. Говорит, хочу продать игрушку: вот этого злобного кота с пищалкой. И ещё злобного кота без пищалки. И просто кота. Тогда магазину нужно подготовить предложения, по которым Маркет осуществляет поиск. Магазин формирует специальный xml с предложениями и сообщает путь к этому xml через партнерский интерфейс. Затем индексатор периодически скачивает этот xml, проверяет на наличие ошибок и сохраняет всю информацию в огромную базу данных.
Таких сохранённых xml много. Из этой базы данных создается поисковый индекс. Индекс хранится во внутреннем формате. После создания индекса сервис Раскладки выкладывает его на поисковые серверы.
В итоге, в базе появляется злобный кот с пищалкой, а на сервере – индекс кота.
О том, как мы ищем кота, расскажу в части об архитектуре поиска.
Архитектура поиска маркета
Мы живем в мире микросервисов: каждый входящий запрос на market.yandex.ru вызывает очень много подзапросов, и в их обработке участвуют десятки сервисов. На схеме изображены только некоторые:
Упрощённая схема обработки запроса
У каждого сервиса есть замечательная штука – свой балансер с уникальным именем:
Балансер даёт нам большую гибкость в управлении сервисом: можно, например, выключать серверы, что часто требуется для обновлений. Балансер видит, что сервер недоступен и автоматически перенаправляет запросы на другие серверы или дата-центры. При добавлении или удалении сервера нагрузка автоматически перераспределяется между серверами.
Уникальное имя балансера не зависит от дата-центра. Когда сервис А делает запрос в B, то по умолчанию балансер B перенаправляет запрос в текущий дата-центр. Если же сервис недоступен или отсутствует в текущем дата-центре, то запрос перенаправляется в другие дата-центры.
Единый FQDN для всех дата-центров позволяет сервису А вообще абстрагироваться от локаций. Его запрос в сервис B всегда будет обработан. Исключение составляет случай, когда сервис лежит во всех дата-центрах.
Но не всё так радужно с этим балансером: у нас появляется дополнительная промежуточная компонента. Балансер может работать нестабильно, и эта проблема решается избыточными серверами. Также происходит дополнительная задержка между сервисами A и В. Но на практике она меньше 1 мс и для большинства сервисов это некритично.
Борьба с неожиданностями: балансировка и отказоустойчивость сервиса поиска
Представьте, что случился коллапс: надо найти кота с пищалкой, но падает сервер. Или 100 серверов. Как выкрутиться? Неужели оставим пользователя без кота?
Ситуация страшная, но мы к ней готовы. Расскажу по порядку.
Поисковая инфраструктура находится в нескольких дата-центрах:
При проектировании мы закладываем возможность отключения одного дата-центра. Жизнь полна неожиданностей – например, экскаватор может перерубить подземный кабель (да, было и такое). Мощностей в оставшихся дата-центрах должно быть достаточно, чтобы выдержать пиковую нагрузку.
Рассмотрим отдельно взятый дата-центр. В каждом дата-центре одинаковая схема работы балансеров:
Один балансер – это как минимум три физических сервера. Такая избыточность сделана для надежности. Балансеры работают на HAProxу.
HAProxу мы выбрали из-за высокой производительности, небольших требований к ресурсам и широкой функциональности. Внутри каждого сервера работает наш поисковый софт.
Вероятность выхода из строя одного сервера невелика. Но если у вас много серверов, вероятность того, что упадёт хотя бы один, увеличивается.
Так и происходит в реальности: серверы падают. Поэтому надо постоянно отслеживать состояния всех серверов. Если сервер перестает отвечать, то его автоматически отключают от трафика. Для этого в HAProxy есть встроенный health check. Он раз в секунду ходит на все серверы с HTTP запросом «/ping».
Другая особенность HAProxy: agent-check позволяет равномерно загружать все сервера. Для этого HAProxy подключается ко всем серверам, а они возвращают свой вес в зависимости от текущей нагрузки от 1 до 100. Вес вычисляется на основании количества запросов в очереди на обработку и нагрузки на процессор.
Теперь о поиске кота. На поиск прилетают запросы вида /search?text=angry+cat. Чтобы поиск был быстрым, весь индекс кота должен помещаться в оперативную память. Даже чтение из SSD недостаточно быстрое.
Давным-давно база предложений была маленькая, и для неё хватало оперативной памяти одного сервера. По мере роста базы предложений, все перестало помещаться в эту оперативную память, и данные разделили на две части: shard 1 и shard 2.
Но так всегда бывает: любое решение, даже хорошее, порождает другие проблемы.
Балансер по-прежнему ходил на любой сервер. Но на той машине, куда пришел запрос, была только половина индекса. Остальная находилась на других серверах. Поэтому серверу надо было сходить на какую-то соседнюю машину. После получения данных от обоих серверов, результаты объединялись и переранжировались.
Поскольку балансер распределяет запросы равномерно, то все серверы занимались переранжированием, а не только отдавали данные.
Проблема возникала, если соседний сервер оказывался недоступен. Решением было указать в качестве «соседнего» сервера несколько серверов с разными приоритетами. Сперва запрос отправлялся на серверы в текущую стойку. Если не поступало ответа, запрос отправлялся на все серверы в этом дата-центре. И уже в последнюю очередь запрос шел в другие дата-центры.
По мере роста количества предложений данные разделили на четыре части. Но и это был не предел.
Сейчас используется конфигурация из восьми шардов. Кроме того, для ещё большей экономии памяти индекс разделили на поисковую часть (по которой происходит поиск) и на сниппетную часть (которая не участвует в поиске).
Один сервер содержит информацию только по одному шарду. Поэтому, чтобы совершить поиск по полному индексу, надо искать на восьми серверах, содержащих разные шарды.
Серверы сгруппированы в кластеры. Каждый кластер содержит восемь поисковых серверов и один сниппетный.
На сниппетном сервере работает key-value база данных со статическими данными. Они нужны для выдачи документов, например, описания кота с пищалкой. Данные специально вынесены на отдельный сервер, чтобы не загружать память поисковых серверов.
Поскольку ID документов уникальны только в рамках одного индекса, могла возникнуть ситуация, что в «сниппетах» отсутствуют документы. Ну или что по одному ID будет другой контент. Поэтому, чтобы поиск работал и происходила выдача, появилась необходимость в консистентности всего кластера. О том, как мы следим за консистентностью, расскажу чуть ниже.
Сам поиск устроен следующим образом: поисковый запрос может прийти на любой из восьми серверов. Допустим, он пришел на сервер 1. Этот сервер обрабатывает все аргументы и понимает, что и как надо искать. В зависимости от входящего запроса сервер может делать дополнительные запросы во внешние сервисы за нужной информацией. За одним запросом может последовать до десяти запросов во внешние сервисы.
После сбора нужной информации начинается поиск по базе предложений. Для этого делаются подзапросы на все восемь серверов в кластере.
После получения ответов результаты объединяются. В конце для формирования выдачи могут понадобиться еще несколько подзапросов на сниппетный сервер.
Поисковые запросы внутри кластера имеют вид: /shard1?text=angry+cat. Кроме того, между всеми серверами внутри кластера раз в секунду постоянно делаются подзапросы вида: /status.
Запрос /status обнаруживает ситуацию, когда сервер не доступен.
Также он контролирует, чтобы на всех серверах версия поисковика и версия индекса были одинаковы, иначе внутри кластера будут неконсистентные данные.
Несмотря на то, что один сниппетный сервер обрабатывает запросы от восьми поисковых, его процессор загружен совсем слабо. Поэтому сейчас мы переносим сниппетные данные в отдельный сервис.
Чтобы перенести данные, мы ввели универсальные ключи для документов. Теперь невозможна ситуация, когда по одному ключу возвращается контент от другого документа.
Но переход на другую архитектуру еще не завершён. Сейчас мы хотим избавиться от выделенного сниппетного сервера. А затем вообще отойти от кластерной структуры. Это позволит нам продолжать легко масштабироваться. Дополнительный бонус – значительная экономия железа.
А теперь к страшным историям со счастливым концом. Рассмотрим несколько случаев недоступности серверов.
Случилось ужасное: недоступен один сервер
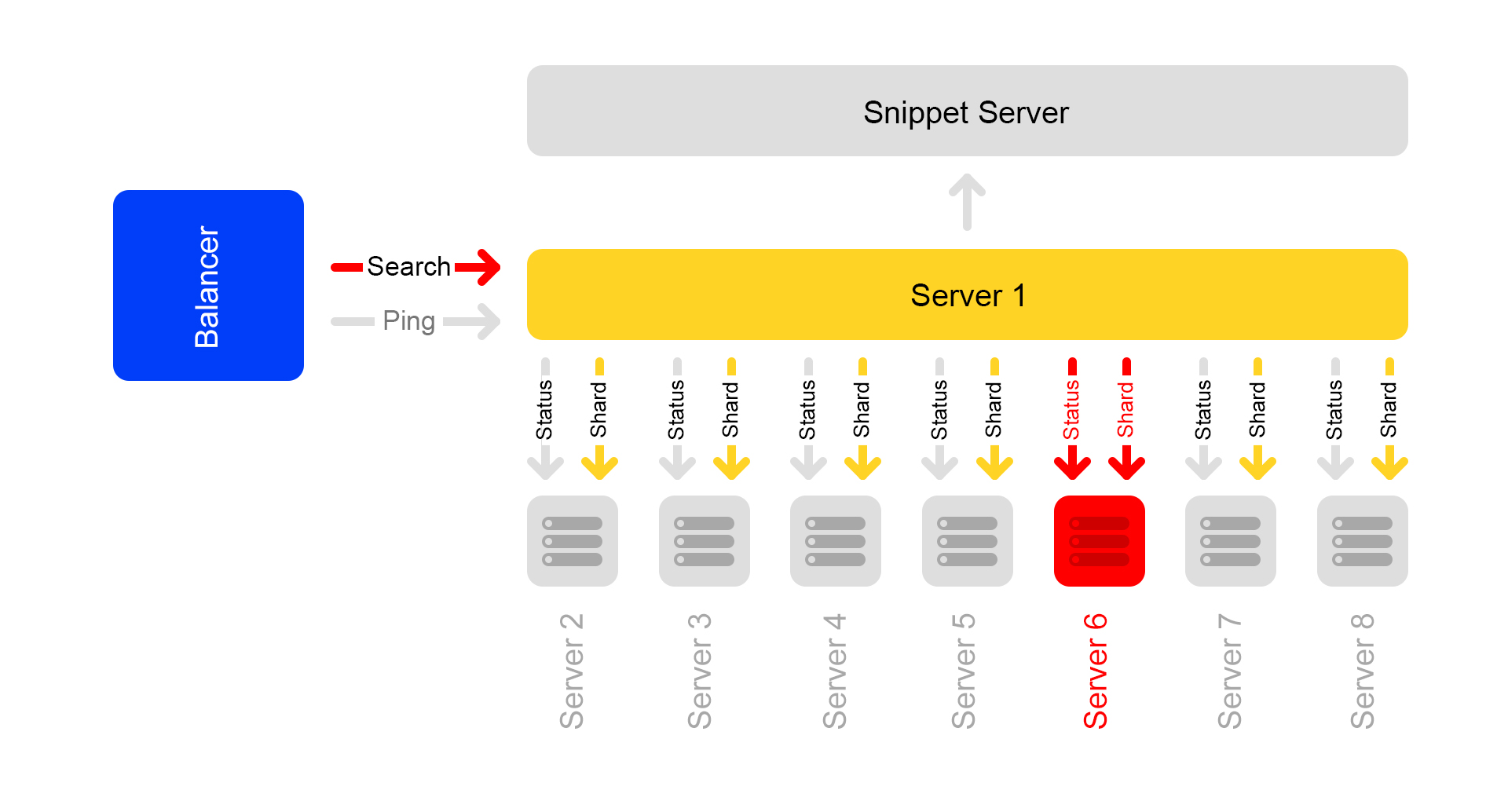
Допустим, один сервер недоступен. Тогда остальные серверы в кластере могут продолжить отвечать, но поисковая выдача будет неполной.
Через проверку статуса /status соседние серверы понимают, что один недоступен. Поэтому, для сохранения полноты, все серверы в кластере на запрос /ping начинают отвечать балансеру, что они тоже недоступны. Получается, умерли все серверы в кластере (что не так). Это основной недостаток нашей схемы с кластерами – поэтому мы хотим от неё уйти.
Запросы, которые завершились с ошибкой, балансер переспрашивает на других серверах.
Также балансер перестает отправлять на мёртвые серверы пользовательский трафик, но продолжает проверять их статус.
Когда сервер становится доступен, он начинает отвечать на /ping. Как только начинают приходить нормальные ответы на пинги от мёртвых серверов, балансеры начинают отправлять туда пользовательский трафик. Работа кластера восстанавливается, ура.
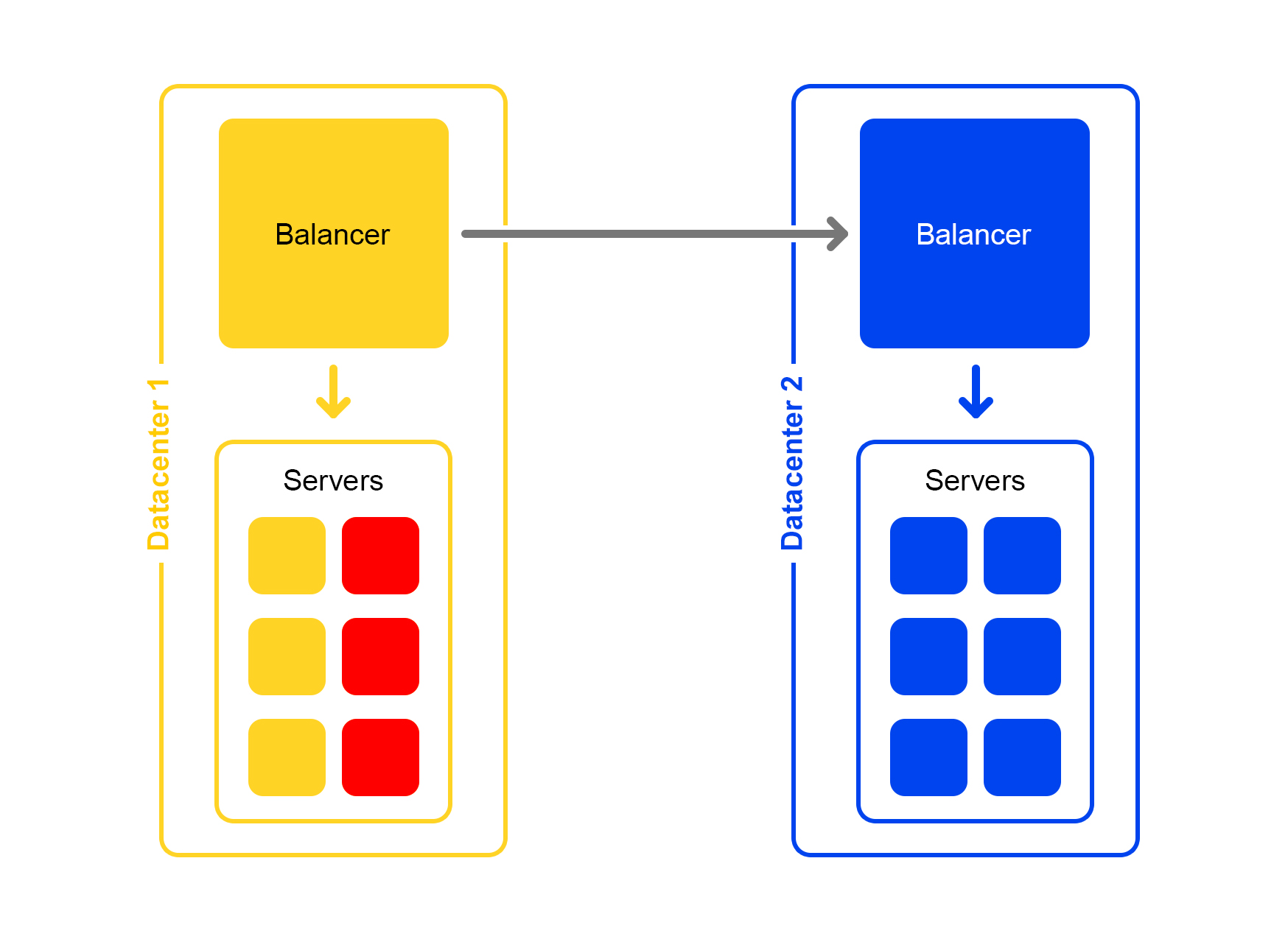
Ещё хуже: недоступно много серверов
Вырубается значительная часть серверов в дата-центре. Что делать, куда бежать? На помощь опять приходит балансер. Каждый балансер постоянно содержит в памяти текущее количество живых серверов. Он всё время считает максимальное количество трафика, которое может обработать текущий дата-центр.
Когда падает много серверов в дата-центре, балансер понимает, что этот дата-центр не может обработать весь трафик.
Тогда избыточный трафик начинает случайным образом распределятся в другие дата-центры. Всё работает, все счастливы.
Как мы это делаем: публикация релизов
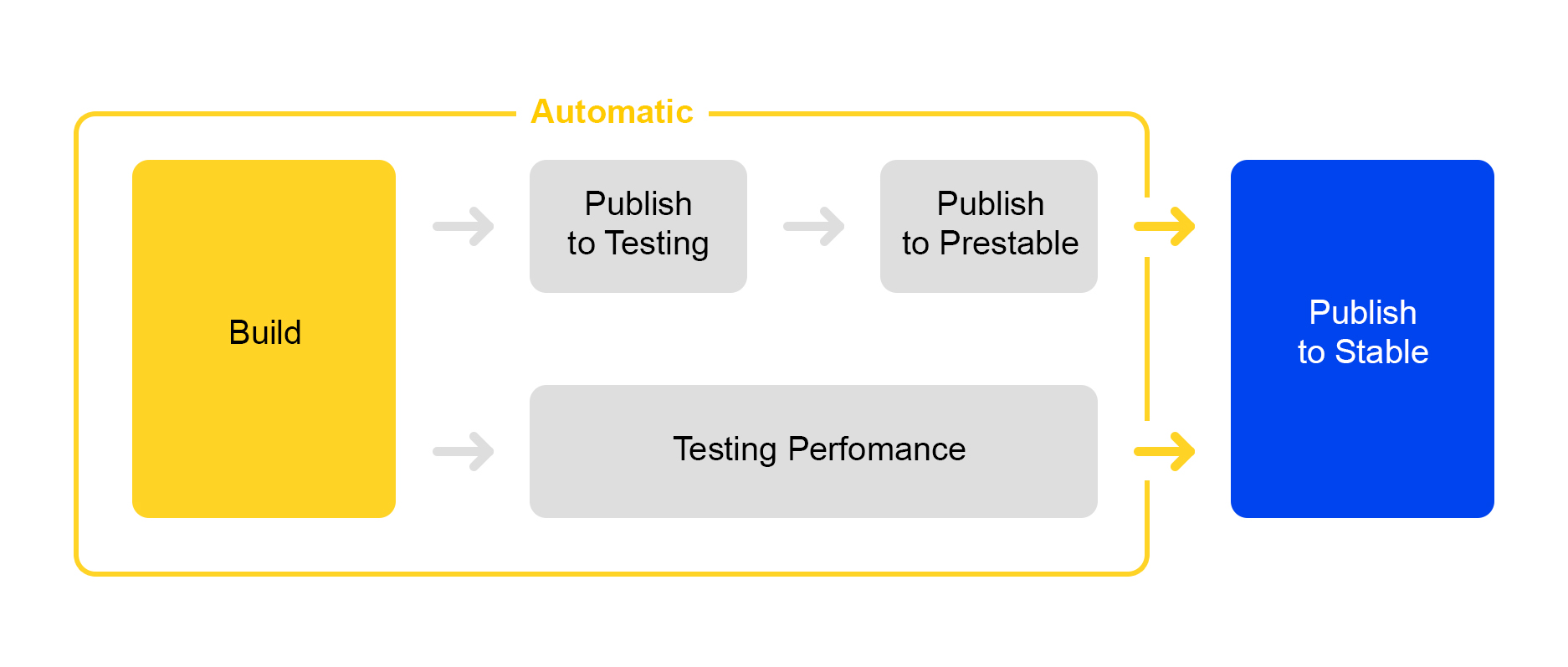
Теперь о том, как мы публикуем внесённые в сервис изменения. Здесь мы пошли по пути упрощения процессов: выкатка нового релиза почти полностью автоматизирована.
Когда набирается определённое количество изменений в проекте, автоматически создается новый релиз и запускается его сборка.
Затем сервис выкатывается в testing, где проверяется стабильность работы.
Одновременно с этим запускается автоматическое тестирование производительности. Им занимается специальный сервис. Не буду о нём сейчас рассказывать – его описание достойно отдельной статьи.
Если публикация в testing прошла успешно, автоматически запускается публикация релиза в prestable. Prestable – это специальный кластер, куда направляется нормальный пользовательский трафик. Если он возвращает ошибку, балансер делает перезапрос в production.
В prestable замеряется время ответов и сравнивается с предыдущим релизом в production. Если всё нормально, то подключается человек: проверяет графики и результаты нагрузочного тестирования и затем запускает выкатку в production.
Всё лучшее – пользователю: A/B-тестирование
Не всегда очевидно, принесут ли изменения в сервисе реальную пользу. Чтобы измерять полезность изменений, люди придумали A/B-тестирование. Я немного расскажу, как это работает в поиске Яндекс.Маркета.
Все начинается с добавления нового CGI-параметра, который включает новую функциональность. Пусть нашим параметром будет: market_new_functionality=1. Затем в коде включаем эту функциональность при наличии флага:
If (cgi.experiments.market_new_functionality) {
// enable new functionality
}Новая функциональность выкатывается в production.
Для автоматизации A/B-тестирования есть выделенный сервис, который подробно описан здесь. В сервисе создается экcперимент. Задается доля трафика, например, 15 %. Проценты задаются не для запросов, а для пользователей. Также указывается время эксперимента, например, неделя.
Одновременно может быть запущено несколько экспериментов. В настройках можно указать, возможно ли пересечение с другими экспериментами.
В результате сервис автоматически добавляет аргумент market_new_functionality=1 к 15 % пользователей. Также он автоматически считает выбранные метрики. После окончания эксперимента аналитики смотрят на результаты и делают выводы. На основании выводов принимается решение о выкатке в production или доработке.
Ловкая рука Маркета: тестирование в production
Часто случается, что надо проверить работу новой функциональности в production, но при этом нет уверенности, как она себя поведет в «боевых» условиях под большой нагрузкой.
Есть решение: флаги в CGI параметрах можно использовать не только для A/B-тестирования, но и для проверки новой функциональности.
Мы сделали инструмент, который позволяет мгновенно изменять конфигурацию на тысячах серверов, не подвергая сервис рискам. Он называется «Стоп-кран». Первоначальная идея заключалась в возможности быстро отключать какую-то функциональность без раскладки. Затем инструмент расширился и усложнился.
Схема работы сервиса представлена ниже:
Через API задаются значения флагов. Сервис управления сохраняет эти значения базе данных. Все серверы ходят в базу раз в десять секунд, выкачивают значения флагов и применяют эти значения на каждый запрос.
В Стоп-кране можно выставлять два вида значений:
1) Условные выражения. Применяются, когда выполняется одно из значений. Например:
{
"condition":"IS_DC1",
"value":"3",
},
{
"condition": "CLUSTER==2 and IS_BERU",
"value": "4!"
}Значение «3» будет применяться, когда запрос будет обрабатываться в локации DC1. А значение «4», когда запрос обрабатывается на втором кластере для сайта beru.ru.
2) Безусловные значения. Применяются по умолчанию, если не выполнено ни одно из условий. Например:
value, value!
Если значение заканчивается на восклицательный знак, ему присваивается повышенный приоритет.
Парсер CGI-параметров разбирает URL. Затем применяет значения из Стоп-крана.
Применяются значения со следующими приоритетами:
- С повышенным приоритетом из Стоп-крана (восклицательный знак).
- Значение из запроса.
- Значение по умолчанию из Cтоп-крана.
- Значение по умолчанию в коде.
Флагов, которые указываются в условных значениях, много – их хватает на все известные нам сценарии:
- Дата-центр.
- Окружение: production, testing, shadow.
- Площадка: market, beru.
- Номер кластера.
Этим инструментом можно включить новую функциональность на какой-то группе серверов (например, только в одном дата-центре) и проверить работу этой функциональности без особого риска для всего сервиса. Даже если вы где-то серьёзно ошиблись, всё начало падать и лег весь дата-центр, балансеры перенаправят запросы в другие дата-центр. Конечные пользователи ничего не заметят.
Если вы заметили проблему, можно сразу вернуть прежнее значение флага, и изменения откатятся назад.
У этого сервиса есть и минусы: разработчики его очень любят и часто пытаются все изменения запихнуть в Стоп-кран. Мы пытаемся бороться с неправильным использованием.
Подход со Стоп-краном хорошо работает, когда у вас уже есть стабильный код, готовый к выкатке в production. При этом у вас ещё остаются сомнения, и вы хотите проверить код в «боевых» условиях.
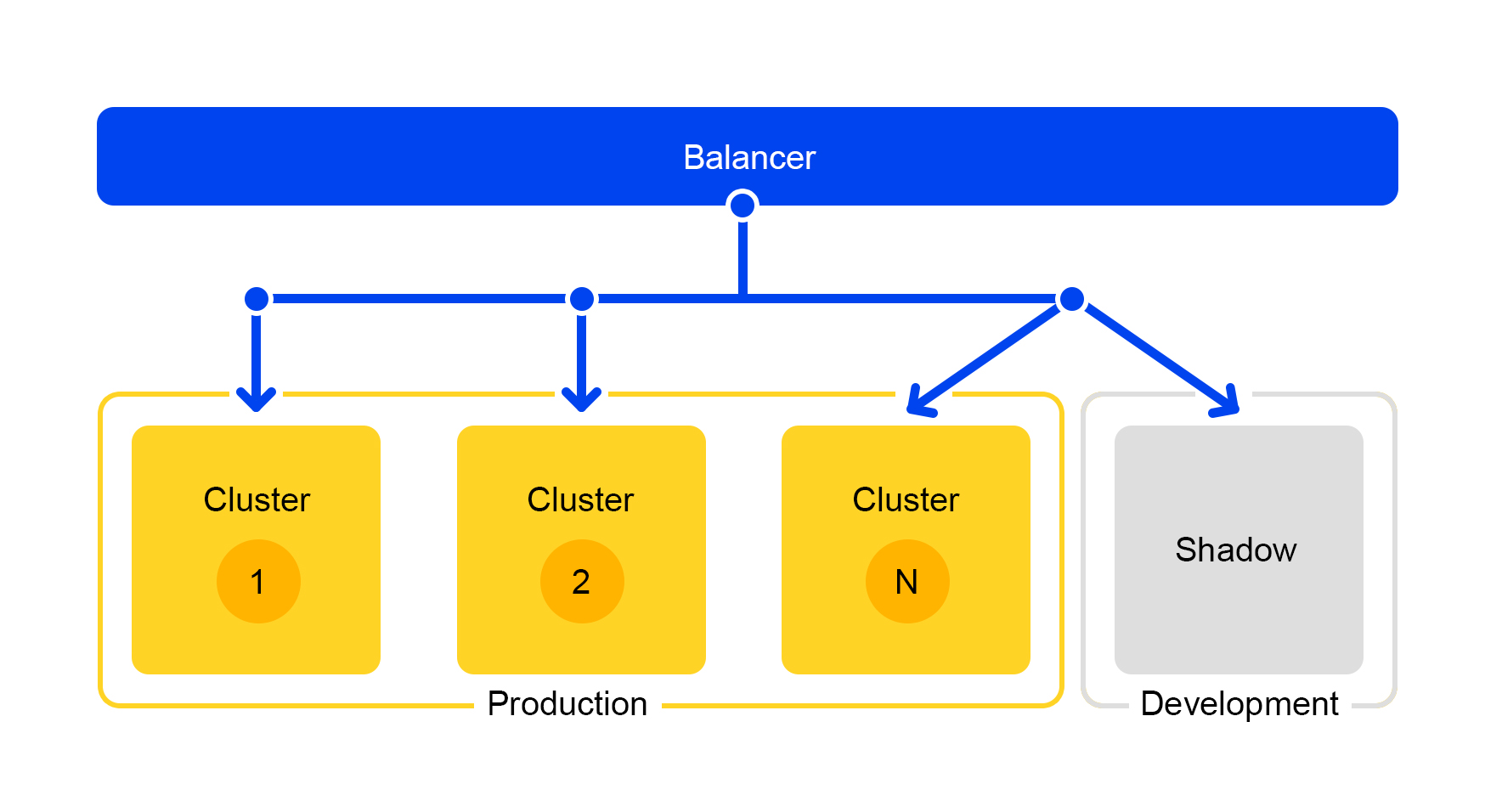
Однако Стоп-кран не подходит для тестирования в процессе разработки. Для разработчиков есть отдельный кластер, который называется «теневой кластер».
Тайное тестирование: теневой кластер
Запросы с одного из кластеров дублируются на теневой кластер. Но балансер полностью игнорирует ответы этого кластера. Схема его работы представлена ниже.
Мы получаем тестовый кластер, который находится в настоящих «боевых» условиях. Туда летит нормальный пользовательский трафик. Железо в обоих кластерах одинаковое, поэтому можно сравнивать производительность и ошибки.
А поскольку балансер полностью игнорирует ответы, то конечные пользователи ответов от теневого кластера не увидят. Поэтому не страшно совершить ошибку.
Выводы
Итак, как же мы выстроили поиск Маркета?
Чтобы всё шло гладко, мы выделяем функциональности в отдельные сервисы. Так можно и масштабировать только те компоненты, которые нам нужны, и делать компоненты более простыми. Отдельный компонент легко отдать в другую команду и разделить обязанности по работе над ним. И значительная экономия железа при таком подходе – очевидный плюс.
Нам также помогает теневой кластер: можно разрабатывать сервисы, тестировать их в процессе и при этом не беспокоить пользователя.
Ну и проверка в production, конечно. Нужно изменить конфигурацию на тысяче серверов? Легко, используем Стоп-кран. Так можно сразу выкатить готовое сложное решение и сделать откат на стабильную версию, если возникнут проблемы.
Надеюсь, я сумел показать, как мы делаем Маркет быстрым и стабильным при постоянно растущей базе предложений. Как решаем серверные проблемы, разбираемся с огромным числом запросов, улучшаем гибкость сервиса и делаем это, не прерывая рабочих процессов.
Комментарии (12)

maxim_ge
22.11.2019 13:05Каждый кластер содержит восемь поисковых серверов и один сниппетный.
Интересно, и что же происходит, если «падает» сниппетный сервер?
Один сервер содержит информацию только по одному шарду. Поэтому, чтобы совершить поиск по полному индексу, надо искать на восьми серверах, содержащих разные шарды.
А содержимое восьми шардов одинаковое во всех кластерах или возможны другие варианты?
Сейчас мы хотим избавиться от выделенного сниппетного сервера. А затем вообще отойти от кластерной структуры. Это позволит нам продолжать легко масштабироваться.
В каком смысле «отойти от кластерной архитектуры»? А что будет взамен? Звучит как мегапрорыв :)
heappro Автор
22.11.2019 19:16Интересно, и что же происходит, если «падает» сниппетный сервер?
Если падает сниппетный, то поведение аналогично. Другие соседи по кластеру узнают о падении через запрос /status. И в свою очередь тоже перестают отвечать. Кластер закрывается.
А содержимое восьми шардов одинаковое во всех кластерах или возможны другие варианты?
В штатном режиме везде одинаковые. Но бывают другие ситуации:
1) Обновление идет пачками по несколько кластеров. То есть на период обновления могут отличаться.
2) Если сервер лежал, потом включился, там оказался старый шард. Но такой кластер не откроется пользователям.
В каком смысле «отойти от кластерной архитектуры»? А что будет взамен? Звучит как мегапрорыв :)
Иммется ввиду избавиться от сущности «кластер», в которой 8+1 сервер с жесткой связью.
Будет отдельный сервис со сниппетами, а поисковые серверы не будут связаны с другими поисковыми серверами.

dmitryredkin
22.11.2019 14:28Хуже поиска в маркете — только поиск в Алиэкспрессе.
Иногда просто непонятно, как можно выдавать такую похабщину????
я конечно понимаю, что ваша цель — это не помочь покупателю, а привлечь побольше продавцов, но как-то неприятно быть кроликом, которого разводят.
С недавних пор бросил попытки побороть левиафана, товары ищу обычным поиском яндекса. Тоже времени уходит немало, но всё же эффективнее, чем в маркете.

mkevac
25.11.2019 01:24Спасибо за интересную статью!
- По какому протоколу общаются ваши сервисы? Это HTTP?
- Хватает ли возможностей HAProxy? Не возникала ли необходимость писать что-то свое?
- Используете ли вы service discovery системы типа consul/zookeeper?
Am0ralist
О, у меня есть вопрос к разработчикам Яндекс.Маркета.
Почему, когда я искал чистящую ленту LTO по артикулу, то яндекс в рекламе маркета мне показывал вменяемое количество объяв и по делу, а при переходе в маркет — мне высыпались все цена на ленты LTO вообще, хотя в запросе было конкретный артикул товара. Таким образом найти необходимое я на маркете не смог.
После чего в ТП мне смогли лишь посоветовать более конкретизировать запрос дабы
вышло ещё больше бесполезных для меня строкмаркет смог бы лучше поискать то, что мне нужно, хотя куда уж конкретнее, чем артикул?То есть если конкретизировать мой вопрос: когда уже маркет начнёт искать то, что хочет именно пользователь, а не то, что по вашему ему нужно?
natan555
Присоединяюсь с аналогичным, запрашиваешь например «Переходник SATA m.2», получаешь некую выдачу, похожую на релевантную, делаешь сортировку по цене. Все. В выдаче полная каша.
EgorZanuda
Вообще перестал пользоваться Вашим сервисом даже избегаю я.маркет по причине:
1. В выдачу запроса попадает много хлама, такое ощущение что тебя ниже плинтуса нагнули. К примеру наберите в маркете «хонор 20» и причем здесь самсунг, айфон, реалме и т.п.? Я, не запрашивал эту шнягу. Люди по мою сторону экрана не такие тупые как вы представляете там у себя, максимум опечатка в двух символах но не в 5 и тем-более не в 7 символах. Нам нужна точная выборка.
2. Агрессивность, даже из за этого прошлось сменить браузер.
roscomtheend
Интересно, когда первая страница повторяется многократно — это от падения сервиса или так и задумано? Что в их «Недвижимости», что в «Маркете» пару раз напарывался (в основном в мобильном).
И в старых ИЕ они умудряются сожрать страницей 2 гиг. Что такого можно наворотить в простом списке товаров? Впрочем, они даже телепрограмму умудряются сделать тормозящей (это просто табличка, на собеседовании фронтэндщика за час такое сваять можно как тестовое, а они свои проводят как будто марсоход будут строить).
sshikov
>первая страница повторяется многократно
Неоднократно сталкивался с тем, что поисковая выдача (цены на товар) повторяется многократно (визуально — листается бесконечно, периодически повторяясь). Обращался в ТП, ничего не добился — попросили воспроизвести, при том что я приложил конкретные условия поиска, и описал сразу, что делал.
dmitryredkin
Ответ: никогда! Кто платит сервису деньги? Продавцы. Если всегда выдавать самое выгодное предложение, в сервисе останется только один продавец, и зачем тогда нужен сервис?
Или вы думаете, что в aliexpress и google play поиск тоже ненарочно испорчен?
sshikov
Хм. Вы хотите слишком многого? Впрочем, я тоже. Совсем недавно искал DMT D3E.
При том, что я ищу это в определенной категории, при том, что это сочетание дает уникальный результат (ровно один).
Как думаете, на каком месте этот результат в выдаче? Правильно, не на первом ((( Где-то пятый, может десятый.
Сколько всего правильных ответов например на 5 страницах выдачи? Ответ — два, второй набор, включающий этот брусок, будет на 3 странице.
Что будет, если ввести DMT/D3E, как в правильном ответе? Ничего хорошего, правильный ответ переместится еще дальше от начала.
Что будет, если ввести «DMT/D3E»? Правильный ответ будет первым, но будет еще два неправильных.